基于动态平衡自适应迁移学习的流量分类方法
2022-09-22尚凤军李赛赛催云帆
尚凤军 李赛赛 王 颖 催云帆
(重庆邮电大学计算机科学与技术学院 重庆 400000)
1 引言
应用流量识别技术可以识别网络中与网络流量相对应的应用类型,然后识别当前占主要带宽流量的应用类型。企业或者校园的网络管理者能够根据不同的情况适时调整干预关键网络流量[1]。然而在真实的世界中,网络流量数据最突出的特点就是其随着时间快速演化,存在概念漂移的现象,并且随着不同的地域和网络环境,其协议类型的分布也不一致[2]。利用机器学习进行流量分类中,原先可以利用的有标签数据变得不再可用,与原来测试样本的分布产生语分布上的不同[3],导致这个假设通常不成立。由于迁移学习没有这些假设,可以将迁移学习用到应用识别上面来,解决这些在现实中不成立的问题。
针对测试集中应用流量样本的分布与训练集中样本的分布不同的问题。对迁移学习中的领域自适应动态分布适应方法进行了改进,在对源领域到目标领域进行知识的迁移时,不同于以往要么假设源领域与目标领域的边缘分布不同P(xs)/=P(xt),要么假设源领域与目标领域的条件分布不同P(ys|xs)/=P(yt|xt),有的假设两者的差异同时存在,但是没有差异化对待两者之间的差异。本文通过在动态和定量适应边缘分布和条件分布的基础上添加了定量初始预估策略,加快了后续定量参数的收敛时间。TrAdaBoost是一种为了解决归纳式迁移学习问题提出的一种算法,是对AdaBoost算法的一种改进,通过实例权重定义策略实现了知识的迁移[4,5]。Pan等人[6]在主成分分析PCA的基础上提出了基于特征的域适应迁移学习算法TCA。季鼎承等人[7]同时考虑多个源领域与目标领域的相关性,进而提出了两种多源学习算法:MTrA和TTrA。MTrA算法的思想是源数据集有多个数据源,每次迭代的过程中选取并使用当前迭代与目标数据相关性最强的数据源训练弱分类器,通过迭代细化策略,进而得到强分类器[8]。其他多源迁移学习:唐诗淇等人[9]提出的迁移学习方法(Online Transfer Learning from Multiple Sources based on Local Classification accuracy, LC-MSOTL)从多个相似的领域迁移知识。张博等人[10]基于特征映射提出的迁移学习方法对多个不同领域的相关性进行学习从而实现知识的迁移。