基于多样性的一致谱嵌入学习
2022-09-24王长鹏
耿 莉, 王长鹏
(长安大学 理学院, 西安 710064)
0 引 言
近年来, 随着多视图数据的大量增长, 多视图聚类[1]在各领域应用广泛, 如医学诊断[2]、 生物数据分析、 信息检索、 轨迹线分析[3]、 异常检测[4]等. 因此, 如何充分利用多视图数据的互补性和兼容性成为数据挖掘、 计算机视觉和机器学习领域一个重要课题. 在建立多视图聚类模型[5]过程中, 应遵循使类间差异尽可能大、 类内差异尽可能小的原则, 在考虑数据质量的基础上, 较全面地利用多视图数据的各特征.
目前, 多视图聚类算法中基于图学习的多视图聚类方法[6-11]受到广泛关注. 在多数情况下, 基于图的方法能取得令人满意的性能. 其基本思想是: 对给定数据样本进行特征提取得到每个视图相应的数据矩阵, 通过一些相似性度量方法构造图矩阵, 然后建立模型以获得高质量用于聚类的融合图矩阵. Nie等[12]将图的构建与谱聚类作为两个分离的过程进行建模, 但未取得令人满意的性能; 文献[13]进一步提出了将两个过程整合到统一框架的模型; Wang等[14]提出了一种更简洁、 高效的方法, 该方法先自加权每个图矩阵, 可获得更好的融合图矩阵, 然后对融合矩阵加入Laplace秩约束控制融合图的连通分量, 在融合图上直接得到聚类结果, 并考虑了不同的图度量对聚类性能的影响; Zhan等[15]利用Hadamard积将不同视图直接融合, 保持其内在结构, 学习到的全局图也尽可能接近得到的Hadamard积, 最后直接由全局图本身得到聚类结果; Zhan等[16]利用定义的代价函数最小化不同视图的差异, 通过考虑视图的兼容性获得具有Laplace秩约束的一致图; Liang等[17]通过增加对于视图不一致部分的关注, 更全面地捕获视图特有的信息; Huang等[18]将自加权学习融合图的过程与多样性度量整合到统一框架中, 得到具有确定分量的融合图, 直接获得标签分布; Wu等[19]设计了一个无参数的模型, 该模型同时关注两个不同的方面, 即不同视图的重要性不同和同一视图不同特征的重要性不同. 上述方法提升了聚类性能, 但计算复杂度较高. Shi等[20]提出了结合矩阵分解相关知识的方法, 降低了模型的计算复杂度, 但其未充分考虑每个视图特有的属性, 而且忽略了不同视图的重要性不同, 未分配每个视图合适的权重.
现有的多视图聚类算法仍存在以下问题亟待解决:
1) 现有的多数方法只考虑了视图之间的一致性, 忽略了视图的不一致部分, 会对聚类结果产生影响;
2) 许多方法需要后续的处理才能得到聚类结果, 而这些步骤会导致信息损失;
3) 各过程独立进行, 导致次优的聚类性能.
为解决上述问题, 本文提出一种基于离散化的一致谱嵌入学习(diversity consensus spectral embedding, DCSE)聚类算法, 通过自加权策略学习不同视图的权重, 并将视图多样性整合到一致图学习过程中, 同时学习一致的谱嵌入, 以便获得聚类指标矩阵. 为求解该优化问题, 本文采用交替迭代优化方案, 并在4个真实数据集上验证本文算法的有效性. DCSE算法流程如图1所示.

