融合引用语义和语境特征的作者引文耦合分析法
2022-08-31张汝昊袁军鹏
张汝昊,袁军鹏
(1. 中国科学院大学经济与管理学院图书情报与档案管理系,北京 100049;2. 中国科学院文献情报中心,北京 100190)
1 引 言
作者引文耦合分析(author bibliographic coupling analysis,ABCA)[1]已经在情报学界得到广泛应用,在发现活跃作者群体与学科知识结构[2-3]方面取得了良好成效。但该方法的作者引文耦合强度仅依赖于简单的引用次数统计,由于引文分析的固有缺陷[4],不论耦合双方出于何种目的共同引用一篇参考文献,都将被均等计入两者的耦合强度,这样的耦合强度是具有风险的、不准确的。随着开放获取和文本挖掘技术的发展,深入施引文献内部对引文全文层面的信息进行挖掘已成为可能,这为完善引文分析法及其前提条件带来了契机。目前国内外已在论文层面开展了利用引文全文特征优化共被引关系的研究[5-7],如何利用引文全文特征推动作者级引文耦合关系的改进,仍有待探索。
本研究提出一种融合引用语义和语境特征的作者引文耦合分析法(semantic- and contextual-based author bibliographic coupling analysis,SC-ABCA),试图利用丰富的全文本资源,从施引动机的相似性这一本质层面,优化现有依赖于简单次数的引文耦合关系强度。该方法通过挖掘学术论文中引用句在全文层面具有的语义特征(如主题内容)和语境特征(如引用位置、引用强度)并作有机融合,比较耦合双方施引句全文特征间的相似性,计算增强型引文耦合强度,为每一次引文耦合赋予差异化的权重;通过“论文-主题-作者”聚合映射考虑作者在各研究场景中的引文全文特征,修正已有方法忽视作者多元化兴趣的问题,从而获得更深层、稳定的作者间研究主题相似性度量,为细致的作者兴趣社群发现提供可能。进而以中文“图书情报与数字图书馆”为实证领域(简称“图情领域”),基于中国知网提供的13562 份HTML 格式全文数据开展对比实证和量化评估,探索这一改良方法的实际应用特点及效果。
2 相关研究现状
本研究通过对引文全文特征的挖掘与利用优化作者引文耦合分析,这主要涉及改进的目标领域“作者引文耦合分析”和方法来源领域“全文本引文分析”,本节将简要回顾两个领域的研究现状。
2.1 作者引文耦合分析
引文耦合(bibliographic coupling,BC)理论起源于Kessler[8]的发现:当两篇论文拥有越多共有参考文献时,它们具有越强的主题相关性。2008 年,Zhao 等[1]将其拓展至作者层级,提出了作者引文耦合分析(ABCA)。在ABCA 中,对于两个作者的参考文献交集,取两个作者引用其中每一篇参考文献较少一方的次数累加和作为两者的引文耦合强度,以此揭示作者间的研究主题相似性[1]。Rousseau[9]在2010 年对ABCA 的理论概念进行了界定和阐明,马瑞敏等[10]对ABCA 关系强度算法进行了归纳。随后的众多对比研究发现ABCA 善于刻画当前研究领域活跃作者的研究兴趣交叉,证实了其对探知学科的前沿结构的效果及可拓展性[11],甚至在特定领域中的精确性要优于ACA (author co-citation analysis)和其他作者关联分析方法[12-13]。近年来,有研究尝试通过修正耦合条件[14]、加入时间因子[15]、融合关键词矩阵[16]对ABCA 进行改进,但这些改进仅使用外在著录信息,并不能从引用内容这一源头上真正解释引文耦合发生的内在机理,因而改进效果往往有限。
2.2 全文本引文分析
全文本引文分析(full-text citation analysis) 或称引文内容分析(content-based citation analysis),是为应对现有引文分析法缺陷而诞生的新一代引文分析方法[17]。其将引文分析的范畴进一步延伸至全文层面,量化引用所体现的影响程度和方向,从而为精细化学术行为研究和影响力评价、精准化科学态势识别提供有力支持[18]。
