一种基于定位和非对称补偿的伪装目标分割方法
2022-09-03徐义飞李晓冬李新德
徐义飞, 李晓冬, 李新德
(1. 东南大学自动化学院, 江苏 南京 210096; 2. 信息系统工程重点实验室, 江苏 南京 210000;3. 南京数学应用中心, 江苏 南京 211135)
0 引 言
伪装是生物或者物体通过改变外表颜色、光照或者材料与纹理等手段隐藏本体,将自身“完美”嵌入周围环境中。隐蔽方式的成功主要得益于生物对知觉选择性的认知误导,即欺骗观察者的感知系统,使其错将前景误认为是背景的一部分。如图1所示,伪装目标的特征表现在前景与背景的高度相似性,相较于显著目标而言更难分辨。通过对伪装目标数据集、显著目标数据集分别进行前景、背景的信息熵处理发现:伪装数据集相比显著目标数据集而言,前景信息与背景信息的贴近程度更高。因此,伪装物体检测通常需要投入大量的视觉感知进行信息提取与聚焦,远比传统的显著目标检测或通用目标检测更具挑战性。

图1 伪装目标示例Fig.1 Examples of camouflaged object
伪装目标分割(camouflaged object segmentation, COS)作为检测的一种像素级表现形式,其研究除具备学术价值外,更具备广阔应用前景:军事上,可在一定程度上提高军事反侦察能力;工业上,有利于安全监视和救援(如矿工搜寻);农业上,有助于推动病虫害预警与防治(如蝗虫入侵监控);医学上,可促进医疗影像的病灶定位与诊断(如息肉分割)。
然而,COS目前仍是一项极具挑战的检测任务。早期的伪装物体分割主要利用手工提取图像颜色对比度、纹理边缘差异等低级特征的方式来区分前景与背景。这类方法可较好分割简单图像中的伪装物体,但考虑到伪装策略会将目标较好地嵌入周围环境中,直接利用低级特征界定伪装物体,方法的泛化能力非常有限。近些年,随着深度学习模型在计算机视觉领域取得了显著的成功,基于深度学习的伪装物体分割逐渐受到了研究人员的关注。Le等人提出集成分类信息的像素级分割网络结构。Fan等人提出基于搜索与识别网络,同时COD10K数据集的公开很大程度上推动了伪装目标分割的发展。Lv等人基于排序的伪装物体检测网络同时对伪装目标进行定位、分割和排序。尽管这些探索取得了不错的效果,但高度相似的前景与背景所产生的歧义区域处理仍会导致不可靠的分割结果,如何提升高相似性区域的分割准确率仍是需要解决的问题。
在自然界中,生物利用伪装策略保护自身在环境中不被捕食者发现。然而,猎物和捕食者的自然博弈过程也促使了捕食策略的进化,形成一套行之有效的伪装猎物捕捉机制:搜索→聚焦→捕获。受捕食前两阶段的启发,本文提出一种定位和补偿网络(locating and compensation network, LCNet)用于目标分割,具备了对高相似伪装物体的准确分割能力。LCNet主要包含两个关键模块:定位模块(locating module, LM)和非对称补偿模块(asymmetric compensation module, ACM)。LM主要用于模拟捕食搜索确立的过程,对文献[21]提出的双注意力并联结构进行改进,通过级联通道和空间注意力的双注意力方式减少信息冗余,并对目标进行初步定位。然后,ACM对定位的结果进行补偿,对强化后的前景/背景,结合对立的掩膜和高斯函数对背景/前景施加注意力加权得到像素歧义区,在特征提取后去除假阴性/假阳性(即前景/背景)区域的干扰。最后,通过构建多层级特征的ACM结构,实现对歧义区域归属的逐步细化,得到精确的伪装目标分割结果。本文的主要贡献如下:
(1) 提出一种新颖的伪装目标分割方法LCNet。该方法首先通过复合主干网提取复杂特征,并通过级联的双注意力模块对目标进行搜索定位,最后采用非对称的高斯注意力获取歧义区进行补偿,细化伪装目标区域的分割结果。
(2) 采用复合主干网的双主干(dual-backbone, DB)结构,强化对伪装目标的感知提取,将前一主干相邻层级的输出与后续主干的输入合并作为后续主干新的输入。同时,为避免主干网络模块过多导致计算复杂度增大,本文移除辅主干网的第一阶段,并对辅主干网的整体结构进行轻量化。
(3) 实验结果表明,提出的方法在3个公开伪装数据集上实现了最优的分割效果,并通过消融实验验证了方法的有效性。
1 LCNet算法
为了更好地定位和细化特征归属,本文提出一种基于定位和非对称补偿的伪装目标分割网络,整体结构如图2(a)所示。网络包含两个关键模块:LM和ACM,以及负责多尺度特征提取的复合主干网的DB。具体而言:首先,将包含伪装目标的图像输入复合主干网的DB结构,进行多尺度特征提取与融合。然后,在主主干网与辅主干网最深层特征图的拼接结果上引入LM,对潜在的物体位置进行初步定位。接着,将主主干网与辅主干网剩余3个层级的特征输出至卷积块(convolution+batch normalization+ReLU, CBR)中进行通道减缩。将水平相近的主辅减缩结果输入至同一个ACM。最后,通过ACM级联的方式,完成对定位结果的逐步细化与补偿,得到最终的COS结果。

