基于文本挖掘的微博文本情绪分析技术研究
2017-05-06戴天翔岑鑫柳珺文王帅欧阳帆
戴天翔+岑鑫+柳珺文+王帅+欧阳帆
摘 要:该文主要针对中文微博的细粒度情绪识别技术中的关键技术展开研究,分析了中文微博的研究难点和微博情感表达特征,提出了一种微博文本情绪显性特征的多策略集成分析法。最后实验组以新浪微博中某一主题为实验数据,对“乔任梁去世”事件这一热点话题的评论文本数据集进行分析,验证了该文的微博情感分析能力,同时还将情感分析结果进行了可视化展示。
关键词:微博 情绪 细粒度 分析
中图分类号:F83 文献标识码:A 文章编号:1672-3791(2017)03(a)-0209-04
近几年随着网络通信技术的发展,微博已经逐渐成为人们喜欢使用的交流工具。人们喜欢在微博上抒发自己的情绪、表达自己的观点。正因如此,大量充满真实感情的微博文本已经悄悄地成为了情绪分析的重要资源。总而言之,微博是一种高度社会化的传播平台:它集中了人们广为熟悉的3种沟通方式——电子邮件、即时通信工具、媒体的优点,又都赋予他们社会化特征[1]。
中文微博是该文的研究对象,在微博的情感极性判断上是目前国内所集中的研究方向,如分析微博表达是正面还是负面,此类研究已经取得了一定成绩并开始广泛应用,然而若要获取微博表达的更细致的情感时再采用传统的粗粒度分析已经无法满足。该文介绍了一种微博情绪细粒度分析方法,并对使用上述方法,进行了相关实验,并给出了实验结果。
1 中文微博细粒度情绪分析研究主要相关技术
在1995年由麻省理工学院的Picard教授在其论文Affective Computing中提出了情感分析的概念,是指对于意见,情绪和情感的计算研究,同时情感分析也被称为情感探测、情绪分类或意见挖掘等[2]。中文微博细粒度情绪分析研究所要达到的任务目标为:输入一整条微博,要求系统去判断出这条微博中是否包含情绪。本文通过研究多策略集成分析,先对中文微博文本进行预处理,再将细粒度情绪分析任务分为两个部分。首先为微博的有无情绪两类判别,这一部分中主要采用基于迭代的朴素贝叶斯分类算法,无情绪的微博输出为NONE,有情绪的微博将进入第二个部分。第二步为对分类为有情绪的微博进行七类细粒度情绪的识别,输出为害怕、喜欢、生气、厌恶、伤心、惊喜、幸福着七类情绪中的一种,该步骤中的主要采用方法为KNN算法。
1.1 细粒度情绪特征表示及权值计算
