基于tri-training和极限学习机的跨领域信任预测
2022-09-06童向荣
王 岩 童向荣
(烟台大学计算机与控制工程学院 山东烟台 264005)
(yixinwon@163.com)
当前各种网上活动中用户与用户之间的交往必不可少.在互联网生活中,无法轻易判断陌生用户是否可信.许多学者利用神经网络、强化学习以及矩阵分解等方法预测用户间的信任关系或者判断用户的喜好,为用户推荐喜欢的内容,其需要利用用户的各种信息,比如用户邻居的偏好、用户项目点击量和用户评价等信息.这些工作大多基于一个领域,但是实际上用户有各种各样的社交领域,一个用户存在于多个不同的社交网络,虽然领域不同,但是当一个网络中的交易信息过少,则缺少标签,利用其他网络的信息帮助系统预测是有必要的.
目前信任评估的研究已涌现出大量的研究成果,但通过其他领域预测信任关系的研究成果却很少.Liu等人[1]利用非对称tri-training模型进行跨网络的信任预测,该模型利用BP神经网络作为分类器,整个模型一共有3个分类器,前2个用于预测伪标签,第3个用于预测目标网络的用户关系.利用BP神经网络结合非对称tri-training构建模型的方法存在2个问题:1)BP神经网络回溯训练找到最优解需要时间长;2)该模型只有2个分类器产生伪标签,需要设置专家阈值.
受tri-training、非对称tri-training以及Liu等人的启发,本文扩展非对称tri-training模型,将tri-training作为框架中的一部分,分类器利用速度更快、泛化性更强的极限学习机.模型有4个分类器,首先通过tri-training模型利用源网络的共同特征训练前3个分类器;然后用训练好的分类器预测目标网络训练集样本,产生伪标签,利用“少数服从多数”原则将伪标签样本加入到目标网络伪标签样本集中;再次用加入特殊特征的伪标签样本集对第4个分类器进行训练;最后利用第4个分类器对目标网络进行预测.
本文的主要贡献有4个方面:
1) 扩展了基本的tri-training模型框架.原始的非对称tri-training一共有3个分类器,其中前2个用于产生伪标签,第3个进行分类.我们将产生伪标签的分类模型改为tri-training模型,然后第4个分类器进行分类,形成最后的模型框架.
2) BPtri-training的算法定义了分类器专家阈值,需根据实验确定阈值,且网络不同,阈值可能也不相同.而我们采用“少数服从多数”投票机制选择tri-training中的伪标签,这样解决了由于预测不同网络需要设置不同阈值的问题.
3) 框架内分类器采用极限学习机,其速度更快,结构更为简单,且泛化能力更强.
4) 利用类似迁移学习机制保存训练模型,即保存输出矩阵β,将训练模型应用到异构领域预测信任关系.
1 相关工作
信任是判断人与人之间交往的一个重要指标,童向荣等人[2]认为信任的表示分为3种:第1种用逻辑表示,将信任认为是二值的,即信任和不信任,用1和0表示,还可以分为信任、不信任和不清楚,分别用1,-1,0来表示.第2种用级别表示,即信任被认为是一个离散区间值,一般有[-1,1]和[0,1]2种情况:前一种情况认为绝对不信任是-1,半信半疑是0,而绝对信任是1;后一种情况,0是不信任,1是信任.第3种用概率表示,即某个用户对另外一个用户的信任程度,概率值越大,表明用户对另一用户的信任值越高,概率为1表示完全信任,概率为0表示用户对另一用户完全不信任.例如,关系R=u,v,p表示用户u对用户v信任的概率是p.本文采用二值逻辑表示信任关系,即1和0.
信任预测应用广泛,一些学者将其应用于电子商务[3]、医疗物联网[4]和广告判断[5].在信任预测问题中,大多数学者基于一个网络进行信任预测研究,比如Liu等人[6]考虑了用户评分的本地上下文信息以及用户的全局偏好建立用户相似度模型,有效解决了用户评分少导致的信任评估不准确问题.Ardissono等人[7]基于信任的推荐系统,在公开匿名信息的基础上增加了关于信任的证据,即个人贡献质量和多维全局声誉.由于社会关系的稀疏和不平衡,Wang等人[8]量化信任和不信任的相关因素,将这些特征作为证据输入到神经网络中,利用Dempster-Shafer理论进行信任和不信任预测.亓法欣等人[9]提出一种利用强化学习增强信任值以提高推荐性能的方法.Wen等人[10]提出了一种高效的开源支持向量机(support vector machine, SVM)软件工具包,称为ThunderSVM,它利用了图形处理单元和多核CPU的高性能,帮助用户轻松有效地应用SVM解决问题.
在不同领域的信任预测研究中,2017年Saito等人[11]在tri-training的基础上提出了一种用于无监督域自适应的非对称tri-training算法,该算法的目标是对与标记源样本具有不同特征的未标记目标样本进行分类.Liu等人[1]在2020年设计了一个新的非对称tri-training模型,其结合了源网络和目标网络的共同特征以及目标网络的特殊特征预测目标网络的社会关系,他们利用BP神经网络作为构建非对称tri-training的分类器.
如何通过一个网络的信息预测另一个网络的信息,重点是保存训练的模型,将其用于目标网络的预测.在过去几年中,关于迁移学习的研究取得了巨大的成功.通过使用迁移学习方法,可以通过信息丰富的源网络预测信息稀疏的目标网络的关系.Tang等人[12-13]开发了一种框架,基于因子图模型社会理论合并预测社会关系,称为TranFG.该算法通过训练源网络获得初始模型,然后将初始模型应用于预测目标网络的关系.Chen等人[14]通过从源域训练样本得到初始模型,然后使用该模型用于训练目标域样本得到伪标签,接着将伪标记的样本合并迭代地重新训练模型,直到收敛为止,该方法也称为co-training.像co-training一样,Zhou等人[15]在2005年提出了一种半监督学习算法tri-training,构建了3个分类器,用于为无标签数据贴上标签.对于未标记的数据,Lee[16]证明伪标记代表选择了具有最大预测概率的类别,它等效于熵正则化.本节将对前人所做的一些工作进行简要介绍.
1.1 tri-training
tri-training[15]是一种半监督学习算法,该算法的特点是使用了3个分类器,利用训练集训练3个分类器,其中训练集样本采用可重复采样选取,将测试样本利用训练好的3个分类器以“少数服从多数”的原则产生预测结果,最终3个分类器通过投票机制作为1个分类器进行使用.
该算法的优点是有3个分类器、利用投票机制、符合现实情况且效率高、不需要设置相关阈值、速度快、提高了模型的学习性能、保证学习效率.
1.2 非对称tri-training
非对称tri-training[11]是一种无监督自适应的算法,在tri-training的基础上构建,同样有3个分类器,分类器采用基本的BP神经网络,功能和tri-training的3个分类器不同,非对称tri-training的主要思想是:1)利用源网络的有标签样本训练得到前2个分类器.2)输入目标域的样本到训练好的分类器,产生伪标签.如果2个分类器对同一个样本产生的伪标签相同,将样本加入到伪标签样本集中;如果不同,则判断分类器的置信度是否大于设定的专家阈值,符合条件的样本同样也会加入到伪标签样本集合中.产生的伪标签样本集和源域样本集会集合重复训练前2个分类器,直到达到收敛.3)利用伪标签样本集训练得到第3个分类器,利用第3个分类器预测目标网络.
该算法产生伪标签样本判断条件限制多,涉及不同网络阈值的设置问题,且采用BP神经网络运行速度慢,所以本文模型在其基础上扩展,使用速度快、泛化性强的极限学习机作为分类器.
1.3 极限学习机
极限学习机(extreme learning machine, ELM)[17]分类器采用随机权值和偏差,对于输出层权重通过广义逆矩阵理论计算得到,不用反复修改权重.如图1所示:
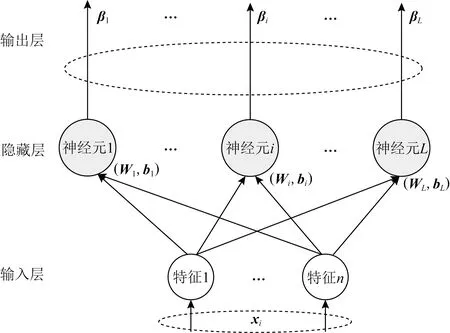
Fig. 1 ELM architecture[18]图1 ELM结构[18]
极限学习机从下到上分别是输入层、隐藏层、输出层.其中输入层输入N个样本,随机生成权重W和偏置b,隐藏层本文设置L个神经元,β是连接隐藏层和输出层的权重矩阵,输入测试样本,得到新的H(x),与矩阵β进行点乘,最终得到分类结果.相比Liu等人[1]利用BP神经网络作为分类器,我们利用极限学习机作为分类器,其速度更快且泛化能力更强.
假设有N个任意样本(xi,yi),样本特征xi=(xi1,xi2,…,xin)T∈n,n是样本的特征个数,样本标签yi=(yi1,yi2,…,yim)T∈m,m是分类结果个数,ELM随机生成权重Wi=(wi1,wi2,…,wiL)T和偏置因子bi=(bi1,bi2,…,biL)T,Wi符合[-1,1]的正态分布,bi符合[-0.6,0.6]的正态分布.
