Spark查询引擎中Join操作的优化
2022-09-06赵丽梅黄小菊宫学庆
赵丽梅 黄小菊 宫学庆
(华东师范大学软件工程学院 上海 200062)
0 引 言
Apache Spark[1]是一个通用的并行查询引擎,能够支持对键值数据源的数据分析处理,扩展键值数据库[2-3]大规模复杂查询分析的能力,例如对键值数据源的Join查询。实际应用场景中常搭建的Spark-over-HBase架构[4],利用Spark查询引擎支持HBase数据源[5-6]的复杂查询,其存储层利用HBase集群对海量数据进行持久化存储,计算层采用Spark查询引擎来执行大规模查询分析。该架构实现存储层与计算层分离,解决了HBase数据库仅能通过键来进行简单查询的不足,扩展了其支持复杂查询的能力。如图1所示,该架构底层采用HBase集群来进行数据持久化存储,HBase集群包括一个HMaster主节点和若干个HRegionServer节点,利用Zookeeper集群来进行分布式协调。数据分布存储在多个HRegionServer节点,通过主节点来协调各HRegionServer的负载均衡并维护集群的状态;上层利用Spark集群来实现对于数据的并行计算和查询响应,Spark集群包括一个Master主节点和若干个Worker节点,通过主节点来管理Worker节点,用户提交应用程序启动Driver进程来触发集群工作。当接收到一个SQL请求后,启动Driver进程,Spark查询引擎生成对应的任务调度,通过数据访问接口提取HBase中的数据到各Worker节点进行数据并行处理,响应查询请求。

图1 Spark-over-HBase架构
Spark-over-HBase架构扩展了HBase数据库的大规模查询分析能力,但是对于复杂查询分析中较常用、开销较大的Join操作,Spark查询引擎的处理过程仍然有以下两方面不足:
(1) 网络传输开销大。根据文献[7]可知,因为存储模式简单,所以大多数的键值数据库不具备在存储层进行谓词下推和投影来过滤数据,扫描数据效率低下。所以,大多情况下Spark查询引擎需要提取全表数据进行处理。对于Join操作,Spark底层实现了Broadcast Hash Join算法、Repartition Join算法[8]。针对两个大表进行Join的Repartition Join算法,是将两表的全表数据进行Shuffle操作[9]。Spark当前采用的Shuffle策略是Sort Based Shuffle,这涉及大量的磁盘I/O开销和计算开销,尤其是网络传输开销。对于宽表或者网络通信效率低下的情况,该部分开销占比更大。
