旅游领域实体和关系联合抽取方法研究
2022-09-21古丽拉阿东别克马雅静
陈 赟,古丽拉·阿东别克,马雅静
1.新疆大学 信息科学与工程学院,乌鲁木齐830017
2.新疆多语种信息技术实验室,乌鲁木齐830017
知识图谱(knowledge graph)是以图的形式表现客观世界中的实体(概念、人、事物)及其之间关系的知识库[1]。知识图谱于2012 年5 月17 日被Google 正式提出[2],其目的是优化搜索引擎性能,提升用户的搜索质量以及搜索体验。国内垂直领域的知识图谱进展较快的多为金融领域和医疗领域的项目,旅游领域涉及较少。通过构建旅游领域的知识图谱并结合智能问答、个性化推荐等上层应用,可以促进旅游行业智能信息服务技术的快速发展,从而带来更高的经济效益。
知识图谱中的数据通常以“实体-关系-实体”或“实体-属性-属性值”的关系三元组存储,形成一个图状知识库,因此从非结构化文本信息中抽取关系三元组是构建知识图谱的关键任务。而旅游领域的文本信息中存在着大量的实体嵌套和关系重叠现象,例如表1文本中包含的以(subject,predicate,object)形式的关系三元组有[(杭州西湖风景区,所在城市,杭州),(杭州西湖风景区,著名景点,苏堤春晓),(苏堤春晓,所属景区,杭州西湖风景区),(苏堤春晓,所在城市,杭州)]。

表1 旅游领域关系重叠样例Table 1 Sample relation overlapping in tourism domain
在实体抽取过程中,其中作为景点名称的实体“杭州西湖风景区”中嵌套作为城市名称的“杭州”,Luo 等人[3]提出基于注意力机制的Att-BiLSTM-CRF模型进行化学领域命名实体识别,使用B/I/O 标签加实体类型来区分实体的开头、中间和结尾或者判断是否为实体。这种命名实体识别的方法无法将实体“杭州西湖风景区”中的“杭”同时标注为景点名称的开头和城市名称的开头,因而无法解决实体嵌套问题。
在关系抽取的过程中,表1 中文本包含EPO(entity pair overlap)和SEO(single entity overlap)两种关系重叠形式。其中,EPO 是指句子中至少有两个关系三元组,并且至少有两个关系三元组以相同或者相反的顺序共享一对实体;SEO 是指句子中有多个关系三元组,并且至少有两个关系三元组共享一个相同的实体。由于管道抽取模型存在误差积累和实体冗余会造成模型性能大幅下降,不能够有效处理关系重叠问题。Zheng等人[4]提出的联合抽取模型将问题转化为序列标注问题,生成标注序列后将关系标签合并为实体三元组时采用就近组合的方法,虽然能够从句子中抽取出多种关系,但并不能处理实体出现重叠的关系抽取问题。
由于目前联合抽取的方法并不能有效地处理信息抽取任务中实体嵌套和关系重叠的问题,本文提出了BAMRel 模型(joint extraction model based on biaffine attention mechanism)。模型的主要特点是通过共享参数使用Biaffine 模型分别构建边界注意力矩阵和关系注意力矩阵来解决实体嵌套和关系重叠问题,同时将实体标签作为特征融入关系抽取部分,在构建的旅游领域关系抽取数据集TFRED(tourism field relation extraction dataset)上和公开数据集上均取得了较好的实验结果。
综上所述,本文的贡献主要有以下三点:
(1)基于远程监督的思想,利用结构化三元组进行数据回标,构建了包含近2万个关系三元组的旅游领域关系抽取数据集TFRED。构建流程和部分数据开源在:https://github.com/chenyun-lh/TFRED,后续将持续对数据量进行扩充。
(2)提出BAMRel 模型,共享BERT 编码参数的同时,实体抽取和关系抽取部分共用Biaffine 模型来分别解决实体嵌套和关系重叠问题,降低了联合抽取模型的复杂度,提供了一种不仅限于旅游领域的简洁高效的模型方案。
(3)进行实验严格论证了实体标签作为特征对关系抽取结果的影响,并量化了影响程度。
1 相关工作
目前关系三元组的抽取方法主要分为管道抽取方法和联合抽取方法。管道抽取方法是将关系三元组的抽取作为实体识别和关系抽取两个独立的子任务进行,本章将介绍管道抽取方法的两个子任务和联合抽取方法的相关工作。
1.1 命名实体识别方法
早期命名实体识别(named entity recognition,NER)方法主要是基于规则的方法。基于规则的系统依赖于手工制定的规则,无法转移到其他领域。后来产生了基于机器学习的命名实体识别方法,NER任务被转换为一个分类问题或序列标注问题,这类方法降低了人工成本,但依赖于特征工程。近年来,基于深度学习的NER模型占据了主导地位,与基于机器学习的方法相比,深度学习有利于自动发现隐藏的特征无需人工构建特征。Dong 等人[5]提出使用BiLSTM-CRF 来进行中文命名实体识别,在NER 任务中有很好的表现。2018 年谷歌提出BERT 预训练模型[6],通过微调的方法可以灵活应用到各项NLP任务中,所以在实体识别任务中将BERT作为编码层的模型会成为性能很强的基线模型[7-9]。
但是在中文NER 任务中,基于序列标注框架并不能解决实体嵌套问题。针对实体嵌套的问题,Jia等人[10]提出通过动态地堆叠基于序列标注的实体识别层来识别嵌套实体,每一层的模型参数及其输入是完全独立的,因而嵌套实体识别过程不会受到其他层的干扰。Fu等人[11]提出部分观察树TreeCRF方法,将嵌套实体识别过程视为部分观察树的选区分析,用统一的方式对观察树中观察实体和潜在实体联合建模。Shen 等人[12]针对包含嵌套实体的长实体识别提出两阶段识别方法,首先对生成的可能实体边界进行过滤和边界回归,然后对边界调整后的实体边界标注相应的类别。指针网络(PointerNet)最早应用于机器阅读理解(machine reading comprehension,MRC)中,Li 等人[13]基于该思想构建问题指代所要抽取的实体类型,引入了先验语义知识,使用单层指针网络来解决实体嵌套的问题。多标签指针网络由单层指针网络衍生而来,如图1所示多标签指针网络使用n个(n为实体类型数量)二元指针网络进行嵌套实体识别。Yu 等人[14]使用双仿射变换构建三维矩阵,把实体抽取任务看成为识别实体开始与结束位置索引的问题,同时对这个开始与结束位置形成的实体边界(span)赋予类型。

