科研人员画像构建方法研究
2022-08-31张志刚王卓昊
王 东,李 青,张志刚,王卓昊
(中国科学技术信息研究所,北京 100038)
根据国家统计局2019 年发布的新中国成立70周年经济社会发展成就系列报告,2018 年我国按折合全时工作量计算的科研人员总量已达到419 万人年,连续6 年位居世界第一[1]。随着科研人员规模的不断扩大,科技管理工作面临着严峻的挑战。一方面,科研人员相关数据分散在不同地方、不同层级、不同机构中,难以快速灵活地对其进行整合和分析;另一方面,现阶段的科研人员评价机制不同程度地存在唯论文、唯职称、唯学历、唯奖项倾向,忽略了科研人员的品德、能力、业绩等重要信息,因此难以全面地刻画科研人员。为解决以上问题,本文根据新形势下党中央和国务院关于深化科技人才评价改革的决策部署[2],提出了一套科研人员画像构建方法,旨在对科研人员的多个维度的数据进行整合和分析,进而直观地展示科研人员的各方面特征,有利于科技管理部门全面了解科研人员现状。
在大数据时代,用户的各种行为都会在互联网上留下记录,为了通过这些记录挖掘出用户的行为特征和兴趣爱好,进而实现个性化推荐、精准营销等场景,用户画像应运而生。用户画像(user pro‐file)本质上是一套描述用户的兴趣、特征、行为、偏好等信息的框架,最早由交互设计之父Alan Coo‐per 提出[3],它是根据用户的真实数据建立的抽象化、标签化的用户模型,目前在电子商务、社交网络等领域中有着广泛的应用。本文基于用户画像相关理论和技术,根据科研人员的行为特征和工作特点,围绕其人员属性和科研属性2 个维度,抽象出科研人员画像。
1 研究现状
在早些年,用户画像主要应用于精准营销、个性化推荐等领域[4-7];近年来,借助用户画像技术来描述和评价科研人员已经成为国内外情报学研究的热点之一。在国外,Sateli 等[8]提出了一套名为ScholarLens 的科研人员画像构建方法,该方法借助NLP(natural language processing)等技术,可以自动地从各类出版物中提取作者的研究方向、研究能力等信息,进而基于资源描述框架(resource de‐scription framework,RDF)生成科研人员画像,并介绍了其在关键词搜索排名、审稿人推荐等方面的应用。Bravo 等[9]从个人标识(identification)、研究兴趣(interests)、研究目标(objectives)、可达性(accessibility)、 文 凭(transcription)、 专 业 技 能(skills)、隶属关系(affiliation)7 个方面构建了科研人员画像。Boussaadi 等[10]基于科研人员的论文数据,借助LDA(latent Dirichlet allocation)主题模型构建出科研人员画像,并讨论了使用Gensim 和Mallet 两种LDA 实现方式对描述科研人员研究兴趣与能力的影响。
在国内,袁伟等[11]从引领前沿、学术影响、顶尖成果和国际视野4 个方面阐述了顶尖科技专家的主要特征,在此基础上遴选出811 个顶尖华人科技专家,然后借助画像系统研究了其在机构类型分布、地区分布、学科分布等方面的结构和特点。高扬等[12]以智能制造领域为例,从基本属性、研究兴趣、学术影响力3 个维度构建了该领域杰出人才的画像模型,进而借助统计分析揭示了其群体特征。彭程程等[13]根据个人信息、合作关系和学术谱系3 个维度提出了一套智慧校园学者画像系统,并在此基础上研究了团队核心人物演化等问题。焦特等[14]结合新生代科研人才的特点,从知识、技能、业绩、创新、心理健康及身体健康6 个维度对其进行画像构建,以便对新生代人才进行精准培养和行为预警。
总体而言,国内外对于科研人员画像已经取得了一定的成果,但仍然存在较多问题。一方面是大部分的画像标签仍局限在学术成果和科研项目上,没有囊括科研人员的关系网络、科研信用等方面的信息,因此不够全面细致;另一方面是大部分画像系统只是对科研人员信息进行罗列或简单的统计,信息的利用率不高,导致画像系统所能提供的信息不够深入透彻。
针对以上问题,本文提出了一种多维度覆盖、多技术融合的科研人员画像构建方法。一方面,在画像标签体系中设立了人员属性和科研属性2 个维度,其中科研属性维度涵盖了科研能力、关系网络和科研信用3 个子维度的标签,因此相较于现有画像系统更加全面细致;另一方面,本文引入了机器学习等技术,提出了实体/关系抽取以及科研能力计算、关系网络构建、科研信用分析等模型,可以基于科研人员的原始数据分析预测出更深层次的信息,切实提高画像系统的应用价值。
2 科研人员画像模型构建
本文围绕科研人员的两个属性维度,提出科研人员画像标签体系,如图1 所示。同时,本文提出一套完整的科研人员画像构建模型,其整体架构如2.1 节所述。此外,为了深入挖掘科研人员的潜在标签,本模型集成了多种机器学习和深度学习技术,形成多个功能子模型,本节重点介绍实体抽取子模型和潜力预测子模型。

