基于知识指导的安全强化学习路由算法
2022-09-14李婧侯诗琪
李婧,侯诗琪
(上海电力大学计算机科学与技术学院,上海 201306)
截至2020年12月,我国互联网普及率达70.4%[1],网民增长规模使网络接入流量激增。在高负载网络中,以开放最短路径优先(open shortest path first,OSPF)为代表的传统数学模型驱动的协议不能感知节点和链路的状态变化以调整路由策略,改善网络传输质量[2]。如图1所示,假设路由器R1、R2和R3均收到了需送往R7的数据,在OSPF算法下,R1、R2和R3会选择通过R5将数据送达R7,R5成为影响网络性能的瓶颈。
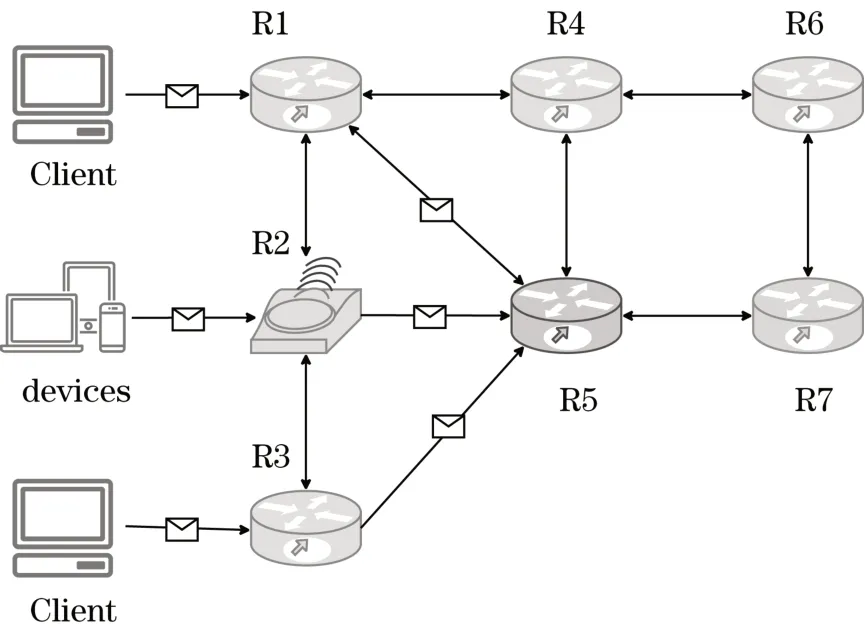
图1 OSPF的局限性Tab.1 Limitation of OSPF
近些年,深度学习和强化学习也被应用在路由优化中,但这类基于数据驱动的算法在大流量传输场景中不能再做出最优或次优决策以保证网络吞吐量,特别是在模型训练初期。基于深度学习的模型训练成本高且可解释性不足,基于强化学习的模型还存在Q值过估计问题。
针对上述问题,本文提出一种基于先验知识指导的安全深度强化学习路由选择知识指导等路由算法(safe double deep Q network with priori knowledge guidance approach,PKG-DDQNS),此算法降低了训练成本,提升了决策安全性和可解释性以及网络吞吐量。其工作主要体现在以下3方面:
(1)为加速模型收敛,提升模型训练初期的吞吐量,降低丢包率,避免探索阶段做出不安全的选择导致网络大范围拥塞,算法将先验知识融入深度强化学习模型,结合ε-greedy策略,生成下一跳。通过对动作进行预判和限制,制止不合适的动作选择,保证整个决策阶段动作安全性。
(2)为提升模型可解释性,奖励函数引入对路由回路的判断,避免形成局部回路,可让数据分组更快送达,提升路由器缓存资源的利用率。
(3)为评估算法有效性,将算法部署在基于Keras和Networkx的仿真环境,量化比较了本算法对网络吞吐量、数据交付率等指标的提升程度。
1 智能路由研究现状
