基于知识蒸馏与注意力图的雷达信号识别方法
2022-09-22曲志昱邓志安
曲志昱 李 根 邓志安
(哈尔滨工程大学信息与通信工程学院 哈尔滨 150001)
(先进船舶通信与信息技术工业和信息化部重点实验室 哈尔滨 150001)
1 引言
雷达信号识别是电子对抗的重要环节[1]。通过对截获的雷达信号进行识别,可以判断敌方雷达的类型、威胁等级,对于夺得战场的信息优势有重要意义[2]。随着新体制雷达大规模投入使用[3],实际战时侦察到的雷达信号可能为新调制类型信号,因此雷达信号识别算法需要进行识别类型扩展。
近年来,学者将机器学习与深度学习的算法应用在雷达信号识别领域。文献[4]将奇异值熵与分形维数作为特征向量,利用支持向量机(Support Vector Machine, SVM)实现了对8种雷达信号的识别。文献[5,6]都是利用卷积神经网络去噪,然后利用Inception网络进行分类识别,在低信噪比下(-10 dB)仍有90%以上的识别正确率。文献[7]设计了栈式稀疏自动编码器,将预处理过的8种雷达信号时频图像送入进行离线训练后,整体识别正确率达到96.4%。以上的识别算法虽然有较好识别正确率但是都是经过离线学习后识别固定类别的信号。当有识别类型扩展的需求时,需要已有类别与扩展类别的所有数据集混合后重新开始训练网络,这对于设备的存储资源和训练时间均有较高要求。文献[8]基于残差网络与3元损失函数学习得到特征映射,利用设计的基于样本库的识别方法实现识别类型扩展,但是随着类型的增加训练后的识别正确率有待提高。