张宁等人[11]提出的K-means-CART使用K均值算法将CART数扩展实现跨领域的迁移学习。洪佳明等人[12]提出的TrSVM是对SVM进行扩展,实现了基于实例的迁移学习。Faddoul等人[13]提出的方法扩展C4.5实现迁移学习。Transitive transfer learning利用第三方学习到的相似关系完成知识的迁移[14],Distant domain TL从多个中间辅助域中选择知识等[15],可以有效地利用多个领域的知识。领域自适应研究如何利用源领域解决目标领域的问题,代表成果有cross-domain transfer[16,17],通过在再生核希尔伯特空间中学习一个领域不变核矩阵,Domain Adaptation Machine[18]等,领域自适应会假设目标领域和源领域在高维空间有相同的条件分布。在动态适应迁移学习(transfer learning with Dynamic Distribution Adaptation, DDA)[19]中,王晋东等人通过使用二分类器模型的错误率来对域之间的散度距离进行计算。但是没有考虑到对分类的确认度,并且通过获取固定数量的转换主元来进行后续的模型训练。
为了解决应用流量源领域和目标领域分布不同的问题,本文提出了目标领域半监督平衡分布适配算法(Semi-supervised Mobile Terminal Application Distribution Adaptation, SMTADA),更加高效地对分布不同的目标领域流量进行分类。实验结果表明,SMTADA能更加高效地识别特征分布不同的目标领域应用流量。
2 模型设计
2.1 基于迁移学习的模型设计
图1是本文使用迁移学习的模式图。通过对知识的迁移,进而来建立一个新的可以应用到目标领域的模型,这样就可以省去应用机器学习时进行人工标记的繁重工作。不同于传统的机器学习方法,迁移学习是尝试将之前已经学习到的知识迁移应用到目标任务当中。
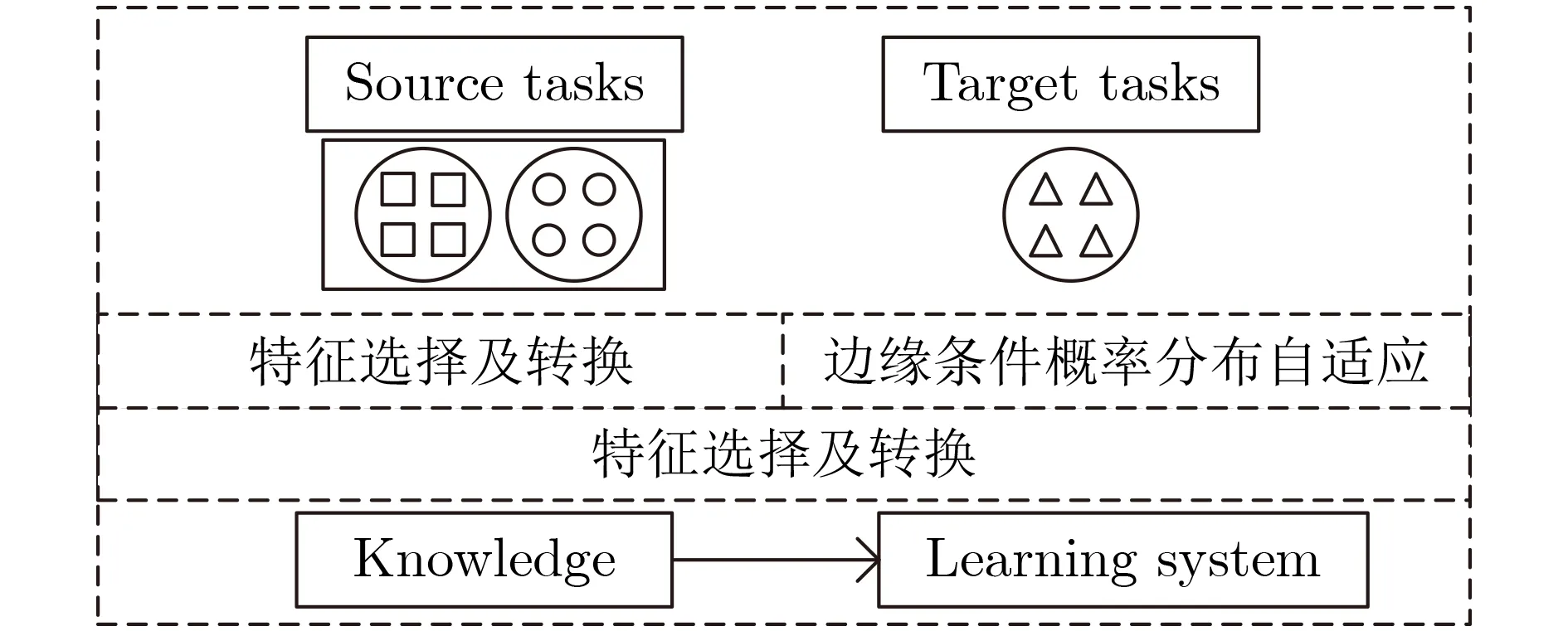
图1 迁移学习模型设计
2.2 特征选择
在应用中,每条流量数据由几百个特征来刻画,这些特征可以充分地反映刻画一条流量数据,只要选取合适的学习方法就可以对流量数据的类别进行判断,但是每一条样本的特征维度很高,存在大量冗余的特征,甚至是相同的特征,这样的特征对于模型分类的贡献不大,这些没有性能贡献的特征会使得算法的时间开销和空间开销变大,甚至在多个无用特征的影响下,不同的特征会相互干扰影响,导致训练模型的性能大大降低。