基于数据驱动的路由选择算法的主要作用为监督学习和强化学习,这类算法不对具体环境建立复杂数学建模,而是对数据建模[2]。
基于监督学习的算法以深度学习模型为主,这类模型可通过带标签数据学到更为复杂的策略。车向北等[3]、唐鑫等[4]分别提出基于图神经网络的路由算法,能感知网络动态变化以优化路由策略。孙鹏浩等[5]、吴凡等[6]分别提出SmartPath和QoS(quality of service)感知算法(DLQA),可根据流量特征变化生成满足不同QoS的路由策略。但这类算法存在3个问题:①训练成本高,模型需通过传统路由算法多次获取足够多带标签数据进行训练;②深度学习存在不确定性,会使路由决策存在安全隐患,当训练数据集之外的情况发生时,网络性能可能会下降;③深度学习可解释性不足,当出现突发情况导致网络性能下降时,难以快速定位问题。
基于强化学习的路由算法的核心是Q-learning[7]。Boyan等[8]提出的Q-routing算法以及Daniel等[9]提出的QCAR旨在为数据分组选择时延最短的路径,可感知拓扑结构和负载变化,避免拥塞。但在探索阶段,网络性能不佳。随后出现的Full echo Q-routing以及学习率可变的(FQLR)在路由决策前进行轮询操作,加快节点间的信息交换以降低延迟[10],但在大流量传输中模型训练初期延迟较高。这类算法的共性问题是当动作空间和状态空间具有连续性时,Q表将急剧增大,查表操作严重影响算法性能。
有学者将Q-learning与深度学习相结合。这类算法基于集中式部署或分布式部署[11],使用基于深度强化学习(deep Q network,DQN)的路由选择算法生成下一跳[12-13]。高飞飞等[13-14]提出基于集中式部署的SDMT-DQN和DOMT-DQN以降低网络拥塞。胡玉祥等[15]、刘外喜等[16]分别提出基于深度确定性策略梯度的EARS和DRL-R,可感知流量大小生成相应的路由策略。但在探索阶段,agent可能会做出使整个网络性能下降的不安全决策。基于分布式部署的MARL算法把每个路由器都看作agent,减少了所需训练的神经网络数目,然而agent需从邻居更新参数以避免陷入局部最优,这增加了通信成本,算法还存在过估计问题。
