一个基于信念网络的微博推荐模型
2022-08-31赵凯华徐建民鲍彩倩
赵凯华徐建民鲍彩倩
(河北大学 网络空间安全与计算机学院,河北 保定 071002)
随着互联网技术的蓬勃发展,以微博为代表的在线社交网络平台已经成为人们获取信息、进行日常交流的重要渠道[1].截至2021年9月,微博月活跃用户达到5.73亿[2],庞大的用户群体导致微博信息爆炸性增长,信息过载和知识缺乏问题越发突出,用户获取感兴趣微博难度增大,因此向用户推荐高质量信息,满足用户的信息需求就显得尤为重要[3-4].
近年来,微博个性化推荐多数依据用户发布的微博或标签来实现,Wang等[5]通过用户发布微博获取用户标签,构建用户兴趣模型,并向用户进行微博推荐.马慧芳等[6]利用用户发布微博构建超图,通过随机游走获得一定关键词来扩充标签,根据标签的概率相关性更新用户-标签矩阵构建用户兴趣模型,并应用于微博推荐中.Sun等[7]使用实体抽取方法,从用户的发布微博中抽取部分能够代表用户个性化偏好的兴趣关键词来实现推荐.王战平等[8]对用户兴趣标签进行语义映射和相关性挖掘,进而实现微博推荐.上述方法可以在一定程度上提高微博推荐效果,但微博作为一种短文本[9],语言灵活、不规范,所含有效信息较少,且微博中用户标签偏少[10].因此,仅利用用户发布微博或标签进行推荐,易出现因数据稀疏而导致推荐效果不理想的情况.考虑到组合不同证据提高系统性能在信息检索系统中已经得到证明[11]以及信息检索和个性化推荐固有的相似性,可以结合与用户相关的证据信息来缓解数据稀疏问题,改善推荐效果.在微博推荐中,一些研究者将用户关系或微博特征等因素作为证据实现推荐,以有效提高推荐效果.Li等[12]根据用户标签获得用户兴趣,结合地域和年龄等因素对相似用户进行聚类,将近邻用户发布的微博推荐给目标用户.Zhang等[13]根据用户历史浏览话题数据得到的用户兴趣向量,对用户进行聚类,将微博话题与核心用户的兴趣相比来筛选微博话题,继而推荐给用户.Kim 等[14]提出一种概率生成模型,依据用户文本信息和用户关系对待推荐微博进行排序,将Top-k条结果推荐给用户.刘宇东等[15]通过用户发布或转发的微博来提取用户兴趣,使用Word2vec计算得到用户与微博文本的相似度,结合微博特征对微博进行排序来实现对用户的微博推荐.陈杰等[16]提出基于用户兴趣和社交网络的微博推荐方法,将待推荐微博进行聚类分组,根据用户兴趣为用户选择最匹配的微博组,进而利用用户与组内的微博发布者间的信任度和相似度来实现推荐.韩康康等[17]利用用户间的信任关系来改进基于内容的微博推荐方法,并在真实数据集上验证了该方法可以改善推荐效果.上述方法多采用线性组合的形式补充证据信息向用户进行推荐,但仍存在推荐过程不够直观、组合证据方式单一、可扩展性不理想的局限性.
信念网络(又称贝叶斯网络)以贝叶斯定理为理论基础,通过图形网络直观地揭示变量间的概率关系,可以结合不同的证据信息来提高系统性能[18].徐建民[19]使用信念网络来应对查询语句简短带来的不确定性问题,并组合同义词证据来提高检索性能.Pan等[20]将信念网络应用到电子商务推荐中,使用贝叶斯网络模型来描述协同过滤算法,根据用户的历史行为信息及项目相关性分别构建用户相似度模型和项目相似度模型,结合2种模型预测用户对项目的偏好,并结合用户的反馈信息更新用户对项目的偏好,提高推荐质量.Huang等[21]提出一种应用于推荐系统的概率推理模型,使用结合专家信息的信念网络模型来推荐项目,并在GPS和MovieLens数据集上验证了加入证据信息可以提高推荐预测.通过分析上述研究发现,在个性化服务中,可以将文档或用户的已知信息数据看作信念网络的先验知识,将文档或用户的潜在特征作为信念网络中待求解的后验概率,利用概率推理来完成个性化服务的概率计算.信念网络与个性化服务间的内在思想联系,证明了将信念网络应用到个性化服务中的可行性.然而,目前尚未有将其应用于微博推荐的研究.
