基于注意力门控膨胀卷积网络的单通道语音增强
2022-09-22张天骐柏浩钧叶绍鹏刘鉴兴
张天骐 柏浩钧 叶绍鹏 刘鉴兴
(重庆邮电大学通信与信息工程学院 重庆 400065)
1 引言
在现实环境中,干净语音常被各种背景噪声干扰,其显著降低了各种语音设备的性能。单通道语音增强即在单个麦克风的条件下从被噪声污染的嘈杂语音中提取出干净语音,同时保证干净语音的质量与可懂度,常作为前端模块被广泛应用于语音通信、自动语音识别等领域。
早期语音增强通常采用基于统计模型的方法,如滤波法[1]、谱减法[2]以及基于最小均方误差的谱估计算法[3],这类方法通常需要特定的条件假设,且难以跟踪非平稳噪声特征,因此不能很好地适用于多变的语音增强场景。而近年来,深度学习迅速发展,由于深度神经网络(Deep Neural Network,DNN)具有较强的非线性建模能力,即使面对高度非平稳噪声,DNN也能有效提升单通道语音增强效果,因此,衍生出多种基于DNN的语音增强方法[4,5],这些方法结合各种特征预处理技术能够展现较强的增强效果,但由于DNN对语音时频结构信息的捕获能力较差,难以进一步提升增强语音质量。针对上述问题,循环神经网络(Recurrent Neural Network, RNN)与卷积神经网络(Convolution Neural Network, CNN)逐步应用于语音增强任务中。由于RNN能够发掘更多时序相关信息,文献[6]用其进行语音增强,取得了优于DNN的增强效果,但RNN存在长时依赖的问题,训练过程梯度容易消失,而长短时记忆单元(Long-Short Term Memory, LSTM)[7]的出现解决了该问题,该结构在RNN的基础上引入了门控机制,能够选择性传递信息并对梯度进行调整,Li等人[8]进一步采用一种双向LSTM结构(Bi-directional Long Short-Term Memory, BiLSTM)来进行噪声抑制,取得了优于LSTM的性能。
随着神经网络由浅向深发展,DNN与RNN会累积过大的参数而无法得到广泛应用。得益于CNN在图像领域取得的成功,众多学者采用CNN来进行语音处理[9,10],CNN能够减小训练参数的同时获取丰富的上下文信息,且能保证语音结构的完整性,因此能够很好地适用于单通道语音增强任务。文献[11]采用一种冗余卷积编解码网络(Redundant Convolution Encoder-and-Decoder, RCED)来进行语音增强,该网络采用全卷积编解码结构,取消了上下采样以及全连接层,取得了优于DNN与RNN的增强效果。文献[12]提出一种卷积循环网络(Convolution Recurrent Network, CRN),其联合CNN与LSTM,能够获取有效上下文信息并对序列前后相关信息进行捕获,但该网络训练参数较大,增强效果提升有限。在CRN的基础上,Tan等人[13]进一步对其改进,提出一种门控残差网络(Gate Residual Network, GRN),该网络能够挖掘更多时频相关信息并能显著降低训练参数,具有较大实用价值。此外,文献[14]在U-net[15]的基础上引入残差学习机制,缓解了模型梯度消失的问题,应用于众多基于深度学习的语音增强任务中。文献[16,17]把注意力门模块(Attention Gate, AG)引入U-net的跳跃连接中,在解码网络中得到了更加鲁棒的特征表示,取得了较好的增强效果。