图1 科研人员画像的标签体系
2.1 整体架构
科研人员画像模型主要分为三层,分别是数据支撑层、数据挖掘层和画像展示层,如图2 所示。首先,数据支撑层主要用于采集和存储构建画像所需的各种原始数据。然后,数据挖掘层借助各种模型从原始数据中挖掘出更深层次的信息,这里的模型主要包括两类,一类是以实体抽取为核心的自然语言处理模型,它是后续进行数据挖掘的基础;一类是为提取科研人员画像标签而打造的模型,主要包括人员属性标签提取模型、科研能力计算模型、关系网络构建模型和科研信用分析模型。最后,画像展示层将各类原始信息和处理后的信息进行整合,形成科研人员画像的人员属性标签和科研属性标签,在画像构建完成后,还可使用数据可视化工具将科研人员画像直观形象地呈现出来。
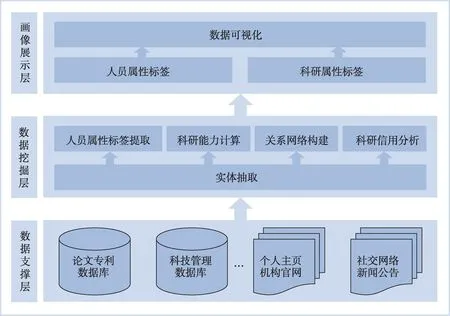
图2 科研人员画像模型整体架构
2.2 实体抽取模型
实体抽取作为自然语言处理领域的基础任务之一,也是本文进行科研人员标签提取的关键技术之一。在采集到科研人员的原始数据后,一般都需要从文本中进行实体抽取,抽取出的实体既可以作为部分标签的直接结果,又可作为深入挖掘标签的文本特征,因此对整个画像模型具有重要意义。
实体抽取技术主要用于识别出文本中的人名、地名、组织名等实体,在本文中,需要抽取的实体主要包括科研人员姓名、科研机构名称以及各类专业术语等。自20 世纪90 年代以来,基于统计机器学习的方法逐渐成为实体抽取的主流,并且取得了不错的效果,其中具有代表性的模型包括隐马尔可夫模型(hidden Markov model,HMM)、最大熵模型(maximum entropy model)以及条件随机场(condi‐tional random field,CRF)等。
进入21 世纪,随着深度学习的流行,卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)等神经网络模型被逐渐应用到实体抽取领域,特别是以Bi-LSTM-CRF (bi-directional long short-term memory CRF)模型为代表的实体抽取模型在许多领域都表现出了较强的性能,但是该模型的一个问题在于,在输入层往往需要将句子转换成词向量的形式,而由于分词结果难免出现错误,所以输入层的误差会逐层传播,影响到最终的实体抽取效果。因此,本文对Bi-LSTM-CRF 模型的输入层进行了改进,提出了一种基于词汇增强的实体抽取模型,其网络结构如图3 所示。