本文将信念网络引入到微博推荐中,构建一个基本推荐模型,该模型具有便于组合证据的优点,以此为基础,依据用户的交互微博(界定为用户点赞、转发和评论的微博)扩展基本模型.本文的主要贡献如下:1)基于贝叶斯条件概率计算微博与用户的相关度,结合微博推荐相关知识,构建基本信念网络推荐模型(basic belief network recommendation model,BBNR).该模型作为一个通用的推荐框架,通过对推荐过程中的概率函数进行合理定义,可以将不同模型(如布尔模型、概率模型和向量空间模型)的特点借助该框架表示出来.同时基本模型框架灵活,可以方便地组合证据信息来解决数据稀疏问题,提高推荐效果.2)利用基本模型方便组合不同证据的特点,将交互微博作为证据,构建融合用户交互微博的扩展模型(extended model with user interaction microblogs,EUIM),在缓解微博数据缺失问题的同时,提升推荐效果.
1 基本信念网络推荐模型
1.1 相关概念
设目标用户集合为U={uj|j=1,2,…,n},其中每个用户都可以通过一组能够体现用户兴趣的特征词来表示,称为兴趣特征词.所有用户的兴趣特征词集合为C={cl|l=1,2,…,t},t为所有兴趣特征词的数目,cl表示第l个兴趣特征词.
1)兴趣特征词cl称为基本概念,与一个二值随机变量(亦用cl表示)相关.
2)c为C的一个子集,称为概念.由于用户可以由一组与其相关的兴趣特征词表示,因此用户uj可以看作是C中的一个概念.同样,微博b经过分词,得到部分关键词,亦可用相关的兴趣特征词来表示,因此微博b也可以看作是C中的一个概念.
3)基本概念集合C构成本文所考虑的样本空间,称为概念空间.

1.2 拓扑结构
借鉴文献[22],基本信念网络推荐模型(BBNR)的拓扑结构如图1所示.
1)模型包括微博节点b、兴趣特征词节点cl和用户节点uj.节点b、cl和uj均与一个二值随机变量(分别用b、cl和uj表示)相关.当cl为1时,表示cl包含在概念c中;当b或uj为1时,表示b或uj为概念空间的一个概念.
2)若兴趣特征词cl属于组成微博b的一个关键词,则有一条弧从节点cl指向节点b.若兴趣特征词cl用来描述用户uj的兴趣特征,则有一条弧从节点cl指向节点uj.
3)推荐模型假设兴趣特征词节点之间相互独立,用户节点之间相互独立,因此同一层节点之间没有弧.
1.3 概率推导
微博推荐就是将符合用户兴趣取向的微博推荐给用户,其实质是用户兴趣与微博相关性匹配问题.由于用户与微博均可表示为概念空间C的一个概念,因此可以将用户兴趣与微博的匹配过程看作为概念匹配过程.而概念空间中的任一概念d对概念空间C的匹配程度,即覆盖程度通过式(1)可得


2 融合用户交互微博的扩展模型
在微博平台中,用户除发布微博外,还可以对平台中感兴趣的微博进行转发、评论、点赞的交互操作,这些交互操作产生的信息数据丰富,能够在一定程度上反映用户的兴趣取向,对于提高推荐性能具有重要意义[23-24].本文将用户uj曾经交互操作过的微博称为uj的交互微博,将交互微博作为证据整合到基本推荐模型中,构建融合用户交互微博的扩展模型(EUIM).扩展模型同样包括拓扑结构和概率推导2部分.
2.1 拓扑结构
融合用户交互微博的扩展模型(EUIM)的拓扑结构如图2所示.