目前国内外已有较多全文本引文分析的相关研究,包括引用强度(count-X)[19-21]、引用位置[22-25]、引用主题[26-29],以及引用功能(包含情感)[30-34]、引用范围[35-37]、引用篇章结构的自动化识别[38-41]等。利用引文全文本特征对ACA 等经典方法进行改良,是该领域中的一个特殊方向。许多研究发现,在纳入共被引位置距离[5,42-44]、共被引句子相似性[45-46]甚至综合利用多种全文本特征后[7-8,47],共被引分析将获得更佳的聚类精度和学科知识结构发现结果。然而,当前面向引文耦合理论的改进却极为稀少,少数研究表明这种改进应用在基于BC 的文献推荐时也同样有效[48]。本课题组近期的一项研究以肿瘤学为实证领域,利用全文层的多维数据对ABCA 进行了初步改进[49],但仍存有不足与遗留问题,例如,仅使用不稳定的次序索引作为引用位置表征,尚未考虑作者的多元化研究兴趣等;此外,由于实证领域可能存在特殊性,引文全文本特征是否可为AB‐CA 带来分析效果的提升、提升的程度如何,仍需广泛的实证研究予以回答。
3 融合引用语义和语境特征的作者引文耦合分析法
本研究提出的SC-ABCA 是一种改良型作者引文耦合分析方法,相较于ABCA 及已有的修正方法,其主要特点是不再依赖于外在著录信息,而是通过挖掘耦合双方的全文文本,综合应用引文在全文层面丰富的引用语义和语境特征,细化、深化ABCA 的分析效果。此处的引用语义特征是指参考文献在全文范围内被施引文献单次或多次引用时引用内容文本具有的主题性特征,即能够回答“引用了什么”这一问题;而引用语境特征则指参考文献在全文范围内被施引文献引用时的结构性特征,即能够回答“在何处引用”“引用的重要性如何”这些问题。引用语义和引用语境从不同维度互补地表征了施引文献对于参考文献的具体使用情况,SCABCA 旨在综合利用两者对作者引文耦合关系进行更精细的剖析与更加深入的优化。
SC-ABCA 包含全文数据的抽取与处理、增强型引文耦合强度计算和“论文-主题-作者”聚合映射三个关键环节,流程如图1 所示。
3.1 全文数据的抽取与处理
3.1.1 全文数据抽取
对半结构化科技论文全文本进行解析是SC-AB‐CA 计算开展的基础。以中国知网提供的HTML 全文本格式为例,对于自定义数据库中的每一篇论文,首先通过class 值为“sup”的标签为每一条参考文献进行全文范围内的一处或多处定位。针对每处定位,除基本信息外,进行两类关键数据的提取。
(1)引用内容文本。以定位引用标签为中心,向左、向右寻找具有句子界限特征的句号或分号,拼接形成完整的引用句。由于引用标注、HTML 页面制作具有多种标准,本研究制作了大量正则表达式规则以应对多样的引用格式。此外,参照先前的相关研究结果[35],在引用句字符数过短(不超过30字符)的情况下,将引用内容文本的前后各一句纳入引用内容文本范围。
(2)引用位置抽取。以定位引用标签为起点,向前搜寻章节标签
获得章节标题,利用当前章节的基本特征通过标准化章节映射机器学习模型(参见3.1.3 节)获得章节类型。
提取完成后的数据示例如表1 所示。

表1 数据抽取示例
3.1.2 语言模型预训练
SC-ABCA 涉及引用语义相似度的计算,需要适当的自然语言处理工具提供词分布式表示支持。先前研究中常用的TF-IDF(term frequency-inverse doc‐ument frequency)方法易导致词形和词义的割裂[6],而学科知识结构探测任务往往不易获得训练BERT(bidirectional encoder representation from transformers)等模型的先验知识。因此,在考虑效率和可扩展性的基础上,选择word2vec 来对实验领域的全文语料库进行词的分布式表示预训练。word2vec 算法使用神经网络以无监督的方式从大型语料库中学习词的语义和词与词间的上下文关联[50],使词语不限于词语本身形态,还与相关词保持着主题联系。在其两种主要模式中,CBOW(continuous bag of words) 通过输入中心词t的上下文窗口内的词来预测中心词t,并通过负采样和反向传播更新词嵌入向量矩阵。相对于另一种模式skip-gram,其对稀有词的敏感度更低,更适合大规模科学文献语料库建模。
为了预先拟合特定领域的词特征和词间关系,本研究将实验领域全文数据集中的所有全文文章用作语料,预训练并生成领域word2vec 模型,以支持后续引用语义相似度计算。
3.1.3 引用位置的标准结构学习
不同于共被引分析,引文耦合分析的分析对象是两篇施引文献,这意味着它们的章节结构可能是不同的,无法用先前研究中的引文临近指数(cita‐tion proximity index,CPI)等方式[5]进行位置比较及计算相似度。为解决这一问题,本研究利用机器学习方法将引文在一篇论文中出现的位置,映射至三种标准化的章节类型——背景综述型(Type I)、方法过程型(Type M)和拓展延伸型(Type F),它们的定义如表2 所示。