一个有L个隐层节点的单隐层ELM可以表示为
Hβ=Y,
(1)
其中,H是隐层节点的输出,β为输出权重,Y为期望输出.H,β,Y分别表示为:
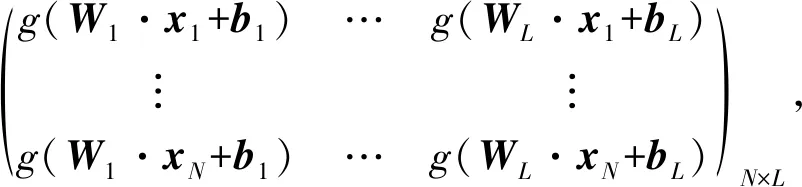
(2)
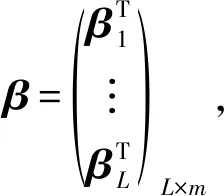
(3)
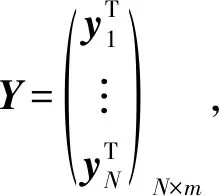
(4)
其中,g(W·x+b)是隐藏层的激活函数,采用sigmoid函数,表示为
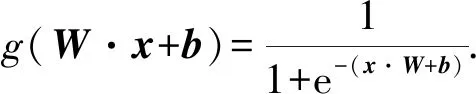
(5)
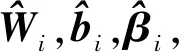
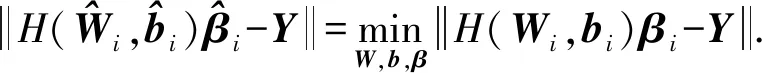
(6)
由于权重和偏置矩阵是随机生成,且ELM不会反向迭代更新参数,一次迭代求出权重矩阵β,即最终输出权重矩阵确定为
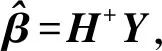
(7)
其中,H+是矩阵H的Moore-Penrose广义逆.
2 问题描述与基本定义
本节给出了问题的基本描述,介绍了网络间的共同属性和特殊属性.
2.1 问题描述
如图2所示,已标记的源网络有合作和不合作2种社会关系,未标记的目标网络有信任和不信任关系,问题是如何通过已标记的源网络预测未标记的目标网络的社会关系.基本思路是结合tri-training模型和非对称tri-training模型利用类似迁移学习的方法对网络进行预测,分类器采用速度更快的极限学习机.首先利用tri-training模型和“少数服从多数”投票机制产生目标网络伪标签,然后利用伪标记目标网络训练分类器ELM4,最后预测目标网络.
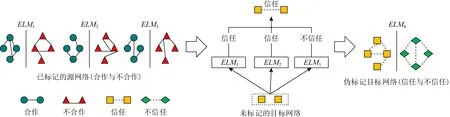
Fig. 2 Different networks for relationship prediction图2 不同网络进行关系预测
2.2 基本定义
定义1.社交网络.由图D=(V,E)表示,其中V表示用户集合,E表示边集合,即节点u和节点v之间的边e(u,v)∈E(D).Γ(u)={v:v∈V,e(u,v)∈E(D)}表示节点u的邻居集.
预测网络的关系需要结合网络的特征,但是由于网络的不同,所有网络有共同特征,个别网络有特殊特征,定义2~5是根据社交网络的结构特征总结的定义.
在社交网络中,嵌入性[19]用于测量2个用户之间共同邻居的数量.在现实世界中,2个人越亲密,他们就越有共同的朋友.因此,边e(u,v)∈E(D)的嵌入值可以描述为:
定义2.嵌入性.给定一个社交网络图D=(V,E),边e(u,v)∈E(D)的嵌入值为
Embeddness(u,v)=|Γ(u)∩Γ(v)|.
(8)
式(8)表示,2个用户之间的共同邻居越多,表示他们越有可能成为朋友.嵌入性在不同的网络中有较好的表达和泛化能力.几乎每一个社交网络都有此特征,利用它作为基本的结构特征.
聚类系数用于衡量节点聚集的程度.同样,边聚类系数可以直接反映2个用户朋友的朋友圈之间的紧密程度,节点u的聚类系数和e(u,v)∈E(D)的边聚类系数定义为:
定义3.节点聚类系数.对于一个节点u,其聚类系数为
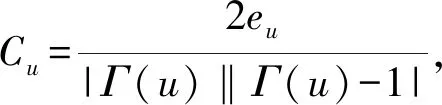
(9)
其中,eu表示与节点u相邻节点之间的边数.
定义4.边聚类系数.对于社交网络中的边e(u,v)∈E(D),Cu,Cv分别表示节点u和节点v的聚类系数,所以边聚类系数Cuv表示为
Cuv=Cu+Cv.
(10)
与边聚类系数相比,链接性(Linkness)[20]不仅评估节点的公共邻居的数量,而且也关注每个节点的其他邻居的数量.所以Linkness可以作为特殊属性来提高目标网络的预测性能.
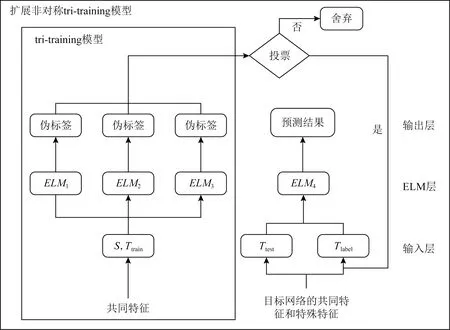
Fig. 3 ELMtri-training model图3 ELMtri-training模型
定义5.Linkness.对于一条边e(u,v)∈E(D),D的子图Duv=D[Γ(u)∪Γ(v)-Γ(u)∩Γ(v)-{u,v}],所以边e(u,v)的Linkness为
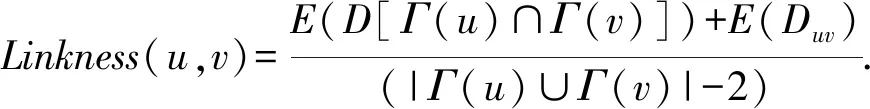
(11)
每个网络的结构特征取决于网络中节点的分布,在线社交网络中,用户之间频繁的交互影响着网络的结构.因此,为了预测目标网络的社会关系类型,将定义2~5的特征用于模型中分类器的输入.
3 跨领域信任预测模型
本节主要介绍网络框架以及训练算法的详细步骤.
3.1 网络框架说明
标记的源网络表示为Dsou=(Vsou,Esl,Xsou,Ysou),目标网络表示为Dtar=(Vtar,Etu,Xtar,Ytar).其中,Vsou是源网络的用户集合,Esl⊂Vsou×Vsou是源网络中标记关系的集合;Vtar和Etu⊂Vtar×Vtar分别是目标网络中的用户集合和目标网络未标记关系集合;Xsou和Xtar分别是源网络和目标网络的关系属性矩阵,每一行对应一个关系,每一列是一个属性.作为二进制分类(标签类型为0或1)的问题,Ysou和Ytar分别表示源网络和目标网络的关系矩阵,由0和1组成.0表示不信任、敌人、不支持或不合作关系,1表示信任、朋友、支持或合作关系.xi表示源网络中的第i个样本,yi表示边的类型.目标网络中样本的xi和yi与源网络中的含义相同.标记的源样本集可以表示为S={(xi,yi)}~Dsou,其中i∈[0,Nsou].同时,T是目标网络Dtar的未标记样本的空间,并且T={(xi)}~Dsou,其中i∈[0,Ntar].
根据2.2节中的定义,构建扩展非对称ELMtri-training模型,如图3所示,模型的构建分为2个部分:
1) tri-training模型.利用已标记源网络样本训练得到3个不同的分类器,然后输入带有共同特征的目标网络样本到3个分类器,产生3个伪标签,通过“少数服从多数”原则投票选取伪标签.
2) 扩展非对称tri-training模型.将tri-training投票产生的伪标签样本加入到伪标签样本训练集Tlabel中,利用含有共同特征和特殊特征的Tlabel训练第4个分类器,最后输入目标网络测试集得到预测结果.
