慢性病疾病组合模式识别方法的应用与比较*
2022-09-14陆姣王媛袁媛
陆 姣 王 媛 袁 媛
【提 要】 目的 应用不同方法识别慢性病疾病组合模式并比较其应用效果。方法 利用中国健康与养老追踪调查数据,分别用潜类别分析(latent class analysis,LCA)、合并多元对应分析和模糊C-means聚类的组合聚类法(combinatorial clustering,CC)、双向聚类法(two-way clustering framework,TCF)识别多病共存患者的慢性病疾病组合模式。同时,根据各方法中所纳入疾病数量多少、是否排除随机组合及其所识别出疾病组合模式的描述指标进行方法比较。结果 LCA能够明确疾病组合模式中各类疾病的概率分布,但纳入疾病数量过多容易导致疾病模式划分不清晰。CC基于患病率识别疾病组合模式,不要求纳入的疾病数量且能够描述不同疾病模式中各个疾病的患病情况。TCF能够不受所纳入疾病数量的影响而最大化保留疾病模式间的相互独立性。此外,仅TCF可以评判疾病组合模式中疾病间的关联强度并有效排除随机的疾病组合模式。结论 LCA适用于纳入疾病数量较少的临床研究,CC适用于社区多病共存的流行病学调查,而TCF更适用于不需进行个体特异性评估的大规模调查。
慢性病患者中多病共存情况日益严重。多病共存意味着患者病情的迁延不愈,不仅给临床决策、治疗与干预带来了诸多困难,而且成为了医疗资源的消耗“黑洞”。通常情况下,多病共存需要多药治疗,容易产生同一适应症重复用药、忽视潜在药物配伍禁忌等不合理用药问题,进而增加药物不良反应的发生风险。如果缺乏及时有效的干预,这种潜在风险将极大地增加慢性病给患者造成的身心损害和经济负担[1]。事实上,多病共存患者所患有的多种慢性病之间可能存在一定的相关关系,并呈现出特定的疾病组合模式,对其进行识别,有助于临床医生预测患者所患疾病的发展方向,并为患者制定合理的干预和治疗方案。近年来,学者尝试将潜类别分析(LCA)、合并多元对应分析(multiple correspondence analysis,MCA)和模糊C-means聚类(fuzzy C-means algorithm,FCM),以及双向聚类法(TCF)应用于慢性病疾病组合模式的识别研究中,本文拟通过系统比较上述方法,为有效识别慢性病疾病组合模式提供依据。
原理与方法
1.潜类别分析
