基于LightGBM的网络入侵检测研究
2022-09-06唐朝飞努尔布力
唐朝飞 努尔布力 艾 壮
1(新疆大学软件学院 新疆 乌鲁木齐 830046)2(新疆大学网络中心 新疆 乌鲁木齐 830046)3(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
0 引 言
入侵检测系统(IDS)[1]是一种主动的网络安全保护技术。入侵检测系统的方法可以分为两种类型,一种是基于异常的检测,另一种是基于误用的检测[2]。目前以误用检测和异常检测为代表的入侵检测方法普遍存在检测精度低和误报率高等不足。由于大数据的不断发展和变化,网络系统的速度不断提高以及入侵者的方法不断变化或变通,IDS仍然是一个重要的研究课题[3]。近年来,由于网络攻击多发生于广域网环境,导致入侵检测工作面临挑战,因此要求研究人员必须结合大数据技术,研究新的攻击检测方法。
目前基于机器学习技术的入侵检测方法普遍存在模型训练过程中易出现过拟合和泛化能力较差的情况,准确率较低、误报率较高。常用的特征选择算法,如卡方检验、随机森林算法,在入侵检测方面取得的效果不理想。为了更好地解决以上问题,本文提出一种新的入侵检测模型。该模型采用基于PCA的特征选择方法,去除冗余特征,采用微软开源的LightGBM算法[5]检测网络攻击,并采用量子粒子群算法(Quantum-behaved Particle Swarm Optimization,QPSO)[6]对LightGBM算法参数进行优化,在NSL-KDD数据集[7]上进行了分类训练和测试实验,并在Spark集群上运行该实验,实验结果证明了该模型的有效性。使用本文提出的入侵检测模型进行预测,提高了准确率、精准率和召回率,缩短了训练时间和预测时间。
1 背景及相关工作
1.1 背 景
入侵检测系统(IDS)被创建用来有效地防御各种类型的网络攻击,并进一步保护网络系统正常运行。入侵检测的目的是识别各种活动,尤其是恶意活动,它是目前保护计算机网络和系统最重要的策略。过去的三十年中,对IDS的研究一直在积极进行,很多研究利用机器学习算法来完成入侵检测任务。
