基于XML Schema分块的快速本体构建方法
2022-09-24屈国兴
何 杰, 屈国兴
(宁夏大学 地理科学与规划学院, 银川 750021)
0 引 言
本体(ontology)是指对共享概念模型明确的形式化规范说明[1], 在解决信息的语义异构、 实现知识共享与重用等方面具有重要作用, 目前已被广泛应用于信息检索、 语义网、 异构数据集成与融合及农业、 军事、 旅游、 地理信息、 生物等领域[2-7]. 领域本体为某领域中的概念及概念间的关系提供了规范化表达, 通过定义类、 实例、 属性、 关系、 公理等元素描述某领域中的类与实例及其之间的层次关系, 对领域知识进行归纳和抽象[8]. 但如何有效构建本体, 提高本体的构建效率、 质量及应用效果是本体大规模应用要解决的主要问题.
由于本体应用主要面向特定领域, 所以本体构建也与具体领域相关. 不同领域知识、 概念的差异性导致了本体构建方法的多样性. 本体构建方法主要包括: 以本体论工程构建方法为主的本体构建方法和以叙词表转换为本体为主的本体构建方法[9], 前者从知识工程的角度研究如何构建本体, 后者主要研究如何根据现有的词表资源生成本体. 目前, 国外典型的本体构建方法有IDEF5法、 骨架法、 TOVE法、 METHONTOLOGY 法、 KACTUS工程法、 SENSUS法、 七步法、 循环获取法及五步循环法等[10]. IDEF5法使用结构化本体开发方法构建企业本体, 其优点是利用图表语言和细节说明语言构建本体, 方便本体的重用并利于理解, 但缺点是缺乏循环开发思想; 骨架法也是一种企业本体构建方法, 该方法对本体的开发流程描述清晰, 但不支持本体演进; TOVE法主要用于商业和公共企业建模, 是一种基于本体评价的本体建模方法, 缺点是不支持演进且建模过程缺少文档; METHONTOLOGY法是一种化学本体构建方法, 优点是利用知识完成本体构建, 本体重用性好, 但该方法缺少迭代进化; KACTUS工程法是一种基于应用知识库的抽象化本体构建方法, 其优点是知识重用性好; SENSUS法基于自然语言处理方法构建本体, 常用于构建面向特定领域的本体; 七步法是一种实用的领域本体开发方法, 但该方法缺乏对本体检查、 评估及用户的反馈; 循环获取法基于文本数据源, 通过概念学习、 关系学习、 评价等循环迭代过程构建本体, 该方法通过对本体构建过程的不断学习和评价提高本体构建质量, 但未提供具体的方法和技术; 五步循环法是一种语义网环境下的基于本体学习的本体构建方法, 其通过对导入的本体进行重用、 抽取、 修减、 精炼、 应用等过程完成本体构建, 但该方法不成熟, 语义网自身的复杂性导致利用该方法建模的难度大、 时间长, 构建的本体应用性不强. 在上述几种本体构建方法中, IDEF5法、 骨架法、 TOVE法、 METHONTOLOGY法都是手工构建方式, 效率较低, 方法细节较简单, 相关技术较少. 七步法、 循环获取法和五步循环法采用半自动构建方式, 方法细节详细, 常用于医学等多领域建模. 国内本体构建方法相对较晚, 但发展较快, 在本体论工程法和叙词表转换法方面都取得了许多成果. 如杜小勇等[11]提出了一种基于本体学习的本体构建方法, 根据数据源结构及本体学习对象的不同层次, 从9个方面分析本体学习问题的特征、 常用方法和研究进展, 并指出了本体构建在方法、 学习工具、 评价标准上是未来的研究重点; 何琳等[12-13]借鉴软件工程中的领域建模和本体学习的方法论, 结合专家给出的领域上层知识模式, 通过机器学习技术从领域语料库中学习概念关系, 最后综合专家的自顶向下和机器学习的自底向上的结果半自动化地构建本体; 刘柏崇[14]提出了中文领域本体自动构建理论, 解决了快速自动化构建领域本体的问题, 同时提出了一种新的本体自动构建模块化方法及本体评价标准, 并在本体构建多语种自适应性方面进行了改进; 李景[15]以农业叙词表为中心知识库, 在系统分析领域本体构建关键技术的基础上, 设计并构建了基于花卉学领域本体模型和农业叙词表的原型系统, 同时对大规模、 多人协同构建本体系统的方法和流程进行了探索; 余凡[16]将叙词表和文本两种不同数据源进行综合运用, 通过对文本信息进行概念提取、 概念过滤、 词汇筛选、 关系提取及形式化处理, 以测绘学叙词表和文献为例构建了测绘学领域本体; 任飞亮等[17]通过对以文本为数据源构建本体的相关研究进行详细分析, 介绍了本体构建结果的常用评价方法及常见的本体构建系统, 并针对本体构建存在的本体更新、 关系消歧、 概念属性自动获取及概念消歧等问题, 提出了更高效的机器学习方法, 并根据文本数据特点进行了本体构建.