(2) 并行度设置不合理。在硬件资源满足条件的情况下,并行处理大数据量往往能够极大地提高工作性能。在Spark执行Join查询时,Join执行的并行度与进行Shuffle操作时重分区的个数有关,即(1)中Reduce任务的个数。Spark提供spark.sql.shuffle.partitions参数来设定Shuffle时分区的个数。一般情况下,各Join实现算法取该参数的默认值。同时,用户也可根据生产环境配置手动调整该参数,但是手动调整人工代价大且难以做出正确估计,很难给出最佳参数配置。
如何减少网络传输代价、合理设置Join的并行度,提升现有的Spark-over-HBase平台下的大表Join性能对于大规模数据查询分析意义重大。
基于此,本文重点从优化算法流程以及动态设定并行度两方面来提升Join操作性能,具体的贡献如下:
(1) 借鉴Semi Join算法[11]的思想,首先提取左表Join列数据构建HashMap,利用该HashMap对右表进行过滤,过滤掉右表Join列数据不在HashMap中的元组,即不符合连接条件的元组。通过该预处理流程,可以减少右表参与Shuffle操作的数据量和进行Join匹配的数据量,降低网络传输开销和相关的CPU开销。
(2) 考虑集群的CPU核数配置来动态设置Join操作的并行度,尽可能充分利用集群资源,提升Join操作效率。
基于以上的优化方法,本文进行了理论分析和对比实验验证。实验结果显示,对于两张表Join列数据不完全匹配的情况,右表与左表匹配数据量越少,本文所提方案优化效果越明显。
1 相关工作
Join操作是大规模查询分析中最常见且开销最大的操作之一,在Spark查询引擎中利用Broadcast Hash Join算法、Shuffle Hash Join算法和Sort Merge Join算法来实现。Broadcast Hash Join算法局限性大,主要适用于两表数据量相差极大,且小表数据量小于规定阈值的场景,本文不予讨论。后两种算法均属于Repartition Join,主要是在进行Join之前对两表数据进行Shuffle操作。Repartition Join主要处理参与Join的两个表数据量都很大的场景,通过Shuffle操作实现两表分区数据有效匹配,但是Shuffle操作的磁盘I/O开销、网络通信开销和内存处理开销很大。
目前,针对各类查询引擎进行大表Join操作的查询优化已经有了很多的研究。
文献[12]提出了基于Hadoop框架的大数据集的Join优化算法,算法主要利用Hadoop的分布式缓冲机制来优化MapReduce框架的Reduce Side Join。对于参与Join操作的两个表,算法先提取出其中一个表的连接属性,然后利用Bit-map数据结构压缩成小数据文件存入磁盘中,通过Hadoop的分布式缓存机制将小数据文件传输到各个分布式节点。然后,在Map阶段,利用读取到的小数据文件对另一个表的数据进行过滤,过滤掉不在该小数据文件中的元组,即不满足Join连接条件的元组。最后,在Reduce阶段将两表连接属性值相同的元组执行Join操作。该优化算法利用其中一个表的连接属性对另一个表的数据进行预过滤,可以减少Shuffle阶段的数据量,降低网络传输开销。但是该算法利用Bit-map数据结构进行压缩,对另一个表数据过滤时存在一定的误判率,对数据的过滤性不好。而且,该算法需要利用Hadoop的分布式缓存机制将小数据文件存入磁盘,额外增加了I/O开销,影响了最终的Join优化效果。
