Multi-Modal Domain Adaptation Variational Autoencoder for EEG-Based Emotion Recognition
2022-09-08YixinWangShuangQiuDanLiChangdeDuBaoLiangLuandHuiguangHe
Yixin Wang, Shuang Qiu, Dan Li, Changde Du, Bao-Liang Lu, and Huiguang He
Abstract—Traditional electroencephalograph (EEG)-based emotion recognition requires a large number of calibration samples to build a model for a specific subject, which restricts the application of the affective brain computer interface (BCI) in practice. We attempt to use the multi-modal data from the past session to realize emotion recognition in the case of a small amount of calibration samples. To solve this problem, we propose a multimodal domain adaptive variational autoencoder (MMDA-VAE)method, which learns shared cross-domain latent representations of the multi-modal data. Our method builds a multi-modal variational autoencoder (MVAE) to project the data of multiple modalities into a common space. Through adversarial learning and cycle-consistency regularization, our method can reduce the distribution difference of each domain on the shared latent representation layer and realize the transfer of knowledge.Extensive experiments are conducted on two public datasets,SEED and SEED-IV, and the results show the superiority of our proposed method. Our work can effectively improve the performance of emotion recognition with a small amount of labelled multi-modal data.
I. INTRODUCTION
EMOTION is a psychophysiological process triggered by the perception of stimulus, which plays a vital role in human behaviour, action and decision making [1]. With the development of human and machine communication, emotion recognition has increasingly become important for an advanced human-computer interaction system [2]. Since emotions are accompanied by a variety of external manifestations, the range of indicators of emotional state is wide, including facial expressions [3], voice [4], body language [5] to physiological signals [6]. Compared with other signals, physiological signals can capture participants’ underlying responses. Electroencephalogram (EEG), as a high-resolution and effective physiological signal, has been widely used in the field of emotion recognition [7].
In conventional EEG-based emotion recognition, it is necessary to collect a large amount of calibration data from one person to train the effective model of this person to get good performance [8]. However, the collection of calibration data is time-consuming, which severely hinders the application of BCI in practice. A major challenge is using a small amount of data to quickly build a model. To address this issue,we design a multi-modal domain adaptation method to use the data from more modalities and previously collected data to improve classification performance under a small amount of samples.
It is difficult to precisely discriminate complex emotions using only one signal [9], while multi-modal fusion can exploit the complementarity of different signals. Recent studies indeed show that fusion of multiple modalities can improve emotion recognition performance significantly[10]–[12]. EEG has been reported to be a promising indicator to reflect emotion states since EEG signals can directly reflect brain activity [13]. Also, eye movement signals have become widely used for emotion recognition. It is because that they are important cues for context-aware environment, which convey important information for emotion recognition [14].These two modalities combining central nervous signal and external behaviour have been considered to be a promising way to describe emotional states [11], [15]. Thus, we conduct this research on multi-modal signals (EEG signals and eye movement signals). Furthermore, we consider using a large amount of data collected by subjects on different days to improve the performance of emotion recognition, especially under a small amount of calibration samples. However, there is remarkable variability between the data collected in different days from one subject (which is also called a session). It is difficult to acquire multi-modal models that can work across sessions. Domain adaptation can be used to make the distribution of the source domain close to that of the target domain to improve the target domain’s performance. The large amount of data collected in the past session from one subject is regarded as the source domain, and the small amount of data collected in a new day from the same subject is regarded as the target domain. In this paper, we try to use domain adaptation to build a cross-session multi-modal model for the improvement of emotion recognition. This has not been studied in previous studies [16].
There are three main challenges for multi-modal domain adaptation. Firstly, due to the addition of multi-modal information, we need to jointly model the heterogeneous features of different modalities to achieve semantic alignment. Secondly,there exists a domain gap between the source domain and the target domain, we need to reduce the distribution differences of each domain to effectively utilize the knowledge of the source domain. Thirdly, there are some samples that have incomplete modal representations, and it is desirable to solve the missing modality problem.
To resolve the problems mentioned above, we propose a multi-modal domain adaptive variational autoencoder (MMDAVAE) method. Firstly, we build a multi-modal variational autoencoder (MVAE) to model the relationship of multimodal emotional data, which can map multi-modal data in different domains into the same latent representation in a shared-latent space, and train a cross-session classifier on the shared-latent layer. On the one hand, the data from different domains (the source domain and the target domain) share the encoder paths of the MVAE, ensuring similarities between multi-modal data from different domains. On the other hand,we set up independent decoder paths of MVAE for each domain, which retains the characteristic of each domain’s modality on the reconstruction layer. Secondly, in order to use the characteristic information of each modality, our method constrains the reconstructed data through adversarial learning loss and cycle-consistency loss rather than performing the transfer operation on the shared-latent layer. By performing domain confusion of each modality and multi-modal generation across domains in the reconstruction layer, the distance between the source domain and the target domain in the latent representation space can be implicitly shortened. In addition,we use the product of experts (PoE) rule to train the joint inference network for the joint posterior of the MVAE, which can efficiently learn the combined variational parameters missing modalities.
Our contributions are as follows. 1) We introduce the MMDA-VAE model that learns shared cross-domain latent representations of the EEG and eye movement data. 2) We propose two constraints: both adversarial learning loss and cycle-consistency loss to solve the multi-modal domain adaptation problem. 3) We extensively evaluate our model using two benchmark datasets, i.e., SEED and SEED-IV. The results show the superiority of our proposed method over traditional transfer learning methods and state-of-the-art deep domain adaptation methods.
II. RELATED WORK
Multi-Modal Fusion:Multi-modal fusion is the concept to join information from two or more modalities to perform in some tasks [17], [18], which has been widely implemented for emotion recognition [11], [12], [19]–[22]. Luet al.[11] used a fuzzy integral strategy to achieve modality fusion on EEG and eye movement signals. Liuet al.[20] used a bimodal deep autoencoder (BDAE) to extract shared representations of EEG and eye movement for the prediction of emotion states. Ranganathanet al.[12] exploited a multi-modal deep Boltzmann machine (DBM) to model feature distributions from face,body gesture, voice and physiological signals jointly for emotion classification. Multi-modal fusion can use more information provided by multi-modal data compared to single modal data, which improves the performance of emotion recognition. But there are two problems: When multi-modal data from different domains are simply input into the emotion recognition model. It becomes difficult to deal with missing modality [23].
Single-Modal Domain Adaptation:There are two categories of existing, shallow domain adaptation methods and deep domain adaptation methods [16]. Many traditional shallow domain adaptation methods have been applied in the emotion recognition field. Zheng and Lu [24] used four algorithms:transductive component analysis (TCA) [25], kernel principal component analysis (KPCA) [26], transductive support vector machine (TSVM) [27], and transductive parameter transfer(TPT) [28] based on SVM to build a general model for new target subjects. Chaiet al.[29] proposed an adaptive subspace feature matching (ASFM) method, developed a linear transformation function to match the marginal distributions of the two domains’ subspaces. In recent years, with the rapid development of deep learning, deep domain adaptation methods have become a popular research topic in the emotion recognition field. Liet al.[30] proposed a bi-hemisphere domain adversarial neural network (BiDANN) method to improve the generality of the EEG-based emotion recognition model. Liet al.[31] used association reinforcement loss on deep neural network (DNN) to adapt the joint distribution of the source and target domains. Single-modal domain adaptation has been widely studied and successfully applied to classification problems with a small number of samples. However, few studies explored the domain adaptation of multiple modalities.These methods simply used cascade features as input to deal with multi-modal problems without mining the relationships between modalities. By our model, the source and the target domain can make full use of the information from more than one modality to get better performance.