上述方法能够在一定程度上提升语音增强效果,但往往难以在模型参数与模型精度上取得很好的平衡,部分方法难以适用于计算资源有限的语音增强任务,且无法同时捕获各个维度的语音特征。我们以最小化参数量并最大化提升语音增强效果为原则,设计了一种新型卷积网络用于语音增强。所提网络采用典型编解码结构,在编码和解码部分,借鉴文献[18]的非对称卷积,提出一种2维非对称膨胀残差(Two-Dimensional Asymmetric Dilated Residual, 2D-ADR)模块,该模块结合非对称膨胀卷积与普通非对称卷积,能够减小训练参数的同时增大感受野,并获取丰富的上下文信息,提升模型对全局信息的感知;在传输层提出一种1维门控膨胀残差(One-Dimensional Gating Dilated Residual,1D-GDR)模块,该模块在膨胀卷积与残差学习的基础上引入了门控机制,能够选择性传递信息并增强网络对时序相关信息的获取,然后根据Dense-net[19]的思想,采用密集跳跃连接的方式对8个1D-GDR模块进行堆叠,以加强层级信息传递并实现隐式深度监督。此外,我们在对应编解码层的跳跃连接中引入AG模块,使得解码过程获得更加鲁棒的底层特征。最后,在TIMIT语料库与28种环境噪声上验证了所提网络的有效性与鲁棒性。
2 相关工作
2.1 基于神经网络的语音增强流程
神经网络在语音增强中的作用一般可概括为通过已知的语音和噪声数据学习得到含噪语音到干净语音特征空间的映射函数。本文采用谱映射的方式进行语音增强,增强流程如图1所示。
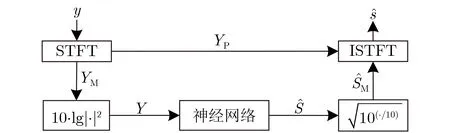
图1 语音增强流程图

2.2 注意力机制
在CNN中,标准卷积仅着眼于局部感受野(receipt field),而忽略了特征图中不同元素间的相关性。例如在K×K的卷积核中,目标元素的值完全由它与它周围K×K-1个元素计算,这可能导致缺乏对全局信息的感知。而注意力机制能够捕捉元素间的相互关系,并赋予元素全局感受野,最终通过各种操作获得不同时间、空间和通道之间的信息相关性[20]。注意力机制的本质是对特征图不同区域进行加权处理,用来突出相关特征,并弱化无关特征。
2.3 门控机制
门控机制最早提出于LSTM,通过门控机制传递相关特征并遗忘无关特征,从而选择性传递信息流,该机制提升了RNN对序列相关信息的处理能力。但由于RNN存在并行性差、计算开销大等缺点,实际应用能力较差。针对上述问题,Dauphin等人[21]提出一种性能优越的门控线性单元(Gate Linear Unit, GLU),其具备门控机制的优点,同时采用全卷积运算,有效减小了训练参数。GLU的表达式为

2.4 膨胀卷积