正向余量特征删除法来对剩余特征进行删除,存在一个比较大的问题,在进行删除判断时,计算出所有剩余判断特征的信息增益率权重相关系数,然后通过最小最大平均原则的策略删除增益率权重相关系数大于平均值的特征,最后留下指定数量的特征。这样就会大概率导致最后留下一些相关性低,但是信息增益也比较低的特征。
本文提出了基于逆向信息增益特征提取和迁移学习相结合的应用流量分类方法,在特征的删除策略上,采用逆向特征自删除策略,与正向余量特征删除相比,算法复杂度会上升,计算时间也会增加,通过信息增益率权重和推土机距离(Earth Mover’s Distance, EMD)优先判断是否删除排在后面的特征,可以避免正向余量删除中所存在的问题。
将信息增益和相关系数相结合,得到信息增益权重相关系数
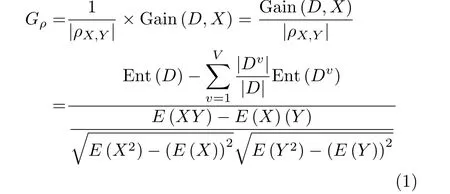
可以更加全面立体地反映属性的重要程度,以及属性与属性的冗余度和相关性。
应用间的推土机Wasserstein距离[20],表示在给定度量空间上度量两个概率分布之间的距离度量函数。在最优传输距离中,指的是把概率分布q转换为p的最小传输距离,此最优传输距离也称为地球移动距离、推土机距离。
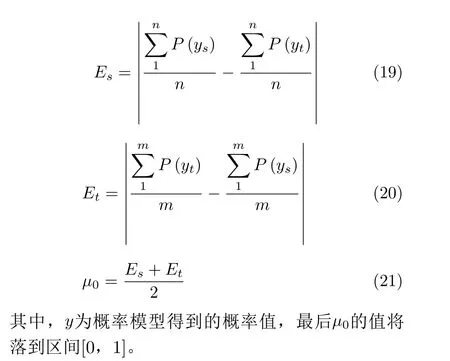
也可以被解释为在将一种概率以一定的概率分布形状转化为另一种概率分布形状的过程中所消耗的最小能量。例如对于两个分布函数F和G,假设其随机变量为U和V,那么分布函数F和G之间的距离为

推土机距离具有很多优良的性质,现在被应用到了计算机的很多领域,包括非平滑样本测试、优化拟合、混合模拟分析、图像处理、降维、生成式对抗神经网络、领域自适应以及信号处理中。但是其本身也有一定的缺点,例如计算量较大,不足够健壮等。
从Ds中 ,按照信息增益的值从小到大,从n~1迭代选择出特征,对特征进行判断。例如选择出了特征Xn,然后将Xn依次与Xn-1~X1进行计算判断,是否存在可以替代完全特征Xn的特征,如果存在就将特征Xn删除,如果不存在就保留特征属性Xn。此策略按照特征的信息增益较小的特征属性Xn开始判断,优先删除自信息较小的属性,尽量保留自信息较大的特征属性。
