基于LSTM模型与加权链路预测的学科新兴主题成长性识别研究
2022-09-01段庆锋刘东霞闫绪娴张红兵
段庆锋 陈 红 刘东霞 闫绪娴 张红兵
(山西财经大学管理科学与工程学院,山西 太原 030006)
新兴主题已经成为科技情报学界持续关注的热点和难点。代表科技趋势的学科新兴主题能够为国家科技战略规划、企业增强科技竞争力、研发人员寻找技术机会提供关键的决策依据,具有极高的战略价值。成长性是新兴主题的重要表现,更是识别新兴主题的关键。通过梳理相关文献可以发现,尽管新兴主题识别采用的逻辑依据各有不同,但出现最多的就是成长性(Growth)特征[1]。通过捕捉成长性特征发现新兴主题识别领域的基本共识。然而,成长性具有鲜明的动态属性,学科趋势面临诸多不确定性,预测甚至洞见学科未来存在挑战性。
以深度神经网络及链路预测为代表的信息技术前沿进展为新兴主题识别提供了有力工具。已有研究采用的方法多样,以曲线拟合分析、时间序列预测、网络分析等为代表的模型工具得到广泛应用,但在识别有效性及预见能力方法仍存探讨空间。LSTM具有很强的时序依赖分析预测能力,有助于捕捉新兴主题快速增长态势;链路预测能够通过网络依赖关系预测二元关系形成几率,有助于从网络演化视角揭示新兴主题的成长性。两种模型从不同层面形成趋势预见能力,通过它们的融合分析,有助于提升学科新兴主题成长性的综合识别能力,进而推进学科新兴主题领域研究。
1 相关研究概述
关于学科新兴主题识别的文献丰富且探讨相对深入。学科主题的内涵理解与外延边界把握是识别分析的基础,以LDA、BERT等为代表的语义分析模型及工具极大地促进了文本语义理解能力[2-3],与基于主题词的定性化分析形成效能互补[3]。新兴特征的准确捕捉与有效区分成为影响识别效果的关键。从思路上看,识别逻辑大致可以分为两大类:一是主题特征序列视角的新兴演化,强调时间维度下的主题状态演化趋势规律;二是结构视角的关系变化,通过知识结构变化揭示新兴过程中的主题要素关系(如引用关系、共现关系)规律,通过聚类分析、社区探测等方法揭示主题簇的涌现或知识模式的呈现[4-6]。
近年随着机器学习理论及算法的不断成熟,面向主题的定量化预测模型及算法开始受到关注[7],尤其深度学习的应用趋势最为明显。例如,Liang Z T等[8]融合深度神经网络模型和文献计量指标用于预测新兴主题。霍朝光等[9]构建基于LSTM神经网络的学科主题热度预测模型(TPP-LSTM),反映了LSTM对于主题热度时间序列的良好预测能力。朱光等[10]将LDA主题模型和LSTM模型相结合,构建主题预测模型,并对科学基金主题趋势开展了预测分析。陈伟等[11]利用LDA主题模型捕捉技术主题聚类,结合应用包含双重随机过程的隐马尔可夫模型(HMM)开展未来技术趋势的定量预测。Xu S等[12]构建了融合多种机器学习模型的新兴主题预测识别方法。许学国等[13]构建结合经验模态分解(Empirical Mode Decomposition)和LSTM模型的时间序列技术主题预测模型,通过与Clarivate Analytics机构2018年报告的比对验证,说明了方法的有效性。李静等[14]对比分析了BP神经网络、支持向量机和LSTM模型在热点趋势预测应用方面的异同。值得注意的是,近年链路预测开始成为主题识别的分析工具。比如,Huang L等[15]基于链路预测指标构建共词网络演化神经网络预测模型,基于预测网络设计4个识别指标,以识别新兴主题。Cho J H等[16]采用基于链路预测的机器学习方法预测技术主题的融合模式。黄璐等[17]将链路预测方法引入主题识别问题领域,基于加权链路预测和神经网络,围绕主题新颖性和影响力两方面,构建识别预测模型。另外,融合多种类型媒介数据的主题预测方法也成为不可忽视趋势。比如,Akella A P等[18]证实了以替代计量指标为代表的社交媒介在学科预测及时性方面的优势;段庆锋等[19]构建融合社交媒介和出版媒介的新兴主题识别指标,基于此构建更加高敏感的新兴趋势预见与主题识别方法。
