基于改进LOF算法的窃电检测方法研究
2022-09-02殷锋周绍军漆翔宇曹旭
殷锋,周绍军,漆翔宇,曹旭
(1 西南民族大学 计算机科学与工程学院,成都610041;2 四川水利职业技术学院 信息工程系,成都611231)
窃电行为长期以来困扰着供电企业,也是阻碍其安全生产和导致遭受经济损失的主要原因[1].常见的窃电方式根据原理的不同可分为断流窃电、欠压窃电两种方法[2].鉴于此,当前的检测手段多依赖人工现场勘察.此类办法成本高且费时费力.而数据驱动的窃电检测手段因其不用区分窃电方式,仅利用窃电样本集和历史用电数据集进行分析就可进行预警,故其优势得到国内外学者的普遍认同[3].目前数据驱动的窃电检测方式开始大量涌现.文献[4]提出将神经网络用于线损管理可以最大限度地简化电力系统.刘月峰等人[5]进一步提出时间卷积网络结构,对于处理大规模并行数据占有优势.
LOF算法作为常见的异常检测算法同样被应用到窃电识别领域之中[6-11].文献[6]提出通过降维将所有用户的用电序列投影到二维空间,而后采用LOF 算法计算每个用户的离群程度,即通过少数异常度靠前的用户去检测其他异常用户.YECKLE 等人[7]利用LOF 算法来提高AMI 的安全性.PENG 等人[8]提出了将LOF 算法[12]和聚类技术结合的检测方法.林之岸等[9]针对规模庞大的低压用户窃电隐患提出了基于K-SVD特征编码改进的LOF模型.然而,传统LOF算法在处理海量数据时存在时间复杂性过高、处理效率低下,而导致处理程序异常退出的缺陷.
针对上述问题,本文引入基于混合查询剪枝的球树模型对LOF 算法进行优化,提出重构数据对象球树模型局部离群因子(Reconstructed data object Ball Tree model Local Outlier Factor,RBT-LOF)算法.并在该算法基础上给出了一种利用DenseNet 算法进行特征提取的新型窃电用户检测模型.经过实验证明,RBT-LOF 算法通过重构数据对象的组织结构以及查询、搜索方式,极大地增加了算法可承受的数据容量,有效地提升算法执行的效率,并且在结合DenseNet 算法对用电数据进行预处理后在检测精度上获得提升.
1 LOF算法过程及缺陷分析
1.1 经典LOF过程分析
LOF 算法作为基于密度的异常值检测算法,其原理是通过衡量每个数据对象和它周围数据的密度情况,计算得到每个数据对象的LOF值来判断数据对象是否为异常值.该算法主要有五个定义:
(1)设k为一正整数,数据对象p的第k距离记作k-dis(p),即距离p第k远的数据对象到p的距离.在数据集C中存在一个数据对象q与p之间的距离记作d(p,q),存在以下两种情况使得k-dis(p) =d(p,q):
i:至少存在k个数据对象q"∈C/{p}满足d(p,q") ≤d(p,q).
ii:至多存在k- 1 个数据对象q"∈C/{p}满足d(p,q") ≤d(p,q).
(2)数据对象p的第k距离领域.它是所有和p的距离小于第k距离的数据对象的集合,记作Nk-dis(p).
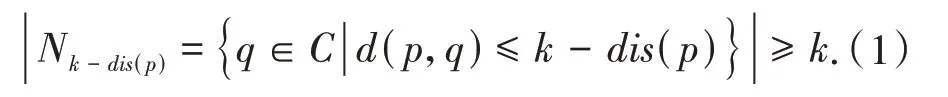
(3)数据对象p到q的可达距离记作reach-disk(p,q),它至少是p的第k距离,或者p、q之间的真实距离.其定义为:
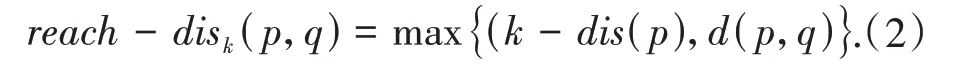
(4)数据对象p的局部可达密度表示p的第k领域内的数据对象到p的平均可达距离的倒数,记作lrdk(p),即为:
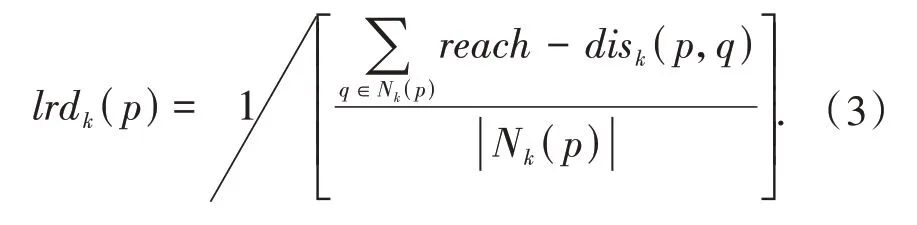
(5)数据对象p的局部异常因子表示p的第k领域Nk(p)的局部可达密度与p的局部可达密度之比率的平均值,记作LOFk(p),即为:
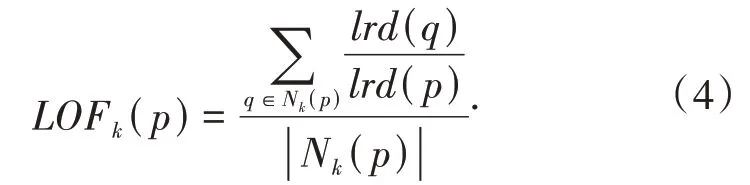
1.2 LOF缺陷分析
作为基于领域平均密度的异常值检测算法,LOF 算法将数据对象和其第k距离领域内的数据对象集中分析处理,检测精度高.另一方面,该算法无需待测数据的分布情况,适应性强,应用场景多元.但该算法以数据对象和其领域点之间的密度比为判定机制,而密度又以距离排序搜索为衡量标准,数据对象的搜索方式为时间复杂度高达O(kn2)的线性搜索,导致该算法的检测效率欠佳.而且线性搜索的方式对计算机资源的消耗十分严重,导致单次检测数据的容量变低,无法快速完成大规模数据的异常值检测工作.