为提高本体的构建效率, 目前已有许多本体开发工具[18-19]帮助快速构建本体, 主要包括WebOnto[20],Protégé-2000[21],OntoEdit[22],WebODE[23]和KAON[24]等. 每种工具都有自己的特点, 各自有自己的输入/输出格式, 定义的概念缺乏通用性, 界面不友好, 协作能力较弱, 推理能力有限. 因此, 目前的本体构建方法仍有许多不足, 主要包括: 1) 现有方法大多数都是面向某个领域或行业, 通用性较弱; 2) 自动化程度低, 需要大量人工参与, 费时费力; 3) 缺乏有效的本体构建工具支持; 4) 没有统一的评价标准, 本体构建质量无法保障; 5) 本体应用程度较低, 大规模本体应用尚未实现.
虽然开放式地理信息联盟(OGC)标准规范能解决网络服务在语法上的异质性问题, 但因语义信息缺乏, 无法解决语义异质性问题[25]. 同时, OGC定义的不同标准规范都是通过XML模式描述, 如网络覆盖服务(WCS)规范有不同版本, 每种版本规范中定义了不同XML模式描述WCS不同的操作(wcsGetCapbilities.xsd, wcsDescribeCoverage.xsd, wcsGetCoverage.xsd等), 并从语法上隐含地表达了相关模式元素(概念)间的某种关系, 但语义上的异质阻碍了其在大规模异构网络服务集成中的应用. 因此, 本文基于现有OGC定义的标准XML模式文件(XML Schema), 提出一种基于XML Schema分块的快速本体构建方法, 实现XML模式到本体的快速转换, 通过本体显示描述概念及其之间的关系, 实现异构网络服务的共享与互操作.
1 XML Schema转换本体方法
1.1 系统体系结构
XML作为一种通用的扩展标记语言, 可提供统一的方法描述和交换独立于平台、 编程语言、 操作系统、 应用程序或供应商的结构化数据, 是万维网中处理分布式结构信息的重要工具. XML Schema是对XML文档结构的定义和描述, 其主要用于约束XML文件, 并验证XML文件的有效性. 组成XML Schema的主要元素包括Element,ComplexType,Annotation,Sequence等.
OWL是一种建立在DAML+OIL基础上的网络本体描述语言, 其目的是清晰明确地表达术语表中术语的含义及其之间的关系, 即本体. OWL本体的基本元素由类、 个体和属性构成. 类是具有相同属性和特征的对象总称, 是个体的集合. 类通常使用正式的描述精确表明其需求, 如类Sensor包含领域中所有的Sensor个体. 类可以被组织为超类-子类的层级关系, 即分类关系. 在OWL中这种分类关系可由推理机自动计算得出. 个体表示感兴趣领域中的对象. 在OWL中, 个体间的等同关系必须明确, 否则其可能相同也可能不同. 属性是个体间的二元关系, 两个个体通过属性相互关联. 属性拥有多种特征, 如转置、 被限制为单值、 传递性、 对称性等.

