基于专利动态指标的新兴技术预测建模方法
——以癌症药物领域为例
2022-08-31杨冠灿卢小宾
杨冠灿,丁 月,徐 硕,卢小宾
(1. 中国人民大学信息资源管理学院,北京 100872;2. 北京工业大学经济管理学院,北京 100124)
1 引 言
新兴技术(emerging technologies)一直是技术创新管理、科技政策制定和技术竞争情报研究领域关注的问题。就技术创新管理而言,新兴技术识别可以作为先导研究以提升科研基金资助的效率,针对新兴技术演化模式的识别能够帮助企业降低资产与经营活动过程中的不确定性;就科技政策制定而言,新兴技术早期识别能够帮助科技政策制定者根据当前具有新兴技术特征的产业与技术的发展态势随时调整政策工具;就技术竞争情报而言,新兴技术布局无疑是动态技术竞争情报分析方法中判断企业、国家技术竞争力的重要依据[1]。近年来,随着大数据挖掘技术的兴起,针对海量专利数据的自动化新兴技术识别与预测,逐渐成为当前的研究热点。
新兴技术总是通过一定的载体来实现的,突出体现在:当大量技术从实验室走出后,就需要借用一定的政府管理权力获得市场技术的市场垄断权利,从而确保研究机构前期所投入的成本能够合理回收,而专利是保护这种垄断权利的有效手段。正因为如此,从另一方面来看,专利文献以及围绕专利实施各主体的行为包含了识别新兴技术的关键信号。因此,基于专利文献及各专利实施主体的行为所构建的指标是新兴技术识别的重要切入点。然而,新兴技术识别是一个复杂问题,即便假定基于专利文献及各专利实施主体的行为所构建的指标已经完整地包含了预测新兴技术出现的全部信息,但在实际建模过程中,仍需要考虑技术发展路径的不确定性、模糊性、颠覆性等因素。
制药行业是典型的高新技术行业,在该行业中,专利信号贯穿药物研发的始终。一方面,FDA(Food and Drug Administration,美国食品和药物管理局)授权的新药可以视为是药物领域的根本性创新;另一方面,在药物领域获得FDA 的药物许可与专利局的专利许可之间具有千丝万缕的联系。任何药物从研发到产品上市往往需要经历平均十年左右的研发、多期临床试验周期[2-3],近年来,一项新药的平均投入成本则更是高达十亿美元。因此,药物申请参与人往往都对专利申请、药物申请过程进行了细致的布局与规划,而专利指标能很好地将这些布局与规划行为纳入其中,能够预判技术的发展趋势。最后,药物产品要想上市需要同时获得两个机构的许可,核心新药产品对整个药物市场往往会产生颠覆性的影响,而癌症药物专利还具备一个优势,即该领域数据集具有非常好的开放共享特征[4-5]。因此,本研究选择癌症药物领域作为切入点,选择利用FDA 授权作为新兴技术预测的代理指标是合适的。
本研究的核心目的是识别未来哪些癌症药物专利最有可能成为新兴技术,这里,判断新兴技术的标准是该专利是否获得FDA 授权。基于这一思路,本研究希望在监督学习的框架下,识别哪些专利比其他专利更有可能成为新兴技术,以及评估模型在预测癌症药物专利授权后早期阶段的模型准确性。本研究的贡献主要在于:从前向视角(ex ante)进行预测而不是采用回溯视角(ex post),这种视角的变化使本研究在构建专利指标时更注重时序因素;对静态指标与动态指标进行区别处理,如设定前向专利引文、前向专利家族指标,从而能够更好地拟合新兴技术识别人员的真实业务场景中对早期新兴技术潜力进行预测的需求。