2 基于混合剪枝树模型改进的LOF算法
针对LOF 算法存在的缺陷,本文引入基于混合剪枝查询的球树模型[13]对该算法进行改进,通过重构数据对象并在球树模型上完成数据区域划分,利用混合剪枝完成高效搜索查询并计算数据对象的LOF值,能够有效地提高算法的执行效率.
2.1 算法改进策略
导致LOF 算法复杂度居高不下的主要原因是其在获取数据对象的第k距离以及第k距离领域时采用了简单但十分低效的线性搜索策略.
因此首先将数据对象重新组织,将其在球树模型上完成数据区域的划分,为后续查询数据对象时提供有针对性的搜索查询.基于混合剪枝查询的球树模型以数据对象第一特征和平衡树构建原则为基础,借助数据对象的第一特征方向,找出树结构超平面的最佳切割位;之后,将数据对象重构成球树模型.可通过式(5)求解最佳切割位.
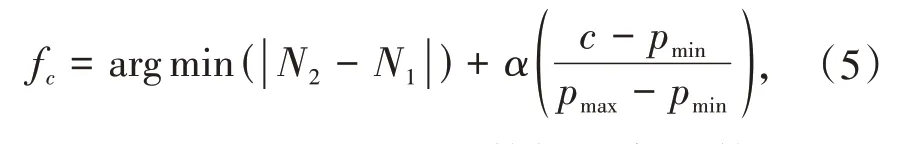
其中N1和N2表示两个子分区数据对象的数量,pmax和pmin分别表示数据对象投影到第一特征后得到的标量集中最大值和最小值.α是一个正权重参数,当查询的数据对象与原始数据对象具有相同分布时,c的位置可以通过平衡数据对象数量来确定,此时α设置较小值以更关注于数据对象数量平衡优化求解.
在完成数据对象重构后,借助构建的球树模型将LOF 采用的线性搜索方式替换为更加高效的基于混合剪枝查询的搜索方式.该搜索方式结合了K-NN搜索算法[14]和范围搜索(Range Searching,RS)算法[15],既能够快速跳过距离过远的节点,又有效地限制了待搜索节点的数量,减少节点搜索所耗时间.在数据集大小为n的情况下,LOF 算法的理论时间复杂度达到了O(kn2),而RBT-LOF 算法理论上的时间复杂度仅为O(nlogn).
2.2 改进后算法描述
融合混合剪枝查询树模型的RBT-LOF 算法流程具体如下.
输入:带异常值的数据集
输出:所有异常值
(1)使用PCA 将输入数据映射到第一特征向量w1;
(2)垂直于w1一定偏移量确定数据空间分割超平面,最佳分割位由求解fc取得;
(3)根据树的构建原则以超平面切割线对数据空间进行切割,直到划分完所有数据对象;
(4)选取任意数据对象,利用混合剪枝搜索策略在空间树中进行搜索查询,得到数据对象的第k距离和第k距离领域;
(5)根据LOF 算法的定义,依次计算选取对象的第k可达距离、局部可达密度和局部异常因子LOF;
(6)将LOF值远大于1 的数据对象判断为异常值;
(7)判断是否所有的数据对象均已被选取并检测,若是则直接输出,否则执行步骤4.