图1 XML转换OWL的体系结构Fig.1 Architecture of transformation between XML and OWL
将XML转换为OWL本体的方法目已有许多研究成果[26-30], 这些方法的共同点就是将转换过程分为三步完成, 即先从XML文档中提取XML Schema, 再将XML Schema转换为OWL模型, 最后通过本体模型将XML文档映射为本体实例. 上述方法的不足之处是未考虑对本体实例的验证, 同时模型演进性较弱. 基于此, 本文在综合考虑相关研究的基础上, 提出一种基于XML Schema分块的快速本体构建方法. 图1是XML Schema转换OWL本体的系统结构. 整个转换过程分以下4步完成:
1) 根据XML Schema和OWL描述模型间的关系定义映射规则;
2) 根据映射规则实现XML Schema到OWL模型的转换;
3) 根据设计好的OWL模型引擎将实验的WCS模式文档实例化为OWL本体实例;
4) 在领域专家帮助下对本体实例进行验证, 验证成功则输出最后的转换结果, 否则修改完善映射规则, 使用新规则重新返回步骤2), 重复后面的转换步骤, 直至验证成功为止.
1.2 映射规则
OWL本质上是基于XML/XML Schema这些语言演化而来, 比后者具有更强大的语义表达能力. OWL与 XML Schema在语法上相似, 结构上相关. 基于这些关联, 定义如下映射规则[28,30].
1) SimpleType(简单类型): 对于内置简单类型、 派生简单类型、 列表和联合类型, 只需将包含声明这类类型的元素或属性的复合类型元素与其之间的关系映射为owl: DatatypeProperties, 如果元素或属性声明包含匿名简单类型时, 则将元素或属性的父元素与它们的关系映射为owl: DatatypeProperties.
2) ComplexType(复杂类型): 对于复杂类型, 一般将复杂类型定义及其内部的复杂类型子元素映射成owl: Class, 而复杂类型与其复杂类型子元素之间的关系映射成owl: ObjectProperties, 将复杂类型与其简单类型子元素或属性之间的关系映射成owl: DatatypeProperties.
3) Element(元素): 如果是一个XML叶子节点元素且只包含简单文本或一个属性, 则映射为owl: DatatypeProperties, 其他类型元素映射为owl: ObjectProperties.
4) Attribute(属性): 对于全局属性, 当有局部属性引用其时, 将局部属性声明的父元素与该全局属性间的关系映射为owl: DatatypeProperties; 对于局部属性, 只需将该属性声明的父元素与其直接的关系映射为owl: DatatypeProperties.
5) Sequence(特定顺序)和Choice(选择顺序): 常用于定义语境, 前者定义的元素是有序的, 后者则无序. 由于OWL中无与之对应的组件, 因此需在这两个元素被定义或引用的复杂类型所对应的OWL类中定义一个新类完成对应顺序选项功能.
6) Ref(引用): 对于被复杂类型引用的属性或简单类型(或包含属性或简单类型)映射为owl: DatatypeProperties, 如果被引用的元素包含复杂类型时, 将被映射为owl: ObjectProperties.
7) Annotation(注释): 将直接映射为owl: comment.
8) xsd: minOccurs: 将直接映射为owl: minCardinality, xsd: maxOccurs映射为owl: maxCardinality.
1.3 模式分块
现有的本体构建方法是半自动化的, 本体构建效率有待进一步提高, 特别是大规模的本体构建问题, 由于模式大而复杂, 各种类型节点间包含各种嵌套关系, 影响了OWL实体集的生成效率. 因此, 先将模式图/树分割为简单的图/树, 然后基于这些子图/树构建本体. 本文采用基于图/树分裂方式的分割算法, 即根据树节点的度的大小对树进行分割, 分割步骤为: 首先按照广度优先方法对树进行遍历, 并计算每个节点的出度和入度, 若入度为0则节点为根节点, 若出度为0则节点为叶子节点, 若出入度都为0则节点为孤节点; 然后对树进行分割, 即从根节点开始, 将根节点出度置0, 根节点所有直接子节点的入度减1; 最后确定分割后子树, 即统计所有入度为0的节点, 每个入度为0的节点及其子节点组成一棵新的子树. 每个节点用其ID号表示, ID号由3位数字组成, 第一位表示该节点深度, 如根节点深度为0, 依次类推, 第二位表示父节点的位置, 第三位表示本节点在该层中位置, 如ID号为123的节点表示第二层第三个节点, 其父亲节点是第一层第二个节点. 节点旁标注节点度的大小, 左边表示入度值, 右边为出度值. 最后根据树的深度确定分割是否结束, 本文算法在确定树的深度小于等于3时停止分割, 算法的伪代码描述如下.