文献[8]指出入侵检测应用中ID3和C4.5算法的重要性,并采用基于二分法的CART算法简化决策树规模,达到分类的目的。为了提高入侵检测的效果,采用主成分分析法(PCA)来进行降维。文献[9]提出了一种新型的混合模型。使用基尼系数进行选择特征以得到最佳特征子集,采用梯度提升决策树(GBDT)算法检测攻击行为,并采用粒子群优化算法(PSO)为GBDT算法寻找参数。但是PSO容易陷入局部最优解。文献[10]提出了一种基于分类和Boosting技术的基于混合异常的入侵检测系统,比较了三种不同分类器的性能及提升情况,Boosting技术可最大程度地提高分类准确性。文献[11]使用Apache spark来进行异常检测,通过使用不同的机器学习算法(例如Logistic回归、支持向量机、朴素贝叶斯、决策树、随机森林和K-Means)来进行异常检测,在异常检测的背景下找到最有效的算法,并在Kddcup99数据集上比较它们的训练时间、预测时间和准确率。
针对网络入侵检测的准确率及效率不够高的问题,可通过特征选择在减少运算量的同时提高准确率及效率,使用QPSO为待优化模型寻找最优参数,通过Apache spark集群进行运算可极大地提高运行效率。
1.2 相关工作
Spark[12]是由伯克利AMP Lab开发的大数据分布式计算框架,是一个比mapreduce更加快速和通用的编程模型。MMLSpark(Microsoft Machine Learning for Apache Spark)[13]是一个增强的生态系统,扩展了Apache Spark分布式计算库,以解决深度学习、梯度增强、模型可解释性和其他现代计算领域的问题。MMLspark将LightGBM算法集成到Spark集群中,以实现大规模优化的梯度增强。
HDFS(Hadoop Distributed File System)[14]用于大规模分布式存储中,以构建具有高容错性和高性能的可扩展云存储平台。HDFS使用主从架构,集群由一个名为Namenode的主节点和多个名为Datanode的从节点组成。YARN(Yet Another Resource Negotiator)[15]被引入作为Hadoop的资源管理层,被定义为大数据应用程序的分布式操作系统。
2 入侵检测系统理论分析
2.1 系统流程
图1展示了本文所提出的入侵检测系统的流程图。使用KDDTrain+数据集来训练提出的入侵检测系统,并使用KDDTest+数据集根据准确率、精准率、召回率和F1值进行评估其性能,根据训练时间和预测时间来评估其效率,整个系统在Spark集群上运行。具体步骤如下:
步骤1使用yarn-cluster模式启动Spark集群,从HDFS读取数据集并创建DataFrame,由yarn进行调度管理,将数据分发到各个节点;
步骤2对字符型数据进行数值化转换,并对所有数据进行归一化处理;
步骤3基于PCA进行特征选择,选出贡献度最高的特征,组成新的特征子集;
步骤4使用MMLSpark中的classbalance方法对数据进行类别不平衡处理,为不同类别的数据设置权重;
步骤5采用LightGBM算法训练模型,并采用QPSO为LightGBM算法选择最优参数;
步骤6根据评价指标对模型进行评估。
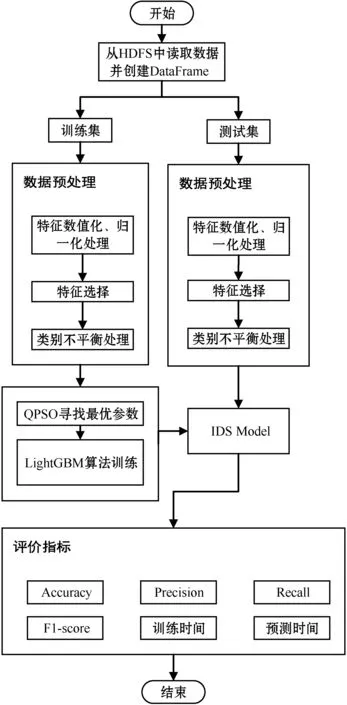
图1 IDS模型
2.2 基于PCA的特征选择
主成分分析方法是一种使用最广泛的数据降维算法。 本文基于PCA的入侵检测特征选择方法的步骤如下:(1) 首先,从主成分中提取系数最大的特征;(2) 选择前k个最大的特征值,并选择相对应的k个特征向量组成向量矩阵;(3) 用特征矩阵从原始数据集选出贡献度高的特征,组成新的数据集。
2.3 基于LightGBM的检测
LightGBM算法是微软在2017年提出的基于GBDT的数据模型。尽管GBDT在许多机器学习任务上都取得了良好的学习效果,但是近年来,随着数据量的几何级增长,GBDT面临着准确率和效率的问题。此时LightGBM算法被提出,LightGBM算法可用于分类和回归任务,在不降低预测准确率的同时,它大大加快了预测速度,并降低了内存消耗。
在减少训练数据方面,LightGBM算法使用leaf-wise生长策略。与传统的level-wise生长策略相比,leaf-wise生长策略则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环,如图2所示。因此同level-wise生长策略相比,在分裂次数相同的情况下,leaf-wise生长策略可以降低更多的误差,得到更好的精度。但是leaf-wise生长策略的缺点是可能会长出比较深的决策树,产生过拟合。所以LightGBM算法在leaf-wise生长策略之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