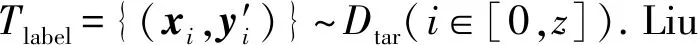
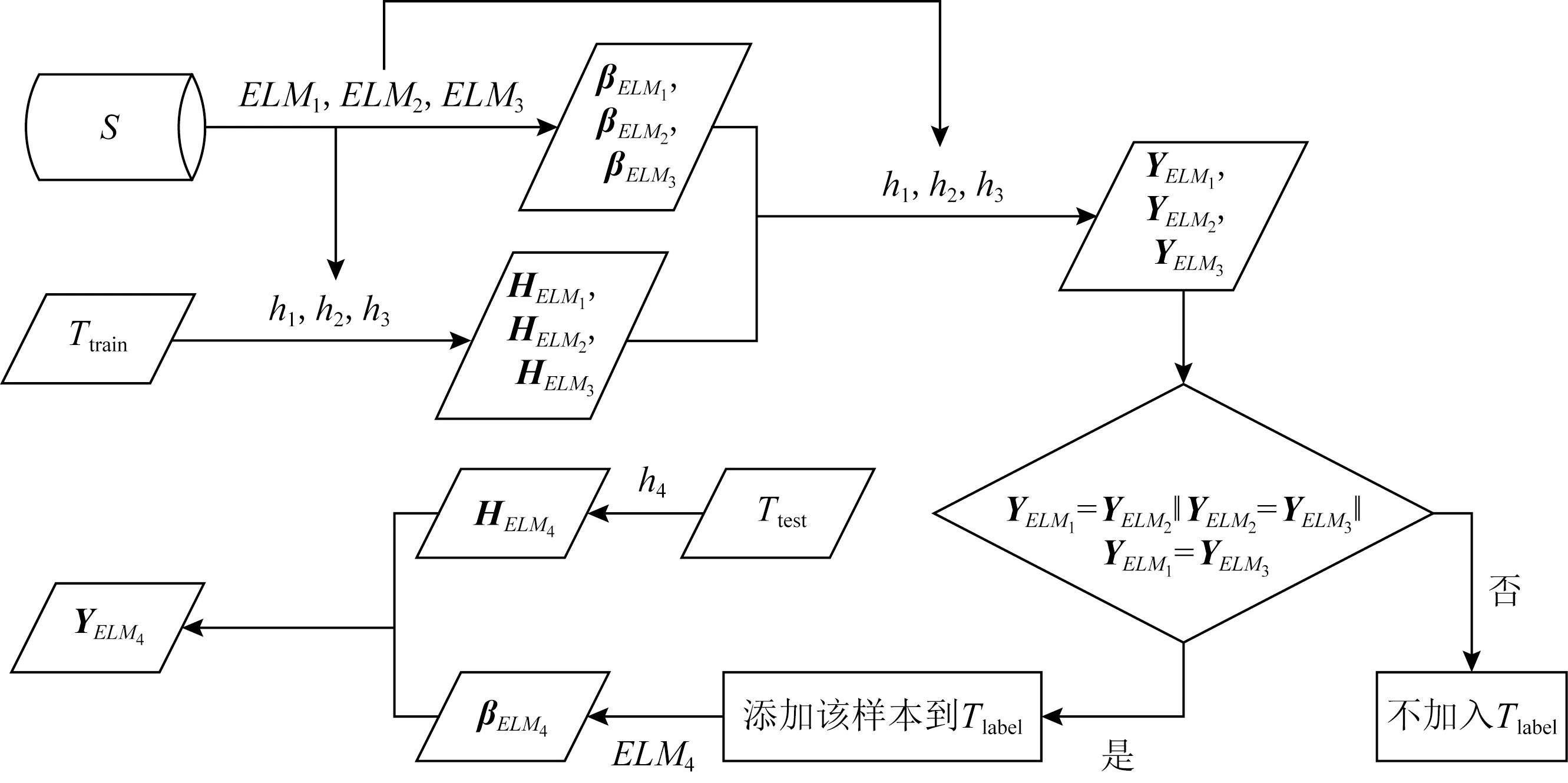
Fig. 4 Detailed process of ELMtri-training model图4 ELMtri-training模型的详细过程
3.2 训练算法
算法1描述了ELM1的训练过程,极限学习机ELM2,ELM3,ELM4与ELM1过程相同.
算法1.ELM1的算法过程.
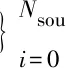
输出:预测结果.
① 随机生成输入权重W和偏置b;
② 根据输入的x以及权重W和偏置b计算隐藏层的矩阵H;
③ 计算隐藏层输出权重矩阵β=H+Y;
④ 输入目标网络样本重复步骤①②,计算得到的新矩阵H′与权重矩阵β相乘得到目标网络预测结果.
算法2.ELMtri-training算法.
输出:ELM4的预测结果.
① 初始化分类器权重W、偏置b;/*每个分类器权重随机生成,各不相同*/
② 利用S样本集训练ELM1,ELM2,ELM3得到βELM1,βELM2,βELM3;
③ 通过算法1利用Ttrain计算得到HELM1,HELM2,HELM3和YELM1,YELM2,YELM3;
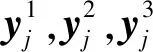
④ for (j=1;j≤len(Ttrain);j++) do
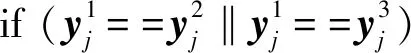
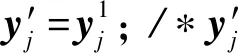
⑦ else
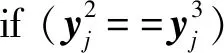
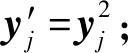
⑩ end if
算法2的主要步骤:
1) 初始化分类器权重为[-1,1]正态分布,偏置为[-0.6,0.6]正态分布,每个分类器权重偏置随机分配各不相同,利用已标记的源网络样本训练得到前3个分类器ELM1,ELM2,ELM3,源网络样本采取可重复取样选取1万个样本,目标网络选取未标记样本数量r=10 000.
2) 使用ELM1,ELM2,ELM3训练产生的分类器h1,h2,h3标记目标样本.tri-training模型中3个分类器h1,h2,h3对同一目标样本预测结果利用投票机制选取,将符合条件的样本加入到伪标签样本集Tlabel中.
3) 利用具有共同特征和特殊特征Tlabel训练ELM4得到分类器h4,输入Ttest计算得到预测结果.
3.3 复杂度分析
本节将从时间复杂度与空间复杂度2个方面分析算法复杂性.
1) 时间复杂度方面.实验部分已对BP神经网络和ELM进行了速度比较,ELM的运算时间小于BP神经网络的运算时间,假设ELM运行预测一个样本的时间为M,需要运算的数据量是N,则时间开销为O(M×N),ELM1,ELM2,ELM3的总时间开销为O(3M×(Nsou+Ttrain)),ELM4的时间开销为O(M×(Tlabel+Ttest)),相加为O(M×(3Nsou+3Ttrain+Tlabel+Ttest)).
2) 空间复杂度方面.模型需要存储源样本S、目标样本T和伪标签样本Tlabel,每次计算随机生成的权重W和b无需存储,4个分类器生成的矩阵β需要存储,所以总空间复杂度是O(S+T+Tlabel+βELM1+βELM2+βELM3+βELM4).
4 实验与结果
本节对6种数据集进行分析,说明数据集的共同特征以及特殊特征,对评价指标进行说明,列出ELMtri-training算法和其他算法的速度以及准确率对比、特殊特征加入对结果的影响,以及本文模型稳定性分析.实验在Intel®CoreTMi5-6200U CPU@2.30 GHz 2.40 GHz和4 GB RAM的PC上进行.
4.1 数据集分析
实验采用6种不同类型的数据集,它们是Alpha,OTC,Epinions,Slashdot,DBLP,WikiVote,以上6个数据集来自Leskove和Rok[21].所有数据集都包含2种类型的标签,Alpha,OTC,Epinions网络中的信任关系,Slashdot网络中的友谊关系,DBLP网络的同一社区中的合作关系以及WikiVote网络中的支持关系.实验数据集节点及关系数量如表1所示:
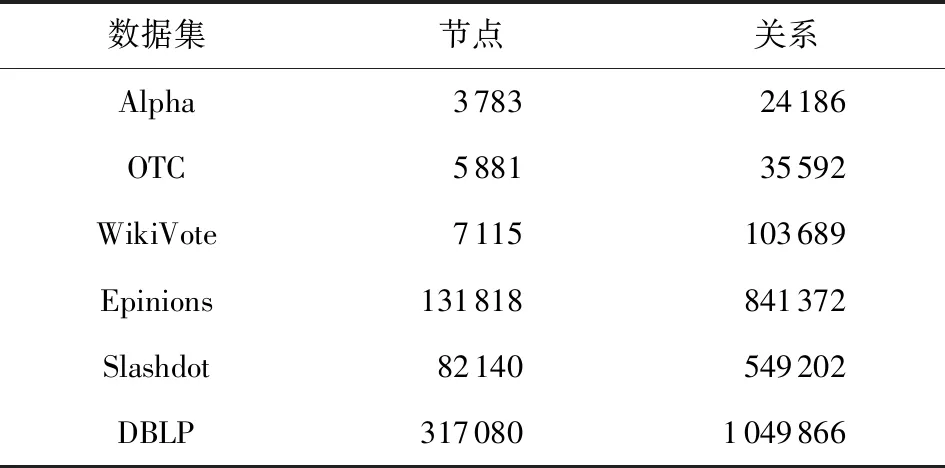
Table 1 Statistics of Six Datasets表1 6个数据集的数据集统计
参考文献[1]的分析结果,实验使用的6个数据集可以分为4种类型:1)Alpha和OTC网络具有较高的平均聚类系数和较低的平均路径长度,表现出小世界现象,说明用户与普通邻居之间的关系更紧密,可将边聚类系数和Linkness作为特殊属性.2)DBLP具有较高的平均聚类系数和较高的平均路径长度,可将边聚类系数作为特殊属性.3)Epinions的平均聚集系数低,平均路径长度长.4)WikiVote和Slashdot网络具有较低的平均聚类系数和较低的平均路径长度.其中Alpha,OTC,DBLP有特殊属性,其他3个网络只有网络共同属性.
参考6个网络的结构特征和数据集特征,表2列出其共同特征,表3和表4列出Alpha,OTC,DBLP的特殊特征.