图1 多标签指针网络嵌套实体识别Fig.1 Multi-label pointer network nested entity recognition
1.2 关系抽取方法
在管道抽取方法中,早期的关系抽取方法主要是基于模板匹配的方法,此类方法适用于小规模特定领域,召回率低、可移植性差。后来出现了半监督学习的关系抽取方法,主要有bootstrapping和远程监督方法。远程监督方法基于一个很强的假设,如果一个实体对满足某种给定关系,包含该实体对的句子都在阐述该关系。但很多包含该实体对的句子并不代表此种关系,会引入大量噪声。为了缓解这一问题,研究者采取了多示例学习[15-18]、强化学习[19]和预训练机制[20]等改进策略。
目前主流监督学习的关系抽取方法是基于深度学习的方法,Soares 等人[20]基于BERT 模型采用多种不同结构来进行实体对的特征提取进行关系分类,但该方法会对同一个句子进行重复编码,耗费计算资源。为了解决该问题Wang等人[21]将多次关系抽取转化为同时抽取问题,将句子一次输入进行多个关系分类。Kong等人[22]针对在管道抽取方法中的歧义实体和词典信息融入到字符信息丢失的问题提出一种在嵌入层自适应地包含词信息的方法,利用词典将所有匹配每个字符的词合并到一个基于字符输入的模型中,以此来提高实体准确率减少误差传播。Wang等人[23]提出了一种基于图卷积神经网络的关系抽取模型,该模型将上下文感知模型与以依赖树为特征的加权图卷积网络模型相结合,融合了上下文和相关的结构信息,并将剪枝策略应用于输入树删除冗余信息。
1.3 联合抽取方法
为了解决实体识别的误差传递问题,研究者提出联合抽取的方法。早期出现了基于特征的联合抽取方法[24-27],这种方法需要人工设计特征,因此需要大量工作对数据进行预处理。Miwa等人[28]首次将神经网络模型用于解决实体关系联合抽取任务,通过共享参数的方法将两个任务整合到同一个模型当中,但两个任务仍然是分离的过程,产生大量的冗余信息。为了解决该问题,Zheng 等人[4]设计了一种新颖的标注方法,这种方法对实体和关系同时抽取,将抽取问题转化成为了标注任务,通过使用神经网络来建模,避免了复杂的特征工程。目前,如何解决关系抽取任务中的关系重叠问题成为了研究热点,主要的方法有基于图神经网络方法和注意力机制的方法。在基于图神经网络的方法中,Fu等人[29]提出了一种基于图卷积网络(GCN)的端到端联合抽取模型GraphRel,该模型利用图卷积网络联合学习命名实体和关系。Fei等人[30]将复杂的重叠情抽取任务视为一个多重预测问题,使用图注意模型对实体之间的关系图进行建模。Zhao 等人[31]提出了一种基于异构图神经网络的表示迭代融合关系抽取方法,将关系和词建模为图上的节点,并通过消息传递机制来得到更适合关系抽取任务的节点表示。在基于注意力机制的方法中,Liu等人[32]提出了一种基于注意力的联合关系抽取模型,该模型设计了一种有监督的多头自注意机制作为关系检测模块,分别学习每种关系类型之间的关联来识别重叠关系和关系类型。Lai等人[33]提出了一种基于序列标注的联合抽取模型,该模型在句子编码信息之后添加多头注意力层以获得句子和关系的表征,并对句子表示进行序列标注来获得实体对。Geng 等人[34]采用卷积运算得到字级和词级的嵌入,并传递给多头注意机制。然后使用多头注意机制对上下文语义和嵌入进行编码,得到最终的标签序列。Nguyen等人[35]使用BiLSTM对句子进行编码,在关系抽取部分使用双仿射注意力机制来解决关系重叠问题,在CoNLL04 数据集上验证了双仿射分类器比线性分类器的显著优势,但该模型的标注框架无法解决中文领域嵌套实体的关系抽取问题。
2 模型介绍
BAMRel 模型主要思路是共享BERT 编码层,将编码层信息共用于实体抽取和关系抽取部分。在实体抽取部分利用BERT 最后两层编码信息进行全连接层降维来分别表示实体的头部信息和尾部信息,然后使用双仿射注意力机制进行分类,形成对实体边界span及标签类型type 的界定;在关系抽取部分,实体类型作为较强特征,对实体抽取部分得到的实体标签类型进行嵌入,与BERT 最后两层降维后的编码信息进行拼接分别表示分别关系三元组中主体subject和客体object信息,然后将编码信息引入biaffine 模型构建关系矩阵,最后利用实体边界信息解码形成对关系三元组(subject,predicate,object)的抽取。
本文提出的BAMRel 模型整体结构图如图2 所示,模型从功能上可以分为句子编码层、实体抽取层和关系抽取层三个部分。接下来将对这三个部分进行介绍。