文献[13]提出了一种基于Bloom Filter数据结构的Spark大表等值连接的优化算法。该算法首先对两张数据表抽取连接属性并进行去重,然后利用Bloom Filter数据结构对去重后的连接属性分别进行压缩得到两个位数组,对两个位数组进行“与”运算,生成BF位数组。利用这个BF位数组再分别对两张表进行过滤,即过滤掉不符合连接条件的记录。最后,对过滤后的两张表执行Hash Join算法,得到连接结果。该优化算法利用Bloom Filter数据结构,同样是过滤掉两个表中不符合连接条件的元组,减少Shuffle操作的数据量。但是对两张表的连接属性进行去重时涉及Shuffle操作,且随着连接属性值的增多,该部分开销随之增加。而且Bloom Filter的数据结构压缩效率没有Bit-map数据结构好,且为了降低误判率,位数组的长度还需适当增加,如何选定合适的误判率以及对应的位数组大小仍需进行优化。
文献[14]在Spark平台上针对大维表的等值连接提出了优化算法。算法主要包括以下几步:(1) 对事实表Fact的连接属性值Key进行去重,得到无重集FactUK,FactUK中元组不仅包括Key键,也包括其在Fact表中的存储位置。(2) 将FactUK与维表Dim进行预连接,执行Partition Join。其中,重分区的个数按照Fact和Dim的大小进行动态设定,并利用一致性哈希算法来进行重分区,避免了因数据倾斜产生的连接负载不均的问题,然后在各个分区上对FactUK和Dim按照Key进行cogroup分组并过滤掉不能匹配上的Key。(3) 将预连接结果按照Fact的分区号进行重分区,在各个分区将预连接结果与Fact表通过zipPartition操作进行组装,返回完整的连接结果。该优化算法主要在于结合了Partition Join与Semi Join的优势,对两表数据进行重分区和预连接,减少了对于事实表全表数据进行重分区的Shuffle开销,同时也优化了连接执行的并行度、采用一致性哈希来进行数据分区,以此获得更好的连接性能。但是该算法也增加了对事实表连接属性值去重的Shuffle开销,并且该算法假设事实表和维度表的数据可以完全缓存到内存中,而在实际生产环境中,很难将所有数据完全缓存到内存中。
2 优化方案
