数据新鲜度驱动的协作式无人机联邦学习智能决策优化研究
2022-09-22范文韦茜周知于帅陈旭
范 文 韦 茜 周 知 于 帅 陈 旭
(中山大学计算机学院 广州 510006)
1 引言
在传统计算范式中,用户设备通常将原始数据上传至集中云服务器进行处理,但是这不可避免地造成极大的传输开销和数据隐私泄露。针对该问题,联合利用移动边缘计算(Mobile Edge Computing, MEC)[1]和联邦学习[2]设计解决方案逐渐成为研究焦点。一方面,边缘服务器分担用户设备的联邦学习本地训练任务,既减轻用户设备的计算负载,又降低向云端传输数据造成的开销;另一方面,利用本地化模型训练结果聚合成全局共享模型,避免了隐私数据泄露的弊端,有利于实现快速、高效的训练过程。然而,边缘服务器通常是位置固定的且覆盖范围有限的,这将导致其无法灵活有效地处理复杂变化的强实时性任务[3]。
随着下一代网络系统如6G通信网络的快速发展,高性能无人机(Unmanned Aerial Vehicle,UAV)已被视为具备感知、计算和存储能力的空中边缘服务器[4]。与传统的安装在地面基站上的固定边缘服务器相比,无人机利用其高度敏捷性、灵活性和移动性实现按需部署,增强了系统的覆盖范围[5]。在许多强实时性应用场景(如交通管理、环境和灾难监测、战场监视等[6])中,多个无人机在不同区域中移动,及时接收众多分散的用户数据,以协作的方式完成复杂的移动边缘计算任务,训练具有高可用性和高实时性的机器学习模型(例如,图像分类模型)[7]。进一步地,在联邦学习模式下,多无人机完成训练后只需要将本地模型参数上传至云服务器进行全局模型聚合,实现训练模型的共享和隐私保护。
值得注意的是,无人机的感知半径有限,且有限的机载电池会约束无人机的移动范围,因此无法保证每个用户设备产生的数据都能及时地被无人机接收并处理。而在移动边缘计算场景中,数据的实时处理对其可用性和模型的实时更新非常重要。为此,文献[8]在模型中采用数据的信息年龄(Age-of-Information, AoI) 来刻画数据的新鲜程度,将其定义为数据最近一次成功传输后经过的时间[9]。但是,它们忽略了数据在区域中等待的时间,这对MEC 场景中无人机的模型训练和通信决策是至关重要的,特别是在多无人机协作训练的情况下。本文将数据的新鲜程度,即数据在端设备上等待的时间与被无人机接收并处理的时间之和定义为数据的信息年龄[10],通过最小化信息年龄来优化无人机移动边缘计算决策,提升联邦学习性能,增强数据处理实时性。因此,如何规划无人机的路径和制定通信决策,以及如何在无人机之间展开协同工作,合理地分配计算资源,同时满足能耗和时延的限制,成为本文需要解决的关键问题。
针对上述挑战,本文提出了一种崭新的基于数据新鲜程度的协作式无人机联邦学习范式,通过多无人机协同地智能地进行移动、通信和计算卸载决策,高效地完成了边缘数据处理任务,显著地降低了无人机的能量消耗并保证了模型高准确率和低数据信息年龄。本文进一步提出一种多智能体深度强化学习(Deep Reinforcement Learning, DRL)算法,有效地处理复杂状态空间,实现多无人机的高效协作和智能决策优化。本文的主要贡献包括4个方面:
(1) 提出面向实时边缘数据处理的多无人机协作式联邦学习范式,能够充分发挥无人机辅助移动边缘计算和联邦学习的优势,避免了云中心集中式数据处理的用户隐私保护弱和任务处理时延大等不足;
(2) 引入信息年龄以描述协作式无人机联邦学习的训练数据的新鲜程度,并据此对多无人机协同决策问题进行建模,以联合优化边缘数据处理的模型准确率、信息年龄以及总体能耗;
(3) 设计了一种新颖的具有全局和局部奖励的优先级多智能体深度强化学习算法,实现多无人机协同地移动、通信和任务卸载决策智能联合优化;
(4) 采用多个真实机器学习数据集进行仿真实验并设置了充分的对比实验,结果表明了本文提出的算法在不同数据分布下和在快速变化的复杂动态环境中都能实现优越的性能表现。
2 系统模型与问题形式化
2.1 区域模型
如图1所示,感知区域被划分为M={1,2,...,M}个子区域,每个子区域的中心位置设为用户设备,它感知并传输该子区域的实时数据至边缘服务器进行处理。在本系统中,由于安装在地面基站上的边缘服务器(后文简称为基站(Base Station, BS))的覆盖范围以及用户设备的射频功率有限,用户设备无法与基站直接通信。为了解决计算的局限性,系统部署多个无人机以接收和处理其覆盖范围内用户设备的实时数据。这些无人机配备了完成计算任务所必要的载荷,包括数据收发设备(如天线)、数据存储设备(如存储卡)和数据处理设备(如嵌入式CPU),以及基本设备(如机体、电池、动力控制和飞行控制装置)及其相关传感器。无人机的载荷高度集成化使其数据存储、数据处理和移动的综合能力远在固定的边缘服务器之上。在本文中,无人机作为性能适中的边缘服务器,支持长、短距离无线通信,能够为基站覆盖不了的区域提供计算服务。因此,无人机可以高效地充当边缘计算节点来完成本文的边缘计算任务。
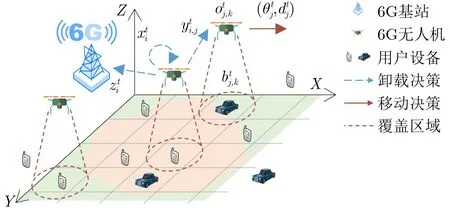
图1 基于MEC的多无人机感知区域