图2 BAMRel模型的整体框架Fig.2 Overall framework of BAMRel model
2.1 句子编码层
BERT(bidirectional encoder representation from transformers)[6]是一种自然语言处理预训练语言表征模型,通过预训练和微调可以解决多种NLP的任务,推动了自然语言处理的发展。BERT 的结构是来自于Transformers模型的Encoder 部分,内部结构由Self-Attention Layer和Layer Normalization 堆叠而产生。针对传统预训练模型无法并行处理句子编码、一词多义和预训练向量一成不变等问题,BERT 模型加入了位置编码(positional encoding)和多头自注意力机制(self-attention)来解决上述问题,使得预训练模型性能得到了极大的提升,并在多个任务中广泛应用。
如图3 所示,BERT 模型输入包括三个部分,分别为字或词嵌入(token embedding)、片段嵌入(segment embedding)和位置编码嵌入(position embedding)。由于片段嵌入是为了在需要判断两个句子之间关系的任务中区分两个句子信息,故在关系抽取任务中不适用片段嵌入。将句子x通过分词器得到分词后的序列X,X=(x1,x2,…,xn),然后将X编码成一个字嵌入矩阵We和位置嵌入矩阵Wp,将两个向量相加得到输入的向量E=(E1,E2,…,EN),如式(1)所示,然后将向量E通过第一层和第N层的Transformer网络得到文本的向量表示H1和HN,分别如式(2)和式(3)所示:

图3 BERT模型结构图Fig.3 Structural diagram of BERT model

其中,HN为句子经过第N层Transformer 网络进行编码后的输出。本文将包含有不同语义信息的BERT 最后两层编码层作为共享编码层,即HN-1和HN层。
2.2 实体抽取层
实体抽取层完成命名实体识别(NER)任务,最常见的标注方式是序列标注,但在信息抽取任务中已经无法解决实体嵌套、类型混淆等复杂抽取问题。旅游领域信息抽取实体嵌套标注样例如表2所示。

表2 旅游领域实体嵌套标注样例Table 2 Sample nested annotation of entities in travel domain
首先将BERT最后两层编码信息HN-1和HN进行拼接得到包含有不同特征的句子表示x,然后使用两个单独的全连接神经网络对特征降维,分别创建span不同表示的起点hs和终点he。
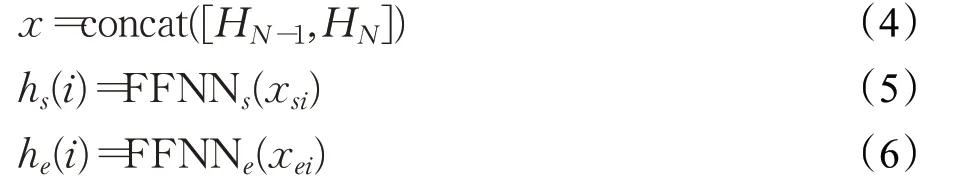
其中,si和ei分别是实体i的span开始和结束的位置索引。与直接使用BERT模型的输出相比,这样处理得到的实体的开始和结束的上下文是不同的,为双仿射变换提供了更准确的信息。最后,在句子上使用双仿射模型创建维度l×l×c评分函数rm,其中l为句子长度,c为实体类型种类数+1(一种非实体类型),如式(7)所示:

其中,Um对hs(i)为头he(i)为尾的实体类别后验概率建模,维度为d×c×d;Wm对hs(i)为头或he(i)为尾的实体类别后验概率分别建模,维度为2d×c;bm为偏置,对类别为c的先验概率建模。
通过计算rm就可以得到在满足si≤ei条件的所有实体所有可能的标签类型分数,并对任意实体span赋予分类标签y:

然后类别分数rm对所有可能的span进行降序排列。最后设定阈值,对第i种实体类别标签分数y(i)大于阈值的位置进行解码。
此任务是一个多分类问题,在softmax 激活函数之后使用交叉熵损失函数对模型进行优化,实体抽取部分损失函数Lner如下:
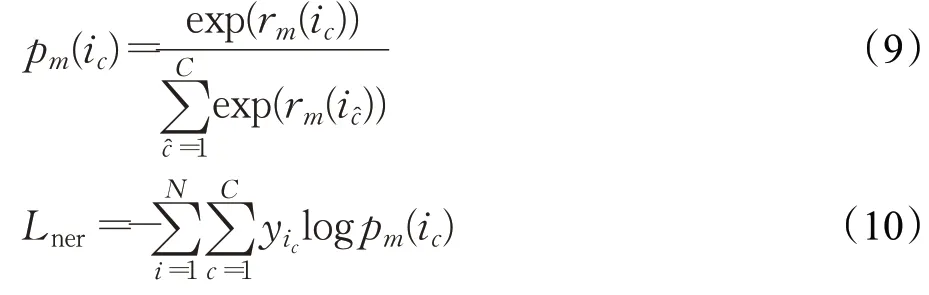
2.3 关系抽取层
首先将共享编码层x经过两个前馈神经网络分别得到主体(subject)和客体(object)的特征表示s(i) 和o(j),目的是将高维度包含丰富信息的编码层通过全连接神经网络降为只包含关系依赖信息的低维度的特征,这样可以加速训练,同时防止过拟合。第i个主体和第j个客体向量表示为:

其中,si和oj分别是主体和客体位置索引。同时实体抽取部分得到的实体标签进行标签嵌入转化为特征向量ce,分别与s(i)和o(j)进行concat连接,然后得到了包含关系依赖信息和实体标签信息的主体token 序列S(i)和客体token序列O(j)。实体标签融合后第i个主体和第j个客体向量表示为:

其中,ei和ej分别是实体和客体实体类型标签的位置索引。目标是为主体S(i)每个tokenSi(i)识别出和每个客体Oj(j)的组合最可能对应的关系标签rk,最后S(i)和O(j)的token序列进行双仿射变换后构建出维度为l×l×r的Attention 矩阵,其中l为句子长度,r为关系类型数。计算给定关系标签rk的tokenSi(i)和Oj(j)之间分数的公式如式(15):
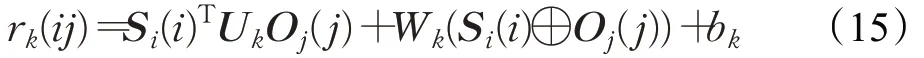
其中,Uk对Si(i)为主体Oj(j)为客体关系类别后验概率建模,维度为d×r×d;Wk对Si(i)为主体或Oj(j)为客体的关系类别后验概率建模,维度为2d×r;bk为偏置,对类别关系为r的先验概率建模。
使用sigmoid 激活函数对主体Si(i)选择Oj(j)作为它们之间具有关系标签rk的客体的概率进行计算,计算如公式(16):

然后设置阈值,对于在某种关系类型下概率值超出阈值的组合标记为1,其他标记为0。最后对标记为1的位置进行解码。
使用交叉熵损失函数对关系抽取损失进行计算,关系抽取部分损失函数Lrel如式(17):
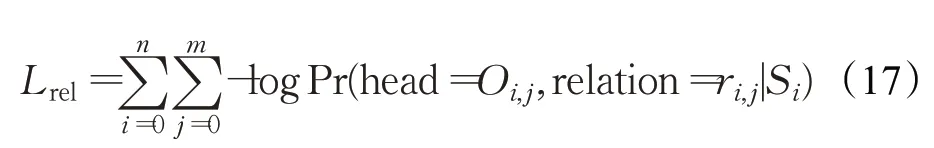
对于联合实体和关系的抽取任务,最终的损失函数定义为:

2.4 解码方式
实体抽取部分,设置阈值的为0.5。由2.2 节可知,图2 中输入文本使用双仿射模型创建维度l×l×c评分函数rm,第一个维度l表示实体的开始位置,第二个维度l表示实体的结束位置,第三个维度c表示实体类型编号。经过实体抽取层计算则有:在实体类型为“景点名称”的标签上经过降序排列后有rm(0,6,1)>0.5,rm(9,12,1)>0.5,即实体类型为“景点名称”的实体有“杭州西湖风景区”和“苏堤春晓”;在实体类型为“城市名称”的标签上经过降序排列后有rm(0,1,2)>0.5,即实体类型为“城市名称”的实体有“杭州”。通过解码可得到实体列表[“杭州”“杭州西湖风景区”“苏堤春晓”]。图4 为嵌套实体“杭州西湖风景区”使用Biaffine机制构造的Span矩阵。

图4 Biaffine机制构造的Span矩阵Fig.4 Span matrix constructed by Biaffine mechanism
关系抽取部分,设置阈值为0.5。由2.3节可知,图2中输入文本经过实体抽取层将实体类型信息融入到共享的句子编码信息中,然后使用双仿射模型创建维度l×l×r评分函数rk,第一个维度l表示主体(subject)最后一个字符的位置,第二个维度l表示客体(object)最后一个字符的位置,第三个维度r表示关系类型编号。经过关系抽取层计算则有:σ(rk(6,1,1))>0.5,σ(rk(6,12,2))>0.5,σ(rk(12,1,1))>0.5,σ(rk(12,6,3))>0.5,如图2关系抽取部分所示,这些位置在对应关系位置上均被标注为1。
最后,结合实体列表和关系编号列表即可完成对含有嵌套实体的关系三元组[(杭州西湖风景区,所在城市,杭州),(杭州西湖风景区,著名景点,苏堤春晓),(苏堤春晓,所在城市,杭州),(苏堤春晓,所属景区,杭州西湖风景区)]的抽取。
3 实验与分析
3.1 实验数据集介绍
由于旅游领域暂无公开的实体和关系抽取联合任务的数据集,本文综合考虑结构化关系三元组中景点信息缺失程度和旅游领域文本信息中出现频次,定义了实体类型和关系类型。结构化三元组和文本信息主要爬取自百度百科和去哪儿、携程、马蜂窝等垂直旅游网站,然后基于远程监督的思想,利用结构化三元组对文本信息进行回标,辅助构建数据集,最终构建了旅游领域关系抽取数据集TFRED(tourism field relation extraction dataset),句子条数共计10 604 条,包含嵌套实体句子1 166 条,约占数据集11%。每条句子包含一种或多种关系,句子中的关系三元组共计18 480 个。训练集、验证集、测试集按照8∶1∶1 比例分割,数据集详细统计信息如表3所示。