CNN通常采用扩展网络感受野的方式来增强对上下文信息的获取,而膨胀卷积[13,16]是提升网络感受野的有效途径,膨胀卷积能够指数性提升网络感受野而不会损失分辨率与覆盖范围,在相同参数的情况下,膨胀卷积能够提取更加丰富的特征。本文网络采用2维膨胀卷积(Dilated Conv2d)与1维膨胀卷积(Dilated Conv1d)相结合的方式,Dilated Conv2d即卷积核在时间和频率两个尺度上膨胀,旨在获取更加丰富的时频相关信息,而Dilated Conv1d仅在时间维度上进行膨胀,旨在捕获更多序列相关信息,两种方式都能有效扩大网络感受野。设2维卷积核F大小为( 2n+1)×(2n+1),则Dilated Conv2d的表达式为

3 网络结构
本文网络采用典型编解码结构,包含编码层、传输层与解码层3个部分,编码层采用2维卷积的方式获取抽象特征,传输层采用1维卷积的方式对编码序列信息进行处理,解码层为编码层的逆过程。在该节中,我们首先提出了两个残差模块,分别为2D-ADR与1D-GDR, 2D-ADR同时作用于编解码层部分,1D-GDR作用于传输层,两个模块分别提取不同维度的特征信息,提升卷积过程对全局相关信息的获取能力。其次,搭建了由1D-GDR组成的密集连接门控残差网络,用以捕获多尺度特征并增强层级信息传递。最后,引入了注意力门模块(AG)并对整体网络结构进行了阐述。
3.1 2维非对称膨胀残差模块与1维门控膨胀残差模块
为了防止梯度消失,许多神经网络采用了深度残差学习的方式[14,16],其能改进信息流与梯度的传播方式而优化网络训练。结合残差学习与膨胀卷积的优点,在网络编解码层中,提出了一种2维非对称膨胀残差模块(2D-ADR),如图2(a)所示。受Lednet[18]启发,所提模块采用了非对称卷积的方式,即利用两个卷积核分别为 1 ×n和n×1的卷积层来替代原来的n×n的卷积层,当n>2时,这一操作使得网络参数减少 (n-2)/n,并且不会损失网络精度。此外,2维膨胀卷积进一步提升了单层卷积模块的实际感受野,更大的感受野有利于获取更多的上下文相关信息并进一步提升网络精度。
在2D-ADR中,所有卷积层的卷积步长都为1,且卷积之后依次通过批次归一化(Batch Normalization, BN)层与指数线性单元(Exponential Linear Unit, ELU)激活函数。输入特征图首先通过一个卷积核为3 ×3的2维卷积层(Conv2d),为了控制网络参数,卷积后通道数C减半,特征图大小变为T×F×(C/2), 其中T和F分别表示时间帧与频率维度。降低通道后的特征图并行通过两个非对称卷积层,右侧分支采用卷积核大小分别为 1×5和5×1的 2维膨胀卷积(Dilated Conv2d),膨胀率d保持一致,用以扩展感受野来增强对全局特征的提取,左侧分支采用卷积核大小分别为 1 ×3 和3×1的普通2维卷积(Conv2d),用以捕获局部特征,两个分支通过逐点相加(Add)进行合并。然后,合并后的特征图通过一个 1×1的卷积层来还原通道数。值得注意的是,为了获得更加鲁棒的特征,受文献[22]启发,本文在输出端构造了特征增强(Feature Enhancement, FE)模块,其由全局平均池化(Global Average Pooling, GAP)和一个全连接(Full Connection, FC)层构成,采用GAP的原因为其从结构上规范了整个网络,以防止过度拟合,从而更好地利用全局上下文信息。最后,特征增强后的输出与模块输入逐点相加得到残差连接输出。
