面向用户需求主题的在线问答社区信息多层级分类研究
2022-08-31张燕刚
成 全,张燕刚
(福州大学经济与管理学院,福州 350116)
1 引 言
随着泛在网络去中心化特征的不断凸显,基于用户生成内容(user generated content,UGC)的在线问答社区已然成为网络用户快速获取个性化需求的重要渠道[1]。然而,在线问答社区内资源内容的包罗万象与鱼龙混杂,导致社区内信息资源的组织与序化问题成为困扰其高效响应、个性化满足用户信息需求的瓶颈。当前,多数在线问答社区将用户生成信息按其发布时间或简单主题进行堆叠与划分,这不仅不利于提升平台信息资源聚合的目标,也不利于实现为用户量身定制个性化精准推送服务的要求,最终将导致用户使用在线问答社区的满意度不断降低,逐渐弱化平台的黏性。为了不断提升网络问答社区内信息资源的细粒度揭示、语义化表达与网络化关联,从而适应当前智能化知识精准推荐服务的目标,亟须构建一套结构完善的多层级主题分类架构体系,以及满足面向需求主题的多层级、细粒度信息资源分类模型,以期实现对用户需求信息的自动化分类与推荐[2-3]。为了达到上述目标,本研究以在线母婴问答社区妊娠期孕妇信息需求为例,从提升在线问答社区信息资源的多层级、细粒度组织效果为基础,以满足用户个性化需求主题高效响应为目标,综合运用内容分析、人工标注、交叉验证、机器学习等研究方法,围绕如何构建用户在问答社区中的多层级、细粒度信息需求主题体系架构,如何引入机器学习机制实现在线问答社区多层级信息分类以满足用户的个性化需求两大核心问题展开深入研究。
本研究的主要贡献在于:①以跨平台的妊娠期孕妇信息需求为例,构建覆盖内容全面、逻辑结构清晰、需求主题个性的多层级、细粒度信息资源主题架构体系,为UGC 模式下特定需求主题识别及多层级信息分类服务研究领域提供理论参考和应用借鉴;②构建基于机器学习的面向用户需求主题的信息多层级分类模型,实现信息多层级、细粒度的自动化分类,为优化在线问答社区信息资源生态,实现信息资源的高效序化与语义化表征提供新的思路和研究视角。
本文后续章节安排如下:第2 节将对用户信息需求与信息层级分类的概念及其相关研究现状进行梳理和阐述;第3 节将从层级分类策略选择、模型网络基本结构、数据层级标签处理、需求主题特征表示、多层级分类器选择、模型评估方法等方面,对面向用户需求主题的信息多层级分类模型构建技术与方法进行详细介绍;第4 节将从用户多层级需求主题分类体系架构构建、实验样本数据的选择与处理、模型参数选择与设置、实验结果可视化呈现等方面进行实验研究;第5 节将对本研究所构建多层级分类模型(users' needs topics - hierarchical clas‐sification,UNT-HC)对特定数据集的分类性能进行评价;最后将总结研究工作,并对后续研究工作的可能路径指明方向。
2 研究现状
2.1 用户信息需求研究现状
用户信息需求的概念,目前学术界尚未形成明确的定义,但初步形成了一个共识性的认知概念与理论体系雏形,即刺激(情境)-认知模型(信息需求)-反应(信息行为)研究框架[4]。通常,信息需求包括信息需要、信息要求、信息利用三种不同的情况,但在某些情况下,信息要求与信息需求被视为同义词,一般不使用信息要求这一术语,而用表达的信息需求代替,同时,信息利用也被作为信息行为的同属概念[5]。
从用户认知角度出发,现有用户信息需求研究主 要 以Taylor、Belkin、Ingwersen、Kochen、Wil‐son、Cole 等学者的信息需求理论为基础,尤其Taylor 根据用户需求认知或意识水平划分的内在的、有意识的、形式化的和折中的信息需求,已成为信息管理科学领域许多模型与研究的基础,同时也是信息检索与信息交互系统设计等研究的动力[6]。Belkin[7]也以用户认知为导向提出了知识非常态理论,并从认知深度垂直解读了Taylor 4 个层次的信息需求。计算机科学领域学者也常把Taylor 折中的信息需求作为默认观点,并从用户信息需求搜索角度出发,将其过程划分为预聚焦、聚焦、后聚焦三个阶段[8]。当然,从社会学角度来看,信息需求是用户信息寻求行为的决定性因素,并且信息需求也并非用户最原始的需求,它主要源于用户生理、情感、认知等更为基本的需求[9]。
