加权随机森林和代价敏感支持向量机与心衰患者死亡风险评估*
2022-09-14孟冰霞罗艳虹韩清华张岩波
杨 弘 田 晶 孟冰霞 张 瑜 罗艳虹 王 可 郑 楚 韩清华△ 张岩波,3△
【提 要】 目的 探讨加权随机森林和代价敏感支持向量机模型在慢性心衰死亡风险评估中的应用。方法 利用AUC-RF自变量筛选方法选出与心衰死亡的相关因素,将选出的变量作为输入变量,预后有无死亡作为结局变量构建传统随机森林、支持向量机、logistic回归、加权随机森林和代价敏感支持向量机分类预测模型。 结果 AUC-RF筛选出的变量中有中枢系统疾病史、肾功能不全史、心包积液、BMI、中性粒细胞比值、肾小球滤过率、N端前脑钠肽等指标重要度较高,提示这些指标或有临床意义。评价指标有灵敏度、特异度、准确度、G-means、F-measure和AUC值,logistic模型评价指标的中位数分别为:78.46%、63.19%、81.4%、0.6933、0.467和0.7003;加权随机森林评价指标分别为:78.08%、82.74%、85.96%、0.8086、0.4853和0.8109;代价敏感支持向量机评价指标分别为:75.38%、72.49%、88.8%、0.7402、0.4749和0.7940。结论 加权随机森林模型对心衰患者预后死亡预测性能较高,该模型有助于临床医生识别心衰死亡危险因素,具有较高应用价值。
心力衰竭(heart failure,HF)是各种心血管疾病进展的终末阶段,其主要原因是心脏无法泵出足够的血液来维持血液流动。HF已经成为21世纪最致命的心血管疾病之一[1]。心衰患者的高死亡率也是全球公共卫生的关注重点[2],据估计,发达国家大约有2%的成年人患有心衰,65岁及以上人群心衰的患病率≥6%[3]。2003年的研究调查显示,我国35至74岁成人心衰患病率大约是0.9%[4]。医疗水平的提高使心衰患者寿命延长,导致我国心衰患病率持续升高,医疗成本不断上升[5]。因此,准确的心衰不良事件预测模型可以对患者和医生提供益处,尤其可以预防不良事件的发生[6]。
本研究采用心衰住院患者电子病历资料,探索基于代价敏感的随机森林和支持向量机模型在心衰患者的预后死亡评估中的应用价值,并与传统logistic回归、随机森林和支持向量机进行比较,识别危险因素,反馈临床,指导高危人群的早期干预,降低心衰死亡率。
对象与方法
1.研究对象
本研究数据来源于山西省太原市2所三甲医院心内科,研究对象为2014年1月-2018年12月首次诊断为慢性心衰的住院患者,每隔6个月通过电话随访,确定其生命状态。研究对象纳入标准为:年龄≥18 岁;有典型的慢性心力衰竭症状(如劳力性或阵发性呼吸困难、乏力、食欲不振)或体征(如双下肢水肿、肺部湿啰音、肝颈静脉回流征阳性);NYHA 心功能分级Ⅱ-Ⅳ级;诊断为缺血性心肌病的患者。排除标准为:近两个月发生急性心血管事件的患者;并发精神疾病的患者;并发其他危及生命的疾病,预期生存时间<1年的患者;拒绝参加本项目的患者。
2.研究方法
(1)资料收集
由培训过的人员查阅医院档案室中的电子病历,并严格按照课题组制定的CHF电子病历报告表(chronic heart failure electronic case reported form,CHF-eCRF)收集患者住院期间的病历信息。按照CHF-eCRF内容,使用EpiData 3.1软件进行双录入。经过筛选,纳入本研究的有效患者1972例,其中在随访期间死亡的患者有391(19.8%)例。
