基于自适应融合网络的无人机目标跟踪算法
2022-09-05刘芳孙亚楠
刘芳,孙亚楠
北京工业大学 信息学部,北京 100124
近年来,无人机被广泛应用于军事侦察、物资派送、公安巡检和智能安防等领域。目标跟踪是无人机应用的关键技术之一,基于机器视觉的目标跟踪技术已成为一项重要的研究课题。由于无人机拍摄视角较高、飞行姿态不断发生变化,导致目标在视频图像中的占比较小并且容易发生形变、遮挡等复杂情况,影响跟踪算法的性能。一般来说,目标在图像中的面积占比小于1%则称之为小目标,小目标一直是影响跟踪质量的重难点之一,原因如下:① 小目标的像素点数较少,因而可利用的有效特征很少,大大增加了小目标跟踪定位的难度;② 小目标在图像中的比例较小,容易受到背景信息的干扰,导致难以提取到其关键特征信息。因此,如何有效提取小目标特征是实现高性能无人机目标跟踪算法的关键之一。
随着深度学习的快速发展,国内外众多研究学者将深度学习技术应用在计算机视觉领域。其中,深度卷积神经网络因具有强大的目标特征提取能力,能够高质量地完成目标检测和目标跟踪等任务而被广泛研究并使用。Wang和Yeung将深度卷积神经网络应用到目标跟踪领域,提出了DLT(Deep Learning Tracker)跟踪算法。Wang等通过分析深度网络模型不同特征层的输出特点,设计了新的网络模型提取目标特征。Hong等提出的CNN-SVM(Convolutional Neural Network-Support Vector Machine)跟踪算法,在CNN隐含层的顶端添加一个在线的支持向量机(SVM)来学习目标的外观特征。Bertinetto等提出了孪生网络结构思想并设计了一个完全卷积的Siamese网络来训练跟踪器。Valmadre等在SiamFC框架中引入相关滤波层进行在线跟踪。Li等受目标检测区域建议网络的启发,对深度网络输出的特征进行区域建议提取,提升了跟踪精度。秦莉等通过融合目标卷积特征和上下文信息的方向梯度直方图特征,优化目标跟踪性能。陈富健和谢维信提出了引入遮挡机制的SiamVGG目标跟踪算法,通过对网络输出置信图的峰值和连通域的变化分析,设置相应的跟踪策略以提升跟踪精度。李敏和吴莎提出一种基于预训练卷积神经网络,在粒子滤波框架下将深度特征和手工特征相结合的目标跟踪算法。Xu等认为先验信息(跟踪目标尺度、长宽比)会阻碍跟踪模型泛化能力,提出了一种不依赖先验知识的跟踪框架SiameseFC++。