本方案中各分区的连接算法仍采用Sort Merge Join,主要利用Semi Join思想对参与Join的两表数据进行预处理,并且动态设定Join操作的并行度,以获得更好的优化效果。假设参与Join的两个表分别为R表、S表,连接条件为R.A=S.B,其中A为R表key键,B为S表列族中的对应列。定义该优化方案为Semi Sort Merge Join,其对应的Join执行流程如下所示。
2.1 数据预处理
基于Semi Join算法进行数据预处理的流程如下:
(1) 提取R表Join列。对R表中的元组进行投影,只保留Join列的信息,结果定义为joinSet数据集。因为HBase数据库中Key键的唯一性,所以该Join列数据没有重复值。并且只提取单列数据,数据量少。
(2) 构建HashMap。对(1)中的joinSet数据集构建HashMap。为了尽可能减少HashMap的内存开销,设定HashMap的Key键为Join列值,value值统一设定为null。
(3) 过滤S表数据。利用(2)中HashMap的Key键匹配S表的Join列,对S表数据进行过滤,剔除掉S表中B列数值不包含在HashMap中的元组。
利用Semi Join算法的思想对数据进行预处理,在执行Join操作前,在内存中构建R表Join列数据的HashMap,利用该HashMap对S表数据进行精确过滤,过滤掉S表数据的Join列在R表中没有相关匹配值的元组,可以减少后续操作中对S表的无用数据进行Shuffle操作的磁盘I/O开销、网络开销和相关的CPU开销,也减少了后续参与Sort Merge Join的数据量。
2.2 进行Shuffle操作
对于Repartition Join的实现,Shuffle操作就是按照设定的重分区的个数对R表和S表数据按照Join列数据的Hash值进行重分区。在Spark SQL中,Shuffle操作重分区的个数主要由参数spark.sql.shuffle.partitions决定,默认值是200。因为重分区的个数直接关系到Join操作执行的并行度,所以合理设置重分区的个数尤为重要。如果该数值设定过小,会导致集群处理性能低且资源利用不合理,未发挥集群优势;如果设定过大,则网络连接超负荷、任务调度开销大,也不利于提升集群的处理性能。
所以在本文方案中,考虑利用动态优化的思想,在执行过程中根据集群资源来动态设定重分区的个数,以此来优化Join操作的并行度。定义重分区个数为Partitionnum,其计算公式如下:
Partitionnum=w×corenum
(1)
式中:corenum表示集群中executor实例总的CPU核数。因为集群的计算能力受制于集群中CPU核数的个数[15],因此用w×corenum表示集群资源的限制。如果分区个数等于corenum,即Join操作的并行度等于corenum,w=1,则可能某些运行较快的任务较早运行完,空闲出相应的CPU核;如果设定w过大,则可能任务调度过于频繁,开销过大。本文设置多组实验,设定不同的重分区个数,测试得出w的最优值为2。