表3 TFRED数据集详细统计Table 3 Detailed statistics of TFRED dataset
为了验证模型改进策略的有效性和BAMRel 模型的鲁棒性,在公开的中文关系抽取数据集DuIE[36]上进行验证。DuIE数据集包含45万个实例、49种常用关系类型、32 种实体类型、34 万个关系三元组、21 万条句子。该数据集包含大量重叠关系,因此基于该数据集可以对模型重叠关系抽取能力进行评估。
3.2 实验环境及参数设置
本文模型使用的GPU 为GeForce RTX 2080Ti,编程语言为Python3.7,深度学习框架为tensorflow2.0。本文使用模型对句子长度进行了限制,最大句子长度为128,训练过程中batch_size 大小为16,使用初始学习率为1E-5的Adam优化器在训练集上学习100轮,在验证集上获得最佳F1 值模型,并在测试集上得到实验结果。模型实体抽取部分和关系抽取部分共享编码层后连接的前馈神经网络维度均为128,使用的激活函数均为relu。在关系抽取部分嵌入的实体标签维度为16,使用Dropout 大小为0.2 来加快训练速度和防止过拟合。实体抽取部分使用softmax 多分类交叉熵损失函数,关系抽取部分使用sigmoid 二分类交叉熵损失函数,两部分阈值设置为0.5,该阈值通过实验进行搜索得到。
3.3 对比模型介绍
为了验证BAMRel模型的有效性和鲁棒性,本文选取了以下主流的联合抽取模型和相关改进模型进行对比实验。
(1)Multi-head[37]:使用BiLSTM作为共享编码器,在实体识别部分使用条件随机场解码,将实体类型信息融合到关系抽取过程中,并把关系抽取转化为一个多头选择的问题。
(2)BERT+Multi-head:将Multi-head 中的BiLSTM替换为BERT编码器。
(3)Multi-head(Ptr-Net):将Multi-head中的BiLSTM替换为BERT 编码器,同时为了解决实体嵌套问题,将基于条件随机场的解码方式替换为多标签指针网络。
(4)CasRel[38]:提出一种用于解决关系重叠问题的级联式二元标注框架,使用BERT 作为句子编码器,将关系建模为将句子中的主语映射到宾语的函数,使用多层关系标签的指针网络进行解码。此方案中对于每组文本数据,分别抽取其所有不同的S(Subject)以及其相关的PO组成多组数据进行训练。
(5)CasRel*:将CasRel模型训练方式更改为每组文本数据仅随机抽取一个S(Subject)以及其相关的PO构建成一组数据的方式进行训练。
(6)CopyMTL[39]:一种基于复制机制编码器-解码器结构的联合关系抽取模型,Encoder 部分使用BiLSTM建模句子上下文信息,Decoder 部分则结合复制机制生成多对三元组。
(7)WDec[40]:一个主要解决关系重叠问题提出的编码器-解码器结构的联合关系抽取模型,在实体识别的过程中使用掩码机制,然后根据实体识别结果进行字解码。
(8)Seq2UMTree[41]:为了解决序列到序列模型在解码过程中曝光偏差问题提出一种新的序列到无序多树的联合抽取模型,解码器部分使用一个简单的树形结构来生成三元组。
(9)FETI[42]:一种新的融合头尾实体类型信息的联合抽取模型,在解码阶段增加了头尾实体类别的预测,并通过辅助损失函数进行约束。
(10)Biaffine(NER):将Multi-head(Ptr-Net)实体抽取部分的多标签指针网络替换为双仿射分类器进行嵌套实体识别,关系抽取部分使用多头选择机制进行重叠关系抽取。
(11)Biaffine(RE):将Multi-head(Ptr-Net)关系抽取部分的多头选择机制替换为双仿射分类器进行重叠关系抽取,实体抽取部分使用多标签指针网络进行嵌套实体识别。
3.4 评价指标
实体抽取部分和关系抽取部分评价指标都使用准确率(P),召回率(R)和F1 值,公式参数定义如下:TP为正确识别的个数,FP 是识别出的不相关的个数,FN是数据集中存在且未被识别出来的个数。
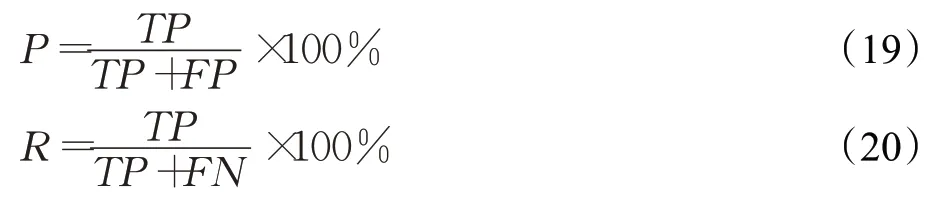
通常精确率和召回率的数值越高,代表实验的效果好,然而有时精确率越高,召回率越低。所以需要综合考量加权调和平均值,也就是F1值,F1值定义如下:

在本实验中,采用严格的评价指标,即如果实体的边界和类型都是正确的,则认为该实体识别是正确的;当关系的类别和头尾实体都正确时,则认为抽取的关系是正确的。
3.5 实验分析
3.5.1 非嵌套实体联合抽取对比实验
由于主流的联合抽取模型无法解决包含嵌套实体的重叠关系抽取问题,故将TFRED 数据集筛选出不包含嵌套实体的句子进行对比实验。为了验证模型的有效性鲁棒性,同时也在不包含嵌套实体的百度DuIE 数据集上进行了对比实验,实验结果如表4所示。