潜类别分析(latent class analysis,LCA)通过潜在类别(class)变量解释外显指标间的关联[2],即外显变量各种反应的概率分布可以由少数互斥的潜在类别变量解释[3],根据个体在观测项目上的反应模式将其分类[4]。分析时限制各潜在类别的概率总和及每个外显变量的条件概率总和均为1,确定最优拟合模型后,依据贝叶斯后验概率识别每个个体的潜类别属性。
贝叶斯后验概率的公式为:
2.组合聚类法
组合聚类法(CC)是在多元对应分析(multiple correspondence analysis,MCA)的基础上运用模糊C-means聚类(fuzzy C-means algorithm,FCM)识别疾病组合特征并划分个体类别的组合方法[5]。首先,采取多元对应分析描述分类变量的交互汇总并揭示不同变量或同一变量中各类别之间的对应关系[6],识别可能存在关联的疾病组合,并得到模糊C-means聚类中进行个体分类的输入数据。其次,从已有的几何空间出发,事先给定聚类中心个数,以极小化所有数据点到各个聚类中心的距离及隶属度值的加权和为优化目标,按照模糊集合中的最大隶属原则将个体归类。最后,使用每一类个体的患病数据描述不同类别的疾病组合模式特征。
3.双向聚类法
双向聚类法(two-way clustering framework,TCF)是由Ng于2014年确定的一种允许重复聚类的两步疾病组合识别法,即先确定不重复的非随机疾病组合群,再根据各非随机疾病组合在人群中的分布特征,通过广义伯努利分布的混合模型将个体分为不同类别[7]。
具体聚类过程如下:
(1)用n×p的(0,1)矩阵描述个体的患病情况,n和p分别表示个体人数和疾病数量,每行表示一个个体,每列表示一种疾病;
(2)用p×p的对称矩阵,通过非对称的Somers’D统计量量化非随机疾病组合中所有成对疾病的关联程度;
(3)用p×p的(0,1)对称矩阵,采用Benjamini-Hochberg法评估非随机疾病组合中所有成对疾病关联的显著性;
(4)通过聚类和转换程序将每种疾病(列)划分到N个不重叠的疾病组合中;
(5)生成n×N的(1,2,3)矩阵表示每个个体在N个疾病组合中的患病程度,1代表个体未患第i个疾病组合中的任何疾病,2代表个体患有第i个疾病组合中的一种疾病,3则代表个体患有第i个疾病组合中的≥2种疾病(i=1,2,…,N);
(6)利用广义伯努利分布的混合模型将n个个体划分为不重叠的类。
实例分析