在判断是否存在可以完全替代特征Xn的特征时,选用信息增益相关系数。首先通过信息增益公式计算出特征Xn之 于特征Xn-1的 信息增益Gain(Xn,Xn-1),如果信息增益大于一定的阈值,那么就可以在一定程度上使用特征Xn-1, 来对特征Xn进行替代。接着使用相关系数来计算两者之间的相关性和两个特征序列之间的相关性,进而与上一步的信息增益值结合,使用信息增益相关系数的大小进行判断。
两者相结合进行判断,可以更加全面地反映出特征与特征之间的关系和联系,不至于太片面。如果流量特征与特征之间的推土机距离越小,特征与特征之间的信息增益权重相关系数越大,可以充分说明两者所具有的相互替代性。
然后通过使用推土机计算公式来对两者的概率分布距离进行计算。
算法所需的最大内存空间主要受到特征结合维度和样本个数的影响,分析可以得出算法的空间复杂度S为O(n×d),即主要受到读入数据集数据的影响,基本已经是最小的内存需要。
2.3 距离最小化
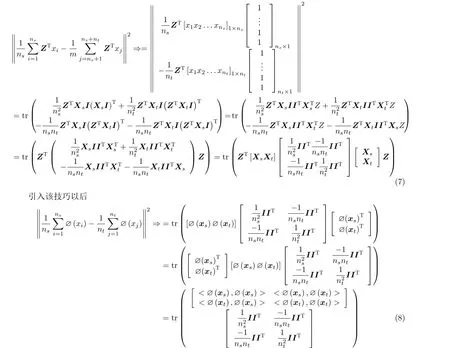
通过使用最大均值差异(Maximum Mean Discrepancy, MMD)[21]来衡量源领域与目标领域之间的距离

由于实际训练中样本个数是有限的,不会趋向于无穷大,遍历空间中的每一个样本,所以通常会使用经验风险最小化和结构风险最小化作为基本策略来估计期望风险。
结构风险最小化等价于正则化,是用来防止过拟合的产生进而提出来的策略,是在结构风险的基础上加上了表示模型复杂度的正则化项或者惩罚项[22]。结构风险的定义为


转换过程为



2.4 应用流量特征的联合分布适应
以往在对源领域到目标领域进行知识的迁移时,要么假设源领域与目标领域的边缘分布不同,要么假设源领域与目标领域的条件分布不同,有的假设两者的差异同时存在,但是没有差异化对待两者之间的差异。为了解决边缘分布与条件分布不同的问题,在动态和定量适应边缘分布与条件分布的基础上添加了定量初始预估策略,加快了后续定量参数的收敛时间,增加动态分布适应的适用性。
根据每个特定的任务自适应地调整边缘分布和条件分布之间的重要性,公式化进行表示为

联合分布适应可以通过图2进行表示分析:
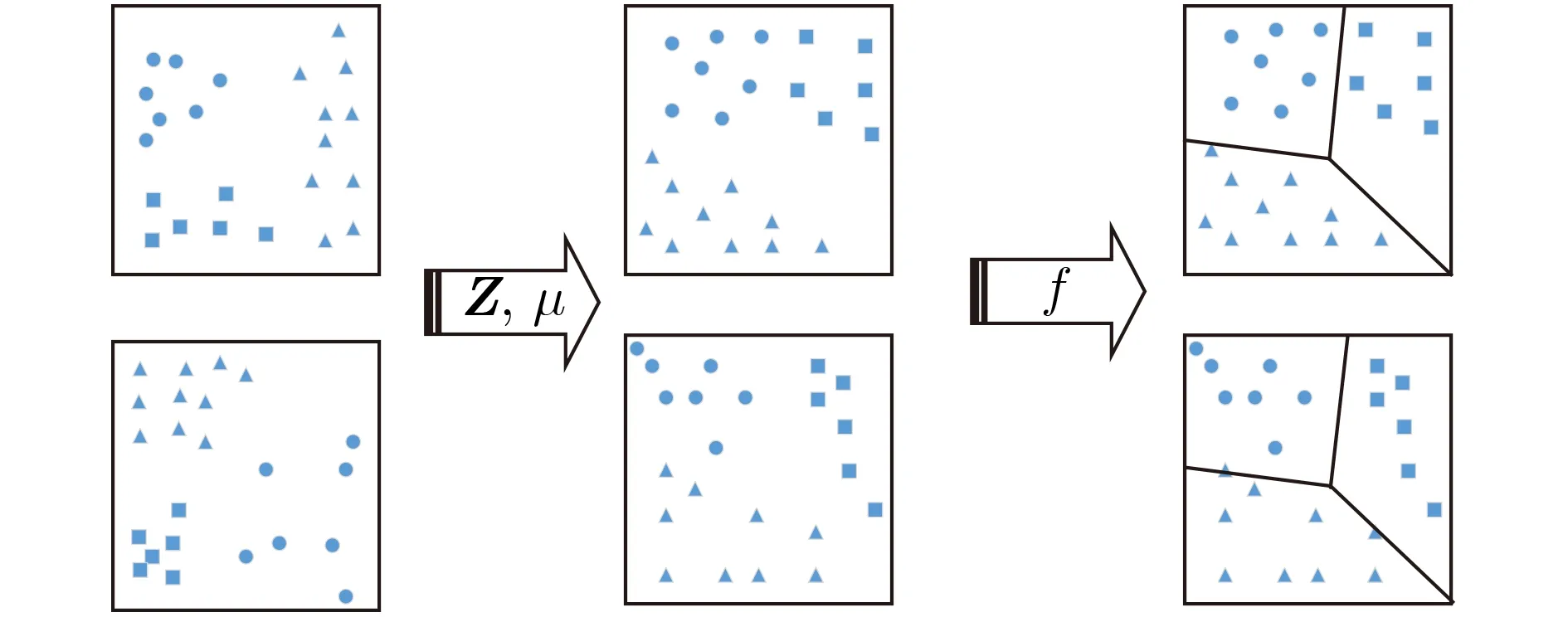
图2 联合分布适应方法
通过变换矩阵Z和参数µ将边缘分布和条件分布进行动态的联合分布适应。