表4 非嵌套实体联合抽取实验结果Table 4 Results of non-nested entity joint extraction experiments
实验结果显示,BAMRel模型在自行构建的TFRED数据集和公开数据集DuIE 数据集上的表现均优于主流的联合抽取模型,体现了模型在更加复杂场景中的鲁棒性和有效性。其中基线模型CopyMTL、WDec、Seq2UMTree 实验结果均来自于文献[41]中的结果,FETI 选择F1 值最高的解码顺序。从TFRED 数据集上的实验结果来看,Multi-head 的多头选择机制在使用BERT 作为编码器后关系抽取结果提升了0.053,而BAMRel 模型比BERT+Multi-head 模型实验结果高出0.012。这是由于使用双仿射注意力机制构建的分类矩阵拥有更多的参数,且乘性方法相比于Multi-head的多头选择机制能捕捉到Subject 和Object 特征之间的交叉关系,而Multi-head 则是通过简单的线性变化进行组合。CasRel 模型由于设计原因对于每组文本数据每次只能传入一个S(Subject)和其相关的PO 进行训练,而存在重叠关系的复杂句子中可能主语不同,因此对每条文本遍历所有不同主语(S)的标注样本构建训练集比随机选择S更能增加模型的鲁棒性,因此CasRel比CasRel*的实验结果高了0.012。
从DuIE数据集上的实验结果来看,CopyMTL、WDec、Multi-head 等模型的准确率要高于召回率0.01~0.015,这是由于模型对句子包含多种关系三元组时抽取能力不足造成的,这类模型不适用于更加复杂的关系抽取场景。而Multi-head 改进后的Multi-head(Ptr-Net)在缓解了高准确率低召回率的情况下模型性能提升了近0.01,体现了预训练模型对模型性能提升产生的巨大影响。Seq2UMTree 和FETI 模型都是基于编码器-解码器的模型,但FETI在解码过程中融合了实体类型信息,F1值比Seq2UMTree提升了0.015,说明了实体类型信息对关系抽取结果提升具有促进作用,侧面说明了BAMRel模型融合实体类型信息进行关系抽取的合理性和有效性。CasRel 模型使用多层标签指针网络巧妙地将关系的预测隐性的放在了尾实体的抽取过程中,结合预训练模型BERT 在两个数据集上取得了较高的F1 值。忽略模型本身设计方面的差异,解码时CasRel的多个二元指针网络使用的是简单的线性分类器,而本文BAMRel模型在实体抽取部分和关系抽取部分都使用双仿射分类器。双仿射分类器构建的注意力矩阵能够使实体识别过程中开始位置token和结束位置token产生信息交互,同时能够捕捉到关系抽取时头尾实体特征之间的交叉关系而提升实验结果,因而BAMRel 模型F1 值在TRFED数据集和DuIE 数据集上比CasRel 模型分别高出0.006和0.004。
3.5.2 嵌套实体联合抽取对比实验
本文首先将Multi-head[37]联合抽取模型应用于中文关系抽取,并针对其无法对句子中包含嵌套实体的关系进行抽取和抽取性能欠佳进行了改进,表5为一系列改进策略在包含嵌套实体的TRFED数据集上进行的对比实验。在进行实体标签类型嵌入时存在两种方案。第一种方案是头尾实体的所有token信息都与实体类型信息进行拼接,第二种方案是只对头尾实体最后一个字符的token信息与实体类型信息进行拼接,其余的token实体类型都编码为0,这两种改进方案分别对应表5 第一组对比实验标签全部嵌入(All)和标签部分嵌入(Part)。从此实验结果来看,在实体识别结果差异不大的情况下,头尾实体部分标签嵌入比全部标签嵌入F1 值高了0.007,显然第二种方案更适合关系抽取方式,只对头尾实体的最后一个字符传入实体类型信息在不会造成信息丢失的情况下增加了实体内token 信息的区分度,有利于头尾实体之间关系的判断。