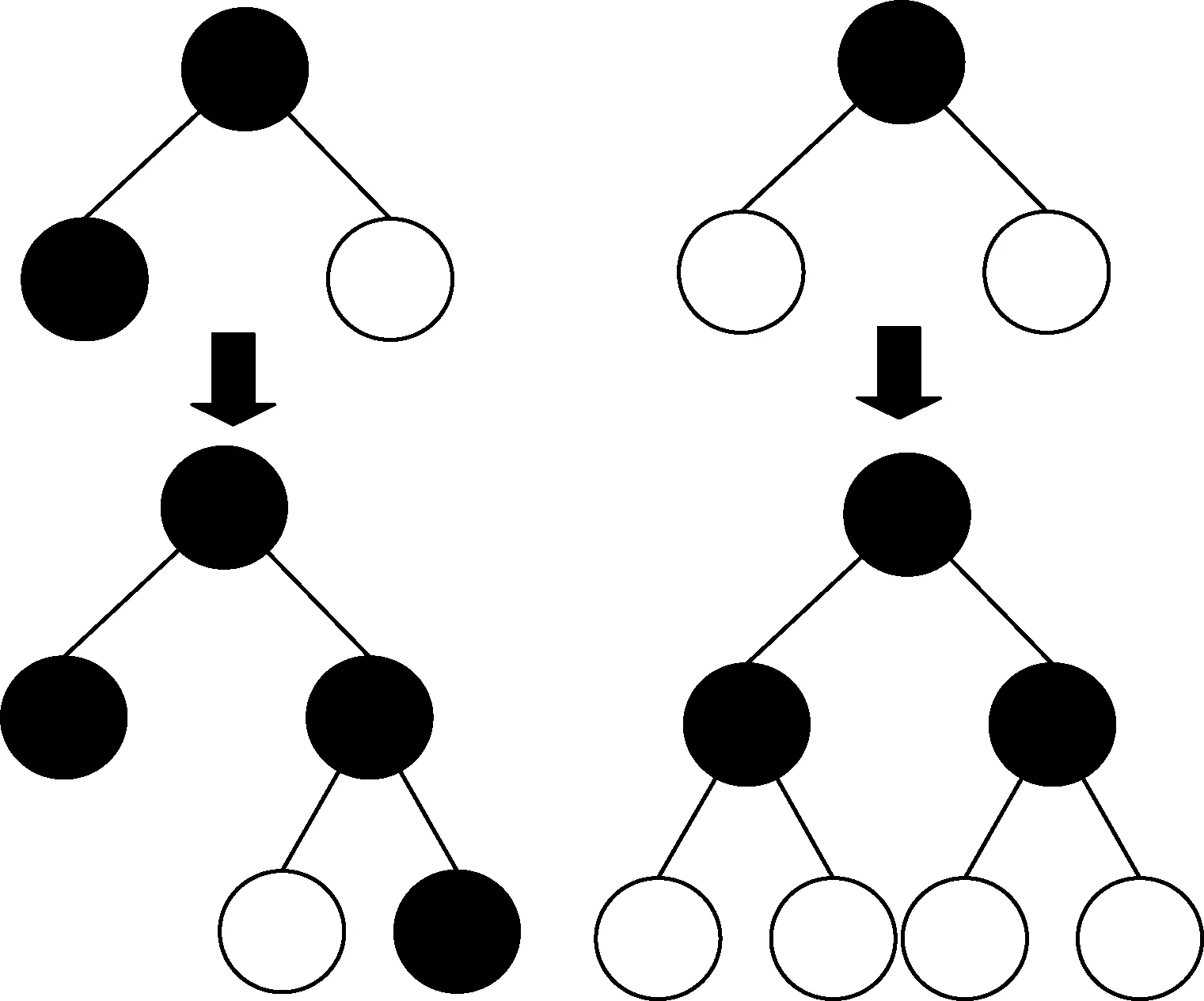
图2 Leaf-wise(LightGBM)和Level-wise(XGBoost)策略
2.4 基于QPSO的超参数寻优算法
QPSO是对PSO的改进,该算法中的粒子具有量子行为,可以在整个解空间当中进行搜索,能够克服PSO易陷入局部最优解的局限性[16]。在QPSO中,粒子被概率表示为一个量子向量,其中给定单位qubit的值(承载信息的最小单位)可以为0、1或两者的叠加,量子粒子向量定义如下:
∀s∈S,∀j=1,2,…,n
(1)
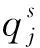
∀j=1,2,…,n
(2)
一旦知道了从量子中获得离散粒子的规则,就可以描述QPSO的演化如下:
Qgbest=α×pgbest+β×(1-pgbest)
(3)
Qbest=α×pbest+β×(1-pbest)
(4)
Q′=c1×Q+c2×Qbest+c3×Qgbest
(5)
式(3)对应于全局最佳量子粒子,符号pgbest表示全局最佳离散粒子。类似地,式(4)表示局部最佳量子粒子,pgbest表示局部最佳离散粒子,其中α和β表示控制参数且满足0≤α,β≤1且α+β=1。
式(5)描述了量子粒子Q的演化,Q表示当前迭代中的粒子和Q′表示Q在下一次迭代中的更新。系数(c1,c2,c3)满足条件0≤c1,c2,c3≤1且c1+c2+c3=1。
QPSO的过程描述见算法1。
算法1QPSO
Data:An instance of the LightGBM
Result:The best solution of the LightGBM
initializeQ(t) andP(t);
EvalutateP(t);
Keep the best solution amongP(t);
while stopping condition is not reached do
t=t+1;
CalculateQ(t) using Equations(5-7);
GetP(t)fromQ(t) using Equation(4);
Apply the LightGBM repair operator;
EvaluateP(t);