本文采用增量学习的训练方法实现雷达信号识别类型扩展。针对增量学习过程中网络会出现灾难性遗忘[9]问题,本文利用基于特征平均值距离的方法选择极少典型样本构成新训练集,设计了基于残差的增量学习网络结构,并利用知识蒸馏与注意力图[10]缓解灾难性遗忘,实现了识别类型的有效扩展。仿真实验表明,在存储资源有限的条件下,本方法对原有分类与扩展分类的雷达信号均有良好的识别准确率。
2 知识蒸馏与注意力图
2.1 知识蒸馏
知识蒸馏[11]是一种有效的模型压缩方法,它将复杂模型所学到的“知识”迁移到参数量少的简单模型中。在知识蒸馏过程中,训练简单模型时加入复杂模型的softmax层输出作为软标签辅助训练,用来提高简单模型的识别效果。在复杂模型产生软标签的过程中,加入温度变量T使各个类别产生较平滑的概率分布,如式(1)所示,这使得负标签所携带的信息相对放大,模型训练更加关注负标签

2.2 注意力图
随着深度卷积神经网络在解决复杂视觉问题方面取得了长足进步,学者对于网络做出决策时的“依据”也进行了研究。注意力图 (attention map)是一种反映网络可解释性的重要方法,其能够表示网络做出输出决策时对输入图像最关注的区域。本文使用梯度加权类激活映射(Gradient-weighted Class activation mapping, Grad-Cam)[12]表示注意力图。Grad-Cam将网络的特征图赋予不同的权重,然后通过生成热力图标记出输入图像中对预测影响较大的像素区域。卷积神经网络最后一层卷积含有最丰富的语义信息与空间信息[13],所以Grad-Cam将最后一层卷积作为特征图。当图像进入网络后,得到其全连接层输出,计算全连接层输出最大值对特征图的梯度,经过平均计算后得到特征图权重,如式(3)所示