本研究中的数据来源于中国健康与养老追踪调查(China Health and Retirement Longitudinal Study,CHARLS)。以2018年实际受访人群为研究对象,筛选14种慢性病(高血压、血脂异常、糖尿病/血糖升高、癌症等恶性肿瘤、慢性肺部疾患、肝脏疾病、心脏病、中风、肾脏疾病、胃部疾病/消化系统疾病、情感及精神方面问题、与记忆相关的疾病、关节炎/风湿病、哮喘)患病情况均有填答的样本进行分析,共纳入19745名个体。其中,4137名未患任何慢性病(20.95%),4667名患有1种慢性病(23.64%),患2种及以上慢性病的个体共10941名(55.41%)。19745名个体的慢性病患病情况如图1所示。
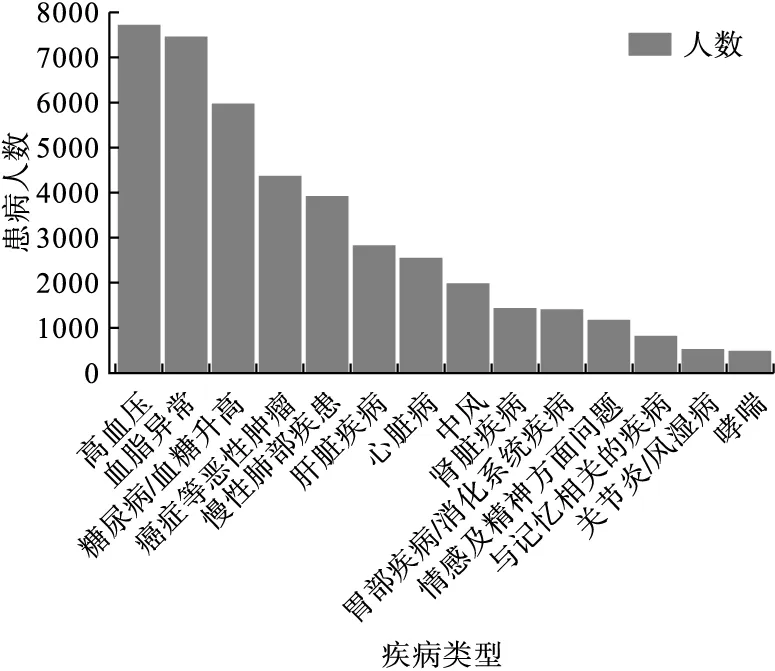
图1 19745名个体的慢性病患病情况
1.潜类别分析
针对10941名患2种及以上慢性病患者的患病情况建立(0,1)矩阵,利用国际主流潜变量建模软件Mplus 7.4,采用莫代尔分配法,根据个体后验概率的最大值识别个体归属的疾病组合。综合1~7个类别模型中的AIC、BIC、aBIC值(表1)与陡坡图(图2)确定最优类别数为5[2],同时5类别模型的Entropy值为0.671,表明此模型分类的精确性最高。结果显示,5个类别中个体(行)归属于各自潜在类别的平均概率(列)为64.60%~82.40%,且根据应答概率图可知(图3),第1类群体患高血压、心脏病、关节炎/风湿病的概率约为80%,同时约有70%的可能性患血脂异常、胃部疾病/消化系统疾病,并伴随慢性肺部疾患和肾脏疾病,可将此疾病组合命名为“高血压、心脏病、关节炎/风湿病为主的疾病组合”(6.28%);第2类群体中约有80%的概率患高血压,且患血脂异常的概率接近60%,可将其命名为“高血压为主,并伴随血脂异常的疾病组合”(40.35%);第3类群体患慢性肺部疾病的概率接近90%,同时约有50%的可能性患有关节炎/风湿病和哮喘,可称其为“慢性肺部疾患为主,伴随关节炎/风湿病和哮喘的疾病组合”(12.48%);第4类群体中胃部疾病/消化系统疾病、关节炎/风湿病的患病概率分别在70%、80%左右,可将其命名为“胃部疾病/消化系统疾病和关节炎/风湿病为主的疾病组合”(33.88%);第5类群体中高血压、关节炎/风湿病的患病率均接近100%,可将其命名为“高血压和关节炎/风湿病为主的疾病组合”(7.01%)。

表1 LCA模型拟合信息汇总表
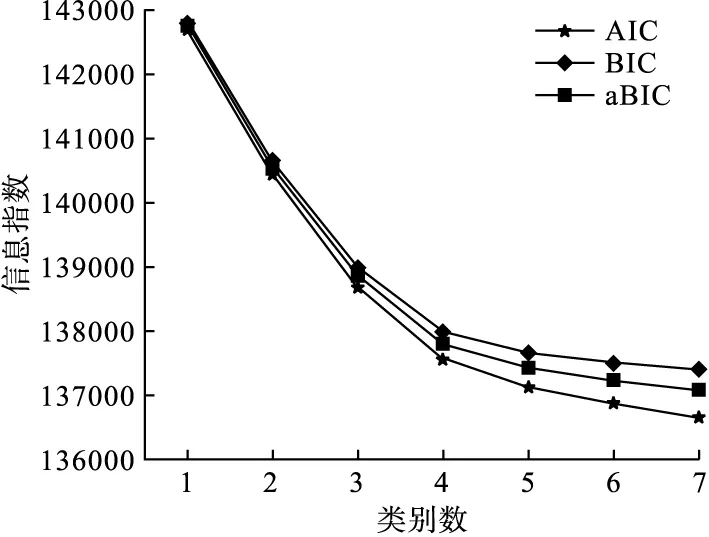