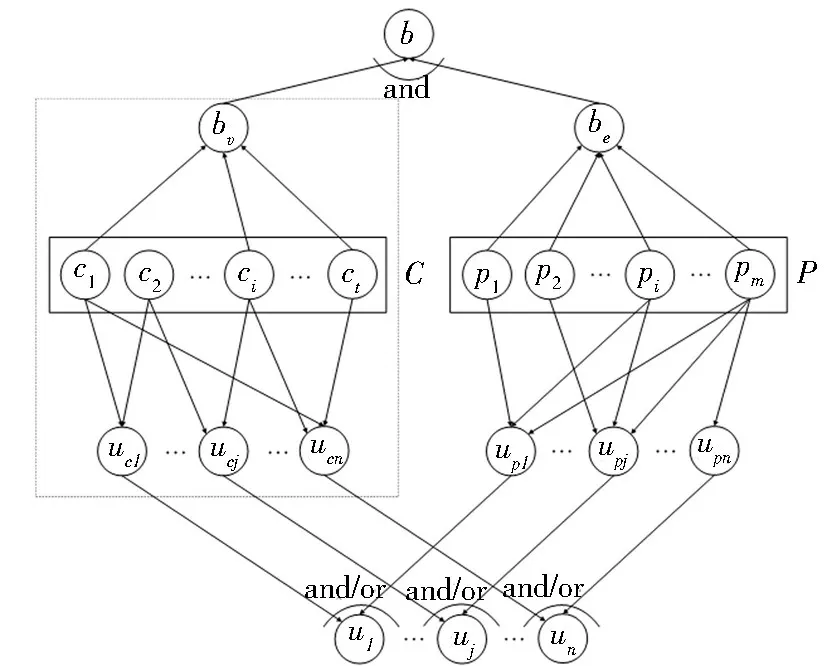
图2 EUIM 模型Fig.2 EUIM model
1)模型中左侧部分为基于兴趣特征词证据的基本网络,bv为当前待评估微博.右侧部分为基于交互微博证据的扩展网络,令P={p1,p2,…,pi,…,pm},pi(i=1,2,…,m)表示交互微博;p1,p2,…,pi,…,pm均为交互微博概念空间P中的一个基本概念,因此这些微博节点都与一个二值随机变量相关联,本文将P中的任一概念记为p.
2)微博节点bv和be是待评估微博b在左右两侧网络中的不同表示,用户节点ucj和upj是对同一用户uj在左右两侧网络中的不同表示,这种表示形式是为了方便建模.
3)若pi与be至少包含1个共同兴趣特征词,则认为pi与be相关,就有1条弧从pi指向be.节点bv和节点be通过合取操作将当前待评估微博与交互微博所提供的证据信息组合起来.
4)若用户upj对微博pi有过交互操作,则有1条弧从pi指向用户节点upj.upj产生的证据信息与ucj产生的证据信息通过and或者or方式进行组合来产生用户节点uj的最终排序.
2.2 概率推导
扩展模型仍采用P(uj|b)来实现对目标用户的排序.在扩展模型中,用户节点产生的证据信息有2种:基于兴趣特征词的证据,用P(ucj|c)表示;基于交互微博的证据,用P(upj|p)表示,2种证据的取值范围均为[0,1].扩展模型中对于用户节点ucj和upj产生的证据信息的组合方式有合取(and)和析取(or)2种[25].2种组合方式得到的概率推导过程如下.
1)and:采用and方式组合证据时,对于用户的排序取决于2种证据的共同作用,当关于用户的兴趣特征词证据值和交互微博证据值都较大时,该用户的排序要靠前,其排序如式(10)所示.


在式(12)或(14)中,只有当pi=1时,才会将每个交互微博pi对当前排序的影响考虑在内.在推导过程中,通过设置阈值∂对待评估微博与用户的相关度进行筛选,当P(uj|b)>∂时,则认为推荐成功.
3 实验
3.1 实验数据
实验通过编程爬取了具有关注关系的889 名用户及其自2019 年1 月1 日至2019 年4 月1 日的192 729条发布、点赞、转发和评论的微博,为了验证推荐模型的准确性,将每个用户的微博数据按9∶1比例划分为训练集和测试集2部分,其中训练集有174 834条微博,测试集有17 895条微博.