用户信息需求是动态的,并且高度依赖于用户情境。近年来,用户健康信息需求研究引起了广大学者的高度关注,其研究成果颇丰。该领域的相关研究不仅与健康意识、健康态度有关,而且适用于特定的社会环境和认知状况[10]。由此,在线上用户信息需求主题研究方面,大量研究主要围绕不同情境下的用户群体展开,尤其是特定用户群体的信息需求研究。其中,癌症[11]、糖尿病[12]等慢性病患者群体是当前较为关注的群体之一。当然,处于特定群体中较为弱势的身份转换期的女性[13]、初为人母的年轻妈妈[14-15]及更为特殊的并发症孕妇[16],更有尚未完全认同且极具独特性的初为人父的年轻父亲[17]的信息需求主题同样受到关注。
从研究方法来看,目前线下用户的信息需求主题研究主要采用访谈、调查等方式,而UGC 模式下的在线问答社区用户则以人工内容分析与编码[14-15]、自动文本需求主题挖掘[13]等人机互动的相关方法进行。当然,每种方法均有优劣,访谈可通过不断交谈来理解用户表述的含义与情境,但涉及私密、敏感话题用户则不愿回答或敷衍,数据易失真或缺失,数据转换也存在挑战;而调查则与之相反,虽更易实施和量化,概念清晰度高,但难获取用户情境与详细资料[18]。与基于小样本的访谈与调查不同,UGC 模式下的用户信息需求更易获取且更能反映用户的真实情况,但无法让参与者阐明其内容含义及后续跟进研究[15]。
2.2 信息多层级分类研究现状
信息多层级分类可看作一种特殊的类别标签之间具备层级结构的信息多分类问题[19]。多层级分类在现实世界中有着重要的作用,广泛应用于文本分类、生物信息学等诸多领域,如图书分类法、物种纲目分类等。当前大多数分类方法局限于单层级二分类、多分类、多标签等问题,往往忽略了类别标签之间因层级结构或关联性所反映出的重要信息。当然,部分学者也在各领域围绕不同信息载体与层级结构处理策略展开了一系列相关理论与实证研究。
从信息载体来看,当前主要聚焦于长文本与图像信息载体的多层级分类研究,根据标签类型又可分为层级单标签和层级多标签分类问题。针对文本信息载体中的层级单标签问题,Stein 等[20]通过组合不同的词嵌入模型与机器学习算法对比发现,Fast‐Text 无论作为分类算法还是词嵌入生成器均提供了出色的结果。通过fine-tuning 微调方式将上层信息传递至下层标签学习中,Shimura 等[21]提出了HFTCNN (hierarchical fine-tuning conventional neural net‐work)模型。利用标签的层级结构,HCCNN(hi‐erarchical classification conventional neural network)模型通过融合各层级标签学习结果以指导完成最终层级多标签的学习[22]。对于更为复杂的极端多标签分类问题,Gargiulo 等[23]利用适用于数据标签正则化的层级标签扩展方法进行层级多标签分类。针对图像信息载体,Chen 等[24]通过层级语义嵌入框架,自顶向下逐层将上一层级的预测得分向量作为下一层级的先验信息,并采用使其与上一层级结果相符层级结构关联规则进行图片信息的细粒度分类。
从处理策略来看,常见的层级结构类型有树(tree) 结构和有向无环图结构(directed acyclic graph,DAG)两种,当前绝大多数研究主要针对树结构,其层级结构处理策略有自顶向下型的局部分类策略、大爆炸(big-bang)型的全局分类策略、收缩型的扁平化分类策略三种,而采用最多的是自顶向下的局部处理策略[19]。
从效果评估方法来看,许多研究人员使用传统的精确率、召回率等方法进行评估,但实际上这不适合层级分类,因为其忽略了类别间的关系。对此有学者建议采用等级精度、召回率等进行度量,不仅考虑实际与预测节点,还可扩展考虑中的对象,但又过度惩罚了具有较多祖先的节点,为此有学者使用最低共同祖先(lowest common ancestor,LCA)度量评估[19,23,25]。还有部分学者采用宏观平均值[26]、微观平均值[27]、平均与整体准确率[28]等进行层级分类效果评估。