词是中文微博文本中最为主要的元素,在文本分析研究中一般是将文本表示成词向量,然而具体到中文微博的情绪分析中,由于情感词是本研究所要主要关注的对象,所以该研究是将每条微博表示成有关情感词的向量。但是,因为中文微博具有短文本的特性,所以每条微博一般只包含了很少量的情感词,而中华汉语言的情感词库又极其庞大,情感极其丰富,这样所表示出来的微博语料向量矩阵将会非常稀疏,这是不愿看到的情况,在这种情况下不单单会让计算变得异常复杂,带来巨大的维数灾难,更严重的是会对分类性能造成十分严重的不良影响。
该文介绍的一种解决方法是基于大连理工情绪本体库中定义的21个小类情感[5],这种方法的大概思路就是将每条微博表示成维度为21维的向量,每一维度对应于21个小类情感中的一类,简而言之就是选择大连理工情绪本体库中固定的21个小类情感作为每条中文微博的特征。21类情感[5]为快乐(PA)、安心(PE)、尊敬(PD)、赞扬(PH)、相信(PG)、喜爱(PB)、祝愿(PK)、失望(NJ)、疚(NH)、恐惧(NC)、羞(NG)、烦闷(NE)、憎恶(ND)、贬责(NN)、愤怒(NA)、悲伤(NB)、妒忌(NK)、思(PF)、慌(NI)、怀疑(NL)、惊奇(PC)。这样就可以使得微博语料的特征矩阵变得不再稀疏,从而方便了计算,达到了降维的目的。
1.2 基于迭代的朴素贝叶斯有无情绪分类
朴素贝叶斯学习理论是一种基于假设先验知识的学习方法[3],该算法的思想是对于等待分类的那些文本,去计算出这些文本在该特征项出现的情况下各种情绪类别出现的概率,最后依据情绪类别的概率来进行划分。在预测一次抛硬币得到正反哪一面的實验中,正反两面出现的概率为均等的先验知识,由一定的背景知识所得到的初始概率值就被称为先验知识。在很多朴素贝叶斯分类的实际应用中,先验知识通常是由训练集中的各类样本所占总样本的比例得到的[4]。例如,在有无情绪二分类中,先验概率可由如下公式得到:
(1)
当i=0时,P(h0)等于无情绪微博样本数n0比上所有的微博样本数N,表示无情绪微博先验概率,当i=1时,P(h1)等于有情绪微博样本数n1比上所有的微博样本数N,表示有情绪微博先验概率。
该文介绍的这种基于迭代的朴素贝叶斯分类算法[5],其主要思想是在实验人员手头上有大量的待测试集合的情况下,但已标明注释的训练集偏少,就可以利用大量的待测试集合的数据来弥补这些不足之处,具体的过程,可先通过上文公式计算,获得假设先验概率,然后利用朴素贝叶斯公式对测试集进行第一次分类,接着将本次分类得到的结果再一次作为先验知识重新计算先验概率,这就完成了第一次迭代,如此反复迭代直至分类器的分类精度收敛至最大值或者迭代次数超过10次。