表2 标准化章节类型及定义
通过提取文章章节的特定特征(包括章节每字均含引文密度、章节含有引文在全文的占比、章节含有期刊类引文密度、章节标题词向量等),在该领域1861 条章节信息的人工标注集上进行训练。最终选择表现最优的支持向量机(support vector ma‐chine,SVM)模型,准确率(accuracy,ACC)为0.91,受试者工作特征(receiver operating characteristic,ROC)曲线如图2 所示。该模型将用于根据引文所在的章节特征,进行标准化章节结构映射。
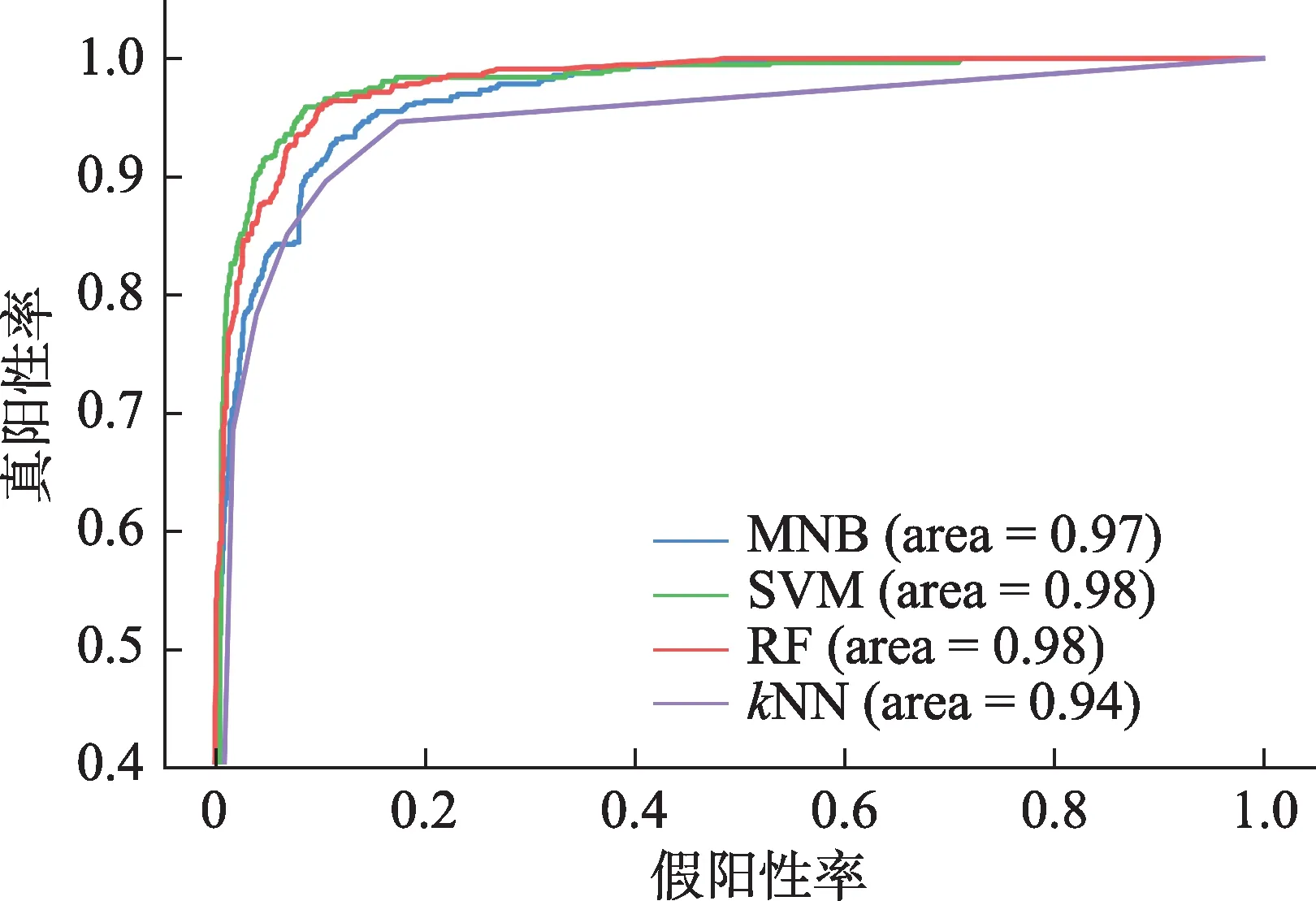
图2 备选映射模型的受试者工作特征曲线(ROC curve)彩图请见https://qbxb.istic.ac.cn/CN/volumn/home.shtml。MNB:mul‐tinomial naive Bayes(多项式贝叶斯);SVM:support vector machine(支持向量机);RF:random forest(随机森林);kNN:k-nearest neighbor(k最邻近);area:曲线下面积。
3.2 增强型引文耦合强度计算
在SC-ABCA 中,增强型引文耦合相似度是核心部分,也是进一步计算作者间联系的基础。
设作者A 撰有论文pA,作者B 有论文pB,pA与pB存在参考文献交集R,对于任意一个耦合参考文献条目r∈R,利用Glänzel 等[51]所建议的用于平缓融合异源数据的余弦角加权式,融合pA与pB关于r的引用语义相似度SemSimr(pA,pB)和引用语境相似度CtxSimr(pA,pB),累加作为pA与pB的增强型引文耦合相似度SCBC_Relevance,即
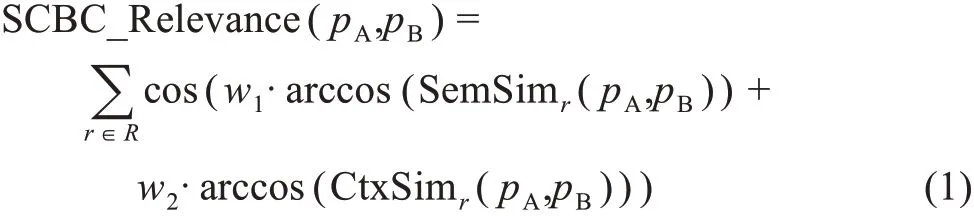
其中,w1+w2= 1,w1、w2将通过调参获得最优配比;引用语义相似度和引用语境相似度的具体定义将在3.2.1 节和3.2.2 节中具体介绍。在SC-ABCA 中,增强型引文耦合相似度计算一方面用于层次化耦合联系并探测语义和语境上更相似的耦合联系,另一方面也用于筛除在语义或语境上相似度极低的耦合联系,在本研究中,计算后的语义或语境相似性值在全局排名最低20%以内的低值耦合连边将被消减。
3.2.1 引用语义相似度
本研究将引用语义相似度定义为:两篇文章同时引用一篇参考文献时在主题内容上的相似性。主题内容相似性的计算基于3.1.2节预训练的word2vec模型。
在完成全文数据抽取后,每一篇论文p对于任意一篇参考文献r都存在一个引用内容文本列表Conr(p),那么,对于作者A 与B 任意一对发生耦合的文章pA和pB的任意一篇共有参考文献r,都有Conr(pA)=[conA1,conA2,…,conAn] 和 Conr(pB)=[conB1,conB2,…,conBm]。将两个列表中的元素枚举配对,分别从预训练的word2vec 模型中取出词向量,组成句向量作余弦相似度计算并作累加,那么,引文耦合语境相似分值SemSimr(pA,pB)可定义为
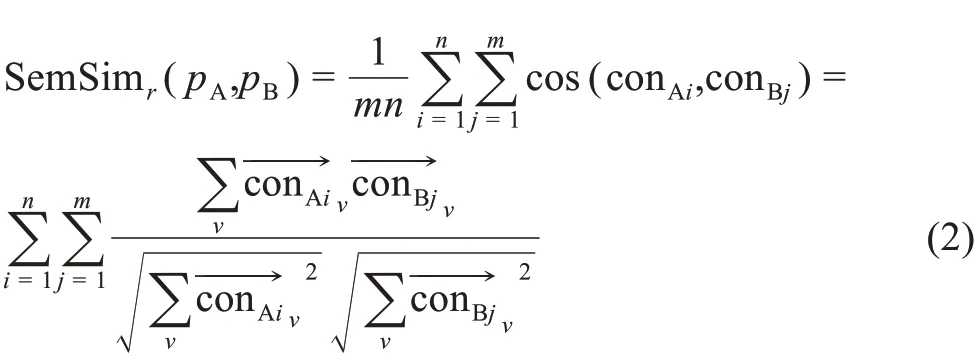
3.2.2 引用语境相似度
本研究将引用语境相似度定义为:两篇文章同时引用一篇参考文献时在全文结构内具有的语境特征,包括提及次数和提及的章节位置。章节位置的标准化基于3.1.3 节的结构映射模型。
从以往研究来看,大多数的引用集中于背景综述型章节,而在此处的引用大多是不重要的[52-53]。因而,本研究以背景综述型为基准值1,分别为方法过程型和拓展延伸型分配权重系数θM和θF,两者的具体数值将通过调参程序(参见4.3.1 节)在一定范围内搜索、调优。
经过上述过程,每一篇论文p对于任意一篇参考文献r都将形成一个引用位置权重列表Locr(p)=[θ1,θ2,…,θn]。对于作者A 与B 任一对发生耦合的论文pA与pB的任意一篇参考文献r,引文耦合语境相似分值CtxSimr(pA,pB)的计算公式为
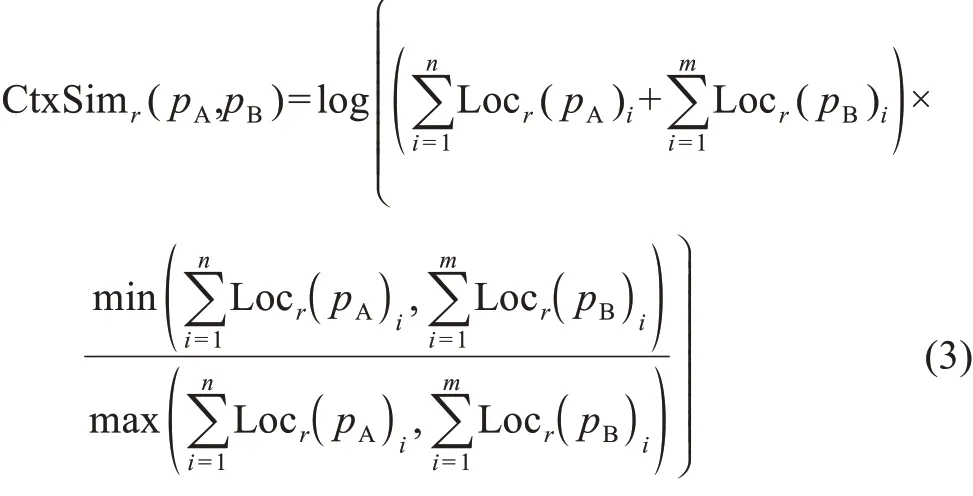
其中考虑了两个主要部分:①r对pA与pB的重要性大小,通过加和pA与pB关于r的位置权重列表总和获得;②r对pA与pB的重要均衡性,通过将两个位置权重列表的较小值除以较大值获得。式(3)的意义在于:如果一篇参考文献r在pA与pB出现更多次数并分布于更重要的位置,且在pA与pB中的重要性更为类似,那么pA与pB对于参考文献r将具有更高的引用语境相似性。