通过使用最大均值差异来评估两个分布之间的差异,可以将上面的公式转化为


为了使得算法在后面更快地趋于稳定收敛,通过使用一个二分类器,来预测计算源领域与目标领域的边缘分布差异的大小。使用源领域和目标领域的样本进行训练,对目标领域进行预测,得到预测概率结果表,如果源领域与目标领域的边缘分布差异较大,通过对概率表进行统计,可以得到概率表中正样本概率的统计值与负样本概率的统计值差异会越大;相应的,如果源领域与目标领域的边缘概率分布差异较小,那么得到的正样本概率统计值与负样本概率统计值差异会越小,利用这个法则,可以在进行特征适配前,来计算µ的初始值
2.5 迭代提高精度
进行条件分布距离计算时,虽然目标领域中的样本没有标签,但是可以使用源领域训练出来的模型进行预测,得到目标领域的伪标签,然后通过逐步迭代,使得伪标签的准确率逐渐上升。进而使得对条件分布距离的计算更加准确。
2.6 动态获取转换主元
在BDA算法中在对特征转换以后,在选择重要转换特征的过程中,直接定义了要选取特征的个数,没有考虑到特征值所反映出来的重要程度,本文通过特征值的大小来判断转换后特征的重要程度,来动态获取转换后的特征数量,避免阈值设置得过大而造成弱特征被选取进来,违背了特征转换的初衷,也可以避免阈值设置过小导致重要特征被丢弃,造成信息丰富度的损失,所带来的性能下降和准确率的下降。定义悬崖式下跌策略,对出现断崖式下跌的特征值所对应的特征向量进行删除,删除策略如图3所示。
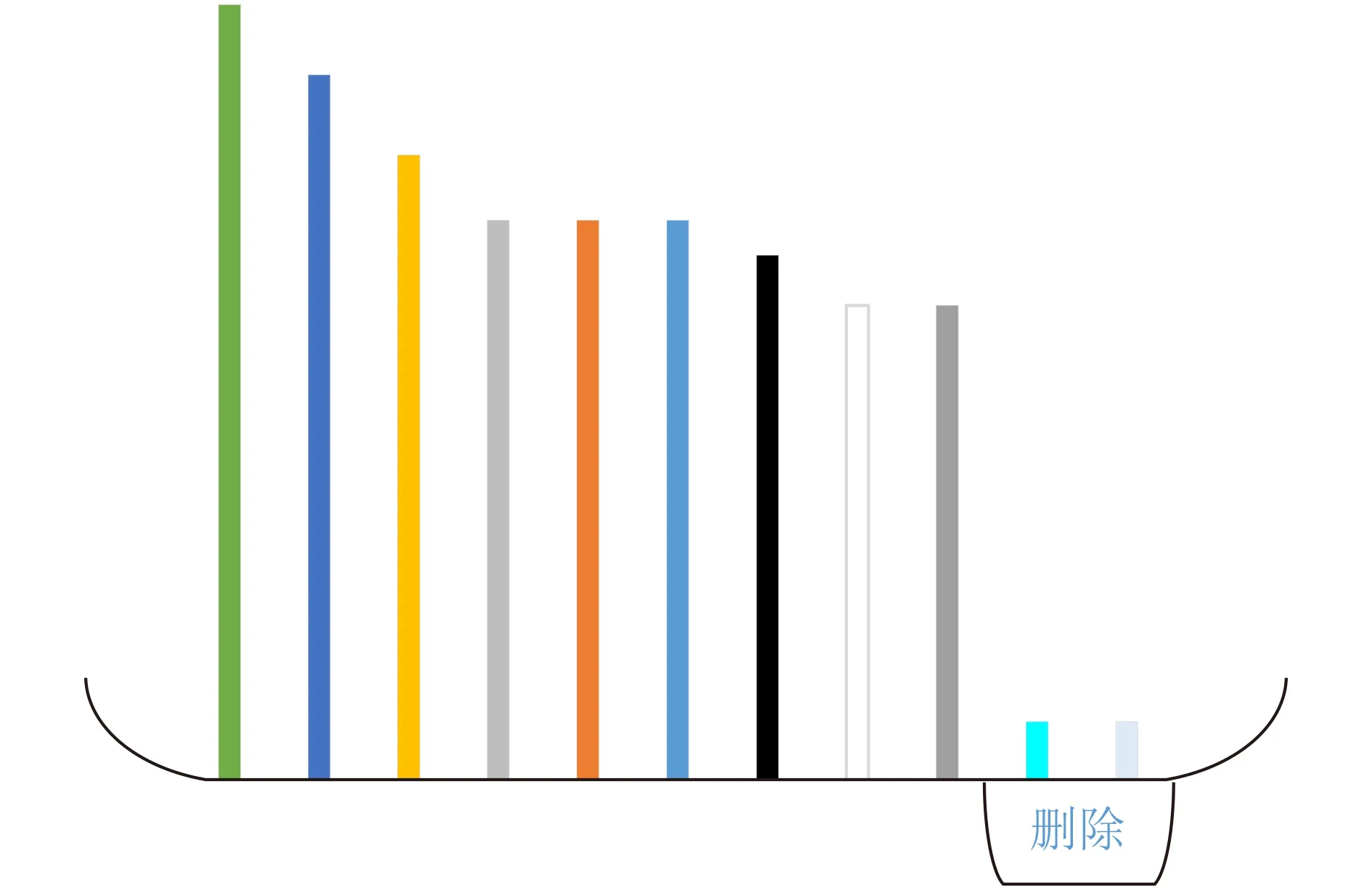
图3 根据特征值删除映射特征向量

在对映射转换后的主元进行选择的时候,通过删除信息丰富度断崖式下跌的特征主元可以得到更加合适的主元特征维度,避免特征信息丰富度被削弱或者对特征信息丰富度提升无关的特征存在。
通过上面的特征主元动态确定平衡分布适配方法可以很好的适配,由于目标领域中会出现一些完全不同于源领域的样本特征,通过从源领域进行知识的迁移依然无法实现很好的分类识别。为了解决这个难以解决的问题,对目标领域进行半监督的学习,通过对目标领域中的部分样本进行标注来实现,流程如图4所示。
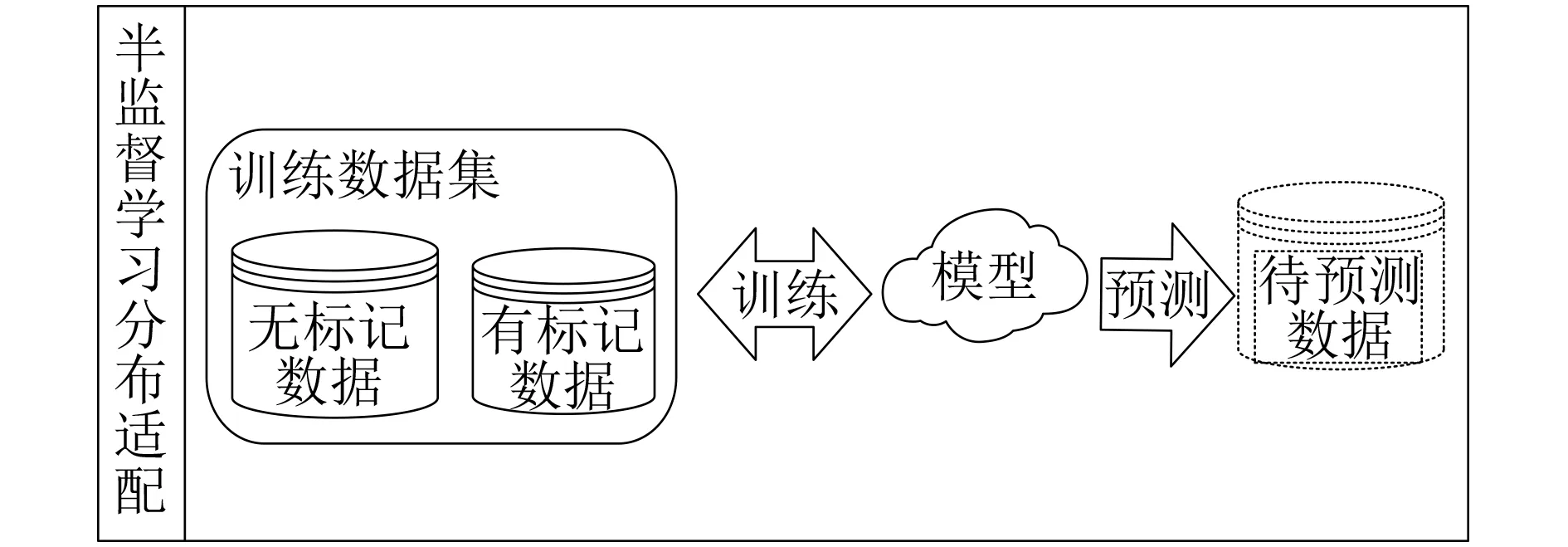
图4 半监督学习分布适配模型训练