综上所述,现有的用户信息需求研究逐渐倾向于面向特定用户群体,但在研究方法上大部分仍采用调查与访谈的方式,UGC 模式下的内容分析与编码方法应用相对较少。与此同时,信息多层级分类问题主要聚焦于长文本与图像信息的层级多标签分类研究,针对短文本多层级单标签分类问题的研究相对缺乏。而短文本的特征稀疏,并且线上用户需求主题细而庞杂,致使专指性信息资源分类聚合充满挑战。为此,本研究将以在线问答社区特定群体中处于弱势的妊娠期孕妇为对象,应用内容分析与编码的方法构建其多层级、细粒度的需求主题体系架构,依托此架构,通过引入机器学习机制构建并实现在线问答社区信息资源的专指性、多层级、细粒度自动化分类模型与应用路径。
3 技术路线与评估方法设计
3.1 信息多层级分类策略选择
本研究所构建的信息多层级分类采用自顶向下的局部分类策略。该策略从类别层级的顶层(根节点)开始,逐层向下直至分到某个类别,即先划分至大类,再到该大类的某一小类,以及该小类的某一超小类。在整个分类过程中均使用类别的层级结构信息,其分类过程符合人们信息多维导航与检索的思维习惯,适应性较强。本研究所采用的树型结构多层级需求主题体系架构与多层级信息分类问题适合选择这种自顶向下的层级结构处理策略,从顶层类别开始逐层向下进行多层级、细粒度的需求主题类别划分。
3.2 信息多层级分类模型网络基本结构
根据构建的用户需求主题体系架构可知,其层级标签从粗粒度向超细粒度延伸,每条样本数据的层级类别标签仅对应层级结构中的唯一一条路径(即一对一关系),因而本研究属于层级单标签分类问题。对于层级单标签问题而言,其核心是要求模型能够利用层级结构关系等全局和局部信息作为先验知识规范约束和有效引导深度网络的学习,以此更精准地识别底层细粒度信息的类别特征。在本研究面向用户需求主题的信息多层级分类模型(UNT-HC)中,自顶向下逐层学习和识别各层级类别标签,在学习训练过程中将上一层学习与识别结果作为先验知识集成并嵌入下一层网络中,以此指导和学习下一层更细粒度的特征与类别。其中,UNT-HC 模型的网络基本结构如图1 所示。
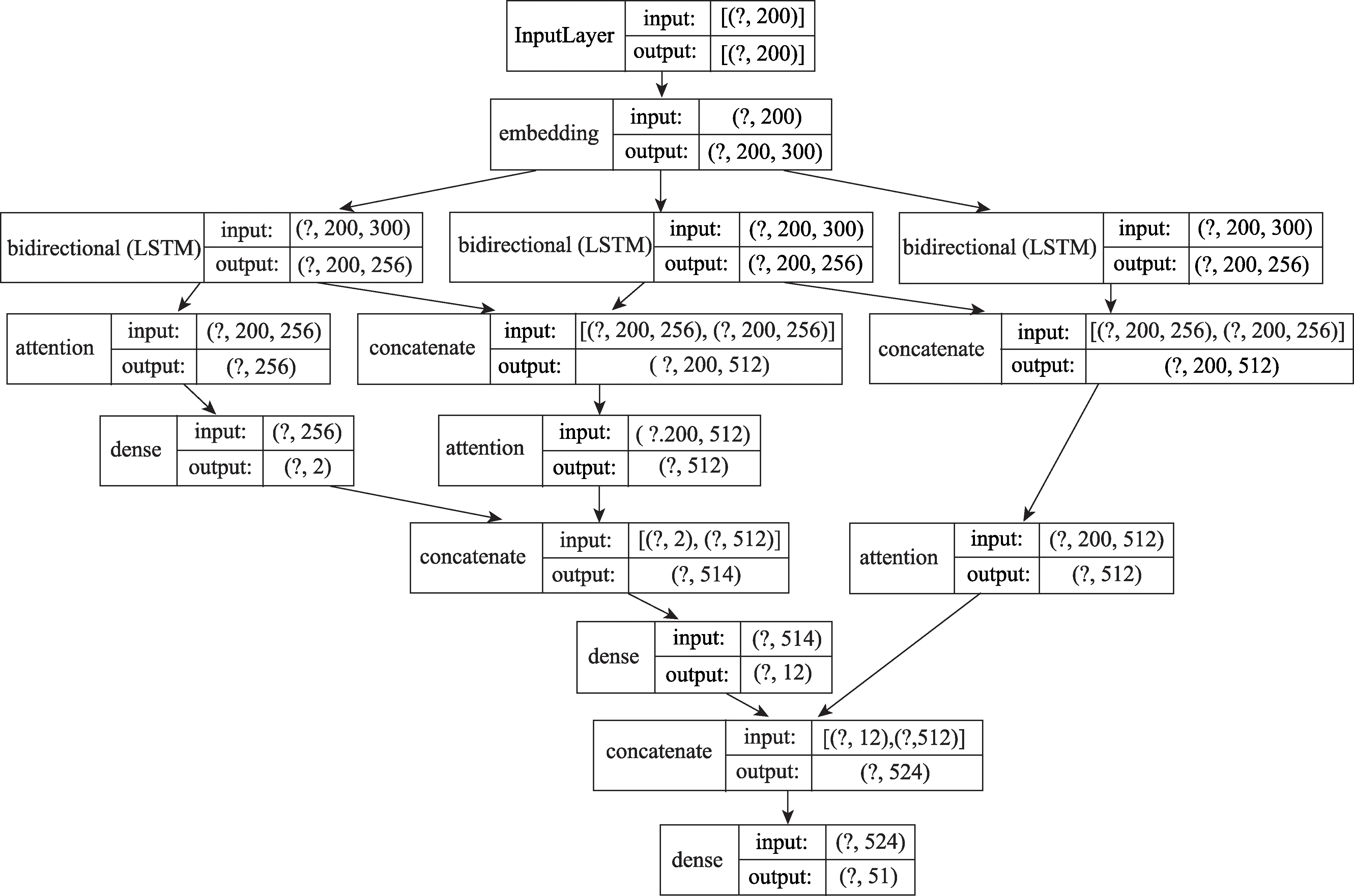
图1 UNT-HC模型网络基本结构
依托UNT-HC 模型的样本学习训练基本流程如下:
(1)输入是一段经预处理,并保留最大特征字符、长度为200 的用户中文提问短文本,同时进行词嵌入转化(图1 中主要利用FastText 实现)。
(2)训练样本数据的顶层标签(即信息支持和情感支持),即在词嵌入基础上通过一个双向LSTM(long short-term memory)循环神经网络获取各隐藏层信息,并对隐藏层信息进行注意力(atten‐tion)机制处理,得到一个注意力概率向量,将各隐藏层信息与注意力概率向量相结合进行连接(concate)操作实现全连接,最后利用分类交叉熵(categorical_crossentropy)进行顶层标签预测。这个过程符合TextAttBiRNN (text attention bi-directional recurrent neural network)文本分类框架。
(3)进行下层级标签预测,此时依然采用Tex‐tAttBiRNN 文本分类框架,但不再重新生成词嵌入。利用下层双向LSTM 循环神经网络得到各隐藏层信息后,通过连接操作融合上一层双向LSTM 的循环神经网络的学习结果并实施本层注意力概率提取,进而融合上一层分类预测结果对该层标签进行学习和预测。
(4)按照上述步骤,逐层遍历整个层级标签,进而完成对整个层级结构中的各层级标签及最底层节点细粒度类别标签的学习与预测。
3.3 数据层级标签处理