2 路由选择建模
网络采用经典网状拓扑结构,如图2所示。路由器r总数为N,可分为3类:①接收各种智能设备产生的数据,即源路由器rs;②目的路由器rd;③中途路由器rm可转发来自其他路由器的数据分组。Ns、Nm、Nd分别是3类路由器的数目,关系如下:
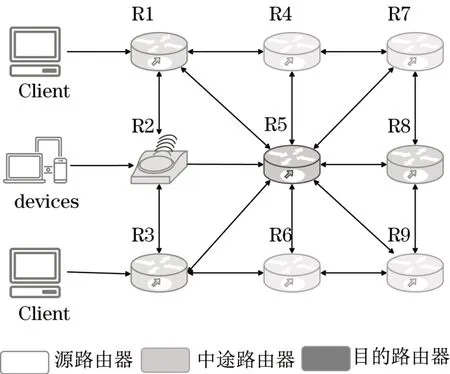
图2 实验拓扑结构Tab.2 Experimental topology
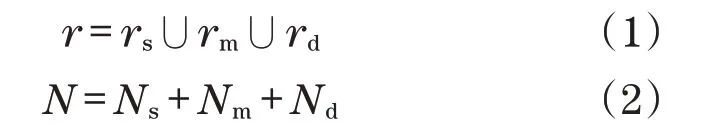
算法旨在为数据分组生成合适的下一跳,将其送达目的路由器。由于单一DQN只能使数据分组送达单一目的地,因此需训练多个参数不同的DQN[14]。在实际决策时,根据数据分组包含的目的节点信息,选用相应DQN来生成下一跳。
3 PKG-DDQNS详细设计
PKG-DDQNS算法的总体架构如图3所示。算法采用软件定义网络的架构。路由器构成了环境,agent位于控制器中。环境、状态、动作、奖励函数、状态价值函数和指导模块是PKG-DDQNS的6要素。
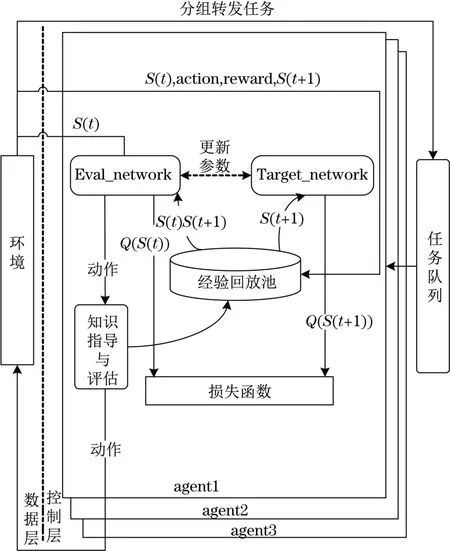
图3 PKG-DDQNS详细设计Tab.3 Detailed design of PKG-DDQNS
3.1 环境
数据源生成的数据送达源路由器,控制器与路由器进行通信收集传输任务,根据目的节点信息,选择相应agent产生下一跳,并发送到路由器执行转发操作。控制器收集环境状态,评估上一时隙的动作,并把状态、动作、即时奖励以及执行动作后的状态存至经验回放池。
3.2 状态
状态包括2部分:①t时刻路由器缓冲区的数据量Dt,Dt=[D1,t,D1,t,…,DN,t],Di,t为t时刻第i个路由器缓冲区的数据总量;②采用改进的one-hot编码记录t时刻数据分组的位置信息Pt,长度为N,Pt=[P1,t,P2,t,…,PN,t],且为t时刻数据分组是否在第i个路由器中,每时刻数据分组只存在一个路由器中,此路由器对应的Pi,t为1,其余为0。若agent做出非法选择,如选取当前路由器的非邻居节点,Pi,t为-1,其余为0。综上,t时刻的状态S为St=[Dt,Pt]。