综上所述,优化后该步骤进行Shuffle操作的具体流程如下所示:(1) 通过配置—num-executors、—executor-cores分别获取Spark集群中每个节点上executor的实例数和每个executor所分配的CPU核数,则集群中executor实例总的CPU核数为两者的乘积;(2) 按照式(1)设定spark.sql.shuffle.partitions参数;(3) 利用Spark的Sort Based Shuffle策略对两表数据进行重分区。
2.3 各分区并行执行Sort Merge Join算法
通过Shuffle操作,将两表的数据分为具有相同个数的多个分区,然后对两表具有相同分区号的分区数据进行合并,执行Sort Merge Join操作,主要流程如下:(1) 在各分区上,对两表数据按照相同排序规则进行排序;(2) 分别顺序遍历两表数据,按照Join连接条件进行匹配。
综上所述,该优化方案的整体执行计划如图2所示。(1) 利用TableScan获取R表数据,通过Map映射Join列数据,并利用CollectAsMap算子构建Join列的HashMap数据结构;(2) 利用TableScan获取S表数据,通过Map映射好各属性后,利用R表Join列数据的HashMap对S表数据进行过滤,过滤掉S表Join列数据不在HashMap中的元组;(3) 通过Map映射R表的各属性;(4) 按照应用配置,计算集群中executor实例总的CPU核数,并根据Join列的Hash值以及2×corenum对R表和S表数据进行重分区;(5) 在对应分区上分别对两表数据进行Sort Merge Join。
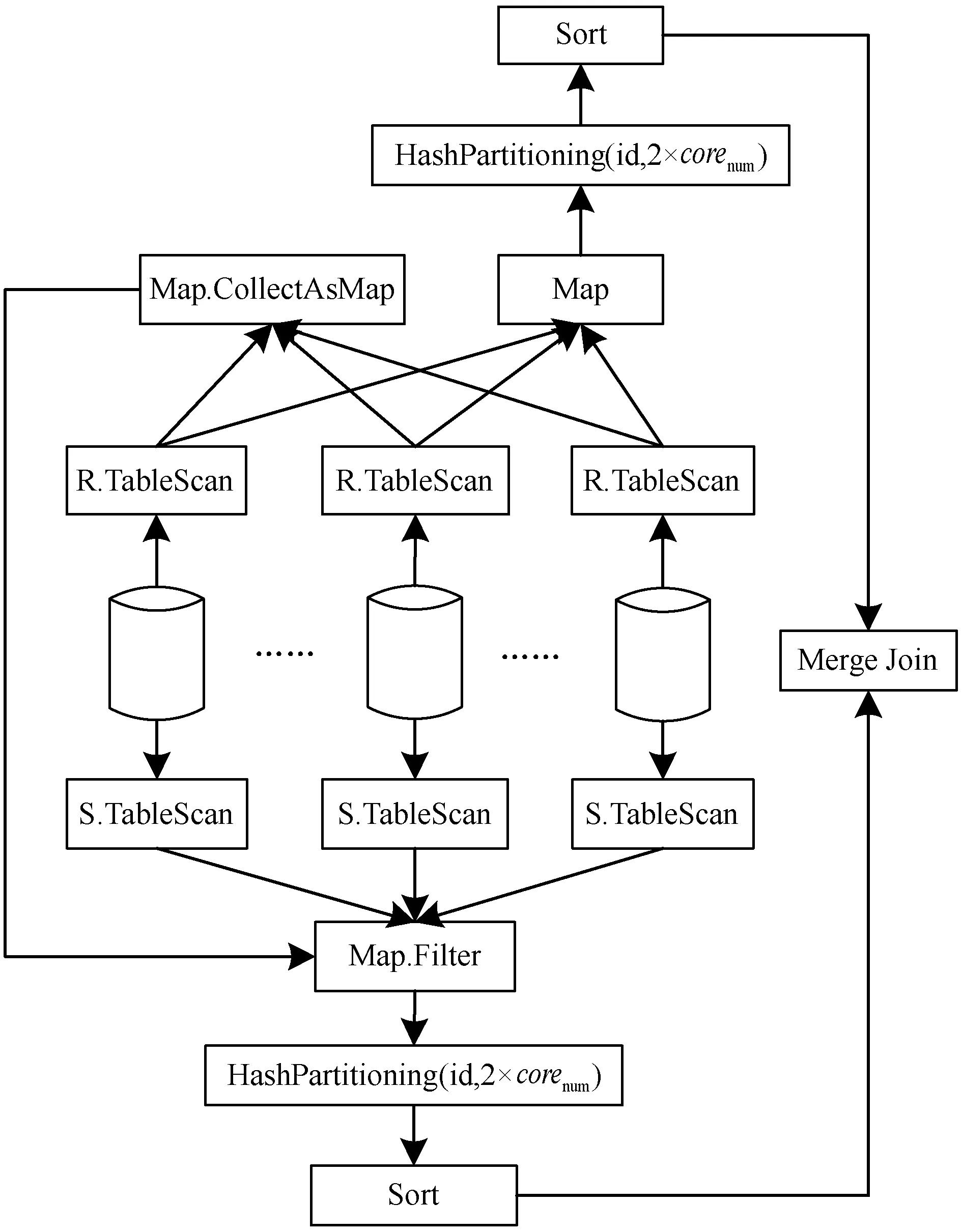
图2 Semi Sort Merge Join算法执行计划
3 优化方案分析
3.1 代价估算
Spark并行处理框架是基于分布式共享内存进行计算处理的,即在任务执行过程中,数据是缓存在内存中进行计算处理的,必要情况下需要将中间结果存入磁盘,例如Shuffle操作。为了简化分析思路,本节方案分析不考虑将中间结果存入磁盘的情况,同时假设内存充足,所有中间结果可以有效缓存在内存中并进行内存计算。
本节的方案分析利用代价模型[16-17]进行代价估算。代价估算基于第2节中的例子,定义代价估计中各参数及参数意义如表1所示。
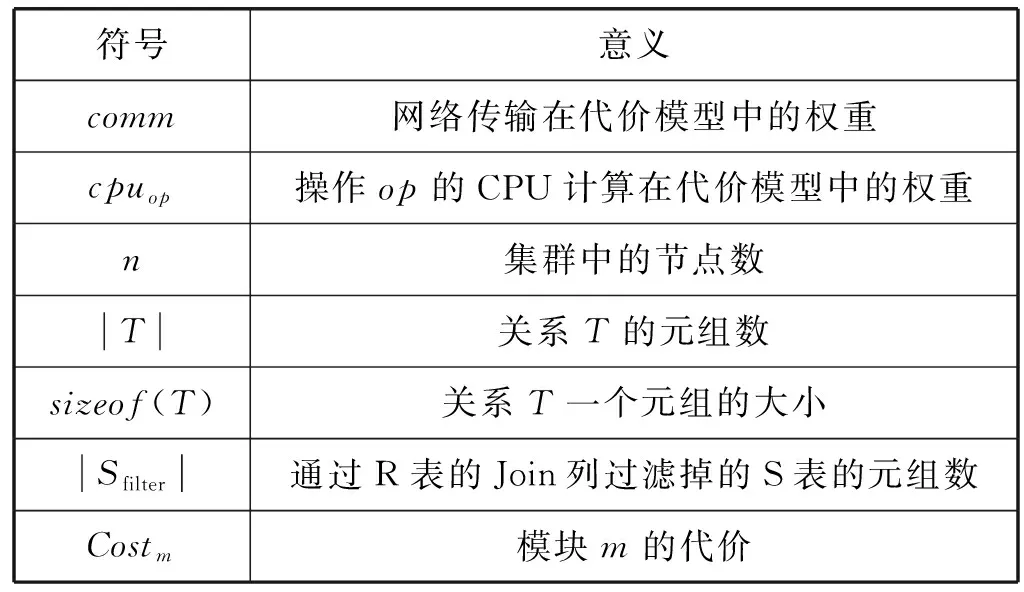
表1 代价模型中各参数及意义
为了方便分析,定义Filterability(过滤性)表示通过R表的A列对S表进行过滤后,S表过滤掉的元组数占原表元组数的比例,其计算公式如下:
(2)
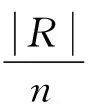