在传输层中,本文设计了一种1维门控膨胀残差模块(1D-GDR)来处理编码压缩后的序列信息,如图2(b)所示。由于门控机制能够有效判别序列相关特征信息,因此1D-GDR在残差学习与膨胀卷积的基础上引入了门控机制。模块包含上下两个并行卷积层,卷积步长都为1,上半部分在GLU的基础上把两个卷积层替换为1维膨胀卷积(Dilated Conv1d),膨胀率保持一致,为了平衡网络的性能与参数,采用了卷积核大小为5的折中选择,且卷积之后通道C减半,下半部分为两个卷积核为1的普通1维卷积层(Conv1d),用以还原通道数,分别得到残差连接输出与跳跃连接输出。通过对1D-GDR模块进行堆叠,并不断增大膨胀率,能够扩大网络感受野并增强对1维特征元素间的长期依赖关系的获取,从而提取更为丰富的时序相关信息。
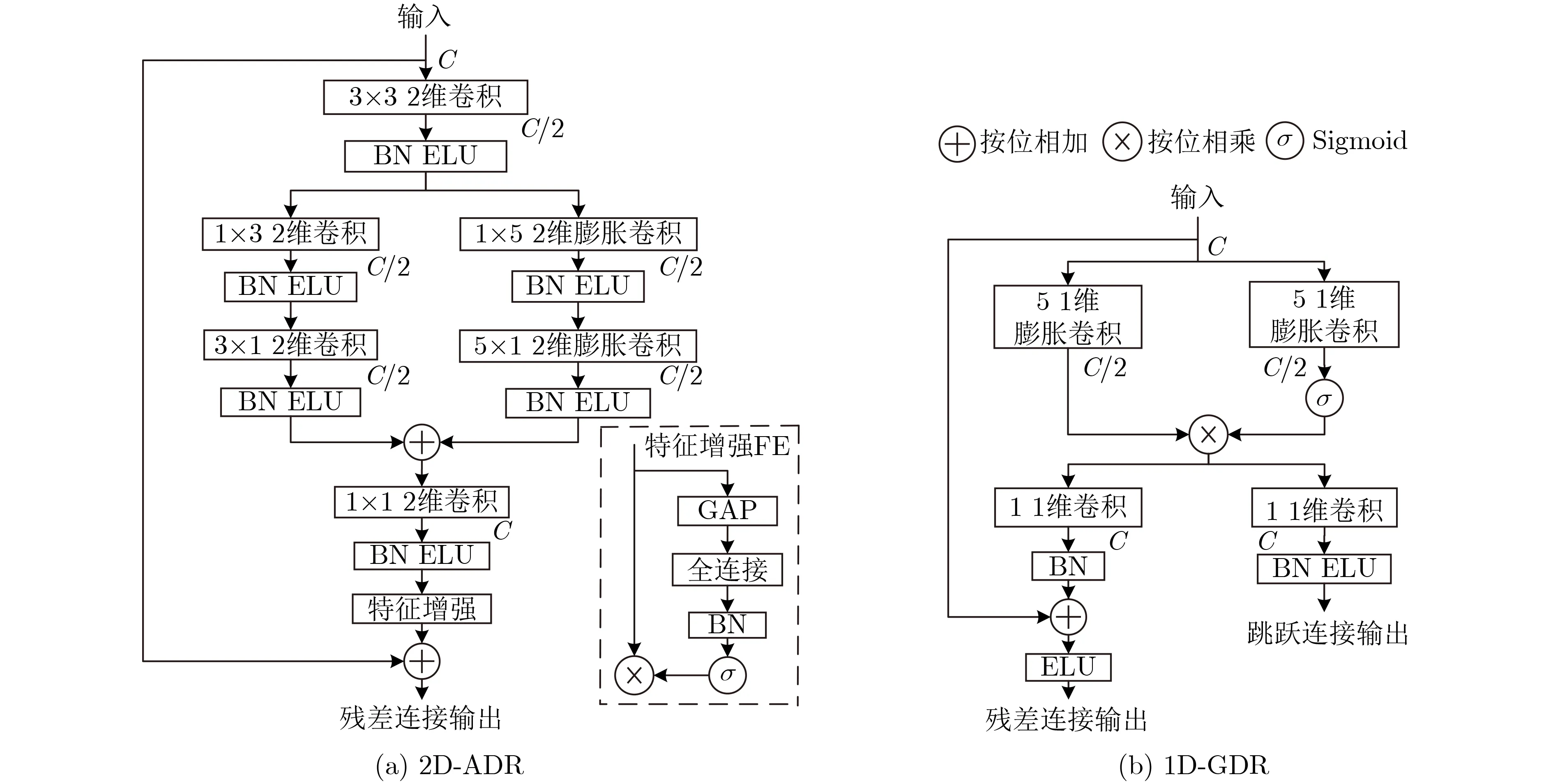
图2 2维非对称膨胀残差模块与1维门控膨胀残差模块
3.2 密集连接门控膨胀残差网络
随着网络层数叠加,特征图的分辨率逐渐降低。目前,许多研究[17,18]采用跳跃连接的方式来融合不同层级的特征,从而弥补编码过程丢失的详细空间信息(如边缘、边界等),并细化特征提取结果。受Dense-net[19]启发,我们搭建了密集连接门控膨胀残差(Dense Connection Gate Dilated Residual, DCGDR)网络,其结构如图3所示。DCGDR主要由2个1维卷积层(Conv1d)与8个1D-GDR组成,2个Conv1d用来调整输入输出维度,其卷积核的大小和步长都为1,中间部分由8个1D-GDR模块以密集跳跃连接的方式堆叠而成,为防止栅格效应,膨胀率d依次设为1, 2, 5, 9, 2, 5, 9, 17,4个模块形成一个堆栈。DCGDR作用于网络的传输层,每一层都重用来自所有先前层的输出,用以捕获多尺度时序相关信息,从而融合不同级别的特征来提高模型的鲁棒性,并给出更加平滑的决策边界。另外,考虑到采用通道拼接(Concatenate)会导致特征通道数随着网络逐渐深入而累加,这将使得模型参数激增,不利于计算资源有限的语音增强任务,因此,每个层级后使用了逐元素相加(Add)的方式来融合不同层级特征。

图3 密集连接门控膨胀残差网络
通过卷积运算之后,网络在第L层的输出可表示为

3.3 注意力门控模块
由于语音频谱包含丰富的频率成分,其中共振峰主要在低频区域占主导,而在高频区域稀疏分布,因此有必要使用不同的权重来区分不同的区域,结合注意力机制特点,在解码过程中本文采用注意力门(AG)模块对低层次特征图的不同区域进行聚焦,AG模块能够自动学习聚焦不同形状和大小的目标结构,并抑制输入特征图中不相关的背景区域,同时突出对特定任务有用的显著特征。本文采用的AG模块如图4所示,模块的具体计算公式可表示为
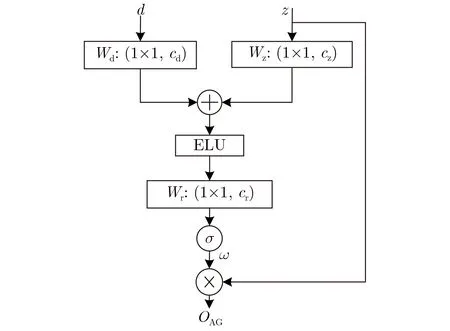
图4 注意力门控模块

3.4 网络整体结构