在现实中,对目标领域中的所有样本进行标注工作量相对来说是比较大的,但是对目标领域中的部分样本进行标注是比较多的实际情况,所以本文结合两种方法的优点,将针对目标领域中部分样本有标签的半监督平衡分配适应算法记为SMTADA(Semisupervised Mobile Terminal Application Distribution Adaptation),如表1。

表1 有标签的半监督平衡分配适应算法
半监督平衡分配适应算法不仅提高了算法的适用性,同时也可以在标注工作量较小的情况下,一定程度上提高算法的准确度。模型的训练数据使用源领域的数据加上已经标注的部分目标领域数据。
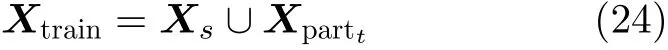
通过引入目标领域中1%~20%有标签样本作为训练集,对目标领域进行半监督学习。
2.7 复杂度分析


3 实验分析
3.1 实验设置
首先使用迁移学习中广泛使用的公开视觉数据集:Amazon(A), DSLR(D), Webcam(W),Caltech-256(C),进行实验验证,在SMTADA中选用了20%的带标签样本作为辅助训练。公开视觉数据集的样例如图5所示。

图5 公开视觉数据集
然后将算法应用到移动应用流量识别上,进行试验对比。本文更多地是注重应用流量的分类,而不是流量的采集,所以采用了剑桥大学Nprobe项目中的公共的数据集,是由Moore等人[23]使用Nprobe网络数据统计采集工具获得。该数据集广泛应用于其他各种网络流量分类方法试验分析中。数据集中包含了各种网络流量的统计特征,包括248个属性特征和1个类别标签用来指明流量的类型。特征属性包括服务端端口、客户端端口号以及各种时间间隔,是一个比较全面实用的分类器。数据集包括11个数据集合,其中entry1到entry10这10个数据集合是在一天中的不同时间段获取到的,最后一个数据集entry12是在12个月网络环境发生变化以后进行采集的。每个数据集包括12个类别标签,但是不是每个类别都有足够的样本用于训练,所以最后留下8个类别,删除了4个不适合作为训练分类的样本类别标签。
每个子数据集虽然有248个特征可供使用,但是有部分特征是冗余的,甚至是相同的,因此通过过滤式特征选择算法来进行特征的选择,减少冗余特征和无用特征对后续模型计算的影响。