对于分布式数据处理,主要考虑I/O代价、网络传输代价和CPU的计算代价这三方面,总的代价估计如式(3)所示。
异丙托溴铵联合布地奈德混悬液雾化吸入治疗上呼吸道感染后慢性咳嗽的效果……………………………… 陈衍秋 陈英俊(3)335
Costtotal=CostI/O+CostComm+CostCPU
(3)
I/O代价主要考虑读取参与Join的表所耗费的时间,因为优化前后均是对数据进行全表扫描,所以该部分代价不进行对比分析。在分布式环境下,网络传输开销占比较大,相对而言CPU的计算开销占比很小,所以本节重点分析优化方案的网络传输代价。优化方案的网络传输代价主要包括对R表Join列构建的HashMap的网络传输时间和Shuffle过程中进行数据重分区所耗费的时间,该部分的代价主要与网络传输的数据量有关,数据量越大,网络传输代价越大。具体如式(4)所示。
Costcomm=(sizeof(H)×|H|+
max(sizenR,sizenfilterS))×comm
(4)

3.2 代价对比
本文方案主要是在Spark实现的Sort Merge Join算法基础上进行改进的,在各分区上仍旧采用Sort Merge Join算法执行Join操作,所以本节主要对比Semi Sort Merge Join算法与Sort Merge Join算法的网络通信代价,对比情况如下:
Sort Merge Join算法未对数据进行过滤,通过TableScan后直接将两表数据进行Shuffle操作,涉及的网络传输代价如式(5)所示。
Costcomm=max(sizenR,sizenS)×comm
(5)
在Semi Sort Merge Join算法中,如果对R表Join列投影后行数和宽度都相对较小,而右表S表是宽表且行数较多,则sizeof(H)×|H|的网络传输代价可以忽略不计。此时,过滤性对网络传输代价影响较大,FT越大,其过滤数据量越多,网络传输数据量越少,对应网络传输代价越小。相较于文献[12-13],如果误判率较高,对S表数据的过滤性不好,不符合连接条件的数据产生的网络传输量就比较大。但是,如果对R表Join列投影后行数和宽度都相对较大的情况下,sizeof(H)×|H|的网络传输代价不容忽视。例如R表和S表全表匹配的情况下,生成HashMap以及将其进行网络传输的开销会降低Semi Sort Merge Join的执行效率。
综上所述,对于R表和S表数据不完全匹配的情况下,Semi Sort Merge Join算法的性能提升主要在于通过R表的Join列构建HashMap后,过滤掉S表不符合连接条件的元组,从而减少Shuffle操作的数据量,减少Shuffle write和Shuffle read的开销。
4 实 验
4.1 系统配置
本实验使用三台服务器搭建HBase集群和Spark集群,服务器的硬件配置以及相关的软件版本如表2所示。