上述基于深度学习的目标跟踪算法,整体上提升了目标跟踪性能,但对小目标的跟踪效果不够理想。要提高深度网络对小目标的处理能力,首先要提高深度网络的特征表达能力。在卷积神经网络中,特征图感受野是一个至关重要的概念,Luo等研究了CNN的感受野尺度问题,提出了有效感受野的概念,表明特征图感受野会直接影响到整个网络模型的辨别能力和鲁棒性。Szegedy等通过设计具有不同大小卷积核的多分支卷积神经网络结构,克服了特征感受野尺度问题对模型性能的影响。文献[15]根据物体的尺度和形状自适应地调整感受野的空间分布。Liu和Huang通过模拟人类视觉感受野提出了一种RFB(Receptive Field Block)感受野增强结构,有效提高了网络模型的表达能力。
综上所述,提出了一种基于自适应融合网络的无人机目标跟踪算法。首先,针对小目标在视频序列中特征难以提取且易受复杂背景干扰等问题,结合RFB的感受野增强特性和残差网络(Residual Network,ResNet)结构的梯度优化特点,构建了感受野增强残差网络模型 (Receptive Field-Residual Network,RF-ResNet),该模型在残差网络结构中引入RFB模块,能够增强特征图的有效感受野区域,提高目标特征的表达能力;其次,提出了一种多尺度自适应融合网络,将RF-ResNet提取的浅层特征和深层特征输入到RFB模块,然后由深层特征至浅层特征逐层进行维度连接操作获得3个尺度的目标特征,并将其输入到自适应加权融合模块中,从而获得包含深层语义信息和浅层细节信息的融合特征;最后,将融合特征输入到相关滤波系统中计算出响应图的最大置信分数,确定跟踪目标位置。本文算法在UAV123数据集上进行了仿真实验,结果表明,该算法在跟踪成功率和精确率方面都达到了较高水平,能够有效提升无人机小目标跟踪算法性能。
1 目标跟踪算法
针对无人机视频目标跟踪过程中,目标所占比例较小且易受复杂背景信息干扰等问题,提出一种基于自适应融合网络的无人机目标跟踪算法,该算法主要由目标特征提取和目标定位2部分组成。特征提取网络结构如图1所示,该网络模型主要包含4个卷积模块和1个自适应加权融合模块,其中Conv1、Conv2和Conv3卷积模块均含有1个3×3卷积层和2个残差模块,Conv4卷积模块含有1个3×3卷积层和1个RFB模块,C2~C4、F1~F2表示特征图。利用RF-ResNet模型提取目标多尺度特征并进行自适应加权融合,获得表达能力更强的目标特征。在目标定位部分,利用初始帧目标样本特征构建滤波系统,然后将后续帧中的目标特征输入到相关滤波系统中,计算出响应图的最大置信分数,从而确定跟踪目标位置。
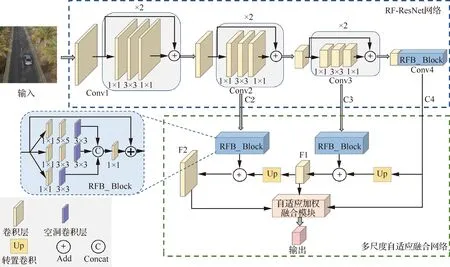
图1 特征提取网络结构图Fig.1 Structure of feature extraction network
1.1 RF-ResNet网络模型