3.3 动作
agent根据状态信息,依照ε-greedy原则为数据分组选择当前路由器的邻居节点作为下一跳A。agent会以ε的概率选取最优动作,以1-ε的概率选取其他动作。
3.4 奖励函数
为在大流量传输场景中减少丢包,令数据分组尽快交付,奖励函数包括因数据分组被丢弃时的惩罚性奖励以及被正常转发时的即时奖励:

式中:λ+φ=1,且λ,φ∈[0,1],φ∈{0,1};λ与φ为权重,衡量指标的重要程度,权重越大,表示该指标越重要。
agent将在以下2种情况获得惩罚性奖励,数据分组传输被终止:①当下一跳路由器的缓冲区已无法存储数据分组时,此时路由器负载过大;②当下一跳不是当前节点的邻居节点,动作非法。
agent在以下3种情况获得即时奖励:①当下一跳已出现在数据分组的路径中,可认为产生了回路,此时给予agent负向奖励Rloop;②数据分组每被转发一次,agent获得负向奖励Rhop;③当下一跳是目的路由器,agent获得正向奖励Rarrive,设置正向奖励有助于加速模型收敛。
3.5 状态动作值函数
算法的核心是不断改进对特定状态的特定行动质量的评估。算法构造的元组记录状态转移情况如下,并将其存储至经验回放池,状态转移元组O为
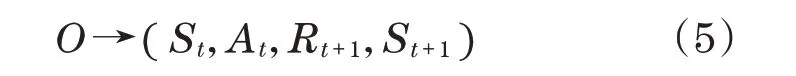
每隔一定时间进行随机采样,更新神经网络参数,预防值Q为
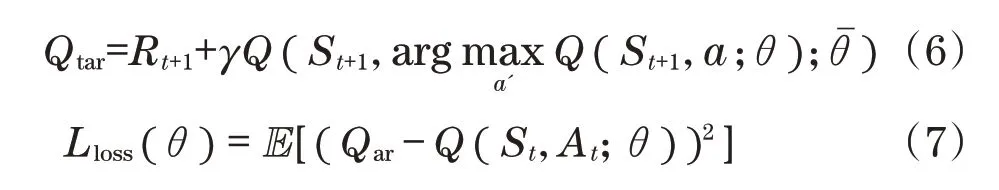
式中:γ为折扣因子;a为动作符合;为target network神经网络采参数。
agent结构如图3所示,包含2个结构相同的神经网络,输入层为状态,输出层为Q值。eval_network产生下一跳,target_network评估状态动作价值。
参数更新时,对于随机采样的每一个状态转移元 组,St输 入eval_network,得 动 作A的Q值Q(St,At),St+1输入eval_network,得下一时刻状态 下 各 动 作 的预 测Q值Q(St+1,At+1),St+1同 时输入target_network,从eval_network的输出层选 取 最 大Q(St+1,a)对 应 的 动 作a',即argmaxa'(Q(St+1,a;θ)),再 从target_network中选取a'对应的Q值,利用式(6)求出Target_Q,再对式(7)求导,更新参数[17]。