图3 基于词汇增强的Bi-LSTM-CRF网络结构
本文提出的模型与传统的Bi-LSTM-CRF 模型最主要的区别在于,其输入层同时采用了字嵌入和词嵌入两种表示形式。在字嵌入层面,使用预训练的BERT(bidirectional encoder representation from trans‐formers)模型获得每个字符对应的字向量,从而引入了字符级别的信息。在词嵌入层面,为了避免分词错误造成的误差传播,本文通过查找词汇表获得所有可能的分词结果,然后根据词频将对应的词向量进行归一化,从而获得最终的词向量。通过这种方式可以有效降低错误分词结果的权重。
对于由n个字符构成的句子S={c1,c2,…,cn},使用BERT 模型获得每个字符对应的字向量,即其中,ci表示第i个字符;表示第i个字符对应的字向量。

对于上述的句子S,如果要获得对应的词向量形式,首先需要扫描整个句子,获得其在词汇表中出现的所有单词,然后借助训练好的word2vec 模型获得单词对应的词向量,最后根据词频计算出每个字符所匹配到单词词向量的归一化形式,作为该字符对应的词向量结果,即

其中,V w i表示第i个字符对应的词向量结果;w表示该字符所匹配到的某个单词;S表示该字符匹配到的所有单词的集合;f(w)表示单词w的词频;ew表示单词w对应的词向量;edefault表示第i个字符未匹配到任何单词时所赋予其的词向量结果,既可以为零向量,也可以为所有单词词向量的平均值。
举例来说,对于“武汉市长江大桥将于年内竣工”这句话,通过在词汇表中扫描,发现“武”对应的单词包括{“武汉”:108次,“武汉市”:92次,“武汉市长”:29次},则“武”对应的词向量为“武汉”“武汉市”“武汉市长”3 个单词对应词向量乘以词频然后归一化的结果。
在获得第i个字符对应的字向量和词向量后,进行拼接即可获得该字符在嵌入层对应的向量Vi,即

在获得嵌入层的结果后,将其输入Bi-LSTMCRF 模型,即可获得实体抽取的结果。
2.3 科研属性标签抽取模型
2.3.1 科研能力计算模型
1)综合实力计算
综合实力是了解科研人员最直观的指标,它从论文、专利、项目等方面对科研人员的能力进行全方位的衡量。在本文中,综合实力通过一个在[0,100]范围内的值CS(comprehensive strength) 表征,该值由论文得分P1、专利得分P2和项目P3得分加权求和得出。
在论文方面,本文的数据一部分来自中国知网、SpringerLink 等数据库,另一部分来自Research‐Gate、知乎、微信公众号等互联网平台数据,由于这些平台提供了论文分享、讨论等功能,所以可以在一定程度上反映出论文的影响力和学术价值。
论文得分P1由上述两类数据的部分指标加权求和得出,各指标取值及其权重如表1 所示。

表1 论文得分相关的指标取值和权重
其中,期刊/会议级别的取值v1可根据实际情况自行赋值,其余指标的取值v2~v8可直接采用指标的统计结果赋值。根据表1,可计算出论文得分
在专利方面,本文仅考虑国家发明专利,专利得分P2的取值即为科研人员所获授权国家发明专利的数量。
在项目方面,由于科研项目的等级以及在其中扮演的角色都在一定程度上反映了科研人员的综合实力,因此项目得分P3的计算方式为其中li和ri分别表示科研人员所参与项目的等级和在其中扮演的角色,具体标准如表2 和表3 所示。