Cross-Modal Generative Models:The variational autoencoder (VAE) [32] is one of the deep generative models, which can be used to reconstruct data across domains in the field of domain adaptation. The VAE-based models use cross-domain reconstruction to capture the common information contained in the two domains in the shared latent-space. Shenet al.[33]proposed cross-aligned VAE to ensure that the latent text space of different domains have similar representations. Liuet al.[34] modelled each image domain by a VAE-GAN architecture and matched the latent representations from different domains. The VAE-based model has the structure of an encoder and decoder. While reducing the dimension, it ensures that the hidden layer can extract cross-modal and cross-domain information [35]–[37]. This reconstructed structure is naturally suitable for solving the problem of multimodal domain adaptation. These methods have been used previously for text-style transfer [33] and image-to-image translation [34], which were rarely applied to multi-modal electrophysiological data. Therefore, they have the potential to solve similar problems in the field of emotion recognition.
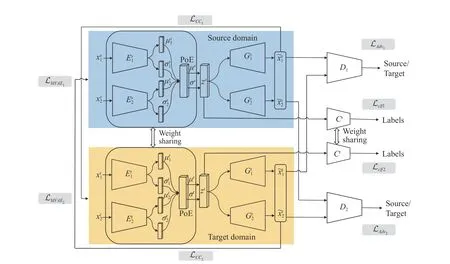
Fig. 1. The proposed MMDA-VAE framework. Two dashed boxes connected by the double arrow illustrate that the encoders of the target domain E 1t andE2t share the weights of the source domain E 1s and E 2s. We represent the encoders and decoders using DNNs and use the PoE network to combine all the encoders and solve the modality missing problem. Here, ~x1s and ~x2s are reconstructed from the source domain. ~xt1 and ~xt2 are reconstructed from the target domain. D1 and D2are adversarial discriminators for the respective modalities. In addition, we feed the reconstructed multi-modal data into the paths of the other domain and constrain the output to be same as the original data to achieve the VAE-like cycle consistency loss.
III. METHODOLOGY
A. Background


B. MMDA-VAE
In this section, we first introduce a MVAE model [38],which learns the joint latent representation from multi-modal data. And then, we extend it to the multi-modal domain adaptation by adding discriminators for adversarial learning and cycle-consistency constraints. The whole structure of our method is shown in Fig. 1. For the sake of readability, we list frequently used symbols and their definitions in Table I.

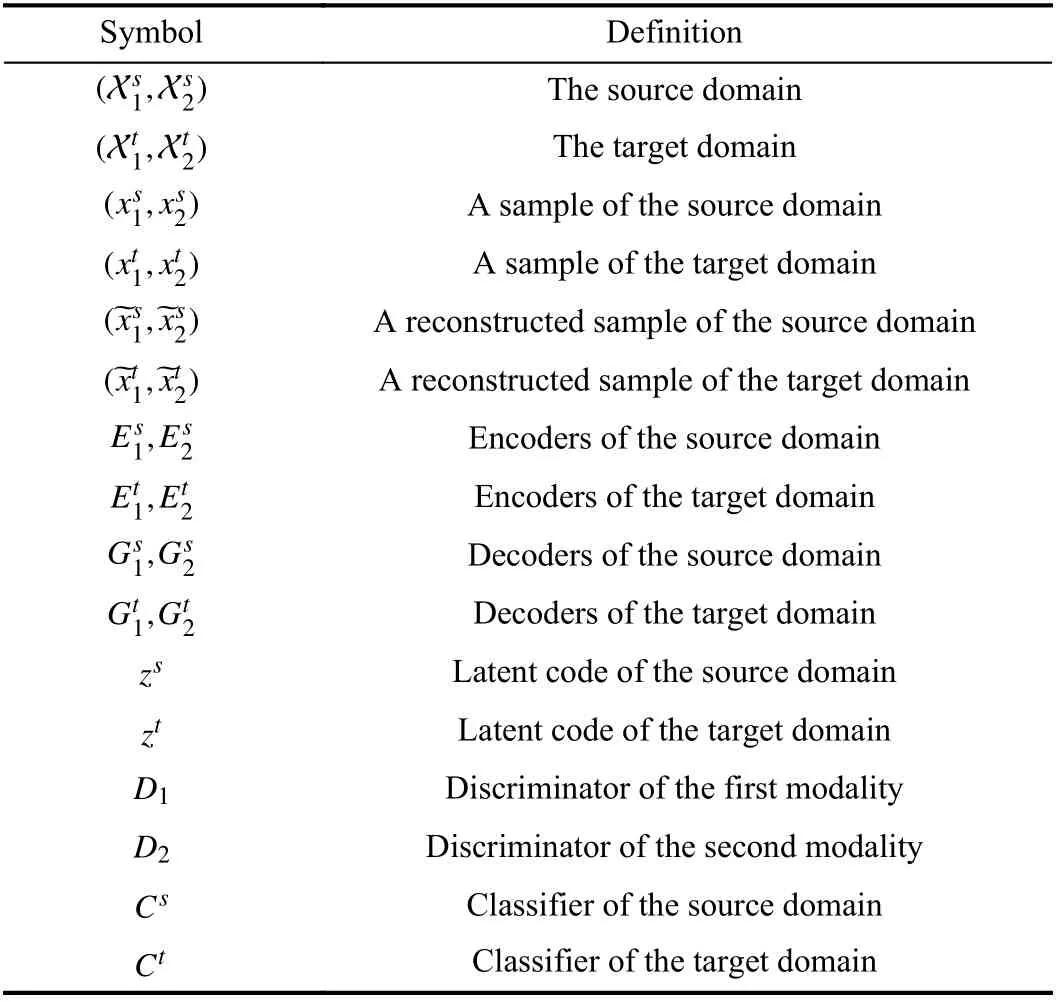
TABLE I DEFINITION OF FREQUENTLY USED SYMBOLS



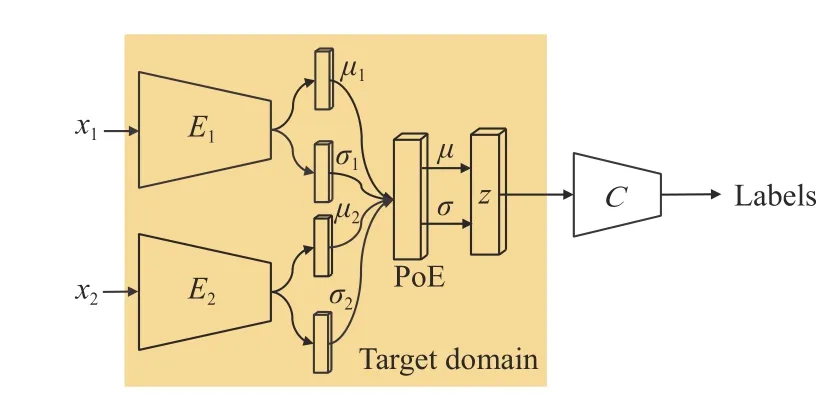
Fig. 2. The inference procedure of MMDA-VAE. The test sample is sent to the shared encoder path to get the latent representation z, and the final classification label is obtained through the classifier with shared parameters.
IV. EXPERIMENTS
A. Datasets
SEED [11]:There were 15 film clips chosen to evoke three target emotions (positive, negative and neutral). The duration of each film clip was around four minutes. Fifteen volunteers were asked to watch these films three times, at an interval of one week or longer. There were 15 trials (five trials per emotion) for each session and the film clips for these three sessions were repeated. The raw EEG data was simultaneously recorded at a 1000 Hz sampling rate with 62 channels using the ESI NeuroScan System. Nine of the volunteers also simultaneously recorded eye movements. Since only nine volunteers collected eye movement signals, we used the data of these nine volunteers in our paper.