为保证模型收敛,每隔一定时间将eval_network中的参数θ赋值给target_network的参数。
3.6 知识指导模块
为提升决策有效性和安全性,增强模型可解释性,加速模型收敛,保障agent训练初期的网络吞吐量,算法引入知识指导模块和ε-greedy策略共同决定下一跳。首先,模型根据ε-greedy策略,选出动作A。A送入知识指导模块,进行合法性检查、安全性评估和建议指导。
集中式部署下,agent拥有全局视角。若A是当前路由器的非邻居节点,则A非法,模块给出建议动作A',并把经验存至经验回放池。若动作A通过合法性检查,模块将对A做安全性评估。若A导致路由器负载过重,模块尝试给出建议动作A',若A'不存在,数据分组将被丢弃,评估的经验将存至经验回放池。若A通过了合法性检查和安全性评估,控制器把A发送至路由器执行转发操作。
建议指导部分使用one-hot向量,记录在当前节点选择每一个动作的评估结果,维度为Nm+Nd。向量n=[n1,n2,…,nNm+Nd]记录当前节点的邻居节点,若ni为当前节点的邻居,ni为1,否则为0。向量d记录动作是否会造成路由器负载过重。若低于负载阈值,di为1,否则为0。向量l评估动作是否产生回路。若否,li为1,否则为0。向量对应位置相乘,若存在多个i,使ni×li×di=1,则按照εgreedy选择。若只存在一个i,则返回i作为下一跳。若i不存在,则选择使ni×di=1的i作为下一跳A'。
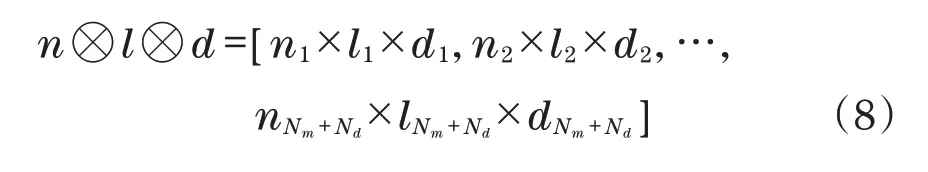
式(8)为加速算法收敛,建议指导部分将评估目的路由器是否在当前节点的邻居中,若在,模块会建议下一跳选择目的路由器。
4 实验仿真与结果分析
4.1 实验设计
4.1.1 实验环境
实验采用的拓扑结构如图2所示,源路由器和目的路由器缓冲区无限制,其余每个路由器缓冲区大小为45 MB。数据源产生的数据分组个数符合泊松分布。神经网络输入层设2N个神经元,输出层设N个。每个时隙数据源生成的数据总量相同。算法所在环境每时隙生成的数据分组一致,模型神经网络参数一致。