图1 DCSE算法流程Fig.1 Flow chart of DCSE algorithm
1 预备知识
1.1 图学习
近年来, 各种相似性度量准则被广泛应用于多视图问题中, 如二进制相似、 余弦相似、 高斯核相似及文献[21]提出的相似性度量准则. 对于给定的多视图数据Xv∈dv×n(其中dv为第v个视图的维数,n为样本数), 可同时基于多视图的一致性与不一致性建模:

(1)
其中:v表示视图的数量;W(i)为第i个视图的相似性矩阵,αi为其对应的缩放系数, 为使缩放结果唯一, 本文限制α中分量和为1, 用简单的加法思想可得W(i)=A(i)+E(i),A(i)为多视图的一致部分,E(i)=W(i)-A(i)为各视图的不一致部分;S为一致相似矩阵;B=(bij)∈v×v的对角线元素为β, 非对角线元素为γ.
1.2 谱聚类
给定一个集合的数据点X=(x1,x2,…,xn)∈d,W=(wij)∈n×n表示数据点之间的相似性, 则谱聚类的目标函数可表示为

(3)
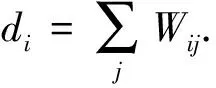
1.3 聚类指标矩阵学习
离散的多图学习可同时进行谱嵌入与聚类指标矩阵的学习[22], 从而更精确地逼近最优离散解, 其目标函数为
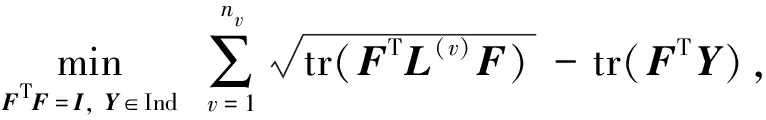
(4)
其中:F为一致谱嵌入;Y∈n×c为聚类指标矩阵, 即每行只有一个元素为1, 其余元素均为0,n和c分别为样本数和聚类数量.该目标函数将谱嵌入学习与聚类指标矩阵学习两个分开的过程整合到统一框架中, 取得了较好的结果.
2 DCSE算法
2.1 算法模型
本文将一致图学习、 一致谱嵌入与聚类指标矩阵的学习过程整合到统一框架, 可得目标函数为

(5)
其中:wi为第i个视图的权重;Ai=Ci+Ei,Ai为构造的相似性矩阵,Ci为各视图的一致部分,Ei=Ai-Ci为视图之间的不一致部分, 即每个视图特有的属性;B=(bij)∈v×v的对角线元素为β, 非对角线元素为α;λ和σ为平衡参数.第一项与最后一项可获得更高效的一致图S, 第二项与第三项用于学习一致谱嵌入F和聚类指标矩阵Y, 各过程相互促进, 共同提升聚类性能.
2.2 优 化
由式(5)可知, 目标函数主要有4个变量需要求解, 若同时考虑4个变量, 则式(5)是非凸问题, 但当求解一个变量固定其余变量时, 则问题变为凸优化问题.因此, 本文采用交替迭代策略对目标函数进行优化.
2.2.1 更新Ci
当只考虑变量Ci时, 式(5)可转化为

(6)
对式(6)关于Ci求偏导, 并令导数为0, 可得下列v个矩阵方程:

(7)
P=B(wwT)+diag(w),
(8)
其中diag(w)表示对角矩阵, 第i个对角元素为wi.
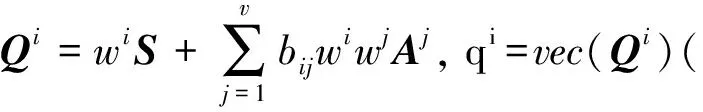
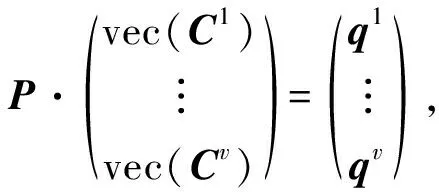
(9)
即
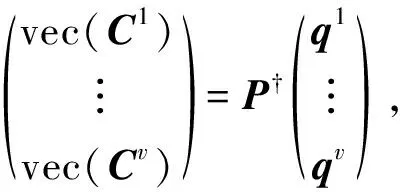
(10)
其中P†表示P的伪逆矩阵.最后, 可通过vec(Ci)得到Ci.同时, 为满足约束条件Ai≥Ci≥0(i=1,2,…,v), 可进一步得Ci的解为
Ci=max{Ci,0},Ci=min{Ai,Ci}.
(11)
2.2.2 更新S
固定Ci,F,Y时, 只考虑变量S, 则式(5)为
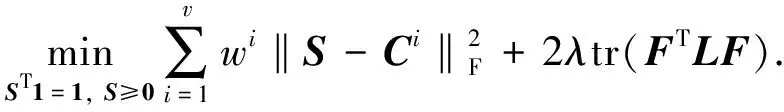
(12)
将式(12)写成元素的形式为
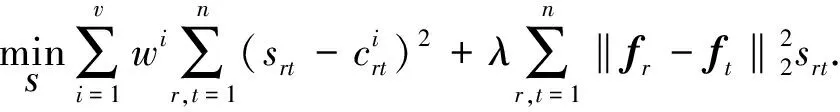
(13)
式(13)对每个r独立, 因此有