2 文献综述
2.1 新兴技术概念界定
虽然,新兴技术在很长一段时间内被很多研究者当做研究的主题,但是一直以来,科研人员对于什么才算是新兴技术并没有达成共识[6]。许多研究提出的新兴技术的定义和概念有所重叠,但同时指出了新兴技术的不同特点。Day 等[7]将新兴技术定义为一种基于科学的创新,认为这种创新需要有创建一个新的行业或改造现有行业的巨大潜力。Mar‐tin[8]则注重新兴技术的经济影响:认为新兴技术不仅应该对特定领域产生影响,还应该对整个社会经济体系产生影响,因此引入了新兴通用技术的概念,并强调了技术领域的广泛性和融合特征。考虑到新兴技术的不确定性和模糊性,Cozzens 等[9]将一项新兴技术概念化为一项表现出巨大潜力但尚未显示其重要价值或达成任何共识的技术。直到2015年,Rotolo 等[10]在研究中总结了新兴技术的五个关键特征,即新颖性、快速增长、一致性、显著影响以及不确定性和模糊性,对新兴技术定义和特点的争论才逐渐趋于统一。这项研究所归纳的特征被科研人员广泛接受,并成为了此后许多研究的前提和基础。
2.2 新兴技术识别方法
德尔菲法、情景分析法、技术路线图法、文献计量法、测度模型法等是技术预测领域较常用的方法。这些早期的新兴技术识别很大程度上依赖于专家智慧,如Delphi,以及大规模调查方法[11]。然而,专家判断会受到主观性不一致的影响[12]。随着技术的不断扩散和创新周期的缩短,以专家智慧集成方法变得耗时且需要大量人工劳动,而且无法应对技术融合导致的颠覆性技术涌现趋势[13-14]。因此,当前迫切需要基于大数据的数据挖掘方法来改进传统的新兴技术识别流程。
在基于专利进行新兴技术识别方面,从前的科研人员进行了多方面的探索。Érdi 等[15]提出了利用专利引文网络来识别快速发展的技术的结构性漏洞指标。Breitzman 等[16]开发了新兴技术集群模型,利用来自多个系统的专利引用信息来识别新兴技术。Arora 等[17]提出了一种更新的搜索方法,通过使用包含和排除术语来识别新兴的技术领域。Lee 等[18]提出将文本挖掘技术与局部异常因子相结合来识别新的专利。Moehrle 等[19]引入了语义专利分析来衡量专利之间的距离,以识别高新颖性发明。Yoon等[20]提出了一种基于主体-行动-对象(subject-ac‐tion-object,SAO)的语义专利分析方法,以识别快速发展的技术趋势。Joung 等[21]提出了一项基于技术关键词的专利分析来监测新兴技术。Ju 等[22]提出了一个质量功能部署(quality function deployment,QFD)框架,以促进对反映客户未来需求的新兴技术的研发规划。
考虑到新兴技术识别本质上是一个动态过程,一些学者更加关注新兴技术的动态。例如,Shin等[23]运用曲线拟合技术计算专利预计被引用次数及其方差,是分子放大技术未来收益和风险的代表。Lee 等[13]和Jang 等[24]提出了一种随机专利引文分析方法,利用未来的引文数量作为代表,评估图像叠加技术和分子放大技术在感兴趣的时间段内的未来影响。Lee 等[12,25]开发了一种随机技术生命周期分析方法,利用专利指标来检验和预测一项技术在其生命周期中的发展,并分别对分子放大技术和光刻技术进行了案例研究。