(2)AUC-RF自变量筛选
本次研究中原始数据库包含798个变量,排除与本研究无关、非结构化数据和缺失比例大于30%的变量后还剩121个变量,对于缺失数据选用“missForest”R包进行缺失填补。为提高模型在实际临床中的应用,考虑本研究数据为非均衡数据,选用CalleML提出的AUC-RF自变量筛选方法[7]。该方法使用受试者工作特征曲线下面积(the area under the receiver-operating characteristic curve,AUC)作为随机森林的性能评价指标,选择最高AUC值的一组自变量作为输入变量,避免预测结果不佳。
(3)加权随机森林模型的建立
加权随机森林(weighted random forest,WRF)是ChaoChen为解决传统随机森林对非均衡数据建模时以错误率最小化为目的,无法有效识别少数类而提出的基于代价敏感学习的方法[11]。其原理是通过对数据中每一类样本进行权重设置,增加少数类权重使错误分类代价增大。本研究在Rsutdio软件中,使用“randomForest”包构建WRF,经试验参数设置如下:ntree(森林中树的树木)为600;mtry(决策树分支所需变量个数)为5;classwt(样本分类的权重)为2∶1。
(4)代价敏感支持向量机模型的建立
基于代价敏感的支持向量机(cost sensitive support vector machine,CS-SVM)由K.Veropoulos[8]于1999年提出,可以提高传统支持向量机算法在非均衡数据中的分类效果。依据支持向量机中惩罚参数C对数据中不同属性样本设置不同的分类权重。依据本课题组既往研究,本研究选择少数类与多数类样本量之比的倒数设置权重,并在其附近取值构建不同模型以选出最优参数。使用“e1071”包构建CS-SVM模型,以线性核为核函数。参数class.weights为4∶1;惩罚参数cost为1。
(5)模型构建方案
本次研究为准确评价模型预测性能,对数据采用分层抽样。从预后良好和死亡的病例中分别抽取2/3样本组成训练集(共1315例,其中预后好转和死亡分别为1054和261例),将剩余的1/3样本组成测试集(共657例,预后好转和死亡分别为527和130例)进行模型评价。使用AUC-RF法筛选出自变量后,将其作为特征变量输入模型,以心衰患者是否死亡作为结局变量,分别构建logistic回归、基于代价敏感的随机森林和支持向量机预测模型并找出最优参数。最后采用同一训练集使用以上方法建立预测模型,利用测试集进行模型评价,并与传统随机森林和支持向量机进行对比。
(6)模型评价指标
为全面评价构建模型的预测能力和泛化性能,针对非均衡数据本研究使用多个指标对模型分类结果进行综合评价。评价指标有灵敏度(true positive rate,TPR)、特异度(true negative rate,TNR)、准确率(accuracy,ACC)、G-means、F-measure、AUC[9-11]。
结 果
1.基于AUC-RF自变量的筛选