Keep the best solution amongP(t);
end
Return the best solution of the swarm
3 实验评估
3.1 实验环境和NSL-KDD数据集
本文实验在Spark集群上运行,该集群中含有3个节点,其中包含1个Namenode主节点、2个Datanode从节点。实验环境使用CentOS7系统,使用Python编写的PySpark和MMLSpark算法包作为实验中的机器学习工具包。将程序打包并提交到Spark集群上,并采用yarn-cluster模式运行程序。集群具体配置情况如表1所示。
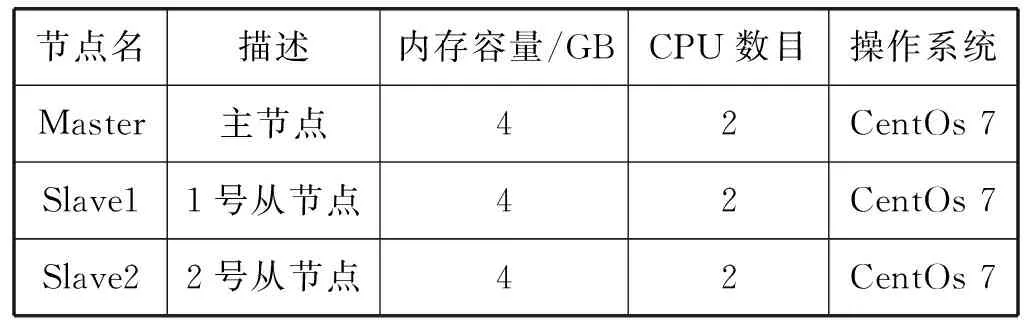
表1 实验Spark集群配置状况
本文采用NSL_KDD数据集,NSL-KDD数据集是KDD 99数据集的改进,删除了大量的重复记录。如表2所示,NSL-KDD总共包含39种攻击,其中每种攻击都可分为四个类别(Probe、DoS、R2L和U2R)。此外,仅在测试集中引入了一组新型类攻击,这些新攻击以粗体显示。表3展示了NSL-KDD训练集和测试集中的正常记录和攻击记录的分布,可看出各类别分布极不均衡。

表2 NSL-KDD数据集中的攻击类型
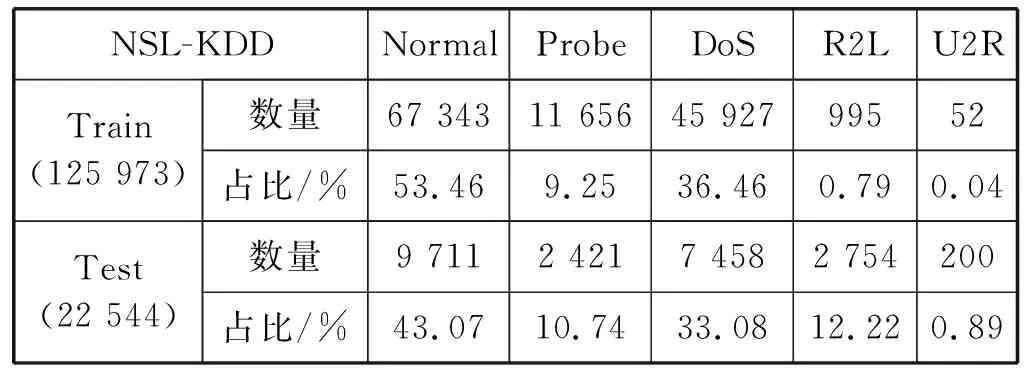
表3 NSL-KDD数据集中的四种攻击和正常记录的分布
3.2 实验设计
本文实验采用NSL_KDD数据集,与Razan Abdulhammed团队[17]使用PCA方法进行特征提取不同,本文将使用PCA进行特征选择。为了更好地训练模型,克服PSO容易陷入局部最优解的缺点,采用QPSO为LightGBM算法选择最优参数。为提高运行效率,整个实验在Spark集群上运行。
3.3 评价指标
本文实验采用6个评价指标来评估模型,分别是准确率(ACC)、精准率(PRE)、召回率(REC)、F1值(F1-score)、训练时间和预测时间。分类结果混淆矩阵如表4所示。
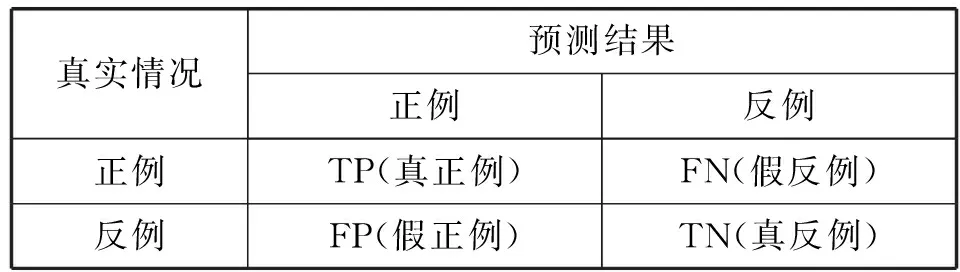
表4 分类结果混淆矩阵
准确率的计算公式为:
精准率的计算公式为:
召回率的计算公式为:
F1值的计算公式为:
3.4 模型训练参数