2 实验设计
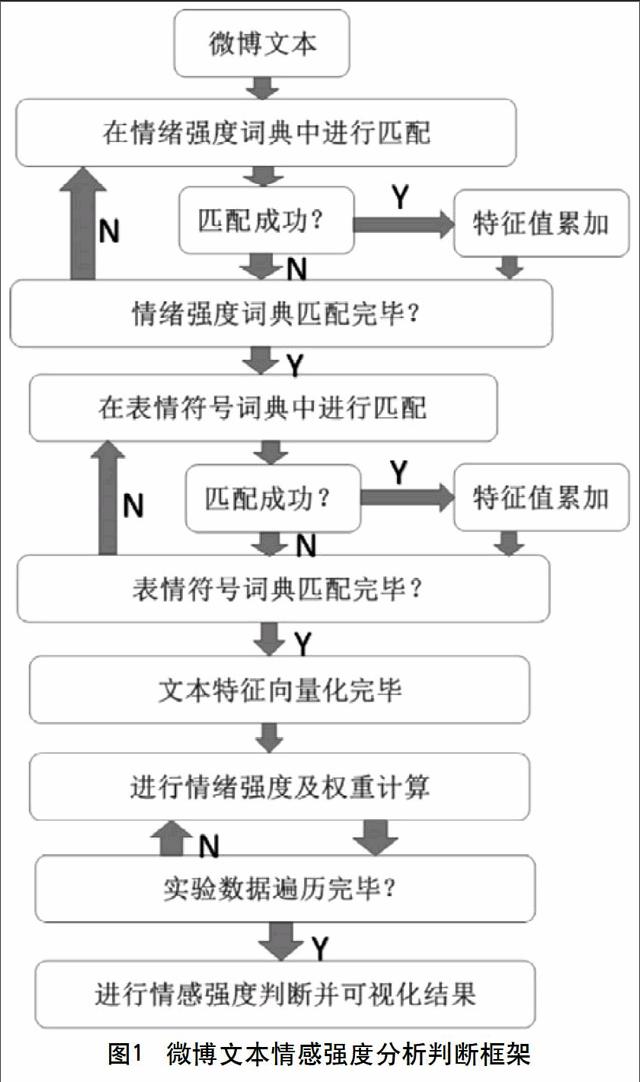
2.1 微博文本情感强度判断分析框架
首先介绍实验组所设计的分析框架如下:
(1)文本预处理:构建情绪词典、表情符号词典,对微博文本进行特征提取、停用词去除、文本特征向量化等工作,将微博文本表示成可以用于机器学习的格式。
(2)情绪特征权重及强度计算:对特征项量化的文本按照一定公式进行情感强度计算。
(3)情感强度判断:按照所计算出的Intensity值进行微博文本的情感强度判断并给出可视化结果。
分析框架图如图1所示。
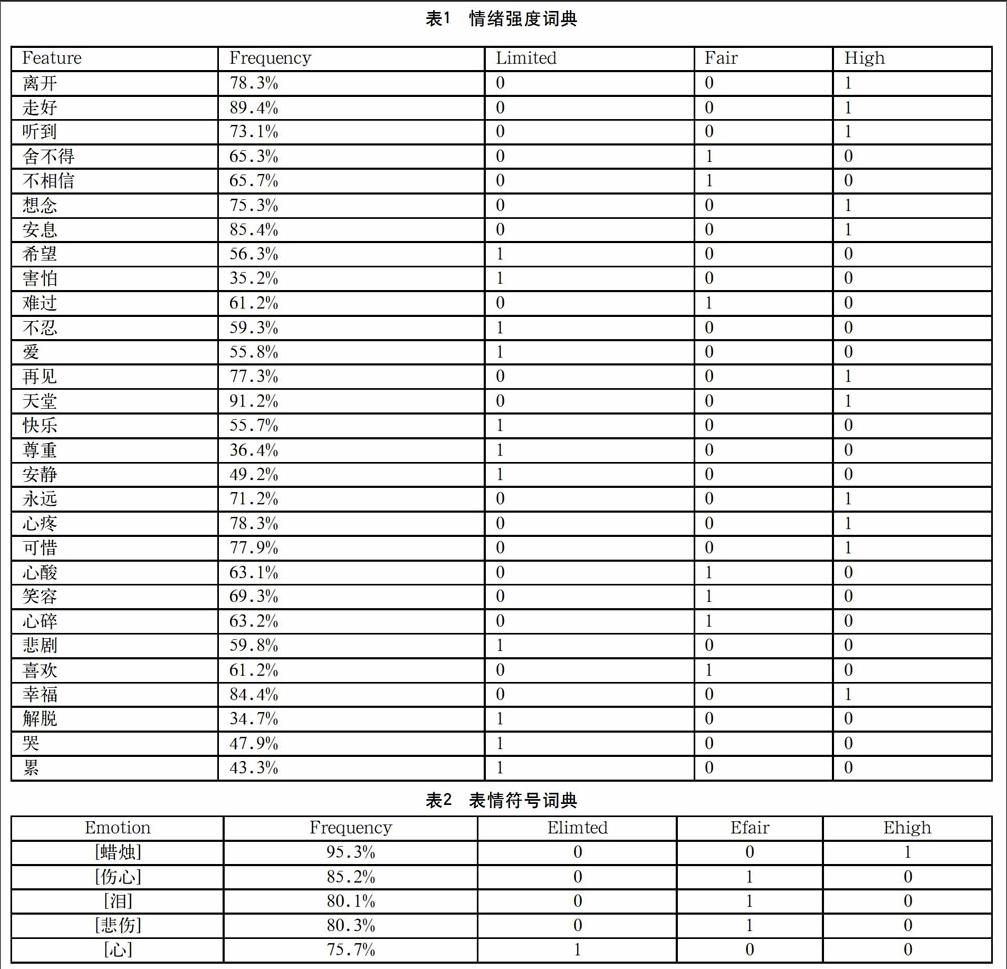
2.2 构建情绪强度词典
根据实验所抓取微博文本特性,根据某些特征词汇在人工判定为“有情绪的”实验文本数据中出现的频率,人工挑选出30个特征词,并经研究进行了对于“悲伤”这一情绪的强度判定,分为3个强度,即“有限制的”(Limited)、“中等”(Fair)、“高”(High)。實验组在统计基础之上,将词频在70%~100%的特征词划分为“High”类,将词频在60%~70%的特征词划分为“Fair”类,将词频在60%以下的特征词划分为“Limited”类,构建情绪强度词典如表1所示。
2.3 构建表情符号词典
表情符号是中文微博情绪分析中非常重要的显性情绪特征之一,实验组在进行文本数据的特征词识别之后,经过人工统计和判断,将所选取的微博文本中出现频率较多的表情符号进行了整理和划分,并分配了不同的情感强度,构建表情符号词典如表2所示。
2.4 构建停用词库
停用词是做文本分析中需要去掉的对分析无用处的词。在很多文本分析应用中,停用词库中的词一般尽可能多的覆盖到无实际含义的词汇。但在实验组的情感强度分析中,我们选用最简单的停用词库,诸如“你、我”之类的人称代词及与情绪无关的词一律去除。
2.5 文本预处理(特征项量化)
抓取实验文本后,实验组将其存储为txt格式,并将每条微博文本分配一个独立的ID,经过特征词提取、表情符号提取、停用词去除等文本预处理工作,将其转化为下列类对象的形式:
class FeatureVector{
int Limited;//情绪词典中Limited所占值
int Fair;// 情绪词典中Fair所占值
int High;// 情绪词典中High所占值
int Elimited;//表情符号词典中Limited所占值