(14)
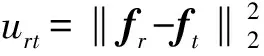

(15)

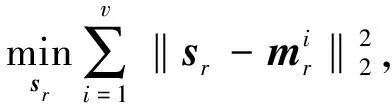
(16)
其具体求解过程同文献[14].
2.2.3 更新F
固定式(5)中其余变量, 只考虑一致谱嵌入F, 可得

(17)
将式(17)改写成如下形式:

(18)
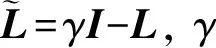
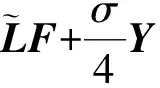
证明: 式(18)的Lagrange函数为

(19)
其中Lagrange乘子φ是对称矩阵.将式(19)关于F求偏导并令导数为0, 可得

(20)
即
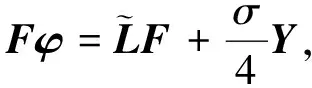
(21)
通过紧奇异值分解得

(22)
因此, 有
(Fφ)T(Fφ)=(UΣVT)T(UΣVT),
(23)
即
φTφ=VΣ2VT.
(24)
因为φ为对称矩阵, 所以
φT=φ,φTφ=φ2,
从而
φ=VΣVT.
(25)
将式(25)代入式(22)可得
F(VΣVT)=UΣVT,
(26)
即
F=UVT.
(27)
2.2.4 更新Y
当Ci,S,F固定时, 式(5)为
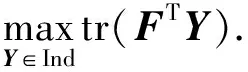
(28)
由迹相关性质可知tr(FTY)=tr(YFT), 从而有
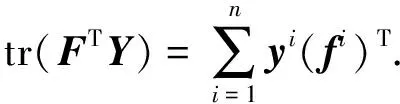
(29)
因为Y∈Ind, 所以Y的每行有且仅有一个元素为1, 其余元素为0, 而且每行元素独立, 于是可逐行更新Y:
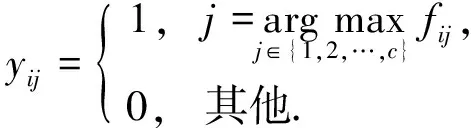
(30)
算法1求解问题(5).
输入:A1,A2,…,Av, 参数σ, 聚类数c;
输出: 聚类指标矩阵Y;