表5 嵌套实体联合抽取实验结果Table 5 Results of nested entity joint extraction experiments
Biaffine(NER)与Multi-head(Ptr-Net)相比,实体识别F1 值提升了0.009,同时关系抽取F1 值提升了0.005。Biaffine(RE)与Multi-head(Ptr-Net)相比,实体识别F1 值与Multi-head(Ptr-Net)模型保持不变的情况下,关系抽取F1 值提升了0.011。原因是双仿射分类器比线性分类器拥有更多的参数,且能捕捉到特征之间的交叉关系,从而提升实验结果。可以将表5中的第二组实验看作BAMRel模型对双仿射注意力的消融实验,在Multi-head(Ptr-Net)模型上验证了使用双仿射注意力机制构建分类矩阵的优越性。BAMRel 模型在实体抽取部分和关系抽取部分共用Biaffine模型,最终在TFRED数据集上F1 值达到了91.8%,关系抽取F1 值比基础模型提升了0.017。
3.5.3 BAMRel模型实体和关系抽取能力评估
为了进一步验证BAMRel 模型从包含不同三元组数量的句子中对实体识别和关系抽取的能力,将TFRED数据集分成了5 类,表6 显示了从不同三元组数量的句子中识别实体和关系抽取的能力。
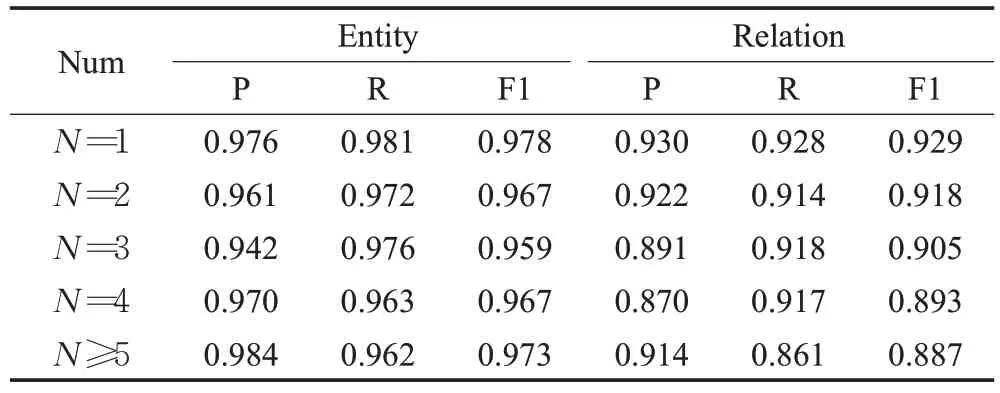
表6 BAMRel模型实体和关系抽取能力评估结果Table 6 Evaluation results of BAMRel model entity and relation extraction capabilities
从表6中实体识别结果可以发现,在包含不同关系数量的句子上实验结果表现出较大差异性。分析其原因是由于每个句子中都可能存在没有预定义关系的实体,但在进行实体识别时都将其识别了出来因而产生误差。联合抽取模型在数据标注时只标注了有预定义关系的头尾实体,而句子中不同程度存在无关系实体,例如标注样例:{"text":"青岛海军博物馆,东邻鲁迅公园、西接小岛公园与栈桥隔水相望、南濒一望无际的大海、北面是著名景点信号山公园,占地4 万多平方米。","spo_list":[{"predicate":"所在城市","object":"青岛","subject":"青岛海军博物馆","object_type":"城市","subject_type":"景点"},{"predicate":"占地面积","object":"4万多平方米","subject":"青岛海军博物馆","object_type":"Number","sub-ject_type":"景点"}]}
在此样例中标注的实体只有“青岛海军博物馆”“青岛”“4万多平方米”,其中城市“青岛”为嵌套实体,而在句子中还存在未被标注的“鲁迅公园”“小岛公园”“栈桥”和“信号山公园”无关系实体会被识别出来,因而会造成实体识别结果出现低准确率高召回率的情况。每个测试句子中包含无关系实体不同的数量造成了实体识别结果的差异性。表6 中包含实体嵌套的命名实体识别F1 值均值为0.968,与表4 中不包含嵌套实体的F1值0.967 相差不大,说明BAMRel 较好地解决了实体嵌套的问题。
从表中关系抽取结果可以发现,随着句子中所包含的三元组的数量增加,模型的性能逐步降低。排除关系抽取难度最小(N=1)的情况,句子中关系数量从2增加到5 以上对关系抽取的F1 值仅降低了0.031,意味着模型受到输入句子复杂性增加的影响较小,适合用于从复杂句子中抽取多个有重叠关系的三元组。
3.5.4 实体类型对关系抽取影响评估
本文提出的BAMRel模型和Multi-head[37]模型都将实体类型信息与共享的编码信息融合进行关系抽取。但是实体识别部分设计存在两种方案,第一种是实体识别仅确定实体边界,来减少误差传播。第二种方案是实体识别同时确定实体边界和实体类型,更多的实体标签数量会增加识别难度传播更多的误差,但实体类型标签可作为特征融合到关系抽取过程中得到更好的实验结果。此时无法判断两种方案的优劣和第二种方案中融合实体类型信息对关系抽取结果的影响程度。因此设计了表7 四组对比实验来评估两种方案优劣和实体类型对关系抽取部分的影响。
由于Multi-head 模型使用序列标注方式,无法对嵌套实体进行识别,故将TFRED 数据集筛选出不包含实体嵌套的句子进行对比实验。表7 中对不同模型关系抽取过程中是否融合实体边界信息(Span)和实体类型信息(Type)进行了对比实验。从第一组实验结果中可以看出,实体识别任务同时确定实体边界和实体类型信息的F1 值比只确定边界信息的F1 值降低了0.12,但是在关系抽取的过程中融合实体类型信息的F1值比不融合实体类型信息的F1值高了0.018。图5记录了表7中第一组实验50 个epoch 实验结果(Ner_f1 和Re_f1 分别代表实验中未融合实体类型的实体识别F1值和关系抽取F1 值,Ner_t_f1 和Re_t_f1 分别代表实验中融合实体类型的实体识别F1值和关系抽取F1值),Ner_t_f1在50个epoch 的测试集上的表现一直低于Ner_f1,而趋于稳定的Re_t_f1 却比Re_f1 平均高0.02 左右,因此可以得到以下三点结论:

图5 第一组对比实验结果Fig.5 Results of first set of comparative experiment
(1)在模型评估阶段,实体识别任务在同时确定实体边界和实体类型产生的误差对关系抽取结果的不利影响远小于将实体类型信息将其融合到关系抽取部分对关系抽取结果的有利影响,因此值得牺牲实体识别部分性能确定实体类型信息将其融合到关系抽取部分。
(2)实体识别部分功能设计的两种方案中,融合实体类型信息方案优于另外一种。
(3)Multi-head模型使用BiLSTM作为编码器,在关系抽取部分融合实体类型信息比不融合实体类型信息F1值提升了约0.02。
从表7中的第二组对比实验的结果可以看到,在使用预训练模型的情况下,实体识别任务同时确定实体边界和实体类型信息的F1值比只确定边界信息的F1值只降低了0.005,缩小了两种识别方案的差距,但是在关系抽取的过程中融合实体类型信息的F1值比不融合实体类型信息的F1 值还是高了0.01 左右,同样缩小了关系抽取结果的差距。结合图6第二组对比实验50个epoch在测试集上的表现,依旧满足第一组实验的结论,实体类型信息对关系抽取的影响不可忽视,但是预训练模型弱化了实体类型对关系抽取结果的影响,Re_t_f1 比Re_f1平均高0.01左右。