网络整体结构如图5所示。根据文献[23]所述,2维卷积更适合在保持原始语音结构的同时进行特征变换,因为它限制了变换过程过多关注局部区域,受其启发,网络的编码层和解码层采用2维卷积的方式对特征进行编解码。相比之下,1维卷积更能捕捉整体特征与特征维数之间的关系,因此,传输层的所有1D-GDR模块都采用1维卷积。
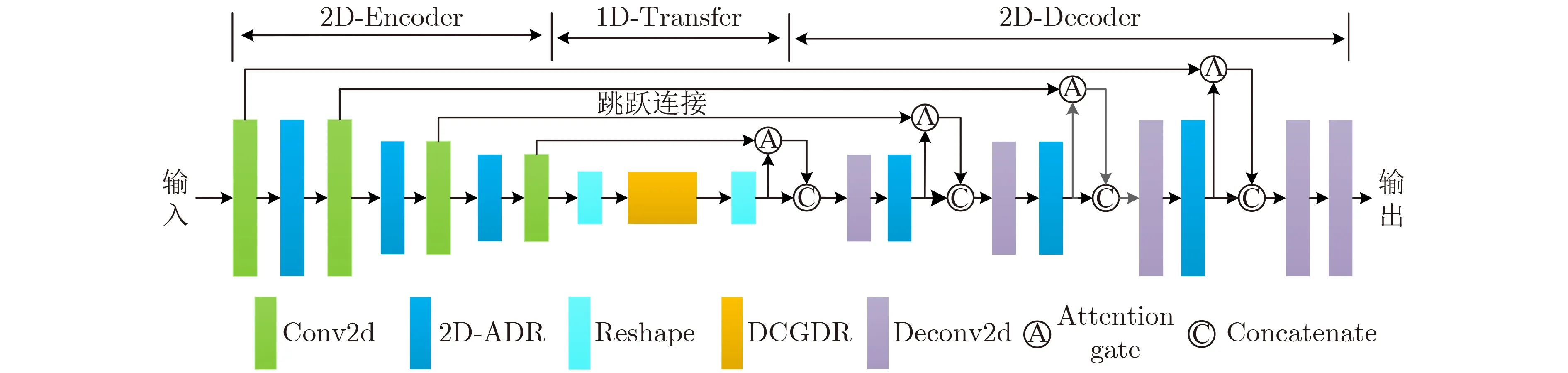
图5 注意力门控膨胀卷积网络
编码层(2D-Encoder)主要包含两类模块即Conv2d与2D-ADR,4个Conv2d模块用来捕获初始语音时频特征并对特征图维度进行压缩,3个2DADR模块用来补偿感受野的损失,并获取丰富的全局上下文信息,其膨胀率分别为1, 2, 4,通过对两类模块进行交替组合,从而编码压缩得到更加鲁棒的低维特征。
传输层(1D-Transfer)的主要模块为DCGDR网络,在进行特征传递之前,需要先将编码压缩后的特征图重塑(Reshape)到1维,从而更加有效地捕捉整体特征的相互关系,同样对DCGDR的输出特征进行重塑(Reshape)还原特征维度。
解码层(2D-Decoder)为编码层的逆过程,主要包含两类模块即2维反卷积(Deconv2d)与2D-ADR,5个Deconv2d模块用来恢复压缩特征的位置信息,并对抽象特征进行一定程度的还原,3个2DADR与编码层对应模块一致,用来对特征信息进行补偿,且膨胀率同样为1, 2, 4。值得注意的是,网络最后一个Deconv2d模块采用Tanh作为激活函数,令其作为网络输出层以还原所有尺度特征。
此外,对应层级的编码层与解码层使用了跳跃连接,每个跳跃连接中嵌入了AG模块,每个AG的输出特征图与相应解码层的输出特征图进行通道拼接(Concatenate)得到新的融合特征作为下一解码层的输入。通过这种方式,更加鲁棒的高分辨率特征与低分辨率特征进行结合,从而提升解码过程对特征的恢复效果并进一步提升网络精度。
网络参数如表1所示。其中k,s,c和d分别表示卷积核大小、步长、输出通道数与膨胀率,c1,c2表示DCGDR中两个Conv1d的输出通道数。输入输出维度的3个参数分别表示时间帧T、频率维度F以及特征图通道数C。其中,编码部分的前2 个Conv2d模块使得特征图在时间和频率上都减半,同时通道数翻倍,而后两个Conv2d仅使得频率维度减半而时间和通道都保持不变,通过这种方式使得网络获得多尺度信息,此外,传输层中DCGDR网络的输入输出维度相同,这使得其具有很好的移植性,而解码层用以还原特征维度和具体特征信息,从整体上看,网络输入输出维度保持为128×128×1。

表1 网络参数
4 实验与结果分析
4.1 数据集及参数设置
实验在TIMIT语料库[24]上进行。选取其中1200干净语音用于训练,300条用于测试。噪声选自Noise92噪声库与其他100类生活常见环境噪声,共28种,噪声被分为训练噪声和测试噪声,而测试噪声又分为匹配噪声(参与训练的噪声)与不匹配噪声(未参与训练的噪声),具体划分方式如表2所示。