循环:
1) 由式(10)和式(11)更新Ci;
2) 通过求解式(16)更新S;
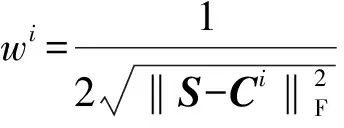
4) 由随机初始化得正交矩阵F, 由文献[23]得参数γ, 迭代更新F;
5) 由式(30)更新Y.
直至收敛.
2.3 时间复杂度分析
本文采用迭代方法对式(5)进行求解, 将式(5)分解为多个子问题进行计算, 其各子问题的时间复杂度如下: 式(10)和式(11)用于更新Ci, 其时间复杂度为O(v2n2); 式(16)用于更新一致图S, 其时间复杂度为O(cn); 式(27)用于更新F, 其时间复杂度为O(t1nc2), 其中t1表示更新F时的迭代数量; 式(30)用于更新Y, 其时间复杂度为O(cn); 更新wi的时间复杂度为O(vn2).假设整个算法的迭代数量为t2, 则该算法的时间复杂度为O(t2(v2n2+cn+t1nc2+vn2)).
3 实验与分析
为充分评估模型的有效性, 本文在4个广泛使用的数据集上进行实验, 并将聚类结果与现有方法进行比较.
3.1 数据集
本文选取4个数据集ORL,Yale,MSRCV1和Cal-7, 各数据集的信息列于表1. 数据集ORL包含40个人的400张不同图像, 每张图像在不同条件下获得. 3个视图的特征维数分别为d1=4 096,d2=3 304,d3=6 750. 数据集Yale从15个个体中提取165个样本, 每张图像通过不同的灯光、 面部表情和姿势获取, 共3个视图的数据. 数据集MSRCV1从8个类别中提取7个类别, 分别为树、 建筑、 飞机、 牛、 人脸、 汽车和自行车, 共210个样本. 广泛使用的Caltech101是包含101个类别的数据集, 而数据集Cal-7是由其中7个类别的1 474个样本所构成的数据集.

表1 数据集信息
3.2 评价指标
为验证本文模型的有效性, 采用5个广泛使用的指标精度(accuracy, ACC)、 归一化互信息(normalized mutual information, NMI)、 纯度(Purity)、F-score、 调整兰德系数(adjusted Rand index, ARI)评估其聚类性能, 指标数值越大, 聚类性能越好.
ACC表示为
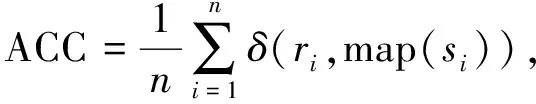
(31)
其中n表示属于c类样本点个数,ri表示第i个样本的真实标签,si表示对应学习到的标签,δ(·,·)表示Dirac函数, map(·)表示最优的映射函数.NMI表示为

(32)
其中I(ri,si)表示ri和si的互信息,H(·)表示信息熵.Purity表示为
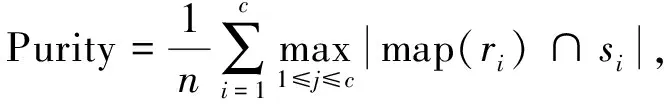
(33)
其表示正确聚类的样本占总样本的百分数.F-score表示为