算法1模式分块.
输入: 模式表示图G;
输出: 模式子图集Gi;
DivideGraph(G)
步骤1) Nodes=SetNumber(G);//给图G所有节点编号
步骤2) foreach (node in Nodes)
步骤3) inDegree=GetNodeInDegree(node); //计算节点入度
步骤4) outDegree=GetNodeOutDegree(node); //计算节点出度
步骤5) depth=GetNodeDepth(node); //计算节点深度
步骤6)Gs=GetSubGraph(G,node); //生成节点子图
步骤7) if(inDegree==0 and depth>3) //对入度为0且深度大于3的节点进行分割
步骤8)Gss=DivideGraph(Gs); //对子图进行分割
步骤9) foreach(G′ inGss)
步骤10) goto 1); //返回步骤1)重新计算分割后每个子图的节点度及深度
步骤11) else
步骤12)Gi=Gi+Gs; //将最终不需要进一步分割的子图添加到结果子图集
步骤13) returnGi. //算法结束, 返回分割后子图集
2 网络服务模式本体构建
2.1 模式转换
XML模式转换为OWL本体模型主要通过模式转换器完成, 转换过程如下.
1) XML Schema解析. XML模式的解析主要通过读取或分析XML模式包含的信息内容, 读取和识别各类模式元素对象并确定这些对象间的关系, 然后根据解析后的XML模式元素对象及其关系生成对应的模式图. 当模式图中的所有元素都未被重用时, 模式图便退化为模式树. 模式图中顶点集包括所有元素、 属性、 非原子类型、 元素组和属性组等. 边集包括连接每个元素与其非原子类型的边及所有类型、 元素组和属性组到它们所包含的元素或属性的边. 图2为模式文件wcsGetCoverage.xsd的模式图表示形式.

图2 WCS模式图表示形式Fig.2 Representation of WCS schema graph
2) 模式图分割. 以图2中模式图为例, 基于模式分块算法, 先对图2中的节点进行编号并计算对应的度, 根据图结构特点, 先将入度为0的根节点进行分裂, 编码为111的节点入度减为0, 再将该节点进行分裂, 其对应的直接子节点211,212,213,214,215入度都变为0, 其中节点213的深度为4, 继续进行分割, 其直接子节点331,332,333入度减少为0, 但由于它们的深度都小于3, 故分割结束, 分割结果如图3所示.