3.2 评价指标
本文采用准确率(Precision)、召回率(Recall)、F值(F-measure)和平均准确率均值(mean average precision,MAP)作为评价指标.准确率表示在Top-k条微博中用户感兴趣微博所占的比例,如式(18)所示.召回率表示用户感兴趣的微博被推荐的比例,如式(19)所示.F-measure指标同时考虑了准确率和召回率[26],可以较为全面地评估算法的性能,如式(20)所示.


3.3 实验方法
3.3.1 用户兴趣特征词数量确定
对于用户发布微博采用jieba分词进行分词处理,保留名词作为用户的候选兴趣特征词,并使用TF-IDF方法对名词进行排序.由于兴趣特征词的数目的选取直接影响推荐质量,因此通过实验分析来确定用户的兴趣特征词数目.图3为兴趣特征词数量分别为10、15、20和25时所对应的准确率和召回率的变化曲线.
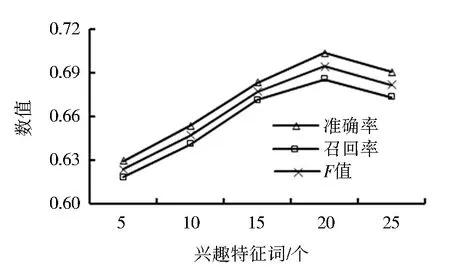
图3 兴趣特征词数量对推荐性能的影响Fig.3 Influence of the number of interest feature words on recommendation performance
由图3可知,当兴趣特征词数量为20时,推荐的准确率、召回率和F值达到最优.分析原因发现,当兴趣特征词较少时,对于用户兴趣的描述不够准确,当兴趣特征词较多时,容易引入噪声信息,这2种情况都会使推荐的准确率和召回率下降.因此,本文选取权重高的前20个特征词作为用户的兴趣特征词.例如用户“馋**橙”的兴趣特征词如表1所示.
从格律上看,44字的《卜算子》句式为5575,5575。从平仄看,◎仄◎平平,◎仄◎平仄(注:◎表示可平可仄)。与五言诗格律相仿。从起句方式看,多用对偶句。从表达功能上看,有“情起”式、“景起”式、“事起”式。

表1 用户“馋**橙”的兴趣特征词Tab.1 Interest feature words of“馋**橙”
数据集中889名用户的兴趣特征词经汇总和去重处理后,共得到8 591个兴趣特征词,部分兴趣特征词如表2所示.
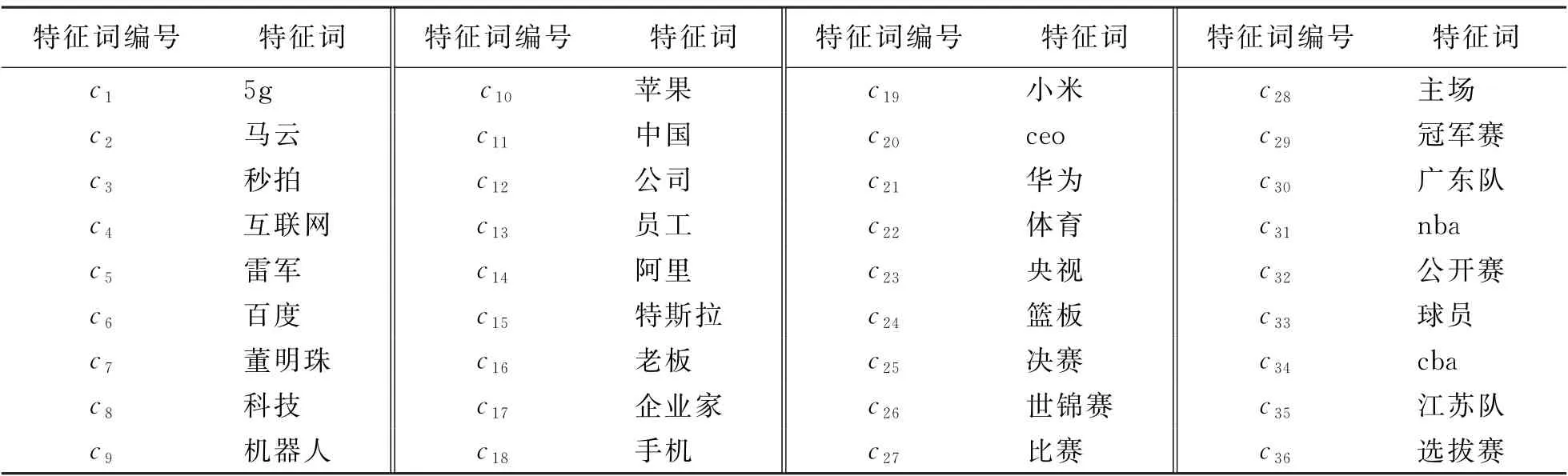
表2 部分兴趣特征词Tab.2 Part of the interest feature words
3.3.2 阈值∂的确定
阈值∂的确定是衡量推荐是否成功的重要参数,本文借鉴文献[27]中人工构建相关判断集的方法来判断目标用户对待评估微博的感兴趣程度,继而确定用户的兴趣微博集.具体评分标准为:很不喜欢评分为0~0.20分;有些不喜欢评分为0.21~0.40分;喜欢评分为0.41~0.60分;很喜欢评分为0.61~0.80分;特别喜欢评分为0.81~1.00分;将专家评分在0.60分以上的微博视为用户的兴趣微博集.当P(uj|b)>∂时,则认为该条微博是用户感兴趣的,故阈值∂取值为0.60.