图6 第二组对比实验结果Fig.6 Results of second comparative experiment
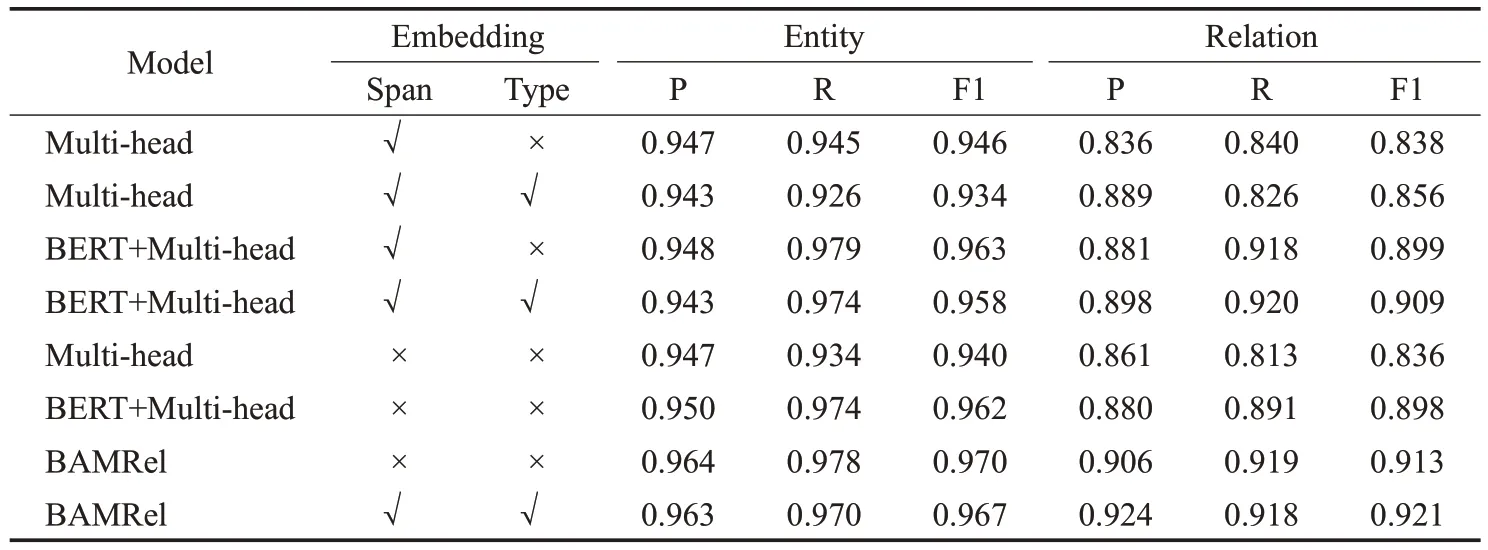
表7 实体类型标签对关系抽取影响评估结果Table 7 Evaluation results of impact of entity type labels on relation extraction
第三组实验是对融合实体边界信息和实体类型信息Multi-head和BERT+Multi-head进行的消融实验。从实验结果来看,在关系抽取过程中不融合实体边界和实体类型信息得到的实验结果与只融合实体边界信息得到的实验结果相差不大。图7和图8分别是两个模型在50个epoch的测试集上的表现(Re_t_f1表示融合了实体边界信息和实体类型信息的关系抽取F1值,Re_u_f1表示未融合实体边界信息和实体类型信息的关系抽取F1值),由图7 图8 可知Multi-head 模型Re_t_f1 比Re_u_f1平均高0.02左右,Bert+Multi-head模型Re_t_f1比Re_u_f1平均高0.01 左右,可以得到结论,实体类型对关系抽取F1 值的影响范围大致在0.01~0.02。最后,设置第四组实验,在BAMRel 模型上验证该结论。从实验结果可知,BAMRel模型融合实体边界和实体类型信息的关系抽取F1 值比高0.008,对模型性能的提升接近这个范围,该结论成立。
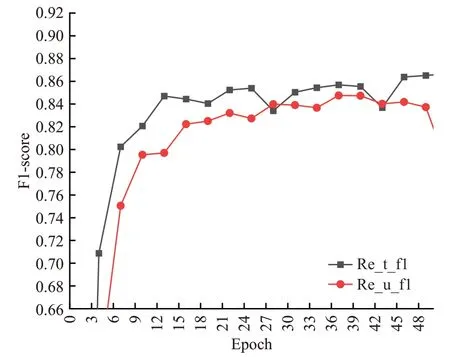
图7 Multi-head消融实验Fig.7 Multi-head ablation experiment

图8 BERT Multi-head消融实验Fig.8 BERT Multi-head ablation experiment
综上所述,在联合抽取模型中,实体类型可作为关系抽取模型的重要特征输入,对关系抽取模型F1 值的提升大致在0.01~0.02 的范围内。本文提出的BAMRel模型融合实体类型信息进行关系抽取是合理有效的。
4 总结
本文提出一种基于双仿射注意力机制的实体关系联合抽取模型BAMRel,模型在自行构建的TFRED 数据集和公开的DuIE 数据集上都达到了最佳的实验结果,证明了BAMRel模型可以有效解决实体嵌套和关系重叠的三元组抽取问题。同时实体抽取和关系抽取部分共用Biaffine 模型构造分类矩阵,降低了联合抽取模型的复杂度,使得模型具有良好的性能。
在实验过程中,BAMRel模型在训练阶段使用实体真实标签,而在评估阶段使用预测标签,训练阶段过于依赖真实标签而产生曝光偏差,会导致误差传播,如何解决曝光偏差问题是接下来值得研究的问题。另外,基于双仿射注意力机制构建的分类矩阵存在标签不平衡问题,解决标签不平衡问题也是接下来模型改进的方向。