含噪语音由干净语音和噪声混合得到,把训练语音和训练噪声按6种信噪比(-6 dB, -3 dB, 0 dB,3 dB, 6 dB, 9 dB)混合得到含噪语音训练集,以训练集的20%作为验证集,每个训练轮次(Epoch)后使用验证集来验证性能。同样,把测试语音与匹配噪声混合得到匹配噪声测试集,为了评估模型泛化能力,把测试语音和不匹配噪声混合得到不匹配噪声测试集,混合信噪比分别为-5 dB, 0 dB, 5 dB,10 dB。最终,我们的训练集包含158400条含噪语音,匹配噪声测试集和不匹配噪声测试集分别包含9600与7200条含噪语音。

表2 噪声类型
本文语音和噪声统一下采样到8 kHz,帧长为31.875 ms,即255个采样点,帧移为7.875 ms,采用汉明窗来减少频谱泄露。对含噪语音STFT后的幅度谱平方取对数得到输入特征,由于STFT后的频谱具有共轭对称性,为减小计算量,每帧的频率维度取一半为128,由于输入帧数同样为128,则网络的输入维度经通道调整后为1 28×128×1,使用干净语音的对数功率谱作为网络训练标签,维度与含噪语音保持一致。
本文模型通过Keras在Tensorflow后端进行开发,开发环境基于CUDA10.0与cuDNN7.4.2。经实验比较,每个卷积模块的初始化方法为“he_normal”,使用ELU作为网络激活函数,采用Adam作为网络优化器,初始学习率为0.001,每10个训练轮次后,检查验证损失是否下降,若未下降则学习率衰减为原先的0.5,Mini-batch大小为32,Epoch次数为100,训练之后保存验证集上最佳权值参数集。
4.2 损失函数
训练神经网络常用的两种损失函数分别为最小均方误差(Mean Square Error, MSE)以及最小绝对值误差(Mean Absolute Error, MAE)。本文采用一种新的联合函数(Huber)作为损失函数,Huber综合了MAE与MSE的优点,能够快速求得稳定解且对奇异值不敏感,具有更高的训练精度,其表达式为

4.3 评价指标及对比方法
实验采用3种指标对语音进行客观评估。采用语音质量感知评价(Perceptual Evaluation of Speech Quality, PESQ)评估语音质量[25],其得分区间为[-0.5,4.5],得分越高语音质量越好;采用短时客观可懂度(Short Time Objective Intelligibility, STOI)评估语音可懂度[26],其得分区间为[0,1],得分越高语音被正确理解的概率越大,后文以百分比(%)表示;采用对数谱距离(Log Spectral Distance, LSD)衡量语音的短时功率谱差异,得分越低语音失真越小。其中LSD的公式为

图6 各损失函数的训练误差与验证误差

同时采用国际电联ITU-T P.835标准推荐的3种主观指标对语音进行主观评估,分别为CSIG,CBAK和COVL,3个指标分别表示信号失真、背景失真和整体听觉效果的平均意见得分(Mean Opinion Score, MOS),取值范围都为[1,5],得分越高,性能越好。主观评测过程中,随机选取25位听觉良好的试听者,并从匹配测试集和不匹配测试集中分别选取20条含噪语音(一共40条,无奇异样本),令25位试听者逐一对各方法得到的增强语音进行评分,最后分别计算3个主观指标在40条样本下的平均值。