2.3 新兴技术识别维度
相比于无监督学习方法的结果可控性较低,基于监督学习的识别方法有其特有的优势[26]。基于监督学习的分类算法可以更好地面向识别场景,通过将新兴技术识别问题转化为寻找能够有效代表不同测量维度的特征并在此基础上构建模型的问题,能够更具前瞻性地识别新兴技术的涌现[1]。基于客观测量维度的新兴技术识别方法对整个新兴技术识别方法论体系的完善产生了重要影响,说明新兴技术识别方法开始逐渐考虑新兴技术的内核,并将识别流程模式化以更便捷地应用于新兴技术识别。这种思路能够通过不断改进指标的赋值和计算办法,可以促进提高新兴技术识别的准确性和效率。
前人对于新兴技术的特征、评价指标和识别方法都进行了许多有价值的探索,其中最为研究者广泛认可的是Rotolo 的观点。Rotolo 等[10]总结了新兴技术的五个关键特征,即①新颖性;②快速增长;③一致性;④显著影响;⑤不确定性和模糊性;该研究所归纳的特征在后续的研究中被广泛使用,并成为目前新兴技术识别相关研究的重要前提和基础。但需要注意的是,Rotolo 等[10]提出的特征在落实到具体的研究和应用方面存在一定挑战性,尤其对于“不确定性和模糊性”这一特征的内涵和量化方式,学界存在一定争议;此外,应当指出,诸如“快速增长”和“一致性”等特征需要随时间推移不断的监测才能加以界定,因此该框架在应用到早期识别方面也存在一定的困难。更重要的是,Roto‐lo 等[10]提出的框架是普适性的综合概念,但各个领域的新兴技术都有其独有的特征,因而,在对具体领域的新兴技术进行识别时,应考虑结合领域特征加以改进。
3 数据与变量
3.1 数据来源
本研究所采用的数据主要来源是“USTPO 癌症登月专利数据”(Moonshot Cancer Drug Patents),该数据对于本研究的重要意义在于:基于严格的专利检索策略给出了在USPTO(United States Patent and Trademark Office)授权专利(1980—2017 年)中癌症药物专利的边界,这一点非常关键,实际上,Wagner 等[27]的研究是基于药物数据(IMS Lifecycle R&D Focus Database)的,虽然也是合理的,但这与专利分析的传统流程不一致,即不是从大量技术领域的专利数据中直接做预测,而是从经专家检验过有可能获得药物许可的专利中去做预测,后者具有领域限制,但真实情景下,专利分析人员更有可能是在一个更广泛的数据范围内进行检索,利用预测模型在早期阶段对新兴技术进行研判。
“USTPO 癌症登月专利数据”包含了已发表的专利申请和已授予的癌症研究与开发(research &development,R&D)相关的专利的详细信息。该数据集是通过执行复杂的搜索查询和验证程序生成的,从而保证了检索结果的可重复,更详细的搜索查询可以参考文献[28]。同时,为了补充该数据集中的不完整信息,我们进一步借助PatentsView API、
EPO OPS API (European Patent Offices Open Patent Services API)对著录数据及专利家族信息进行了补充。另外,由于“USTPO 癌症登月专利数据”中的FDA 许可药物关联信息仅截至2016 年,因此,我们通过FDA 批准的药品数据(俗称“橘皮书”数据)补充了2016 年以后的癌症药物关系信息。