以随访后有无出现不良结局(死亡)对患者进行分组,随后利用“AUCRF”包构建随机森林预测模型,以重要性评价指标对变量进行降序排列,如图1所示。
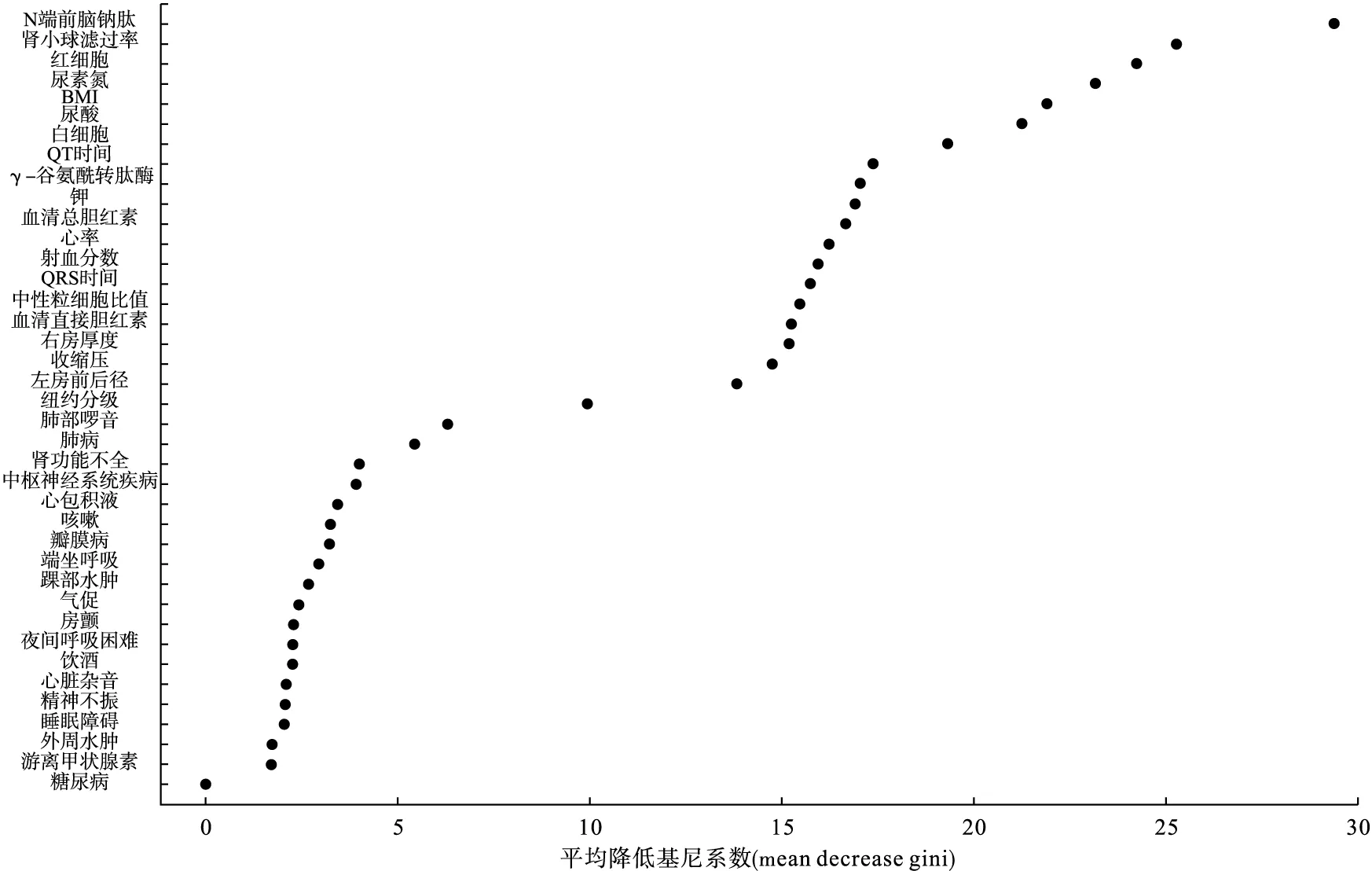
图1 随机森林模型中自变量重要性排序
为保证模型准确性,对随机森林进行五折交叉验证,重复20次,得到平均AUC值为0.8336,重复100次AUC-RF后得到自变量入选模型的概率,其中尿素氮等6个变量入选概率为1,23个变量入选概率大于90%。本研究选择入选概率大于80%的26个自变量进行建模,如表1所示。
2.logistic回归模型
本研究以最大Youden指数作为分类截断点,利用“glm()”函数建立logistic回归模型。重复抽样100次,构建100个logistic模型,并在测试集上进行验证,获得每个模型的评价指标。
3.WRF模型类权重选择
本数据为非均衡数据,据以往经验首先对类权重进行模拟设置。本研究在ntree、mtry默认参数下,设置类权重分别为2∶1,3∶1,4∶1,5∶1训练模型,并在测试集上进行性能评价。各类权重下都重复50次,结果见表2。

表1 最终建模变量赋值
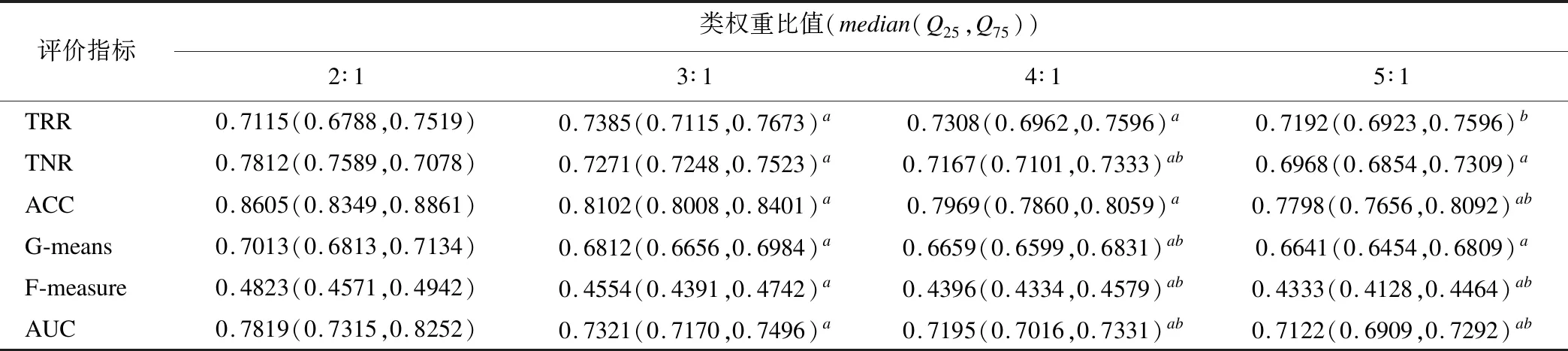
表2 不同类权重构建的WRF在测试集上的表现
由表2可知,随着少数类与多数类权重的增加,指标TRR、TNR、ACC、G-means、F-measure和AUC均呈下降趋势。对权重下模型指标进行多组件秩和检验可知其余权重下模型与类权重2∶1模型比较,差异有统计学意义,且各项指标均较高,灵敏度为71.15%,特异度为78.12%,准确度为78.19%。最终选择类权重为2∶1进行模型构建。
4.CS-SVM模型类权重选择
本研究使用“svm()”函数设置参数clss.weights找到最优类权重。据以往研究经验,将少数类与多数类之比的倒数设置为class.weights值可以使模型对非均衡数据有较好的识别度。故本研究分别设置class.weights为2∶1,4∶1,6∶1,8∶1构建模型。各类权重下重复50次,结果如表3所示。

表3 不同类权重构建的CS-SVM在测试集上的表现
如表3所示,随着少数类与多数类权重之比的增大,TRR呈上升趋势,而TNR和ACC呈下降趋势。G-means,F-measure和AUC在类权重为4∶1时取得最大值,随后小幅度下降。将不同类权重设置模型指标进行多组件秩和检验后,差异均有统计学意义。因本次研究数据类型为非均衡数据,因此允许特异度和准确度有小幅度降低[12],但有较大的G-means、F-measure和AUC。故最终采取类权重为4∶1构建模型。
5.不同预测模型分类性能比较
采用相同训练集和测试集构建并训练logistic、WRF、CS-SVM和传统随机森林,支持向量机的慢性心衰患者预后死亡的预测模型,比较各模型性能优劣,重复100次,均采用中位数和上下四分位数进行表示。各指标如表4所示。

表4 不同分类模型在测试集上性能比较