综上所述,LSTM模型和链路预测已经被科技情报学界关注,开始将其引入并应用于学科新兴主题研究领域。然而,还鲜有结合两种模型预测优势构建的新兴主题研究。LSTM模型并未考虑不同主题之间的内在关系,而面向二元关系的链路预测则弥补了LSTM时序模型在主题网络演化方面的局限。本文结合两者特征,针对学科新兴主题成长性识别问题,构建新型组合模型,提升成长性特征的动态刻画与预测能力。
2 研究方法
2.1 分析框架
新兴主题的成长性成为识别的关键依据。按照生命周期理论,新生、新兴、成熟、衰退、消亡依序构成发展过程,新兴阶段通常表现出的高增长性成为趋向成熟过程中呈现的外部可观察特征[20],更重要的是当前的新兴状态是实现未来成熟的不可避免历程,这种新兴特征很大程度上为将来状态提供了重要启示,是科学预见的客观基础。
新兴主题不但具有成为未来热门主题的潜力,更应该在未来学科知识体系中承担重要地位与影响力。由此,主题成长性可以从两方面加以考察:热度和影响力。一是聚焦于主题本身的发展规律,开展时序预测,从数量层面反映其状态预期;二是通过主题间关系演化,开展网络预测,从关系结构层面反映其未来影响力预期。基于趋势预测的思路,结合主题新兴阶段的生命周期特征,设计学科新兴主题识别方法流程,如图1所示。
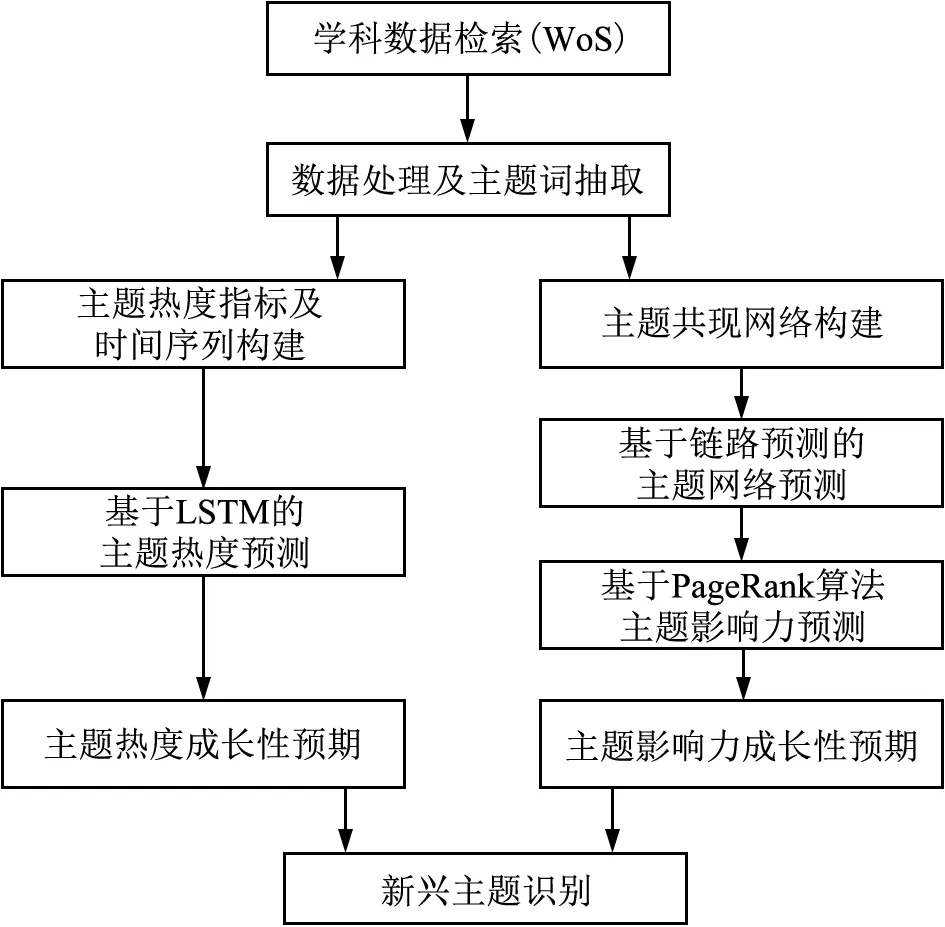
图1 基于组合预测的学科新兴主题识别流程
首先,构建结合文献计量指标与Altmetrics指标的主题热度指标,并采用长短记忆神经网络LSTM,预测主题未来的热度状态;其次,采用链路预测方法,预测未来的主题词共现网络,通过PageRank算法揭示主题的未来影响力;最后,基于预测结果,将预测状态与历史状态进行比较刻画,揭示主题热度的增长性预期与影响力演化预期,由此通过二维动态特征的综合研判,形成学科新兴主题的识别依据。
2.2 主题热度预测
2.2.1 主题热度指标
主题热度指主题在学科领域的受关注或者流行程度[21],可以从两个层面加以考察,一是狭义学术层面;二是广义社会层面。在狭义学术层面,主题内容在学科领域的发表曝光程度体现了主题在学术层面的流行热度,反映学者对主题的关注程度,可以通过主题所出现的文献数量加以衡量[22]。在广义社会层面,主题通过更广泛多样社会媒介加以传播,主题内容受到更多相关利益者的关注、讨论,体现了主题在更广泛社会层面的流行热度,更多地反映了社会大众对于主题内容的兴趣与关注程度。主题在广义社会层面的传播热度可以通过Altmetrics指标加以衡量。作为科学计量学的新型度量工具,Altmetrics指标捕捉了作为主题内容载体的学术文献在多种网络媒介(尤其学术社交媒介)的传播及交互事件(如点赞、转发、提及等),通过相关事件计量的方式刻画了学术内容的社会关注程度[23],非常适用于刻画主题在社会层面的流行关注程度。
考虑到学科主题热度是不同媒介层面的综合体现,由此构建第i个主题的加权热度总指标H:
Hi=α·Pi+(1-α)·Ai
(1)
其中,α为权重系数,且0≤α≤1,这里将其设定为0.8。指标P代表主题出现的文献篇数,指标A代表主题在社会媒体受到的关注程度,其定义为:
Ai=Altmetricsj·Iij
(2)
其中,Altmetricsj为第j篇文献的替代计量指标值,Iij为指示变量,将其定义为:
(3)
指标P和A通过计量方式分别刻画了主题在学术文献和大众媒介的传播与关注程度,从不同层面体现了主题热度。考虑到指标P和A分别来源于不同媒介,数值存在明显的量级差别,因此采用极大极小法对两个指标分别进行归一化处理,消除指标量纲。
2.2.2 主题热度预测模型
长短期记忆模型LSTM是一种循环神经网络,相关文献已证实其在时序序列预测方面的优异性能,能够很好地满足主题热度预测任务[14]。首先,以年份为时间单元,计算主题热度指标H,形成包含若干主题的面板数据;其次,以跨度T年为时间窗口,前T-1期指标数据为输入,第T期为输出,构造LSTM预测模型,如图2所示。通过训练集样本进行模型学习训练,考察损失函数、AUC等性能指标,经过多轮更新迭代,直至得到性能满意的LSTM拟合模型;最后,采用拟合模型预测主题未来热度值。