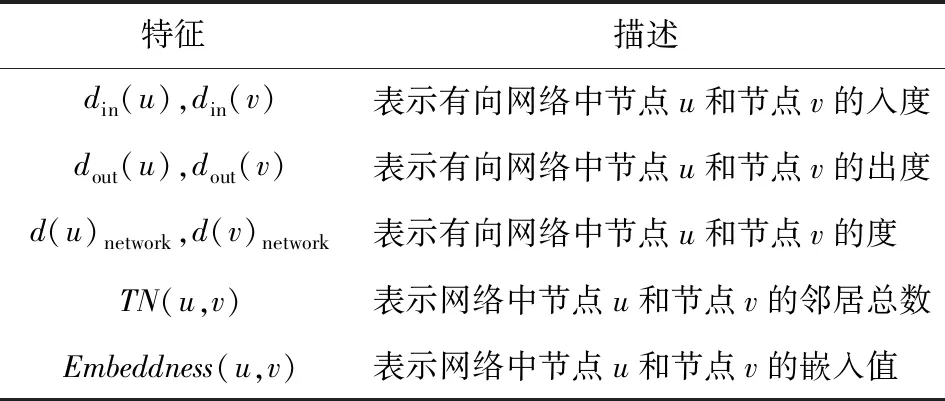
Table 2 Common Features表2 共同特征

Table 3 Special Features of Alpha and OTC表3 Alpha和OTC的特殊特征

Table 4 Special Features of DBLP表4 DBLP的特殊特征
4.2 评价指标
实验使用3个测量指标,分别为精度(Precision)、召回率(Recall)、F1度量(F1_score),分别表示为:
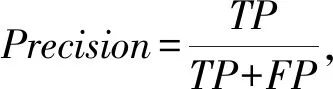
(12)
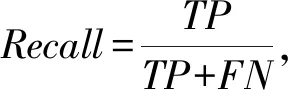
(13)
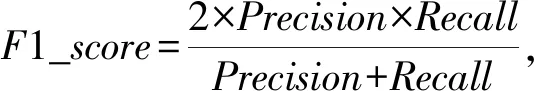
(14)
其中,TP表示将网络中值为1的预测为1的数量,TN表示将网络中值为1的预测为0的数量,FP表示将网络中值为0的预测为1的数量,FN表示将网络中值为0的预测为0的数量.
4.3 特殊特征作用
本节的实验测试训练ELM4时加入特殊特征对信任预测是否有提升作用.为保证实验准确性,设置2次实验伪标签样本加入特殊特征与否,其他参数保持一致,实验从源网络和目标网络分别抽取1万个样本,前3个分类器在2个实验中生成的权重相同,源网络2次实验随机抽取的样本相同,隐藏层神经元个数设置为100,使实验结果差距更明显,且每次测试不同源网络预测信任关系时,目标网络样本7∶3的样本不变.
Alpha,OTC,DBLP这3个网络有特殊特征,将源网络和目标网络组成的实验对:OTC-Alpha,Alpha-OTC以及Alpha-DBLP作为实验例子,实验分别从Precision,Recall和F1_score测试Tlabel中特殊特征的加入对结果是否有影响.由图5可以看出,一共有9个对比,其中7次加入特殊特征比没有加入特殊特征时指标高,由此可得出加入特殊特征对于信任的预测性能有提升,所以实验加入了特殊特征来进行.
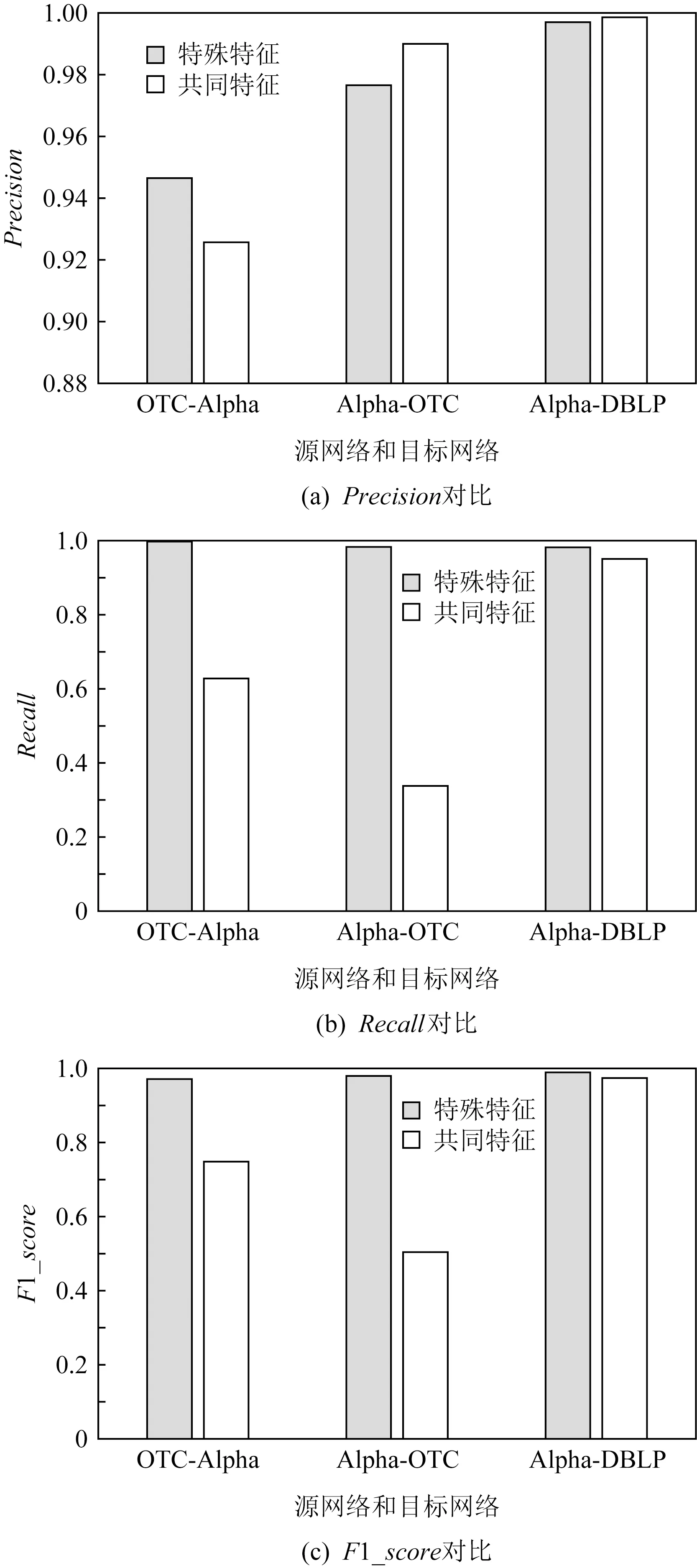
Fig. 5 Add special feature comparison图5 加入特殊特征对比
4.4 算法速度对比
实验在Epinions中选取1 000个样本,按照7∶3的比例分为训练样本和测试样本,构建一个输入节点为8、隐藏节点为300、输出节点为2的BP神经网络,迭代次数设置为300,将ELMtri-training模型的一个ELM分类器与SVM,Random Forest,ThunderSVM对比,如表5所示,BP神经网络和ELM预测的结果准确率相同,但是运算时间差距较大,ThunderSVM速度虽然快,但是准确率比ELM低,所以ELMtri-training模型采用ELM分类器.
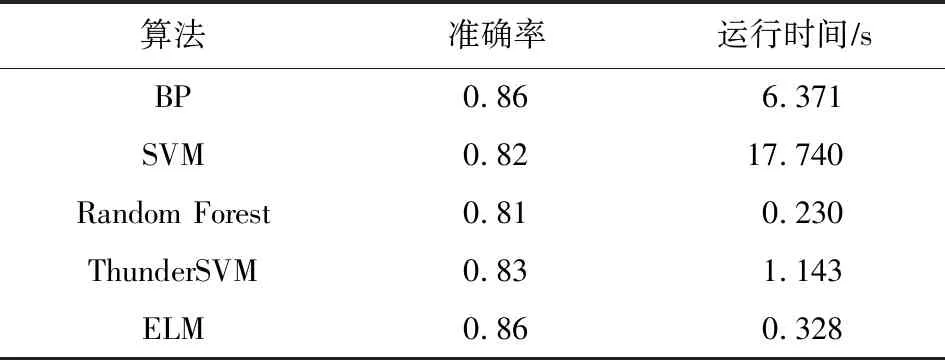
Table 5 Speed Comparison表5 速度对比
4.5 数据集测试
实验分别在源网络和目标网络中随机选取1万个样本,为保证实验的现实性,目标网络每次随机分配7∶3的训练集和测试集,实验结果取5次实验中最好的一次.
