基于均方差算法的铁路信息系统智能监控动态基线技术
2022-09-09刘忏张鹏王朝晖孙强周翔豪
刘忏 张鹏 王朝晖 孙强 周翔豪
(中国铁路信息科技集团有限公司 北京市 100038)
随着铁路主数据中心的投入使用以及铁路云平台的应用,铁路信息系统基础设施的数据规模也在不断增长,铁路信息系统基础设施运维管理平台每天要对不同监控对象如网络交换机、服务器、数据库和中间件等进行实时监控,不仅体现在数据量的增长上,数据类型的种类也越来越复杂,每天产生的告警数量和告警类型也在不断增长。应铁路运维管理的要求,保证铁路信息系统的正常运行是当前的第一要务,这就要求一线运维人员能够及时处理系统各项报警信息,在第一时间使系统恢复正常,因此引入异常数据检测技术的必要性不言而喻。现有的数据异常检测通常依赖于设置固定的告警数值基线对各项监控指标进行监控,但由于监测方式不够智能,特别是考虑到铁路信息系统数据与具体时刻的相关性,传统的固定基线告警判定机制导致监测的结果不够精准,产生的告警信息会增加更多成本。因此引入动态基线管理技术,依托大数据分析技术计算运行趋势,配置动态告警阈值,使监控预警更加符合铁路业务实际使用情况,提高告警的精确性,最终实现提高铁路运维能力的要求。
1 动态基线技术
1.1 动态基线告警原理
动态基线告警原理是当监控数据超出了上容忍边界和下容忍边界时,监控系统将产生告警信息提醒运维人员,主要的流程如图1所示。

图1:动态基线告警流程
1.2 基线管理
基线的主要作用是划定一个区域,即数据正常产生波动的一个范围,它通常作为信息系统基础设施监控告警的判定条件,传统的简单设置阈值设置规定了数据正常变化的固定上下基准线,在此基础上还含有两个基准线,分别名为上容忍边界和下容忍边界,以MySQL 数据库DB time 监控指标为例,传统的基线管理如图2所示。

图2:传统基线管理
传统的基线管理中设置的两个容忍区域规定了数据可以容忍的波动范围,当实时获取的数据超过了两个容忍边界时系统将迅速产生告警。但是无论上下基线还是上下容忍边界,它们的数值都是在系统上线前人为规定的固定值,传统基线管理未考虑到上线容忍边界与其他变量的关系,特别是没有考虑到铁路业务与时间的相关性,比如客票业务的流量在不同时间段的差异,高铁的售票高峰期分别是在早九点到九点半,十一点半以及下午一点到一点半,两点到两点半和四点半。值得一提的时,在夜间时段,售票系统暂停使用。