2.2 联邦学习模型


2.3 任务卸载模型


表1 系统参数及其定义

式(4)表示无人机i执 行卸载决策的数据总量要与从覆盖区域内的用户设备接收的数据总量一致。在多无人机协作过程中,每个无人机进行数据通信时主要传输实时数据和模型。相对于任务数据量的大小,模型的大小一致且可以忽略。因此,本文主要考虑任务数据传输时所产生的通信时延开销和通信能耗开销。
2.4 信息年龄模型


2.5 能耗模型

2.6 问题形式化
基于所构建的数学模型,本文希望在合理地规划无人机的飞行轨迹、智能地选择通信设备并分配联邦学习本地计算任务的前提下,找到一个可以长期最大限度地保持区域数据新鲜和模型的高预测准确率,同时最小化每个无人机能耗的解决方案。为此,将系统的优化目标表示为

其中,权重因子µ1和µ2可以实现AoI、预测准确率和能耗的长期动态平衡。由式(5)可知,为了减少自身能耗,无人机偏向于在原地徘徊并做更少的通信决策;而为了保持区域数据长期新鲜,无人机会频繁移动以收集和处理用户设备的实时数据。但是,无人机频繁收集覆盖区域的用户数据将导致其通信时延和能耗的开销增大。此外,联邦学习模式基于收集到的任务数据进行多分类预测模型训练,以提升模型准确性为目标,却忽略了任务的实时性。但是在实际应用中,数据的实时性对于模型预测是十分重要的。如果基于过时的任务数据训练模型对新鲜的数据进行预测,那么其得到的预测性能将不理想。在本文中,多分类预测模型是通过联邦学习在多分类数据集上训练而得到的,模型的训练效果包括模型的准确性和模型的实时性。其中,模型的准确性是通过多分类预测任务的结果体现的,模型的实时性是由数据的新鲜程度决定的。
3 算法设计
本文所要解决的多无人机协作路径规划、通信决策和任务卸载决策问题属于复杂的离散变量和连续变量耦合的组合优化问题,采用传统的优化方法难以求解。因此,本文将该问题转化为马尔可夫决策问题,并设计基于深度强化学习的新型智能化优化算法来高效求解。
3.1 问题转化