表2 科研项目等级计分标准

表3 人员角色权重分配标准
在计算出论文得分P1、专利得分P2和项目P3得分后,即可计算出科研人员的综合实力得分:
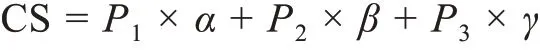
其中,α、β、γ分 别表 示P1、P2、P3的 权重,α+β+γ= 1。在计算出综合实力得分CS 后,将所有科研人员的该项得分除以最高得分,即可获得归一化后的综合实力得分。
2)科研潜力计算
根据《中国科技人才发展报告(2020)》的相关数据,2019 年我国国家自然科学奖获奖成果完成人的平均年龄为44.6 岁,超过60%的完成人是年龄不足45 岁的青年才俊。再如,从国家重点研发计划实施情况来看,45 岁以下的科研人员占全体参研人员的比重达到了80%以上。由此可以看出,青年人才已经逐渐成为我国科研人员的主力军。因此,如何合理评估青年科研人员的潜力,从而对其进行定向培养已经成为情报学界的重要研究问题。针对这个问题,本文提出了一种基于LVQ(learning vec‐tor quantization) 神经网络的科研人员潜力预测模型。
LVQ 即学习向量量化模型,属于前向神经网络模型,它基于统计分布的自适应数据分类思想,可以通过竞争性的隐含层实现函数传递,因此其隐含层也常被称为竞争层。LVQ 神经网络由输入层、隐含层和输出层组成。其中,输入层和隐含层之间为全连接,而隐含层和输出层之间为部分连接,也即每个输出层神经元与隐含层神经元的不同组相连接。
隐含层神经元个数总是大于输出层神经元个数,隐含层神经元和输出层神经元的值只能为1 或0,而两层神经元之间的连接权值固定为1。在网络训练过程中,输入层和隐含层神经元间的权值将被修改,即当某个输入模式被送至网络时,与输入模式距离最近的隐含层神经元被激活而赢得竞争,其状态变为“1”,但其它隐含层神经元的状态均为“0”。因此,与被激活神经元相连接的输出神经元也发出“1”,而其他输出层神经元状态均为“0”[15],如图4 所示。

图4 LVQ模型的计算方式[15]
在本文中,科研人员潜力预测被当作一个分类任务,即将科研人员潜力从高到低分为5 个等级,分别是Ⅰ级、Ⅱ级、Ⅲ级、Ⅳ级、Ⅴ级。使用LVQ 神经网络进行潜力预测的具体步骤如下。
(1)采集数据。通过查阅大量文献,本文共确定并采集了10 类与科研潜力有关的指标,如表4 所示。完成数据采集后,按照8∶2 划分训练集和测试集。

表4 科研人员潜力预测模型所需指标
(2)初始化神经网络。LVQ 神经网络具有不需要对输入向量归一化以及正交化的特点,利用MATLAB 中神经网络工具箱函数可创建LVQ 神经网络。
(3)模型训练。将训练集作为LVQ 神经网络的输入向量,利用LVQ2 算法对网络的权值进行调整,直到满足训练要求迭代终止。
(4)模型验证。网络通过训练后,可对测试集中的样本数据进行预测,获得对应的输出结果,将该结果与人为识别的结果进行对比,以此来评判模型的质量。
3)社会影响力计算
社会影响力主要依据科研人员的头衔、奖励和学术机构任职等情况而确定,并由一个取值在[0,100]范围内的Y表示,该值由头衔得分Y1、奖励得分Y2、职称得分Y3和任职得分Y4计算得到,如表5 所示。表5 中的得分属性可根据不同要求和情况进一步优化、调整与配置。

表5 社会影响力评分标准
社会影响力得分Y的计算方法为:先从Y1、Y2、Y3这3 个子指标中选取值最大的一项,然后加上Y4的得分,最后进行归一化,即

2.3.2 关系网络构建模型
科研人员的关系网络是了解科研人员行为特征的重要参考之一,因此本文将关系网络纳入科研人员画像中,主要包括三类关系,分别是科研团队关系、合作学者关系和师生传承关系。其中,学界对前两类关系的研究较为成熟,对应的提取方法也较为简单,例如,科研团队关系可以从项目承担团队名单中直接提取,合作学者关系可以从论文合著作者或专利共同发明人中直接提取。但是,目前对第三类关系即师生传承关系的研究较少,师生传承关系在众多科研领域中广泛存在,在很大程度上影响到科研人员个人和群体的发展走向,因此研究如何提取这类关系具有重要意义。
本文试图沿着两个途径提取科研人员的师生传承关系。一个途径是直接提取学位论文库的结构化数据,从作者和指导教师字段构建师生关系;另一个途径是借助基于CNN、RNN、GCN(graph con‐volutional network)分类的关系提取方法,从科研人员的论文致谢、个人博客、学术论坛、新闻报道等文本中,自动地提取出 老师,指导,学生 三元组,进而形成师生关系网络。在构建出师生关系网络后,还可通过简单的规则推导出同门关系,从而完善整个关系网络。如图5 所示。