感受野是卷积神经网络每一层特征图上的像素点映射在输入图片中的区域大小。在整个特征图中起主要作用的是有效感受野区域,有效感受野只占理论感受野中心区域的一部分,且呈现高斯分布特点,即中心像素的响应值最大,离中心越远像素的响应值强度越弱。因此,增强有效感受野区域将会大大提升特征的表达能力。基于此,RFB对特征感受野区域特点进行分析,利用多分支卷积层和空洞卷积增强特征图的有效感受野,提高网络的特征表达能力,结构如图2所示。
1) 多分支卷积层。采用不同大小卷积核构成的多层网络,其特征提取能力要优于使用相同卷积核的网络结构。因此,RFB网络设计了一种含有3个分支的网络结构,如图2所示,每个分支分别采用 1×1标准卷积、扩张系数rate为1的3×3空洞卷积,1×1标准卷积、3×3标准卷积、扩张系数为3的5×5空洞卷积和1×1标准卷积、5×5标准卷积、扩张系数为5的3×3空洞卷积。此外,RFB网络还采用了ResNet中的直连(shortcut) 结构,使得梯度能够很好地传递到浅层,减轻深层网络的训练负担。

图2 RFB网络结构Fig.2 Structure of RFB network
2) 空洞卷积(Dilated Convolution)。空洞卷积在标准卷积层中加入了一个新的参数—扩张率(Dilation Rate),该参数决定了卷积核在处理数据时各像素之间的距离,能够将卷积核扩张到规定的尺度,并将原卷积核中未被占用的像素区域填充为0,因而能够在不增加额外运算量的同时,增大特征图的感受野。如图2所示,在每一个分支的1×1标准卷积之后都添加一个不同扩张率的空洞卷积层。
一般情况下,卷积神经网络层数越深,获取的语义特征越丰富,表达能力越强。但是单纯的网络层数堆叠有时并不能提高网络的识别能力,往往会大幅增加网络模型的复杂度和计算量,甚至导致训练难度增大、网络梯度难以优化,出现梯度消失或爆炸等问题。He等深入地研究了网络模型难以优化的问题,总结出初始化网络参数和正则化输出特征这一训练深度网络模型的关键方法,并针对梯度消失或爆炸导致的网络模型退化问题,提出了ResNet 残差网络结构,通过shortcut连接方式有效的减少了网络梯度传播时经过的层数,使得损失值发生爆炸和消失的问题得到缓解,加快网络模型训练速度,提升网络模型表达能力。因此,结合RFB的感受野增强特性和ResNet的梯度优化特点,构建了RF-ResNet网络用于提取跟踪目标的图像特征,该网络模型结构参数如表1所示,其中Kernel表示卷积核尺寸,Size表示输出特征尺寸,Channels表示输出特征的维度。

表1 RF-ResNet网络参数Table 1 RF-ResNet network parameters
1.2 多尺度自适应融合