(34)
其综合考虑准确率(Precision)和召回率(Recall)的调和值, 其中
ARI表示为
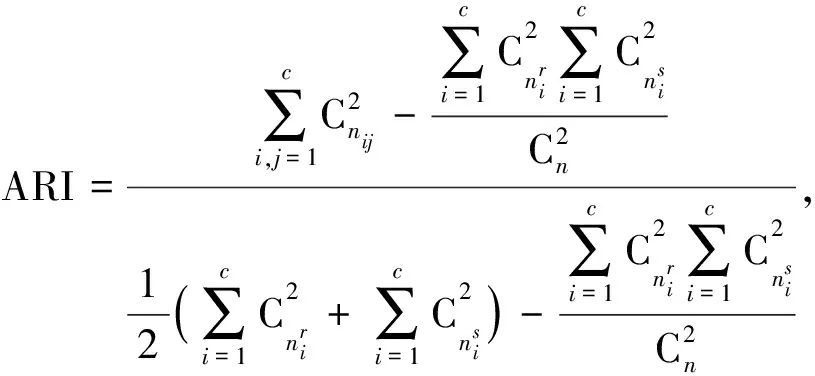
(35)
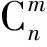
3.3 对比方法
将本文算法与现有的多视图聚类算法进行比较, 按原算法进行参数设置, 对比方法如下:
1) 经典的谱聚类算法(spectral clustering, SC), 本文在每个视图上实施该方法, SC1表示在第一个视图上运行该算法, 其余依次表示在对应视图上运行该算法;
2) 基于多图融合的多视图聚类算法(multi-graph fusion for multi-view spectral clustering, GFSC)同时考虑图融合与结构, 在进行谱聚类步骤后执行K-means以获得最终的标签;
3) 基于图学习的多视图聚类模型(graph learning for multiview clustering, MVGL)从不同的单视图学习一个全局图, 最后学习到的全局图包含确定的连通分量, 避免了通过后续步骤得到聚类指标矩阵;
4) 自适应加权普鲁克方法(adaptively weighted Procrustes, AWP), 该方法对视图的聚类能力进行加权, 形成一个加权的普鲁克平均问题;
5) 多视图一致图聚类算法(multiview consensus graph clustering, MCGC)学习一致图, 最小化不同视图之间的分歧, 并加入Laplace秩的约束;
6) 自加权多视图聚类(self-weighted multiview clustering, SwMC), 该方法自动学习权重, 避免了引入额外的参数, 并加入Laplace秩的约束获得聚类标签.
3.4 实验结果
本文DCSE算法与其他对比算法在4个真实数据集上的比较结果分别列于表2和表3. 为避免K-means初始化步骤导致的随机性, 本文运行DCSE算法20次取平均结果.
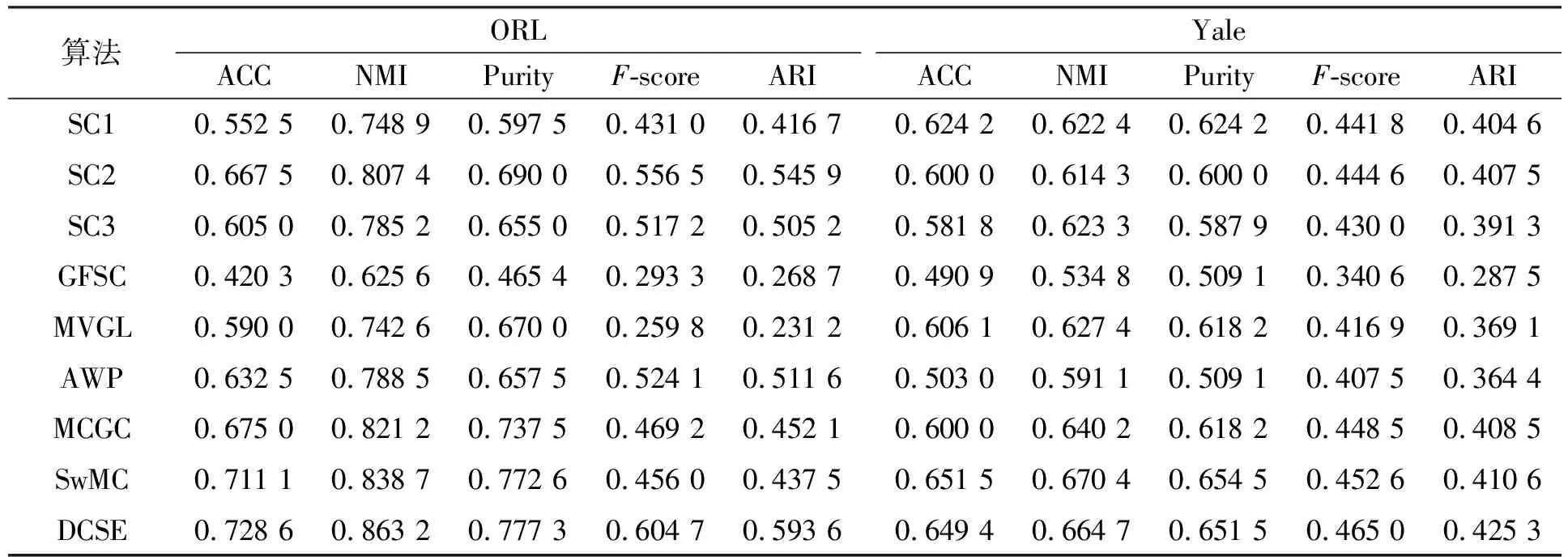
表2 不同算法在数据集ORL和Yale上的聚类性能比较
由表2和表3可见:
1) 不同视图具有不同的聚类性能, 因此在多视图聚类过程中需分配给不同视图不同的权重, 而本文采用的自加权策略可较好地解决该问题;
2) DCSE算法在数据集ORL和MSRCV1上取得了最好的聚类性能, 并在数据集MSRCV1上与性能第二好的MCGC算法相比, 分别在ACC和NMI上约提高3%, 在Purity上约提高5%, 因此聚类过程中同时考虑视图多样性与学习标签矩阵非常必要;
3) 在数据集Yale上, 虽然DCSE算法没有在每个指标上都取得最好的聚类性能, 但其度量指标值与最好的算法相比差距很小;
4) 在数据集Cal-7上, DCSE算法在3个指标上都取得了最大值, 这也验证了本文算法的优越性, 而执行谱聚类算法时第5个视图在Purity指标上数值较大, 因此多视图聚类时需分配较大权重, 本文算法可处理此问题.