数据预处理方面,选取了27 万“USTPO 癌症登月专利数据”中授权专利信息,筛选后剩余自1980 年以来的111345 条记录;进一步地,根据FDA授权与否构建模型的因变量,其中,包含FDA 授权的专利授权数量为1275 条,未获得FDA 授权的专利授权数为110070 条。考虑到特别早期的药物专利在专利申请流程以及药物申请流程上可能和近期的数据存在较大差异,最终,选择2005 年1 月1 日—2015 年12 月31 日的数据。筛选后数据包含66241条,其中,FDA 授权的标签数据为838 条,FDA 非授权的标签数据为65403 条。
3.2 特征选择及指标
在特征选择时,本研究在自变量选择上主要考虑三个方面因素。首先,自变量能够反映技术的发展趋势或新兴技术某一方面的特征;其次,自变量需要区分为静态变量和动态变量,针对动态变量,根据需要前向视角的要求,采取迭代计算一项专利在其授权后1 年、2 年、3 年不同阶段,对应动态指标的动态增加量,同时,由于一项专利在其授权时可能已经会存在专利家族成员,而该指标也是非常重要的特征,所以单独计算该指标;最后,为了与之前的相关研究展开比较,本研究尽可能选取了先前研究中被广泛采用的指标[29-31],具体如表1 和表2 所示。

表1 预测模型的指标及解释
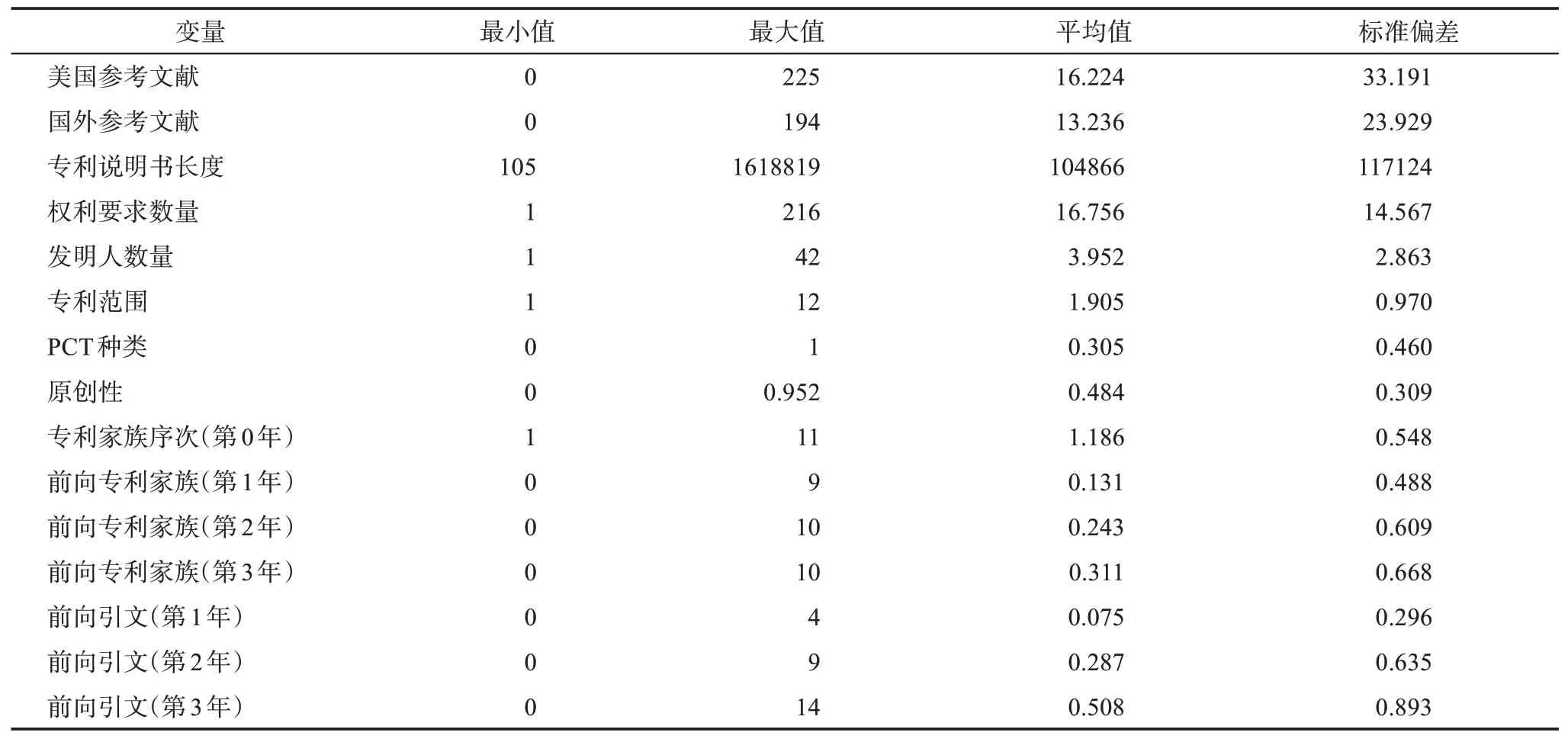
表2 变量描述性统计
4 方 法
4.1 从时间采样方法
本研究采用了从时间采样(out-of-time sam‐pling)的采样方法。这种依据时间的抽样方式是“留出法”(hold-out sampling)中的一种形式,该方法是一种定向的、非随机的留出采样,其目标是尽可能地使训练集和测试集的划分具有代表性,简单地说,就是用来自一个时间段的数据来构建训练集,而使用来自另一个时间段的数据来构建测试集[33]。从FDA 审批的特点来看,正好体现出如下特点:FDA 批准的成功率在过去几年中一直在变化,同时,由于癌症数据覆盖的时间很长,FDA 批准的一些专利的特征似乎也在演变。鉴于此,创建模型的目的是通过量化指标去识别未来的新FDA 授权成功的可能性,因而,分割时间最好接近当前日期,才能使测试集更贴近未来的情况,得到更加接近真实的模型效果。
因此,本研究根据从时间采样方法对训练集和测试集进行划分,这里有几点具体考虑。在模型选择时删除太旧的数据,只选取2005 年以后的样本数据作为数据集;根据指标的选择,选取3 年为度量动态指标的时间窗口,由于目前的专利信息更新到2019 年8 月,无法获得2019 年完整的数据,遂将不足1 年的2019 年的不完全数据进行排除,将2018 年年底作为截止日期,反向追溯3 年作为指标抽取的时间窗口(2015-12-31 至2018-12-31);最终,根据从时间采样方法,选取最近一年(2015-01-01 至2015-12-31) 的数据(7650 条) 作为测试集,以2015-01-01 为划分日期,将2015-01-01 之前的数据(54338 条)作为训练集。
4.2 非均衡数据采样
对于一般预测模型而言,如果通过采样能够获得代表原始数据的数据子集,就能够有效地提升模型的运行效率。但本研究中所面对的数据是典型的非均衡数据,如果不进行适当的采样,往往一般的分类算法就无法有效地开展分类,因此,对于训练集中的非均衡数据进行采样具有非常重要的作用。