图5 师承关系提取流程图
2.3.3 科研信用分析模型
近年来,部分科研人员涉嫌学术不端的事件时有发生,给所在机构乃至整个学术界造成了较大的影响。因此,本文将科研信用作为科研人员画像的标签之一,希望能从新闻报道或管理部门公告等数据中自动提取出科研人员所涉及的学术不端事件,作为科研人员的信用标签。
科研信用分析模型的具体步骤为:首先通过网络爬虫采集大量的新闻报道和科技管理部门公告等文本数据,然后利用实体抽取模型识别出其中的科研人员姓名实体,同时将学术不端关键词库与文本数据进行匹配,若文本数据中存在学术不端相关关键词,则初步认定该科研人员涉嫌学术不端,并生成对应的信用标签。由于学术不端行为发生的概率较低,并且其真伪性需要专家介入调查,因此,在产生负面的信用标签后,还需要人工审核以决定该标签是否纳入最终的画像系统中。如图6 所示。
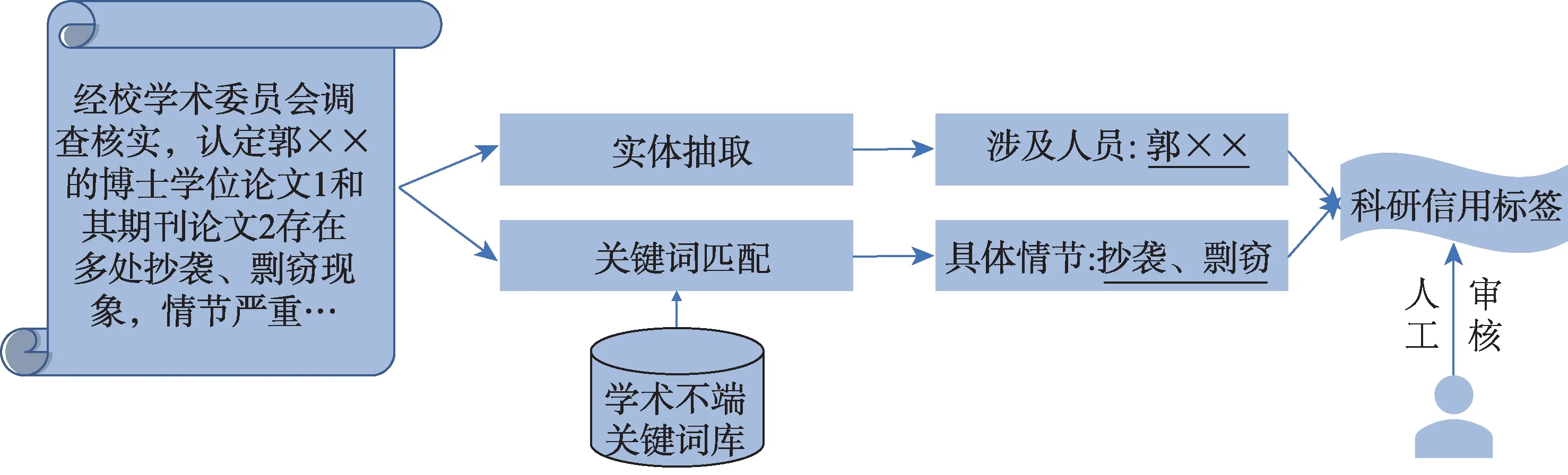
图6 科研信用标签提取步骤
3 科研人员画像构建实例
为了证实方法的可行性,本文以部分科研人员为例,给出了其画像的具体构建过程,并借助数据可视化的方式将构建结果直观地展示出来。
3.1 数据收集
构建科研人员画像相关的数据类型、包含信息和来源如表6 所示。
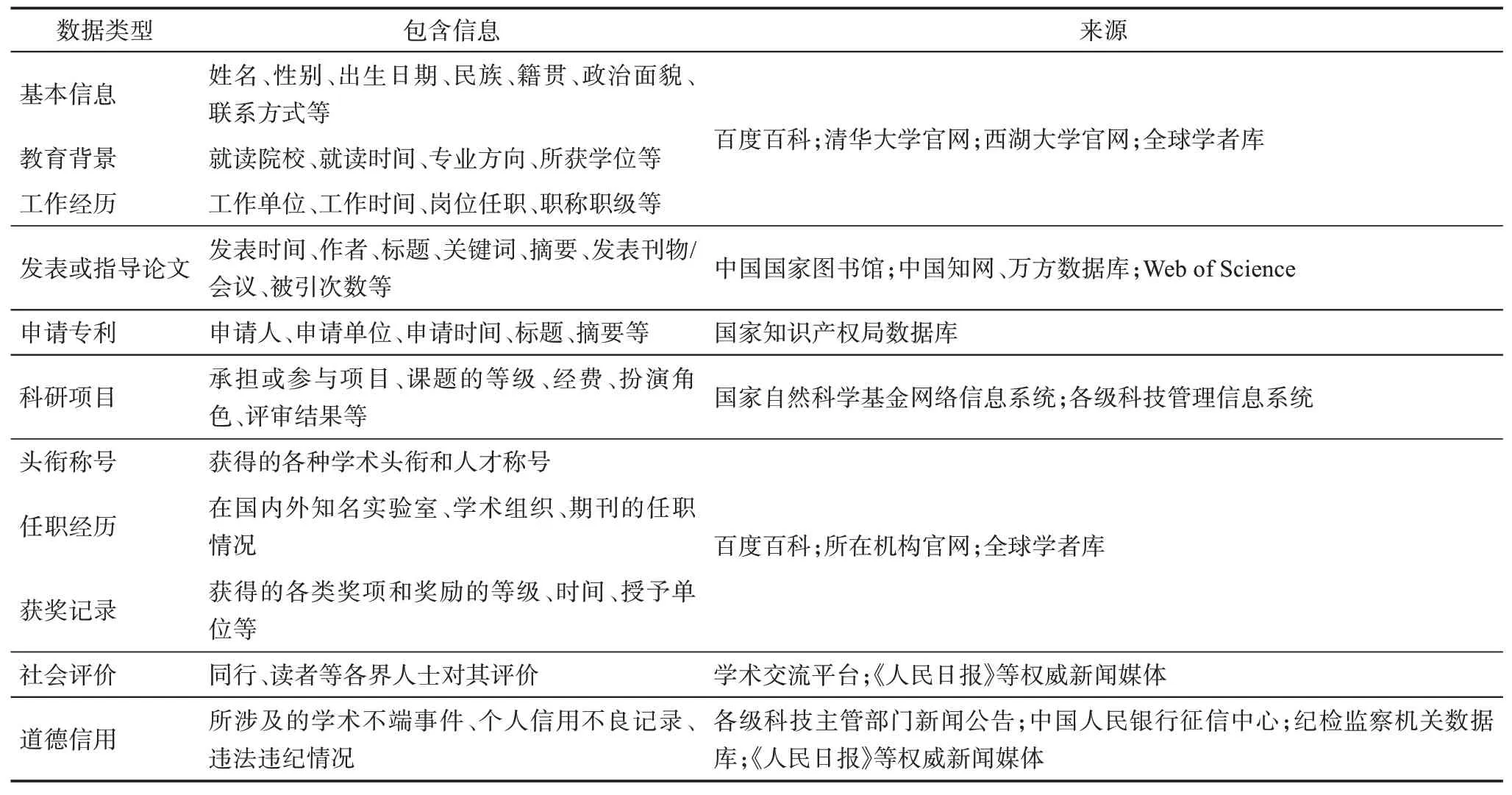
表6 科研人员画像涉及的数据类型、包含信息和来源
3.2 数据预处理
在本文中,数据预处理阶段除了常见的数据统一、数据去重等操作外,还需要进行姓名消歧操作。