本研究属于层级单标签分类问题,其层级标签为一对一关系的树型结构。此时,通过样本最底层细粒度节点的类别标签,能够形成一条追溯至根节点的唯一路径,从而得到该底层节点其上的各层级节点标签。本研究的最终目标是利用标签间的层级结构信息,更准确地识别出最底层细粒度节点的最终类别标签。在学习训练过程中,可提取或拆分出各层级类别标签,并将其进行规格化处理,然后转化为独热编码(one-hot),以便在各层级标签学习与识别过程中使用。
3.4 需求主题特征表示
当尝试引入机器学习机制实现文本分类应用时,需要解决的首要问题是如何对用户需求文本信息进行文本特征揭示与表达,即如何将自然语言转化为机器能够理解并学习的结构化形态。在机器学习中,特征属性的选择通常直接关系到后续训练结果的可靠性,一个好的特征属性往往能够得到令人满意的分类效果。本研究在结合现有研究的基础上,尝试分别采用word2vec、LDA2vec 及其已预训练好的中文FastText 与腾讯DSG (directional skipgram)词向量模型对用户提问文本数据的需求主题特征进行表示,并根据UNT-HC 模型分类效果,选择其中相对较优的词嵌入模型进行后续模型效果对比验证实验。
3.5 多层级分类器选择
从图1 可知,模型各层级的基础分类器均选择TextAttBiRNN 分类算法。TextAttBiRNN 分类算法是在双向LSTM 文本分类算法的基础上改进的,主要引入了注意力机制,能够有效应对与分类任务不相关的数据点,注意力被表示为整个集合中所有点的softmax 加权平均值,权重则被计算成一些非线性的向量和上下文信息,在上下文中,部分文字被赋予更高的权值来突出,从而使双向LSTM 编码得到的表征向量能够通过attention 机制去更加关注那些与决策需求最相关的信息,进而提高文本分类的效果。
3.6 模型评估方法
由于本研究为多层级单标签问题,除顶层标签类别为两类外,其余层级标签均属采用独热编码的多类别单标签,且最底层类别标签被视为最终类别标签,因而可采用传统单层级多分类评估方法对模型效果进行评估。categorical_crossentropy 损失函数就是针对这类情况的多分类交叉熵损失函数,要求类别标签为独热编码,一般配合柔性最大值(soft‐max)进行单标签分类。鉴于此,本研究采用分类交叉熵函数来评估UNT-HC 模型的分类效果。其中,分类交叉熵损失函数定义为
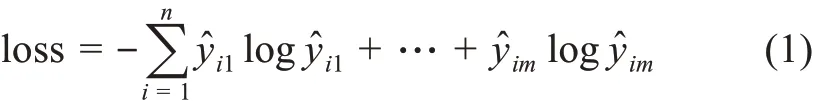
其中,n代表样本数;m代表分类数。因为该函数是一个多输出损失函数,因此函数的计算过程分多步实现。当时,loss=0,否则,loss>0,而且概率相差越大,loss 值也越大。
UNT-HC 模型自顶向下拥有三层不同的独热标签,当一条文本输入模型后,整个模型会相应地输出与三个层级一一对应的预测向量,各层级输出的损失值也将会对应一个损失权重,并且三个层级的分类损失值会根据各自的损失权重合并构成一个最终模型的分类损失值。
与多分类交叉熵损失函数相对应,分类精确度函数(categorical_accuracy)检查实际标签(y_ture)中最大值对应的索引(index) 与预测标签(y_pred)中最大值对应的索引是否相等,因仅比较一个值,即最大的那个值的索引,所以比较适用于多分类单标签任务,但不适用于多标签任务,并且与损失值一样,整个模型会相应地输出各层级的分类准确率。
4 实验研究
4.1 实验内容设计
面向用户需求主题的信息多层级分类模型(UNT-HC)实验内容主要涉及以下三个部分:
(1)在线问答社区用户信息需求主题层级分类体系构建,利用在线母婴问答社区妊娠期孕妇提问文本数据构建用户信息需求主题层级分类体系,并以此作为UNT-HC 模型构建及其数据样本标签编码评估的标准;
(2) 通过实验对比多组不同的参数值取值对UNT-HC 模型多层级分类效果的影响,并且选取其中相对最优的一组参数取值作为最终模型的参数设置;
(3)通过实验对比不同词表征模型对UNT-HC模型多层级分类效果的影响,并从中选择一种相对较优的词表征模型进行后续模型分类效果对比验证实验。
4.2 用户信息需求主题体系构建
4.2.1 用户需求数据选择与预处理