本研究针对非均衡数据比例IR(imbalanced ra‐tio) =838/65403(训练集中),即少数样本(FDA授权专利)与多数样本(非FDA 授权专利)的情况,采用SMOTE (synthetic minority over-sampling technique)[34]采样方法,对少数类样本人工合成新样本添加到数据集中,达到消除少数类与多数类之间的数据分布不平衡的问题的目的。SMOTE 采样的具体思路[34]如下:
(1)对于少数样本,依次计算其中每一个样本到本类中其他样本的欧几里得距离,得到改为样本的k近邻;
(2)根据少数类与多数类之间的不平衡比例,设置一个过采样的倍率N,对于少数类中的每个样本x,从它的k近邻中随机地选取多个样本,假设选择的近邻为xn;
(3)最后,选择出xn后,进行新的样本集合的创建,其公式为
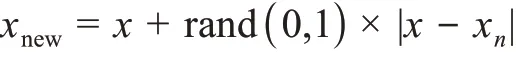
根据SMOTE 采样方法采样后,训练集中多数样本和少数样本达到均衡,最终,训练集中的样本数量为108795 项专利。进一步根据分层采样方法将训练集中的数据拆分为训练集和验证集,得到了训练集(76156,70%)和验证集(32639,30%)。对于测试集,没有采用SMOTE 采样,保持了原始的数据不均衡分布。
4.3 模型选择
本研究采用逻辑回归(logistic regression)模型对FDA 是否授权进行识别。选择逻辑回归模型的理由主要是基于两点:一方面,过去大量评价新兴技术形成、专利高价值评价的模型都是基于逻辑回归模型的[35-36],因此,选择逻辑回归模型有利于与过去的研究开展比较;另一方面,逻辑回归具有一定的模型可解释性,这一点使我们不仅能够知道不同模型最终的绩效,也能够了解模型所包含不同变量对模型的影响。
逻辑回归的基本假设是研究数据服从伯努利分布,该模型利用极大似然函数的方法确定模型参数,最终达到数据二分类的目的;逻辑回归的目的就是最小化预测可能性,其函数[36]为
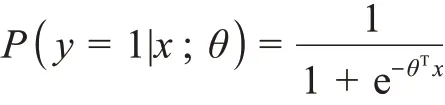
假设函数P(y=1)≥0.5 时,我们预测成正类;反之,预测为负类。在这里,本研究采用极大似然法来对参数进行估计。极大似然法(the method of maximum likelihood)是在知道随机样本满足某种概率分布,却又不清楚概率分布的具体参数的状况下,进行多次试验,观察试验结果,推出参数的大概值的一种参数估计方式,即在参数θ的可能取值范围内,选取使L(θ)达到最大的参数值θ,作为参数θ的估计值。
本研究设计了4 个不同的模型。模型1 只包含不随时间变化的变量。模型2~模型4 则在模型1 的基础上增加了一组随时间变化的自变量(即“前向专利家族”1~3 年,“前向引文”1~3 年),模型2~模型4 中增加的部分,分别是这组随时间变化的变量在专利授权后第1~3 年的对应值。
5 实证分析
5.1 专利指标的影响效果
本研究所采用的10 类15 个指标,所有指标的P值均小于0.001,说明其对模型结果作用显著。每类指标在模型1~模型4 中对模型结果的作用方向均保持不变,其中5 类指标一直发挥正向影响,5 类指标发挥负向影响,如表3 所示。