实验部分,为了验证网络的有效性,我们首先比较了网络在不同参数设置下的增强效果,其次,本文使用了多种性能优越的语音增强网络作为对比方法来与本文网络进行对比,包括BiLSTM[8],RCED[11], CRN[12], GRN[13]、噪声感知注意力门控网络(NAAGN)[16]以及注意力U型网络(AU-net)[17],同时对比了经典谱减法[2]并采用最小值追踪算法对噪声进行估计。其中,RCED是一种基于CNN的典型编解码网络,CRN的编解码层与文献[12]保持一致,中间层为3层单向LSTM,每层包含512个隐藏单元,BiLSTM包含3层双向LSTM,每层同样包含512个隐藏单元,NAAGN仅采用其网络主体结构,其余网络的参数遵循原论文设置。为了减少变量,所有网络的输入输出都为对数功率谱且维度与本文保持一致,同时采用本文的损失函数与数据集来进行训练与测试。
4.4 实验及性能分析
保持其他参数不变,表3为本文网络选取不同膨胀率对增强语音的PESQ和STOI(%)影响(其中PESQ和STOI(%)为14种测试噪声和4种信噪比条件下的均值,表4同理)。对比表3可知,当编解码层和中间层的膨胀率分别为1, 2, 4和1, 2, 5, 9, 2, 5,9, 16时,网络获得最高指标,可能是该设置减小了膨胀过程中的栅格效应,网络获取了更加丰富的全局相关特征。表4为不同AG块数量对PESQ和STOI(%)的影响,AG块由第1个解码层依次向后叠加。观察表4可知,若不采用AG,网络指标相对较低,添加AG之后,PESQ提升了0.023~0.081,STOI(%)提升了0.31~0.85,这说明注意力机制有助于进一步提升增强效果,同时,当网络嵌入4个AG块时,以微小的参数提升换取了更高的PESQ,因此我们采用该设置。
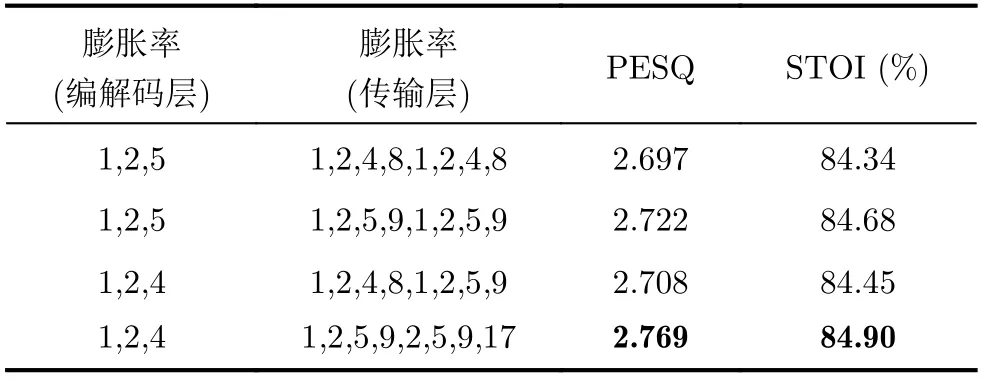
表3 网络取不同膨胀率对增强语音的PESQ和STOI(%)影响
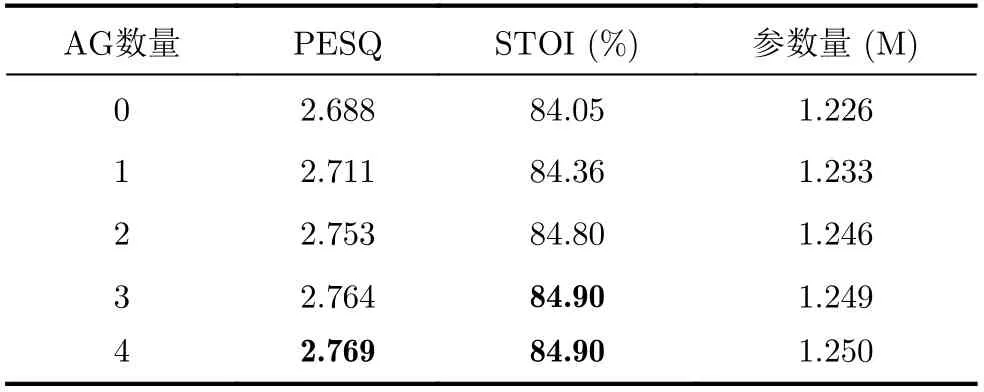
表4 AG的数量对增强语音PESQ和STOI(%)影响
表5和表6为匹配噪声和不匹配噪声信噪比(dB)为-5, 0, 5, 10下各方法得到的增强语音的平均PESQ和STOI(%)。对比表5可知,在匹配噪声下,谱减法的整体增强效果不理想,低信噪比下的语音质量和可懂度改善较小,可能是其对非平稳噪声特征捕获较差的原因,CRN与BiLSTM的PESQ和STOI得分相近,且高于RCED方法,这说明循环网络的应用能够促进时序相关信息的获取,从而进一步提升增强效果,此外,GRN与AU-net网络获得了更高的指标,NAAGN同样取得了可观的性能提升,而相比于以上方法,本文方法在各信噪比下PESQ均取得一定领先,PESQ均值提升了0.065~0.443,这说明本文方法增强语音的质量较高,但在-5 dB的STOI(%)略低于NAAGN,这可能是NAAGN采用了更大的卷积核,具备更大的感受野,低信噪比下的频谱损失相对较小,但本文方法的STOI(%)均值仍优于其他对比方法,STOI(%)均值提升了0.67~5.41,这体现了本文方法的有效性。对比表6可知,在不匹配噪声下,本文方法在各信噪比下的STOI(%)与PESQ均优于其他方法,且相较于匹配噪声下的指标,本文方法指标下降幅度更小,这说明本文方法具备更好的泛化能力。