卷积操作利用卷积核与输入图像进行卷积运算获得目标特征图,如图3(a)所示,一个4×4的输入特征,用3×3的卷积核做填充维度(padding)为0,步长(strides)为1的卷积操作,最终得到2×2的特征图。转置卷积(Transposed Convolution)也称作反卷积(Deconvolution),是一种常见的上采样方法,可以简单理解为标准卷积的反向运算,如图3(b)所示,以2×2的特征图作为输入,用3×3的卷积核做padding为2,strides为1的转置卷积操作,得到4×4的特征图。卷积神经网络提取的深层特征图含有丰富的语义信息,但缺少浅层网络中的细节特征,因此,通过转置卷积运算可以将低维局部特征映射成高维向量,获得大尺寸的特征图,以便与浅层网络输出的特征图进行融合,增强目标的特征表达能力。
卷积运算是将卷积核以滑动窗口的方式在输入特征的对应元素上依次相乘,然后将所有相乘结果求和得到最终的输出结果。若以矩阵乘法表述卷积运算,、和分别代表输入矩阵、输出矩阵和卷积核,则卷积运算可表示为
=*
(1)
根据转置卷积原理,其表达式为
=*
(2)
式中:T表示转置运算。通过对输入矩阵进行转置卷积运算,得到预期的原始特征矩阵。
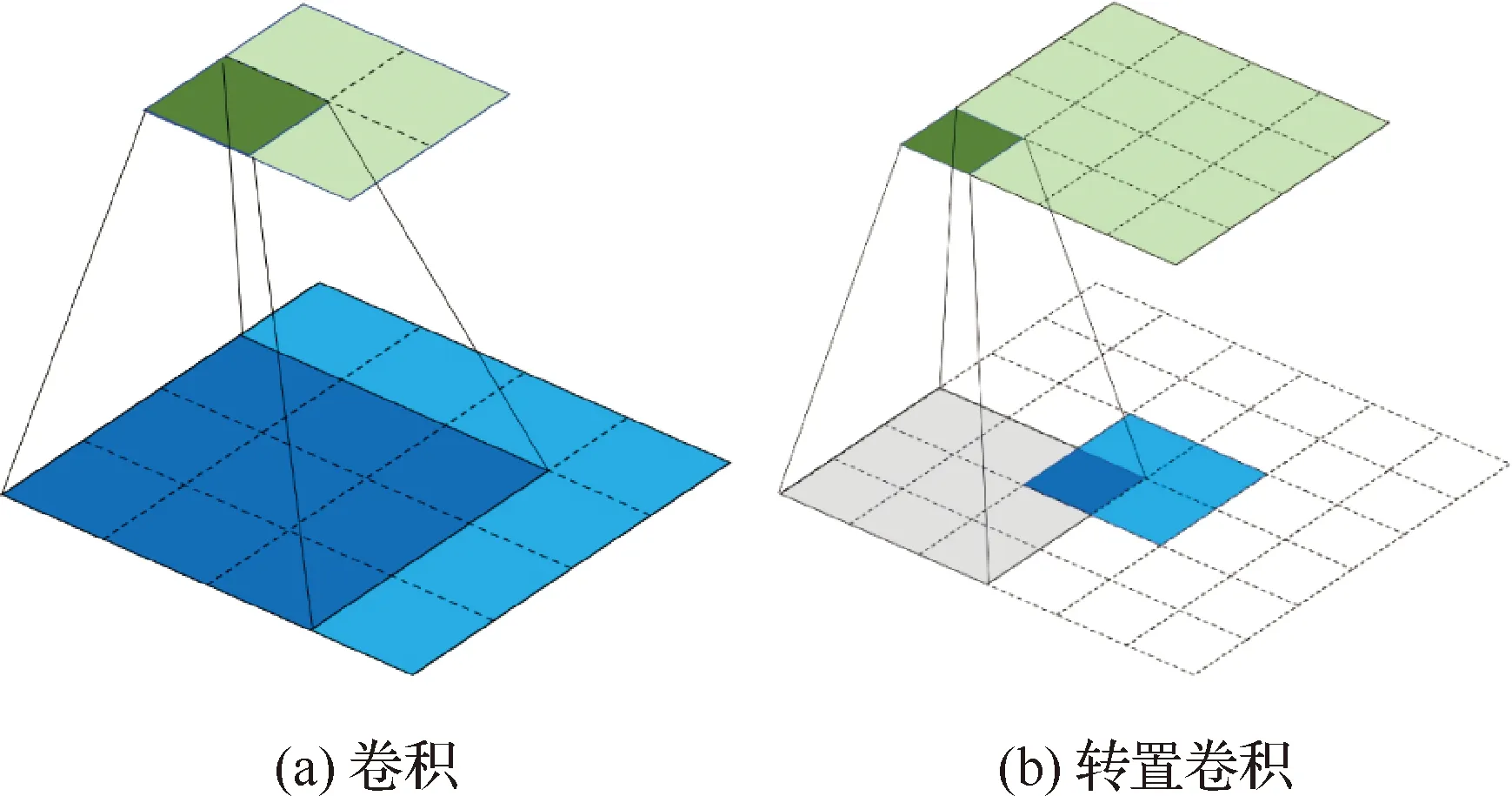
图3 卷积与转置卷积示意图Fig.3 Diagrams of convolution and transposed convolution
特征提取网络不同卷积层的特征图所包含的特征信息不同,浅层特征图主要包含图像的细节特征,如纹理、边缘信息等,并且其感受野尺度较小,适用于小目标的跟踪定位;深层特征图包含丰富的语义信息,对目标属性的判别能力较强,但其感受野尺度较大,局部像素之间的关联性较弱,更适合定位较大尺度的目标。因此,设计了如图1所示的多尺度自适应融合网络,将深层特征与浅层特征相融合得到同时包含细节信息和语义信息的目标特征,大大提高了目标定位精度。具体而言,首先将Conv4层输出的特征图C4进行转置卷积运算,使其与前一层特征图C3的空间尺寸一致;然后将特征图C3输入到RFB模块增强其感受野,并按照通道维度与特征图C4转置卷积后的结果进行矩阵求和操作,得到融合特征图F1;同理,得到与特征图C2相同尺度的融合特征图F2;最后,考虑到C4、F1和F2这3种特征图的感受野尺度大小及所包含特征信息的差异性,设计了自适应加权融合模块,可得到表达能力较强的目标特征。
图4为自适应加权融合模块,首先利用SE(Squeeze-and-Excitation)通道注意力机制,让网络模型自适应地学习特征图中每个通道的重要性,并通过提高重要通道的权重,增强有效特征,抑制无效特征,提升每个特征图的表达能力。具体来讲,通过全局平均池化层(Global Pooling)将特征图的每个二维通道变成一个实数,该实数表示对应特征通道响应的全局分布,然后经过2个1×1卷积层建立通道间的相关性,并由Sigmoid激活层获得每个特征通道的归一化权重,最后的Scale操作将归一化后的权重加权到特征的每个通道上,实现重要通道的提升;最后,将3个特征图调整为相同尺度并分别设置权重系数,让网络学习每个特征图对跟踪任务的贡献程度,通过自适应地调节权重系数将3个特征进行加权融合,从而最大化利用每个特征图的关键信息。融合公式为