信息需求激发用户信息行为,但用户若未使用言语或词语表达出来,旁人将难以知晓其真实的信息需求。在线问答社区中的提问作为用户折中的信息需求,是其对自身信息需求的自由描述与主动表达,实质上更趋近于用户意识到的“最真实的需求”,由此成为信息需求观察与研究最优质的素材[29]。然而,国内在线母婴问答社区众多,研究中难以实现全覆盖,故通过以下方式筛选了三个具有代表性的平台作为本研究数据来源:①根据中国品牌大数据研究院公布的母婴网十大品牌排行榜[30],筛选出拥有问答模块的6 个网站;②结合艾媒咨询发布的《2019 中国综合母婴平台监测报告》[31]中的用户体验满意度调查结果,保留了已筛选的品牌和满意度排名均稳居前三的网站;③利用中国网站排行查询保留的3 个网站的母婴网站综合排行榜和Al‐exa 排名,进一步验证其代表性;④为便于数据采集和保障数据质量,再次确认其提问数据是否按照备孕、怀孕等阶段划分。
按照上述方法与筛选标准,为了保障用户需求主题的全面性以及减弱因平台差异而导致研究结果受影响,本研究最终选择了宝宝树、妈妈网、育儿网三大在线问答社区作为最终数据来源。与此同时,在各平台怀孕期(即妊娠期)问答资源模块中采集了不同时间段的共16188 条用户提问文本,其中,宝宝树7624 条,妈妈网5571 条,育儿网2993 条。
因数据来源于不同平台,且为用户自定义生成文本,其质量参差不齐,为了提高数据质量,本研究初步筛选并删除了原始数据集中以下7 类数据:①纯表情、符号、数字等非文本或超短无效文本(44 条);②提问式产品广告(144 条);③非母婴主题提问(68 条);④非妊娠期阶段用户需求提问(1286 条);⑤特定对象间交流文本(25 条);⑥难以判断其需求主题的提问(91 条);⑦需求主题较偏且数量极少的提问(5 条)。经筛选、清洗后,最终获得有效用户提问数据14525 条。
4.2.2 用户需求主题编码与测试
本研究利用内容分析法与迭代编码的方式从用户提问文本中提取用户需求主题,进而构建用户信息需求主题体系架构,其内容主要分为两大部分:第一,初始需求主题体系架构编码方案的制定与迭代编码修正;第二,编码方案全面性、适用性及编码间可靠性测试。具体的构建流程如图2 所示。
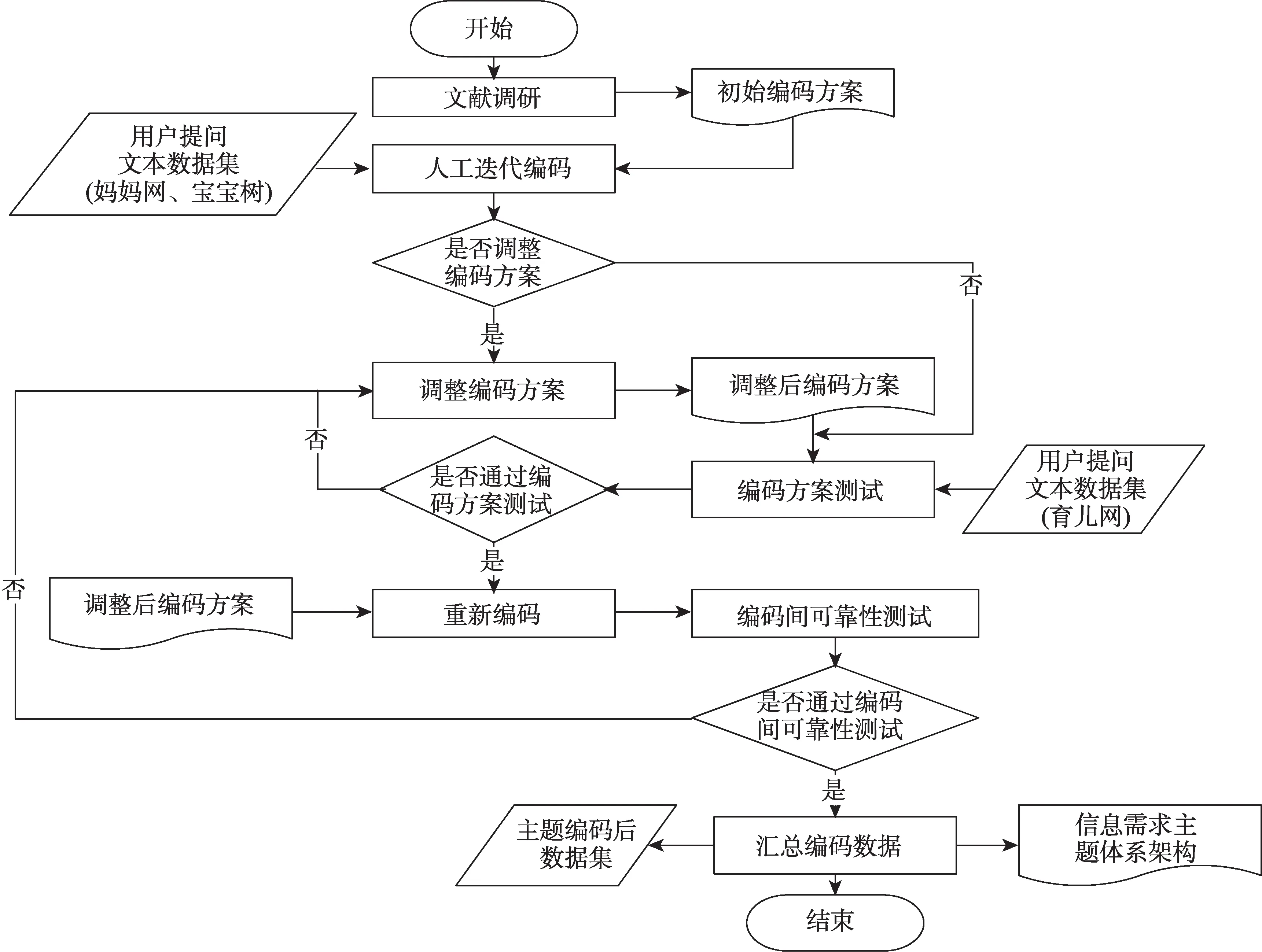
图2 用户信息需求主题体系架构构建流程
1)初始编码方案制定
因用户庞杂的信息需求主题涉及健康、医药、生活等诸多细微领域,现阶段极少有如同疾病分类体系那样相对完整且层次结构分明的分类体系架构可供参考,因此本研究仅能够依托现有线上线下零散且不成体系的需求主题研究和用户提问文本数据,通过扎根理论的方法,从中提取和凝练出具有层级结构的需求主题体系架构。有研究表明,用户除在线寻求信息支持外,同样也寻求情感支持[16]。鉴于此,本研究将信息支持和情感支持作为在线问答社区中妊娠期孕妇需求主题初始体系架构中的顶层需求主题目录。与此同时,参考现有的线下妊娠期孕妇需求主题,尤其是在Liu 等学者设计的中国孕产妇健康需求量表(maternal health needs scale,MHNS)[32]和Almalik 等学者的孕妇妊娠期间33 项学习需求量表[33]的基础上,结合顶层主题目录,按照粗粒度-细粒度-超细粒度层级结构,通过概念整合与归纳制定了层级深度为3 层的初始需求主题体系架构编码方案:第1 层包含2 项,第2 层涉及11项,第3 层涵盖47 项需求主题目录。
2)迭代编码与方案修正
根据已制定的初始编码方案,采用迭代编码的方式,对“妈妈网”和“宝宝树”两组数据集中的每条用户提问文本所反映的需求主题进行编码,并在迭代编码过程中根据反馈出来的新问题不断调整和修正编码方案。
3)编码方案全面性测试
经过不断地迭代编码与方案修正后,需求主题编码方案基本趋于稳定,为了验证最新编码方案的全面性与适用性,使用该编码方案对另一组未进行迭代编码的“育儿网”数据集进行用户多层级需求主题编码,并观察其是否出现新需求主题。最终结果显示,“育儿网”数据集并未出现新需求主题,并且与“宝宝树”和“妈妈网”数据集相比,“胎儿取名”“妊娠期工作”“妊娠期产假”“临产前物品准备”等8 类需求主题并未在该数据集中出现。由此说明,该编码方案具有较强的全面性和适用性。由于育儿网数据集的需求主题均包含在前两个数据集中,因此将三个数据集合成一个更大的数据集,并用最新的编码方案对数据集进行重新编码。