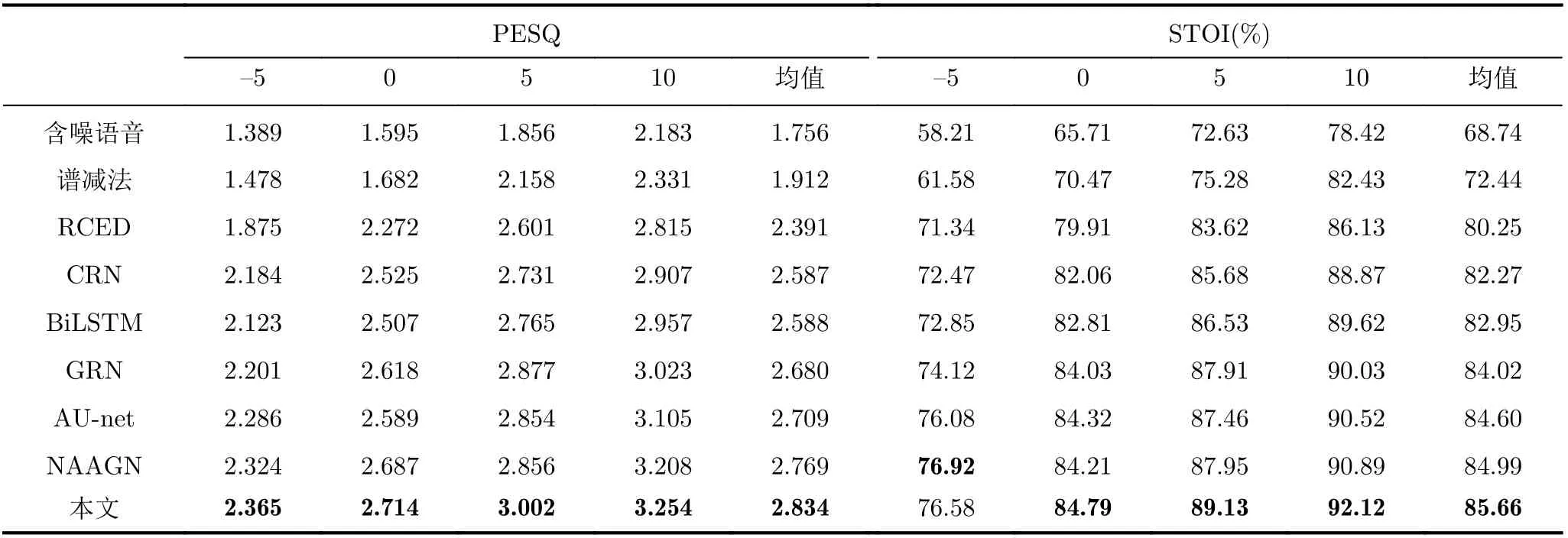
表5 匹配噪声下各方法的平均STOI(%)和PESQ
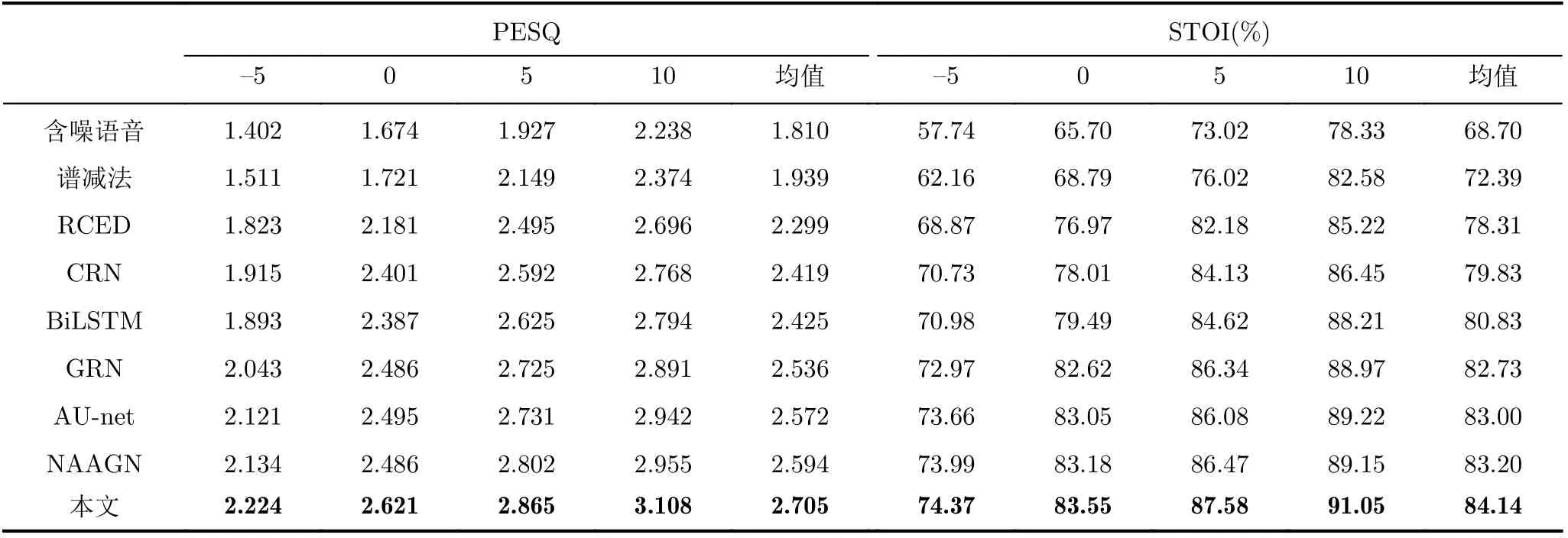
表6 不匹配噪声下各方法的平均STOI(%)和PESQ
表7为各方法的3种主观评价指标(CSIG, CBAK和COVL)得分。观察表格可知,本文方法的3种主观指标得分均优于其他方法,CSIG与CBAK相对提升较多,这说明本文方法在增强过程中引入的干扰噪声较小且能有效恢复语音成分,同时对背景噪声也有较强的抑制能力,整体质量和听觉效果良好,语音失真和背景噪声不易察觉。

表7 各方法的CSIG, CBAK和COVL得分
图7为各网络分别在14种噪声下的LSD(4种信噪比下的均值)。从图7可看出,在Hfchannel,Factory2与Crowd噪声下,本文方法的LSD取得了次优值,说明本文模型对这几种噪声特征的捕获效果较差,但整体上,在多数测试噪声下,本文方法取得了最小的LSD,这说明本文方法增强语音的失真更小。
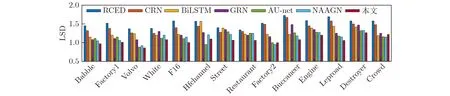
图7 各方法的LSD对比
图8以0 dB含噪(Babble噪声)女声为例,对比了各方法增强语音的语谱图。由图8可看出,谱减法对该噪声的处理能力较差,难以恢复完整语音,RCED与CRN方法能够恢复一定语音成分,但仍存留部分低频噪声且高频语音难以恢复,BiLSTM进一步降低了低频噪声,而GRN与AU-net恢复了更多高频语音,相比于以上方法,NAAGN取得了更好的增强效果,在语音的恢复和噪声的抑制上都有较好表现,而相较于NAAGN,本文方法取得了进一步的效果提升,保留了更多语音谐波特性,综合恢复效果更加显著。
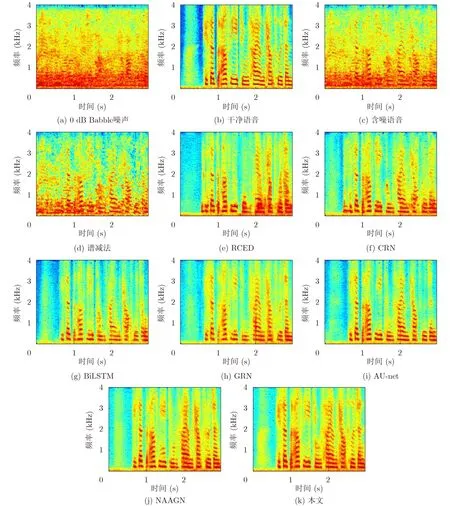
图8 语谱图
图9比较了各网络的参数量。我们发现,所提网络的参数量明显低于其他网络,且根据上述对比,本文方法的客观与主观指标也取得了一定提升,综上所述,本文方法以更小的计算资源达到了更好的增强效果,具有较高的实用价值。

图9 参数对比
5 结束语
在有监督语音增强中,上下文信息以及时序相关信息对神经网络能否准确映射得到目标语音特征空间至关重要,针对上述问题,本文设计了一种新型膨胀卷积网络来聚合语音的多尺度上下文信息,同时结合门控机制、残差学习以及注意力机制设计了不同的模块来处理不同维度的语音特征,从而进一步提升语音增强效果。通过在TIMIT语料库以及28种噪声下进行训练和测试,相比于其他优越的语音增强方法,本文方法在语音的质量与可懂度上均有一定提升,且语音失真相对更小,同时网络具有更小的参数量,整体方法结构具有较高的鲁棒性与泛化能力。后续研究需要继续优化网络各模块结构,进一步调整模块数量,减小计算复杂度,从而在模型参数与增强效果上取得更好的平衡。