图2 LCA信息指数陡坡图
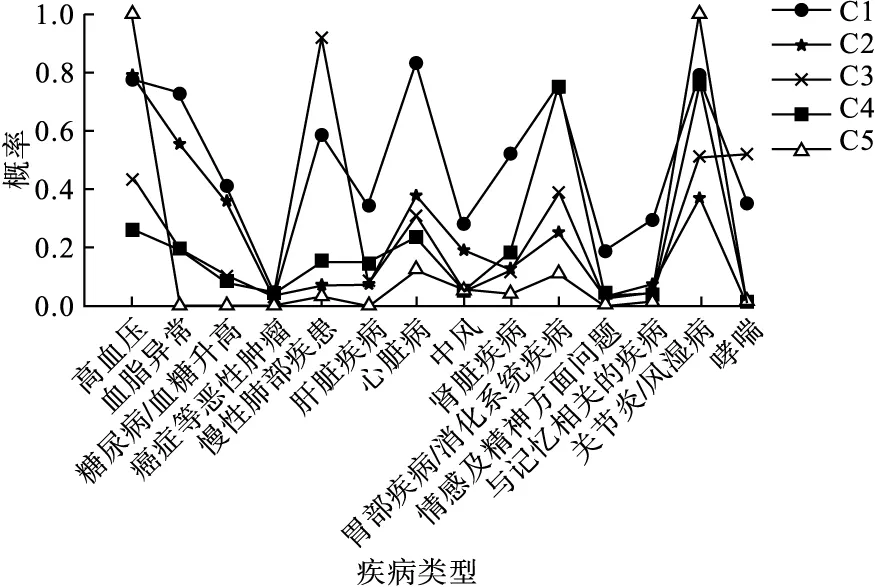
图3 LCA各类别的应答概率图
2.组合聚类法
针对10941名患2种及以上慢性病患者的患病情况建立(1,2)矩阵,采用SPSS 21.0进行MCA。结果显示,两个维度分别能解释数据变异的12.09%和10.90%,且总信度为0.81,处于较好水平(表2)。在此基础上,利用Matlab 9.6软件进行FCM对个体进行聚类,并进行100次迭代以去除聚类结果的随机成群效应。当结果中观察/预期比i≥2或疾病特异度ii≥25%时,一种疾病即被视为与特定疾病组合相关(i指一类群体中某种疾病的患病率与整个样本中该疾病的患病率之比;ii指一类群体中某种疾病的患者数与整个样本中该疾病的患者数之比)。最终确定4类疾病组合,第1类疾病组合(C1)由癌症等恶性肿瘤、慢性肺部疾患、肝脏疾病、肾脏疾病、胃部疾病/消化系统疾病、关节炎/风湿病组成;第2类疾病组合(C2)包括高血压、血脂异常、癌症等恶性肿瘤、胃部疾病/消化系统疾病、关节炎/风湿病;第3类疾病组合(C3)则由慢性肺部疾患、肝脏疾病、心脏病、肾脏疾病、情感及精神方面问题、与记忆相关的疾病、哮喘构成;第4类疾病组合(C4)包括高血压、血脂异常、糖尿病/血糖升高、心脏病、中风、与记忆相关的疾病。每种疾病组合中的慢性病特征见图4。
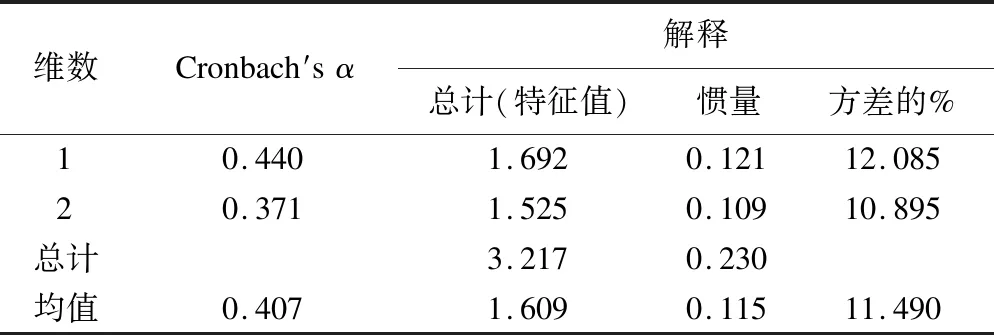
表2 MCA模型汇总表
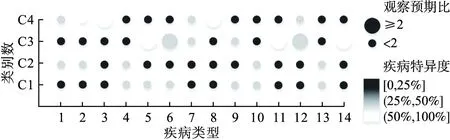
图4 CC识别出的疾病组合模式特征
3.双向聚类法
建立针对所有人群的(0,1)矩阵,通过R软件确定9个重叠的疾病组合簇(表3),通过比较不同疾病组合中重复出现的疾病与每个疾病组合的关联强度,将重复疾病划分到与其相关性最高的疾病组合中,9个重叠的簇进而转化为3个不重叠的疾病组合(G1-G3)(表4)。其中,G1包含了“高血压、血脂异常、糖尿病/血糖升高、心脏病、中风、与记忆相关的疾病”,G2包含了“慢性肺部疾患、肝脏疾病、肾脏疾病、哮喘”,G3包含了“胃部疾病或消化系统疾病、情感及精神方面问题、关节炎/风湿病”。在此基础上对个体进行聚类,利用贝叶斯信息准则选择5类别模型为最优模型(图5),并基于如下设定描述群体类别:(1)个体未患特定疾病组合中的疾病,则其与该疾病组合为低度关联;(2)个体患有特定疾病组合中的一种疾病,则其与该疾病组合为中度关联;(3)个体患有特定疾病组合中2种以上疾病,则其与该疾病组合为高度关联。最终所分类的人群中,第1类人群高度关联G3,第2类人群高度关联G1并中度关联G2,第3类人群中度关联G3,第4类人群低度关联G1、G2和G3,第5类人群则高度关联G1和G3。