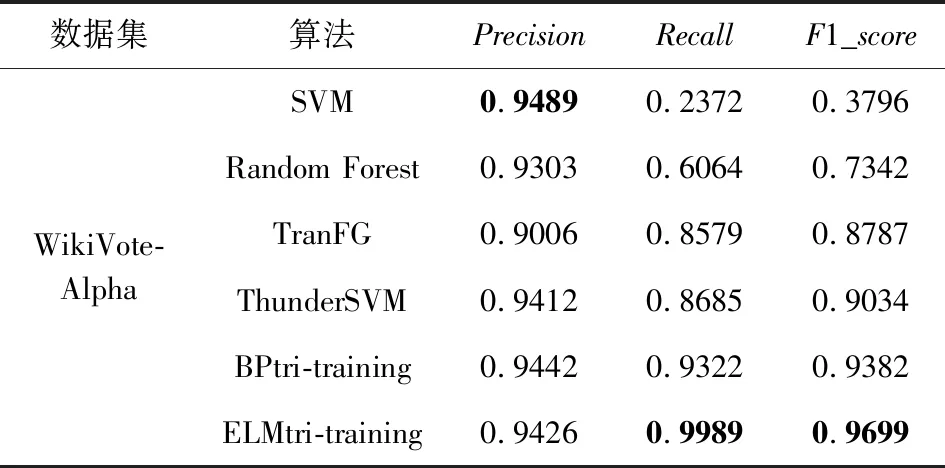
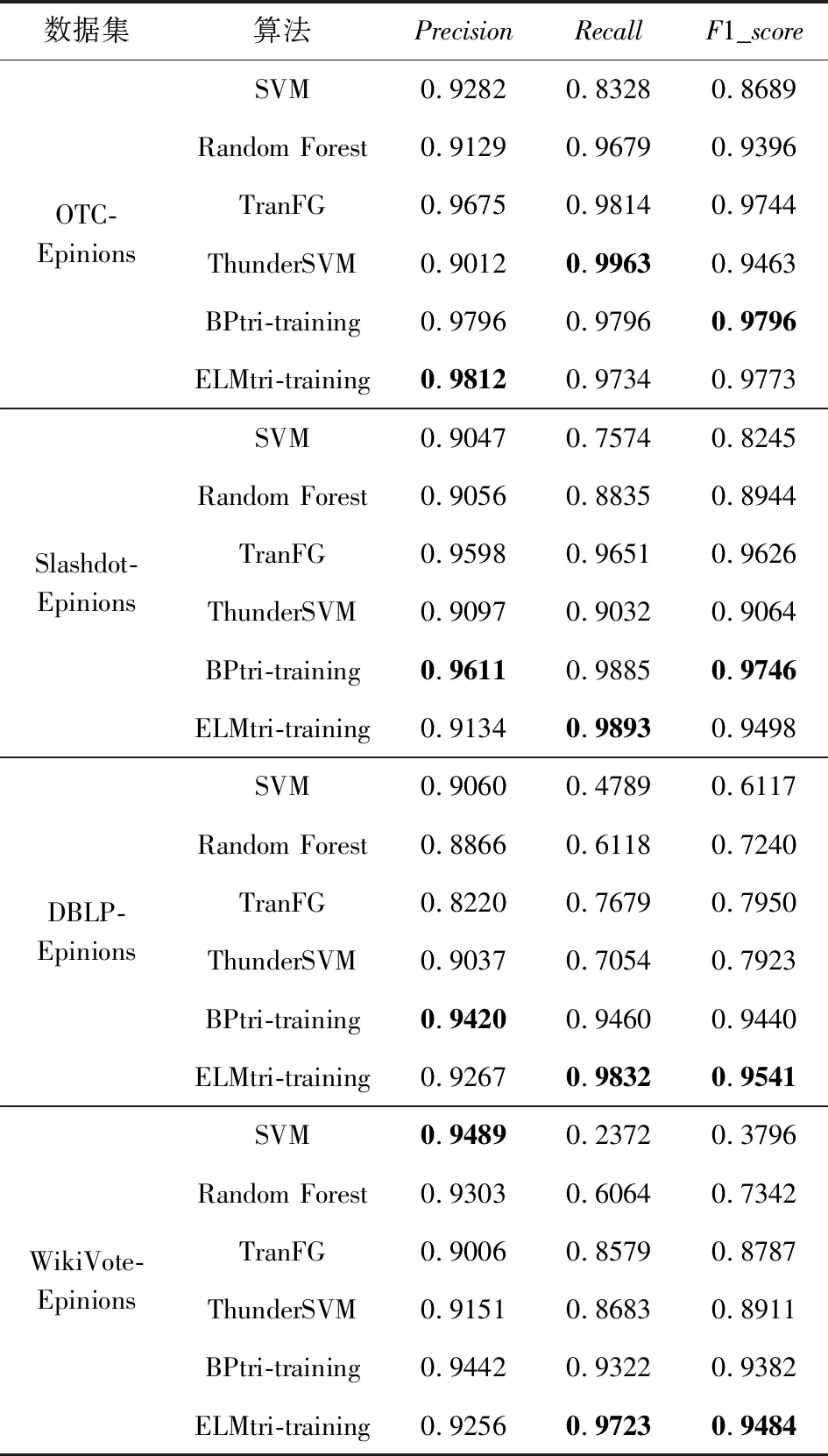
将所提的算法与SVM,Random Forest,TranFG,ThunderSVM,BPtri-training算法进行比较.实验与文献[1]中的实验结果进行对比,实验结果表示于表6~11,其中6个网络分别用作目标网络.
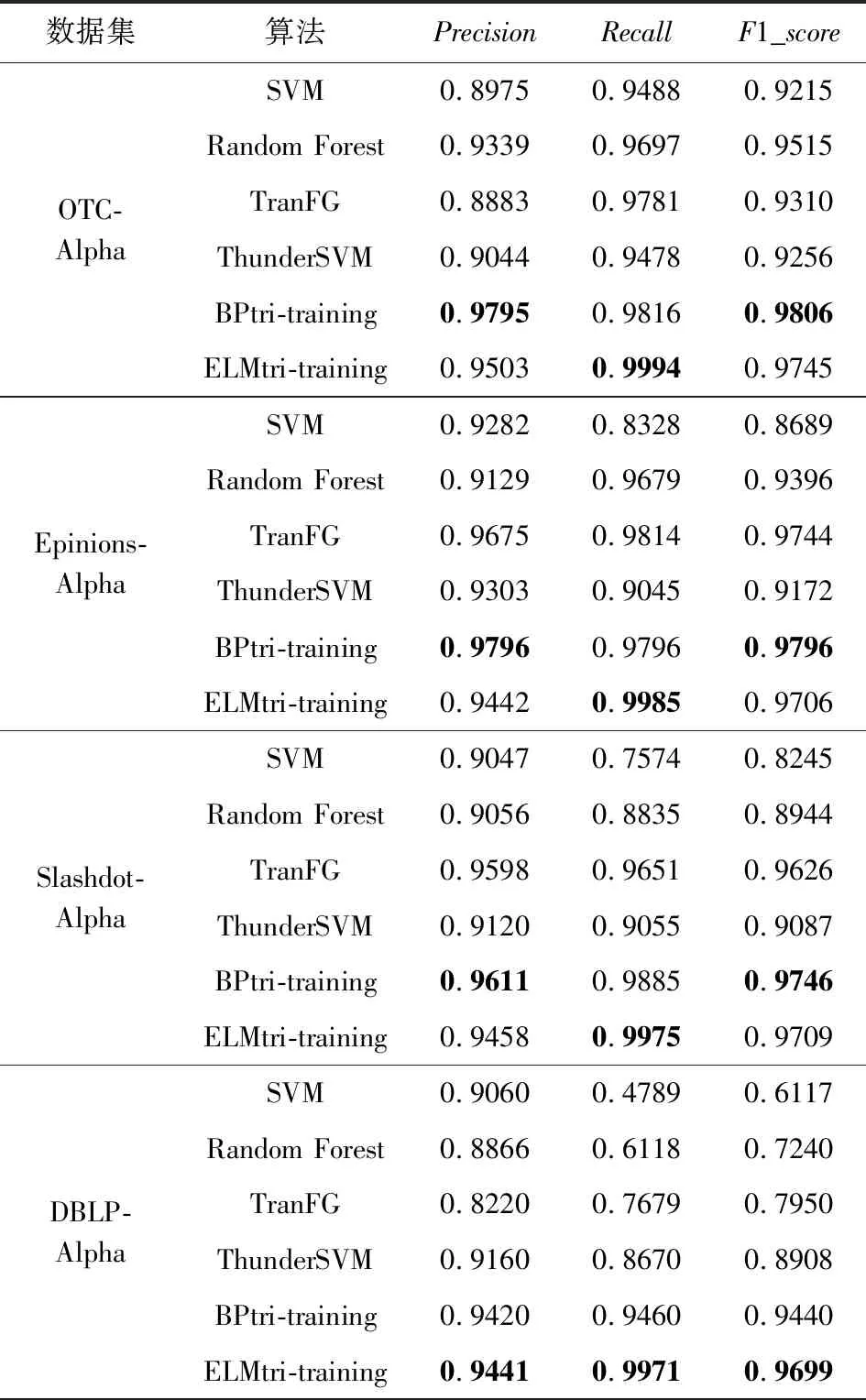
Table 6 Trust Relationship Prediction Results in TargetNetwork Alpha表6 Alpha作为目标网络的信任关系预测结果
续表6
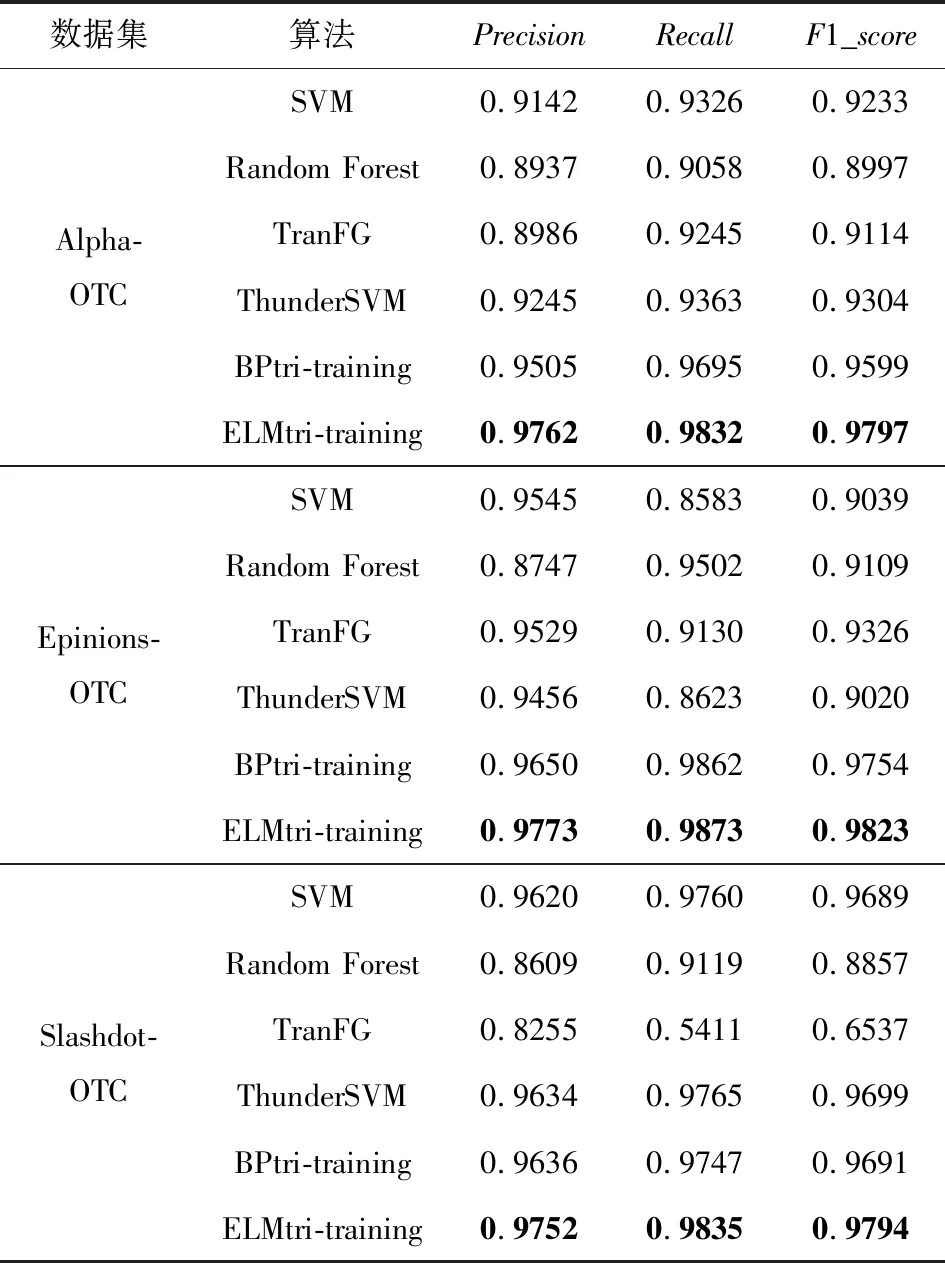
Table 7 Trust Relationship Prediction Results in TargetNetwork OTC表7 OTC作为目标网络的信任关系预测结果