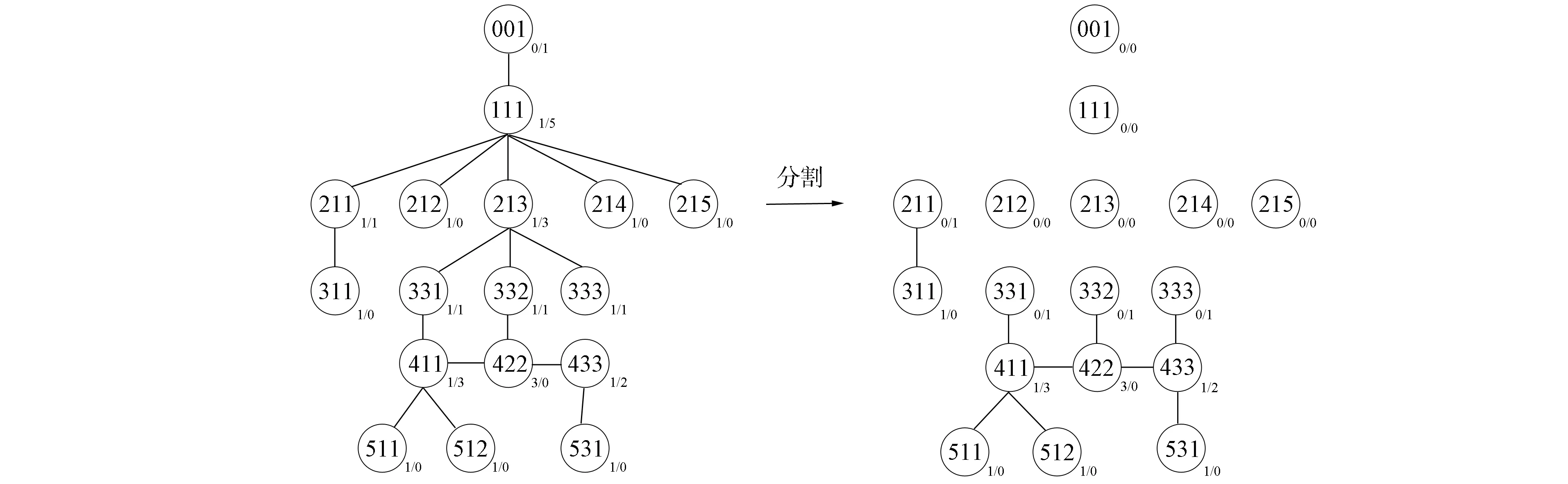
图3 wcsGetCoverage.xsd模式图分割结果Fig.3 Partition results of schema graph of wcsGetCoverage.xsd
3) OWL实体集生成. 利用Jena(http://jena.sourceforge.net/)提供的API函数实现将上一步生成的模式图转化为OWL实体集. 根据1.2节的映射规则, 将对应的复杂类型、 元素组、 属性组声明转化为OWL类, 元素与对应子元素的关系用OWL对象属性表达, 属性及简单类型则转化为OWL数据类型.
在图3分割后的8个子图中, 5个节点111,211,332,411,432为复杂类型, 其他节点为元素. 根据1.2节给出的映射规则, 节点001直接映射为owl: Class, 111是001的直接子类, 与001间关系映射为owl: DatatypeProperties; 节点211为复杂类型, 其为111的直接子类, 同时其包含一个属性元素, 故节点211映射为owl: Class, 它与节点111关系映射为owl: DatatypeProperties; 节点212,213,214,215等均为元素, 直接映射为owl: DatatypeProperties; 节点331,333是复杂类型元素, 映射为owl: ObjectProperties; 节点332为复杂类型, 映射为owl: Class. 图4为wcsGetCoverage模式经过转换后的OWL本体.
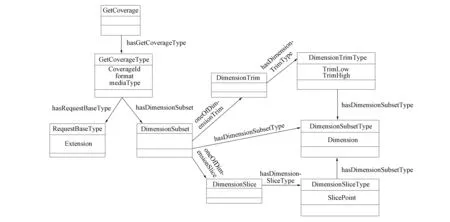
图4 转换后的OWL本体模式图Fig.4 Transformed OWL ontology schema graph
2.2 本体实例化
本体实例化操作主要通过OWL模型引擎完成. 模型引擎在现有OWL模型框架基础上, 读取给定的XML文档, 根据XML文档元素与OWL模型元素间的对应关系, 提取对应的XML文档元素实例数据, 生成对应的OWL模型实例. 本文以requestGetCoverageTrimmingSlicing.xml为例, 具体文档内容如图5所示, 该文档实例化一个本体类GetCoverage请求的具体Coverage实例对象, 定义了请求Coverage对象的CoverageId,DimensionTrim,DimensionSlice,format,mediaType等信息.