4)编码间可靠性测试
为验证本次编码间的可靠性与一致性,以及编码方案的有效性与可重复性,本研究邀请了未参与编码的一组成员,在给予其编码方案和阐明了编码说明与判定规则的前提下,从数据集中随机抽取了10%的样本数据进行编码,并采用Cohen's kappa系数对编码的一致性和可靠性进行检验。结果显示,三个层级的需求主题编码间的kappa 系数均大于0.8(P<0.01),说明本次需求主题编码间的一致性与可靠性程度很强,同时也反映了本研究编码方案具有很强的有效性和可重复性。
至此,可将当前多层级信息需求主题编码方案认定为最终的在线问答社区妊娠期孕妇多层级信息需求主题分类体系架构,同时也可将其编码数据集作为后续信息多层级分类研究的实验数据样本。最终的在线问答社区妊娠期孕妇多层级信息需求主题体系架构如图3 所示。
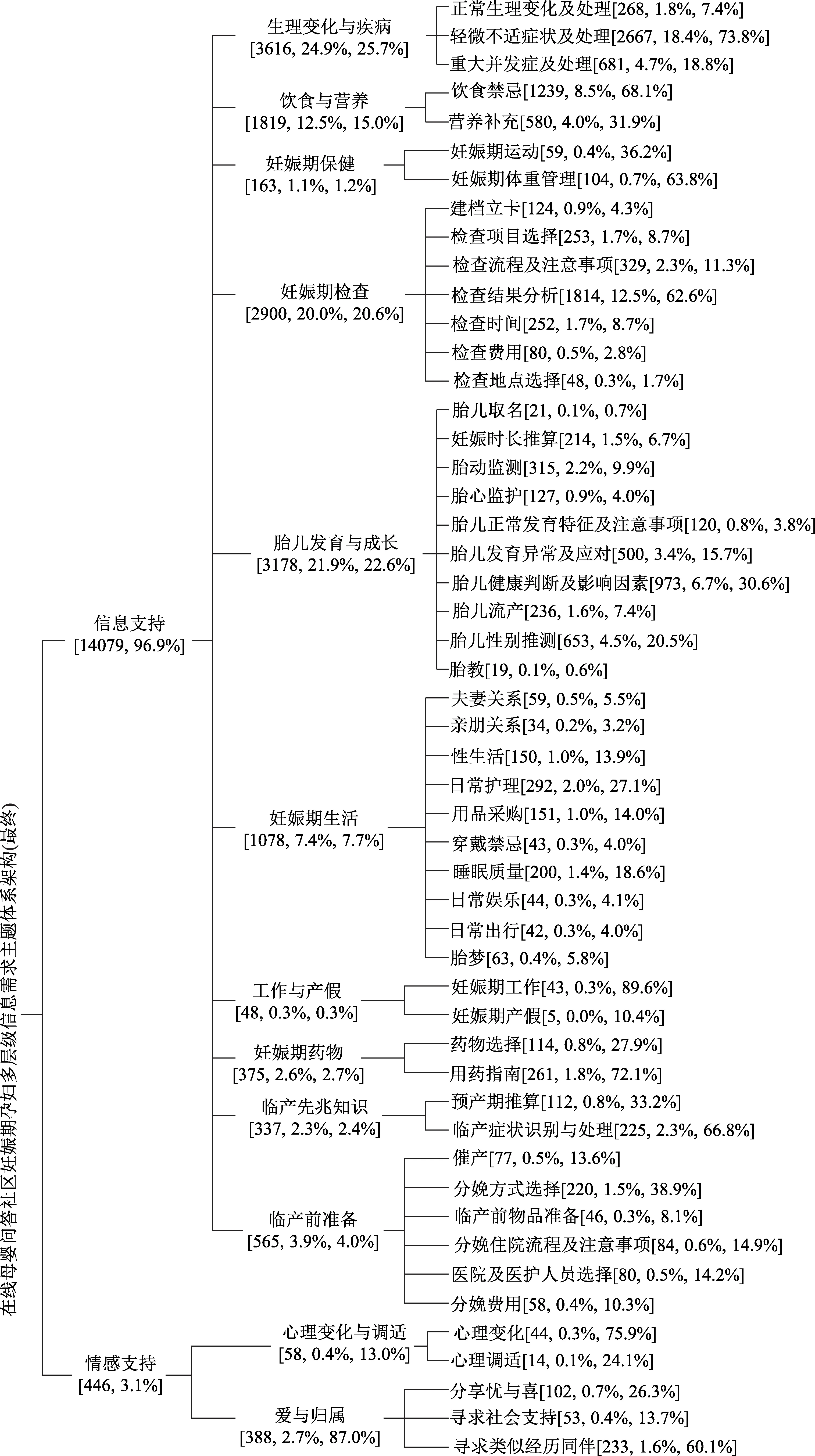
图3 在线问答社区妊娠期孕妇多层级信息需求主题体系架构
该需求主题体系架构共包括三个层级,第1 层级包含2 类需求主题,第2 层级涵盖12 类需求主题,第3 层级覆盖51 类需求主题。图3 中,各二级和三级主题之后的中括号内的三组数值分别表示该主题下的数据条数、总需求主题数据条数的占比和上一层级父节点需求主题数据条数的占比。
4.3 层级分类实验数据划分与预处理
4.3.1 数据选择与划分
UNT-HC 模型是面向在线问答社区用户信息需求主题体系架构构建的,因而本次实验样本数据选择上述已编码和测试验证通过的、具备层级结构标签的在线问答社区妊娠期孕妇信息需求主题数据集(以下简称mother_data)。因为数据集中超细粒度标签类别较多,而数据集总体数据量又相对偏少,为保证实验所使用训练集与测试集对所有需求主题标签的覆盖面,本研究将数据集中的14525 条数据根据第3 层级的51 类需求主题标签分别按照各类别主题标签9∶1 随机划分为训练集与测试集,然后将各类别主题标签的训练集与测试集对应合并,最终将整个数据集按照9∶1 随机划分出训练集与测试集。最终,训练集包含13076 条样本数据,测试集包含1449 条样本数据。
4.3.2 文本数据预处理
文本预处理过程就是从文本中提取关键词表示文本的过程,对于中文文本而言,预处理主要包括中文文本分词和去停用词两个阶段。中文文本没有天然的空格进行间隔,因而本研究利用Jieba 分词工具对数据集进行分词操作。但mother_data 数据集涉及医学专业领域,并且是用户自定义生成文本,其文本包含了大量如“妊娠糖尿病”“前置胎盘”等专业性词汇,又掺杂了大量如“有木有”“集美们”“BB”“小月子”等网络或民间用语,致使原有词表难以满足需求,故通过搜狗词库等向原有词表中添加了30多万个自定义词汇,从而提升文本分词效果。与此同时,因实验数据文本为短文本,文本特征词较少,而部分关键词在类别划分过程中可能为关键特征词却被划为停用词。鉴于此,本研究未进行停用词处理,从而保证文本最大特征,进而提升类别识别度。
4.4 多层级分类模型参数设置
由于本实验数据样本为短文本,且长短不一,故保留最大特征数字长度的MaxLen 参数值设置为200,若文本特征数字长度小于参数值,则会自动填充为0,使之与参数值保持一致。与此同时,因LSTM 模型在训练或预测过程中极易产生过拟合现象,为防止和改善过拟合现象,一方面,在各层级的双向LSTM 层中增加dropout 参数与recurrent_drop‐out 参数;另一方面,加入早停机制(EarlyStop‐ping),随着epoch 的增加,若最终标签识别的损失值连续两次上升,则提早终止训练。但是,因dropout 参数和recurrent_dropout 参数的最佳参数值难以主观确定,对此,本研究选择了几组现有研究中常见的参数值组,利用mother_data 数据集和Fast‐Text 词嵌入模型,将各组参数分别代入UNT-HC 模型中,在其余参数保持不变的情况下,通过最终标签预测准确率的大小,从中选择准确率相对最佳的一组参数值作为dropout 参数和recurrent_dropout 参数的最终参数值。其中,各组参数值与之对应的最终标签识别准确率变化趋势如图4 所示。由图4 可知,当dropout 与recurrent_dropout 参数值均设置为0.5 时,其准确率相对最佳。