3 基于RBT-LOF算法的窃电用户检测
在RBT-LOF 算法基础上,提出了一种新型窃电用户检测模型.考虑到对用户用电信息这类高维数据手动进行特征提取的话,既繁琐又难以确定所获取特征的实际效果;相比之下,利用深度学习技术进行特征提取具有无需专家经验,且检测准确率高的优势.就目前而言,因DenseNet 算法[16]是众多深度学习技术中性能表现较为优越者,故使用其对用户用电数据进行特征提取;而后,再利用随机森林算法[17]来进行筛选足以判断用户类型的重要特征;最终,将提取出的特征数据取代原始用电数据以作为RBT-LOF算法的输入,由此判别窃电用户.
3.1 窃电用户检测过程描述
首先,预处理原始数据集,清洗含有缺失值的数据;其次,利用DenseNet 算法提取用户用电数据特征;随后,使用随机森林算法对特征降维;之后,将降维后的用户用电特征输入到RBT-LOF 算法中计算各用户的局部异常因子以判别出窃电用户;最终,返回窃电用户集合.具体流程详见图1.

图1 基于RBT-LOF的窃电用户检测流程Fig.1 User detection flow chart of stealing electricity based on RBT-LOF
3.2 特征提取与降维
文章数据集来源于爱尔兰能源局收集的智能电表数据[18],包含用户在534天内的用电数据,采用48 点数据描述.由于原始数据集的规模巨大且存在数据缺失的情况,因此先对原始数据集进行了清洗,清洗后的数据集包含了6048 个用户的数据.因为该项统计是建立在用户同意收集的基础之上,故可默认数据集中的用户均为正常用户,所以需要人工构建窃电用户样本加入其中.本文采用文献[19]所提出的方法生成了6048个窃电用户,最终实验数据集包含了12096个用户的用电数据.
DenseNet 算法的参数配置参考了文献[1]的设置,由于DenseNet 算法自动提取的特征矩阵维度较高,而高维度数据又往往不便于处理,因此需要对数据特征进行降维处理,以形成低维度的特征集.而降维处理目前的理想算法就是随机森林(Random Forest,RF)算法.因此,本文选取RF 算法用以判定用户用电特征的重要程度,并将特征重要性排序以供选择.其对用电数据的特征重要性排序如图2所示.
由图2 可知,用户数据的重要信息主要保存在V17、V12、V14 和V10 这四个特征中,因此正常用户与窃电用户主要的差异就应该体现在这四个特征中,故需要对这些特征在两种不同类型用户中的差异进行分析,分析结果如图3所示.

图2 用户用电数据特征重要度排序Fig.2 Ranking of characteristic importance of user power consumption data
由图3 可知,正常用户与窃电用户数据的重要特征的特征值分布差异十分明显,说明这部分特征包含了每个用户的重要差异信息,也是区别正常用户与窃电用户的主要特征.因此将原有数据的其他特征剔除,构建一个数据信息相对集中、数据维度相对较低但又保存了大多数重要用电信息的实验数据集,数据集={V10,V12,V14,V17}.

图3 Top4特征在两种类型用户用电数据中的特征值分布差异Fig.3 Difference of eigenvalue distribution of Top 4 feature in two types of user power consumption data
3.3 局部异常因子计算
在完成数据集预处理之后,便可利用本文算法计算各数据对象的局部异常因子的值以进行最终的窃电用户判断,局部异常因子的计算方式详见文章第一节.
LOF值的大小是LOF算法判断一个用户是否为窃电用户最直接的依据.以1 为分界值,LOF值的大小与用户为窃电用户的概率呈正相关.如果某个用户与它周围的用户相距过远,那么该用户的局部离群因子LOF值远大于1,便有可能为窃电用户;反之表明该用户及其领域可能同属一簇,为窃电用户的概率很小.因此,将LOF值大于1的用户加入窃电用户集中返回即可.
4 实验
4.1 实验设计
为 了 验 证 本 文 方 法 的 性 能,选 择WDNet[20]、CNN[16]、SVM[21]和LOF 算法作为对比在实验数据集上进行了大量实验.实验采用准确率(Accuracy)和召回率(Recall)验证本文提出方法在精确性方面的能力;使用AUC(Area Under the ROC curve,AUC)指标衡量本文方法的泛化能力;且由于本文所提出的RBT-LOF 算法主要对LOF 算法的数据划分与搜索方式进行了优化,并不会改变原算法的检测精度,因此选择了检测效率以及单次可检测数据容量与LOF算法对比来衡量RBT-LOF算法的执行效率.
4.2 结果分析
4.2.1 单次可检测数据容量及执行效率对比
LOF 算法存在一个需要自设定的参数k,不同的k值会影响实验的结果.由于实验数据样本大小有限,可能存在测试数据不足的情况,需要扩充测试数据样本.为避免因实验数据而造成的误差,本次实验使用原数据随机多次地扩充测试数据样本的容量.不同k值下两种算法单次能检测的最大数据容量如表1所示.