SEED-IV [40]:There were 72 film clips chosen to evoke four target emotions (happy, sad, fear, and neutral). The duration of each film clip was approximately two minutes.Fifteen volunteers were asked to watch these films in three days as three different sessions. Each session consisted of 24 trials (six trials per emotion), and the stimuli for these three sessions were completely different. The raw EEG data was simultaneously recorded at a 1000 Hz sampling rate with 62 channels using the ESI NeuroScan System. Eye movement signals were also simultaneously recorded using SMI ETG eye-tracking glasses.
For both two datasets, we performed similar data preprocessing and feature extraction. To further filter the noise and remove the artefacts, the EEG signals were processed with a band-pass filter between 1 and 75 Hz. Then,the EEG and eye movement data were re-sampled to reduce the computational complexity and align these two modalities.
After data preprocessing, we extracted the differential entropy (DE) [41] feature from EEG data. The DE feature is defined as follows:
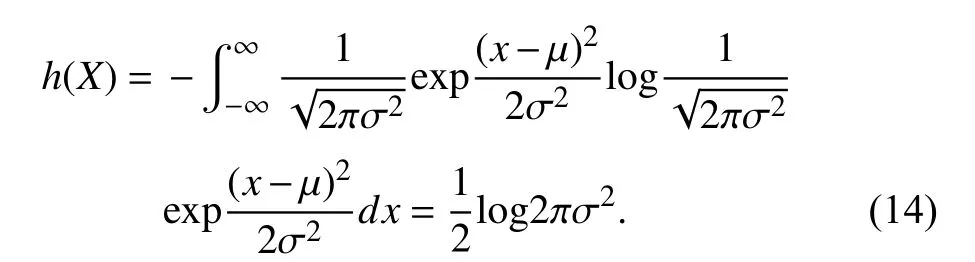
For SEED, short-term Fourier transforms with a 1 s time window without overlapping was used, for SEED-IV, we used a 4 s time window. The length of the EEG segment is strictly based on the setting in the originally published paper [11],[40]. The DE features can be calculated in five frequency bands: delta (1-4 Hz), theta (4-8 Hz), alpha (8-14 Hz), beta(14-31 Hz), and gamma (31-50 Hz), where we used all bands features for these two datasets. As for eye movements, the parameters collected by the eye tracker include pupil diameter,fixation dispersion, saccade amplitude, saccade duration, and blink. We extracted features such as mean, standard deviation,DE and so on, the details of which were consistent with the original literature [40].
B. Setup
We regarded three sessions of the same subject as three domains, where the target domain was one session data of the subject, and his/her existing sessions too turn as the source domain. Thus, we could create six transfer tasks: 1→2, 1→3,2→1, 2→3, 3→1, 3→2 on both two datasets.
The training set consisted of the source data and the labelled target data, i.e., all the samples from the source session and samples from the first three or four trials (one trial per class)in the other target session. We used samples from the second three or four trials in the target session as the validation set.The samples from the rest of the twelve or sixteen trials in the target session were used to evaluate classification accuracy.The average accuracies of all the subjects in the dataset were reported. The details of two datasets used in our experiments were summarized in Table II.

TABLE II PROPERTIES OF THE DATA USED IN EXPERIMENTS

C. Compared Methods
Our method was mainly compared with two types of methods, namely, the multi-modal fusion method and the single-modal domain adaptation method.
Multi-Modal Fusion Method:Since modality fusion based on multi-modal electrophysiological signals has been studied in the field of emotion recognition, we compared several baseline methods of modality fusion often used in this field,which included FLF, DLF based on SVM [11], discriminant correlation analysis (DCA)+LDA [42] and BDAE based on DBM [40].
● FLF [11] concatenates the EEG feature vector and the eye movement feature vector into a larger feature vector.
● DLF [11] combines the classification results of two classifiers to obtain the final decision, where the maximal(sum) rule was to calculate the maximal (sum) values of all the probabilities.
● DCA + LDA [42] removes the inter-class correlation and limits the correlation to that found within classes, which is often used in feature fusion for biometric recognition.
● BDAE [40] trains two individual restricted Boltzmann machines (RBMs) to extract the shared representations of both two modalities.
FLF is a conventional modality fusion method based on SVM, while BDAE is a common modality fusion method in deep learning. Both of them have been widely used in multimodal emotion recognition. In order to verify the effect of different input conditions, we additionally designed two types of baseline based on FLF and BDAE.
● Source only (SO) uses the source samples to classify the unlabelled target samples.
● Target only (TO) uses the labelled target samples to train models, without the help of the source domain.
Single-Modal Domain Adaptation Method:SVM was the most common method implemented for EEG emotion recognition, and three conventional methods (KPCA, TSVM,and TCA) based on the SVM classifier that was often used as baselines for the domain adaptation problem. In recent years,with the development of deep learning, many deep domain adaptation methods have been applied in EEG emotion recognition. We compared the proposed method with both conventional and deep domain adaptation methods, with details were as follows:
● KPCA [26] uses a low transfer dimensional space using kernel methods.
● TSVM [27] uses the decision boundary in a semisupervised manner and weights all training instances equally.
● TCA [25] aims to use some transfer components to embedding features into a high-dimensional space to preserve the shared attributes between two domains.
● DDC [43] is based on classic deep network architectures,and a linear-kernel MMD loss is added on the feature representation layer to maximize domain invariance.
● DAN [44] embeds all the task-specific layers’ representations into a Reproducing Kernel Hilbert Space (RKHS),where the mean embeddings of two domain distributions can be matched.
● DANN [45] integrates a gradient reversal layer into the deep network, which can ensure that the features are domaininvariant and discriminative for the classification task.
● JAN [46] uses a transfer network by aligning the joint distribution of multiple domain-specific layers across multiple domains.
● ADA [47] produces statistically domain invariant embeddings, while minimizing the classification error on the labelled source domain by reinforcing associations between source and target data in the embedding space.
● CDAN [48] conditions the adversarial adaptation models using discriminative information to align different domains of multi-modal distributions.
● CoGAN [49] uses the joint distribution with just samples drawn from the marginal distributions by enforcing a weightsharing constraint.
● UNIT [34] uses a VAE-GAN architecture to learn a joint distribution of data in different domains by using data from the marginal distributions in individual domains.
● DAAN [50] dynamically learns domain-invariant representations while quantitatively evaluating the relative importance of global and local domain distributions.
For fair comparison, we modified the above methods so that they were trained with the labelled source samples and the labelled target samples.