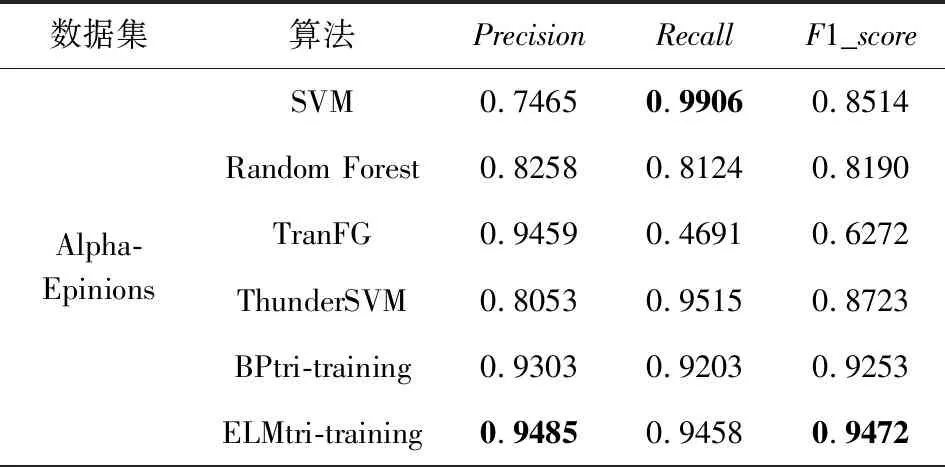
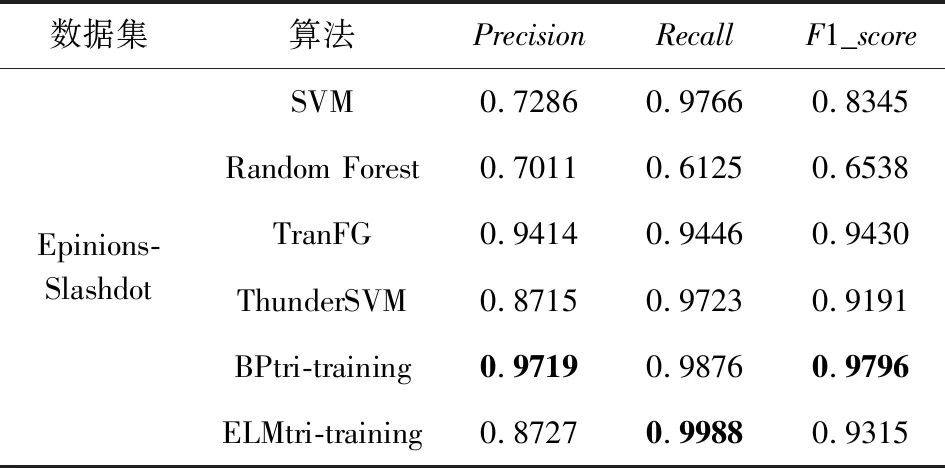
Table 8 Trust Relationship Prediction Results in TargetNetwork Epinions表8 Epinions作为目标网络的信任关系预测结果
续表8
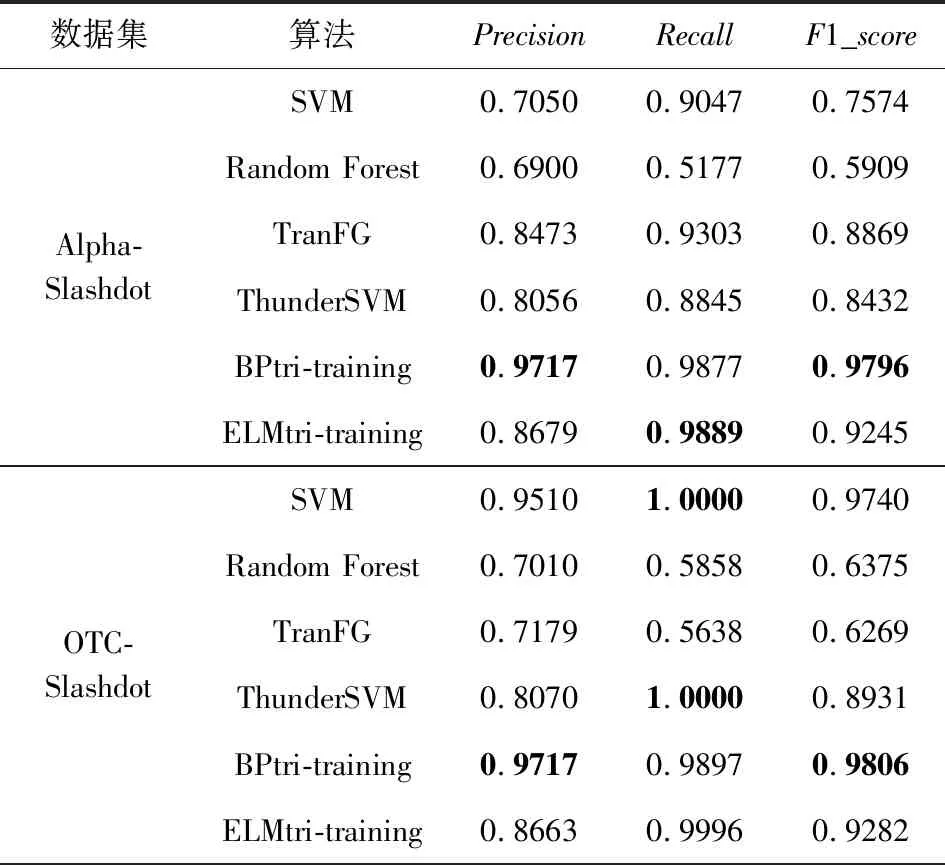
Table 9 Trust Relationship Prediction Results in TargetNetwork Slashdot表9 Slashdot作为目标网络的信任关系预测结果
续表9
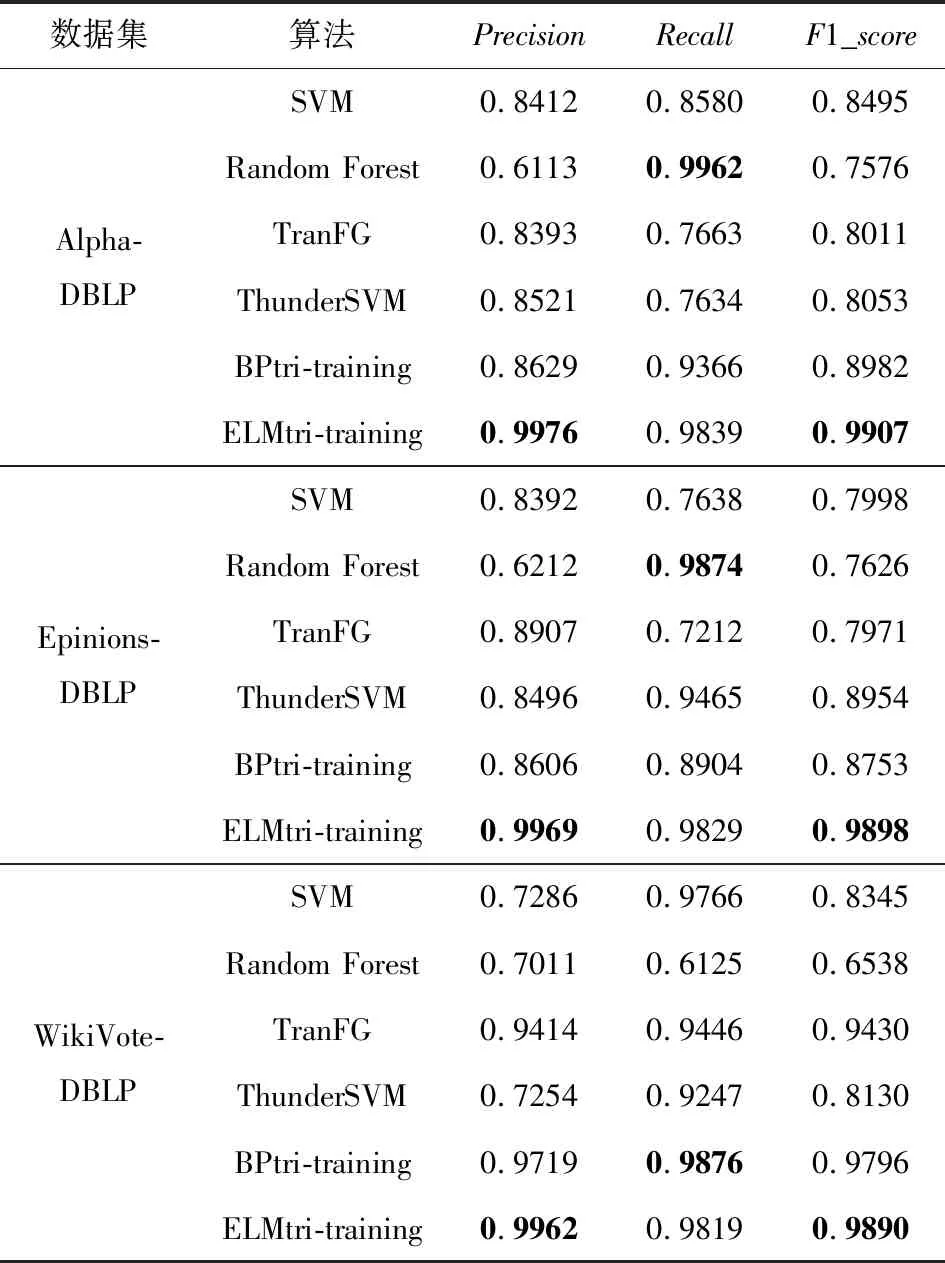
Table 10 Trust Relationship Prediction Results in TargetNetwork DBLP表10 DBLP作为目标网络的信任关系预测结果