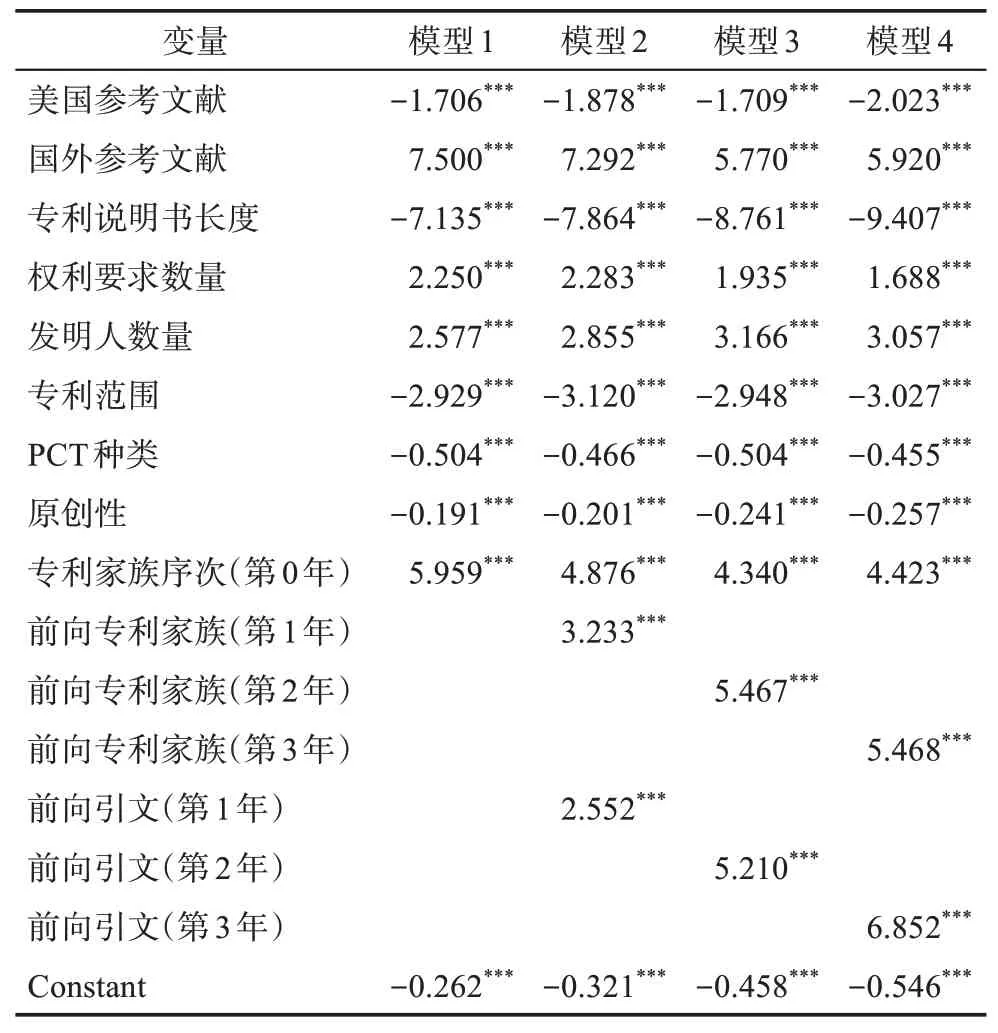
表3 变量影响系数表
在对模型发挥负项影响的5 类指标中,有4 类指标(“原创性”“专利范围”“PCT 种类”“美国参考文献”)对模型的影响力一直十分稳定,没有随动态因素的加入和时间的推移产生明显变化,其影响力大小几乎持平。“专利说明书长度”在模型1~模型4 中一直发挥着强的负向作用,且其负向影响力的大小随时间的推移而不断增加,其影响力增长速度基本保持稳定。
在对模型发挥正向影响的5 类指标中,“权利要求数量”随时间的推移呈现出缓慢下降的趋势,但总体而言,其在模型1~模型4 中的影响力基本保持稳定,变化程度很小。“国外参考文献数”在模型1~模型4 中一直发挥着较强的正向影响因素;在模型1~模型3 中,其正向影响力适中,位列第一;在模型2 和模型3 中,随着“前向专利家族”和“前向引文”影响力的增强,其影响力在明显下降后呈现出稳定趋势;综合来看,其正向影响始终保持在前两位。“专利家族次序”(即专利通过批准时的专利家族数量),这一指标在模型1 中发挥着较强的正向作用;其正向影响力的大小在模型1 和模型2中仅次于“国外参考文献”,而在模型3 和模型4中,其正向影响力较模型1 有一定程度的降低,排在第四位;综合来看,其影响力的大小基本保持稳定,变化幅度不大。
两个动态指标“前向专利家族1~3 年”和“前向专利引文1~3 年”,在模型2~模型4 中的作用均为正向,且呈现随时间推移的增长趋势。这两个指标在模型1 和模型2 中影响力增长幅度较大,在模型3和模型4 中影响力增幅相对较小。比较而言,前向专利引文的增长幅度强于专利家族,这与前人对于专利引文在预示专利价值方面的作用会随时间推移而增长的看法是一致的。经过时间推移,前向专利引文在模型4 中已经是正向影响力最高的指标了。“发明人数量”在模型1~模型4 中的正向影响力基
本保持稳定,其正向影响作用体现出发明人间的优势互补对于专利价值提高所具有的正向帮助。
5.2 模型效果比较
本研究采用了交叉验证的方式对数据进行了10次随机划分并重复试验,评估后取各项参数的平均值,从而进一步确保模型结果的科学性和准确性。交叉验证后,得到基于验证集的模型结果和基于测试集的模型结果,如表4 和表5 所示。
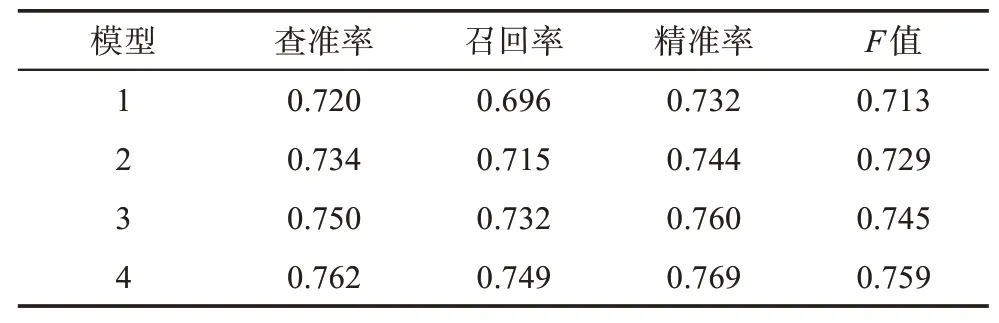
表4 基于验证集的模型绩效

表5 基于测试集的模型绩效
在模型1 的基础上,在模型2~模型4 中分别加入第1~3 年的专利家族年内增长量和第1~3 年的专利被引频次年内增长量。通过观察验证集的模型结果可以发现,模型的查准率、F值和召回率,均呈现出随时间推移的递增状态,其各个指标均在模型2 到模型3 间出现了最大的增幅。综合各项指标的趋势来看,我们可以容易地得出一个结论,在验证集中,模型效果随着时间的推移而逐渐变得更好,这证明随着时间的推移,动态指标中新增的信息对于预测模型而言是有益的。
