运动目标编号识别技术的研究
2022-09-14于双芳
于双芳
(空军工程大学航空机务士官学校,河南 信阳 464000)
引言
在国内外,关于运动目标识别方面的研究已经有很久远的历史,最早的体现是在英国完成了车辆图像识别系统;自此,产生了车辆自动识别系统,它最先用于被盗车辆的检测[1]。目前车牌检测系统的研究在国外已经达到了一个非常高的水平。在国内,中科院在运动状态下检测目标信息方面研究做的较好,它生产的“汉王眼”就是一个优秀的产品[5]。在现代,随着科学技术技术的提高,电子产品性能越来越优越,图像处理技术的发展,进一步促进了图像识别技术的发展,提高了图像识别系统的性能。
1 图像预处理
由于运动目标的图像采集是在室外进行,天气的变化直接影响着采集的图像质量好坏,曝光不足或过分曝光的图像经常出现,除此之外还有它干扰的存在,都使图像质量下降。因此对原图像进行预处理,去除原图像中的干扰信息是必不可少的,而且要保证不增加原图像额外的信息量,从而达到增强部分图像的效果。图像预处理方法使用尺寸调整、亮度校正、灰度化、滤波、锐化和腐蚀。
2 运动目标编号的识别
首先对图像进行字符的分割,为了使单个字符的特征明显,识别效率高,进而使用颜色填充把字符变为实心体,最后对字符进行识别。
2.1 字符分割
选用投影法进行单个字符的分割[1]。分割结果见图1,从图1 中可以看出投影法对数字的分割结果是比较理想的,但对汉字和较小字符的分割结果不理想,不过可以满足本研究的要求。
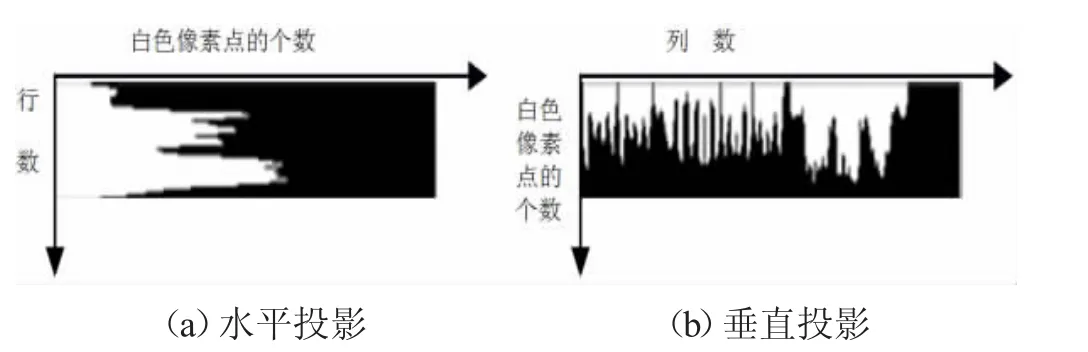
图1 投影分割方法的结果
2.2 颜色填充
颜色填充常用的一种方法是种子填充,它与边缘检测运算刚好相反,互为逆运算。为了保证运动目标编号自动识别系统的实时性,本研究选用扫描线种子填充法。
2.3 字符识别
字符识别是根据每个字符独有的特征比较分类[3]。字符识别包括汉字的识别、数字的识别和英文字母的识别,对于数字和英文字母来说,数字只有0~9 10个字符,英文大写字母和小写字母共52 个[5],都属于小字符集,提取特征比较容易;而常用汉字就有3 755个[2],其他汉字更是结构复杂,属于大字符集,所以提取特征就比较难。字符识别从宏观上讲属于图像识别,图像识别又被称为模式识别,根据模式识别的概念,识别一幅图像,无论图像中是字符还是景物都是除掉表面现象找出它们的共有特征,然后根据每个字符独有的特征进行分类。
神经网络识别是一种人工模拟人脑神经网络编写的识别方法[5]。神经网络识别系统的准确性和实时性很高[6],BP 神经网络(Error back propagation neural network)是目前字符识别中经常用到的一种识别方法。BP 神经网络识别流程见图2。
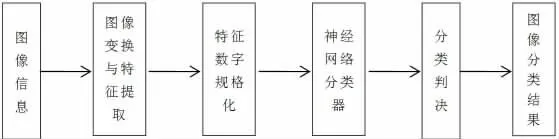
图2 BP 神经网络识别流程