本文利用Grad-Cam对线性调频信号(Linear Frequency Modulation, LFM)、Frank编码信号、二相编码信号(Binary Phase-coded Signal,BPSK)、V型调频信号(DLFM)、偶2次调频信号(Even Quadratic Frequency Modulation, EQFM)与正弦调频信号(Sinusoidal Frequency Modulation signal, SFM)产生的热力图与叠加到原时频图像的效果图如图1所示。在热力图中,红色区域表示对网络输出影响较大的区域,由图1可以看出红色区域主要覆盖信号的时频结构,也就是说网络对信号调制类型识别时其决策依据主要为信号的时频结构。同时网络对于不同雷达信号的注意力图不同,将其作为额外的监督信息,在进行扩展类型识别时可以帮助缓解灾难性遗忘。

图1 雷达脉内调制信号时频图像Grad-Cam可视化效果
3 基于知识蒸馏与注意力图的雷达信号识别方法
本方法首先将雷达信号的平滑伪Wigner-Ville分布(Smooth Pseudo Wigner-Ville Distribution,SPWVD)作为网络的输入,将积累的扩展类型信号与存储的典型原有分类信号混合组成新的数据集。然后进行类别增量训练,训练过程中加入知识蒸馏损失与注意力图损失缓解训练过程中的灾难性遗忘。最后进行数据集管理,采用基于均值距离的样本选择方法,选择典型新类样本进行存储,同时删除部分原有分类样本维持存储样本总数不变。具体流程图如图2所示。