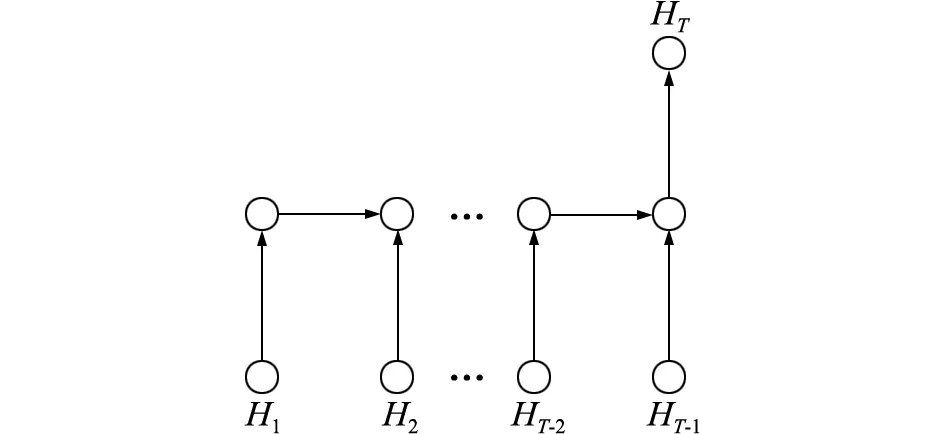
图2 基于LSTM的主题热度预测模型
2.3 主题影响力预测
共现关系是刻画主题语义结构的重要途径,能够揭示学科知识分布及演化规律,已成为情报科学领域的成熟范式。主题间相互作用关系及拓扑结构嵌入是个体相对影响力的重要体现。预测主题间潜在共现关系能够为主题影响力演化提供前瞻性启示。
链路预测利用拓扑结构信息预测二元关系的形成或消失,能够被用于预测主题间共现关系的涌现。基于此,使用链路预测相似性指标构建主题共现网络预测模型,并基于未来主题网络,通过PageRank算法识别学科主题的潜在影响力。整体上,主题影响力预测包括3个阶段:主题共现网络构建;主题共现关系预测;主题潜在影响力。
2.3.1 主题共现网络构建
如果两主题至少共同出现在同一篇学术文献的标题、关键词及摘要,则认为两者存在共现关系。采用Ochiai系数法[24],将主题i和j的共现强度wij定义为:
(4)
其中Oij代表主题i和j共同出现的文献篇数,Oi.代表主题i与其他所有主题共现篇数的加总求和,O.j的定义同理。共现强度反映了主题间语义关系的紧密程度,取值范围为0~1之间,取值越大,语义连接越紧密,否则相反;当取值为0时,代表主题无语义关联。以主题为节点,共现强度为连接权重,构建形成主题共现网络。
2.3.2 主题共现网络预测
1)加权链路预测指标
网络环境下,节点之间形成连接的可能性可以通过一系列相似性指标加以估计预测,即相似性越高,形成链路的几率越高。目前,常见的链路预测指标方法大多针对非加权网络,只有少数学者基于加权网络对加权网络链路预测问题开展探讨。借鉴吕琳媛等的研究[25],采用18个基于加权网络的链路预测相似性指标,用于链路预测。整体上,依据指标原理,主要分为4大类,即基于局部信息、路径、随机游走及其他类型,如表1所示。局部信息主要指共同邻居,加权网络下体现为与共同邻居链路的加权和,共同邻居多的节点间容易形成连接是预测链路的基本出发点;基于路径的指标考虑了三阶路径(LP指标)或者更高阶路径(Katz指标),弥补了基本共同邻居(相当于二阶路径)指标信息有限的不足;基于随机游走的指标主要利用随机游走过程工具考察节点间的距离,通常认为路径步数越短,节点越相似;另外,MFI指数以矩阵森林理论(Matrix-Forest Theory)为基础构建,自洽转移相似性指数Tr基于节点间相似性可传递假设来刻画节点的间接相似程度。上述不同类型相似性指标具有互补优势,将其加入预测模型更有利于适用复杂网络环境并提高预测精度。

表1 加权链路预测指标
2)链路预测模型
采用链路预测指标,构建预测主题共现的BP神经网络。BP神经网络通过信息前向信息传播、梯度后向传播的方式训练神经网络节点连接权重,能够拟合逼近任意非线性函数,具有极强大的数据学习能力,是拟合主题间链路相似性指标与主题共现强度之间规律的有效工具。具体地,搭建三层神经网络结构如下:以表1中主题相似性指标为输入,形成18个节点构成的输入层;输出层只包含1个节点,代表主题共现网络关系;依据以往经验及相关文献确定隐藏层节点数量,设定包含36个隐节点。同时,设定隐藏层激活函数为ReLU,输出层激活函数为Sigmod。
针对输出节点的二元分类取值,设定基于交叉熵的损失函数为:
(5)
其中yi表示第i个样本的实际取值(1代表存在主题共现关系,否则为0),表示第i个样本的模型估计值。泛化能力是模型设定与选取的参考依据,这里主要考察指标AUC,其量化了ROC曲线的分类能力,取值越大分类效果越好,输出概率越合理。另外,AUC表示随机抽取一个正样本和一个负样本,分类器正确给出正样本的score高于负样本的概率。因此,参考Lü L等[26]的计算方法,采用拟合模型,针对随机选取的存在链接关系样本与不存在链接关系样本分别进行预测,则AUC取值为:
(6)
其中n表示总共随机抽样比较次数,n1表示存在链接关系样本取值大于不存在链接关系样本的次数,n2为两者数量相同次数。
3)数据处理