观察测试集上的结果可以看到,模型1~模型4中各项指标均呈现了上升趋势。但一个值得注意的问题是,在对于FDA许可专利预测最关键的指标——召回率(recall)上,模型预测结果保持了与验证集相同的绩效;但在另一个指标——精准率(precision)上,则有较大的降幅,例如,在模型4 中,精准率仅有5.73%(66/1152),即模型4 总共预测了1152 个样本为正样本(即FDA 许可),但仅有66 个专利最终获得FDA 的许可。事实上,对于本例中所针对的癌症药物预测模型而言,召回率和精准率的意义并不是完全等同的,实践中我们更关注于能否尽可能将那些具有市场潜力的癌症药物专利都提前预测出来,这可以帮助企业在市场竞争方面取得极大的优势,从这个意义而言,召回率无疑是关键的,且结果支持了该观点;精准率低则意味着预测可能存在一定程度的错误,即将一定比例最终未能市场化的专利预测了出来。精准率低会最终影响企业的决策成本,但对企业商业决策的影响要弱于召回率。
另外,该问题是典型的数据极度不均衡导致的,对于这种问题最终评判的标准不能仅依赖查准率(accuracy)或者F值(F-measure),需要综合来评价。我们进一步引入提升法来衡量模型的有效性,提升(lift)是“运用该模型”和“未运用该模型”所得结果的比值。图1 显示了模型4 的提升图和累积提升图,该图是衡量模型性能的可视化辅助工具。提升图的横坐标展示的是模型4 对测试集进行预测的全部结果,以及按照预测概率从高到低排序的结果;纵坐标则展示的是提升值,即“运用该模型”和“未运用该模型”所得结果的比值。根据图1 显示,在模型预测前10%具有高概率获得许可专利时,在其预测结果的准确性上,模型4 较随机模型有6 倍以上的优势;而当模型预测前20%具有高概率获得许可专利时,模型4 的预测优势仍然明显(接近2 倍),观察累积提升曲线,如果我们设定判定获得许可专利的概率阈值为0.5,模型4 仍有2 倍于随机模型的优势。因此,尽管F值和精准率(precision)不理想,但通过结合提升图,我们有理由确认基于动态指标所构建的模型是有效的。
为了进一步验证模型的效果,本研究构建了模型的ROC曲线(receiver operating characteristic curve),如图2 所示。在二分类任务中,AUC (area under curve)值是一个概率值,是指根据当前的分类算法,随机抽取一对正/负样本,模型将这个正样本排在负样本之前的概率大小。因此,AUC 被用来表示模型准确性,AUC 值越高,也就是曲线下方面积越大,算法越有可能将正样本排在负样本之前,说明模型准确率越高,分类效果越好。从图2 可以观察到,模型1~模型4 的有效性呈递增状态,其AUC值均大于0.8,说明其具有较高的识别效力,且模型识别效力随其动态指标取值时间的推移而增强。整体而言,从模型1 到模型4,模型的绩效是在不断提升的,这说明,模型2 到模型4 过程中,增添的时序变量对模型预测绩效起到了正向的作用。
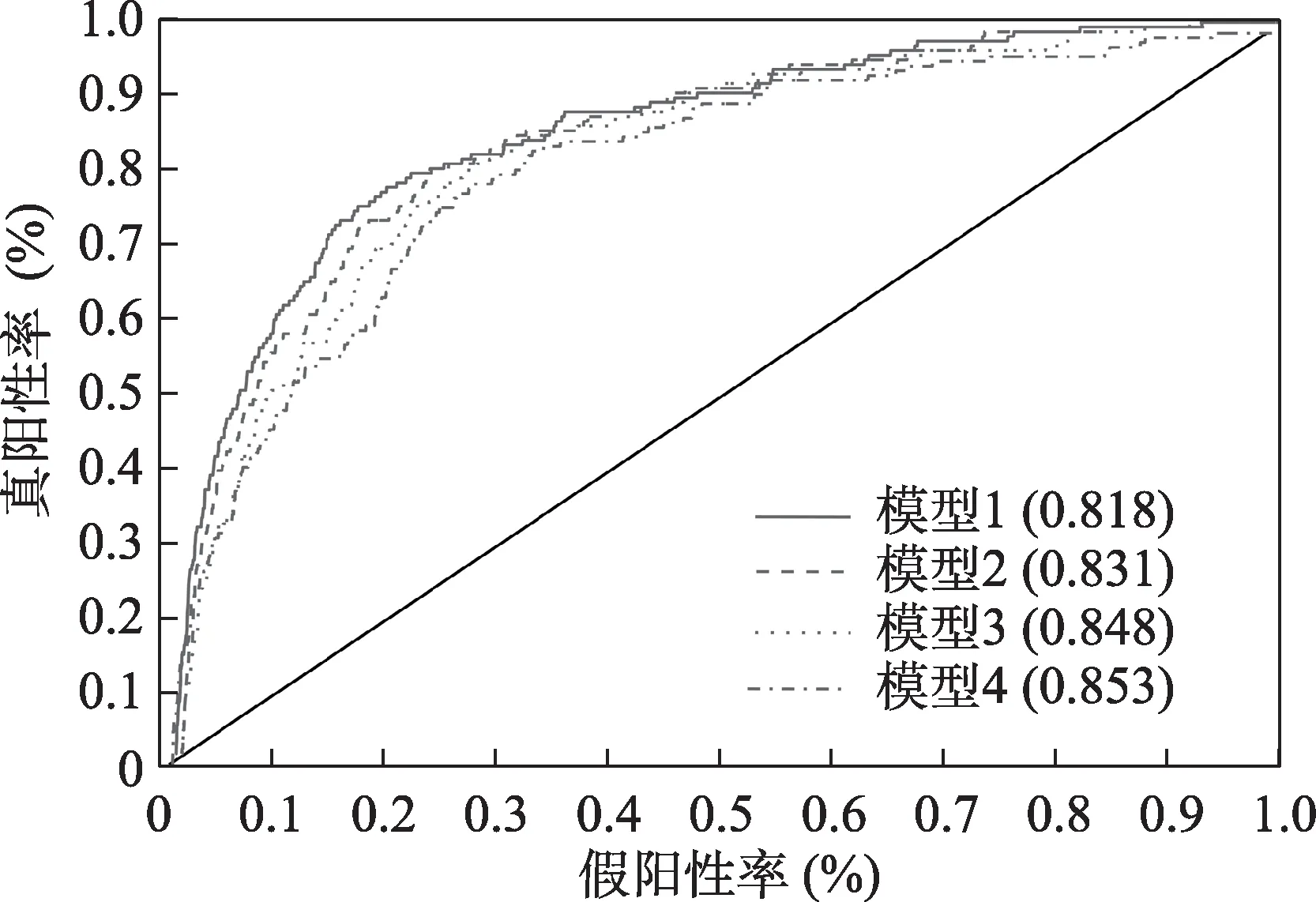
图2 多模型的ROC曲线
5.3 与现有结果的比较
Su 等[2]在2018 年发表的文章中针对专利指标对FDA 授权可能性进行了研究,其基于美国批准的药物专利,从知识、合作、法律3 个维度选取了13 个专利指标,通过probit 模型和Cox 比例风险模型,分别检验了不同维度的指标在药物获得FDA 授权概率(即商业化的可能性)以及药物获FDA 授权速度(即商业化的速度)两个方向上的作用效果。上述研究结果可以作为对照组,验证本研究的效果。