BP 神经网络与其他识别方法相比,最大的优势在于其分类器含有一个向后传播神经网络,可以将新训练得到的不理想结果修正后再次匹配,BP 网络分类器见图3。
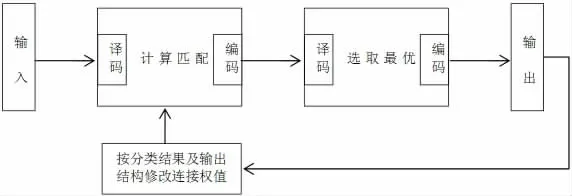
图3 BP 网络分类器
BP 神经网络训练需要权重系数,但BP 网络的权重系数不是人为设置的一个不变系数,它是不断训练、不断变化的。BP 网络是一种简单地表示模型,图4 为三层BP 网络简图,它分为三层,层与层之间相连,而同层之间的单元没有联系。当BP 网络输出层给出的响应结果不正确时,它会向它的前面一级传送修正[6]。

图4 三层BP 网络简图
假设有N 个训练样本,对第q(q∈Z)个训练样本,隐层j 的实际输出为Oqj,它的第i 个神经元的输出为Oqi,设

式中:Dqj表示对q 个训练样本,单元j 的期望输出[7]。
利用梯度最速下降法,使权值沿误差函数的负梯度方向改变[7]。若权值的变化量记为Δwij,即

式中:η 为学习因子。
BP 网络的训练算法如下:
(1)初始化,给所有节点一个小阈值;
(2)训练足够多的样本图像,使训练样本的是正确率达到要求;
(3)输出结果与期望结果比较,如果在误差范围内,则进入下一个样本的训练,否则执行(4);
(4)误差后向传播,修正权重系数wji(t+1)=wji(t)+ηδqjOqj,再进行样本的训练。
神经网络识别方法具有好的容错性,而且识别速度快[8]。所以本研究设计系统使用BP 神经网络识别方进行运动目标编号的识别。
3 运动目标编号自动识别系统的实现
本研究利用上述算法应用VC++ 平台结合OpenCV 库编制成一套适用于现场运行的软件系统,本章结合系统的算法流程图,下面就根据算法流程图对各个模块的实现进行分析说明并给出系统运行结果。
3.1 运动目标编号自动识别系统算法流程图
运动目标编号识别自动识别系统主要包含五部分:图像采集、图像预处理、定位、识别、车厢编号提取。
(1)图像的采集,把运行运动目标编号的图像拍摄下来,作为目标图像。
(2)图像预处理,把原图像尺寸归一化、校正亮度、锐化、灰度化、滤波以及膨胀与腐蚀。
(3)定位,先把灰度图像进行边缘检测二值化,然后对运动目标编号区域定位。
(4)识别,先把定位出的运动目标编号区域中的字符分成单个字符图像;为了识别更确切,利用种子填充算法把单个字符图像填充完整,然后再进行识别。
(5)运动目标编号的提取,把识别出的运动目标编号显示在屏幕上。
3.2 功能模块与实验结果分析
3.2.1 图像的采集
本研究设计的运动目标编号自动识别系统中的图像采集,直接使用场地现有的图像采集设备,这样不仅可以省去很多复杂的过程,还可以节省资源。场地现有设备是通过传感器与照相机设备相连,当有运动目标经过时,传感器会将感应信号转化为动作信号启动照相机采集图像,然后将采集的图像经过输入线路传输给运动目标编号识别系统。采集的原图像尺寸为7 728×5 368 像素。
3.2.2 图像预处理