出于机器学习算法需要,按照时间先后顺序,将学科文献数据依次划分为3个子集。采用式(4),针对不同数据子集,分别构建主题共现网络,即N1、N2、N3。3个网络具有相同的主题节点,但拥有不同连接权重。网络N1为训练集、N2为测试集、N3为待预测网络。
作为神经网络输入节点,加权链路相似性指标具有完全不同量纲,需要对数据进行归一化处理。采用极大极小法,对18个输入指标进行归一化,得到0~1区间的统一量纲数据。另外,每个样本的输出为二元分类标签,主题间存在共现关系(共现强度不为0)取值1,否则取值0。
不平衡数据是影响模型分类性能的不可忽视因素。主题共现网络是典型稀疏网络,存在链接的正例样本只占很小比例,分类算法过多关注于负例样本,导致链路预测分类性能下降。因此,采用基于随机过采样的SMOTE算法修正不平衡数据,通过对少数正例样本的分析,合成新正例样本加入数据集,以实现正负样本的基本平衡。
采用上述方法,以数据集N1为训练集,数据集N2为测试集,经过多轮训练及测试,直至得到满意的预测模型。
2.3.3 链路预测与主题潜在影响力预测
将训练完成的神经网络模型用于链路预测,预测主题网络N3的潜在主题共现机会。以主题网络N3中不存在共现关系的主题对为预测对象,估计这些主题对在未来构建新关系的可能性。预测模型输出节点表示二元关系形成概率,因此将预测值大于0.5的主题对判定为潜在新关系(网络边)。基于此,将新的共现关系加入主题网络N3,借鉴黄璐等[17]的研究,预测网络边的权重计算公式为:
(7)
其中Si为预测概率值,max(S)为预测得分最大值,max(W)为网络中存在边的权重最大值。预测网络边与原有网络合并形成主题未来网络N′3,用于主题影响力预测。
主题未来网络是在当前数据基础上对主题未来趋势的最新预测,而主题节点所处的中心位置及嵌入环境状态也反映了其潜在发展趋势。因此,通过挖掘分析预测网络可以发现主题个体的未来可能。网络理论认为节点的影响力可以通过其嵌入环境(如邻居节点)加以刻画,即认为如果某节点以高影响力节点为邻居,则其亦应拥有较高影响力。PageRank算法是度量这种网络节点影响力的经典算法,能够定量刻画主题共现网络节点的相对影响力。基于主题预测网络N′3,采用加权的PageRank算法,主题i潜在影响力的预测值PRi计算公式如下:
(8)
其中节点j为i的邻居Γ(i),Wij为i与j连边的网络权重,Dj表示j的度中心性,α为取值0~1区间的阻尼系数,这里设定为常见的0.85。
2.4 新兴主题综合识别
借鉴相关研究可知,未来状态趋势通常成为判定新兴主题的关键依据,对主题动态的预测把握是捕捉新兴特征的基本思路。高速成长通常是主题新兴阶段的外在呈现,这种特征可以通过未来状态与当前状态的动态变化加以描述和刻画。基于主题热度和影响力的预测值,构建其增长率指标,以反映动态成长性特征。
1)主题热度增长率定义为:
(9)
2)主题影响力增长率定义为:
(10)
其中PR(N3)和PR(N′3)分别为基于当前网络N3和未来预测网络N′3计算得到的主题影响力,反映指标PR的预测值与当前值,ΔPR反映了指标预测值相对当前值的增长率,是对增长趋势的定量预测。
热度增长率是新兴主题的数量层面体现,影响力增长率是新兴主题的结构层面体现,综合两者状态有助于更全面把握新兴主题本质规律。基于上述两方面指标,构建二维识别空间,综合判定主题新兴性,即两个指标水平越高,则认为主题新兴趋势越强烈。
3 实证分析
3.1 数据源及预处理
研究选取情报学学科为实证领域,相关数据包括两部分:科学文献元数据和Altmetrics指标。首先,文献元数据来源于WoS数据库,通过选定检索策略,获得查询结果,并从中抽取实证所需元数据,主要包括DOI号(DI)、关键词(DE)、标题(TI)、摘要(AB)、期刊(SO)、年份(PY)。借鉴相关文献,筛选出情报学代表性期刊,包括《Journal of the Association for Information Science and Technology》《Information Processing & Management》《Scientometrics》《Information & Management》《Journal of Informetrics》,这些期刊是本学科高影响力代表且议题新颖活跃,是探测学科新兴主题的最佳载体。具体地,以情报学领域代表期刊为线索,检索得到跨度8年(2013—2020)且文献类型为Article的记录共计6 326条,查询时间为2021年6月。