3.3 “论文-主题-作者”聚合映射
在计算增强型引文耦合连边并构建起论文层引文耦合矩阵后,进行如图3 所示的“论文-主题-作者”聚合映射流程。与先前研究不同,本研究没有采用直接取两个作者参考文献交集或取加权参考集最小值累加的做法,而是将作者的每篇论文视作一个相对独立的研究场景,首先在独立场景内探讨引用语义和语境的相似性,在经聚类获得学科知识结构后,通过分布转化手段构建作者间的联系强度。
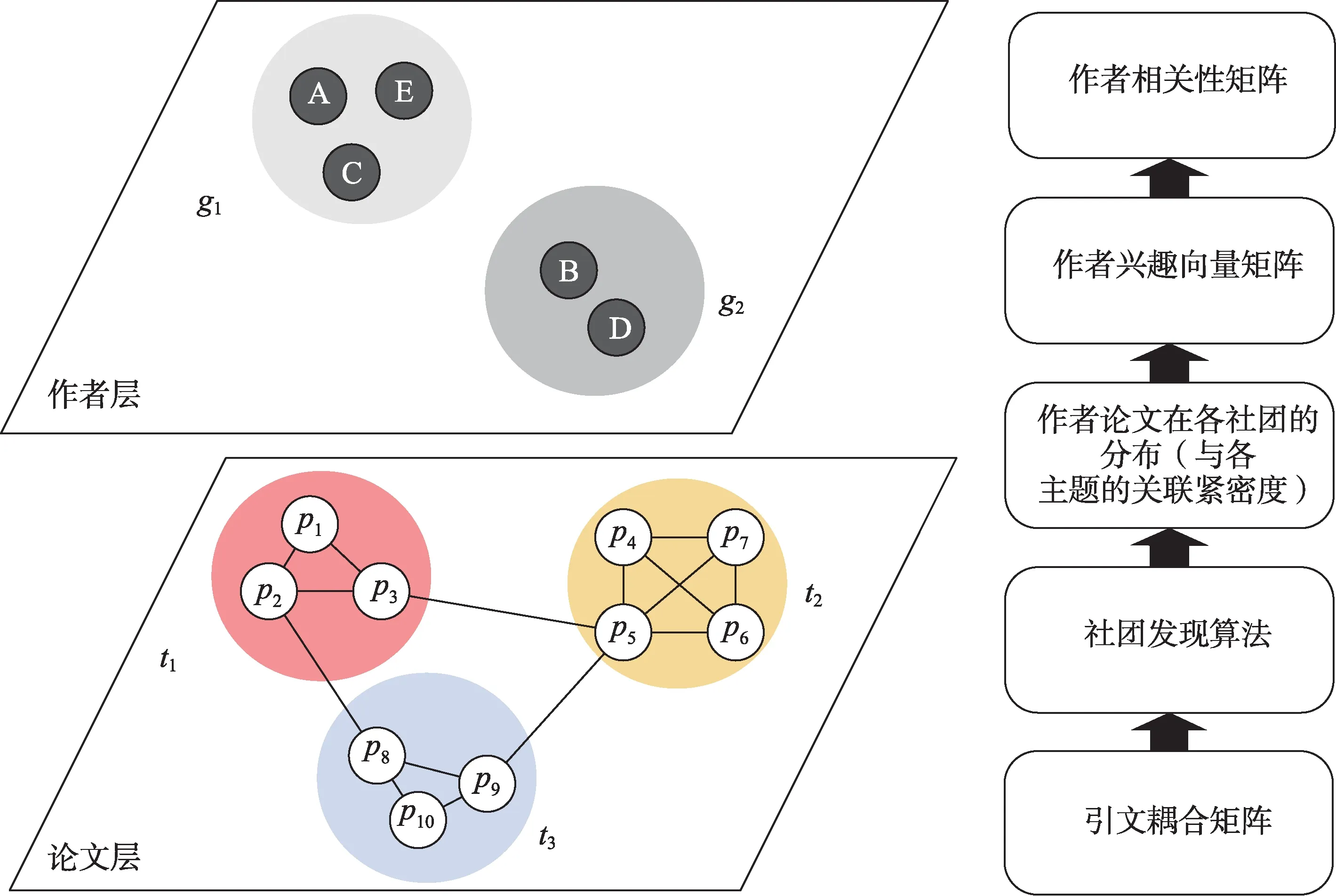
图3 “文献-主题-作者”聚合映射流程示意
设引文耦合矩阵构建的网络中存在文献节点集合V={v1,v2,…,vn},在应用社团发现算法后产生主题社团集合T={t1,t2…,tm}。对于任意一位作者文献集P={p1,p2,…,pk}中的任意一篇论文pi与任一主题tj∈T的关联紧密度wij,可用pi与tj下所有文献节点的连边权重总和计算,即
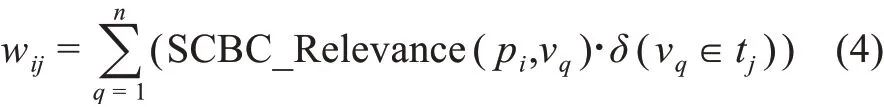
其中,vq∈V。δ内算式vq∈tj为真时,δ(vq∈tj)=1;假时,δ(vq∈tj)=0。那么,每位作者的文献集合主题分布可表示为进而可得出该 作 者 的 兴 趣 向 量 分 布 为ψ=(ψ中的所有元素加和将被置为1),表示该作者与现存主题的联系紧密度偏重。在对所有作者进行兴趣向量生成后,获得作者兴趣向量矩阵及作者相关性矩阵。
4 实证研究
4.1 技术路线
实证研究的技术路线如图4 所示。首先确定实验领域及期刊,在遵守中国知网(China National Knowledge Infrastructure,CNKI) 访问规 则的 情况下获取目标领域的全文HTML 页面。在解析后,将引用位置、提及次数、引用内容文本和全文本语料用于SC-ABCA 的增强型引文耦合强度计算,并生成增强型引文耦合矩阵用于论文层聚类;在此基础上,经聚合映射过程形成作者兴趣向量矩阵和相关性矩阵;最后,利用降维可视化技术、k-means 聚类和多种评估手段,将SC-ABCA 与现有ABCA 模型、对照组模型(含聚合映射过程但不使用全文数据)进行多方位的量化比较,获得研究结论。
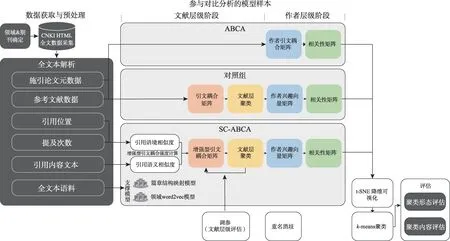
图4 实证研究技术路线
4.2 数据来源
本研究选择图情领域为实验领域,其因有三:①图情领域作为交叉学科,其学科的复杂性和较弱的体系结构适合聚类对比实验;②在中文学术领域中,图情领域较为活跃,且研究模式、出版较为规范;③本课题组研究领域同为图情领域,便于解读结果。在确定实验领域后,将时间跨度定为2016—2020 年,于2021 年6 月5 日开展数据采集工作,取CNKI 中“图书情报与数字图书馆”领域综合影响因子在1.0 以上的21 本期刊为数据来源(表3),并以论文发表年至2021 年每年平均被引1 次及以上的论文为数据采集对象,共采集到具有HTML 全文本格式的论文13562 篇,占期刊发文总量的85.5%。
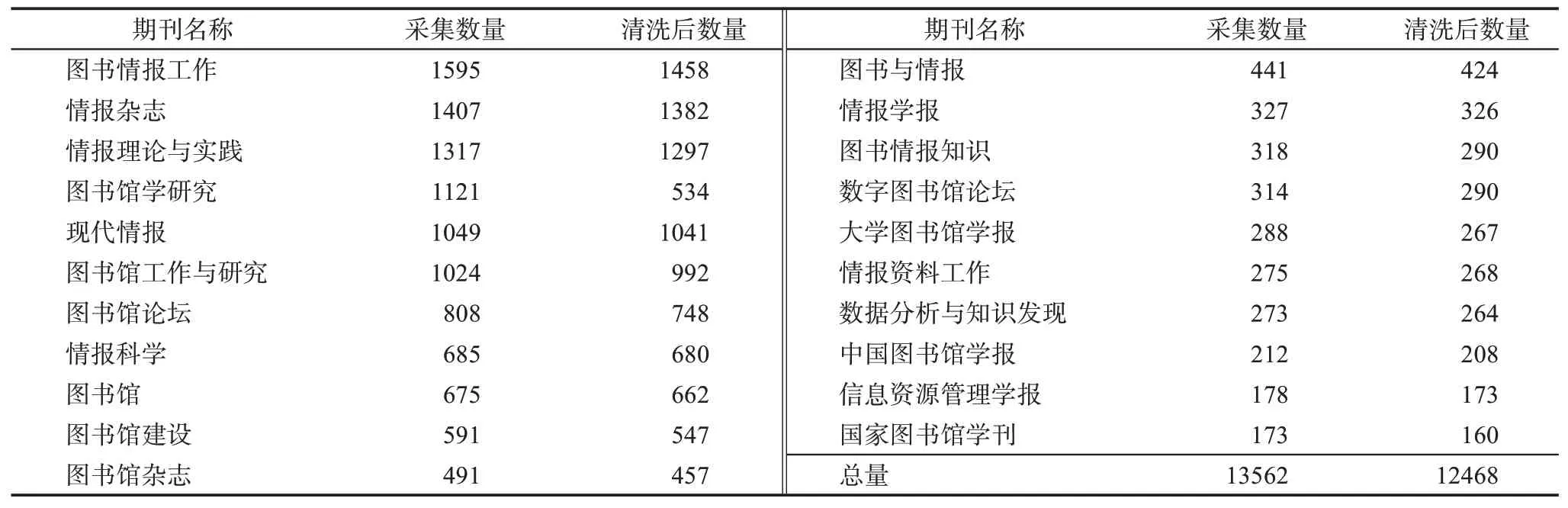
表3 论文全文本数据来源与数量统计 篇
在对数据进行初步处理和解析,筛除HTML 页面格式不规范、缺乏重要信息的文献后,最终获得12468 篇用于后续实验的全文本数据,涉及作者6232 人(人工查证并排除了77 位疑似存在重名问题的学者),共产生参考文献条目247402 个,总耦合边数323516 条。文献的耦合频次分布、作者发文量分布、作者的耦合频次分布如图5 所示。
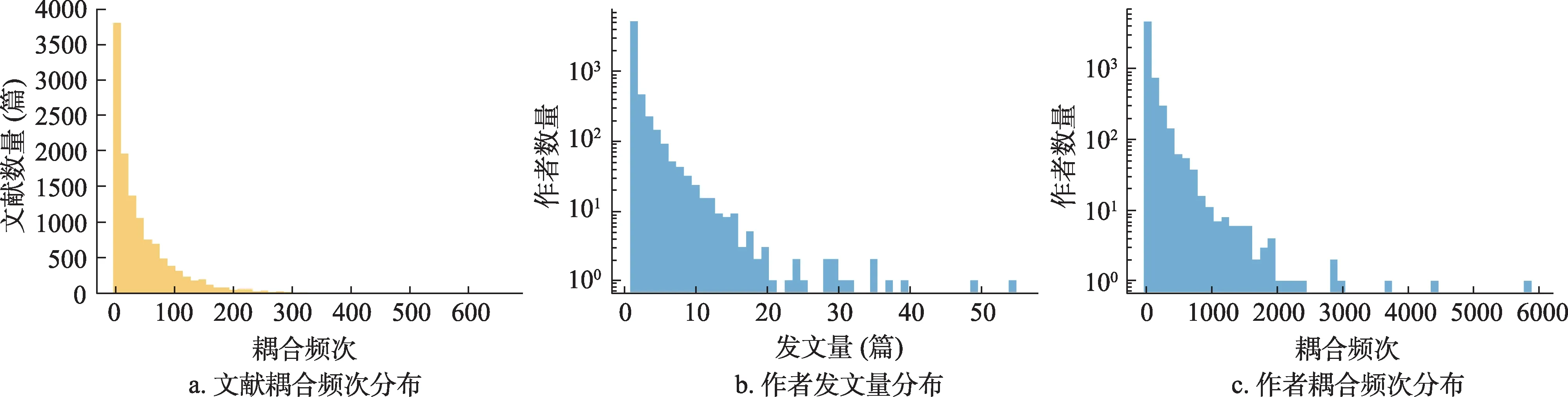
图5 文献与作者数据分布统计
由于作者引文耦合分析旨在分析活跃作者并倾向于发现当前领域内的知识结构,与以往研究不同,本研究不设置作者选取阈值,而是将所有作者(6232 位)全部纳入后续实验流程中。本研究的所有计算均在第一作者模式下展开,不选择全作者模式的原因有以下两点:①为了更好地与原始ABCA 进行比较;②避免额外干扰因素,如挂名问题等。
4.3 研究方法
4.3.1 参数调优方法