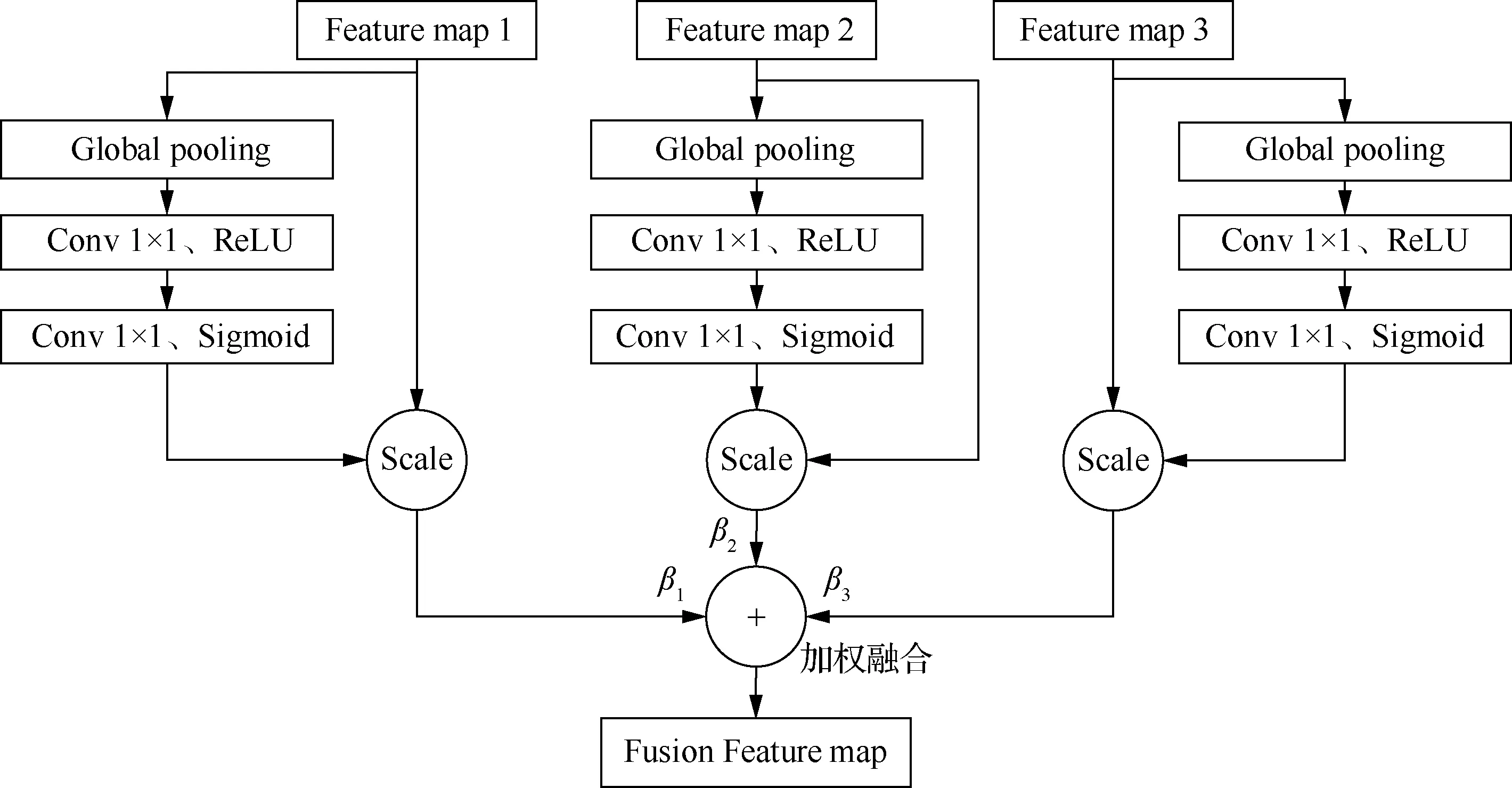
图4 自适应加权融合模块Fig.4 Adaptive weighted fusion module
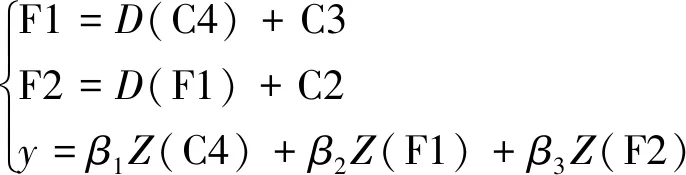
(3)
式中:( )为转置卷积函数;( )表示特征通道增强操作;、和分别为各特征图的权重系数,且++=1。
1.3 基于相关滤波的目标跟踪
近年来,众多研究学者联合利用CNN和相关滤波算法完成目标跟踪任务,取得了非常优异的跟踪效果。本文以改进的判别相关滤波为基准,构建相关滤波系统,对提取的目标图像特征进行分析,确定跟踪目标位置。
将RF-ResNet网络提取的目标图像特征记为={,,…,},其含有个维度。首先,将特征通过插值处理映射到连续空间域,公式如下所示:
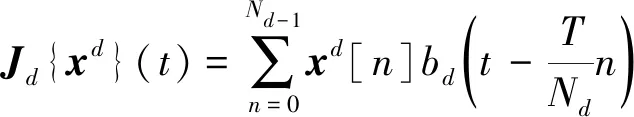
(4)
式中:()()表示特征转换到连续空间域的特征;表示特征图第个通道的空间特征个数;[]被视为一个离散空间变量;表示离散空间的间隔,∈[0,);表示插值函数。
利用连续空间域的特征,通过计算获得滤波器模型预测结果,计算方式为
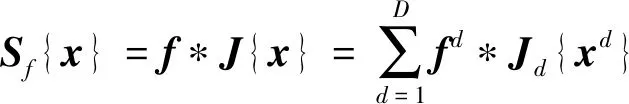
(5)
式中:={,,…,},表示第个维度特征的滤波器;表示特征维度数量,*表示卷积运算。
学习相关滤波器的损失函数为

(6)
式中:表示样本数量;将样本对应的期望结果设为周期性重复的高斯函数,|| ||表示L2范数,损失误差由L2范数计算得到,表示样本的权重,同时引入一个正则化惩罚参数来缓解周期性假设的缺陷。
然而,并非所有维度的特征都对跟踪结果起到贡献作用。如果特征图有个维度就设置个滤波器,那么一部分滤波器的贡献度可能很小,不仅严重影响运算速度,还会使跟踪性能受到冗余信息的干扰。因此,只选择贡献度较高的个滤波器进行线性组合,进行滤波器模型预测即可,计算公式如下所示:
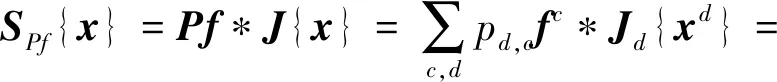
*{}
(7)
式中:是一个×维度的矩阵,相当于线性降维算子,,表示对进行滤波的学习系数,则相应的损失函数为

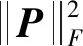
(8)
1.4 跟踪算法流程
本文算法流程如图5所示,主要步骤如下:
构建特征提取网络:结合RFB和ResNet结构特点,以及无人机视频图像的特点,构建RF-ResNet网络模型提取目标特征。