其次,Altmetrics指标来源于网站Altmetric.com。该网站成立于2011年,具有数据免费、开源、覆盖率高、指标丰富等优点,是目前主流的Altmetrics服务提供商,尤其提供面向科研用途的公开查询API,能够满足本文数据需要。Altmetrics指标具有不同类型,本文从中选取了总指标Altmetric Mention Score,其为多种不同来源及社交媒介指标的加权和,能够综合地反映文献在社交媒介关注程度。DOI是科学文献的唯一标识符,因此以文献DOI号为线索,一对一地查询获得每篇文献的Altmetrics指标。具体地,采用Python程序查询文献的Altmetrics指标,删去指标缺失的文献,最终获得用于实证的3 208条记录,其基本统计特征如表2所示。
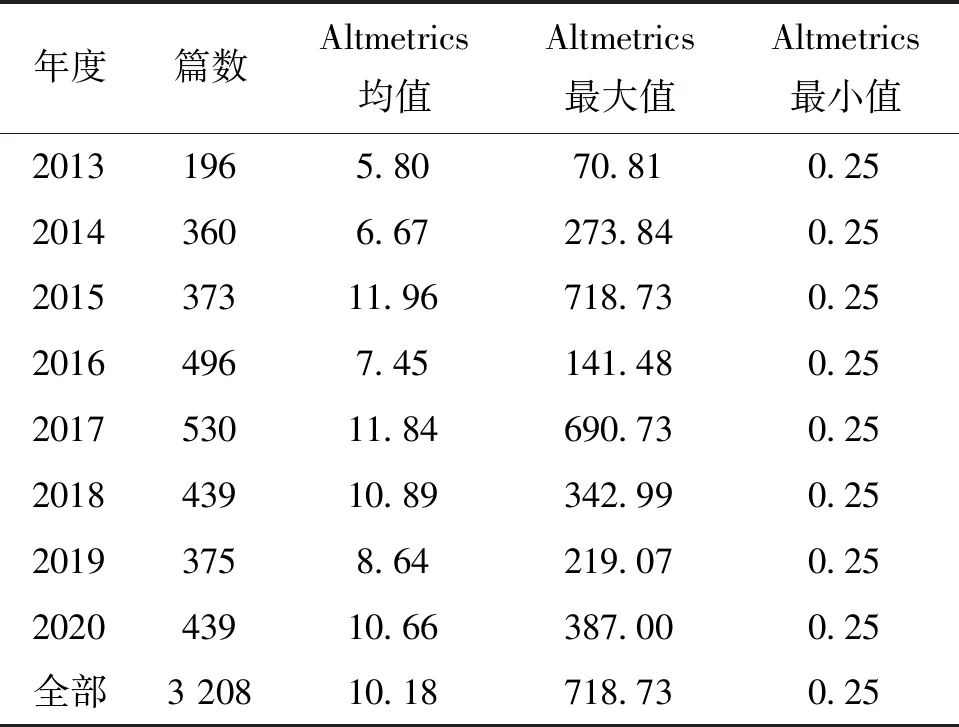
表2 采集文献基本统计特征
主题抽取与共现网络构建是开展实证分析的基础。首先,从文献元数据的DE字段,提取主题词,作为备选主题,这些主题词由文献作者给出,能够精准地表达文献核心内容。为了进一步缩小目标搜索范围,过滤掉探测意义不大的极低频主题,根据样本分布特征,选取出现频率前250个主题作为备选主题集。其次,以主题为节点,共现关系为边,共现强度为权重,构建主题共现网络。分别以2013—2015年、2016—2017年、2018—2020年数据为子集,构建主题共现网络N1、N2、N3。
3.2 指标计算及模型设定
依据式(1)~(3),计算主题热度指标P、A和H,各个指标的年度均值如表3所示。从时间维度看,主题热度H均值随着时间逐步增高,直至2018年达到最大值,这种数据膨胀很大程度上是近年社交媒介平台用户规模快速扩张导致的,比如作为构成部分的指标A采用替代计量指标计算得到,亦呈现同样数据特征。因此,应用于时间序列预测模型,本文将指标H归一化处理,采用极大极小法得到[0,1]区间的数值分布,以保证时间维度可比性。
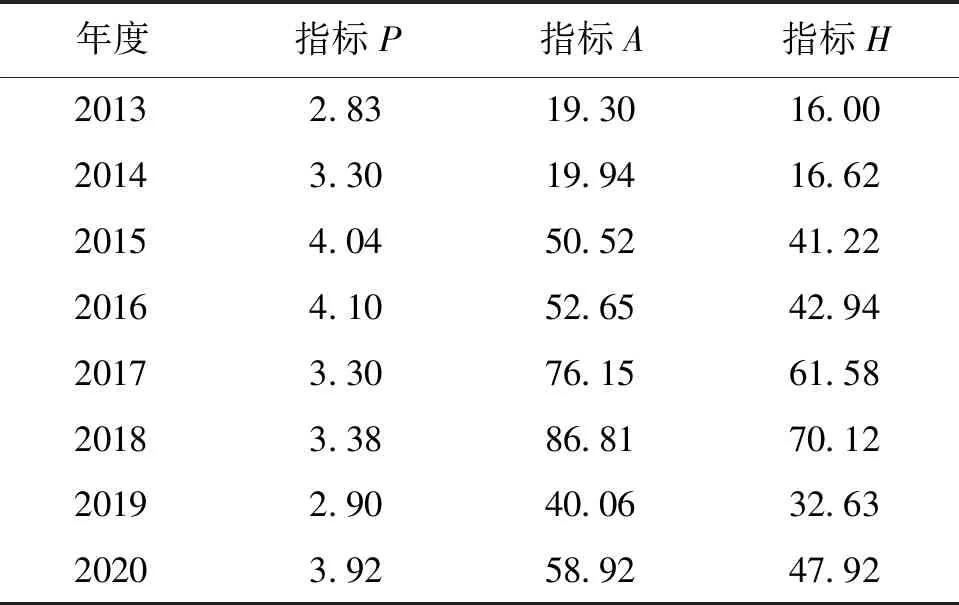
表3 主题热度指标年度均值
针对不同阶段主题共现网络,分别计算相应的相似性指标,其基本统计特征如表4所示。整体上,数据分布特征差异较大,除simRank指标之外,其余指标取值都偏小,比如基于局部信息的指标几乎都集中于0~0.1之间。因此,将指标导入模型之前,进行了归一化处理。
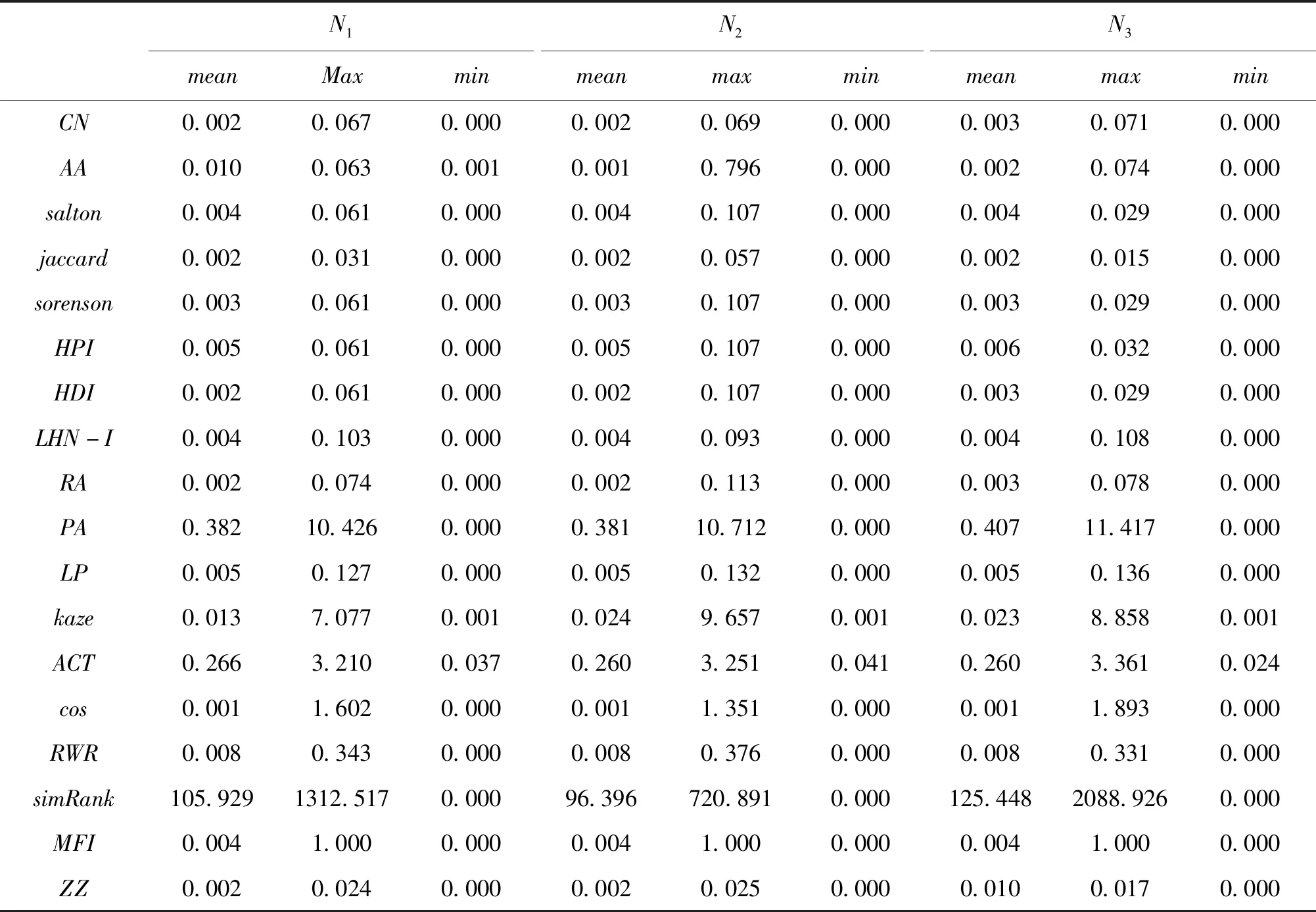
表4 加权链路相似性指标基本数据特征
使用Python语言,编程实现面向主题热度预测的时间序列LSTM模型。具体地,基于主题热度指标H,以2013—2019年数据为输入,以2020年数据为输出,调用Keras模块中的LSTM函数,构建面向时间序列的神经网络模型。选取均方误差MSE为误差函数,使用随机梯度下降算法SGD,进行多轮模型训练,结果如图3所示。经过大约10轮训练之后,可以看到训练误差和测试误差都稳定地下降到很小数值,说明模型拟合参数达到收敛状态,完成主题热度预测模型训练任务。
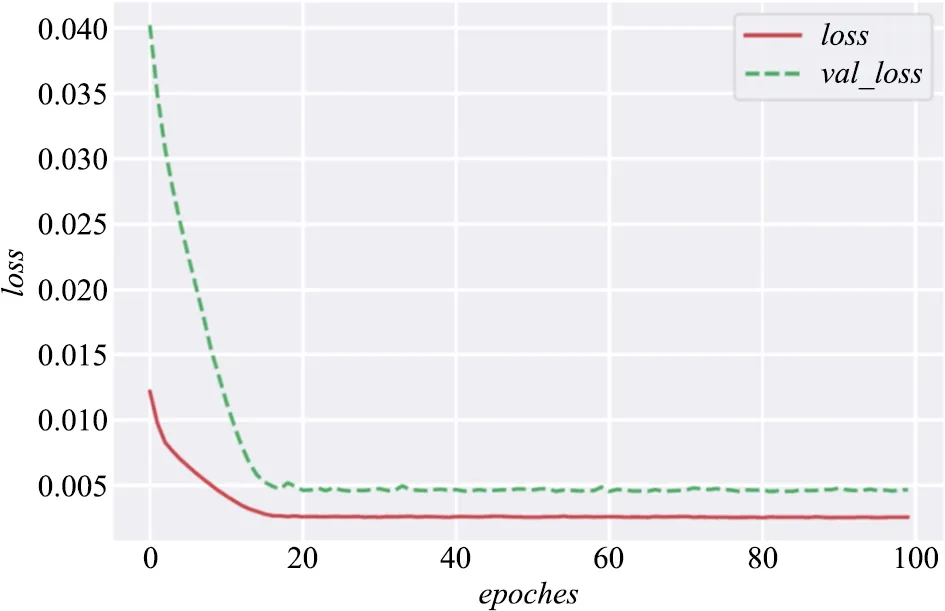
图3 主题热度预测模型训练
表5给出了模型在测试集上的预测表现。ARIMA模型是常见的时间序列分析工具,这里用作基准模型作为参照对比。通过比较可以发现,不论是平均绝对误差MAE还是均方误差MSE,本文采用的LSTM模型都明显优于ARIMA模型,LSTM模型适用于主题热度指标序列的预测任务。
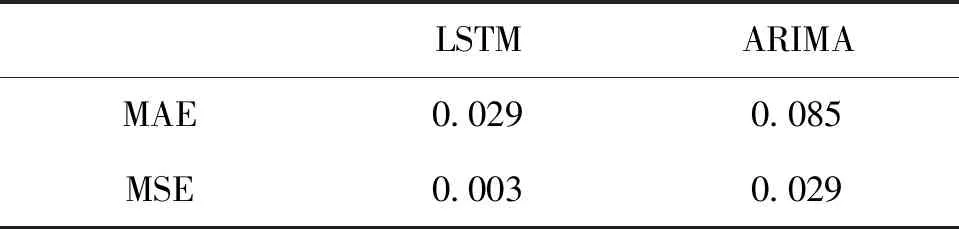
表5 模型性能比较