图2 定位补偿网络Fig.2 LCNet
1.1 复合主干网

具体而言,若只有一个主干网,第-1级特征-1作为输入,第级特征作为输出,第级映射关系为,输入和输出关系可表示为
=(-1),≥2
(1)
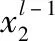

(2)


(3)
式中:包含核尺寸为1×3与3×1的CBR处理模块;Up(·)为上采样操作。特征通过两个不同核尺寸的CBR处理模块后,加权与输入相加。最后,以上采样操作调整回流特征尺寸,保证特征拼接尺寸一致。
辅主干网中的DBA模块主要包含多分支提取结构后缀通道注意力处理。文献[24]指出,将两个具有不同表征能力的分支(例如1×1卷积和3×3卷积)组合起来比两个相同分支(例如两个3×3卷积)更好。本文提出的多分支拓扑将具有多尺度卷积、顺序1×1-×卷积、平均池化等分支,并对拓扑分支的求和结果施加高效序列提取(effective squeeze-and-excitation, eSE)注意力,明确地建模了特征映射通道之间的相互依赖关系,以增强其表示性:
=((_gap()))⊗
(4)
式中:为多分支结构提取完的结果;为sigmoid激活函数将输入映射到0~1之间;_gap为通道域全局平均池化(global average pooling, GAP)操作。最后,本文借鉴ResNet的残差思想,将原始输入特征图按元素添加至中。通过主干提取的多层级特征会分别借助通道减缩输入至LM以及ACM中。
1.2 定位模块
本文所提出的LM结构如图3(a)所示,其中MAX表示最大池化,GA表示高斯注意力。LM由通道注意力与空间注意力串联构成,其主要作用于DB深层次拼接的特征图上,以获取语义增强的特征。LM中通道注意力利用特征的通道间关系生成通道注意图,关注的是单个检测器内容语义提取,在本文中以非局部的方式实现。在通道注意力之后,级联空间注意力模块,增强位置信息的提取,进而与前者在信息提取上互补。
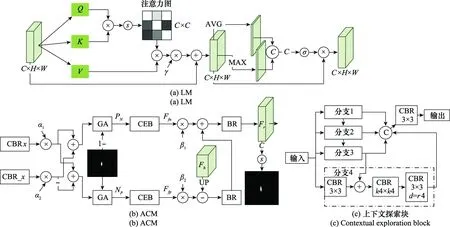
图3 两大关键模块Fig.3 Two main building blocks
具体而言,给定特征输入⊂××,首先通过形状变换得{,,}⊂×,=×,然后对,矩阵叉乘,并采用softmax函数归一化得到通道注意力图⊂×:

(5)
式中:为输入特征总的通道维数;值表示第个通道,:与第个通道,:的相似度程度。最后,与矩阵叉乘,得到通道注意力的输出特征⊂××:

(6)
式中:为第个通道特征加权后的结果;(·)是价值变换函数,以线性函数的方式实现;归一化因子()采用softmax函数;是范围1~的点集。在此基础上,为减少信息的传输损失,引入一个可学习的残差跳跃连接,最终的非局部通道注意力可表示为
=γ+
(7)
式中:为比例系数;⊂××为增强后的特征(为其第个通道成份),其建模了特征图通道之间的长范围语义依赖关系,加强了特征的可判别性。在通道注意力的基础上,本文引入了一个空间注意力模块,对通道注意力输出结果分别采用空间域的GAP_gap及全局最大池化_gmp,并将两结果拼接作为卷积的输入,最后借助sigmoid函数对结果进行映射处理,得到空间注意力图:
()=(conv([_gap(),_gmp()],(7,7)))
(8)
将得到的注意力图对输入特征加权,筛选出空间位置信息,操作过程可表示如下:
′=()⊗
(9)
式中:⊗为元素乘法运算;输出特征′⊂××。通过LM的处理,初步确立了目标的通道语义与空间位置信息,以便后续的ACM级联补偿与逐步细化。
1.3 ACM
伪装物体在纹理上通常与背景极其相近,如何划分歧义区域的归属将直接影响最终的分割精准度。本文从两个对立面进行信息的逐步细化与补偿,实施细节如图3(b)所示,而对应的补偿机理见图4。

图4 推理分析补偿Fig.4 Reasoning analysis compensation
首先引入LM或上一级ACM的输出特征,其相较于真实值会存在歧义区域的错误划分,需查漏补缺。本文对DB的同等级输出施加差异化的求和,进而得到侧重于前景信息的特征与侧重于背景信息的特征。进一步借助对立的,分别对与施加全局高斯注意力,得到歧义区域(中关注背景得歧义成份以及中关注前景得歧义成份),最后对()进行进一步特征提取与融合得假阴性特征(假阳性),并对输入特征进行信息补偿,即正补偿、负补偿。

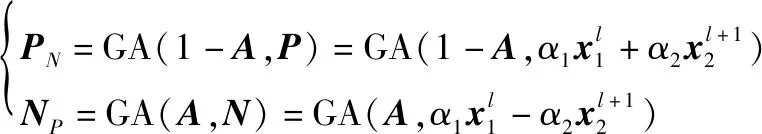
(10)
式中:/为歧义区域(前景背景中关注得到的背景前景);为上一级模块输出的真值预测;GA为文献[4]所提出的高斯注意力,以增强目标特征的提取。在此基础上分别输入图3(c)所示的上下文探索分支结构,主要利用扩张卷积结构增大感受野,然后借助通道维度的叠加融合,以增强大范围内感知丰富上下文的能力,借此获得歧义区域的最终归属,并利用划分结果对特征图进行补偿:
=BR(BR(Up()-)+)
(11)
式中:BR为批归一化和ReLU激活函数的组合;,为可学习的比例系数。
1.4 损失函数
考虑到交叉熵损失只能刻画图像在像素层面的不同,无法较好反映出整体、局部以及边缘信息的差异。本文在该损失的基础上引入交并比损失,即=+,用于描述LM在空间位置的偏差。而ACM更加关注边缘歧义区域的像素归属,故引入结构相似性损失去引导ACM对边缘区域的补偿与细化,即=+。为突出不同层级的贡献度,本文通过不同权重系数加以区别,总的损失可描述如下:

(12)
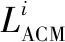
2 实验验证
2.1 实验设置
数据集。本文主要在3个基准数据集上对本文提出的方法进行评估:CPD1K、CAMO以及COD10K。COD10K是目前最大的伪装数据集,且标注精度很高,总共包含5 066张伪装图片,其中3 040张图片用于训练,2 026张用于测试:CAMO总共包含1 250张不同类别的数据样本,其中1 000张用于训练,250张用于测试;CPD1K总共包含1 000张只有人的数据样本。由于数据集未对样本做测试和训练的划分,本文随机将其中800张用于训练,200张用于测试。本文将训练所有数据(COD10K+CAMO+CPD1K)作为方案Ⅰ,只训练COD10K数据集作为方案Ⅱ。

实施细节。本文的LCNet采用Pytorch实现,训练和测试均使用一台8核16线程的工作站,配备Intel i7-11700 CPU @2.5 GHz,32 GB RAM和2块NVIDIA GeForce RTX 3090 GPU 24 GB。在训练和测试阶段,图像尺寸统一调整为416×416。随机白噪声以及图像随机翻转被用于在训练阶段进行数据扩增。主主干网采用由ResNet-50模型在ImageNet上进行预训练获得的权重来初始化,其余参数通过随机方式初始化。本文批量载入图像的数量为64,采用Adam优化器进行梯度下降处理,遍历样本45轮耗时约56 min,训练过程损失变化见图5。图5(a)为总损失变化,图5(b)为对应的4个子损失函数(式12),
可看出本文方法在训练阶段以较快的速度收敛。

图5 训练损失曲线Fig.5 Training loss curve
2.2 方法对比
为验证本文提出方法的分割性能,本文与6种最新的基于深度学习的目标分割模型进行比较,并按照训练方案Ⅰ,使用原文推荐的参数来训练。借助指标在测试集上进行效果评估,得到的比较效果如表1所示,其中标注↑的指标值越大越好,标注↓的指标值则相反。表1中最好的结果已加粗表示,而蓝色字体为现有方法的最好值。由表1可以看到,在训练方案Ⅰ下,本文所提出的方法在各项指标上均优于现有方法。
为了进一步衡量本文方法的分割性能,对本文方法采取了方案Ⅱ的训练方式,实验结果如表1的本文(Ⅱ)部分。可以看到,在COD10K、CAMO数据集上,本文方法的多个评估指标结果仍高于6种最新方法的平均值(表1中绿色字体所示),体现了本文分割方法的高效性。而本文方法在CPD1K上效果欠缺明显,主要原因在于CPD1K中包含较小样本,与COD10K的数据分布差异较大。