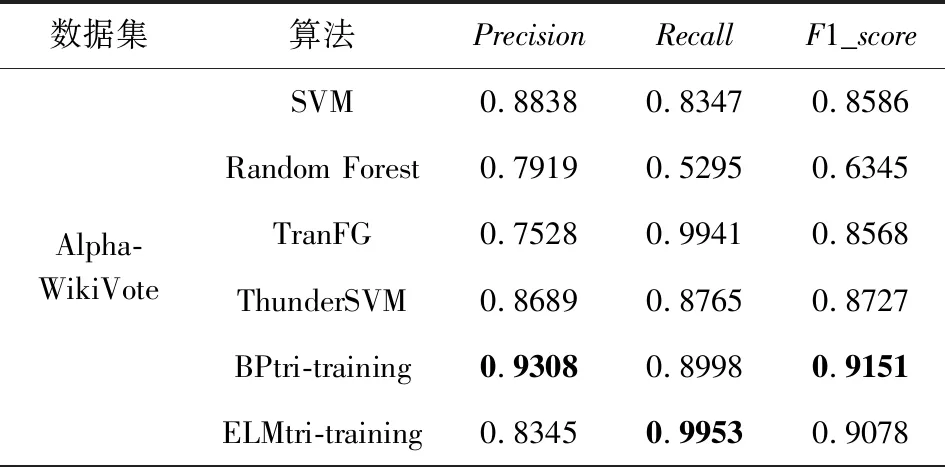
Table 11 Trust Relationship Prediction Results in TargetNetwork WikiVote表11 WikiVote作为目标网络的信任关系预测结果
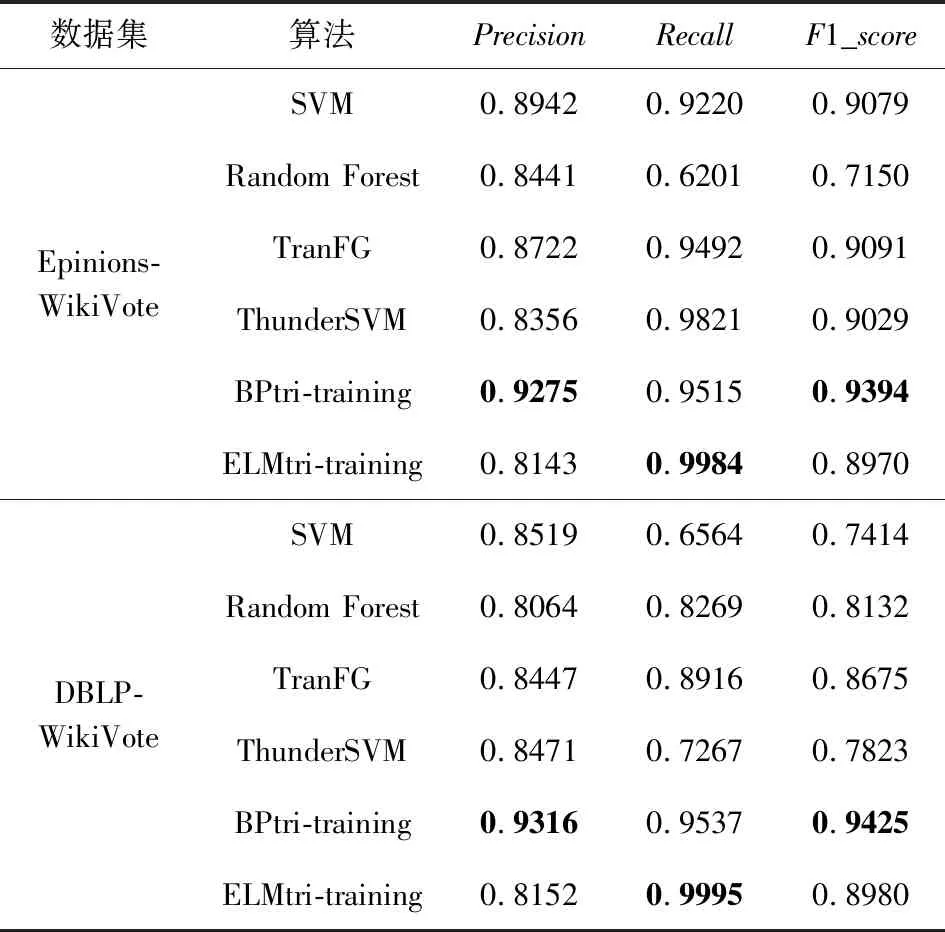
续表11
由表6~11中的结果,可发现ELMtri-training在Alpha,OTC,Epinions,DBLP数据集上大多数情况的表现比其他算法优秀,在Slashdot和WikiVote数据集上大部分Recall比其他算法高,Precision和F1_score比BPtri-training低,且在同一目标网络,不同源网络的情况下所提模型较为稳定.结果表明,无论源网络和目标网络是否为同一类型,ELMtri-training模型都具有稳定的性能.