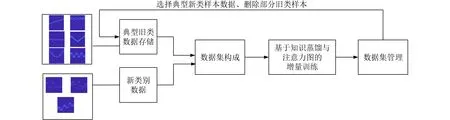
图2 基于知识蒸馏与注意力图的雷达信号识别方法流程
3.1 网络结构
本文采用基于增量学习的网络结构,信号经过SPWVD后送入网络进行训练,过程可以分为特征提取与分类识别,如图3所示。其中θs为用于特征提取的参数,一般为卷积神经网络中的卷积层。θo为识别已有类别所用到的参数,当需要进行类型扩展时增加全连接层的输出,所增加的参数用θn表示[14]。
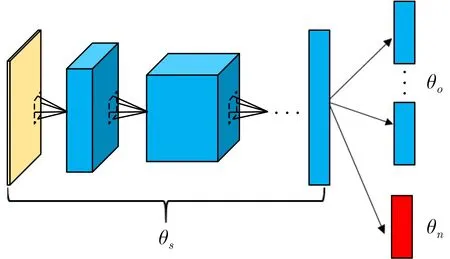
图3 增量识别卷积神经网络参数示意图
本文基于残差网络[15]设计的网络结构如图4所示,共有4组残差单元,每组残差单元两层卷积,将雷达信号做SPWVD后,经过线性插值调整为128×128的图像作为输入。最初的卷积层加上4组残差单元组成特征提取参数θs,全连接层的参数作为θo,输出扩展后增加的参数为θn。最后一组卷积单元的输出含有对时频图像最丰富的语义信息且未丢失空间信息,所以将其作为特征图用于计算Grad-Cam, softmax层的输出含有对时频图像预测概率的信息,所以将其作为软标签。利用网络扩展前后对于扩展类型数据Grad-Cam与输出预测的不同作为额外的监督信息加入训练。
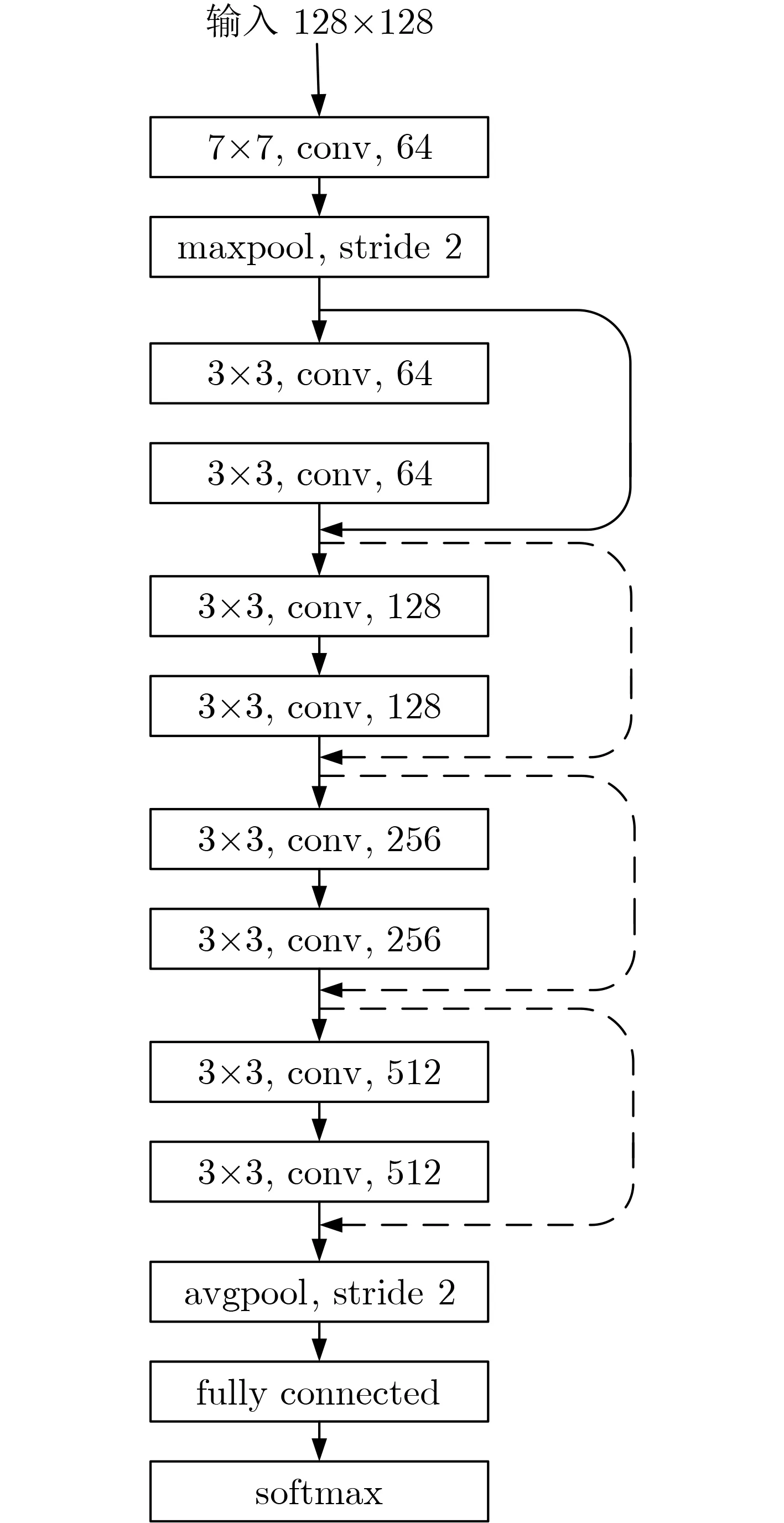
图4 网络结构
