基于梯度提升决策树的注射成形产品外观缺陷在线检测
2022-09-09黄佳文蒋昌猛董添文阮宇飞
黄佳文 蒋昌猛 董添文 阮宇飞
(上饶师范学院 江西省上饶市 334000)
1 引言
塑料注射成形产品的外观缺陷检测是塑料生产中的关键程序,产品的外观缺陷不仅会影响美观,而且还会降低产品的装配精度和使用性能。现有产品外观缺陷检测主要还是采用人工检测方法,这一类方法对检测人员的依赖度高,检测效率低,漏检率高,很难满足当前的高精度、快速注射成形生产的需求。因此,开发高效、精确、便捷的注射成形产品外观缺陷检测检测方法,是当前注射成形加工领域的迫切需求。
为了实现对注射成形产品外观缺陷的高效、精确检测,现有的研究主要采用基于机器视觉技术的非接触检测方法。如Ha 等人提出了一种基于卷积神经网络(Convolutional Neural Networks,CNN)的边缘智能注射成形缺陷检测方法,该方法通过采用数据增广,有效解决了数据样本过小和数据不平衡的问题,所提出的检测模型准确率达到了90%以上。Liu 等人提出了一种知识重用策略来训练卷积神经网络模型,以提高外观缺陷检测的准确性和鲁棒性,通过引入基于模型的迁移学习和数据增强,将来自其他视觉任务的知识转移到当前的缺陷检测任务中,从而在有限的训练样本下实现高精度的外观缺陷检测。上述这一类基于机器视觉的产品外观缺陷检测方法可以实现对成形产品外观缺陷的快速检测,同时也具备较高的检测精度,但也存在着一些弊端,其检测精度容易受外界环境的影响,如光线角度、零件摆放位置等,都会影响最终的检测结果,且基于机器视觉的检测平台搭建复杂,硬件成本和使用成本高昂,限制了这一类方法在缺陷检测领域的广泛应用。
另一类缺陷检测方法主要是通过安装额外的传感器,采集注射成形过程中的大量过程数据,通过对这些过程数据的处理与分析,预测当前批次生产的产品是否存在缺陷。如Chen 等人通过采用模内温度和压力传感器中采集的实时数据,提出了一种基于人工神经网络 (Artificial Neural Network,ANN)的在线缺陷检测方法,检测的准确率达到了94%以上。这一类基于过程数据的检测方法,相对于基于机器视觉的方法实现简单,同时也具备较高的检测精度,但是基于神经网络模型的训练需要大量的数据,而大量训练数据的获取通常比较困难,而且存在着训练时间较长,成本较高的问题,显著限制了这一类方法在工业界的使用。