表1 不同k值下各算法的单次最大检测数量(×10000)Tab.1 The single largest detection transaction data volume of the algorithm under different k values(×10000)
由表1可知两种算法的单次最大检测数据容量对阈值k的取值并不敏感,相对保持稳定.传统的LOF 算法单次最大检测数据量偏低,无法快速完成大规模的用户用电数据检测.RBT-LOF 算法通过对数据空间划分方式进行优化,其单次最大检测数据容量远高于传统的LOF 算法,有效地提高了窃电用户的检测效率.
为方便实验结果的对比,以传统LOF 算法的单次最大检测数据容量为测试数据容量,分别使用两种算法对用电数据进行异常值检测.检测耗时如图4 所示.由图4 可知在设置不同阈值k的情况下,RBT-LOF 算法的检测效率远优于传统的LOF 算法.同时,随着检测数据量的增加,检测速度上的提升越发明显,说明RBT-LOF 能够有效且稳定地提高传统LOF算法的异常值检测效率.

图4 两种算法在不同k值下的检测效率对比Fig.4 Comparison of the detection efficiency of the two algorithms under different k values
4.2.2 精确性能和泛化能力对比
为了证明本文所提出的方法的有效性,实验使用准确率(Accuracy)和召回率(Recall)来检测算法精确性能,并使用AUC 指标衡量算法的泛化能力.以上指标的计算方法可参考文献[1].由图5 可以看出,本文所提出的方法的准确率和召回率分别为96.83%和95.79%,在对比算法中均达到了最优,WDNet 作为优化后的卷积神经网络优于SVM 算法和传统卷积神经网络CNN 算法,比较接近本文所提出的方法.而传统的LOF 算法的实验结果因数据集中异常样本占比较高,所以在准确率和召回率上的表现相对较差.
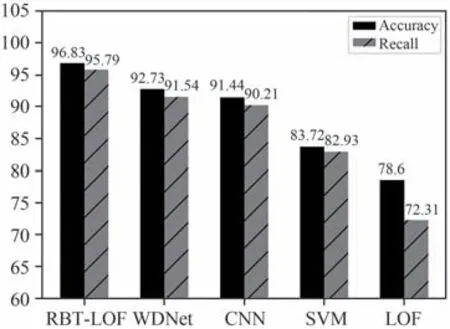
图5 不同算法的准确率和召回率对比Fig.5 Comparison of accuracy and recall of different algorithms
实际上,机器学习所学得的模型除了能较好地拟合训练样本之外,还应能适应新样本.模型在未知数据上表现良好的能力被称为泛化能力,一般以模型在测试集上的性能来衡量模型的泛化能力,并将验证结果以混淆矩阵与ROC(Receiver Operating Charact-eristic)曲线下面积(Area Under the ROC c-urve,AUC)进行呈现.由图6 可以发现,本文所提出的方法的AUC 值达到0.97,优于其他对比算法,证明该算法在泛化能力方面表现良好.
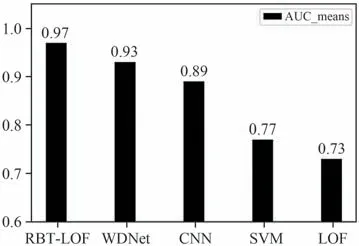
图6 不同方法的AUC结果对比Fig.6 Comparison of AUC value in different methods
5 结语
本文针对窃电检测领域内常用的LOF 算法所存在的执行效率低、最大数据容量差等问题提出了基于混合剪枝树模型改进的RBT-LOF 算法.RBTLOF算法将待测数据重新划分后存储于平衡树模型中,并引入一种混合剪枝的数据搜索方式,能够有效地提高数据对象的LOF值计算效率,从而快速挖掘出数据中的异常值.在数据集大小为n的情况下,RBT-LOF 算法理论上的时间复杂度为O(nlogn),原算法为O(n2).在所提出的算法基础之上提出了一种窃电用户识别方法,经过大量试验证明,该方法相对传统LOF 算法能够大幅度提升窃电检测效率和单次最大检测数据容量,相对其他窃电检测方法具有更好的分类准确率和稳定性,且具有良好的泛化能力.
本文提出的RBT-LOF 算法只专注于解决LOF算法存在的低检测效率问题,未对其检测精度进行深入探讨.在今后的研究中,需要进一步优化,在确保检测效率的同时提高检测精度,并在真实应用场景中设计算法的分布式部署应用方案.除此之外,本文在应用混合剪枝树模型时选用了PCA 算法求解数据的第一特征,但考虑到本文实际生产数据的不平衡性,选用性能更好的算法如RPCA 算法[22]等应当会带来更好结果,在未来的研究中将验证该想法,并考虑设计合适的替代算法.