与现阶段一些经典的传统方法进行了比较,传统的迁移学习方法包括:最近邻算法(k-Nearest Neighbors, k-NN)、支持向量机(Supported Vector Machine, SVM)、主成分分析(Principal Component Analysis, PCA)、迁移成分分析(Transfer Component Analysis, TCA)、联合分布适配方法(Joint Distribution Adaptation, JDA)、平衡分布适应迁移学习方法(Balanced Distribution Adaptation for transfer learning, BDA)。
3.2 性能分析
首先将本文提出的SMTADA算法应用在视觉公开数据集上进行试验,在目标领域中选用20%的带标签数据作为SMTADA中的辅助数据,实验的结果如表2所示。
评价指标使用准确率来表示
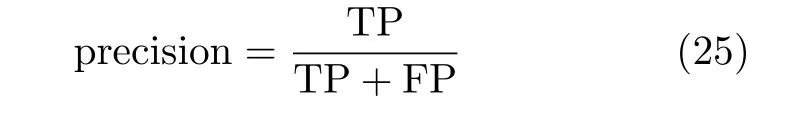
其中,TP表示将正类预测为正类,FP表示将负类预测为正类。可以看到,在选用了目标领域中20%的带标签样本作为辅助训练,使用半监督方式以后,算法的预测准确度得到了比较大的提升。在现实中,目标领域中的样本并不是全部没有标签,对目标领域中的部分样本进行标注,然后使用本文提出的SMTADA方法可以得到比较好的结果,实验结果如表2所示。

表2 添加20%目标领域样本半监督学习结果(%)
为了验证平衡参数µ对分类结果的影响,首先从0.1到1对参数µ进行遍历,验证边缘分布和条件分布的不同影响。平衡因子µ对模型的性能影响如图6所示。
从图6可以看出不同的影响因子对模型的准确率会产生不同的影响,可以看出源领域和目标领域的边缘分布和条件分布的确存在分布不同的情况。
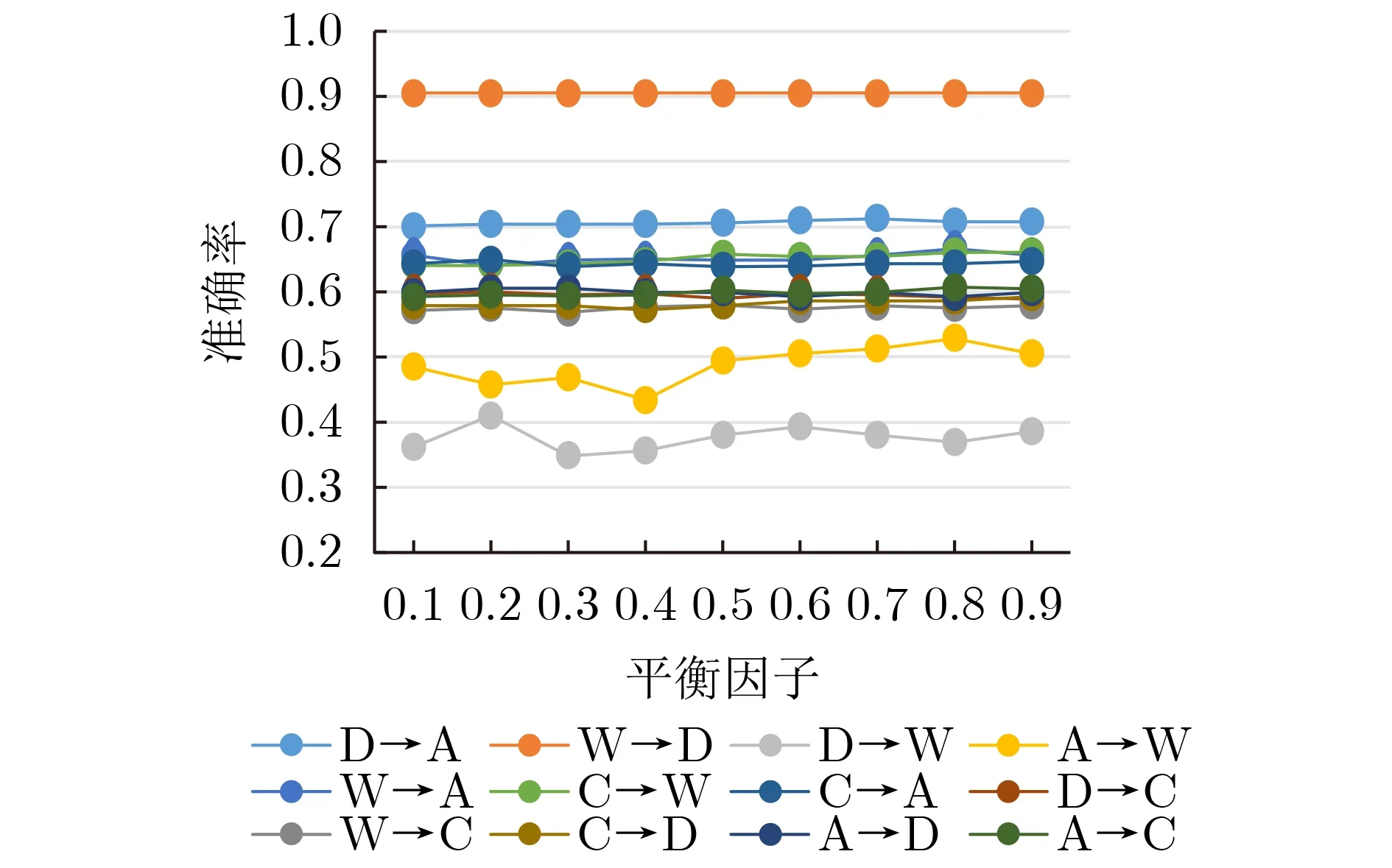
图6 不同参数μ对模型的影响
与最新的迁移学习方法相比较,在目标领域完全没有标签的情况下,本文提出的方法在一定程度取得了比较好的结果。但是在实际环境中,可以将目标领域数据集的部分样本进行标注,即使目标领域数据集很大,对少量数据样本进行标注不会增加太大工作量,让标注的数据起到领头羊的作用,辅助无标签样本进行分类。实验中使用半监督的SMTADA方法达到了比较好的结果,相比于无监督的方法得到了比较大的提升。
通过上面的实验可以看出本文提出的模型在公开数据集上取得了比较好的结果,然后将算法应用到应用流量识别上,进行试验对比,实验结果如表3所示。