4.1.2 模型
为评估算法性能,实验选取以下模型。
OSPF:各路由器通信获取全局拓扑结构后,用Dijkstra算法计算到各节点最优路径。
QCAR[10]:采用Q-learning和随机选取不拥挤节点的方式生成下一跳,将流量分配到多条路径。
DOMT-DQN[17]:基于Nature DQN[15],根据目的节点选择对应DQN产生下一跳。
4.1.3 实验思路
(1)在相同输入流下,比较网络吞吐量。每时隙数据源生成47 MB数据。为验证状态动作函数设计和知识指导模块的有效性,引入以下模型变体:
PKG-DQNS:Target_Q沿 用Nature DQN计算,其余与PKG-DDQNS一致。
DOMT-DDQN:Target_Q沿用式(6)计算,其余与DOMT-DQN一致。
(2)在不同负载下,比较平均吞吐效率以及平均丢包率。定义吞吐效率为每轮训练结束后已送达的数据量与数据总量的比值,平均吞吐效率和平均丢包率分别表示对200轮训练的吞吐率γavt、丢包率求平均γavd为
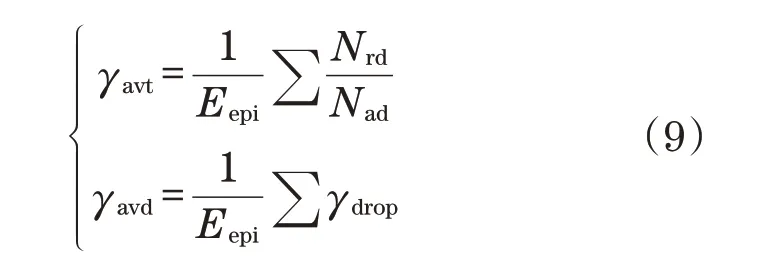
式中:Eepi为训练轮次;Nrd为每轮训练成功送达的数量;Nad为每轮训练生成的数量总量;γdrop为每轮训练丢包率。
(3)在相同输入流下,比较每轮训练数据分组传输的平均路径长度lav为

式中:Nrp为送达目的节点的数据传送任务数目;len为每个分组跳数。
4.2 结果分析
4.2.1 消融实验
吞吐量与训练轮次如图4所示,就吞吐量而言,总体上PKG-DDQNS优于PKG-DQNS;DOMTDDQN优于DOMT-DQN,证明了用式(6)计算Target_Q的有效性,对状态动作的更优估计可提升网络性能;同时证明知识指导模块的有效性,且知识指导模块对于吞吐量的提升作用更大。训练100轮后,4个基于深度强化学习的模型使网络吞吐量高于部署了QCAR和OSPF的环境,这证明了使用深度强化学习方法的有效性。
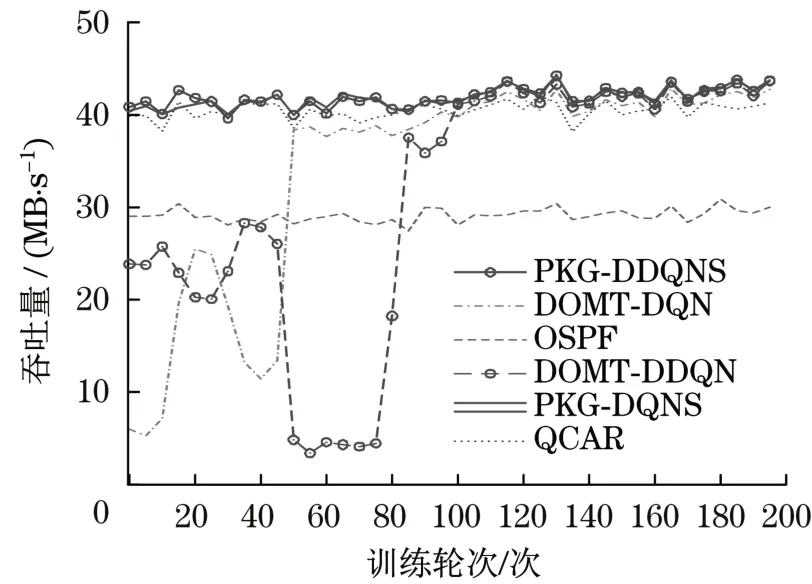