SC-ABCA 中有两套参数需要在实际应用时调优,分别是:引用语境相似度即式(3)中引用位置列表Locr(P)可能涉及的章节重要性权重θM和θF,以及式(1)中引用语义相似度的权重w1和引用语境相似度的权重w2。面向这两套参数,调优过程分为两个阶段:第一阶段,将w1置为最小值0,w2置为最大值1,通过模型表现优劣选取最优的θM和θF配置组;在第一阶段基础上,第二阶段再进行w1和w2的最佳配比调控。
上述调优均需要利用标注数据集对论文层社团发现结果进行测验。由于节点数目众多,作为实证研究又缺乏分类先验知识,因此,本研究随机抽取1000 对文献节点对进行关键词语义相似度计算基础上的人工判读确认。当节点对在研究背景、研究方法、研究对象三个方面有两者以上相同或相似时,人工标注节点对为相关。在此基础上,将1000 条标注节点对与社团发现结果进行如表4 所示的比对,并计算精确率、召回率、F1 值和准确率,分别为以选择最优配置组合用于后续实验。
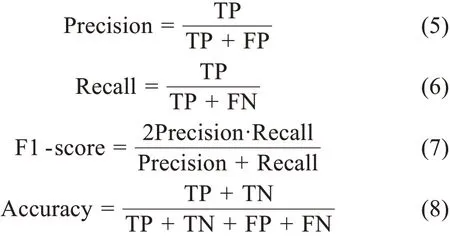

表4 预测结果与标注数据的比对方法
4.3.2 聚类与降维技术
1)论文层社团发现
为避免直接、笼统地进行作者级的引文耦合计算,本研究首先构建作者在知识层面的联系。通过Louvain 算法进行论文层的社团发现,以揭示领域知识结构,为后续作者兴趣向量的生成提供维度参照。
Louvain 算法是Blondel 等[54]在2008 年提出的社团发现方法,能够对含数亿节点的大规模网络进行快速的社区发现。Louvain 算法的基本过程分为两步:①将网络中每个节点i视为一个社团S,对于S的所有邻接社团T,尝试把i移入T中,保留产生模块度增量最大的一次移动;对所有节点都执行此操作。②将上一过程获得的新社团转化为新节点,新的边权重来自社团间的边权重之和,形成简化网络。不断重复上述两个过程,直到模块度不再增加。对于大型网络而言,Louvain 算法具有高效、高精度的特点。
2)作者层聚类方法
在获得作者兴趣向量矩阵并转化作者相关性矩阵(参见3.3 节)后,本研究使用k均值聚类算法(k-means)进行作者层的聚类。k-means 是一种常用的迭代求解的聚类分析算法,其基本原理是:首先选择尽可能相距较远的k个样本为初始化质心,再循环计算数据集中每个样本点到质心距离,将其归入最近质心类别并更新质心位置,直到质心变动距离收敛为止。本研究选择k-means 的原因有二:①算法复杂度低,可应对大规模数据集;②聚类结果有效、直观,易于理解和解释。
3)降维可视化技术
本研究使用t 分布随机近邻嵌入(t-distribution stochastic neighbor embedding,t-SNE) 对模型样本产生的矩阵进行降维和可视化。t-SNE 是一种非线性降维技术,适合在低维空间中嵌入并可视化高维数据,其保证在原始空间中距离相近的点在投影至低维空间后仍然相近[55]。t-SNE 算法包括两个阶段:第一阶段,对每个数据点与其他节点的相似性分布进行建模,将相似性转换为概率分布,其中,原始空间中的相似度由高斯联合概率(Gaussian joint probabilities)表示,低维空间中的相似度由t 分布(student's t-distribution)表示,这有助于数据点在低维空间中分布得更均匀;第二阶段,利用梯度下降法最小化上述两种概率分布的相对熵(Kullback-Leibler divergence),即找到高维空间向低维空间的最优变换。
t-SNE 相较于主成分分析、多维尺度变换等降维技术更为灵活,可避免直接降维的数据重叠,易于直观地观察数据在多种尺度、流形、聚类形态下的分布情况;相较于其前身SNE(stochastic neigh‐bor embedding)[56],能够缓解数据点的中心拥挤趋向。目前,t-SNE 已广泛应用于基因组学、自然语言处理、生物信息学等领域的研究中。
4.3.3 评估方法
1)对照组构建
为防止SC-ABCA 方法中部分改进举措的无效性或干扰性,便于对比和效果呈现,本研究设置了对照组模型。如表5 所示,对照组模型将具有与SC-ABCA 一致的双层架构,拥有“论文-主题-作者”聚合映射过程;但其不使用全文本数据,仅将文献耦合次数作为引文耦合强度。
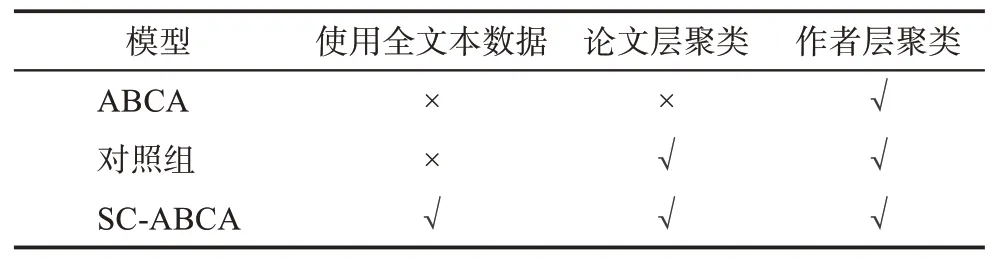
表5 三组模型样本的基本配置对比
2)聚类形态(外部)评估
聚类形态(外部)评估即通过数据图中数据点分布是否具有清晰的聚类形态来判定聚类效果的好坏。本研究中使用轮廓系数(silhouette index)来量化聚类的形态表现,其将主要应用在k-means 聚类时的最优k值选取中。设有数据集D,并已通过某一算法获得了若干类簇,那么轮廓系数的计算方法定义为