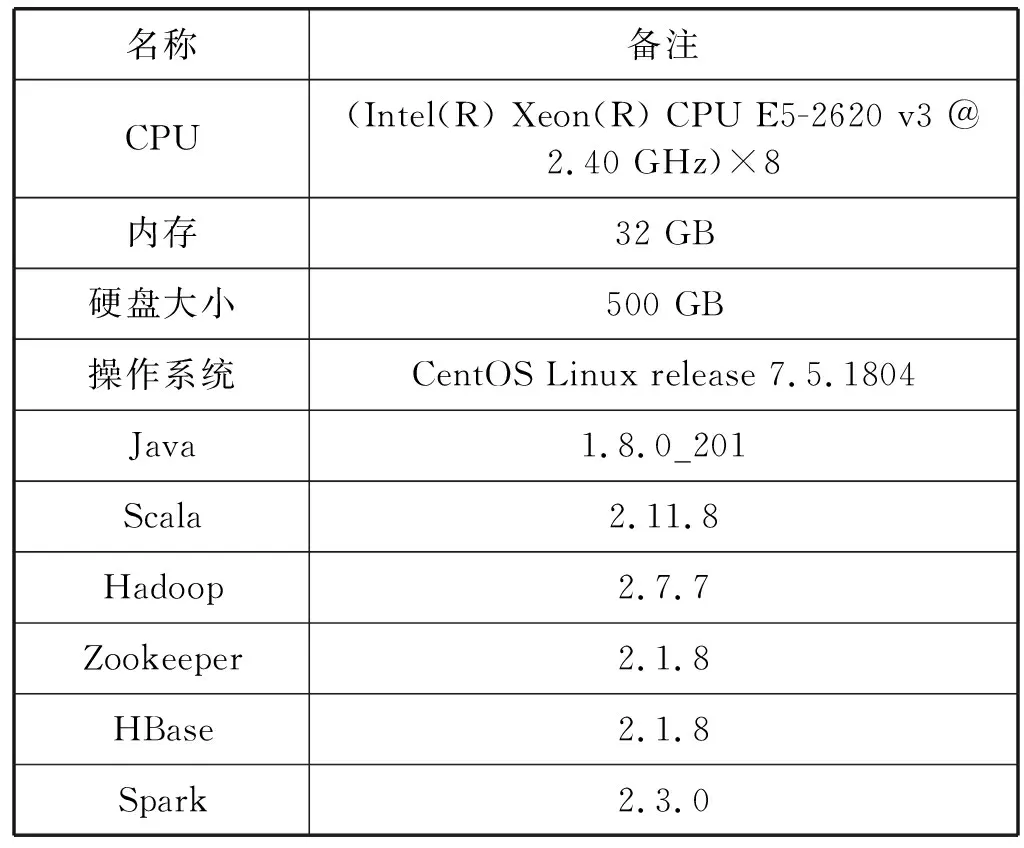
表2 相关配置及软件版本
4.2 测试数据集
本文的实验均使用TPC-H Benchmark数据集[18]。TPC基准是被全球数据库厂商公认的性能评价标准,其中的TPC-H测试基准是一组决策支持基准,可测试系统执行复杂、高并发查询的能力。
TPC-H数据集总共包括8张表,根据表之间的关联性,选择orders表(订单表)和lineitem表(订单明细表)来进行Join查询性能的实验。实验数据表使用TPC-H提供的数据生成器生成数据,数据大小由比例系数SF决定的,根据SF的不同大小生成不同数量的测试数据集。
4.3 实验设置
本节实验主要通过两表Join查询来测试Spark查询引擎提供的Sort Merge Join算法的查询处理性能以及本文方案的性能。实验主要利用orders表和lineitem表进行等值连接,连接条件为orders.O_ORDERKEY=lineitem.L_ORDERKEY。
本文设置的每组实验均执行5次,实验结果取平均值。
4.4 Semi Join算法预处理的性能优化测试
本节主要测试优化方案中利用Semi Join算法进行数据预处理对Sort Merge Join算法的提升效果。实验对应的lineitem表的行数为1 200万,为了测试两表之间匹配程度对算法的影响,设置orders表的数据量分别为1 000、10万、100万、150万、300万,查询对应lineitem表中有效匹配元组数分别为4 000、40万、400万、600万、1 200万。
实验的结果如图3所示。其中横坐标表示orders表的行数,纵坐标表示查询执行时间,单位为秒。对比两个算法的执行时间,当orders表行数小于100万时,可以明显看到经过Semi Join预处理后Join执行时间更短。而且,随着orders表行数的减少,对应linetime表中有效匹配元组数逐渐减少,过滤掉的数据量逐渐增多,通过Semi Join算法预处理后对于Spark的Sort Merge Join算法的提升效果更加明显。但是,随着orders表数据量逐渐增加,对应linetime表中有效匹配元组数也在增加,过滤掉的数据量也逐渐减少,利用Semi Join进行预处理反而不利于Sort Merge Join的执行,主要是受提取orders表的Join列数据构建HashMap的内存和网络传输开销的影响。
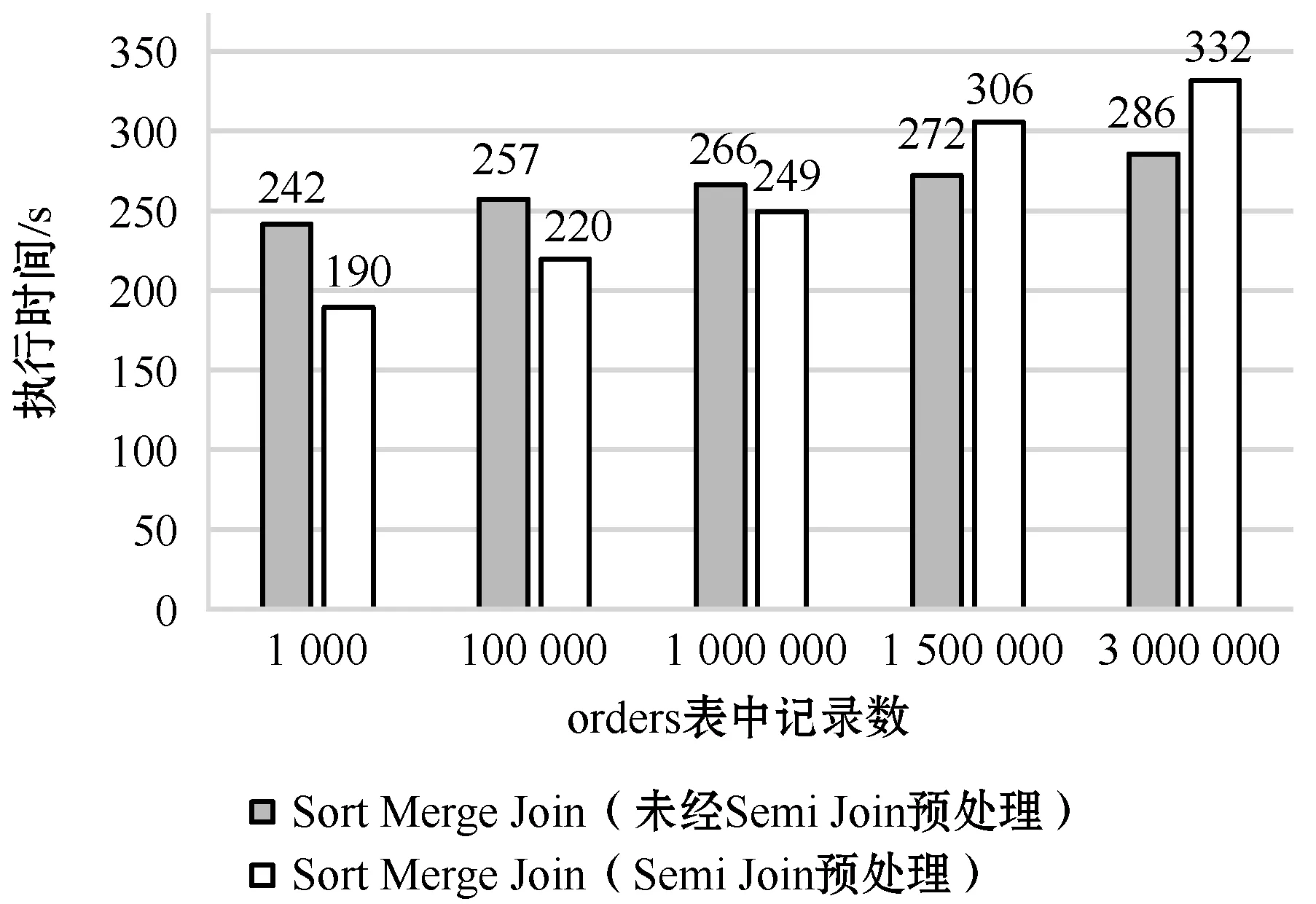
图3 Sort Merge Join算法经过Semi Join预处理与未经Semi Join算法预处理响应时间对比