图5 XML文档实例片段Fig.5 Instance fragment of XML document
图5中文档实例类GetCoverage映射为owl: class,Coverage对象的CoverageId, DimensionTrim,DimensionSlice,format,mediaType等属性映射为owl: DatatypeProperty,DimensionTrimType和DimensionSliceType, 用于定义属性DimensionTrim,DimensionSlice的取值范围, 所以映射为rdfs: range. DimensionTrimType使用属性Dimension,TrimLow,TrimHeigh具体定义属性的取值范围. 同理, DimensionSliceType使用属性Dimension,SlicePoint具体定义取值范围, 这些属性都映射为rdf: datatype. 图6为图5转换后的OWL本体实例片段.

图6 转换后的OWL本体实例Fig.6 Transformed OWL ontology instance
2.3 实例验证
目前本体评价尚无比较系统化、 实用化的方法, 通常需根据某个具体应用场景的具体需求构建对应的指标体系, 然后建立评价模型进行评价[31-33]. 本文先通过Wonder Web OWL Ontology Validator软件(http://www.mygird.org.uk/OWL/Validator)对构建的OWL本体模型进行语法验证, 然后人工对本体实例进行验证. 主要验证以下三方面:
1) 类和属性定义的清晰性, 即根据给定的转换模式文件, 准确抽取相关类和属性, 对其进行明确定义, 保证定义的类与属性准确、 无二义性;
2) 类的关系逻辑一致性, 包括类层次关系的一致性, 即根据文中定义的模式图结构、 各模式元素间逻辑关系及转换规则验证类的关系在逻辑上的一致性;
3) 类与属性定义的完整性及可扩展性.
一方面, 本文在验证完前两项内容后, 重新对转换后的本体模型与原XML模式原型进行对比分析, 保证定义的完整性; 另一方面, 从应用的角度分析本体模型的可扩展性, 根据本体扩展能力验证相关类和属性可扩展性. 本文实验中邀请了相关领域专家对本体模型进行评估和验证, 重点按上述定义验证标准分别对本体实例中类与属性定义的清晰性、 类的逻辑关系一致性、 完整性和可扩展性进行人工验证. 专家组的结论是本文方法构建的网络服务模式本体实例满足给定的标准和领域应用要求, 但实验数据结构简单、 数据量小, 对大规模、 复杂本体实例构建结果还需进一步验证.
2.4 性能实验
为有效验证本文方法在性能上的优势, 选择OGC定义的WFS(网络要素服务)和WCS两种不同类型的标准模式文件作为本体构建实例, 所有实验统一使用Win7 64位PC机上安装的Sun Java 1.8.0库, PC机配置为3.2 GHz Intel(R) Core(TM)i5-6500处理器和8.0 GB RAM, 不同配置的电脑运行实验结果在性能上会有差异. 选择模式文件包含的节点数见表1, 统计本文使用的基于模式分块方法(B1)和非分块方法(B2)性能, 由于人工辅助时间受具体人员经验和水平的影响, 不同经验和水平人员辅助时间差异较大, 对实验结果影响也较大, 所以本文在统计时未考虑人工辅助时间. 表1列出了不同本体构建方法性能的比较结果. 由表1可见: 本体构建时间与模式包含的节点数成正比; 基于WCS模式构建本体所需时间总体比WFS多, 这主要是由于WCS模式文件节点数量多且结构更复杂; 两种构建方法中, 基于分块的本体构建方法由于采用分治思想, 将复杂的XML模式图分割成更简单的子图, 从而提高了本体构建效率, 与传统方法相比, 基于分块的方法性能约提高10%.

表1 本体构建方法性能比较
综上所述, 本文在综合分析现有本体模型构建及评价方法的基础上, 根据现有网络服务集成应用存在的语义异质问题, 提出了一种基于XML 模式分块的OWL本体转换方法, 实现了在线网络服务模式的半自动本体化及验证工作, 为网络服务特别是语义网环境下的异构网络服务共享与互操作提供了支持. 同时, 为提高本体构建效率, 通过一种基于模式图节点分裂的方法将一个较大的XML模式图分割成多个模式子图, 再基于模式子图构建本体. 实验结果表明, 该方法在一定程度提高了本体构建性能.