首先,在指标构建上,Su 等[2]采用的是较为传统的指标度量方式,利用某一时间节点的截面数据;而本研究充分考虑了自变量指标随时间的变化情况,参考时间因素,设置了两组动态指标。其次,本研究聚焦于研究专利授权后3 年内的新兴技术潜力,而Su 等[2]的模型采用了5 年和10 年引文的观察视角,这种测量指标更适合回溯式评估而并不利于构建早期预测模型。最后,从测量结果上而言,Su 等[2]构建的模型得到的ROC-AUC 的4 个值分别为0.733(模型1)、0.748(模型2)、0.732(模型3)和0.747(模型4),其模型准确率(AUC 值)为74.7%;而本研究中,测试集的AUC 值分别是0.818(模型1)、0.831(模型2)、0.848(模型3)、0.853(模型4),更高的AUC 值体现出本研究模型的有效性,也说明了构建动态指标的合理性,以及利用专利指标开展新兴技术预测模型的可行性。
6 结论与展望
6.1 结 论
本研究通过更系统的引入动态专利指标,改进了专利指标在预测新兴技术方面的时滞特征,实现了癌症药物领域新兴技术的早期识别,弥补了前人研究往往是事后识别的时滞性缺陷,在新兴技术的事前识别这一方向上做出了有效探索。
本研究创新性地在专利指标设计中加入了时间因素的考量,相对于传统专利指标往往采用某一时间点上的截面数据,加入了时间因素动态指标的设计使指标能更好地体现随时间变化的变量在不同阶段所具有的不同信息价值,使其更符合指标内涵随时间变化的实际特点。经对比验证发现,加入了时间因素的动态指标相比于截面指标,在新兴技术识别方面发挥了更好的识别作用。
相较于前人研究,本研究采用了更权威而完整的数据集,并且依据癌症药物领域的实际情况补充了相应的记录,建立了更加大规模且贴近实际情况的试验基础,使本研究的结论更具真实性。将本研究的模型结果与前人的研究对比,发现较前人的研究取得了更好的模型效果,说明模型在提高时效性的同时并没有牺牲有效性,对未来的研究者进行模型构建具有一定参考价值。本研究发现,静态指标中,“国外参考文献”指标对于新兴技术有很好的识别效果,“专利说明书长度”与新兴技术间有显著的负相关关系;动态指标中,“前向专利家族”和“前向引文”的识别能力在专利获批前3 年内会随着时间推移而增强。
6.2 展 望
本研究存在一些局限性,需要在未来加以改进和优化。本研究的核心目的是初步探索基于专利的指标是否可以帮助识别专利成为新兴技术的可能性。结合癌症药物领域的特点,本研究选择FDA 是否授权作为新兴技术的代理指标,FDA 是目前看来能够代理新兴技术的优选指标,但也许存在其他更科学的代理指标未曾被发现和使用,在未来的研究中有待进一步探索。
本研究更注重建立一个可解释的模型,为后续的研究提供一些有启发性的见解,而不仅仅是关注模型的准确性问题。虽然目前的模型已经达到了可以判断其有效的基线,但在一些方面还有较大的提升空间。当前,神经网络和文本挖掘等技术已被证明能有效应对此类分类问题,所以下一步应该考虑使用更多数据驱动的复杂融合性方法,构建新框架来提高模型的效率。
本研究将时间窗口期限定在了1~3 年,这既是出于想要在早期对新兴技术进行识别,尽量提前判断时间的考量;也是出于希望能够使用更近期的数据对模型进行训练和测试,使其更符合当下的实际情况。但是,3 年的窗口期可能不足以观测动态指标随时间变化的准确趋势,未来可进一步扩大时间范围,以期得到更深入的见解。