3.3.3 实验结果及分析
本文设置了3组实验:1)用户交互操作权重αi的确定;2)BBNR 模型和EUIM 模型的推荐性能比较;3)与现有推荐方法比较.表3为实验所设计的推荐方法简写及其解释.

表3 推荐方法简写及其说明Tab.3 Abbreviations and describe of recommendation methods
1)用户交互操作权重αi的确定
在表征用户对微博的感兴趣程度方面,3种用户交互操作的贡献程度是不同的,其重要性等级为:转发>评论>点赞,利用层次分析法,对用户转发、评论和点赞的交互操作权重α1、α2、α3进行两两比较,构造的判定矩阵如表4所示.

表4 用户交互操作权重判定矩阵Tab.4 Decision matrix of user interaction weight
该矩阵的最大特征值为3.003 7,对应的特征向量为μ=(0.871 1,0.462 9,0.164),将该特征向量进行标准化操作,得到的向量为μ′=(0.581 5,0.309,0.109 5),因此转发、评论和点赞的权重分别为α1=0.581 5,α2=0.309,α3=0.109 5.
2)BBNR 模型和EUIM 模型的推荐性能比较
对构建的BBNR 模型和EUIM 模型的性能比较,考虑到微博每页的微博数为15条,而用户会仔细浏览的推荐页数一般为2页,因此本文选择比较模型在Top-30结果下的推荐性能.表5为2种模型的3种推荐策略在Top-30推荐结果下的准确率、召回率和F值.
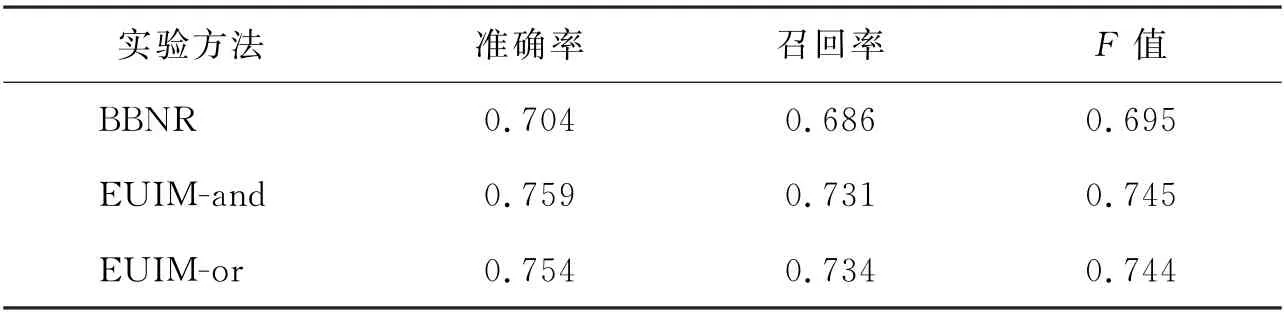
表5 本文推荐策略的性能比较Tab.5 Performance comparison of recommendation strategies in this paper
如表5所示,EUIM 模型较BBNR 模型来说,准确率至少提高了约5%,召回率至少提高了约4.5%,F值至少提高了约4.9%.分析实验结果发现,结合用户交互微博作为扩展证据,可以有效解决微博中不活跃用户的数据稀疏问题,提高推荐性能.其中,在EUIM 模型的2种组合推荐方法中,and方法的准确率要高于or方法,这是由于在and方法中,2种证据共同作用,对于只符合1种证据要求的微博起到过滤的作用,必须2种证据概率值都较大,推荐给用户的可能性才会大,因此在提高推荐的准确性方面具有较好的改善效果;而or方法的召回率要高于and方法,这是由于在or方法中,有1个证据较大,则其排序就会靠前,对于推荐的准确性有一定的影响,但能够做到为用户推荐更加多元化的符合用户兴趣的微博,提高微博推荐的多样性.由此可见,2种组合方式适用于2种不同的人群:当用户为不活跃用户,发布微博较少,用户兴趣不明显的情况下,可以使用or组合方式,为用户提供尽可能多的选择;当用户微博数据充足的情况下,可以使用and组合方式,为用户较为准确地定位到感兴趣微博.