图4 各组参数值的最终标签识别准确率变化趋势
4.5 多层级分类实验结果分析
利用上述已划分且经过预处理的训练集与测试集,将通过对比实验选择的最佳模型参数代入UNTHC 模型中进行多层级分类实验研究。但为了选择一种相对较优的词表征模型进行后续模型分类效果对比验证实验,在本实验过程中分别使用word2vec、FastText、DSG、LDA2vec 四种词表征模型对moth‐er_data 数据集中的用户提问文本进行表征,并且分别将层级分类实验结果的准确度输出。其中,不同词表征模型层级分类准确度实验结果如表1 所示。
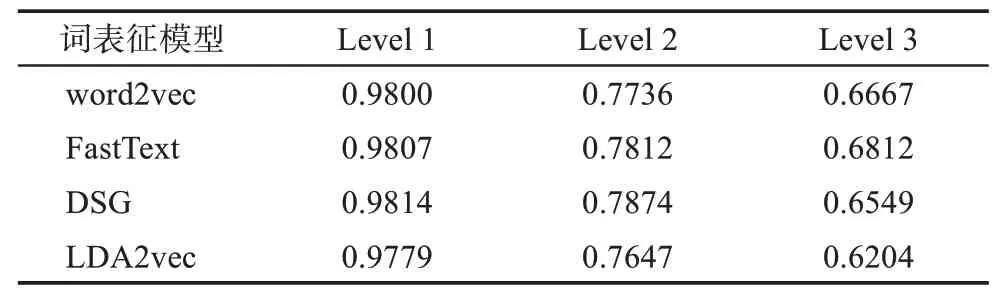
表1 不同词表征模型层级分类实验结果
由表1 可知,四种词表征模型的各层级分类最佳准确率差距均较小,其原因主要是FastText 和DSG 等已预训练的词向量来源于新闻、小说等语料,而本研究文本是极具医学背景的母婴主题,其匹配度与适用性较差。同时,由于文本语料均为短文本,文本特征稀疏,总体来说并不适用于LDA模型。当然,仅从最底层分类效果看,由FastText进行词表征的层级分类模型效果最佳,其准确率为68.12%,相比于其余三种模型分别提升了1.45、2.63 和6.08 个百分点。由此,在后续两组实验中,将选择本实验中的FastText 词表征模型及其对应的层级分类结果完成对比验证。
在测试集的识别预测过程中,由FastText 进行表征的层级分类模型的损失值和准确率变化曲线如图5 所示。由图5 可知,测试集第1 层级的损失值与准确率一直趋于平稳。当迭代3 次时(即epoch=3),测试集第2 层级的损失值与准确率也逐渐趋于平稳,但后期损失值略有上升趋势,出现轻微的过拟合现象。当迭代到第9 次时,第3 层级损失值与准确率趋于平稳,此时模型达到最优。
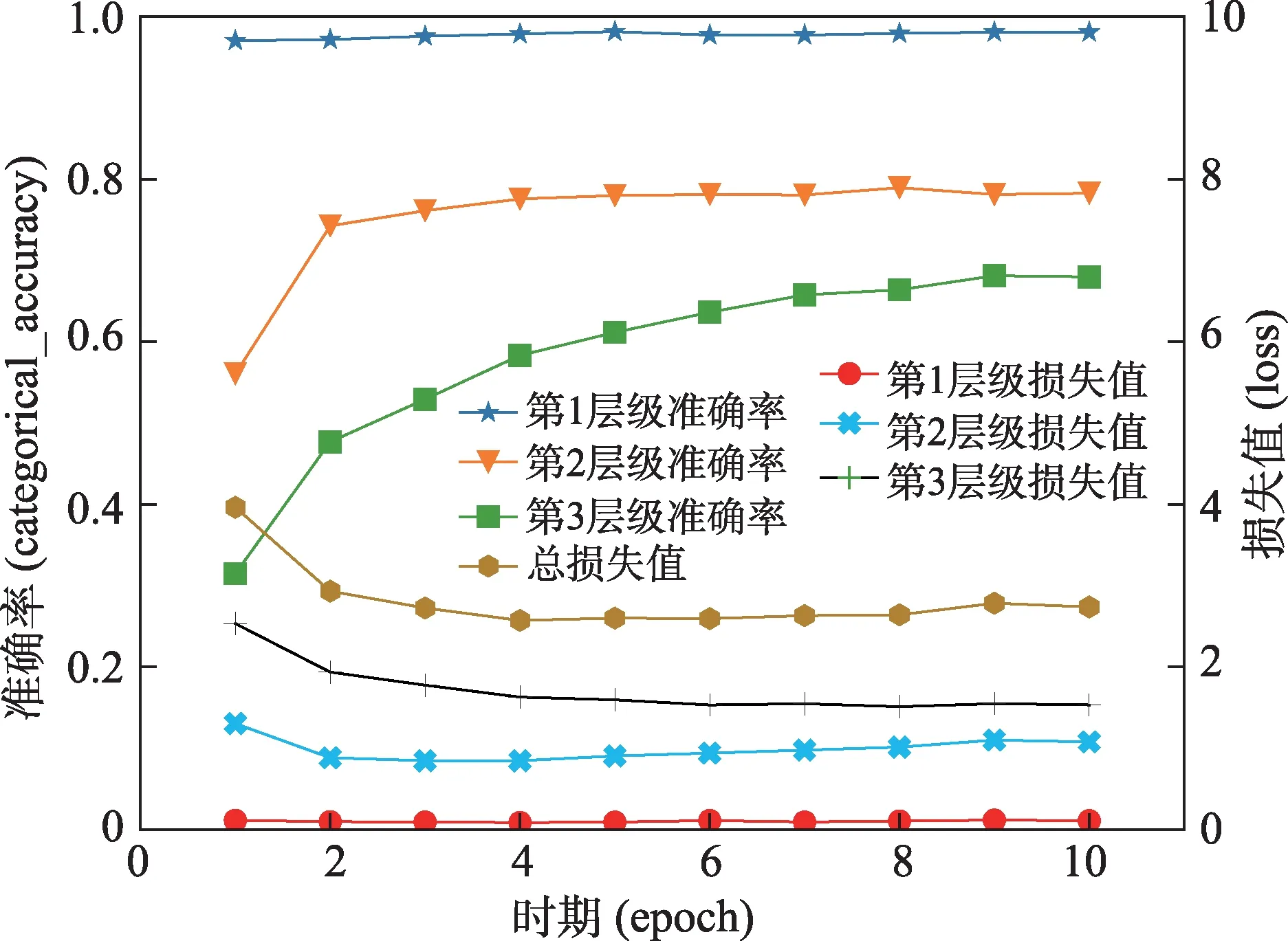
图5 模型损失值与准确率变化曲线
5 多层级分类模型效果对比验证
5.1 对比验证内容设计
(1)通过实验对比验证本研究UNT-HC 模型分类效果是否能够明显优于单层级多分类模型的分类效果。本研究最终目标是期望能够通过引入机器学习机制,识别出用户超细粒度信息需求主题,并以此实现细粒度专指性信息资源聚合,从而更好地满足用户个性化需求,其实质是对用户细粒度需求主题进行分类,以期通过利用“粗粒度-细粒度-超细粒度”层级结构关系来提升用户超细粒度信息学需求主题分类效果。为了验证UNT-HC 模型相较于直接进行最底层超细粒度需求主题的单层级多分类效果有显著提升,此项实验将利用两种模型在同样的数据集、词表征方法、参数配置等情况下,对数据集最底层标签进行分类并对比验证。
(2)通过实验对比验证在针对层级单标签分类问题时,UNT-HC 模型能否更优于现有的多层级分类模型。本研究将选择同样可针对层级单标签问题的HCCNN 模型和HFT-CNN 模型,经转换后,在使用相同训练集与测试集及评估指标的基础上,对样本数据集进行层级分类,并对比验证三种模型分类效果优劣。
5.2 单层与多层模型效果对比验证
为验证本研究模型UNT-HC 相较于单层级分类模型的分类效果是否有显著提升,本研究利用相同数据集对比验证了单层TextAttBiRNN 文本分类算法与UNT-HC 分类模型,其对比实验结果如表2 所示。

表2 单层与多层模型分类结果