3.2 算法设计
传统的多智能DRL算法,如多智能体深度确定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient, MADDPG)算法,通常优化单一的整体奖励。但是这可能会使学习过程在优化全局对象和局部对象之间来回波动,从而导致收敛不稳定、收敛速度缓慢等问题。因此,本文将奖励函数分解为全局奖励和局部奖励,其中局部奖励是每个智能体的本地优化目标,即减少无人机的能耗;而全局奖励是智能体群组的共同优化全局目标,即提高目标区域数据的AoI和模型预测准确率。为了实现全局优化目标和局部优化目标之间的动态平衡,本文引入可分解的多智能体深度确定性策略梯度(DEcomposed Multi-Agent Deep Deterministic Policy Gradient, DE-MADDPG)方法[13]。
DE-MADDPG是一种采用双critic网络的多智能体DRL算法,其目标是同时朝着使全局奖励和局部奖励最大化的方向优化策略。在给定当前状态si时,每个智能体i中的分布式actor网络可以生成动作ai。Actor网络使用确定性策略梯度方法进行参数更新,其梯度可以表示为


在本文的多无人机动态决策场景中,状态空间和动作空间规模随着无人机数量和目标区域规模的增加而迅速增加。为了学习有价值的样本进而优化策略以加速DRL的收敛过程,本文进一步结合优先级经验回放机制[14]与DE-MADDPG方法,设计了基于优先级的可分解多智能体深度确定性策略梯度算法(Prioritized Decompose Multi-Agent Policy Gradient, PD-MADDPG)。缓存中的每个样本都有一个优先级,为其样本的TD误差。TD误差越大的样本,其估计值与目标值差距越大,网络使用此样本进行训练时可以更快提升性能。
3.3 算法实现
本文将训练一个共享预测模型的联邦学习作为系统的主要任务(表2),在训练过程中调用PDMADDPG 算法提供阶段性通信和卸载决策(表3),并将预测模型训练结果反馈给PD-MADDPG算法进行优化。PD-MADDPG算法在每一轮联邦学习的本地迭代中在线为无人机提供执行联邦学习的相关决策,并且在每轮全局迭代后,都进行离线网络训练。无人机在探索时依据当前状态执行动作,计算全局奖励rgt和局部奖励rlt。以上离线训练过程结束后,将训练得到的多个actor网络模型部署到对应的无人机上再执行。

表2 联邦学习算法(算法1)