根据表6~11的测试数据,分别计算6种算法在同一目标网络同一指标的方差,测试模型对于不同目标网络预测的稳定性.图6~8分别表示3个指标在6种算法以及不同目标网络的稳定性,其中横轴是目标网络,纵轴是方差.由图6~8可以看出,ELMtri-training模型的方差多数比其他算法低,且波动很小,稳定性优于其余5种算法.
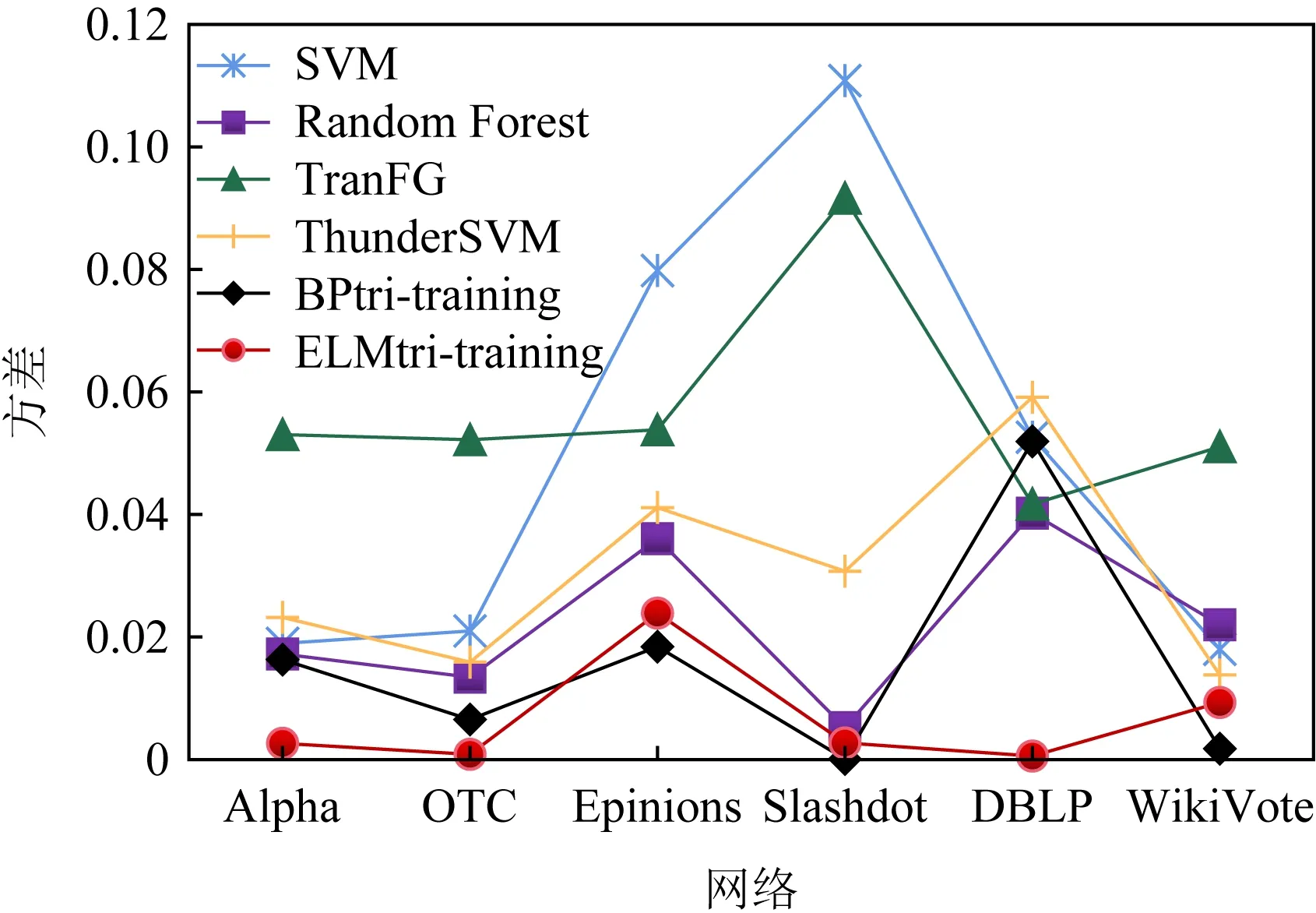
Fig. 6 Precision stability图6 精度稳定性

Fig. 7 Recall stability图7 召回率稳定性
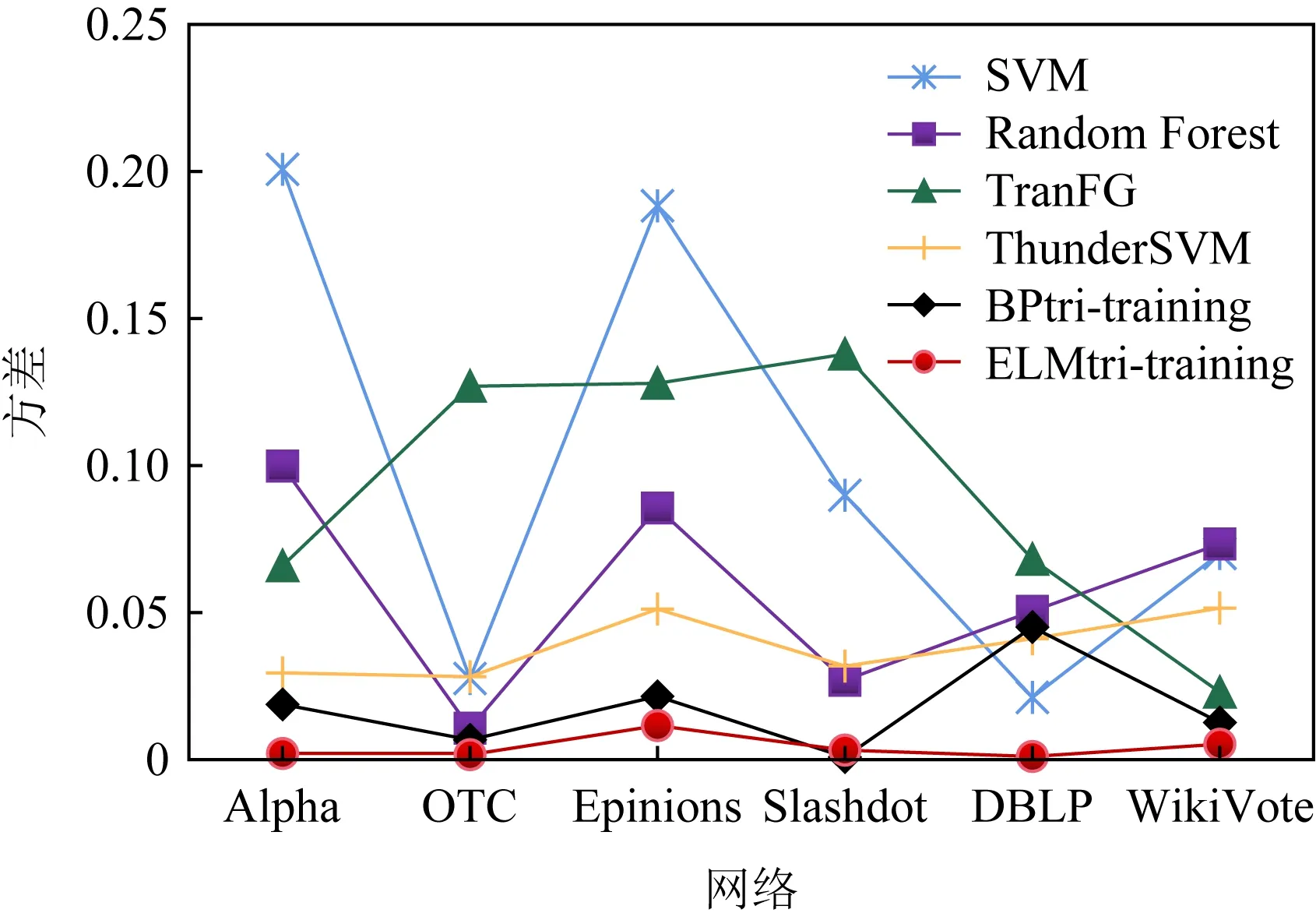
Fig. 8 F1_score stability图8 F1度量稳定性
5 总 结
本文基于非对称tri-training和tri-training模型构建ELMtri-training模型,模型外部框架为扩展非对称tri-training模型,模型包含4个ELM分类器,前3个用于tri-training模型.输入源网络样本到tri-training模型中训练产生分类器,然后输入目标网络训练样本产生伪标签,通过投票机制将伪标签样本加入目标网络伪标签训练集,输入加入特殊特征的伪标签样本训练第4个分类器,最后输入目标网络测试样本预测得到结果.利用类似迁移学习方法保存输出矩阵和训练的分类器.通过实验结果对比,所提出的算法在大多数情况下优于已有的预测算法,且对于不同的源网络和相同的目标网络,预测结果相对比较稳定,说明此模型的可扩展性以及稳定性比较好.模型可以考虑用于推荐系统,未来工作可以寻找网络间的共同特征和特殊特征方面的优化,使得预测结果更加准确.
作者贡献声明:王岩提出算法思路,负责完成实验并撰写论文;童向荣提出系统思路,调整论文框架,指导并修改论文.