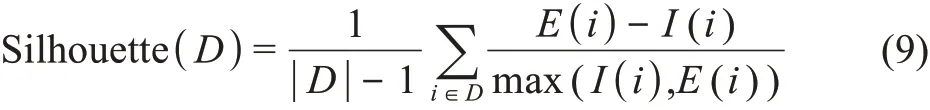
其中,I(i)表示D内任一节点i与其所属类簇内其他节点的距离均值;E(i)表示节点i与其所属类簇的最近邻簇内节点的距离均值。轮廓系数越大,说明数据集D内的类簇间距越远,聚类形态越佳。
3)聚类内容(内部)评估
仅仅从聚类的形态进行聚类效果评估是不够的。良好的聚类通常应具有真实性和较强的类簇内在属性联系,完全以聚类形态为导向的评估,将忽略类簇可能存在的层次特征(如子群的存在)。然而,作为实证研究,完整的分类先验知识难以获取,这使得兰德系数、互信息等常用聚类评估无法使用。在此,本研究借鉴了Boyack 等[44]提出的类簇内容一致性检验方法,提出以下两种聚类内容评估指标。
(1)内容凝聚度增值(content coherence gain)。内容凝聚度增值用于评估当前数据集内各类簇中的样本内容属性的一致程度,定义为
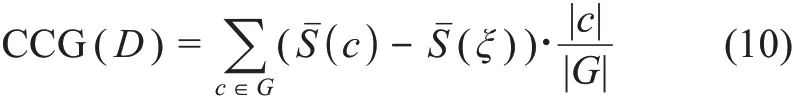
其中,G表示当前已获得的类簇集合G={c1,表示类簇c中所有样本与类簇质心间的关键词集word2vec 向量的余弦相似度均值,ξ表示与类簇c等大的随机生成类簇,取差值并以类簇大小为权加总所有c∈G,获得内容凝聚度增值。其意义在于,评估当前算法获得的聚类类簇多大程度上具有高于随机水平的内容内聚性。
(2)直引概率增值(directed citation probability gain)。直引概率增值用于表示当前算法获得的聚类结果发生类内直引的概率在多大程度上高于随机水平。定义为
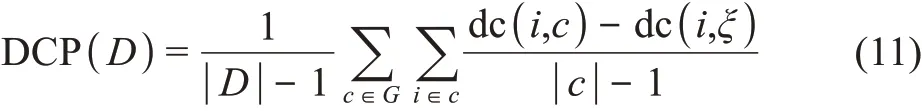
其中,G表示当前数据集D已获得的类簇集合G={c1,c2,…,ck};对于其中任一类簇c中的任一点i,dc(i,c)表示i引用类内样本的次数,dc(i,ξ)表示i引用与类簇c等大的随机生成类簇ξ内样本的次数,为D中的所有i计算后取均值作为聚类结果的直引概率增值,意为平均而言,聚类后的样本点多大程度上倾向于引用类内而非随机生成的节点。
4.4 实证结果
4.4.1 调参结果
本节展示3.3 节中各参数的最优权重配置调整结果。经上文所述的数据抽取与预处理后,共获得12468 个文献节点和323516 个总耦合连边,本节参数调整均在此基础上展开。
(1)语境相似度计算中的位置权重θM和θF权重配置与F1-score 分值如图6 所示。结合三维柱形图和切面投影图可知,当拓展延伸型章节权重θF略高于基准值1(背景综述型章节值)且方法过程型章节θM略高于θF时,模型表现较优;当θM、θF和基准值过于接近或差值过大时,模型表现呈下降趋势。在本研究中,最优配置应位于(θM= 1.6,θF=1.2)处。
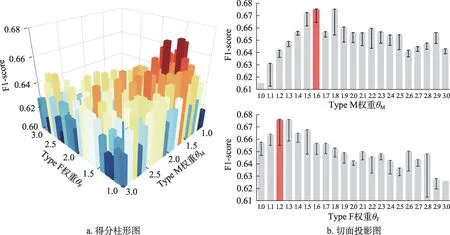
图6 引用位置的权重参数调整结果
(2)语义相似度w1和语境相似度w2的权重配比及得分如表6 所示。由表6 可知,语义相似度权重为0.6、语境相似性权重为0.4 时模型具有最优的效果。此外,最终调优的模型相较于对照组,即通常使用的文献耦合分析法,F1-score 提升超过13 个百分点,准确率(ACC) 提升超过10 个百分点。这从定量角度说明,引入全文本数据可以为传统文献耦合分析带来明显的聚类效果提升。
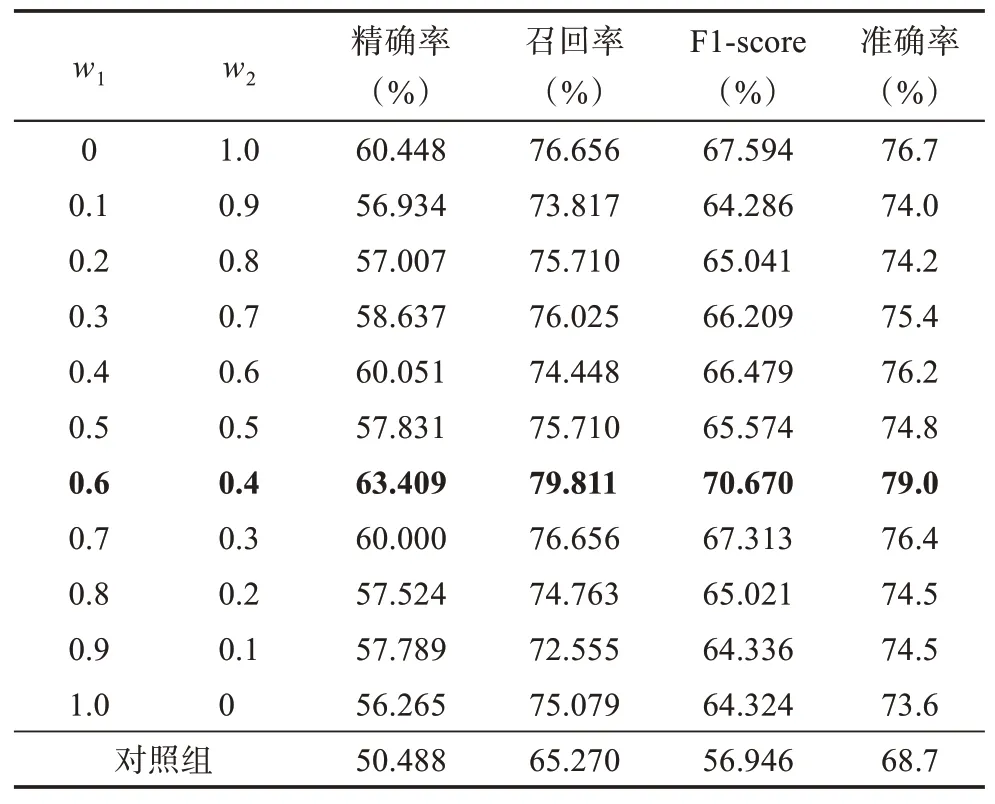
表6 语义和语境相似度权重配比及得分
4.4.2 论文层社团发现结果
在确定最优参数的SC-ABCA 后,以所有实验文献为节点,增强型耦合联系强度为边权构建论文层的耦合网络,用于发现领域知识结构以支持后续作者兴趣向量的生成。SC-ABCA 与对照组的论文层级网络基本情况如表7 所示。由表7 可见,SCABCA 网络相较于对照组更为稀疏,且在模块度水平接近的情况下含有更多的模块。

表7 论文层网络基本信息
图7展示了SC-ABCA 及对照组在论文层级的社团发现结果,其中的流量刻画了两组结果的对应联系,模块标签名来自各模块含有论文标题与关键词的TF-IDF 抽取结果和人工查验总结。图7 显示,SC-ABCA 相较于对照组,发现了更多、更细的研究主题,例如,对照组的#8 公共文化服务被细分为阅读推广与阅读疗法、图书馆公共文化服务、微信平台与微服务等5 个模块;#5 移动图书馆、社交媒体与知识共享被细分至个性化推荐研究、虚拟社区与知识互动行为研究、信息搜索与信息偶遇、社交媒体与社交网络等6 个模块;#16 科学计量与科技评价被细分至科技评价、学科交叉与合作研究等4个模块;#9 专利情报与智能技术应用被细分至科技前沿识别与演化路径分析、专利情报分析、深度学习与自然语言处理应用等5 个模块。