在各类学术出版物中,姓名歧义问题经常出现,它主要有两方面的含义[16]:一是同名异人问题,即不同的人可能拥有相同的姓名,这种问题在中文著作中较为常见;二是同人异名问题,即同一个人具有不同的姓名,例如,“施一公”对应的外文名包括“Shi Yigong”“Shi YG”“Shi Y.G.”等,这种问题在外文著作中较为常见。由于姓名歧义问题的存在,在数据收集阶段获得的原始数据可能存在错误,因此必须使用姓名消歧技术对其进行预处理。目前姓名消歧的主要思路是利用图模型和网络关系等方法计算得到出版物之间的相似度,然后通过聚类的方式进行姓名统一。本文使用经典的Kmeans 算法对收集到的论文进行聚类,聚类的簇数使用肘方法(elbow method)[17]确定,然后将聚为一类的论文所对应的作者姓名统一,达到消歧的目的。
在姓名消歧完成后,即可将数据存入数据库中,本文采用Neo4j 数据库进行数据存储。Neo4j 是一种NoSQL 图形数据库,相对于传统的关系型数据库,它支持更多的数据类型,并且具有高性能、轻量级、可扩展等优势。在存入数据库后,一方面,需要对时间、日期、单位等字段的格式进行统一;另一方面,由于不同数据库所收录的数据可能存在重复现象,因此还需要对数据记录进行去重操作。
3.3 标签生成与画像可视化
借助上文所述的实体抽取模型以及科研能力计算模型、关系网络构建模型和科研信用分析模型,可生成科研人员画像所需的各种标签数据。为了更加形象、直观地展示各类标签,本文采用数据可视化的方式对标签进行加工处理,部分结果如图7~图9 所示。