构建多尺度特征自适应融合网络:将提取的Conv2、Conv3和Conv4层特征进行自适应融合,得到融合目标特征图,并利用指定数据集训练目标跟踪算法。
目标定位:将融合的目标特征输入到相关滤波器,计算响应图并将其峰值作为当前帧跟踪目标的位置。
模板更新:每隔5帧对跟踪目标模板进行更新,以适应跟踪目标的各种变化。

图5 算法流程图Fig.5 Flowchart of algorithm
2 仿真实验
2.1 实验数据
本文使用COCO2017数据集作为训练集,在Inter corei7 8th CPU,NVIDIA GEFORCE GTX 1080Ti GPU的计算机平台上训练目标跟踪算法。
COCO2017数据集拍摄场景丰富,目标种类多,被广泛应用于目标检测及目标跟踪训练任务中。本文对COCO2017数据集进行裁剪处理,制作出40 000多个跟踪目标序列,包含多类拍摄场景,并且标注目标尺度分布范围大,有利于训练出鲁棒性更强的网络模型。
UAV123数据集由无人机飞行拍摄的视频组成,共包含123个子视频序列,图像帧数超过110k帧,拍摄的目标包括行人、汽车、轮船、自行车等多类物体,由于拍摄的视点较高,大多数跟踪目标属于小目标,并且无人机飞行姿态不断变化,拍摄角度也存在较大差异,从而导致目标姿态、形状及尺度频繁发生变化,因此UAV123数据集有很大的挑战难度。
为直观地验证本文算法对小目标跟踪的有效性,从UAV123数据集和VisDrone2018数据集中选取了4个典型小目标视频序列进行仿真实验,这些小目标视频也存在其他挑战,详细信息如表2所示。

表2 4个小目标视频序列Table 2 Video sequence of 4 small targets
2.2 实验结果与分析
2.2.1 多尺度特征融合对比实验
为验证多尺度特征自适应融合方法的有效性,在UAV123数据集上做了以下对比实验。第1组利用Conv2,Conv3 和Conv4进行自适应特征融合后的目标特征进行跟踪;第2组是利用传统的维度连接融合方法,将Conv2,Conv3 和Conv4进行多尺度融合后的特征完成目标跟踪任务;第3组则直接利用RF-ResNet网络输出的特征进行目标跟踪。采用跟踪成功率和跟踪精确率对跟踪性能进行评价,实验结果如图6所示,本文提出的自适应融合方法的跟踪精确率达到了0.702,分别比维度连接融合方法和无融合特征进行目标跟踪的精确率提高了1.3%和4.5%;跟踪成功率达到了0.475,分别比其他2种方法提高了5.4%和9.3%。实验证明本文提出的多尺度特征自适应融合方法能够高效地融合深层网络语义特征和浅层网络的细节特征,大大地提高融合效率,增强特征的表达能力,有效提升目标跟踪性能。