图4 吞吐量与训练轮次Tab.4 Throughput and training times
4.2.2 负载变化与性能
根据图5(a)所示,每时刻生成的数据量增加22%时,PKG-DDQNS的丢包率仅增加了1.52%,其余模型丢包率增长均高于1.52%。根据图5(b)所示,当数据生成速率从每个时隙生成45 MB到46 MB、50 MB到51 MB时,除QCAR的其他模型平均吞吐量均有上升现象,证明基于深度强化学习方法在感知流量变化方面的优越性。模型能根据网络的流量情况,调整策略。PKG-DDQNS和PKGDQNS使网络平均吞吐率高于DOMT-DQN和DOMT-DDQN,且平均吞吐率的变化幅度更小,表明ε-greedy与知识指导联合决策可保证吞吐率的稳定。PKG-DDQNS使平均吞吐率保持在85%以上。尽管在负载逐渐增加的情况下QCAR的平均丢包率最低,但总体上QCAR的吞吐效率低于其他模型,说明QCAR更倾向于丢弃数据量更大的分组,也表明知识指导模块作用可兼顾分组送达数目和分组数据量送达率。
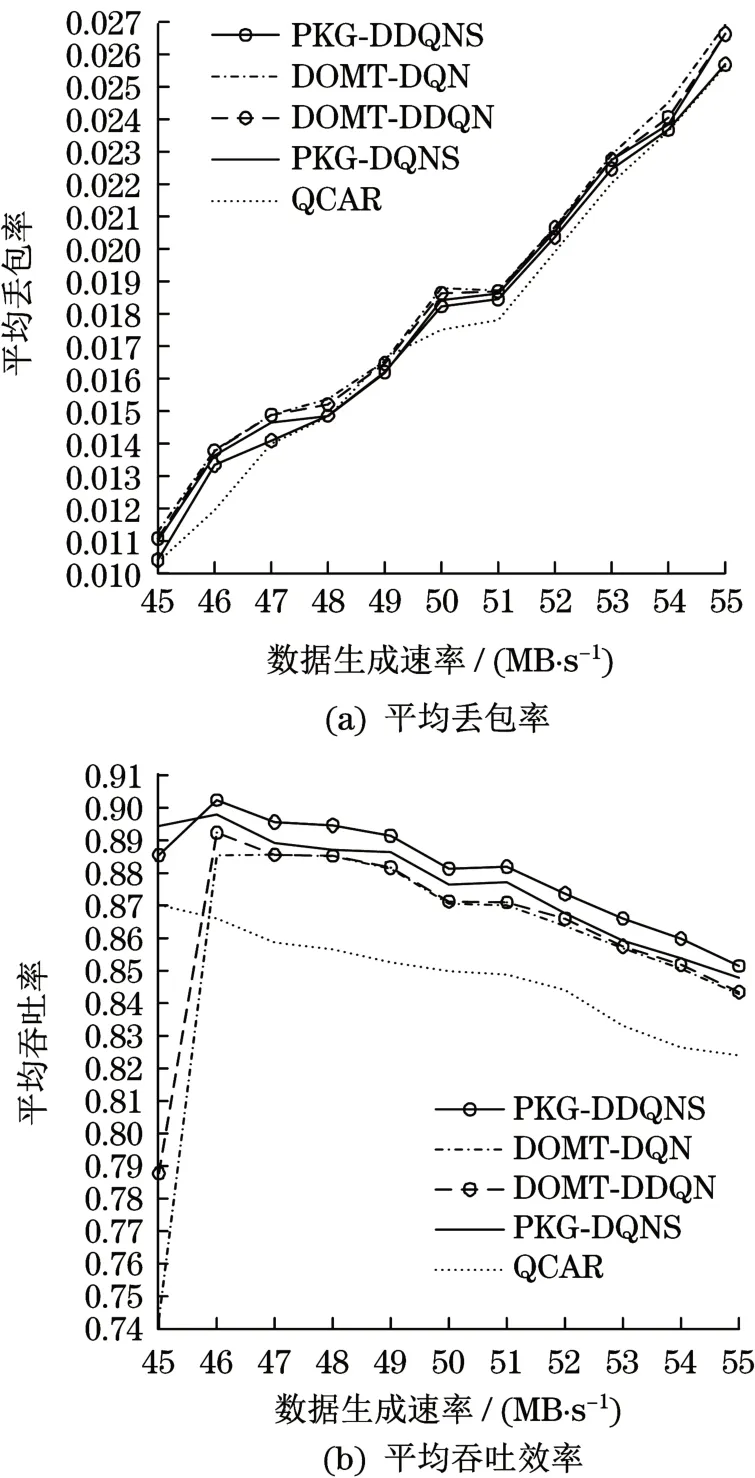
图5 网络负载变化与性能Tab.5 Network load changes and performance
4.2.3 平均路径长度
如图6所示,PKG-DDQNS的平均路径长度在3~4之间,其余模型均高于PKG-DDQNS,证明了回路惩罚机制的有效性。PKG-DDQNS能在满足QoS约束的同时优先选最短的路径将数据分组送达。尽管OSPF的平均路径长度最短,但沿着负载相对小的路径转发反而能提升网络性能。
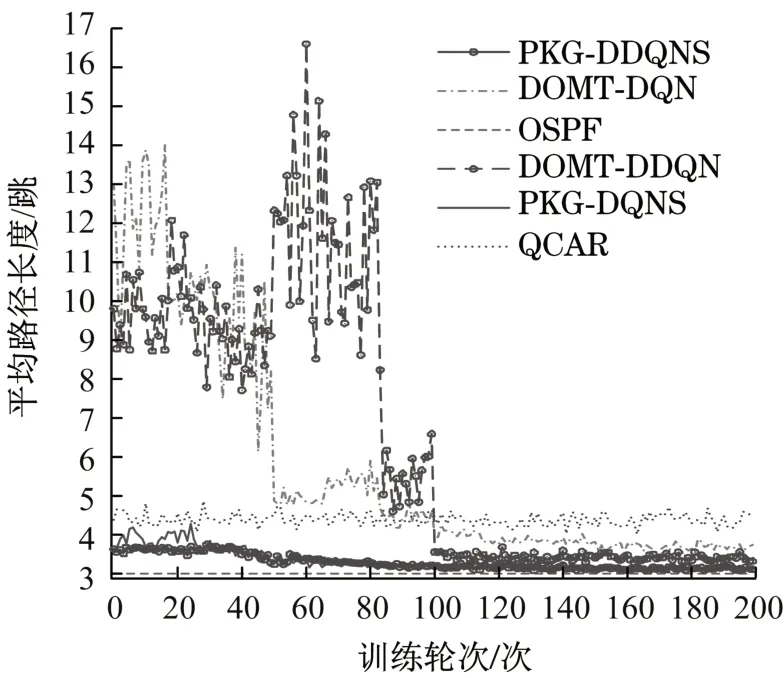
图6 平均路径长度Tab.6 Average path length
5 结语
为提升大流量传输时的网络吞吐量,保障从训练开始阶段到相对收敛网络始终具有较高的吞吐量,提出一种基于先验知识指导的安全深度强化学习路由选择算法PKG-DDQNS,融合ε-greedy和先验知识评估,利用集中式部署的优势,避免了网络出现环路和大规模拥塞,降低了训练成本。与现有算法相比,该算法显著提升了网络稳定性和吞吐量。