3)不同推荐方法的比较
该实验将基于标签的微博推荐方法MCPRM-STM、基于用户聚类的微博推荐方法RA-CD 和基于浏览数据的微博推荐方法KFUS作为对比实验,以验证本文方法的推荐有效性.选择上述3种推荐方法作为对比方法的原因是
①MCPRM-STM 为使用用户兴趣标签的推荐方法,没有引入证据信息.
②RA-CD 推荐方法考虑了用户关系证据.
③KFUS推荐方法使用用户关系证据来完成推荐,未考虑用户的发布微博.
本文的BBNR 方法通过用户发布微博挖掘用户兴趣,实现了向量空间模型的排序结果,而EUIM-and和EUIM-or为通过用户发布微博挖掘用户兴趣,采用用户交互微博作为附加证据的推荐方法.图4为不同推荐方法在Top-30推荐结果下的准确率、召回率、F值和MAP值.
分析图4可得:1)EUIM-and方法和EUIM-or方法的推荐性能明显优于BBNR 方法、KFUS 方法和MCPRM-STM 方法,较优于RA-CD 方法.产生这种结果的原因:扩展模型在使用用户发布微博的基础上,方便自然地组合用户交互微博证据来支持推荐,并灵活使用组合方式,在缓解数据稀疏性的同时,可以很好地改善推荐性能;而EUIM-and和EUIM-or的F值基本相等,这就说明了扩展模型在灵活采用2种组合方式满足不同人群的信息需求的同时,又能够保证推荐性能,从而验证了使用本文模型组合证据来改善推荐效果的准确性;2)BBNR 方法的准确率、召回率和F值最低,这是因为该推荐方法仅使用了用户的发布微博来进行推荐,数据稀疏导致推荐性能最差;3)MCPRM-STM 方法通过用户发布微博获取兴趣标签,并使用加入了语义信息的用户兴趣标签进行推荐,因而推荐性能优于BBNR 方法;4)KFUS方法使用用户的浏览数据挖掘用户兴趣,进而结合用户关系证据来进行推荐,可以在一定程度上缓解数据稀疏问题,提升推荐性能,但提升空间有限,分析实验结果发现,不是所有的用户浏览数据都可以体现用户的兴趣,用户的浏览数据中存在一部分干扰信息;5)RA-CD 方法的准确率、召回率和F值略低于EUIM-and方法和EUIM-or方法,这是因为虽然用户背景信息可以用来挖掘用户兴趣,但多数用户的背景信息是不完善的,可利用信息有限.