这就意味着如果上下容忍线在24 个小时内固定不变,将不符合数据的实际情况,假设上下容忍线根据白天的实际情况设置具体数值,那么夜间产生的告警可能因为容忍线不合适的取值区域而被漏掉,同时也会造成更多错误的告警,浪费更多资源最终导致运维效率的下降。图3为铁路主数据中心运维管理平台中获取到的连续六天客票系统MySQL 数据库DB time 监控指标的数值变化曲线图,我们可以发现监控指标DB time 在每日的变化趋势相似,这说明不同时刻的业务数据量与具体时刻具有关联性,所以根据不同时刻数据的具体数值设计的动态基线更加合理。
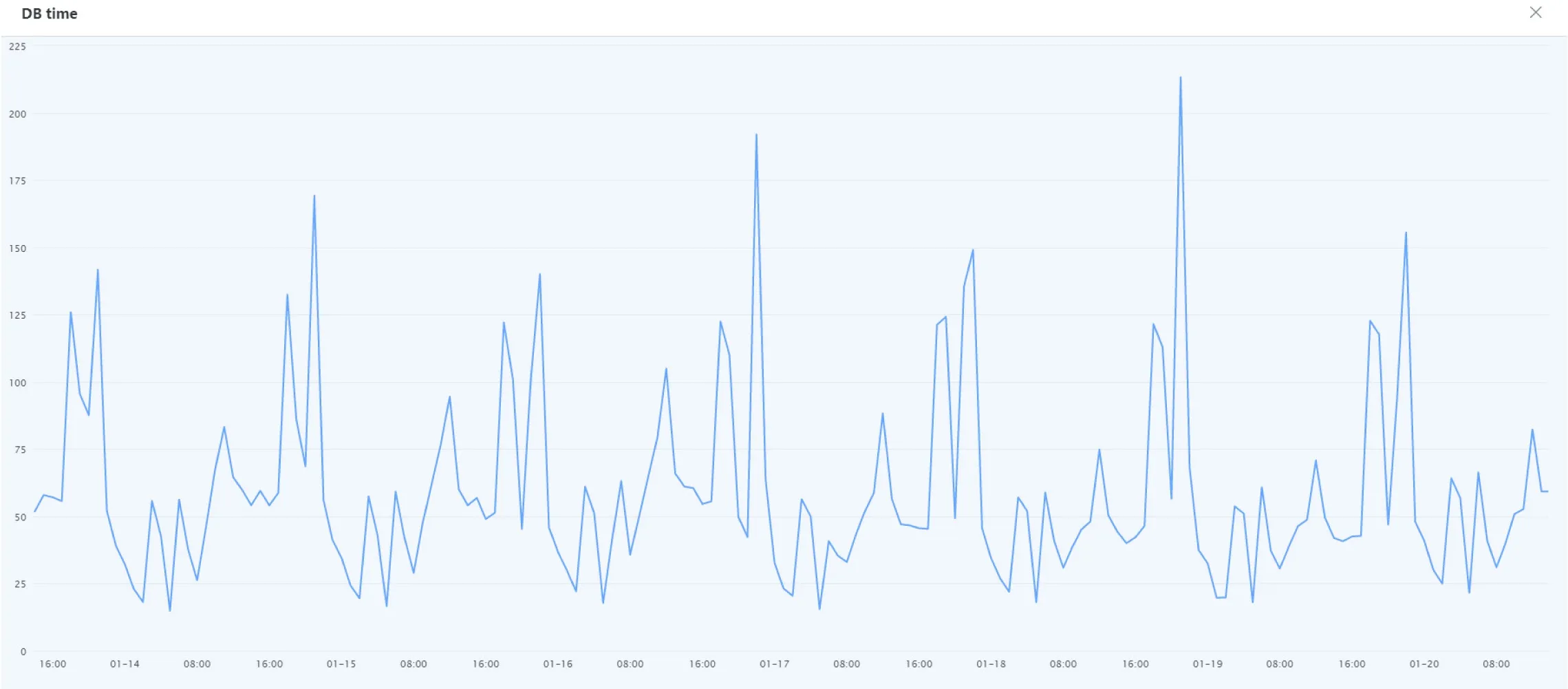
图3:DB time 数据折线图

表1:连续六天DB time 在整点的数据 单位:s
如果设定每间隔一小时取值一次,可以得到六天中共144 个数据,整理后得到的完整数据如表1所示,波峰主要位于18:00、19:00、21:00 和22:00 四个时刻,波谷出现在2:00和5:00,因此不同时刻数值的波动决定了基于固定基线的告警规则不够灵活,经过改进后的动态基线技术则针对此问题提供了新的解决方案,它可以根据不同时间段的数据流量根据以往的数据分布特征对基线和容忍边界进行动态调整,通过概率算法对在不同时间段特别是峰值与波谷值变化较大的监控指标如网络流量以及MySQL 数据库DB time 能够实时的改变基线和容忍边界的参考值,合理的划分数据正常与数据异常的区域。改进后的动态基线如图4所示。
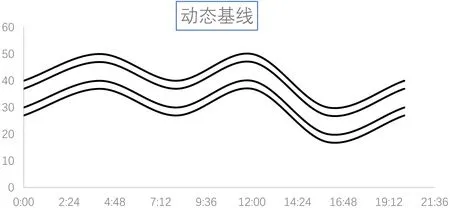
图4:动态基线示意图
2 基线算法比较
2.1 排序法
排序法是一种常见取值法,主要计算原理如下首先获取样本,将得到的样本数假设为X 个,然后设置样本有效概率,一般取95%,即样本空间中95%的数据为有效数据,将样本空间进行排序,分别取取最大值与最小值作为上基准线和下基准线。再根据容忍度计算容忍区间。
2.2 均方差概率算法
首先对预处理后的有效数据进行排序,假定共有N 个,分别记为x到x。假定有效数据的A%(对应基线的样本置信度)为可以接受而不用产生告警的指标值,滑动排序数据的窗口(共N×A%个数据),计算该窗口中数据的均方差。计算该窗口中样本的平均值作为期望值E(x)。计算窗口各个样本点对于数学期望的偏离程度,单个偏离是:
X-E(x)
为消除符号影响,一般取:
(X-E(x))
虽然排序法计算过程简单,但考虑到其结果不够精确,最终选择使用均方差概率算法来实现动态基线。