将PCA用于特征提取,图3展示了不同k取值的情况下准确率的变化情况,最高准确率仅为76%,其中k表示主成分的数量。

图3 PCA取不同k值时的准确率
NSL_KDD数据集共有41个特征,使用PCA进行特征选择,从中选择贡献度最高的特征。当选择前9个特征作为输入时,入侵检测性能最好。这9个选定的功能分别是F27、F30、F5、F23、F8、F1、F2、F39和F3,这些特征的简要说明见表5。
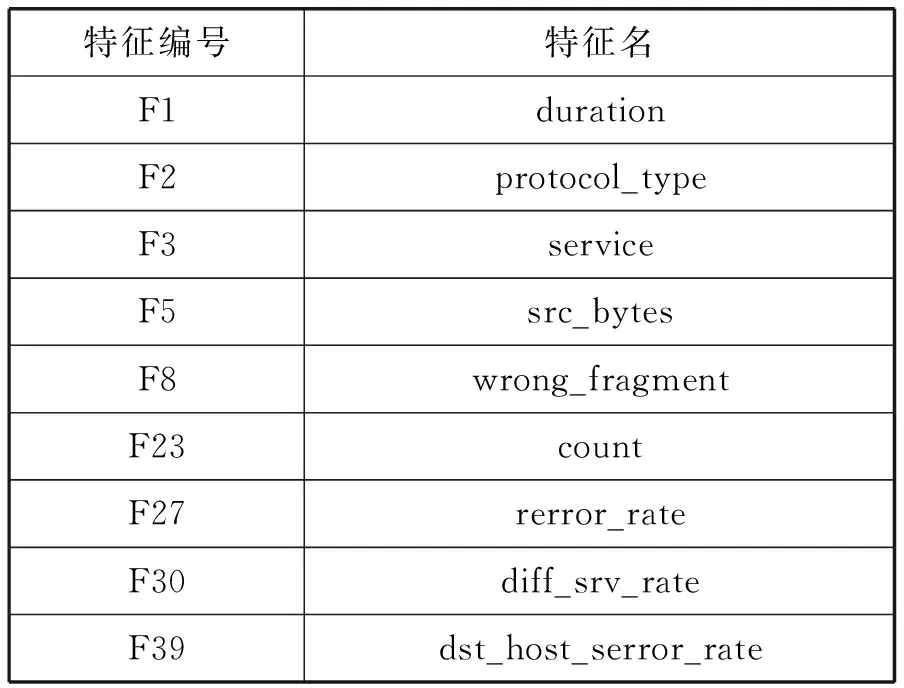
表5 本文方法所选择的最终9个特征
将原始数据集41个特征和基于PCA的特征选择方法选出的9个特征分别作为入侵检测系统的输入,其结果进行对比,如表6所示,同时与采用卡方检验、随机森林进行特征选择的结果进行对比。可以看出,使用PCA进行特征选择取得了较好的结果。
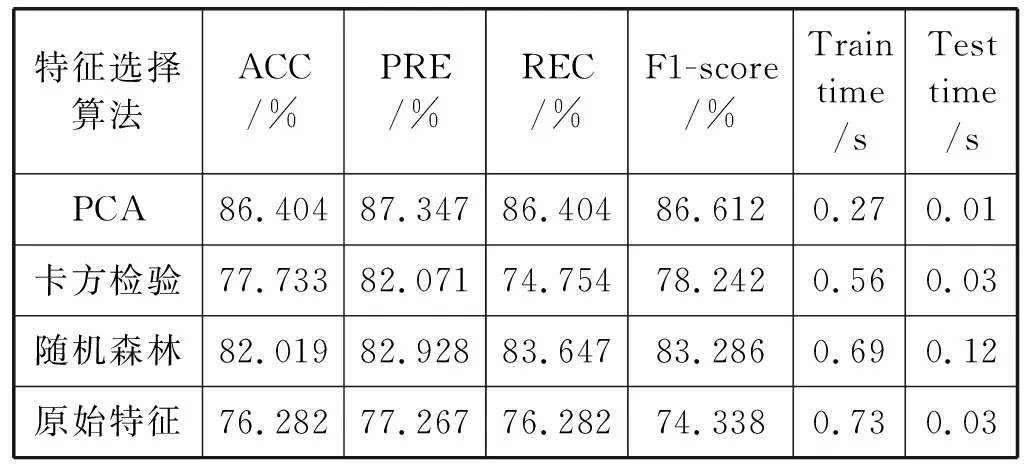
表6 不同特征选择算法下的检测结果
为了使模型取得更好的效果,利用参数寻优算法为LightGBM算法找到最优参数。需为PSO设置如下9个参数:particle_num=20(粒子群数量)、iter_num=50(迭代次数)、maxDepth(起始值,结束值)、learningRate(起始值,结束值)、numIterations(起始值,结束值)、w(惯性因子)、c1(局部学习因子)、c2(全局学习因子)、particle_dim=3(粒子维度)。经过一定次数的迭代,PSO找到的最优参数使准确率达到79%左右,但是再经过多次迭代,准确率最高仅达到82%左右,无法继续提高。
本文采用QPSO来寻找模型的最优参数,仅需要设置四个参数,其中particle_dim(粒子维度)对应待寻优参数的个数。QPSO设置的参数如表7所示。
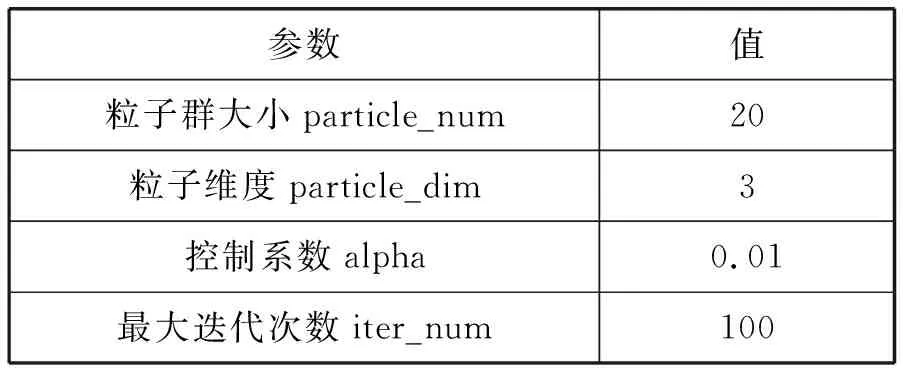
表7 QPSO算法参数
LightGBM算法的待寻优参数有三个,分别为树的最大深度maxDepth、学习率learningRate和迭代次数numIterations,其余参数使用默认值。maxDepth是LightGBM中非常重要的一个参数,maxDepth过小,模型精度不够,maxDepth过大,模型易过拟合。采用QPSO选择出的LightGBM参数如表8所示。
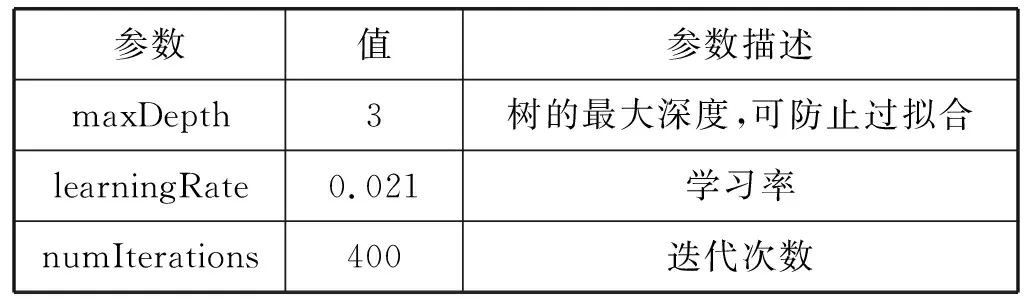