图6展示了本文方法与6种最新方法的分割效果定性对比。从左到右依次是原始图像、分割真值图像、本文方法的真值预测以及6种最新方法的真值预测。通过对比可以看出,本文方法的伪装目标分割结果与真值图像最为一致,无论是大伪装物体(第1、2、3、6行)还是小伪装物体(第7、8行)以及背景复杂的伪装物体(第4、8行)。本文方法的高分割精确性主要得益于主干强感知、双注意力定位以及边缘细节的层层补偿,最终感知物体位置并合理划分了歧义区域的像素。
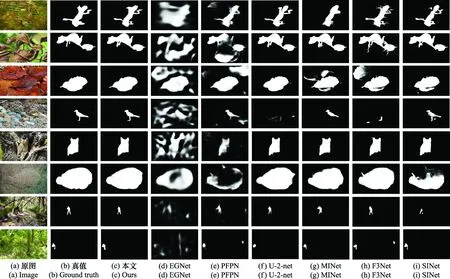
图6 本文提出的方法与6种最新方法的分割效果对比示例Fig.6 Comparison of segmentation result between the proposed method and the six latest methods
2.3 消融分析
为验证LCNet中DB、LM以及ACM等模块的有效性,本文进行消融实验对照,结果如表2所示。其中,未打“√”表示方法缺失该模块。可以看出,在同一训练方案下,3个模块的缺失均会显著降低方法的分割表现。其中,ACM的影响最为显著。为了进一步描述ACM如何影响分割效果,本文从定性的角度进行分析,如图7所示。
图7从左到右依次为原图、真值,第1、2、3个ACM的预测特征图以及预测真值。由图7可以看出,随着级联ACM的作用,预测真值的歧义像素归属逐步细化。为了对比,在图中第1行预测特征图中,标注出上一阶段(LM或上一级ACM)的真值。通过与真实值的对比可直观发现特征的改变:原本在LM作用下的猫头鹰只关注到躯干的大体位置特征,在ACM_1的作用下,施加了对头部与翅膀处的歧义区域的注意,补偿缺失的前景与剔除背景的干扰,预测真值中多出右耳朵的模糊雏形(见图7(d))。ACM_1输出在ACM_2作用下细化猫头鹰的左耳朵周围的特征,使预测真值多出了左耳朵(见图7(f))。而ACM_2输出在ACM_3作用下,使预测值的左右耳朵变尖,进而更贴近真值(见图7(h))。可以看出,在本文级联ACM补偿作用下,目标细节特征逐步精准,具备较强的分割性能。
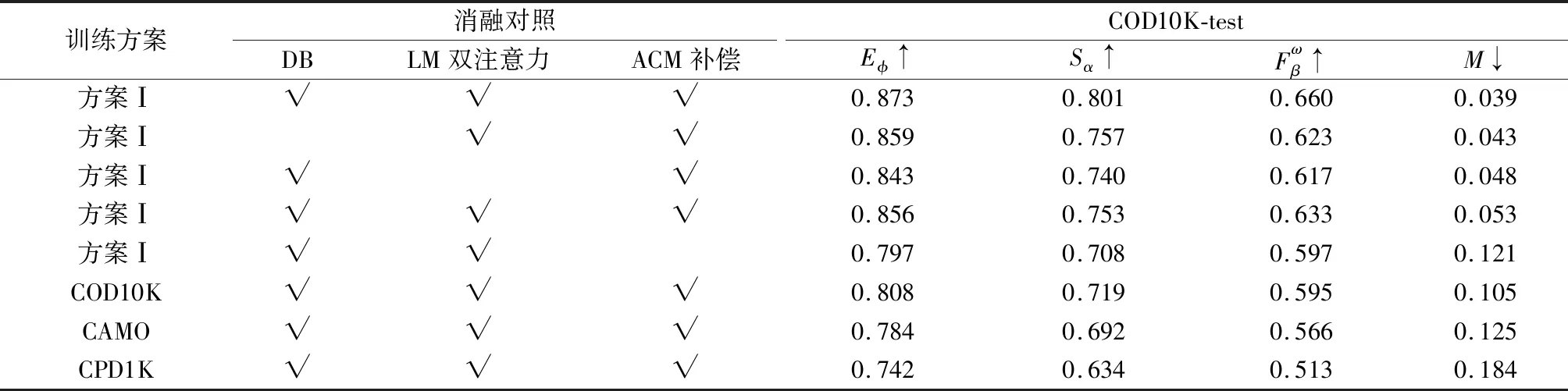
表2 消融实验Table 2 Ablation experiment

图7 级联ACM的逐步细化Fig.7 Gradual refinement of cascading ACM
3 结 论
为克服伪装目标的前景与背景的高度相似性,本文提出一种基于定位和非对称补偿的网络结构LCNet,通过DB结构强化对底层特征的感知提取,然后引入双注意力的定位模块对伪装目标位置进行初步确定,最后采用级联的ACM,逐步细化歧义区域的像素归属。通过实验表明,本文提出方法在3个公开数据集上达到最优的分割性能。下一步,将改进模型并融入类别信息,以使伪装物体研究在军事、工业、农学、医学、生物学等领域具备更深广的应用潜力。