3.2 基于知识蒸馏与注意力图的增量训练




3.3 数据集管理
增量学习过程通常在存储资源有限的条件下进行[16]。采用基于特征均值距离的方法选择每一类的典型样本进行存储可满足存储资源有限的条件。基于特征均值距离的选择方法如式(8)所示

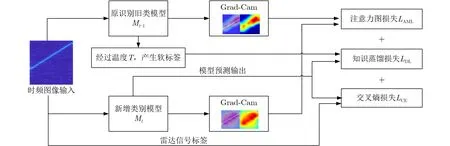
图5 基于知识蒸馏与注意力图的增量训练过程

图6 模型关注区域差异示意图

4 实验结果与分析
4.1 实验设置
为评估本方法的有效性,使用MATLAB生成数据,每种雷达脉内调制信号的频率参数根据采样频率做归一化处理,每种信号的长度N=512~1024且每种信号的参数都有一个动态变化的范围。首先将参数如表1所示的6种雷达脉内调制信号作为已识别的信号类型,数据集样本信噪比范围在-10~8 dB,每隔2 dB每种信号产生500个样本,所以每种信号有5000个样本,其中4500个样本作为训练集,500个样本作为验证集。测试集数据信噪比在-12~0 dB,每隔1 dB产生500个样本数据。
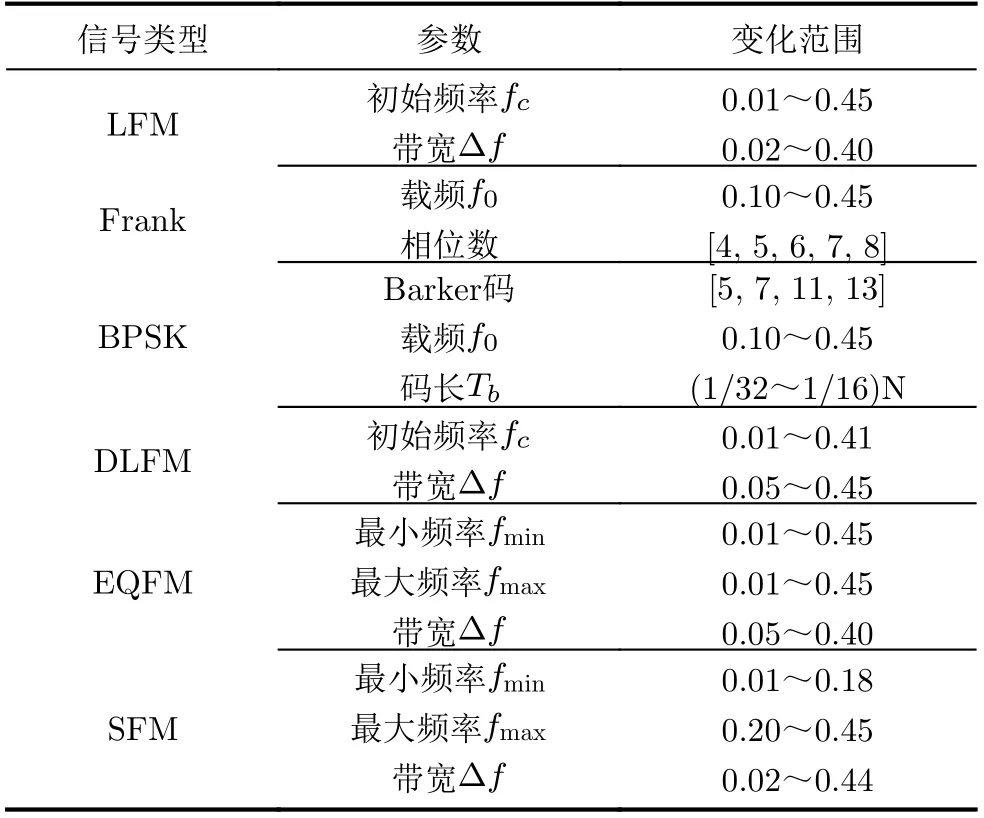
表1 已识别信号参数设置
基于以上训练集,训练得到模型Mt-1作为原有信号的识别模型。同时选取文献[18,19]所提出的模型与本文模型进行对比。文献[18]采用了基于AlexNet的模型进行识别,文献[19]采用了扩张残差网络进行识别。训练完成后用测试集测试,在不同信噪比环境下识别准确率如图7所示。由图7明显看出本文所用网络结构准确率较高,所用网络结构对信号有良好的特征提取能力与分类识别能力。