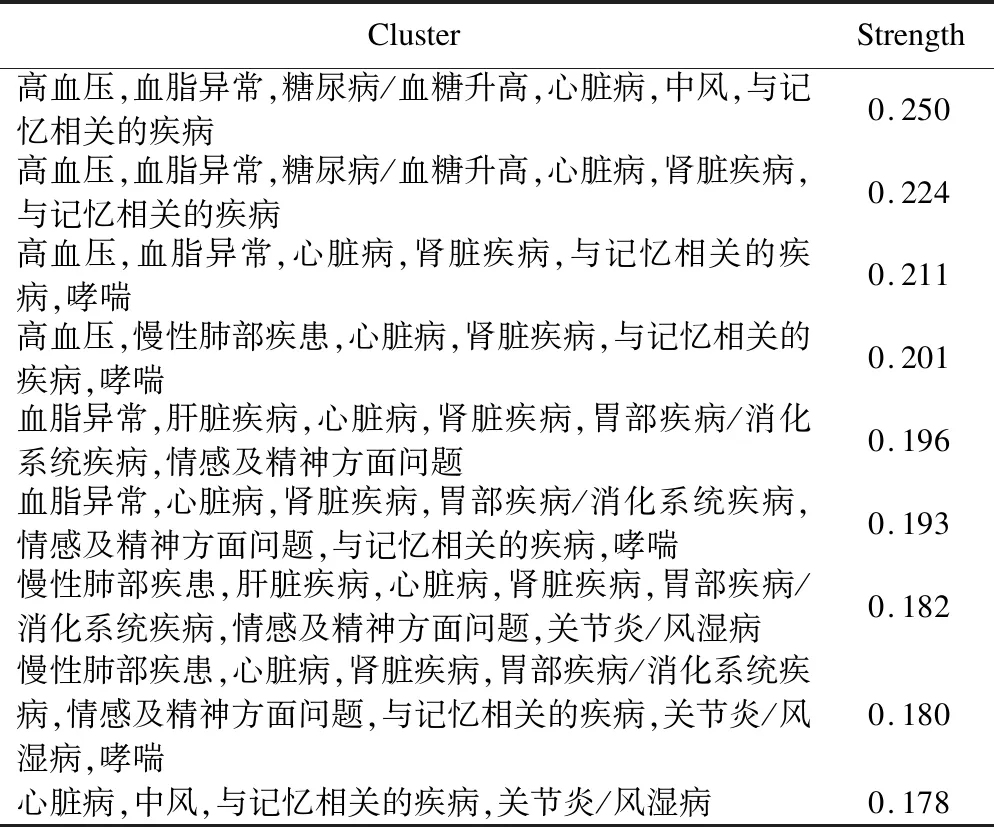
表3 TCF识别出的9个重叠的疾病组合

表4 TCF识别出的3个不重叠的疾病组合
讨 论
识别慢性病疾病组合模式对个体多病共存的干预与治疗具有重要意义。疾病组合模式的识别既要尽可能保证同一疾病能够出现在不同疾病组合模式中,也要确保不同疾病组合模式间的相互独立性。更为重要的是,所识别的疾病组合模式应具有非随机性。本文通过比较LCA、CC和TCF三种方法发现,这些方法各具优劣,分别适用于不同的研究环境中。LCA能够定量描述疾病组合模式,了解各类疾病组合在人群中分布情况的同时明确组合中各类疾病的概率分布。但是,潜类别分类个数的确定是实际应用中的一个难点[2]。此外疾病数量越多,疾病组合模式可能越复杂,解释难度也会相应地增加,同时LCA需要足够大的样本量支撑模型分类的精确性,因此该方法更适合于纳入疾病数量较少的临床研究中。结合MCA和FCM的CC弥补了单一MCA的分类结果不具有统计学意义的缺陷,而且其突破了变量个数的限制,能够根据最大隶属原则将样本分类。但是,该方法基于每种疾病的患病率描述疾病组合,难以排除疾病组合模式的随机性,更适用于社区多病共存的流行病学调查。TCF一方面能够通过利用非对称的Somers’D统计量与Benjamini-Hochberg程序有效避免疾病变量间的共线性问题[8],并有效排除随机的疾病组合模式;另一方面能够评判疾病组合模式中疾病间的关联强度,且不受所纳入疾病数量的影响而最大化保留疾病模式间的相互独立性。但是,该方法无法将个体划分到一个具体的疾病组合模式中,且要求纳入的疾病数量≥10种,更适用于不需对个体进行特异性评估的大规模调查。

图5 TCF识别出的5类人群的疾病组合特征
综上所述,三种方法均实现了疾病组合模式与人群归属类别的识别,但在实际应用中,应根据研究目的的不同选择适宜的方法。如果需要明确每个个体所归属的特定疾病组合,且所研究的疾病数量较少,LCA是较为适用的方法;如果研究目的对疾病组合的非随机性要求较低、对所研究的疾病数量没有限制,则CC更为适用;TCF则适用于根据非随机的疾病组合模式对大规模人群分类的研究。