图7 科研人员基本信息、工作方向、科研成果及获奖情况
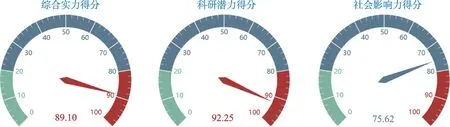
图9 科研人员综合实力、科研潜力、社会影响力得分
4 科研人员画像构建所面临的问题
(1)科研人员画像的时效性有待提升。
在个性化推荐、精准营销等场景中,用户画像所使用的数据大多来源于日志等互联网实时数据,因此构建出的用户画像与实际的目标用户特征差异相对较小,时效性也相对较好。然而,科研人员画像的数据来源有相当一部分是其产出的各类文献,这些文献从开题到发表之间的时间较长,因此构建出的画像时效性会受到较大影响[18]。例如,在2018年公布的国家重点研发计划申报指南“基于立体精准画像的学术同行分类与推荐系统”中,就要求“个体科研行为画像与真实行为的时间间隔在72 小时以内”,这无疑是一个很大的挑战。为了达到这一要求,未来可以考虑多引入一些互联网上科研人员之间的相互评价、互动等实时数据。
(2)科研人员画像的质量难以评价。
图8 科研人员经历
目前,对科研人员画像的研究大多集中于数据集成或标签构建方面,尚未提出一种行之有效的画像质量评价方法,因此无法确定构建出的科研人员画像的质量好坏。为了解决该问题,一方面可以将科研人员画像应用于人才评价、专家推荐、项目申报等下游任务中,根据下游任务的反馈来评判画像质量的好坏;另一方面,针对高层次的科研人员,可以直接采集本人或者权威同行对其画像的意见,从而获得一手的评价结果和改进方向。
5 小 结
为了有效利用散乱在各个数据源的科研人员信息,并对其整合以便全面、直观地了解科研人员,本文基于机器学习的实体抽取模型以及科研属性标签抽取模型,提出了科研人员画像的构建方法。该方法从人员属性、科研属性两个维度刻画了科研人员信息,并借助可视化方法对科研人员的标签进行处理。通过数据收集、预处理及可视化呈现,对本文提出的画像模型构建方法进行了验证,使科研人员的画像情况得到了展现,对科技管理、人才评价等场景起到了积极的作用。