类似地,使用Keras模块实现主链路预测模型。具体地,由主题网络N1和N2得到训练集和测试集,采用随机梯度下降算法SGD,以二元交叉熵BinaryCrossentropy为损失函数,进行多轮训练,结果如图4所示。大约经过150轮训练之后,训练误差和测试误差都呈现稳定收敛状态,数值上小于0.05,反映模型拟合良好;而AUC指标在训练集合测试集上非常接近,都达到0.98,反映了满意的预测性能。
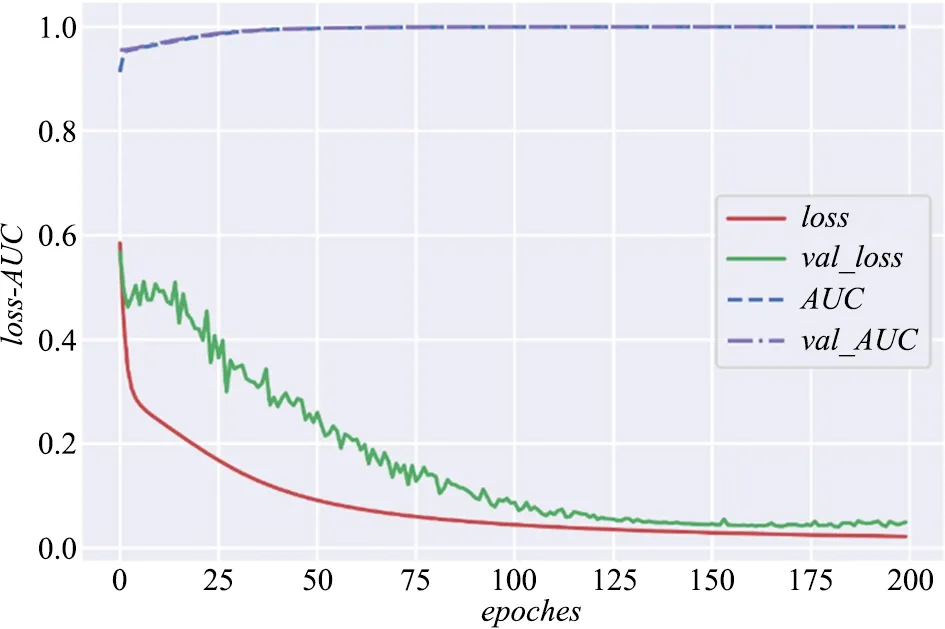
图4 主题影响力预测模型训练
为了检验指标的选取合理性,分别使用4种类型指标(基于局部信息、基于路径、基于随机游走及其他)进行链路预测模型训练,与本文基于全部指标的训练结果进行比较,如表6所示。可见,采用全部指标的链路预测性能基本都处于较明显优势,只有在准确率方面比基于随机游走指标的结果略低。总体上,包含全部18个指标的链路预测模型能够取得较为满意预测性能。
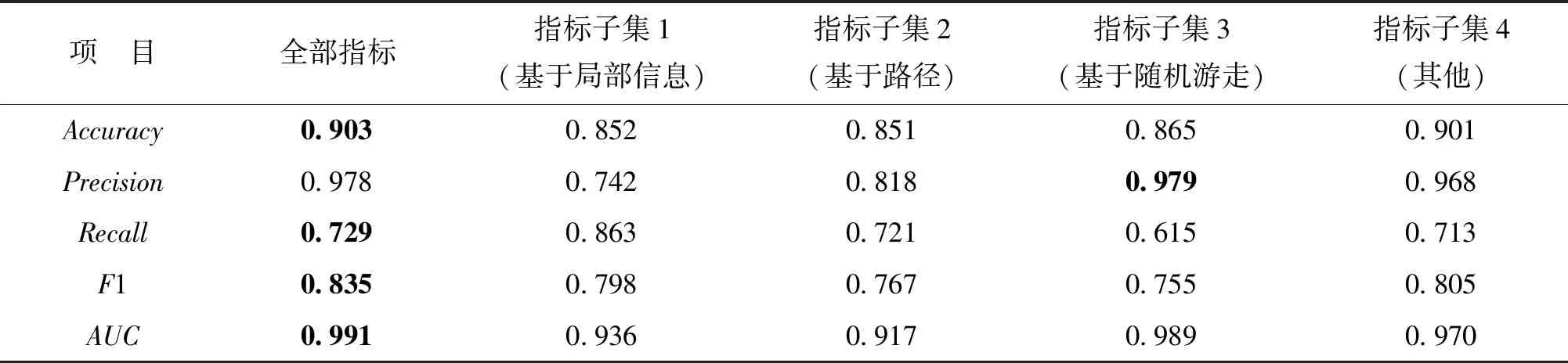
表6 不同指标的链路预测性能比较
3.3 新兴主题识别
采用训练完成的神经网络模型,预测主题未来状态,包括主题热度与影响力。将2014—2020年主题热度指标输入热度预测模型,得到主题的热度预测值H2021;使用链路预测模型,预测主题网络N3的潜在链接,得到主题未来网络N′3,并计算得到主题节点的影响力预测值PR′。为了进一步展示主题动态趋势,分别计算了两个指标预测值相对于当前值的增长率。
表7给出了按照上述4个指标降序排列的主题。通过对比,可以显然发现两个基于增长率的指标对于新兴主题表现出更强的敏感性。对于主题热度与影响力指标,排名前列的大都是热门主题,既包含了持续创新且热度不断的成熟主题(bibliometrics、citation analysis、patent等),也包含了近年兴起受到普遍关注的新兴主题(altmetrics、scopus、social media等)。对于基于增长率的指标,排名前列主题不但包含了一般新兴主题,更重要的是筛选出了更多高价值主题——出现时间相对短暂但创新潜力巨大的新兴主题,比如COVID-19、blockchain、convolutional neural network、Internet of things,这些主题未出现在表2的主题热度与影响力排行榜之中,但都进入主题热度增长率和影响力增长率排行榜,甚至COVID-19和blockchain的热度增长率预测值排名分别达到了第1和第3。
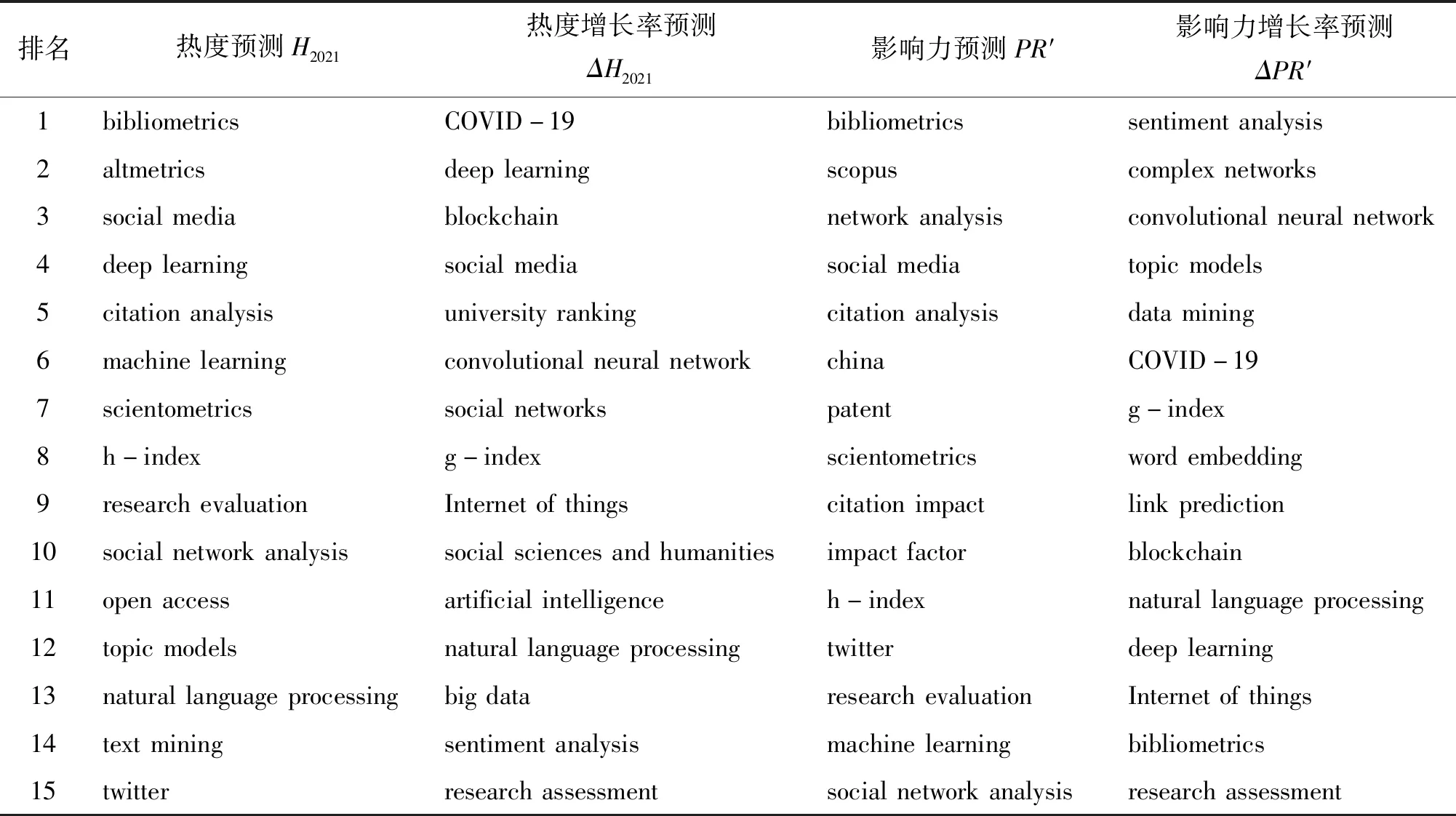
表7 按不同指标预测值降序排序的主题词(前15名)
总之,可以看出基于增长率的指标(热度增长率和影响力增长率)比规模性指标(热度和影响力)更适用于新兴主题识别任务,前者能够更早地发现新兴主题的增长潜力,这些主题虽然当前关注程度相对较小,但后续发展动能强劲,这种前瞻优势对于科技决策者具有重要参考价值。
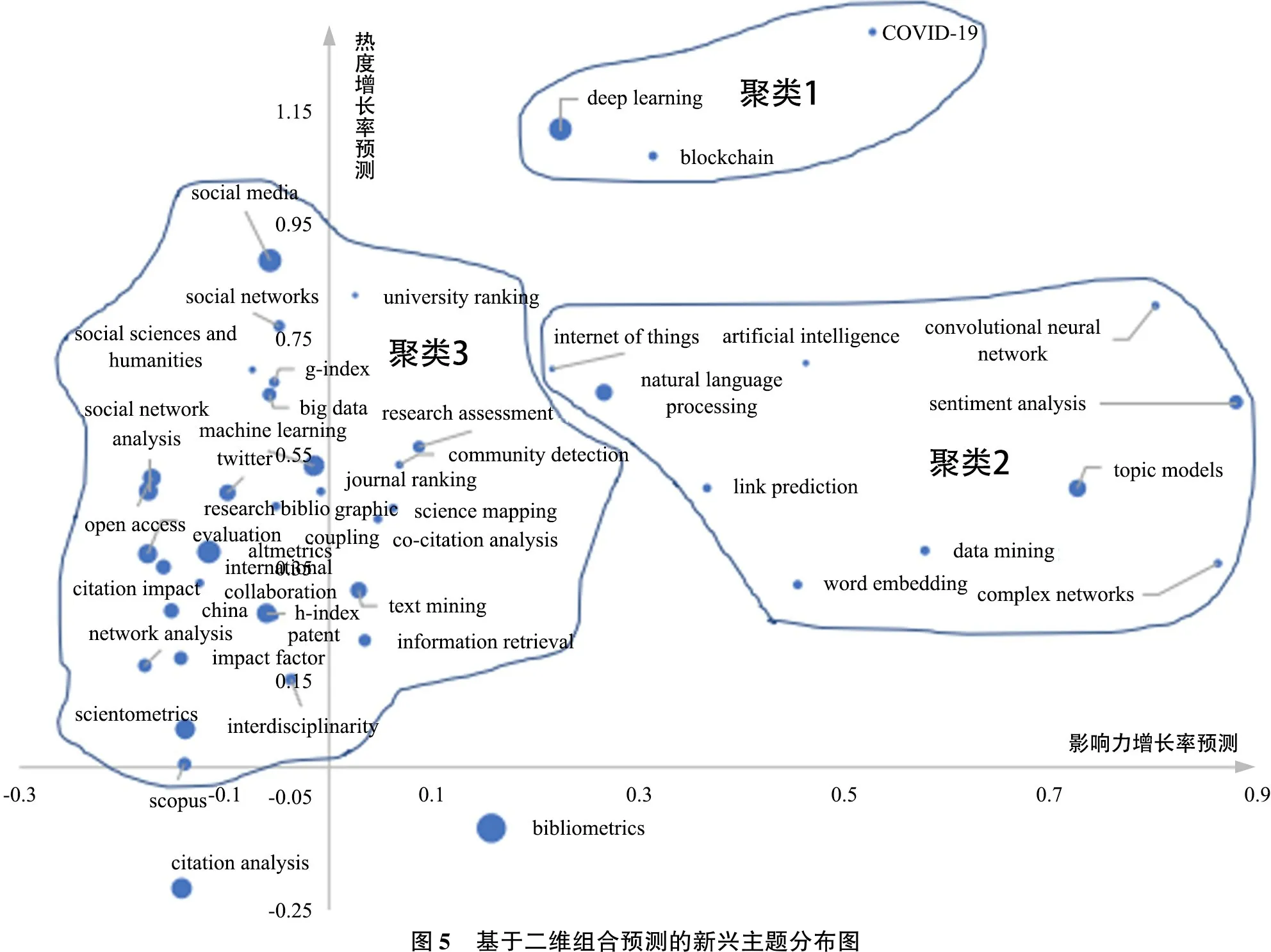
为了形成对新兴主题的综合研判,以主题热度增长率预测值为纵轴,影响力增长率预测值为横轴,绘制主题散点图,如图5所示。其中,散点大小正比于指标P,反映主题在文献的呈现热度。二维识别空间中,除了成熟主题bibliometrics和citation analysis之外,其他主题位于横轴之上,具有正向的热度增长率预测值,反映情报学领域较高的活跃性预期。近半主题位于纵轴右侧,具有正向的影响力增长预测值,反映了这些主题持续增长的影响力预期,它们将不断与本领域知识元素相互融合嵌入并通过网络连接形成增长扩散的影响力。可以发现,第1象限主题具有“两高一低”特征,即出现频率低(散点面积偏小)和两指标(热度增长率预测和影响力增长率预测)取值高,更符合新兴主题早期阶段属性,是探测高潜力新兴主题的重点观察区域。
采用聚类分析,可以得到3个相对聚集的主题群落。聚类1位于第1象限上方,属于关注热度高增长型,具有出现时间较短但关注程度增长迅猛的特点,是发现新兴主题的高概率区域;聚类2位于第1象限右下方,属于影响力高增长型,具有影响力增长迅速特点,意味着这些主题日益融入领域知识网络,与越多的主题形成语义连接,并通过网络嵌入形成更大的主题影响力,同样也是新兴主题的重要探测区域;聚类3主要位于第2象限,呈现关注热度高且增长快,但知识网络影响力偏低甚至下降的特征,主要以热门主题为主,新兴主题相对偏少。