针对现有技术存在的上述问题,本文提出了一种基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的注射成形产品外观缺陷检测方法。所提方法通过注射机内置的和模内安装的温度和压力传感器,在线采集每一个注射成形批次过程中的料筒压力、喷嘴温度、模内压力、模具温度数据。对采集得到的数据进行预处理之后,采用无监督学习中的主成分分析(Principal Component Analysis,PCA)算法,分别对每一类数据进行降维,并结合K-means 聚类方法,得到当前成形批次的4 个特征数据。进一步地,针对不同类型的数据,采用基于统计分析的方法,得到4 个对应的特征数据。构建基于梯度提升决策树的分类模型,利用上述得到的8 个特征数据构建训练数据集,并训练所构建的分类模型,从而实现对注射成形产品外观缺陷的在线检测。实验结果表明,本文所提方法在较小的训练数据集下,就能够有效检测当前批次成形的产品是否有外观缺陷。
2 数据采集与特征提取
2.1 数据采集
本文所提方法中共涉及到4 类数据,按采集方式的不同,可以分为以下两大类:
(1)内置传感器采集;
(2)外置传感器采集。
其中内置传感器采集是指利用注射机本身内部自带的传感器采集数据,包括了喷嘴温度数据和料筒压力数据的采集。如图 1(a)所示为内置传感器数据采集示意图,数据在线采集过程中,通过并联的方式从注射机控制系统的IO 接口中,将传感器的输出信号接入数据采集卡中,数据采集卡通过串口通讯与计算机实现数据交互,从而按设定的采样周期实现对喷嘴温度数据和料筒压力数据的采集。外置传感器采集的数据包含了模内压力、模具温度数据,通过在模具内安装型腔压力传感器和温度传感器,采集模具内部的压力和温度数据。数据采集平台如图 1(b)所示,传感器采集的信号接入数据采集卡,数据采集卡通过串口通讯与计算机实现数据交互,从而实现对模内压力和模具温度数据采集。
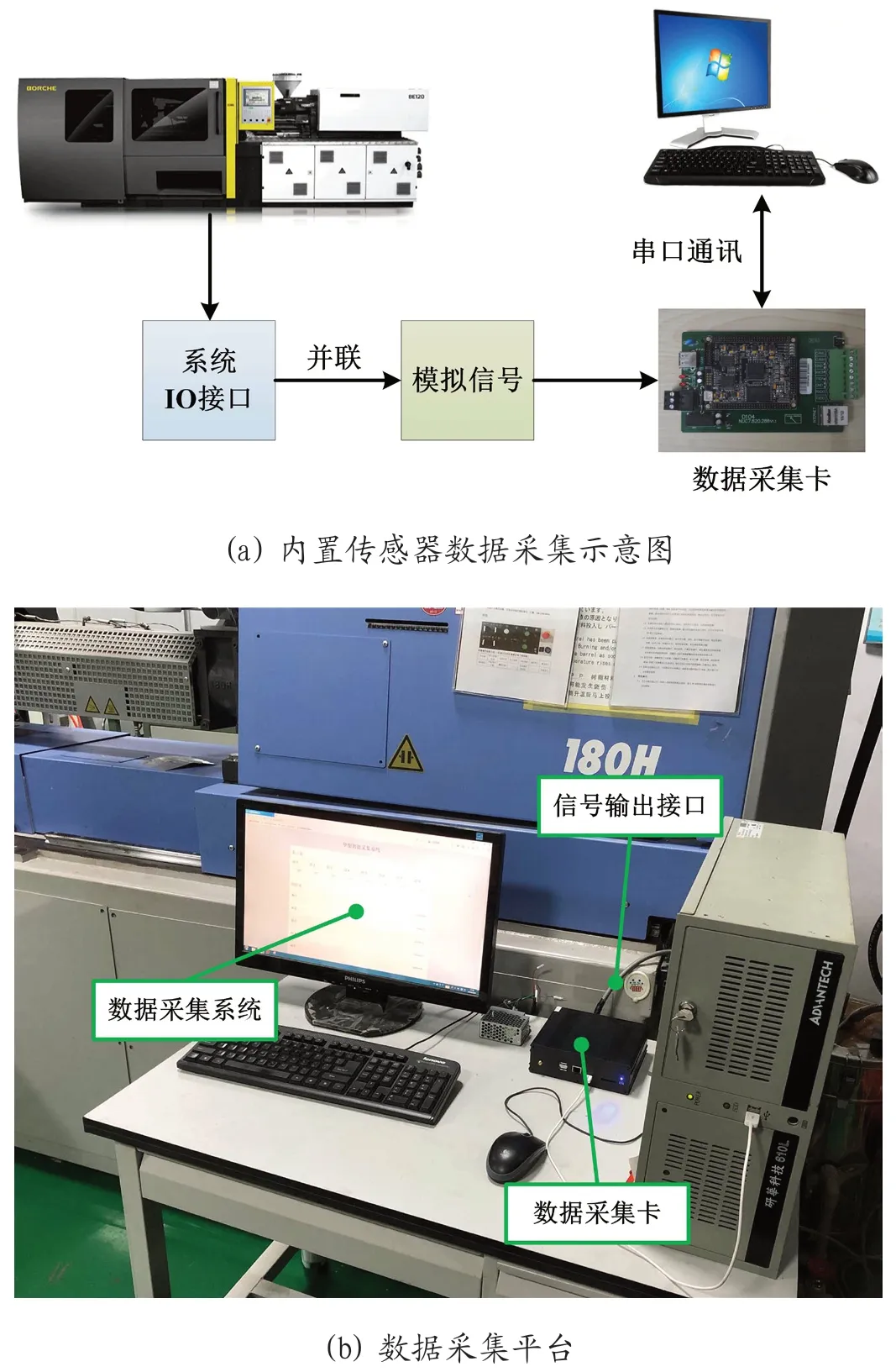
图1
2.2 特征提取
采集得到数据不可避免会存在噪声的干扰,因此在进行特征提取之前首先要进行数据预处理,从而尽可能地降低由于噪声对最终检测结果带来的影响。针对本文中涉及到的4类数据,根据不同数据的特点,分别采用两种不同的数据滤波方法,共提出得到8 个特征数据。针对在同一个周期中数据变化较大的压力数据,本文采用递推平均滤波法,对采集的压力数据进行滤波。具体如公式(1)所示:


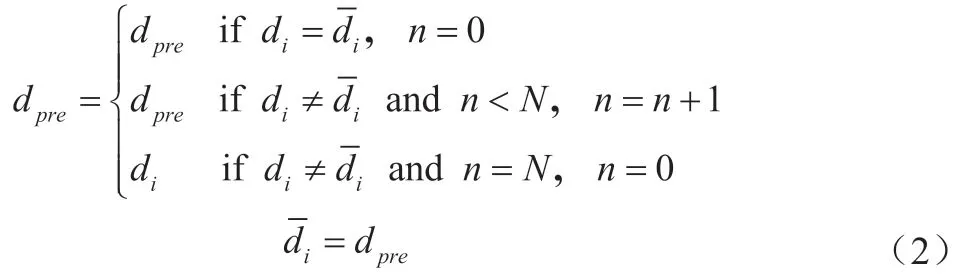

进一步地根据滤波后的数据提取特征数据,针对前述的4 类数据,本文提出首先采用PCA 算法对滤波后的高维数据进行降维,再对降维后的数据采用K-means 算法聚类,寻找低维空间中的聚类中心,然后计算样本到聚类中心的位置作为特征数据,针对某一类数据,具体特征计算流程如下:
(1)构建一个由已知无缺陷产品的数据组成的数据集D,数据集的样本数为N,每个样本的长度为M;
(2)将当前样本的数据加入到上述已构建的数据集中,得到新的数据集D,数据集的样本数为N+1,每个样本的长度为M;
(3)对得到的新数据集采用PCA 降维,得到降维后的数据集为F,其中k 为降维后每一个数据样本的维度大小,在本文中k 的取值为3,本文中涉及的4 类数据对于大部分样本降到3 维后依旧能够保留95%以上的原有信息;
(4)对降维后的数据集按列进行归一化处理,使每一列的数据都分布在0 到1 的范围内;
(5)采用K-means 算法对上述归一化后的数据进行聚类,得到上述N+1 个样本在三维空间中的聚类中心坐标(x,y,z);
(6)计算当前样本在三维空间中到聚类中心的欧式距离,把距离作为当前样本数据的一个特征值。
根据上述计算流程,分别计算滤波后的4 类数据的特征值,得到每个样本的4 个特征数据,进一步地,根据不同数据的特性,本文提出了另外两种提取特征数据的方法。首先,针对压力数据,本文提出采用压力对时间的积分作为注射压力和模内压力的特征数据,具体的计算如公式(3)所示:

其中,p(t)表示一个批次中滤波后的压力数据,t 为压力采样时间。根据上述公式分别计算每个样本的注射压力和模内压力对时间积分,即可得到与压力相关的两个特征数据。针对料筒温度和模具温度数据,本文提出采用每个批次中温度的总体标准差作为温度的特征值,总体标准差可以很好地反应温度的波动情况,而在注射成形生产中,温度的波动是影响最终成形产品外观质量的一个关键指标。总体标准差的计算如公式(4)所示:

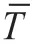
3 缺陷检测模型
本文采用基于GBDT 的方法构建注射成形产品外观缺陷检测模型,GBDT 是一种集成学习模型,模型由多个基分类器组成,每一个基分类器就是一棵分类回归树,因此GBDT可以看成是由多棵分类回归树组成的加法模型,可用如下函数描述:

其中,g(x|γ)为基分类器,θ为基分类器的系数,γ为基分类器的参数,M 为基分类器的个数。在模型训练过程中,通过采用串行的方式训练多个基分类器,每一个基分类器学的之前所有分类器结果和的残差,在训练的过程中,对于给定的训练数据集和损失函数L(y,f(x)),训练过程可用求解如下公式的最小值描述:



表 1:工艺参数设置

表 2:训练与验证数据集

表 3:样本标签及结果定义

表 4:缺陷预测结果对比
(1)初始化;
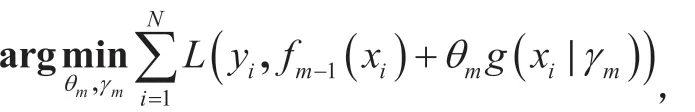


GBDT 模型具有鲁棒性强、适用于本文中的低维数据、调参快捷等优点,但作为一种提升算法,GBDT 模型中多个基分类器之间具有强的依赖性,模型训练过程中需要依次训练每一个基分类器,训练过程耗时比较长,而且在样本较小的情况下,GBDT 模型泛化能力较差,通常会面临过拟合的问题。针对以上两个问题,本文分别提出了相应的解决方案。首先,针对训练时间比较长的问题,作为一种提升算法,模型中的每一个基分类器都要依次进行训练,不同的决策树之间无法实现并行化训练,因此无法通过采用每个基模型并行训练的方式降低训练的时间。在每一棵决策树的训练中,最耗时的步骤是对所有特征值进行排序,根据前述的分析,本文共提取了8 类特征值用作模型的训练,如果在每一棵决策树的训练中都要对这8 类特征进行排序,该步骤会耗时非常多。因此,本文提出一种改进措施,在进行模型训练之间,对所有的特征进行排序,并分别保存每一类特征排序后的结果,从而在后续的迭代训练中,可以直接根据已经排好序的特征数据去选择最佳的分割点,而且可以实现8 类不同的特征可以并行计算,从而显著缩短模型训练的时间。
进一步地,针对GBDT 模型存在的泛化能力较差的问题,本文通过在原先损失函数的基础上,加入了正则项,从而提升所训练模型的泛化能力,加入正则项之后的损失函数如下所示:


4 实验验证
4.1 实验设计
为了验证本文所提方法的有效性,本文设计了多个对比实验,验证本文所提方法的有效性。实验所用注射机为博创公司生产的BS180 型注射机,所用模具为一模两腔哑铃型样条模具,所用模具和成形产品的实物图如图2所示,实验所用材料为聚丙烯(PP)。实验过程中相关工艺参数的设置如表1所示。

图2
实验中注射压力和模内压力的采集频率为1000Hz,喷嘴温度和模具温度的采集频率为2 Hz。所用训练数据集和验证数据集的构成如表2所示。
数据集中正类和负类样本的标签及预测结果的定义如表3所示,1表示正类,有外观缺陷的注射成形产品,0表示负类,外观无缺陷的产品。对于缺陷检测模型的预测结果,这里给出了4 种定义,其中TP 表示真阳,即模型预测结果为正类,实际也是正类样本。FP 表示假阳,模型结果预测为正类,实际是负类样本。FN 表示假阴,模型预测为负类,实际是正类样本。TN 表示真阴,模型预测为负类,实际为负类样本。
4.2 实验结果与讨论
为了验证本文所提方法的有效性,本文通过采用三个不同的模型进行实验对比验证。其中,模型一为本文所提方法,首先提取8 类特征,然后构建基于GBDT 的缺陷预测模型。模型二为只提取6 类特征,相比于模型一中减少了喷嘴温度和料筒压力的统计特征,预测模型依旧是基于GBDT 算法构建。模型三为基于支持向量机(SVM)算法构建,模型的输入为与模型一相同的8 类特征数据。三个不同模型的预测结果如表4所示,从表中可以看到,当采用相同的特征数据集时,在本文所提方法下,模型对注射成形产品外观缺陷检测准确率达到了95.2%,要显著高于采用基于SVM 的模型。而当采用只提取了6 类特征作为输入的模型二时,虽然依旧是基于GBDT 算法的模型,但相比于采用8 类特征的模型一,其检测的准确率会有较大的降低,只有90.7%,但相比于基于SVM 的模型其准确率还是有一定的提高。
进一步地,本文采用受试者工作特征(Receiver Operating Characteristic,ROC)曲线来评价三种模型的缺陷检测结果。如图3所示为不同缺陷检测方法下预测结果的ROC 曲线,图中横坐标表示假阳率,其定义为FPR=FP/(FP+TN),纵坐标表示真阳率,其定义为TPR=TP(TP+FN)。图中红色的虚线表示随机猜测的检测结果,曲线越靠近左上角则表明缺陷检测的准确率越高,而ROC 曲线下的面积(AUC)越大,则表明模型的效果越好。从图中可以看到,本文所提方法的ROC 曲线最靠近左上角,其AUC 达到了0.97,而采用SVM 的检测模型,其ROC 曲线是最靠里的,AUC 只有0.90。采用6 类特征的GBDT 模型,其ROC 曲线介于上述两个模型之间,AUC 为0.93。上述结果表明,本文所提模型在注射成形产品外观缺陷检测性能上,要显著优于SVM 模型,而在相同模型条件下,采用本文所提的特征提取方法提取的8 类特征训练的模型,其检测性能要优于只有6 类特征的模型,验证了本文所提方法在特征的提取、分类模型的构建上的优异性。

图3:不同方法缺陷预测结果ROC 曲线对比
为了进一步验证本文所提方法的有效性,本文采用了精准率-召回率(Precision Recall,PR)曲线评价模型的性能。在模型结果的PR 曲线中,曲线越靠近右上方,表明模型的效果越好,模型A 的PR 曲线被另一个模型B 的PR 曲线完全包住则说明模型B 的性能要优于模型A。如图4所示为注射成形产品缺陷检测结果的PR 曲线的对比,可以看到图中蓝色的,本文所提模型的PR 曲线完全把另外两个模型的PR 曲线包住,且模型的AP 值(曲线下的面积)达到了0.82,要显著高于另外两个模型的0.68 和0.62。

图4:不同方法缺陷预测结果PR 曲线对比
5 结束语
本文提出了一种基于梯度提升决策树的注射成形产品外观缺陷在线检测方法,所提方法通过注射机内置的和模内安装的温度和压力传感器,在线采集每一个注射成形批次过程中的多种压力、温度数据,并采用无监督学习和统计分析的方法提取得到8 类特征数据,利用上述特征数据,构建并训练基于梯度提升决策树的分类模型,实现了对注射成形产品外观缺陷的准确检测。