int Efair;//表情符号词典中Fair所占值
int Ehigh;//表情符号词典中High所占值
int Intensity;//权值
};
2.6 情感强度特征向量表示及强度计算
经过文本预处理之后,每一条微博文本都转换为
(2)
其中,每个特征参数的权重Weight由人工统计进行给定。
3 实验结果与分析
3.1 实验环境
编程语言:C++
实验软件:Visual Studio 2013
实验系统:Windows 8.1
3.2 实验数据获取
实验组从新浪微博中选取了“乔任梁去世”这一主题的评论数据作为实验数据集,利用手工方式抓取微博文本,共抓取了1500条实验数据。
3.3 实验设计与分析
由于实验抓取的数据经人工判定,共99.6%的评论属于悲伤一类情绪,因此实验组主要针对实验数据进行情感强度分类,参考文本特征选择算法进行实验。
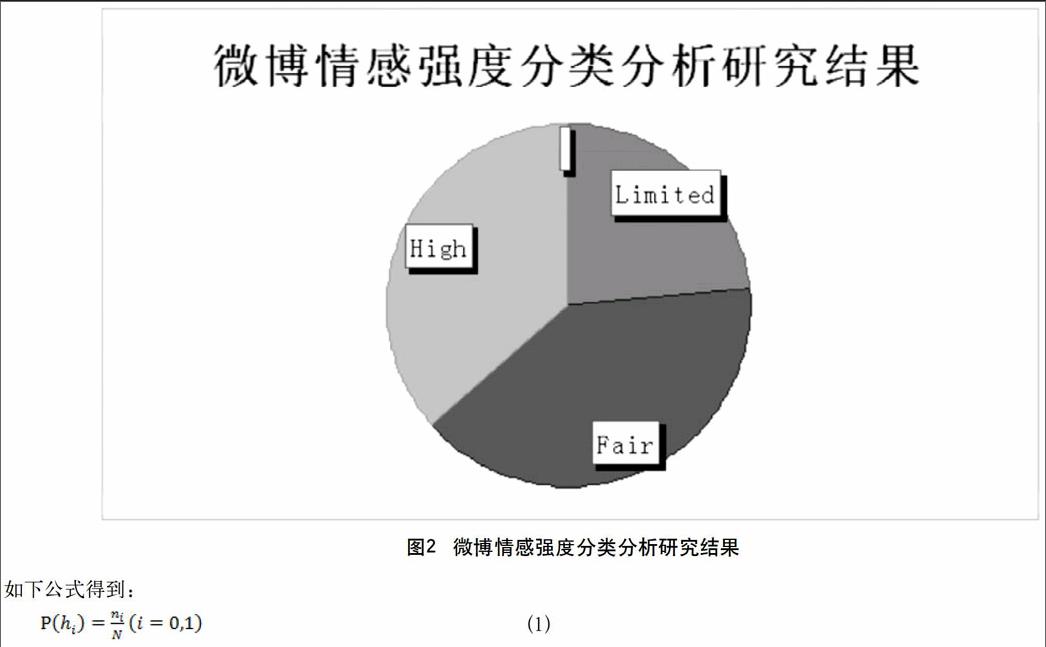
3.4 情感强度分类判断及可视化结果
实验组将“悲伤”情绪强度分为3种,分别为“Limited、Fair、High”,经过权重计算,将每条微博文本的Intensity值按一定比例进行了分类,实验数据经过机器学习判断,结果如图2所示。
4 结语
(1) 基于中文微博情绪分析国内外发展现状,阐述研究背景和研究意义;然后介绍了一些中文微博文本细粒度情绪分析所用的理论知识及技术手段。
(2) 参考现行的理论技术手段,对1 500条同主题的新浪微博进行了情感强度分析研究,根据所抓取微博文本特点,构建了实验情绪词字典、表情符号字典以及停用词字典,对微博文本进行预处理工作,是微博文本特征向量化。根据特征计算权重公式对特征向量化微博文本进行情感强度分析判断,并给出实验结果。
参考文献
[1] 李开复.微博改变一切[M].上海财经大学出版社,2010:26-74.
[2] Picard R W.Affective computing: challenges[J].International Journal of Human Computer Studies,2003,59(1):55-64.
[3] 王国才.朴素贝叶斯分类器的研究与应用[D].重庆:重庆交通大学,2010.
[4] 雷龙艳.中文微博细粒度情绪识别研究[D].湖南:南华大学,2014.
[5] 徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报,2008,27(2):180-185.