聚类1包含3个主题,COVID-19、blockchain、deep learning都是具有重要价值的领域新兴主题。为了揭示主题的爆发性增长态势,表8给出了不同年度的主题相关文献数量。①主题COVID-19出现时间最短暂,却被预测出最强烈的增长态势,情报学界对2019年暴发的新冠肺炎疫情(COVID-19)给出了积极的学术反馈,比如2020年只有7篇相关文献,而2021年却猛增至27篇,意味着将来极可能成为领域重点关注的“明星”主题;②主题blockchain近两年开始受到情报学领域重视,作为分布式共享账本和数据库,区块链(blockchain)具有去中心化、不可篡改、全程留痕、可以追溯等独特优势,相关文献从2020年的6篇增至2021年的25篇,是其在情报组织与数据管理等方面巨大应用潜力的集中体现;③主题deep learning从2018年开始形成稳定的快速增长路径,相关文献在2020年增至47篇,反映了随着深度学习理论与技术的不断成熟,其多元应用不断扩展深化,同样也成为情报学领域的关注热点,日益成为情报体系的方法要素,推动情报方法的智能化发展。总之,本文基于机器学习方法的预测程序准确地揭示了上述主题的爆发式增长,对2021年的热度预测与现实吻合程度高,体现了该方法对于新兴主题动态特征的敏感捕捉能力。
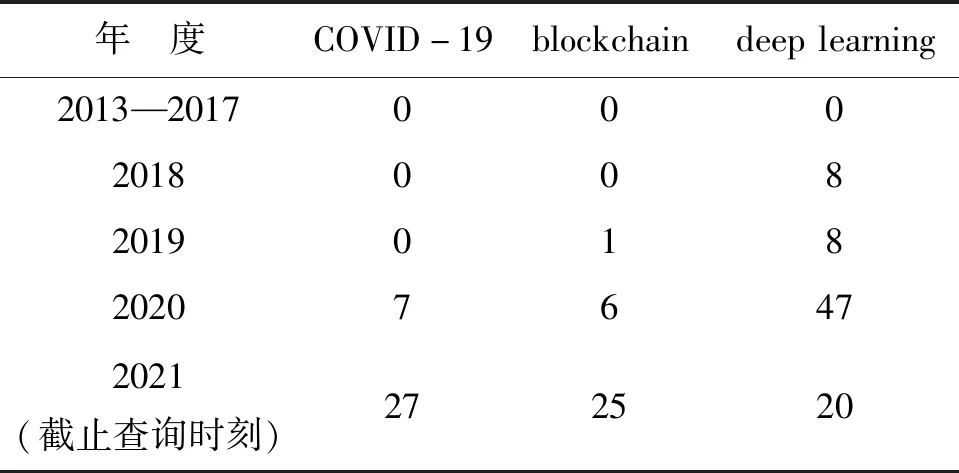
表8 聚类1主题的年度文献分布
聚类2包含10个主题,基本上都涉及信息技术方法,其共同表现出影响力高增长特征。通过综合分析,进一步分为两个子群落,即以convolutional neural network、artificial intelligence、internet of things、link prediction为代表的新兴技术,与以topic models、complex networks、sentiment analysis为代表的常见领域热门技术。主题热度方面,前者虽然出现时间相对更短,但快速吸引情报领域关注,整体拥有更高的热度增长潜力。主题影响力方面,除convolutional neural network之外,大部分新兴技术都比传统热门技术拥有相对较低的影响力增长性预期,此现象反映了两者技术扩散能力的差异,领域对于传统热门技术的接受程度更高,更利于传统技术主题与更多不同领域及方向知识要素建立并形成语义关联,而新兴技术更多地处于技术导入应用初期,还未形成明显的知识网络影响力优势。
聚类3基本为情报学领域核心热门主题,数量众多,成熟度较高。相对于典型成熟主题(如citation impact、h-index、information retrieval),以twitter、altmetrics、social networks为代表主题表现出一定新兴特征;但是,这些主题不如聚类1主题的新颖性与热度增长性高,也不如聚类2中新兴主题的影响力增长性显著。显然,该领域主题新兴特征偏低,筛选出的3个新兴主题虽然仍为情报学领域值得重点关注的未来方向,但其已呈现出相对平稳倾向,不再表现为爆发性增长态势,而是开始趋于稳定发展模式。
通过二维识别空间的综合性聚类分析,识别出3类不同特征的新兴主题:一是高新颖、高增长潜力的新兴主题群,包括COVID-19、blockchain、deep learning,位于识别空间上方位置(聚类1),以高热度增长率预期为基本判别特征,成为学科关注“新星”;二是以convolutional neural network等为代表的新兴主题群,内容上聚焦于信息技术方法,位于识别空间右下位置(聚类2),以高影响力增长预期为基本判别特征;三是以altmetrics等为代表的预期稳定型新兴主题群,位于识别空间左侧位置(聚类3),呈现关注热度和影响力都趋于相对稳定的发展模式。可以看出,构建的预测性指标能够有效识别新兴主题成长性,而且对于不同类型新兴主题形成良好区分能力。