3 基线计算过程
动态基线的计算过程分共分为四部分,分别是历史数据样本的采集、数据样本降噪处理、动态基线算法计算处理数据、得到动态基线。计算流程图如图5所示。

图5:动态基线计算流程
3.1 历史数据样本空间的建立
建立基线的第一步是选取数据点,在采集历史数据时,需要主要样本空间能够包含尽可能完整的数据集合,首先样本点需要包含各个时间段的历史数据,这样才能确保得到的基线更加准确,以铁路主数据中心客票系统MySQL 数据库DB time 为例,我们选择采集一个月每天MySQL 数据库DB time 具体数值,较前面连续六天数据量相比样本空间含有更多的样本数量,从而能够得到较为精确的结果。图 是来源于铁路主数据中心运维管理平台采集到的一个月内MySQL数据库DB time 在所有时刻的完整数据。整理后的数值如表3所示。
3.2 样本预处理
由于采集到的数据样本受采集工具规定间隔时间影响,样本数量较大,采集上来的时间并不一定是整点数据,而在进行数据计算时。就需要将采集的历史数据先进性平滑处理,将时间都换算为整点数据,方便动态基线的计算。
3.3 动态基线算法
计算动态基线上下限采用基于标准差的概率算法。为方便展示,取三十天内每日九点整的数值进行计算,经过预处理后的样本数据集如表2所示。
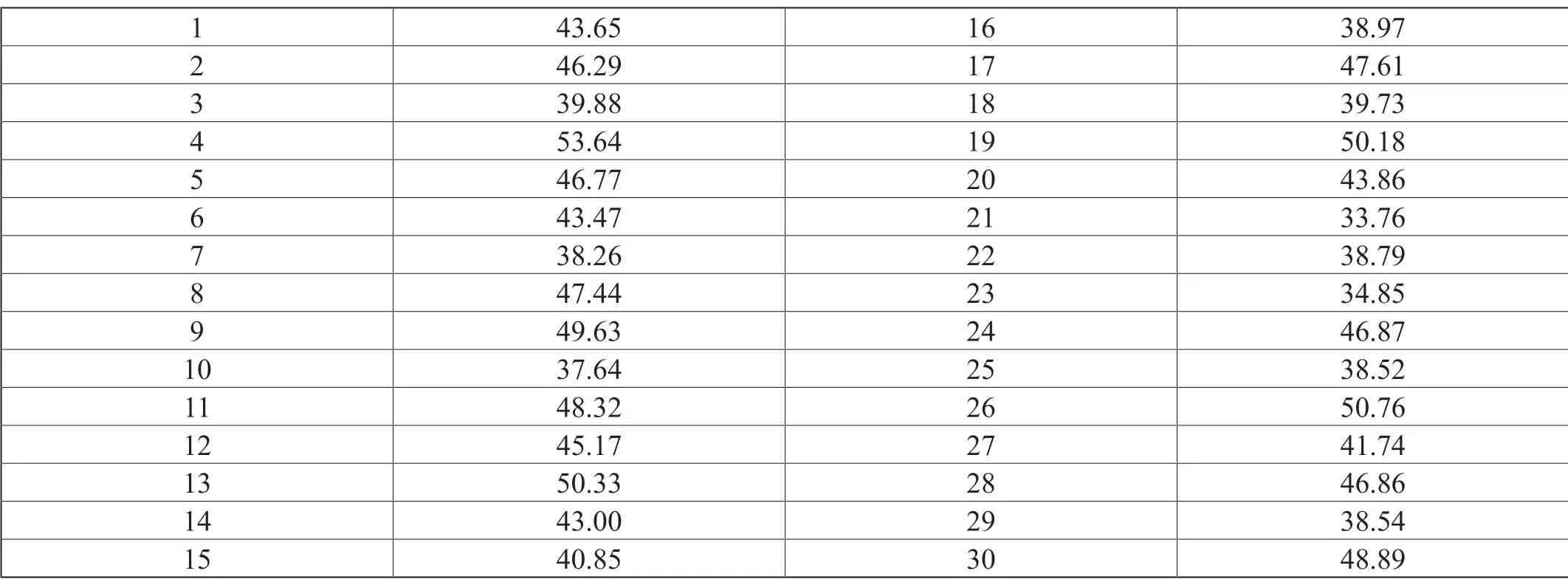
表2:三十天每日九时DB time 数据汇总表
取均方差最小的窗口中的数据,以其最大值作为基线的上限,最小值作为基线的下限。首先对数据集进行排序,得到的数列是[33.76,34.85,37.64,38.26,38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63,50.18,50.33,50.76,53.64]
首先去掉最大值与最小值,剩余28 个数据,按照概率算法过程,我们将选取其中的有效数据。第二步是数据分组样本空间最大值是53.64,所以得到9 个区间,分别为[0,6],[6.01,12],[12.01,18],[18.01,24],[24.01,30],[31.01,36],[36.01,42],[42.01,48],[48.01,54]。将28 个样本放入九个区间中可以得到以下结果
区间1:[ ]
区间2:[ ]
区间3:[ ]
区间4:[ ]
区间5:[ ]
区间6:[34.85]