表3 PD-MADDPG算法(算法2)
3.4 算法复杂性分析


4 实验结果与分析
4.1 仿真实验设置

4.2 数据集与对比算法
本文采用3个真实的10分类数据集来进行仿真测试:(1) MNIST,由250个不同的人手写数字0,1,...,9构成;(2) Fashion-MNIST,由10个不同类别的28像素 × 28像素的灰度图像组成;(3) CIFAR-10,由10个物品类别的32×32的3通道彩色RGB图片组成。每个数据集中70%的数据用于训练分类预测模型,30%的数据用于测试其预测准确率。将训练集数据平均分配给每个用户设备,并设置非独立同分布程度D来刻画每个用户设备数据的不同用户特性或者地理区域特性。D = 0表示每个子区域的训练样本均匀地包含所有分类标签,D ∈(0,1)表示所有数据均匀地属于D个标签,D = 1表示每个子区域设备上的所有数据只属于一个标签。
本文使用4种优化整体奖励的算法进行对比实验:(1) P-MADDPG,将优先级经验回放缓存技术引入 MADDPG算法,所有无人机共用一个优先级缓存;(2) P-DDPG,将优先级经验回放缓存技术引入 DDPG算法,所有无人机分布式地训练各自的actor网络和critic网络,它们之间不共享信息,并且每个无人机上都设置分布式缓存;(3) GREEDY,列出每个时隙每个无人机所有可能的动作,在其中选择执行使整体奖励最优的动作(其搜索空间庞大和实现复杂度高,难以在实际应用中部署);(4) RANDOM,每个无人机在每个时隙随机地产生动作,包括飞行方向、飞行距离、通信决策和卸载决策。
4.3 实验结果
4.3.1 基于联邦学习的预测模型效果分析
图2展示了本文提出的基于联邦学习的PDMADDPG算法在不同的数据集和D = [0, 0.5, 1,2]的预测准确率的表现。随着用户设备数据的非独立同分布程度的增加(从0到1),预测准确率变差,并且收敛速度变慢。这是因为非独立同分布程度的增加导致每个用户设备中的数据标签种类变少。虽然某一种标签的样本数量会相对增加,但是多样性的降低会使得本地模型更加偏向于预测某几种标签的样本。对于全局模型而言,非独立同分布程度越大,本地模型就越发散。聚合发散的本地数据集会使模型性能变差,并使收敛回合数增加。只有当收集了足够多的样本标签后,全局模型的预测准确率才会逐步提高直到收敛。
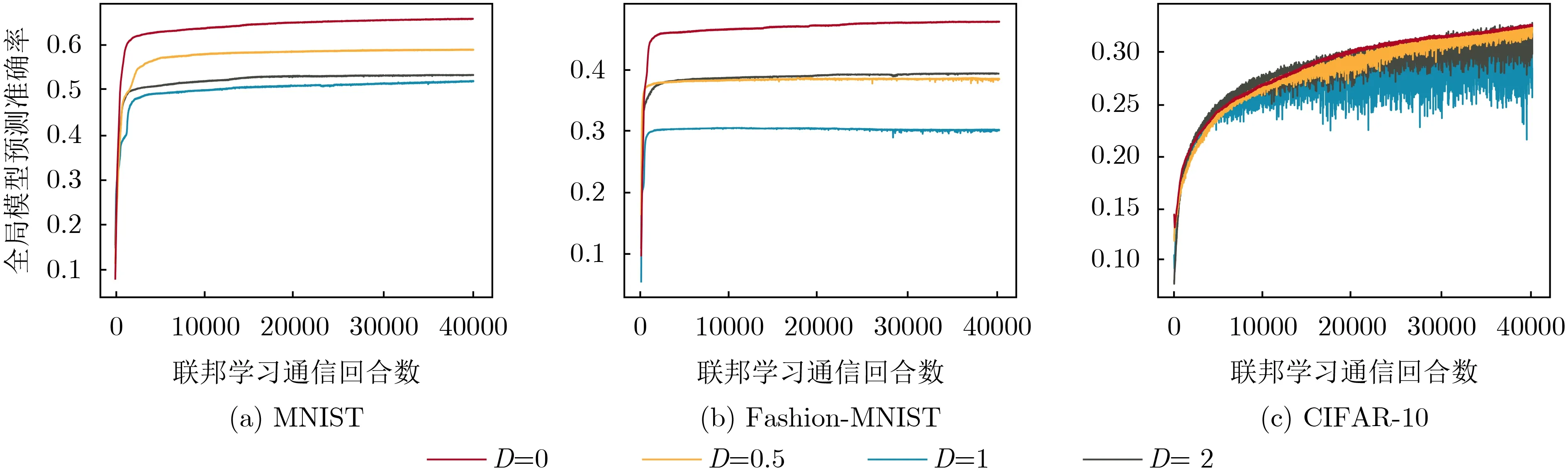
图2 PD-MADDPG 算法的全局模型预测准确率
表4展示了PD-MADDPG与4种对比算法在准确率性能上的差异。对不同数据集而言,所有算法的整体性能都会随着数据集的复杂度变大而变差,并且非独立同分布程度的增加会使模型预测准确率下降。其中,PD-MADDPG算法表现最优,预测准确率平均提升了16.3%,这是因为它将奖励分为全局奖励和局部奖励。P-MADDPG, P-DDPG和GREEDY算法整体优化预测准确率、数据AoI、无人机能耗,因此可能会导致优化目标失衡,即为了确保能耗而牺牲准确率。RANDOM算法的动作没有任何策略,其性能是最差的。