图7 论文层级聚类结果对比
需要注意的是,由于领域知识结构中存在众多零散模块,本研究仅保留含有节点量在总体1%及以上的主要主题模块,便于后续作者兴趣向量生成。SC-ABCA 共获得30 个(含总节点量91.5%),对照组共获得12 个(含总节点量92.7%)。
4.4.3 作者层聚类结果
本节将比较提出方法SC-ABCA 与ABCA 及对照组的作者研究兴趣社群发现效果。
在将论文层级的耦合聚类与领域知识结构转化为作者的研究兴趣分布,形成每个作者的研究兴趣向量后,SC-ABCA 生成了5476 个30 维的作者兴趣向量,对照组生成了5800 个12 维的作者兴趣向量,进而将两个作者兴趣向量矩阵分别转化为5476×5476 和5800×5800 的Pearson 相 关 系 数 矩 阵;对于ABCA,遵循原始版本中的计算和矩阵构建方法[1],生成5960×5960 的作者引文耦合矩阵,并同样转化为Pearson 相关系数矩阵。
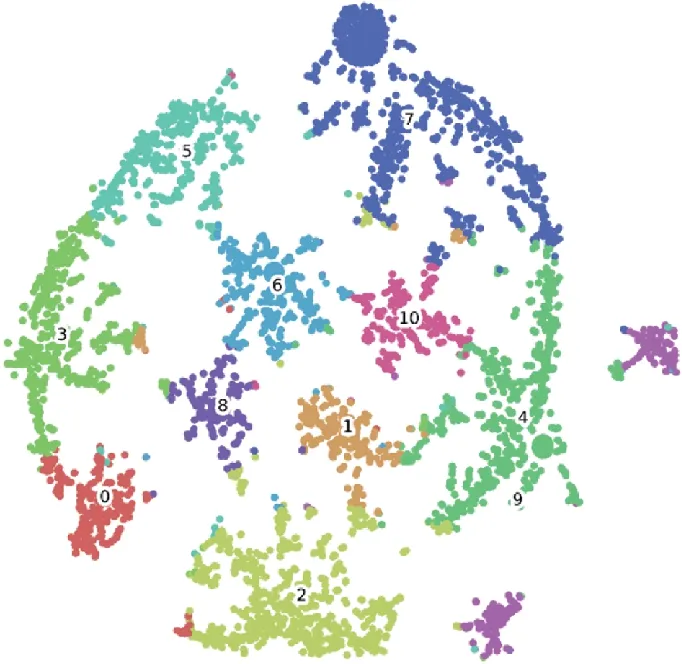
图10 对照组作者聚类结果
将转化后的SC-ABCA 矩阵、对照组矩阵和AB‐CA 矩阵分别作为t-SNE 降维技术和k-means 聚类算法的输入。首先利用t-SNE 形成3 个矩阵在低维空间的可视化群落分布,然后利用轮廓系数曲线分别确定超参数k(类别数量)的取值,在此基础上为群落着色,如图8~图11 所示。
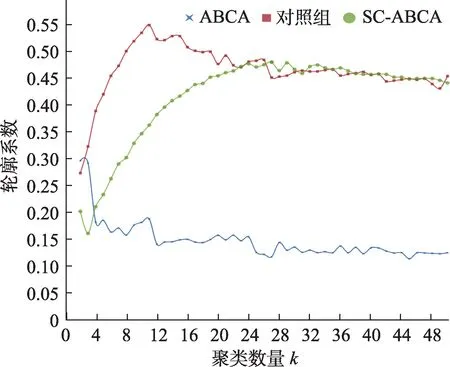
图8 轮廓系数曲线
由图8~图11 可直观观察到3 种矩阵所形成的领域作者兴趣社群分布状况。SC-ABCA 的作者兴趣社群呈星状、团状分布,社群繁多并且小而紧凑;对照组形成的作者兴趣社群呈树状分布,各社群面积较大但划分较为明确;ABCA 形成的作者兴趣社群分布中存在一个巨大而聚类特征不明确的团簇,总体聚类效果不佳。
由图8 可知,对照组明显的轮廓系数峰值出现在k=11 处;SC-ABCA 的轮廓系数峰值出现相对较晚且平缓,最优k值达到27;ABCA 的轮廓系数曲线不具有收敛峰值,结合观察k=11 时的次高峰与图11,将其k值定为11。从轮廓系数峰值的横向对比来看,ABCA 远落后于另两者,而SC-ABCA 不及未使用全文信息的对照组,这可能是因为SC-AB‐CA 的聚类群落更多且分布更为临近,群落间的平均距离不及对照组而导致轮廓系数稍低。

图9 SC-ABCA作者聚类结果

图11 ABCA作者聚类结果
本研究进而从聚类内容指标比较三者的差异。图12 展示了3 个模型在各自最优k值下的内容凝聚度增值和直引概率增值。在两个评估指标上,使用聚合映射方法的SC-ABCA 和对照组均获得远优于现有ABCA 的分值;而利用全文数据计算增强型引文耦合强度的SC-ABCA 相较于不使用全文数据的对照组又有大幅提升,内容凝聚度增值提升约27.7%,直引概率增值提升约50.0%。这说明在SCABCA 发现的作者兴趣社群内,作者从事的研究主题具有更强的群内一致性,更倾向于引用群内作者的研究成果。
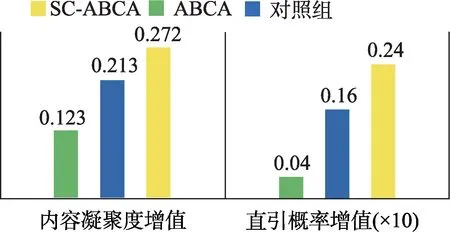
图12 内容凝聚度增值和直引概率增值评估结果
为排除SC-ABCA 较高的k值可能携带的内容凝聚度增值优势,在多个k值上进行再评估,并绘制内容凝聚度增值曲线。如图13 所示,内容凝聚度增值的提升并不仅仅是更细的社群划分带来的,对照组在轮廓系数到达峰值(k=11)后,内容凝聚度增值已在0.22 左右临近饱和,而SC-ABCA 的内容凝聚度增值直至轮廓系数收敛点(k=27) 后才在0.28 左右临近饱和,并仍保留有稍高的增长趋势。总体来看,SC-ABCA 在聚类内部评估上的表现优于对照组,并大幅优于现有ABCA。
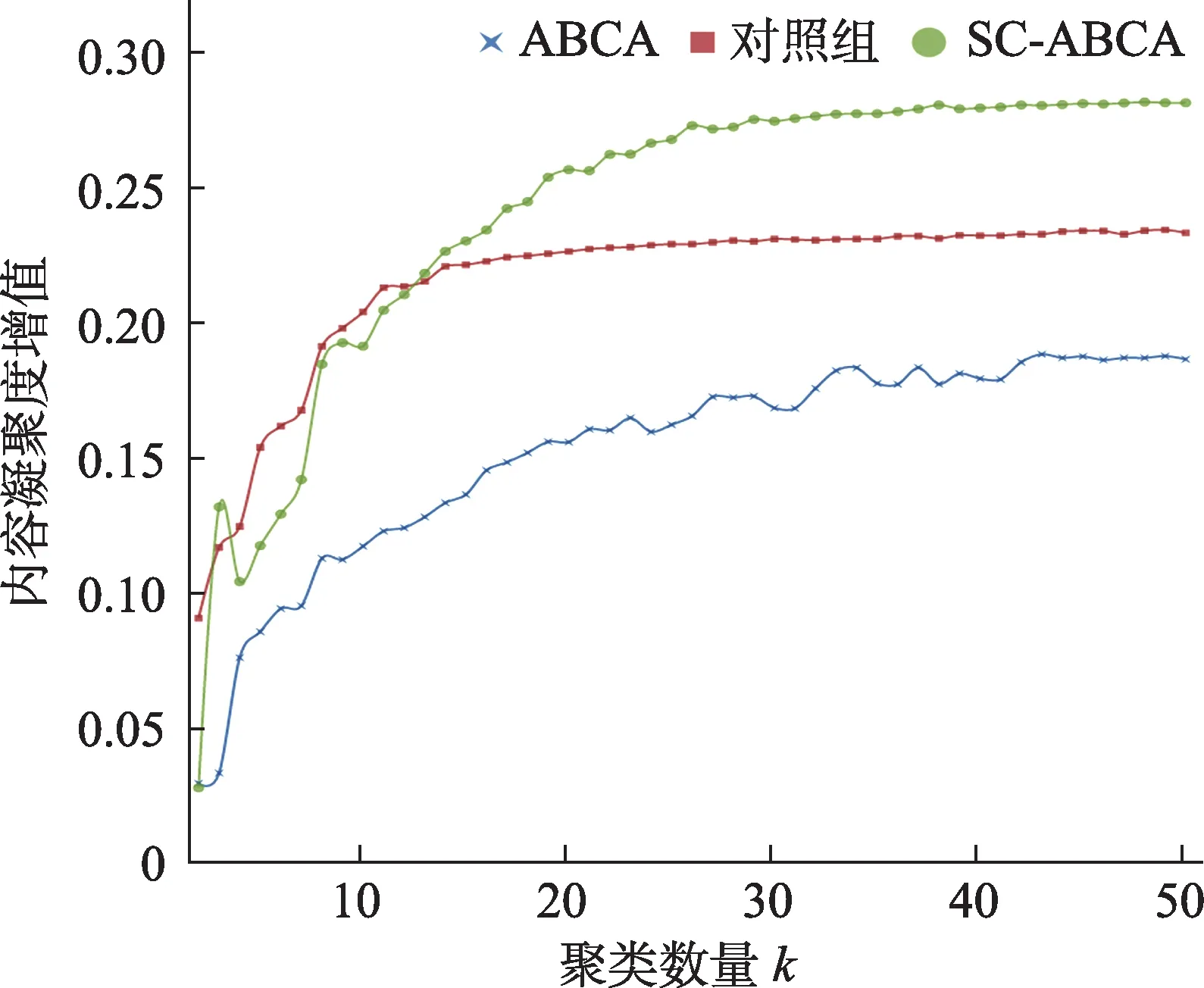
图13 内容凝聚度增值曲线图
5 讨 论
结合上述结果可以得出结论,本研究提出的SC-ABCA 相较于现有ABCA 具更优的作者兴趣社群发现效果。即使面对大规模的作者总量,SC-AB‐CA 仍呈现出更佳、更细致的聚类群落分布,其划分出的作者兴趣社群具有更高的群内同质性——同群作者具有更强的研究关键词一致性,具有更高的互引概率。本研究有以下发现。