表3 不同算法在数据集MSRCV1和Cal-7上的聚类性能比较
综上, 本文模型在考虑视图多样性的同时自动学习权重, 使学习到的一致图具有更优性能, 且避免了后续过程独立进行导致的信息损失, 在4个数据集上性能都较好.
3.5 参数分析
本文算法共涉及α,β,λ,σ4个参数, 为学习到具有较好聚类结构的一致图, 需调整参数λ使图的联通分量数等于聚类数量c, 因此在迭代过程中, 若连通分量数大于c, 则将λ调整为λ/2, 若连通分量数小于c, 则将λ调整为2λ.对于参数σ, 根据经验设为0.1.对于参数α和β, 均在[10-5,105]内取值, 并以数据集Cal-7和ORL为例验证参数的敏感性. 图2为在数据集Cal-7和ORL上参数α和β的敏感性分析. 由图2可见, DCSE算法性能较稳定, 表明本文算法对参数α和β具有鲁棒性.
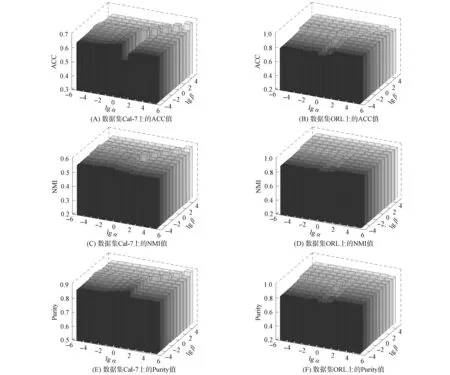
图2 在数据集Cal-7和ORL上参数α和β的敏感性分析Fig.2 Sensitivity analysis of parameters α and β on Cal-7 and ORL data sets
3.6 收敛性分析
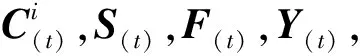

(36)
然后, 通过求解式(12)得变量S(t+1), 则有

(37)
结合式(17)可知

(38)
最后, 通过式(30)更新Y(t+1), 有
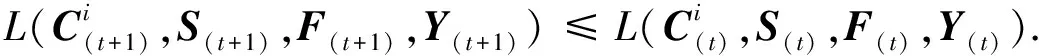
(39)
因此, 本文目标函数收敛.
综上所述, 本文提出了一种DCSE多视图聚类模型, 与已有模型不同[24-25], 该模型同时进行一致图学习、 一致谱嵌入学习与聚类指标矩阵的学习, 在学习一致图过程中综合了视图多样性的信息, 得到了高质量的一致图.上述3个学习过程同时进行, 也可有效地避免步骤分开导致的信息损失.由于模型中加入了标签离散化过程, 因此不需任何后续步骤便可得到聚类结果.此外, 本文还提供了有效求解的优化算法, 并在4个数据集上验证了本文算法的有效性.