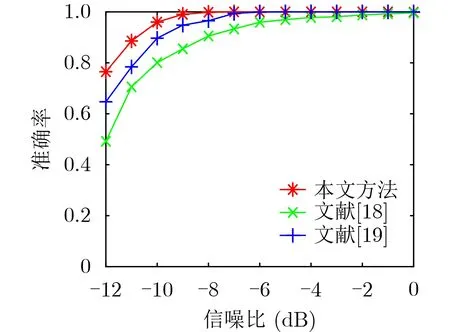
图7 准确率对比
设存储容量为600个样本,训练完成的模型Mt-1利用基于样本特征均值的方法,每一类信号选取100个作为典型样本进行存储。仿真参数如表2所示的雷达脉内调制信号依次作为扩展类型。信噪比设置与已识别的6类信号相同,每类新增信号同样也为4500个样本。所有训练过程batchsize设为64,采用Adam优化器,初始学习率设为1×10-3,随训练过程递减,知识蒸馏时设T=2,知识蒸馏损失、注意力图损失与交叉熵损失的加权系数分别取0.8, 0.1, 0.1。
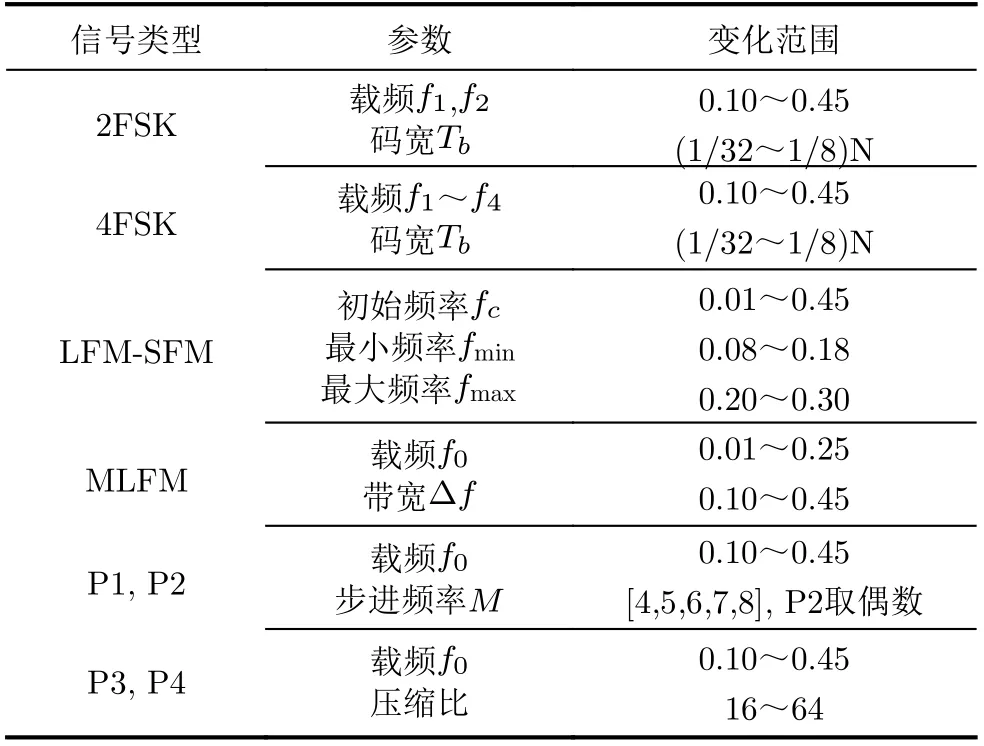
表2 扩展类型信号参数设置
4.2 与联合训练效果对比
联合训练是将原有分类与扩展分类的所有数据混合重新开始训练,不存在灾难性遗忘问题,可以看作增量学习识别效果的上限,但是对于存储及训练时间有较高要求。本次实验与联合训练方法进行对比,在识别6类调制信号的基础上依次增加新调制类型。
图8为当扩展类型数量为4类,采用基于联合训练的方法、未添加注意力图损失的方法与本文方法训练时,每隔10个batchsize所记录的损失值,由图8可以看出每种方法训练完成后模型都收敛。图9为扩展类型为4类时,以上3种方法所训练的模型在-5 dB下识别效果的混淆矩阵。由图9可以看出,在-5 dB时本文方法的识别效果好于未添加注意力图损失的方法,且只有几种信号的正确率略低于联合训练方法。