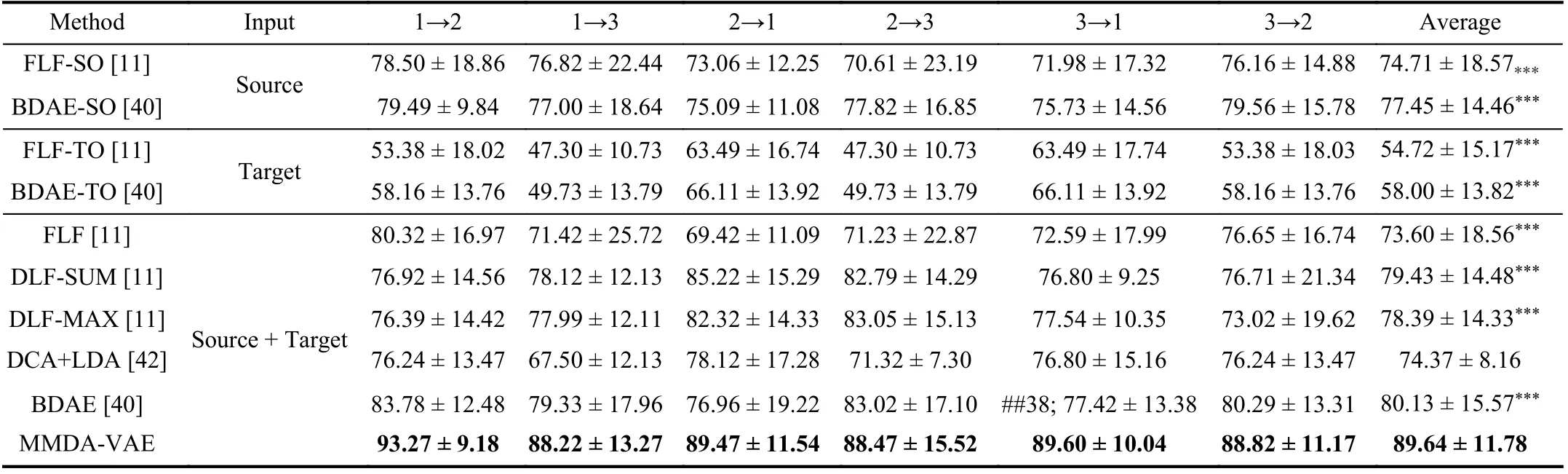
TABLE III MEAN ACCURACY (%) FOR MODALITY FUSION EMOTION RECOGNITION ON THE SEED DATASET
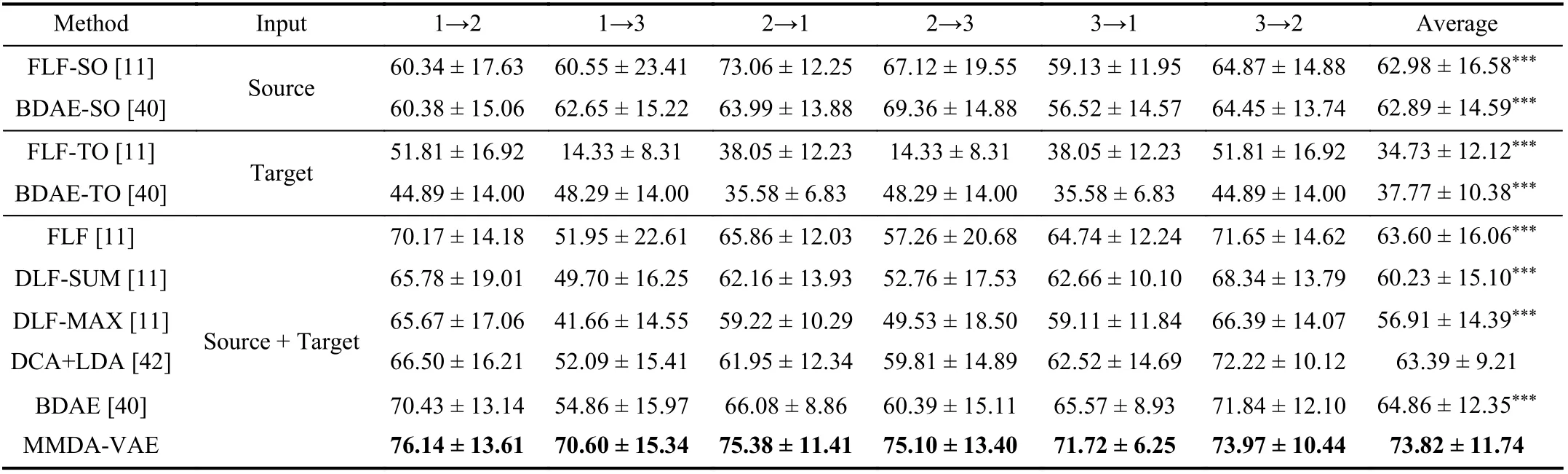
TABLE IV MEAN ACCURACY (%) FOR MODALITY FUSION EMOTION RECOGNITION ON THE SEED-IV DATASET
D. Statistical Analysis
In this paper, thet-test was conducted to analyse the difference of comparison results and other subsequent experiments.Post hoc analysis was conducted with a Benjamini &Hochberg correction. The significant level was set at 0.05. All results are presented asmean±stddeviation.
V. RESULTS
In this section, we designed a series of experiments to verify our method. Firstly, our methods are compared with the multimodal fusion method and single-mode state domain adaptation method. Secondly, ablation studies were performed to show the effects of the two components. Thirdly, we designed the missing modality situation, the cross-subject situation, the different transfer strategy situation and the session-independent/-dependent situation to show comprehensive performance. In addition, visualization and sensitivity were conducted.
A. Comparison Results
Comparison With Modality Fusion Methods:The results on the SEED dataset and the SEED-IV dataset were summarized in Tables III and IV. Our proposed method significantly outperformed FLF-SO and BDAE-SO. Also, MMDA-VAE achieved a significant improvement compared with FLF-TO and BDAE-TO on both datasets. The results show that MMDA-VAE can obtain better performance than directly using the source data to classify the unlabelled target data or using a small quantity of labelled target samples to train models. On both two datasets, MMDA-VAE showed significant improvement over FLF, DLF-SUM, DLF-MAX,DCA+LDA and BDAE. Our method was 9.51% and 8.96%higher than the best performing modality fusion method,BDAE, on the two datasets. This demonstrates that our MMDA-VAE is designed to solve the problem of multi-modal domain adaptation and achieved significantly better results.
Comparison With Domain Adaptation Methods:The domain adaptation results on the SEED dataset and the SEEDIV dataset were shown in Tables V and VI, separately. The input of these comparison methods was the concatenation of EEG and eye movement for fair. Our method achieved high accuracies of 89.64% and 73.82% on the two datasets. On the SEED dataset and the SEED-IV dataset, the performance of MMDA-VAE was significantly better than conventional methods, KPCA, TSVM, and TCA. Compared with the classic deep domain adaptation methods, MMDA-VAE significantlybeat the DDC, DAN, DANN, JAN, DAAN, and ADA methods. In contrast to the deep generative models, CDAN,CoGAN, and UNIT, our method showed significantly better performance on both datasets. This demonstrates that our MMDA-VAE is more suitable for the domain adaptation problem of multi-modal data.