(1)融入全文数据的增强型引文耦合强度有利于发现更为细致的学科知识结构。不论在论文层还是作者层,SC-ABCA 与不使用全文数据的对照组的结果差异都在于前者发现了更多的群落,这使得每个群落下的样本具有更强的同质性。一般来说,科学文献通常需要对相关著作进行密集引用,其中既涉及与该文献密切相关的领域,也涉及次相关或弱相关的基础前身领域,若仅考虑简单的引用计数,将很难及时地将新兴子领域从父领域或其他紧密相关的领域中细分出来;而SC-ABCA 考虑了施引方在引用不同程度相关的参考文献时,引文具有的特定语义和语境特征,这大大丰富了现有耦合强度的深度和可解释性,有利于使特定的研究主题群落在术语、上下文,甚至研究逻辑与习惯上呈现出不同于其他主题群落的特征表现。因此,更易于呈现出细致的学科知识结构发现效果。
(2)利用论文层耦合聚类形成的知识结构来映射构建作者兴趣向量是可行的。现有ABCA 惯例式地采用了将作者来自不同论文的所有参考文献直接归拢为集合以参与运算的做法,由于作者是比科技文献更为复杂的主体(可能具有多元化的研究兴趣),这一做法并不恰当。例如,对于那些已极为成熟的主题领域,尽管某作者仅在该主题少量发文,也极易与该主题领域内的众多作者产生耦合联系,如果该作者另有主要从事的主题领域,那么他将被不正确地归入这一成熟主题领域;如果该作者的主要从事领域是一新领域且其扮演着关键节点角色,那么新领域可能也将被“吞噬”,难以发现。数据量越大,越趋于复杂,这一关键问题就越发明显,如图11 所示的巨型噪声群簇。本研究首先在论文层,即作者的独立研究场景内进行了基于引用语义和语境特征的耦合网络聚类,然后将作者的每一篇论文投射到聚类形成的领域知识结构中,计算该论文与每个主题的联系紧密程度,以此将作者的文献集转化为作者兴趣向量,这在本质上将作者间的引文耦合相似性转化为了作者间知识结构的相似性,使作者间的联系更为稳定,更具鲁棒性,能更好地应对大规模数据。
(3) SC-ABCA 具有一定的可拓展性和应用前景。相较于以往严格限制分析对象数量的作者级引文分析方法,SC-ABCA 不再仅限于对少数“领域精英”的分析,而是能够胜任分析大规模作者群体的任务,并为其中的多样化作者个体提供更为可靠的相似性分析结果,可进而投入众多大数据级的学术用户信息服务应用场景中,有望为合作预测与推荐、科研用户画像、科研群组知识服务等提供精准化支持。
6 结 语
本研究提出了一种增强型的作者引文耦合分析方法SC-ABCA。该方法面向现有作者引文耦合关系强度对于有限的外在著录信息的依赖问题,通过对施引文献全文本的挖掘,基于全文层面的引用语义和语境特征计算引文耦合强度,从施引动机间的相似性这一本质层面,为引文耦合关系提供了更具差异性和可解释性的空间,是对传统文献计量方法在全文本可用背景下的有益延展与创新。同时,该方法进一步考虑了单作者的多元化研究兴趣,利用“论文-主题-作者”聚合映射代替ABCA 面向作者直接归拢文献的过程,使作者在各研究论文中体现的引用语义和语境特征均能独立地参与耦合关系强度的计算,为更细致、更具鲁棒性的作者兴趣社群发现提供了可能。通过与ABCA、设置对照组的量化对比实验和评估,本研究发现SC-ABCA 相较于现有方法具有更优的作者兴趣社群发现效果,并适用于面向大体量作者的分析,这可能拓宽现有方法的适用范围,使之更易对接广泛的下游应用,具有一定拓展前景。
然而,SC-ABCA 也存在着局限。首先,SCABCA 的运行依赖于学术论文的全文本格式数据,而此类数据的获取在当下仍然不成熟,尤其在国内,部分领域的全文数据获取相对不易,全文本格式也不够规范,这可能影响SC-ABCA 在当前的实际可用性和分析结果的完整性。其次,SC-ABCA中的引文范围定义沿用了先前研究的结论[35],而更准确的引文范围识别需要额外的机器学习模型支持;最后,在本研究开展的对比研究中,为了降低多作者署名带来未知干扰因素,仅使用了第一作者的计算模式,如何考虑单篇文章中各合作者的主题偏向性是SC-ABCA 有效应用全作者和分数计数模式前必须解决的问题。
当前,科技论文的全文本获取、解析,包括基本规律的揭示已不再困难,但如何利用好这些丰富的全文本层数据,如何将它们与适当的技术、理论有机融合,如何最大限度地发挥它们的价值并推动现有情报分析方法的精准化革新,是从事该方向的学者乃至整个图情领域仍须重点考虑和关注的问题。
