一种基于改进YOLOv4算法的茶树芽叶采摘点识别及定位方法
2022-08-30徐凤如张昆明王瑞卿万盛明
徐凤如,张昆明,张 武,王瑞卿,汪 涛,万盛明,刘 波,饶 元
(安徽农业大学 信息与计算机学院,安徽 合肥 230036)
茶树芽叶采摘点的准确识别及定位是采茶机器人高效运作的关键环节。运用人工智能技术开展对茶树芽叶采摘点定位方法的研究,改变人工采摘的传统模式,对提升茶叶采摘效率,缓解劳动力短缺具有重要意义。
已有研究对茶树芽叶识别提出了相应的分析方法:1)传统方法[1-3];2)深度学习方法[5-7]。对于传统方法:杨增福等[1]在RGB颜色空间中提取茶叶图像的G1分量,然后根据芽叶的形状特征,检测出茶树芽叶的边缘;汪建等[2]通过在颜色空间上对像素进行划分,然后结合颜色距离和边缘距离进行区域生长合并,分割出茶树芽叶;张浩等[3]基于色彩因子法实现了自然环境下茶树芽叶的识别。然而上述文献采用的方法对色彩区分度要求较高,容易受到天气等自然环境影响。对于深度学习方法[4]:许高建等[5]使用更快速的基于区域的卷积网络方法(Faster Region-Convolution Neural Network,Faster R-CNN)模型来识别茶树芽叶芽稍区域,结果表明该算法有着较高的准确率与召回率;王子钰等[6]基于单次检测器(Single Shot MultiBox Deteltor,SSD)算法提取茶叶图像的特征,从而实现对茶树芽叶的精确与自适应检测;张怡等[7]基于Res Net卷积神经网络搭建了茶叶的深度学习模型,在保持模型识别均衡的同时占用较小的内存空间。以上方法可以准确地识别出图像中的茶树芽叶区域,但识别速度慢,无法满足自动化采茶的实时性要求。YOLOv4[8]算法是一种简单高效的目标检测模型,其CSPDark Net53神经网络特性使其在目标检测的实时性和准确性上均优于上述深度学习方法。
茶树芽叶形状较小,采摘点位置的偏差会损坏芽叶的品质,因此在检测出茶树芽叶区域后,还要进一步在区域范围内确定采摘点的位置。陈钰婷等[9]使用全卷积深度神经网络(Fully Convolutional Network,FCN)模型[10]及OpenCV中的“矩”函数对茶树芽叶的采摘点进行定位,全卷积深度神经网络,即神经网络中全由卷积层相连接,对图像进行像素级的分类,解决了语义级别的图像分割问题。裴伟等[11]根据茶树芽叶的外形轮廓提取其最小外接矩形,并以矩形的中心点为采摘点。陈妙婷等[12]将采摘点标注信息喂入卷积神经网络中,训练得到良好的采摘点识别模型。以上方法可以定位到芽叶采摘点,但是使用卷积神经网络识别茶树芽叶的采摘点区域,并不能得到具体准确的特征,容易出现多处错误识别的情况;以最小外接矩形的中心点为采摘点的误检率较高。
本研究拟采用改进型YOLOv4-Dense算法对茶树芽叶进行目标检测,然后基于HSV颜色阈值分割方法提取目标区域内的茶树芽叶轮廓,并运用OpenCV形态学算法找到符合条件的特征点,以期为采摘点的准确定位提供有益的借鉴。
1 材料与方法
1.1 图像采集
本文研究的太平猴魁芽叶数据采集于黄山市太平区茶园基地,采集设备有Inter D415深度相机、尼康数码相机和智能手机,对应的二维图像分辨率分别为1 280 P×720 P、6 000 P×4 000 P和3 000 P×4 000 P。为了防止模型过拟合且增加其鲁棒性,采集样本中包含多气象环境、不同芽叶稠密度以及不同光照条件下的茶树图片共5 000余张,均匀随机抽取其中的70%作为训练集,另外的30%作为测试集,图1为一组茶树芽叶的图像数据集。

图1 数据集部分样本Fig.1 Some samples of the data set
1.2 芽叶目标检测方法
1.2.1 YOLOv4算法模型
YOLO系列目标检测算法将检测问题转换成回归问题,是典型的端到端算法模型[13],只需一次基础卷积网络操作便可得到目标检测对象的选框区域、位置信息和置信度的值,大大提高了检测的效率。
YOLOv4算法在数据层面采用了Mosaic数据增强方法,随机取得样本集中的4张图片,进行任意裁剪并拼接成原始图片大小,丰富了小目标数据集,从而增强模型的鲁棒性,并采用自对抗训练(Self-Adversarial-Training,SAT)在原始图片的基础上添加噪声干扰,使算法产生误判的样本,从而提升模型的泛化能力,防止网络过拟合。
YOLOv4算法采用CSPDark Net53作为主干特征提取网络Backbone,主要由CBM卷积块与CSPX卷积残差组合模块构成,其中:CBM卷积块由卷积层Conv、批处理归一化层(Batch Normolization,BN)和Mish激活函数组成;CSPX则由3个CBM卷积块和X个Res unit模块张量拼接而成[9],如图2所示。Res unit模块由主干卷积路径与一条大的残差边组成[4],在提取特征的同时,借助残差边的跳跃连接有效缓解深度网络中的梯度消失现象,如图3所示。