区间7:[37.64,38.26,38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74]
区间8:[43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61]
区间9:[48.32,48.89,49.63,50.18,50.33,50.76]
通过统计发现在区间8 中的样本数最多,将区间8 的样本和相邻的区间7 与区间9 的样本汇总可以得到最终有效的样本空间:
[37.64,38.26,38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63,50.18,50.33,50.76]共计27 个数据。
设置窗口置信度为0.8,即80%作为作为历史样本的信赖程度,剩下的20%样本属于杂质数据,滑动窗口长度的计算公式图下
L=N×A%
这里A 取0.8,N 取27,所以窗口长度为21.。使用滑动窗口对27 个样本取值分别得到7 个窗口。
窗口1:[37.64,38.26,38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61]
窗口2:[38.26,38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32]
窗口3:[38.52,38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89]
窗口4:[38.54,38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63]
窗口5:[38.79,38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63,50.18]
窗口6:[38.97,39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63,50.18,50.33]
窗口7:[39.73,39.88,40.85,41.74,43,43.47,43.65,43.86,45.17,46.29,46.77,46.86,46.87,47.44,47.61,48.32,48.89,49.63,50.18,50.33,50.76]
分别对七个窗口的数据求均方差可以得到结果如表3所示:

表3:窗口均方差汇总表
可以发现,第七个窗口内的样本具有最小的均方值,所以选取该窗口的最大值与最小值作为动态基线的上下基线在九点整的取值。所以上基线与下基线分别为50.76 和39.73。接下来计算上容忍边界和下容忍边界,容忍边界的意义就在给数据一个可以容忍的超过基线的范围,当实时数据值越过了容忍边界,系统将产生告警信息。容忍边界的计算公式如下:
B=(1+T)×L
B=(1-T)×L
其中B和B分别代表上容忍边界和下容忍边界,T代表容忍度,L和L分别代表前面得到的上基线和下基线,这里我们将T 设置为0.1,也就是10%,最后得到上下容忍边界为55.84 和35.76。最后我们得到了上午九点整的上下基线和上下容忍边界具体数值。以此类推,根据30 天内完整的整点时刻的样本数据,最终可以得到24 小时内包含每个时刻的动态基线模型如图6所示,动态基线模型使用历史数据形成的24 小时内阈值的变化趋势,与传统的固定基线模型相比性能更加优异,能够显著减少错误告警的数量,提高运维管理工作效率。
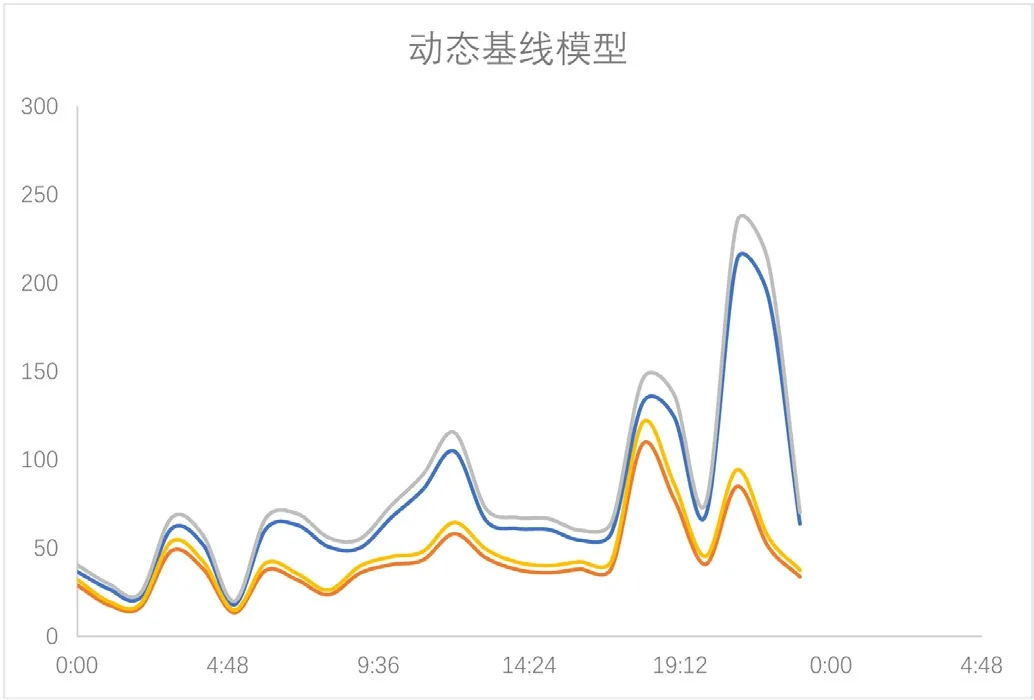
图6:动态基线预测图
4 智能阈值配置
在监控指标繁多,设备数量巨大的背景下,引入阈值的智能配置功能的必要性不言而喻。区别于传统阈值的人工手动配置,智能阈值配置主要实现告警阈值的自动计算与设置,不同监控指标的告警阈值可以根据实际业务的情况实时浮动变化,能够进一步提升告警的准确性,最终实现提高运维效率的目的,实现智能阈值配置的主要方法是运用动态基线技术,通过对海量历史数据的计算与分析,预测某个时间点的正常数据范围,当实时数据超过了正常范围,将会产生报警,提醒运维人员处理故障。
5 结束语
本文通过分析铁路实际业务情况,对基于均方差的动态基线计算方法进行了探讨,以动态基线为基础的智能阈值技术可以有效减少错误告警,为运维人员提供了有效的数据参考,提升运维效率。但本文中展示的计算过程中为方便展示,只提取了一个月内的MySQL 数据库DB time 整点数据。但在实际的运行环境中有更多影响动态基线的变量,例如在节假日时具体数据会较平日有所不同。所以在动态基线实际的应用过程中,需要历史数据形成的样本空间足够大,比如将整年的数据都放入样本空间,从而能够涵盖更多时刻如重大节假日的监控数据,这样才能保证最终获得准确的基线。除了样本空间的选择之外,在选择基线算法时也可以考虑建立基于机器学习的动态基线模型,结果也将更为精准。