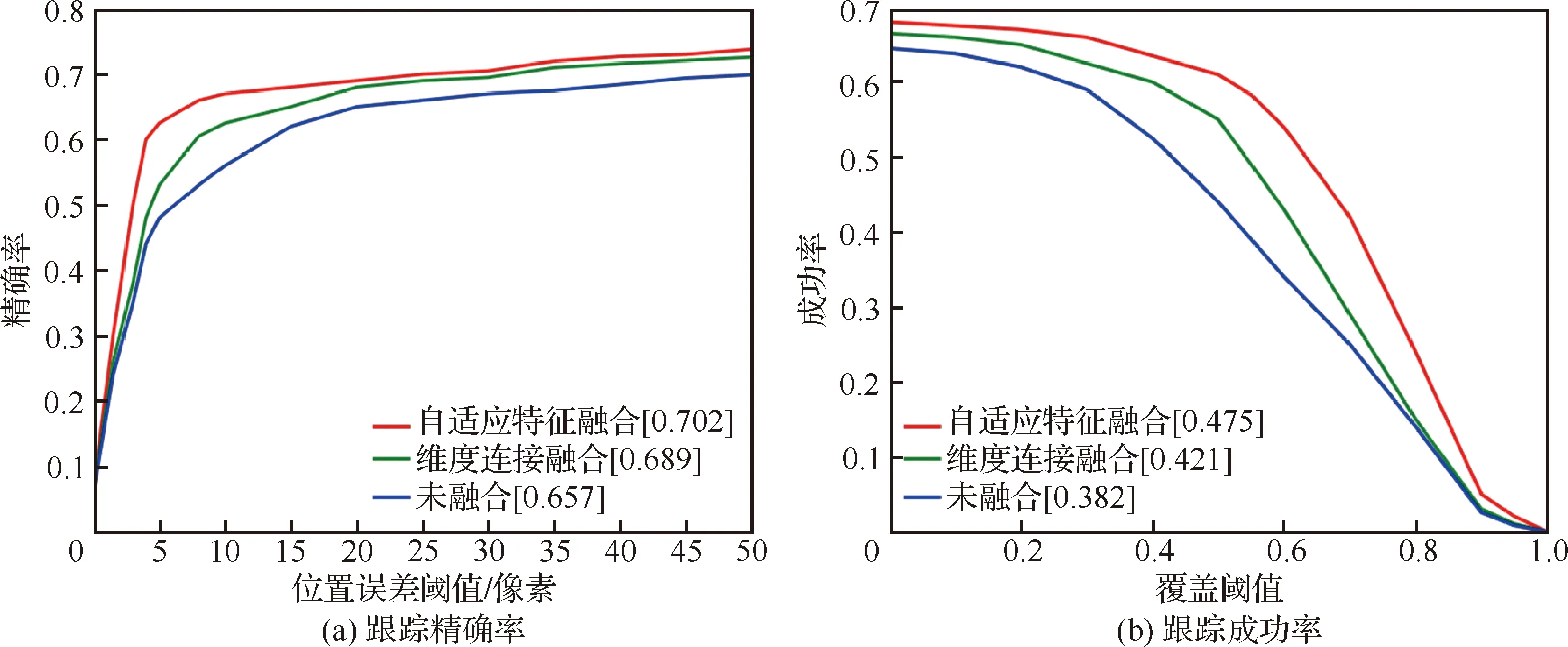
图6 特征融合跟踪性能Fig.6 Feature fusion tracking performance
2.2.2 跟踪算法性能分析
为了直观验证本文算法的有效性,将其与SiamRPN、ECO、SiamCAR、SiamBAN和DaSiamRPN这5种跟踪算法在表2所示的无人机跟踪视频序列上进行仿真实验,结果如图7 所示。

图7 视频仿真结果图Fig.7 Partial results of video simulation
1) Car2序列。无人机在高空拍摄行驶的汽车,并跟随汽车飞行,因而目标在序列中呈现小目标和视角变化的特点。在前118帧序列中,小车在缓慢的拐弯,4种算法都能比较准确地跟踪上目标;在第200帧,小车拐过弯道开始加速行驶,同时无人机为了能够捕捉到小车,也开始调整飞行速度,此时ECO算法定位框发生了较大误差,在第373帧,DaSiamRPN算法跟踪框已漂移到其他物体,而本文算法能够保持稳定精准的跟踪状态。
2) Group1序列。3个相似的人员并排行走,同时无人机在不断改变拍摄角度,造成了小目标和相似性目标影响的复杂情况。由于目标尺度小,而且其周围又有极其相似的物体,很考验跟踪算法对目标特征的辨别能力。在第721帧,相似目标和跟踪目标接近时,ECO、SiamCAR和DaSiamRPN跟踪结果开始发生偏移;在第863帧,SiamCAR、SiamRPN和DaSiamRPN算法错误地跟踪上相似目标;SiamBAN算法跟踪比较稳定,并且本文算法通过融合深层网络的语义信息,对小目标的辨别能力更强,因而能够一直稳定的跟踪目标。
3) Wakeboard6-1序列。无人机高空飞行拍摄海面上的冲浪者,由于无人机不断调整飞行轨迹和姿态,因而跟踪目标宽高比频繁发生变化,为跟踪带来了很大难度。在前438帧,4种算法都能成功地跟踪上目标;而在484帧,无人机调整了相机视角,跟踪目标的位置及尺度都发生了较大变化,SiamCAR、SiamRPN和DaSiamRPN算法发生严重的跟踪漂移,丢失跟踪目标;在后续帧中,如582帧,SiamCAR和SiamRPN算法始终无法定位到目标,而ECO和DaSiamRPN算法虽能成功跟踪,但是跟踪框的尺度误差较大;可以看出,SiamBAN和本文算法对小目标的跟踪性能更稳定。
4) Car序列。自行拍摄的拥挤街道场景中行驶的汽车,不仅汽车目标尺度小,还有复杂的背景以及相似的目标影响,具有很大的跟踪难度。从跟踪效果上可以看到在前100帧视频序列中,4种算法都能成功地跟踪上目标,但是随着目标移动,复杂背景以及相似目标向跟踪目标靠近,SiamCAR、SiamRPN、DaSiamRPN和ECO算法的跟踪结果发生漂移,SiamBAN算法跟踪效果比较稳定,同时,本文算法能够有效提取目标特征并且有效适应复杂背景及相似目标的影响,跟踪效果较为理想。