图10为扩展类型数量为4时,联合训练与本方法训练时与训练后所存储的样本数量。因为本方法采用的损失函数缓解了灾难性遗忘,所以训练时只需600个典型原有类别的样本与4500个扩展类型样本。当新增识别4类训练完成后,网络总共可以识别10类雷达脉内调制信号,根据样本选择方法每一类保存60个典型样本。同时,由于本方法训练集样本数量低于联合训练样本数量数倍,所以训练时间也会缩短。综上,本文方法进行雷达信号增量识别的效果与联合训练大致相当,但训练时间和存储要求远低于联合训练。
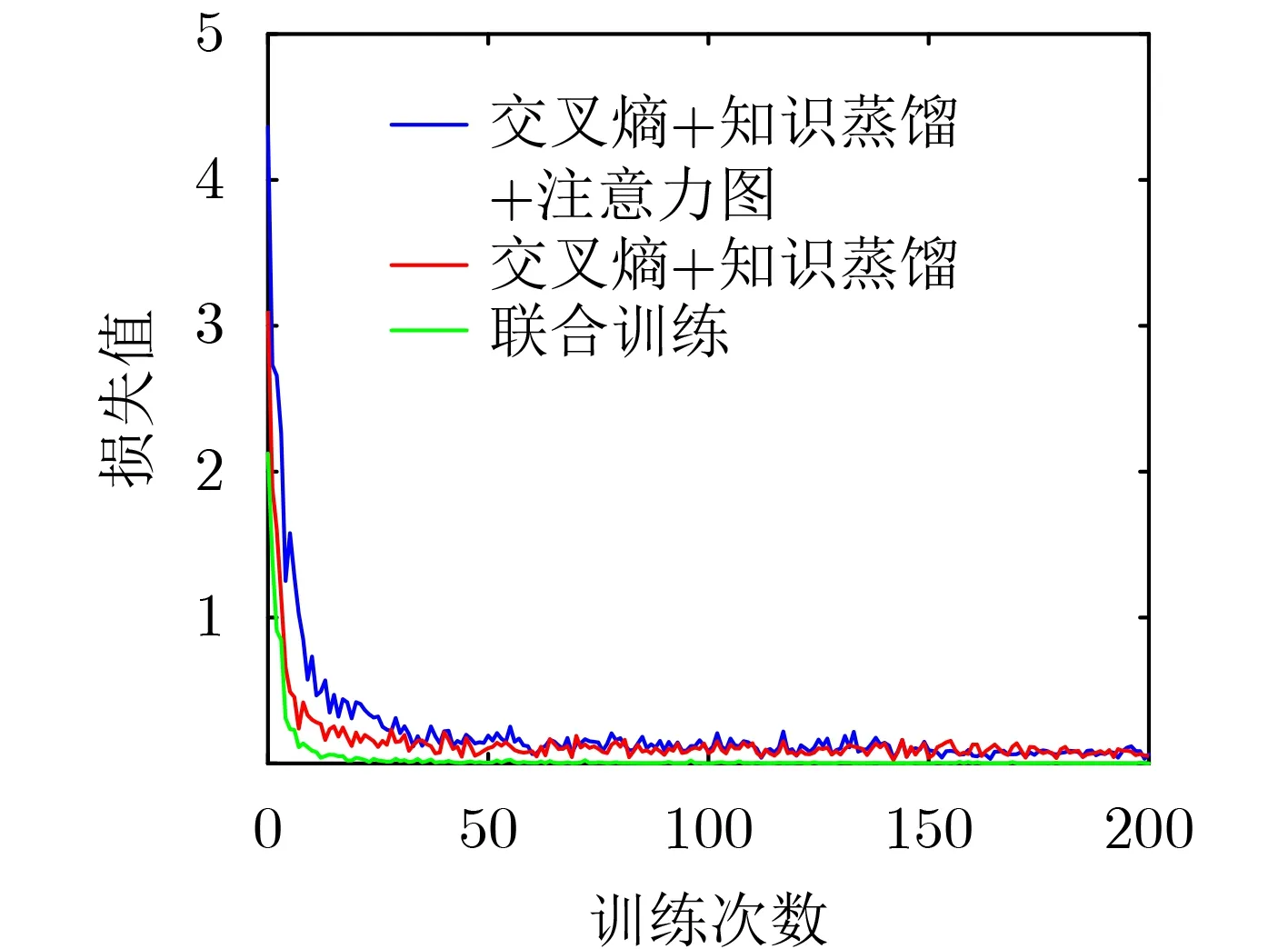
图8 不同模型损失

图9 信噪比-5 dB识别效果对比
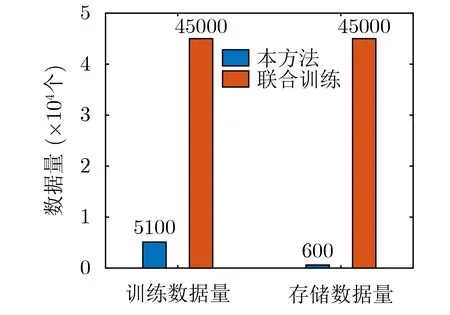
图10 联合训练与本文方法存储数量对比
4.3 缓解灾难性遗忘有效性验证
为验证所采用的损失函数的有效性,在相同数据集情况下,与文献[20]基于连续微调的增量识别方法进行对比;为验证存储典型样本的有效性,与只采用扩展类型数据训练的方法进行对比。当依次扩展1~4类调制信号时,得到每种模型在-12~0 dB下对于所有调制信号的平均识别正确率如图11所示。
由图11对比可知,由于添加了知识蒸馏损失与注意力图损失,从而缓解了网络对已有信号类型的遗忘,本文方法识别正确率要明显高于文献[20]中只采用交叉熵损失的连续微调方法。同时,当只用扩展类型数据进行训练时,与本文采用典型原有样本存储的方法在低信噪下的识别正确率有很大差距。这是因为低信噪比情况下时频结构受损严重,识别正确率相对较低,当仅使用扩展类型数据训练没有原有数据参与时,模型对已识别信号更容易遗忘。综上,本文方法所采用的知识蒸馏、注意力图与典型样本存储能够缓解增量识别过程中的灾难性遗忘,提高模型的识别正确率。