表4 各算法在不同数据集的不同非独立同分布程度时的全局模型预测准确率
4.3.2 算法收敛性和可分解奖励分析
图3是在MNIST数据集中D = 2时的算法奖励变化。在图3(a)中,除GREEDY算法之外,PDMADDPG算法比其余算法的平均总奖励高48.4%,比基于DRL的算法高38.7%。它分别优化全局奖励和局部奖励,因此两者的性能都是最优的,即它能找到最合适的移动、通信和卸载决策,使得奖励在优化无人机能耗、数据AoI及预测准确率之间找到较好的平衡。当设置较小的局部奖励权重µ2时,总奖励的收敛性主要受全局奖励的影响,因此两者的收敛性非常相似,如图3(b)所示。在该设置中,GREEDY算法偏向选择使全局奖励更大的动作。RANDOM算法中无人机会任意地移动并通信,因此数据新鲜程度普遍较高,全局奖励较高。PDMADDPG算法通过全局critic网络来优化全局奖励,使得无人机执行有利于维持数据新鲜程度和预测模型准确率的动作,它比基于DRL的算法的平均全局奖励高37.1%。在图3(c)中,PD-MADDPG算法是最优的,因为无人机分布式actor网络的优化同时受全局critic网络和局部critic网络的影响,并且无人机之间是通过相互协作来进行决策的。它比所有算法的平均局部奖励高66.2%,比基于DRL的算法高48.3%。
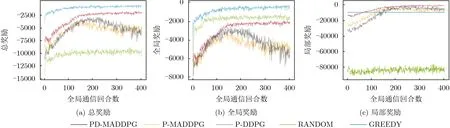
图3 在 MNIST 数据集中D = 2时各算法奖励的变化
4.3.3 基于实时联邦学习的协作式无人机计算系统的规模可扩展性分析
当无人机数量和通信范围不变时,以MNIST数据集中D = 0.5为例,本文绘制了目标区域边长为5, 10, 15和20时,各算法在收敛后100个回合内平均总奖励的变化,如图4所示。当区域规模增大时,无人机服务的用户设备增多,在保证预测准确率和区域数据新鲜度的前提下,它的移动能耗增加,因此所有算法的平均总奖励都减少。其中,PD-MADDPG算法的平均总奖励的下降速率最慢,比所有算法的下降速率慢38.6%,比基于DRL的算法的下降速率慢23.5%。这说明本文提出的算法受区域变化的影响程度最小,无人机能找到更合适的协作方式,在保证其他优化目标的前提下减少无人机的移动能耗,因此其可扩展性是最好的。
GREEDY算法在每次迭代中遍历所有可能的动作从而执行使整体奖励最优的决策。但是这将产生额外的运行能耗,而该能耗是算法运行代价。本文在能耗建模时更关注多无人机执行决策时产生的通信开销,因此没有在优化目标中考虑算法运行能耗,而是最小化无人机能耗。具体地,GREEDY算法的计算复杂度为O(aN·M),其中a是问题的动作空间。一次迭代中,GREEDY 算法耗时202.04 s,PD-MADDPG算法耗时20.13 s,这说明GREEDY算法的时间复杂度比PD-MADDPG算法的高约10倍。由图4可知,仅当目标区域规模增加时,GREEDY算法的平均总奖励下降得比PD-MADDPG算法快,目标值之间的差距逐渐加大。随着动作变量和空间规模变大,GREEDY算法的复杂度呈指数级增加,因此其可扩展性是最差的。

图4 平均总奖励随目标区域规模的变化
5 结束语
本文主要研究了在实时边缘数据处理场景中,以无人机作为边缘服务器,通过智能地进行轨迹规划、通信决策和卸载决策来实现模型预测高准确率、高数据新鲜程度和低无人机能耗的优化问题。考虑到用户设备数据的实时性、隐私性和规模有限性,本文引入联邦学习在无人机上执行本地训练,然后聚合为全局模型,通过多轮迭代获得共享的预测模型。为了解决该多目标优化问题,本文设计了一种全局奖励和局部奖励融合的多智能体深度强化学习的算法,动态地进行多无人机的轨迹规划以及任务卸载和通信决策。最后,大量的仿真实验结果表明本文的PD-MADDPG算法的优越性,验证了所设计的系统和算法的合理性、有效性和可拓展性。