所以,Join之前利用Semi Join算法进行数据预处理主要适用于左表与右表Join列值不完全匹配的场景。右表与左表Join列值匹配数越少,过滤掉的右表数据量越多,则参与Shuffle操作以及Sort Merge Join的数据量越少,对Join操作的性能提升越有帮助,提升效果越显著。
4.5 Join操作并行度优化测试
由4.4节可知,对于左表与右表Join列值不完全匹配的场景,经过Semi Join预处理后,Sort Merge Join算法的提升效率显著。在此基础上,进一步测试Join操作的并行度对Sort Merge Join算法的提升效果,即对比本文所定义的Semi Sort Merge Join算法的完整优化方法与Sort Merge Join算法的性能。
在本节实验中,选用100万行的orders表和1 200万行的lineitem表进行实验。在搭建的Spark集群中,集群Worker节点数为2,每个节点上分配2个executor,对每个executor分配2个核,则集群中的总核数为8。在实验设计中,调整参数spark.sql.shuffle.partitions来设定shuffle时不同的重分区个数,从而影响到Join操作的并行度,以此来测试Join操作的并行度对执行时间的影响,结果如图4所示。

图4 Join操作并行度对查询时间的影响
可以看出,当设定重分区个数为16,即Join操作的并行度为16时,Semi Sort Merge Join算法执行时间最短。所以,当设定重分区个数为Spark集群的CPU核数的2倍时,Join执行性能最优。因此,对于2.2节中的式(1),设定w系数为2。
4.4节中仅测试经过Semi Join预处理后对于Sort Merge Join的提升效率,未测试Join操作的并行度优化对算法的影响。在100万行的orders表与1 200万行的lineitem表进行Join操作的场景中,未经过Semi Join预处理的执行时间为266 s,经过Semi Join预处理的执行时间为249 s,优化后算法性能提升了6.39%。在本节中进一步设置好最佳并行度后,Semi Sort Merge Join算法的执行时间为222 s,相较于未经过Semi Join预处理的Sort Merge Join算法性能提升了16.54%。可见,通过动态设定连接并行度对Join操作的查询也有很大的帮助。
5 结 语
Spark支持大规模数据处理,对任务进行分布式并行执行。但其涉及开销较大的Join操作,一直是大数据查询分析的瓶颈。本文对Spark现有的大表Join实现算法进行了研究,发现其未考虑两表Join列数据匹配关系对Shuffle操作的影响。因此,本文基于Semi Join,根据两表Join列之间的匹配关系,提出了一种改进的Join实现算法。该算法利用左表Join列数据所构建的HashMap对右表数据进行过滤,主要适用于两表Join列数据不完全匹配的情况,且右表与左表匹配数据量越少,该算法优化效果越明显。