从表4可以看出传统支持向量机和随机森林灵敏度(TPR)仅为1.54%和12.31%,而特异度(TNR)分别为99.24%和98.1%,模型倾向于识别预后死亡的患者,而且G-means,F-measure和AUC均较低。logistic的灵敏度最高为78.46%。对少数类进行加权的随机森林和支持向量机灵敏度都在75%以上,说明两者均可较好的识别出预后死亡的心衰患者。但是两种模型的特异度分别为82.74%和72.49%,较传统模型偏低,说明在提高对少数类识别率的同时,对多数类识别能力有所影响。针对非均衡数据的性能评价指标,加权后的两种模型较传统模型均较高,其中WRF的G-means(0.8086),F-measure(0.4853)和AUC(0.8255)是所有模型中最高的一组。在准确率(ACC)上,logistic与WRF和CS-SVM表现相差不大。综上所述,WRF、CS-SVM和logistic与传统模型相比,性能相对稳定,尤其针对非均衡数据上对少数类识别表现较好,其中WRF分类性能更为优越。
讨 论
心衰是一种慢性病,其特点是患者生活质量差、再住院率高、死亡率高和费用负担高等。改善以上不良后果的有效手段是对心衰进行病因预防,早期诊断,以及对不良事件的早期预测[13]。在这些方向上,机器学习技术的应用做出了巨大贡献。
国内对心衰患者死亡预后预测的研究较少,多使用Cox风险比例回归进行危险因素识别应用,未针对模型性能进行评价[14-16]。国外此类研究较多,如Shalh等[17]和Fonarrow等[18]分别使用支持向量机和CART构建模型估计了急性失代偿心衰住院患者的死亡率风险。Bohacik等[19]将2032名患者的住院病历数据应用于决策树对慢性心衰患者进行生存分析,灵敏度为37.31%,特异度为91.53%,准确度为77.66%。与本文WRF模型相比,其灵敏度较低,说明未能有效识别“死亡”这一少数类样本。Panahiazar[19]等在2015年利用Mayo诊所电子健康记录数据,对慢性心衰患者构建了logistic回归和随机森林的生存分析模型。分别构建了1年、2年和5年后患者死亡率,模型结果显示logistic回归和随机森林模型预测性能相差不大,AUC平均都在60%以上,最大可达到80%,与本研究结果相近。2016年,Panahiazar[20]团队再次应用2015年文章的数据构建对比辅助模式逻辑回归(CPXR(Log))模型,1年、2年和5年后患者死亡预测模型准确率都在80%以上,尤其1年后预测准确率高达91.40%,表现优越。
本研究对心衰患者构建预后死亡风险预测模型,通过回顾性研究方法收集患者的住院病历资料,并考虑到非均衡结构的数据,从中筛选出26个变量应用logistic回归、加权随机森林和代价敏感支持向量机进行构建模型,以弥补传统机器学习无法有效识别少数类的缺陷,提高对心衰患者预后死亡的识别性能。结果显示,加权随机森林模型的综合表现最优,可以为临床工作者提供一定程度参考,具有重要的临床意义。
综上所述,本文使用代价敏感的思想在一定程度上弥补了慢性心衰对死亡预测数据的不平衡性,加权随机森林预测性能较好。但是,依然存在不足之处,如本文未对患者中长期死亡风险如1年后,2年后进行分别建模;研究对象局限为山西太原市内三甲医院患者,样本来源相对单一,代表性不足,选择偏倚不可避免;本次研究仅有住院的电子病历信息,心衰患者的疾病状态具有高度异质性[20],还应该补充患者个体的基因信息,以提高模型预测性能。