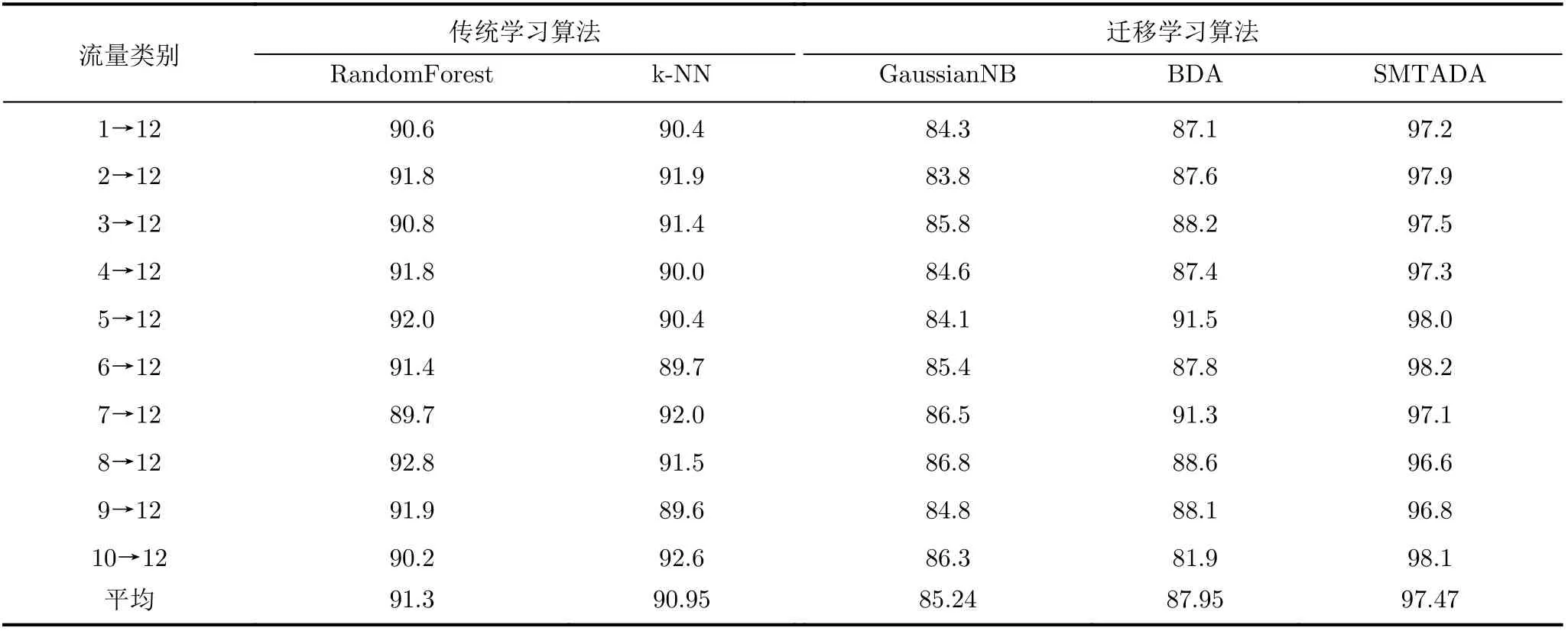
表3 应用流量实验对比结果(%)
在应用流量识别中,首先使用本域的数据进行训练模型,然后用模型预测本域的应用流量分类准确率达到了95%,但是由于概念漂移、新应用的不断产生以及网络拓扑和时间的变化,新的应用流量的统计特征将不再符合训练数据和测试数据来自同一个特征空间,特征遵循相同的概率分布这一假设。所以传统的机器学习算法在不服从这一假设的情况下,效果并不是很好。而迁移学习没有这一假设,通过一定的迁移策略进行知识的迁移,使得模型达到了比传统机器学习相对更好的效果。
然后对源领域和目标领域中的数据集进行特征选择,通过本文提出的应用流量逆向特征自删除策略进行特征的选择选出来的特征集合为{109, 119,123, 126, 223, 110, 1, 243, 233, 106, 221, 114, 241,115, 22, 231, 122, 165, 111, 155, 162, 169, 163,164, 42, 93, 92, 186, 95, 94, 0},一共31个特征属性,通过表4展示了部分所选特征的含义。

表4 所选特征的部分含义
所选特征用于SMTADA得到结果如表5所示。
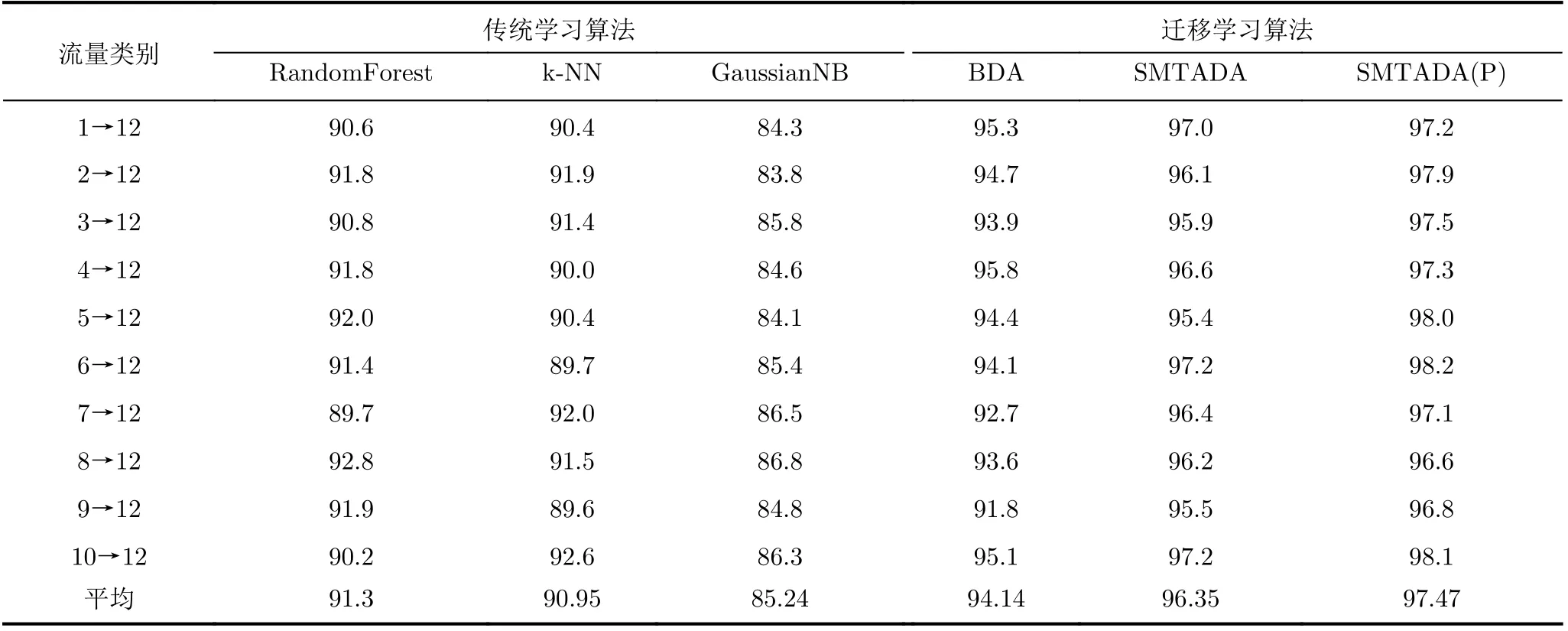
表5 逆向选择策略所选特征实验结果(%)
将选择出来的特征应用于SMTADA算法中,从图7可以看出,算法的运行时间缩短了80.2%,由于特征数量的删除,导致了部分信息的缺失,平均准确率比使用全特征时的准确率降低了1.12%。但是为后续的研究以及使用提供了参考价值。
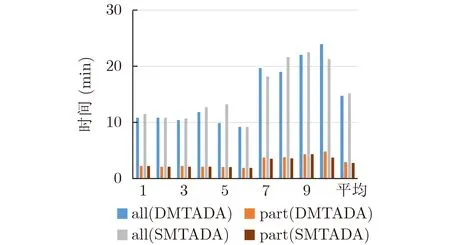
图7 特征选取前后所用时间对比
4 结束语
考虑应用流量特征分布随着时间等因素不断变化问题,本文提出了一种基于SMTADA迁移学习的应用流量分类方法。该方法通过最小化源领域和目标领域特征分布之间的平均均值距离构造迁移转换矩阵,利用转换迁移矩阵将源领域和目标领域特征迁移到同一个特征子空间中,达到减小分布距离的目的。实验结果表明,提出的方法在一定程度上减小了概念漂移等因素导致的源领域与目标领域边缘分布和特征分布不同导致机器学习预测准确率下降的问题。如何进行在线迁移学习,提高迁移过程的动态特征将作为下一步研究工作。