为了进一步定量分析本文算法在上述4个视频序列的跟踪性能,采用位置误差阈值为20个像素时的跟踪精确率和交并比覆盖阈值为0.5时的跟踪成功率,实验结果如表3所示,相比其他5个算法,本文算法在跟踪精确率和成功率方面均达到了较高水平,分别为0.752和0.536。

表3 算法跟踪性能Table 3 Algorithm tracking performance
为了进一步客观地评估本文算法的跟踪性能,将其与CCOT、ECO-HC、ECO、SiamBAN、DaSiamRPN、SiamRPN、UPDT、SRDCF、MEEM、MUSTER和SAMF共11个跟踪算法在整个UAV123数据集以及UAV123数据集中46个具有代表性的小目标视频序列上进行对比实验,结果如图8、图9所示。在46个代表性小目标视频序列中,本文算法取得了较高的跟踪性能,跟踪成功率达到0.475,跟踪精确率达到0.702,充分证明了本文算法较其他算法对小目标跟踪的有效性。在UAV123数据集上,本文算法的跟踪成功率为0.613,跟踪精确率为0.805,验证了本文算法在跟踪准确性和稳定性方面具有优异的整体性能。本文算法在所有对比算法中,跟踪指标仅略低于SiamBAN算法,该算法得益于anchor free策略,避免了繁琐的超参数调节,使得算法能够在6大数据集上进行高效训练,优化了跟踪性能。下一步工作也将从网络整体训练优化方面进行改进。
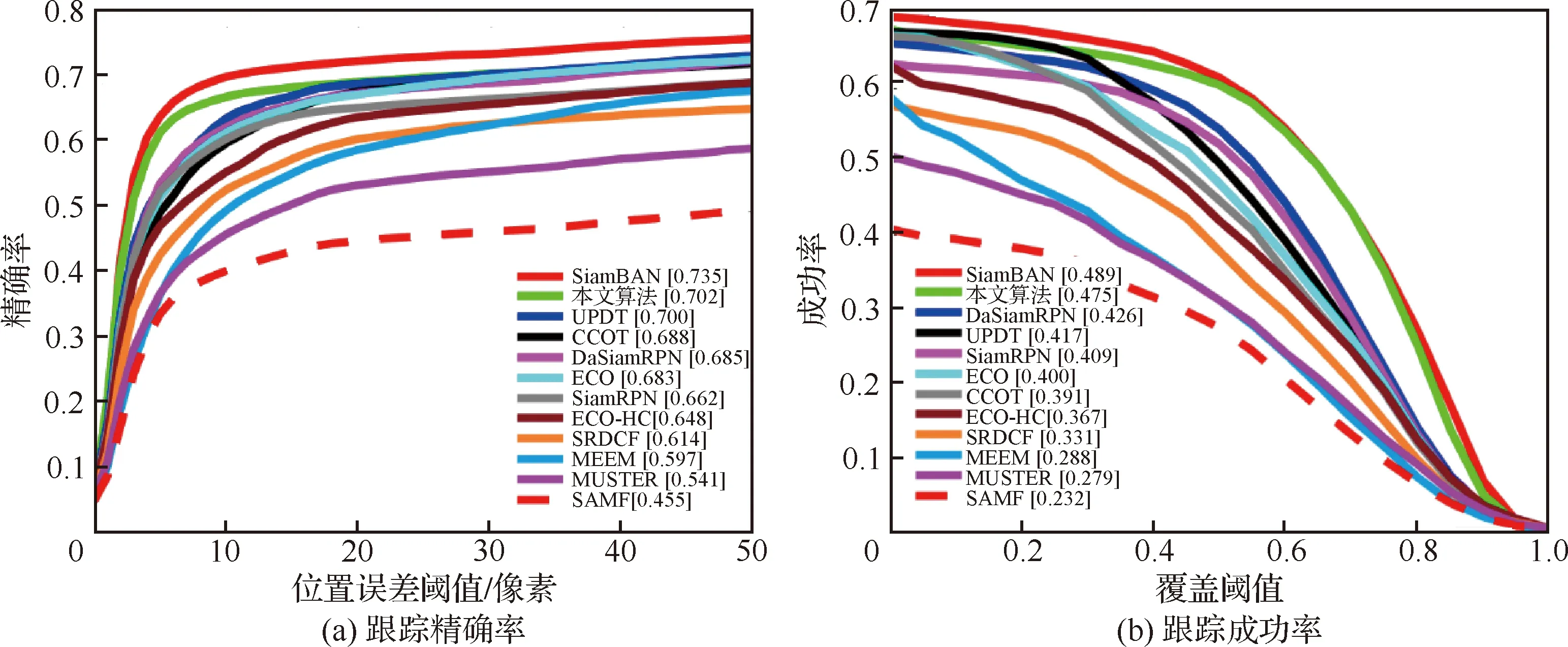
图8 UAV123数据集中46个代表性小目标视频序列跟踪性能Fig.8 Video sequence tracking performance of 46 representative small targets in UAV123 dataset
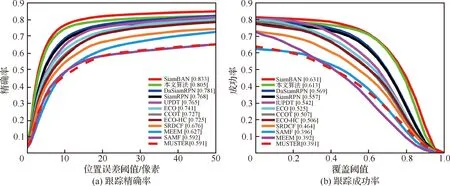
图9 UAV123数据集整体跟踪性能Fig.9 Overall tracking performance of the UAV123 dataset
3 结 论
本文提出了一种基于自适应融合网络的无人机目标跟踪算法,主要贡献如下:
1) 结合RFB的感受野增强特性和残差网络结构的梯度优化特点,构建了感受野增强残差网络模型RF-ResNet,能够有效提取目标特征并增强特征的有效感受野。
2) 提出了一种多尺度自适应融合网络,通过将RF-ResNet提取的浅层和深层特征输入到RFB模块和自适应加权融合模块,获得了含有深层语义信息和浅层细节信息的融合特征,提高了目标特征的表达能力,降低了小目标在视频序列中易受复杂背景的影响及其特征难以提取等问题。