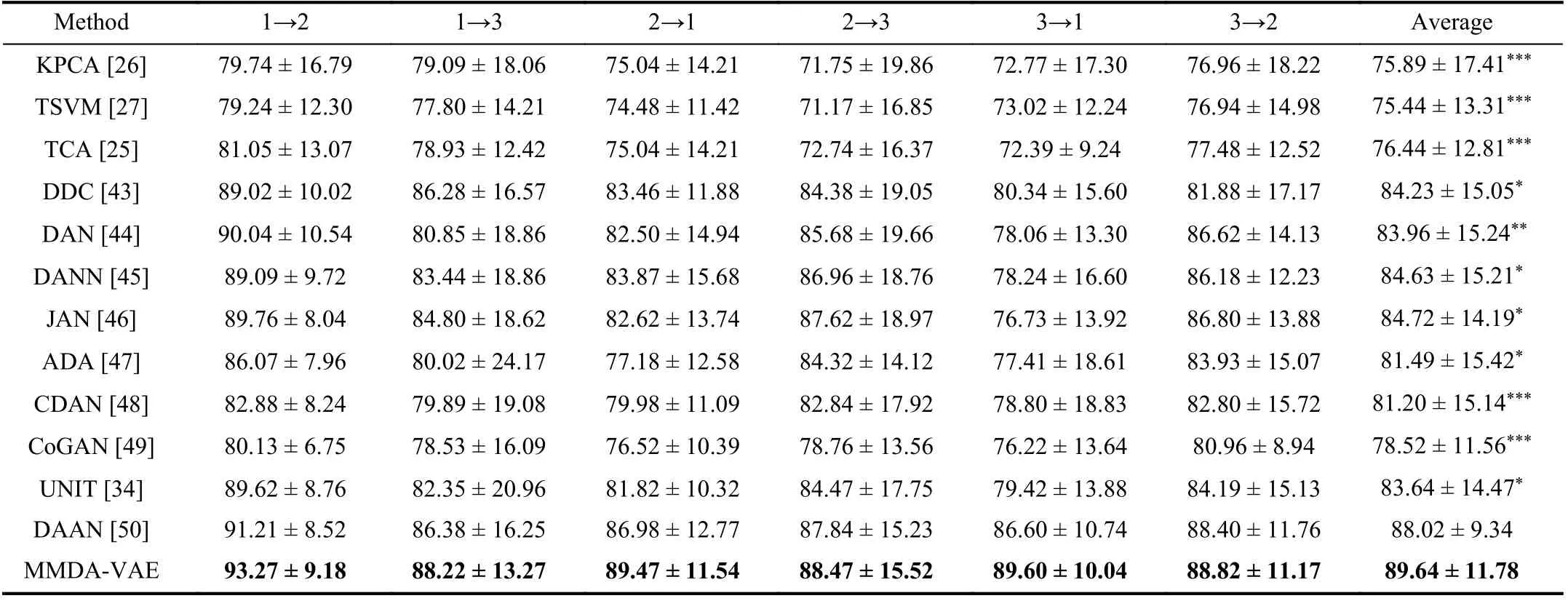
TABLE V MEAN ACCURACY (%) FOR DOMAIN ADAPTATION EMOTION RECOGNITION ON THE SEED DATASET
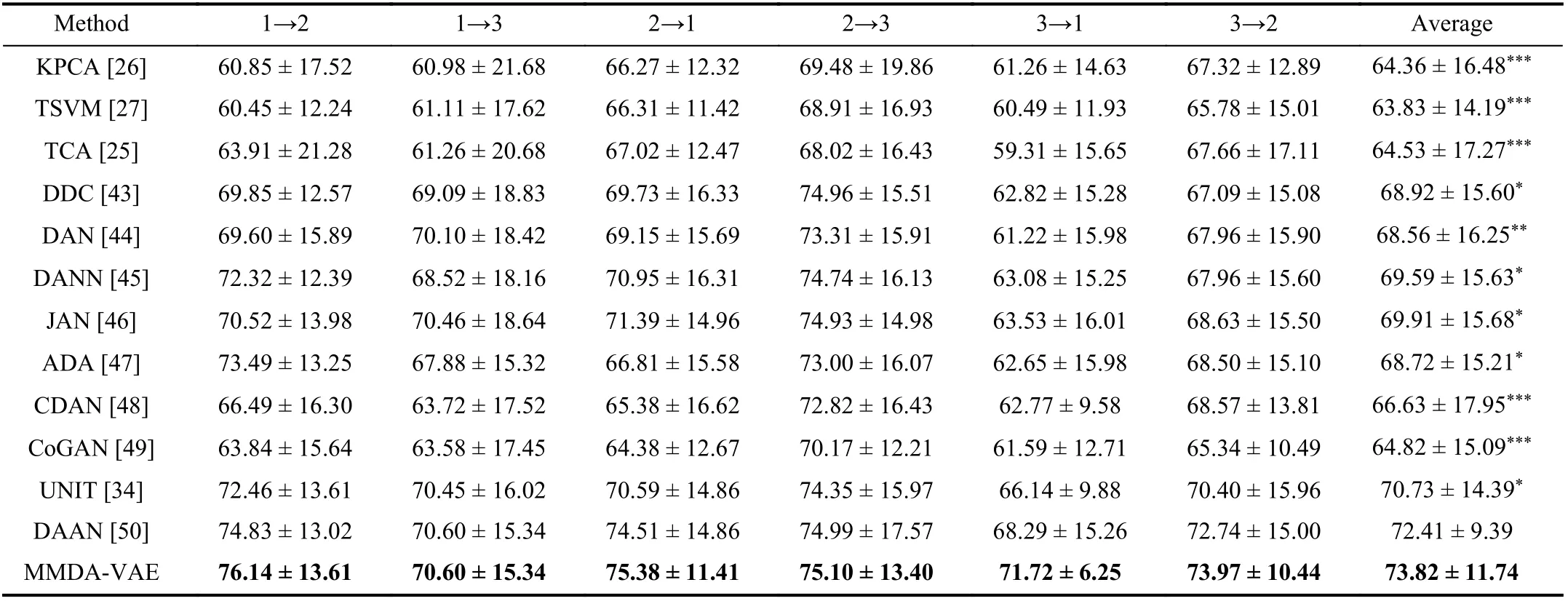
TABLE VI MEAN ACCURACY (%) FOR DOMAIN ADAPTATION EMOTION RECOGNITION ON THE SEED-IV DATASET
We selected several representative single-modal domain adaptation methods as comparison methods, and only a single modality was used for training and testing. The results were shown in Fig. 3. Compared to only using an EEG modality,our method significantly beats the conventional methods KPCA and TCA, on two datasets and beats the deep domain adaptation methods, DAN, DANN, and UNIT. As for only using eye movement, it was also significantly better than all the baselines on two datasets. This shows that using two modalities of emotion recognition performed better than the usage of a single modality. Moreover, in the comparison of EEG and eye movement modalities, the EEG modality performs better.
B. Ablation Study
We conducted ablation studies to evaluate the effects of two main components, which included cycle consistency loss and adversarial loss. Tables VII and VIII showed the results tested on the two datasets. On the SEED dataset, our method showed significant improvement over “No cycle consistency loss”with increases of 2.96% and increases of 1.86% “No adversarial loss”. On the SEED-IV dataset, our MMDA-VAE also achieved 2.29% and 1.31% higher values than “No cycle consistency loss” and “No adversarial loss”. Therefore, for the MMDA-VAE method, cycle consistency loss and adversarial loss have a great impact on the performance. The best accuracy is obtained when the two transfer losses are used together.
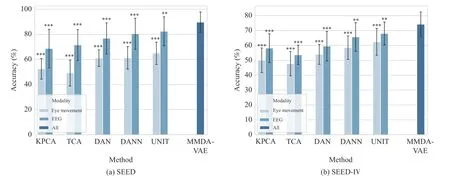
Fig. 3. Performance comparison for some domain adaptation methods using a single modality on (a) the SEED dataset and (b) the SEED-IV dataset. We carry out the significance test between our method and other single-modal domain adaptation methods (***: p < 0.001, **: p < 0.01, *: p < 0.05).