由表2 可知,相比于直接对最底层标签预测的单层级分类算法TextAttBiRNN 而言,本研究模型UNT-HC 的分类效果有明显提升,其准确率提升了10.56 个百分点。如图6 所示,从单层与多层模型测试集最终标签预测的损失值与准确率变化曲线来看,单层模型在迭代至第6 次时强制提前结束,第4 次迭代之后,其损失值随着准确率的上升而上升,出现过拟合现象。
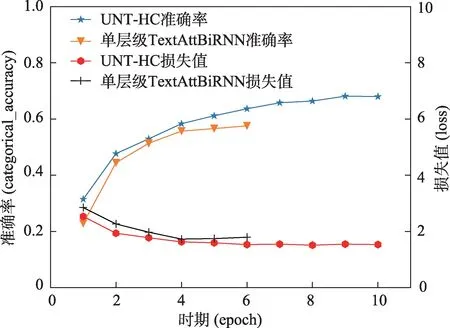
图6 单层与多层模型损失值与准确率变化曲线
5.3 多层级分类模型效果对比验证
为验证相较于现有的多层级分类模型HFT-CNN与HCCNN,本研究模型UNT-HC 的分类性能,在采用同一数据集的情况下,分别利用两种层级分类模型对其进行多层级分类训练与测试。经实验,HFT-CNN 模型和HCCNN 模型的最终标签分类结果如表3 所示。

表3 各层级分类模型分类结果
根据各层级分类模型最终标签分类预测准确率结果可知,本研究模型UNT-HC 相比于HFT-CNN 和HCCNN 模型的多层级单标签分类效果更优,其准确率分别提升了24.78 和15.95 个百分点。图7 为三种层级分类模型最终标签预测的损失值与准确率变化曲线,从图7 可以看出,HFT-CNN 模型在迭代至第5 次时被强制停止,第3 次迭代时模型达到最优,但其准确率与UNT-HC 模型相差较多,并且模型在第3 次迭代后,损失值逐渐上升,准确率逐渐下降。与此同时,HCCNN 模型在迭代至第8 次时被强制停止,当epoch=6 时模型达到最优,但其准确率与本研究UNT-HC 模型仍存在一定差距。
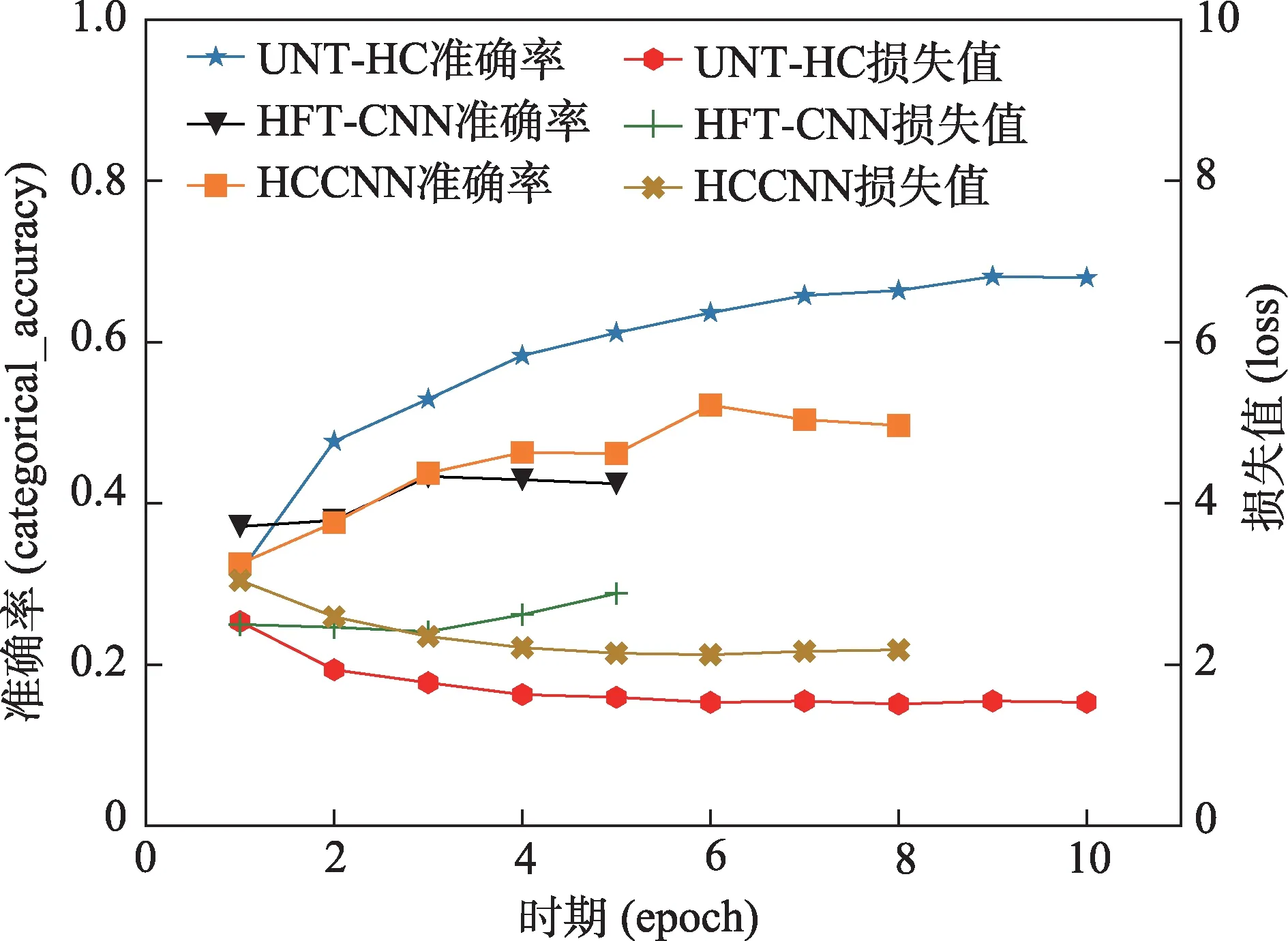
图7 三种层级分类模型损失值与准确率变化曲线
6 结 语
本研究围绕如何构建面向用户需求主题的在线问答社区信息多层级分类模型的核心目标,通过收集三大母婴问答社区妊娠期孕妇提问数据,采用内容分析与迭代编码的方法,构建了面向在线问答社区妊娠期孕妇的多层级、细粒度信息需求主题体系架构,并且利用已编码且验证通过的用户需求主题数据,对构建的信息多层级分类模型进行分类实验与模型效果对比验证研究,证实了本研究信息多层级分类模型在处理在线问答社区中多层级、细粒度、单标签分类问题方面具备相对较强的适用性和优越性。本研究主要工作与贡献体现在以下两个方面:①以在线母婴问答社区妊娠期孕妇信息需求数据为研究对象,构建了具备3 层结构,最底层覆盖51 类用户信息需求主题的在线母婴问答社区妊娠期孕妇多层级、细粒度需求主题体系架构,相较于现有母婴需求主题分类体系而言,本研究所构建的多层级、细粒度需求主题体系专指性更高,覆盖面更全,需求主题粒度更细,结构更清晰,构建过程及方法扩展性更强,能够推广应用至其他阶段或群体需求主题体系架构的构建过程中,构建的需求主题体系架构也能为UGC 模式下妊娠期孕妇健康信息需求领域研究,以及多层级信息分类服务导航、信息资源细粒度组织与管理等提供一定的理论参考与应用借鉴;②构建了面向用户需求主题的信息多层级分类模型,并且对比验证了该模型在多层级单标签分类问题方面的相对适用性与优越性,其模型或方法能够为在线信息服务平台优化资源聚合、提升用户体验、系统设计以及其他领域信息资源多层级分类任务提供一定的解决思路与方法支持。
然而,因时间成本、可操作性及自身理论水平等因素限制,本研究仍有一些需完善和改进之处:①本研究仅针对妊娠期孕妇构建了其需求主题体系架构,未进一步细化至孕早、孕中、孕晚期等阶段,也没有扩展至女性备孕期、产褥期等整个孕育过程;②在编码方案制定及需求主题命名环节,受可操作性等因素影响,最终未能够寻求或获取到母婴专业领域专家们的建议及意见,可能导致体系架构的结构、命名等缺乏一定科学性或权威性支撑;③本研究暂未采用最新的如图神经网络、动态词嵌入等模型参与模型构建与实验,后续将进一步利用最新的词嵌入及其基础分类模型完善实验,进一步优化本研究的效果;④在现实情况下,一条用户提问文本往往层级越低其需求主题概念标签越多,因而多层级分类问题的实质是一个更为复杂的层级多标签分类问题,而如何有效解决更为复杂且更契合实际的信息层级多标签分类问题无疑是本领域极具挑战性的前沿性问题。