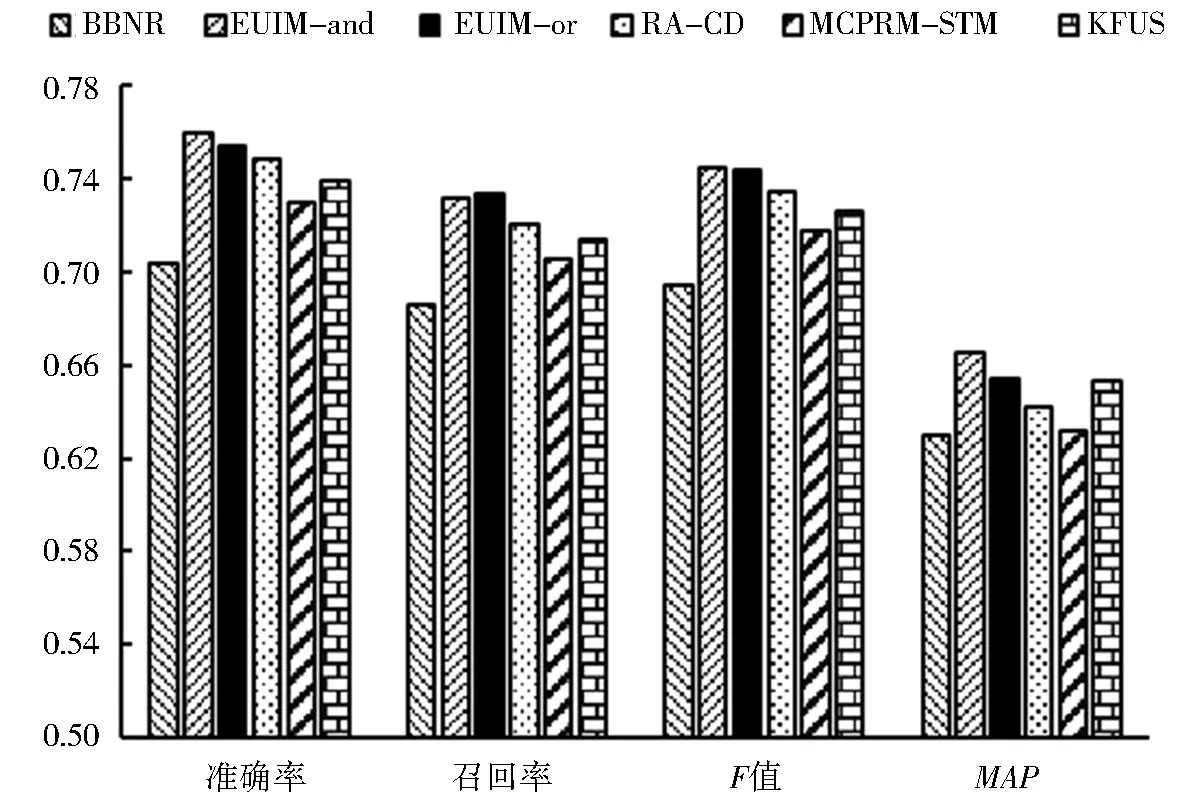
图4 不同推荐方法的性能比较Fig.4 Performance comparison of different recommendation methods
在个性化推荐中,不仅需要衡量推荐方法的准确性,还需要衡量推荐列表中用户感兴趣微博的排序合理性,对于用户感兴趣的微博,应尽可能地靠前排序.因此,对图4中6种推荐方法的MAP值进行观察发现,EUIM-and方法的MAP值最高,其次为EUIM-or方法,说明本文所提模型在微博推荐排序方面更为合理.
通过对上述的实验结果进行分析可知,本文所提模型作为一个通用的推荐框架,能够方便灵活地组合证据来提高微博推荐的准确性;此外,使用语义信息或用户关系也可以提高微博推荐的准确性.
4 结束语
针对现有微博推荐方法或模型不便组合证据的问题,将信念网络应用到微博推荐场景中,提出BBNR模型和EUIM 模型,通过计算微博与用户的相关度来完成推荐,并在真实微博数据集上进行实验,证明了本文所构建模型的有效性,为微博推荐的研究提供了新思路.与其他推荐方法相比,本文提出的信念网络推荐模型能够通过方便地组合证据来缓解数据稀疏性,并进一步提高推荐性能,更好地满足用户的信息需求.在未来的工作中,可以考虑结合用户关系或外部知识库(如知识图谱)扩充语义等诸多证据,实现更好的推荐效果;也可以考虑将该思想应用到其他个性化推荐领域,如电影推荐、图书推荐等,提升该领域的推荐性能.