TABLE VII MEAN ACCURACY (%) FOR THE ABLATION STUDY ON THE SEED DATASET

TABLE VIII MEAN ACCURACY (%) FOR THE ABLATION STUDY ON THE SEED-IV DATASET
C. Missing Modality Results
In order to verify the feasibility of our method in the condition of a missing modality, we conducted a comparison strategy: “All” was equal to the original setting; “Only EEG”means that the training component and testing component of the target domain only contained EEG modality; “Only Eye”meant that there was only an eye movement modality in the target domain. The source domain contains the two modalities of EEG and eye movement. The results were shown in Tables IX and X. When we used all the modalities of the target domain,the results showed significant improvement when compared to only using the eye movement modality and only using EEG modality on both datasets. Besides, only using the EEG modality is better than only using the eye movement modality on the SEED-IV dataset. This result shows that using multimodal data has better performance than using single-modal data. And among these single-modal datasets, EEG data provides more emotional information than eye movement data. It also demonstrates that our MMDA-VAE can handle the domain adaptation problem in the case of incomplete modalities between domains.
D. Cross-Subject Results
To verify the generalizability of our proposed method, we conducted cross-subject emotion recognition experiments. We selected the first session’s data, and considered one subject in this session as the target subject in turn while considering the remaining subjects in the same session as source subjects. We trained multiple models on multiple source domains from other subjects, and reported the voting predictions of all the models on the target domain. We repeated two comparison experiments of modality fusion and domain adaptation in this way, which were same as the cross-session’s baseline.
The results of the modality fusion methods on these two datasets were summarized in Table XI. Our method achieved the highest accuracies 85.07% and 75.52% on the two data-sets. These results show that cross-subject experiments have achieved the same effect as cross-session experiments with modality fusion, which significantly exceeded the baseline.The result of domain adaptation methods on these two datasets were shown in Table XII. Our proposed method was significantly better than these conventional methods, KPCA,TSVM, and TCA. For the deep domain adaptation methods,our performance exceeded all the comparison methods of the two dataset, but only DDC, DAN, CDAN, CoGAN, and UNIT show significant differences. These results show that the performance of cross-subject experiments is consistent with that of cross-session experiments in the conventional domain adaptation, but the performance of cross-subject experiments is not as good as that of cross-session experiments when compared with the deep domain adaptation. On the whole, our MMDA-VAE can obtain optimal performance under two types of experimental settings, i.e., cross-session and crosssubject settings, indicating that it can effectively deal with various situations in the BCI’s practical application.

TABLE IX MEAN ACCURACY (%) FOR THE MISSING MODALITY EXPERIMENTS ON THE SEED DATASET

TABLE X MEAN ACCURACY (%) FOR THE MISSING MODALITY EXPERIMENTS ON THE SEED-IV DATASET
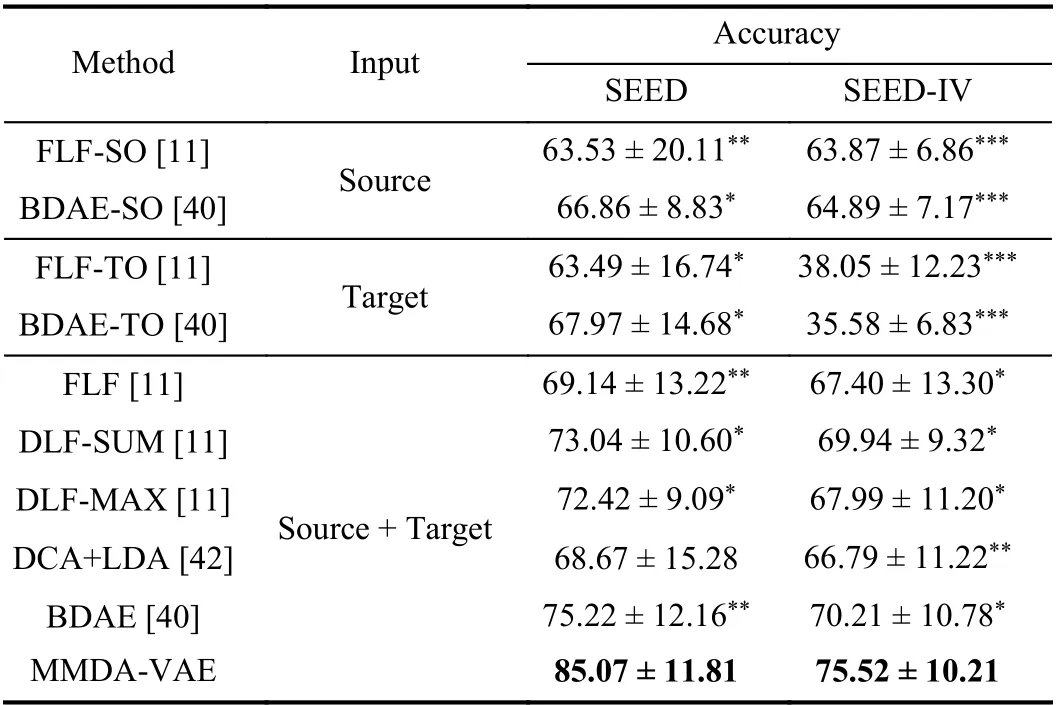
TABLE XI MEAN ACCURACY (%) FOR CROSS-SUBJECT MODALITY FUSION EMOTION RECOGNITION
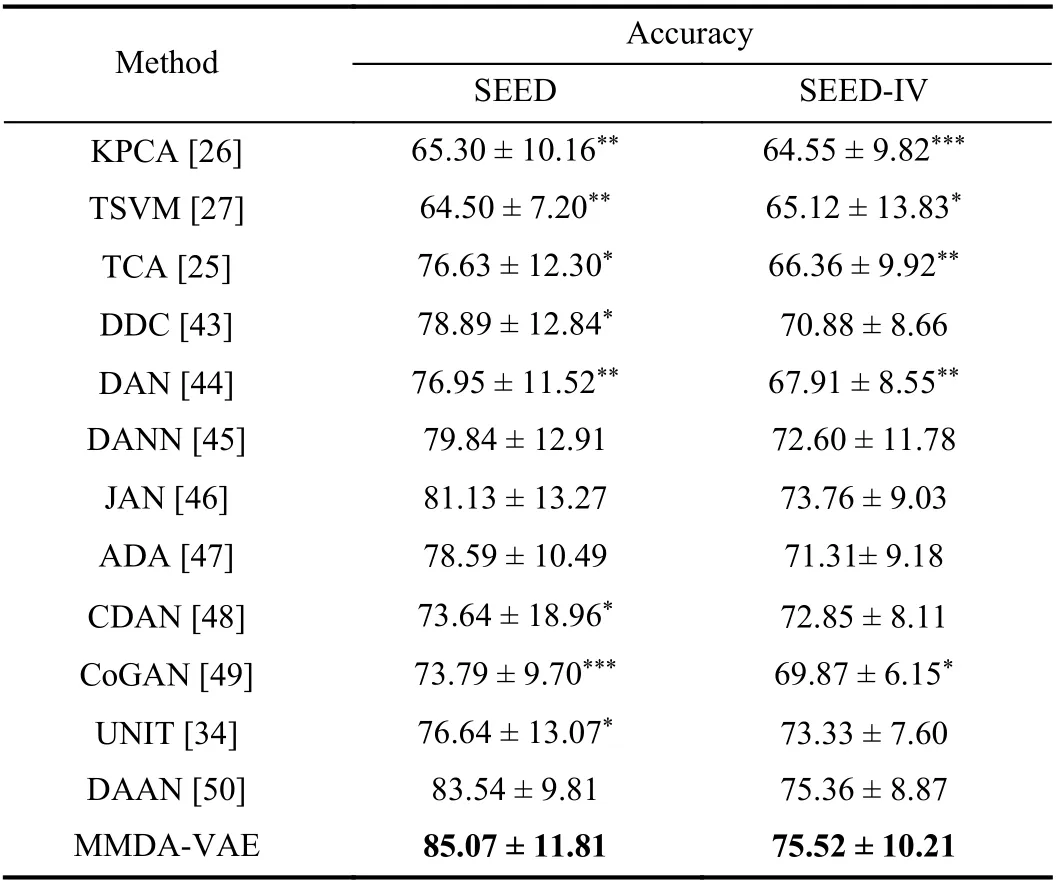
TABLE XII MEAN ACCURACY (%) FOR CROSS-SUBJECT DOMAIN ADAPTATION EMOTION RECOGNITION
E. Different Transfer Strategy Results
Our MMDA-VAE used a deep generation model to reconstruct multi-modal data, and operated on the reconstruction layer. We compared our transfer strategies with two transfer methods that operated on the feature-fusion layer. We added the MK-MMD constraint on the latent feature layer of MVAE,which is called MVAE-MMD [44] and added a discriminator to confuse the fused representation of MVAE from two domains, which is called MVAE-adversarial [45]. Tables XIII and XIV summarized the results on the SEED dataset and the SEED-IV dataset. On both two datasets, the averaged differences between the results of MVAE-MMD and MVAEadversarial were 0.49% and 0.04%, respectively. The results showed that the MMD-based method and adversarial-based method had very similar performance on our basic framework MVAE. Our MMDA-VAE method achieved significantlyhigher classification accuracy over the MVAE-MMD and MVAE-adversarial methods on both two datasets. The results show that our MMDA-VAE gets a better domain-invariant on the reconstruction layer, compared to directly constraining the latent space of MVAE.