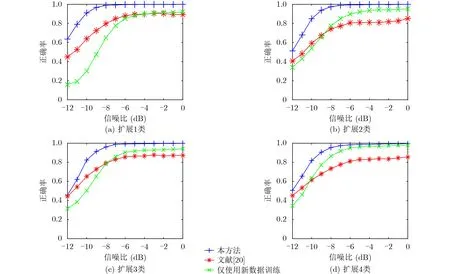
图11 识别正确率与信噪比关系曲线
4.4 增量识别扩展性验证
为测试本方法识别效果随扩展类型数量增加的变化,设计依次增加8种调制信号。每一类进行增量训练后,用信噪比为-7 dB的测试集进行测试。增量到8种信号时,模型总共可以识别14种信号,每一类信号存储43个典型样本。模型对调制信号的识别正确率与扩展数量的关系如图12所示。由图12可知,随着识别种类的增加模型识别效果逐渐下降。这主要是因为随着调制类型的增多,模型所学到的“知识”越多,再次新增类别时,“遗忘掉的知识”也会增多。同时由于存储限制,每一类的典型样本也会越来越少,也会造成识别效果下降。
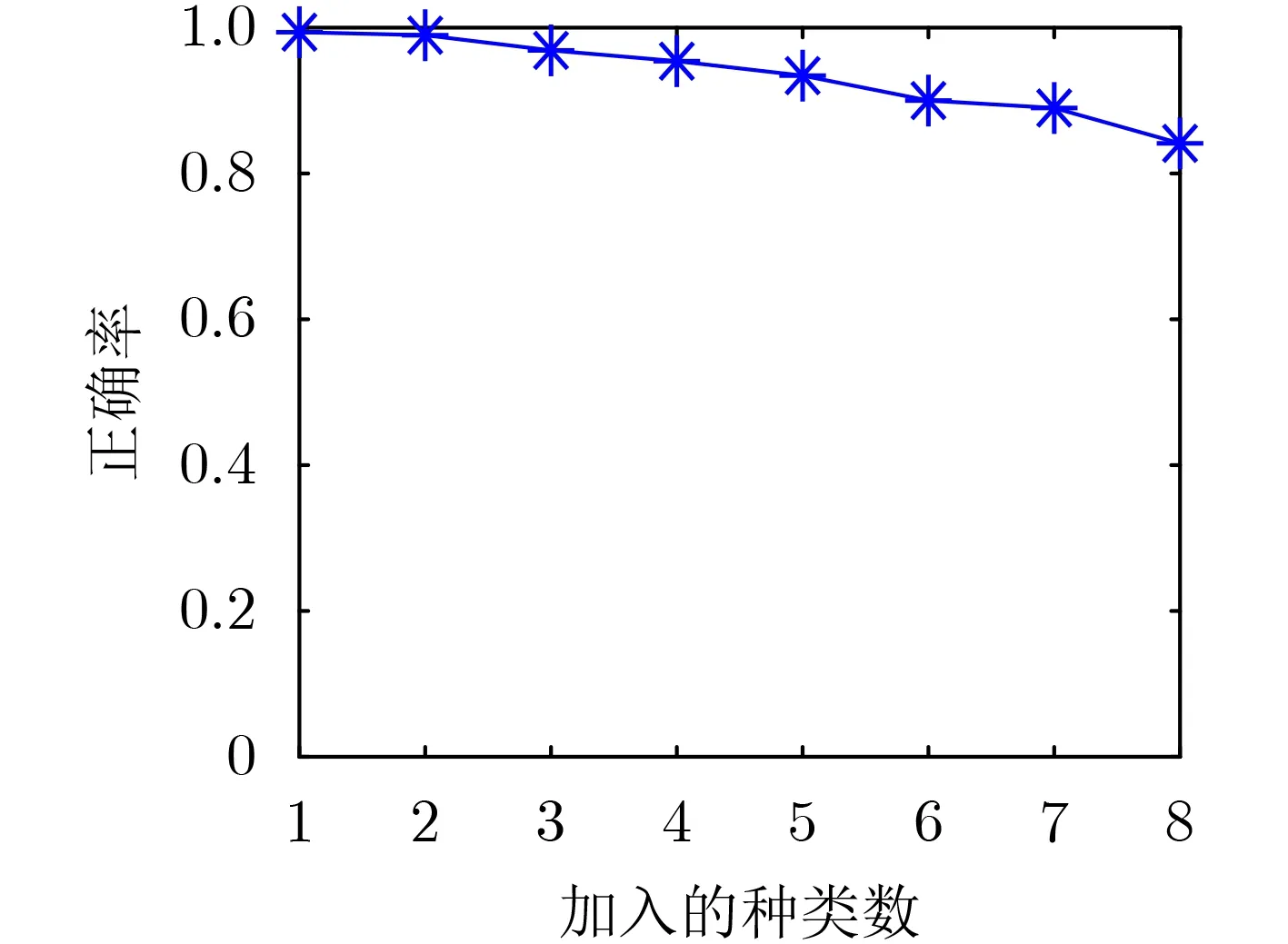
图12 类别扩展数量与识别正确率关系曲线
5 结论
本文基于知识蒸馏、注意力图与典型样本选择等方法,提出了一种基于残差网络的雷达信号增量识别方法,有效地解决了雷达调制信号识别类型扩展问题。仿真结果表明,本方法对原有分类和扩展分类的调制信号识别正确率逼近于联合训练模型得到的结果,但训练时间和存储要求远低于后者,同时本文所采用的损失函数能够有效缓解类别增量过程中的灾难性遗忘,使得模型对原有分类和扩展分类信号均有较好的识别正确率。