表8 LightGBM算法参数
3.5 实验结果与分析
在本文提出的入侵检测模型中,使用PCA进行特征选择,可取得更好的结果。图3展示了使用PCA进行特征提取时,不同k值所对应的准确率,整体准确率不高,其中最高为75.839%。
从表6的结果可以看出,在使用基于PCA的特征选择算法选出的9个特征作为输入时,准确率高于使用PCA进行特征提取的结果,也取得了优于其他特征选择算法的效果。同时,与使用全部41个特征作为输入相比,准确率、精准率、召回率和F1-score均有提升,同时由于特征数量减少,训练时间和预测时间均有减少。同时可以看出在Spark集群上进行实验,训练时间大大减少,可以非常快速地进行入侵检测。由此可见,由于使用了基于PCA的特征选择方法,仅使用了41个特征中的9个(21.95%),就达到优于使用全部特征训练模型的性能。使用参数寻优算法是为了尽快找到待优化模型最优参数,但是PSO本身需要设置的参数过多,不利于最优参数的寻找,且易陷入局部最优解。因而采用QPSO进行参数寻优,算法中的粒子具有量子行为,可以在整个解空间当中进行搜索,实验证明QPSO取得了优于PSO的结果。
表9将文献[18]与本文提出的入侵检测系统进行了比较。文献[18]采用K-Means聚类算法对数据集进行聚类,然后使用XGBoost算法为每个簇训练不同的分类器,以取得更好的结果。从结果比对可以看出,经过PCA特征选择之后,再由LightGBM算法进行训练的结果要优于K-Means聚类算法和XGBoost算法的组合,本文提出的入侵检测系统可有效地进行检测。
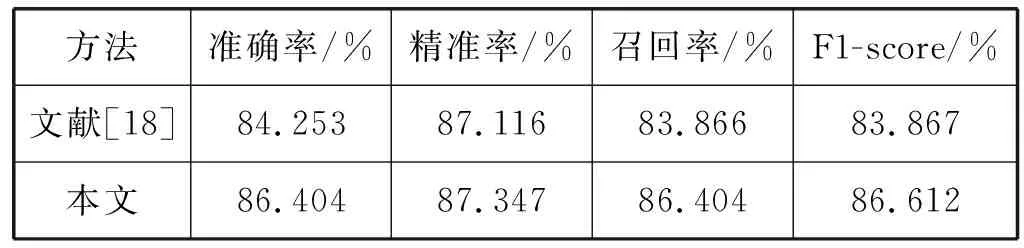
表9 在NSL-KDD训练集上的结果
4 结 语
利用PCA进行特征选择,以QPSO为LightGBM算法寻找最优参数,并在Spark集群上进行实验,可以有效、快速地进行入侵检测。从本文的实验结果可以看出,使用PCA进行特征选择,仅使用9个特征进行训练得出的结果优于原始数据集的41个特征。在入侵检测方向,LightGBM算法也展现了良好的性能。
在未来的工作中,将计划探索更多的特征预处理,以及更有效的分类算法,以更好地进行入侵检测。目前,还在研究设计更有效的方法以针对入侵检测,以及使用分布式计算减少模型训练时间。