TABLE XIII MEAN ACCURACY (%) FOR THE DIFFERENT TRANSFER STRATEGY EXPERIMENTS ON THE SEED DATASET

TABLE XIV MEAN ACCURACY (%) FOR THE DIFFERENT TRANSFER STRATEGY EXPERIMENTS ON THE SEED-IV DATASET
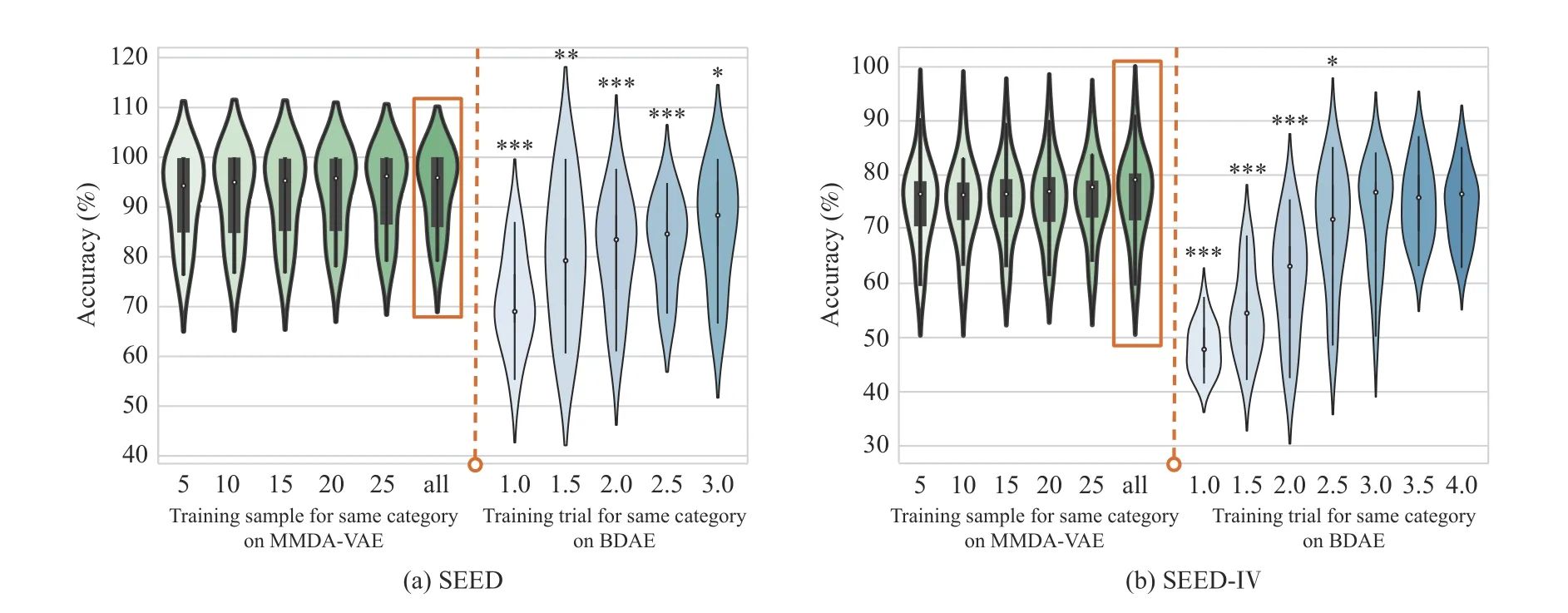
Fig. 4. Performance comparison for session-independent and session-dependent experiments on (a) the SEED dataset and (b) the SEED-IV dataset.
F. Session-Independent and Session-Dependent Results
In order to verify the effectiveness of domain adaptation technology in the field of EEG emotion recognition, we integrated the session-independent and session-dependent experiments together for comparison. We keep the test set and valid set unchanged, and explored the performance of the model by changing the training set. The result curve is shown in Fig. 4. On the SEED dataset, we used the last 3 trials as the test set, with the 9th to 12th trials as the valid set. On the SEED-IV dataset, we used the last 4 trials as the test set, and the 16th to 20th trials as the valid set.
To investigate the influence of the number of calibration data samples (labelled target samples), we conducted a session-independent experiment on the MMDA-VAE model on the left side of the orange dotted line. We selected the samples from the first trial set for each category to be 5, 10,15, 20, 25, and samples of the complete trial (“all”). We calculated thet-test between “all” and other cases, but there was no significant difference on both two datasets. It demonstrates that the number of calibration samples had little influence on the classification performance of MMDA-VAE.
To compare our method with the traditional sessiondependent method, we trained a series of BDAE models which continuously increased the number of trials in each category. The compared MMDA-VAE benchmark is marked with the orange box, and 0.5 indicates that only the first half of the trial is used for training. On the SEED dataset, our method significantly outperformed the BDAE using 3.0 calibration trials in each category, achieving a 7.66% higher value. There was a similar phenomenon on the SEED-IV dataset. The accuracy was higher by 6.04%. This result shows that the MMDA-VAE can exceed the performance of traditional session-dependent multi-modal emotion recognition, effectively reducing the calibration time.
G. Space Visualization
T-distributed stochastic neighbour embedding (t-SNE) is a useful technique for dimensionality reduction. Here, we usedt-SNE to visualize the distribution of the learnt latent representation. For simplicity, we randomly chose one target subject on task 1→2 of the SEED dataset. In Fig. 5(a), the source data and the target data were discrete, and the data collected from the same video seemed like a strip. The emotional states were not easy to discriminate based on these original features. In Fig. 5(b), the discrepancy between two domains was obviously reduced in the latent representation space of our MMDA-VAE. Besides, the representations belonging to different categories became more distinguishable than before. As seen, our MMDA-VAE can effectively learn domain-invariant representations with discriminative category information.

Fig. 5. The distribution of source and target domain samples before and after the adaptation on task 1→2 of the SEED dataset.