表9给出了采用不同模型方法的识别结果比较,识别出的主题按照成长趋势程度降序排列。①直接预测主题指标趋势是最常见的分析方法,ARIMA模型和LSTM模型给出的新兴主题各有侧重,不过ARIMA没有识别出以blockchain、deep learning为代表的最新议题,总体上看LSTM模型的识别结果更加精准;②网络结构指标与PageRank算法是网络关系嵌入环境的常见分析方法,分别采用两个度量指标(度中心性Degree和PageRank指标)进行新兴主题成长识别,与本文链路预测+PageRank方法进行比较。显然,基于度中心性的结果相对较差,虽然也能将以word embedding为代表的多数新兴主题筛选发现,但是对于短期萌发的主题敏感度不够,尤其没有识别出近两年发展的主题COVID-19和blockchain。可以看出,单纯基于PageRank方法与链路预测+PageRank方法相比,识别召回的新兴主题范畴基本相差不大,但是对于短期新兴主题的敏感性存在差异,以COVID-19、blockchain为代表的萌芽主题在后者采用链路预测的识别结果中被赋予了更高的优先级,更利于发现时间短、频次低、潜力大的新兴主题,显然更吻合新兴主题的识别初衷。此种结果也反映了链路预测在趋势前瞻方面的优势,非常适应于发现高成长价值新兴主题;③本文采用了指标时序和影响力相结合的二维识别方法,虽然与基于影响力的一维识别方法(链路预测+PageRank)相比结果基本相同,但是通过二维识别空间能够对指标进行类型细分,比如识别出“学科‘新星’”与“学科方法工具”两类新兴主题,它们存在差异化的增长动力与新兴特征。可见,本文方法具有更精细的主题成长性识别能力,这种敏锐分析能力有助于加深学科新兴主题的把握洞见。
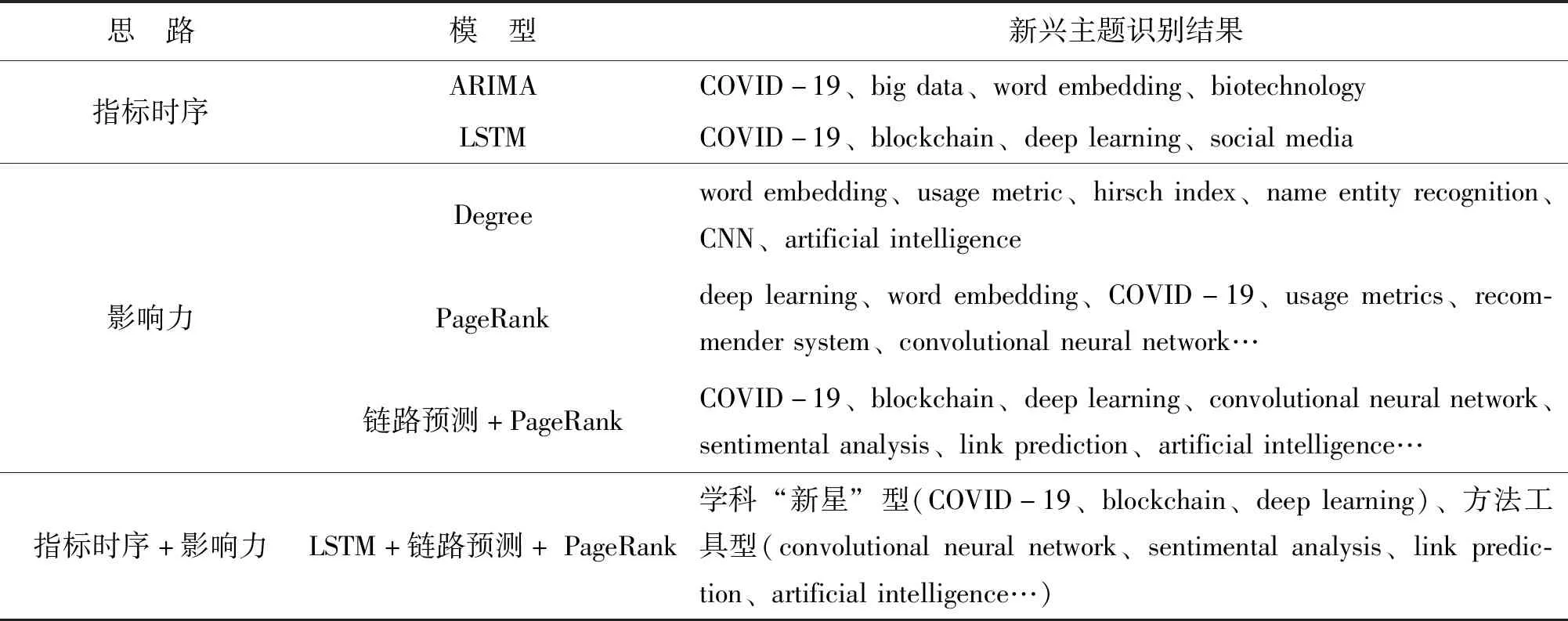
表9 不同模型识别结果比较
4 结 论
把握未来成长潜力是识别学科新兴主题的关键。本文从热度和影响力两个方面,对学科新兴主题开展组合预测与综合研判。热度方面,设计融合文献计量和替代计量的主题热度指标,并构建基于LSTM的热度时间序列预测模型,旨在预测主题未来热度增长性;影响力方面,基于主题共现网络,采用PageRank算法刻画主题节点的学科知识网络影响力,并使用加权网络链路预测指标,构建主题影响力预测模型,旨在预测主题未来影响力增长性。以热度和影响力的增长率为未来成长性的刻画指标,构建二维识别空间,形成对新兴主题高成长特征的综合研判,并通过聚类分析揭示新兴主题的不同类型特征。
针对情报学学科的实证研究充分检验了方法的有效性。实证结果发现,反映成长性的预测指标能够有效捕捉新兴特征,例如高热度增长率预期基本成为判定新兴主题的必要条件,而高影响力增长预期则成为识别“方法类型”新兴主题的重要条件。进一步通过二维识别空间的聚类分析,可以对新兴主题形成更加细致区分,主要包括3种子类型:以COVID-19为代表的热度高增长预期新兴主题群、以convolutional neural network为代表的影响力高增长预期新兴主题群、以altmetrics为代表的预期稳定型新兴主题群。不同类型新兴主题具有特定的内在创新特征和演化趋势,细粒度的类型区分为深入理解把握学科趋势提供了有效洞见。总之,分析结果说明,本文构造的成长性预测性指标对新兴主题具有良好的识别能力,不但能够将新兴主题从包含各种干扰信号的海量数据中筛选出来,而且能够通过聚类分析分辨出新兴主题的不同子类型特征,反映了基于成长性预测性指标的识别方法对于新兴主题具有良好适用性。
不同于基于客观证据的主观性预测,本文借助机器学习算法,构建预测模型,直接对主题的发展趋势开展客观预测,进而形成基于新兴特征预期的识别方法。该方法聚焦于主题未来预期,充分借助基于机器学习算法的大数据预测能力,更适应于知识快速迭代并复杂演化的学科场景,有助于为决策者提供更具前瞻性的科技战略决策支持。随着机器学习算法的不断进化和科技大数据的日益丰富细化,数据驱动的科技预测能力不断提升,前瞻性学科情报探测及趋势分析必然成为重要发展方向。