由运动目标编号自动识别系统算法流程图可知,图像预处理包含尺寸调整、亮度校正、锐化、灰度化、滤波以及腐蚀[9]。
3.2.3 运动目标编号的识别
由运动目标编号识别系统算法流程图可知,运动目标编号的识别部分包括字符分割、颜色填充和字符识别。
(1)字符分割,为字符的识别做准备。本研究设计的系统选用投影法进行单个字符的分割,从实验结果中也可以看出,投影法对图像中数字的分割结果是比较理想的,但对较小字符和汉字的分割并不是很准确,不过这一点对本研究运动目标编号的识别提取没有太大的影响,是可以满足要求的。
(2)颜色填充,是为了字符识别更准确。颜色填充这一方法是在实验的过程中加入的,因为图像中的数字8 总是识别不准确,大部分被识别成了3 或者6,所以这里想利用颜色填充,把字符变成实心体,这样字符的特征就会变得更多一些,然后再进行字符训练,达到更高的识别率。本研究使用的颜色填充方法是种子填充算法中的扫描填充算法,并在其基础上加入了一些限制条件,可以从定位出来的车厢编号区域看出,除了字符边缘是白色点之外,其他地方都是黑色点,根据这一特点在找像素段时,当遇到像素段只有一端有白色像素点时,这种像素段优先填充。
(3)字符识别,识别出有用信息进行存储和显示,这是本系统的目标。运动目标编号自动识别系统中,由于外在原因和内在条件的影响,存在着很多不利因素,当然也有它的便利性。运动目标编号区域的字符集有以下四个特点:
A.小字符集。运动目标编号区域的字符是比较固定的。汉字包括车、空、调、发、电等字符;英文字母包括A,K,X,D,T 等字符;数字包括0~9 10 个字符。
B.单个字符的图像像素小。运动目标编号区域在图像中占的比例并不大,定位出的区域被分割为单个字符之后,图像变得更加小,增加了识别难度。
C.外界因素干扰大。图像的采集是在运动目标高速运行的情况下进行的,而且外界光线的的变化也会给图像的采集带来困难,很可能采集的图像是光线不足或者光线过强,又或者是字符黏连的。
D.相似字符的相互干扰。在字符训练的过程中常出现的一个错误就是2 被识别成了Z。
神经网络分类器比其他分类器多了一个学习规则,更适用于本研究设计的系统,所以选择BP 神经网络识别方法。
运用本研究设计系统对运动目标编号进行识别的结果见表1,图像的识别正确率和平均反应时间还是比较理想的。从表1 中可以看出图像的识别正确率与图像的质量有很大关系,在下一步的研究中加入图像融合技术,可以使图像的质量更好,从而提高识别率,但也要保证系统的实时性。
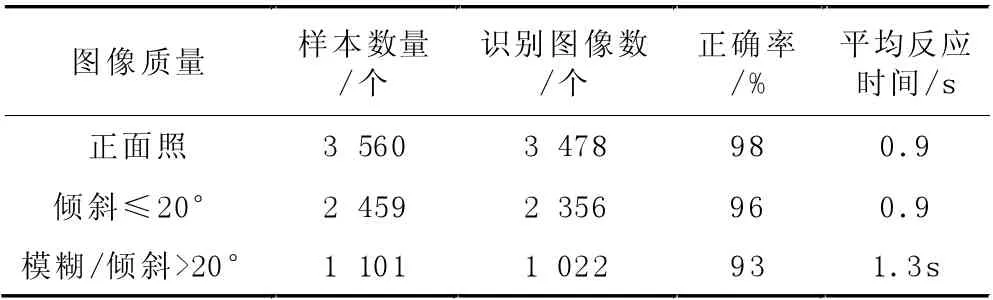
表1 运动目标编号识别结果的统计
4 结论
本研究研究了现有运行运动目标编号定位和识别系统的现状,查阅了大量国内外的技术文献和资料。经过对三层BP 神经网络识别方法进行识别技术的研究,提出了一种适用于运动目标编号区域的粗定位和精确定位两层定位方法。经过现场试验运行,表明本研究设计的运动目标编号自动识别系统对所采集图像的识别正确率是达到预期目标的。