H. Sensitivity Analysis
To clarify the effect of these hyper-parameters, we conduct experiments with different scaling constants of the λ1– λ5and λL2. We chose the selected hyper-parameter from {1, 0.1,0.01, 0.001, 0.0001} and kept other hyper-parameters optimal.The results on task 1→2 of the SEED dataset from one subject are shown in Fig. 6. For different λ1, λ3, λ4, and λL2, the performance of our method fluctuates slightly. For differentλ2and λ5, our method is relatively variable. It shows that the weight of KL divergence loss had a greater impact on the result. Importantly, the performance is generally stable within the setting range ( λ1– λ4and λL2from {0.01, 0.001, 0.0001};λ5from {0.001, 0.0001, 0.00001}).
VI. DISCUSSION
In this paper, we combined EEG and eye movements to identify human emotional states. Our model made good use of the information of the two modalities. We can use a large amount of multi-modal data as the source domain to assist in providing a small amount of single-modal data in the target domain. Moreover, our method can naturally deal with the problem of missing modalities through the PoE structure.Although the performance of the modal missing data is lower than that of multi-modal data, the cost of multi-modal data collection is also a problem that needs to be balanced. It is meaningful for the application of emotional BCIs.
The traditional supervised learning method involves collecting a large amount of labelled data to train the classification model. In the case of a small amount of calibration data, we hope to use data collected by the same subject at different sessions to assist in model training, and reduce the calibration data collection time. In order to achieve this goal, we need to use domain adaptation technology to eliminate the difference in data distribution between each session. The results show that with a small amount of calibration data, our model has obvious advantages over the baseline without domain adaptation. We also chose the most widely used modal fusion method BDAE to train a series of session-dependent experiments. The results show that our domain adaptation model can be comparable to the performance of collecting sufficient data for traditional classification. This suggests that the domain adaptation method can use cross-session data to improve the classification performance and save calibration time, which is a promising approach in the actual use of emotional BCIs.
In addition to using data collected by the same subject in different sessions, our method can also train a cross-subject model using the data from the other subject. Since EEG has individual differences, there are also differences in distribution of the data between different subjects. Generally speaking, the difference in the data collected from different subjects is greater than the difference in the data collected from the same subject in different session [51]. We summarized crosssubject and cross-session experiments in Table XV. The cross-subject result on the SEED dataset was 4.57% lower than the cross-session result, while the cross-subject result on the SEED-IV dataset was 1.70% higher than the cross-session result. The subjects in each session of the SEED-IV dataset watched different evoked videos, but the subjects in each session of the SEED dataset watched the same evoked videos repeatedly. So the difference between each session may be greater on the SEED-IV dataset. Since emotion is not an instantaneous state, we additionally calculated the accuracy of trial-wise, that is, the label of the entire trial is voted by the samples removed from the same trial. We found that the classification accuracy of trial-wise and sample-wise methods have similar results when performing the tasks of withinsubject and cross-subject domain adaptation.
We found that in Tables V and VI, the accuracy of the SEED-IV dataset was 15.82% lower than that of the SEED dataset. This may be due to the fact that the SEED dataset is a three-category emotion classification dataset, and the SEEDIV dataset is a four-category dataset. We therefore use the accuracy ratio from Tables V and VI to the chance level for the performance comparison, the SEED dataset: 89.64%/33.33% = 2.69 and the SEED-IV dataset: 73.82%/25% = 2.95.Looking at accuracy ratio, MMDA-VAE shows no performance degradation on the SEED-IV dataset and the results suggest that the number of categories caused the difference in the accuracy.
Although our method achieves better performance than compared methods, this method has several limitations. Firstly, our method is based on the structure of VAE, including decoder and encoder. This results in a larger number of parameters in this method compared with other methods. Secondly, this method assigns the same weight for two modalities.Future works should propose an algorithm to adaptively assign weights for different modalities based on the amount of the information they supply. Thirdly, other physiological signals have also been studied to estimate emotion states,including electromyogram signals (EMG) [42], electrocardiograms (ECG) [52], and galvanic skin responses (GSR) [53].Thus, future studies should consider employing more multimodal recordings, in combination with improvement of this method, to further improve the performance of emotion recognition. Finally, since this study is more concerned with improving the accuracy rate under the conditions of EEG practical usage, we do not further discuss the computational complexity.
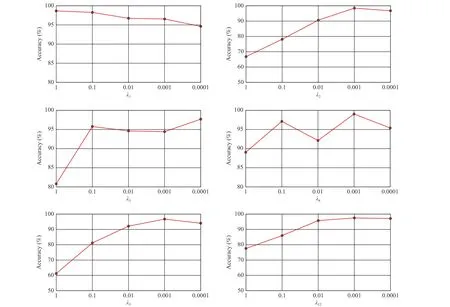
Fig. 6. The sensitivity analysis of hyper-parameters.
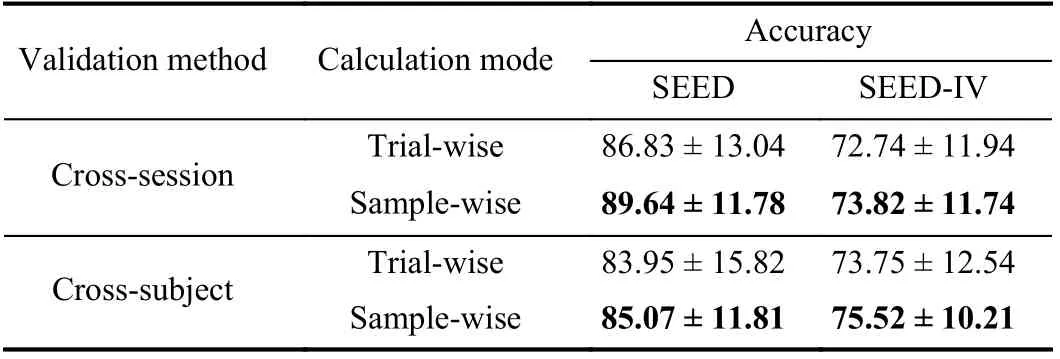
TABLE XV MEAN ACCURACY (%) FOR DIFFERENT ACCURACY CALCULATION MODE
VII. CONCLUSION
In this paper, we propose the MMDA-VAE method to achieve emotion recognition with small calibration samples.This method is based on the MVAE architecture, which ensures that the latent layer can extract the representation of modality fusion. We set up discriminators after the reconstruction layers of MVAE, and make the reconstruction data from the source and the target domains more confusing though adversarial learning. Also, we use the cycle-consistency constraint to convert the source domain and target domain data to each other during the reconstruction process. Our method can constrain the output space to narrow the modality gap and the domain gap, which helps the target subjects make use of the data of the other modalities and other sessions as much as possible. Indeed, the reconstructed structure leads to the increase of parameters. Our comprehensive experiments on two public datasets show the superior performance of the model. We also conducted some experiments with missing modalities. The results show that our MMDA-VAE can effectively deal with the difficulties in obtaining complete multi-modal data in practice. Our model provides a solution that overcomes the variability of data collected in different sessions and helps to reduce calibration time. This is a practical improvement in the field of emotion recognition based on EEG.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Autonomous Maneuver Decisions via Transfer Learning Pigeon-Inspired Optimization for UCAVs in Dogfight Engagements
- Interval Type-2 Fuzzy Hierarchical Adaptive Cruise Following-Control for Intelligent Vehicles
- Efficient Exploration for Multi-Agent Reinforcement Learning via Transferable Successor Features
- Reinforcement Learning Behavioral Control for Nonlinear Autonomous System
- An Extended Convex Combination Approach for Quadratic L 2 Performance Analysis of Switched Uncertain Linear Systems
- Adaptive Attitude Control for a Coaxial Tilt-Rotor UAV via Immersion and Invariance Methodology