图2 CSPX结构图Fig.2 CSPX structure diagram

图3 Res unit结构图Fig.3 Res unit structure diagram

1.2.2 Dense模型
残差网络ResNet[18]模型可以训练出更深的卷积神经网络模型,从而获得更高的准确度。ResNet模型的核心是通过建立前后层之间的跳跃连接来应对网络的梯度消失及退化问题。
DenseNet[19]模型的网络整体结构与ResNet模型一致,但相比于ResNet模型,DenseNet模型提出了一种新的密集连接机制:即网络每一层的输入都是前面所有层输出的并集,且该层所学习的特征图也会被直接传给其后面所有层作为输入其中:DenseNet模型网络的密集连接机制如图4所示,图5为ResNet模型网络的连接机制如图5所示。由图4可以看到,在DenseNet模型密集连接机制中,每一层的特征与前面所有层的特征在通道(channel)维度上连接在一起,实现了特征的复用,由于每层都直接连接输入信息和最终的误差信息,因此可以减轻梯度消失的现象。

图4 DenseNet模型网络的密集连接机制Fig.4 The dense connection mechanism of the Dense Net network model

图5 ResNet模型网络的短路连接机制Fig.5 The short-circuit connection mechanism of the ResNet network model
DenseNet模型的密集连接方式需要特征图大小保持一致,因此模型采用了“DenseBlock+Transition”的结构。“DenseBlock”是包含很多网络层的模块,由BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)组成,其中:BN表示批处理归一化层;Conv表示卷积层;Re LU表示线性整流函数。一个DenseNet由多个DenseBlock组成,其结构如图6所示,各个层的特征图大小一致,层与层之间采用密集连接的方式。
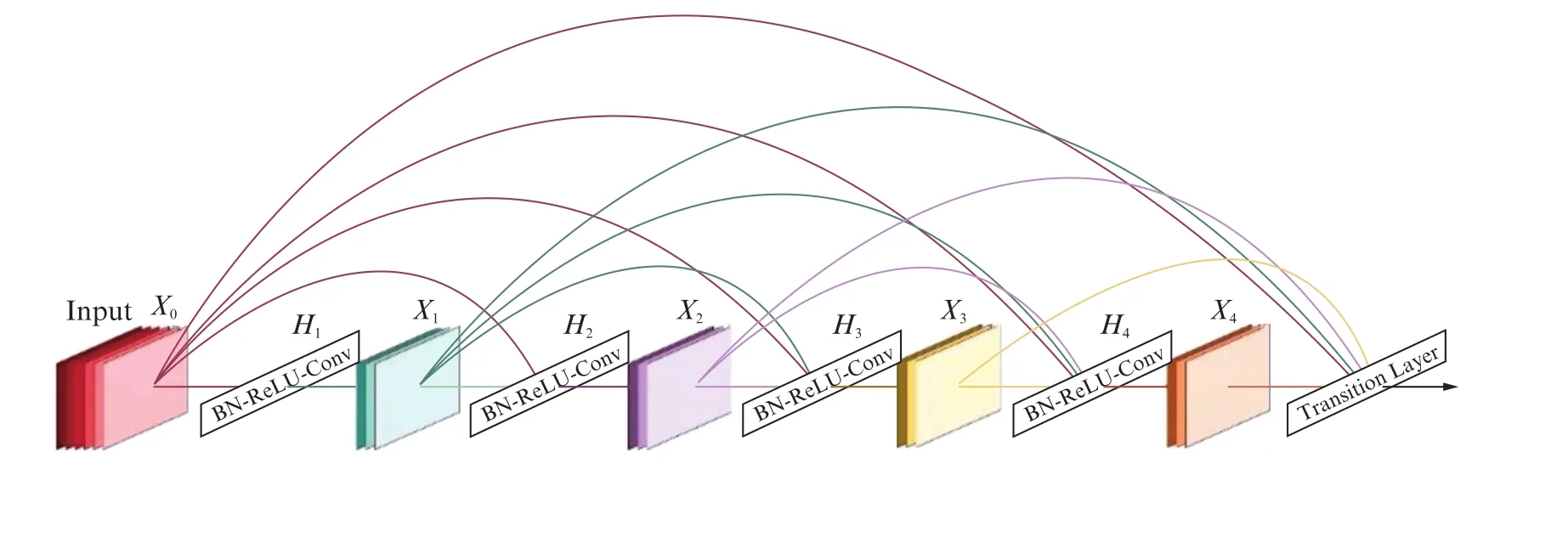
图6 DenseBlock结构图Fig.6 DenseBlock structure diagram
“Transition”结构是连接相邻两个Denseblock的过渡层,由BN-Conv(1×1)-AvgPooling(2×2)组成,用于降低特征图的大小,完成前后DenseBlock模块的连接。DenseNet的高效率关键就在于网络每层计算量的减少以及特征的重复利用,在DenseNet中,会连接前面所有层作为输入,得到的输出式为

其中:xl表示输出;Hl(·)代表非线性转换函数,其中可能包括一系列的BN、ReLU、Pooling及Conv操作;l为当前层;[x0,x1,…,xl-1]就是将之前所有的特征图以通道的维度进行合并,由于每一层都包含前面所有层的输出信息,因此对特征图数量的要求并不高,从而减少了DenseNet模型的参数量。
1.2.3 改进的YOLOv4算法模型
DenseNet通过增强网络层间的密集度缓解了梯度消失的现象,加强了特征的传播与复用,并减少了各个网络层的参数量和计算量,因此,在YOLOv4中的CSPDark Net53网络基础上将残差块CSPX中的残差单元Res unit替换为密集连接单元Dense unit,并将其定义为D-CSPX,如图7所示,其中:“+”为add操作;C为Concat操作;CSPX结构图如文中图2所示。

图7 修改模块的结构图Fig.7 Structure diagram of the modified module
改进后的YOLOv4-Dense算法的网络结构如图8所示。输入图片为茶树数据集图片,在模型训练的网络参数部分可以设定好图片像素宽(width)和像素高(height),不需要人为进行每张图片的调整。CBM由卷积层(Conv)、批处理归一化层(Batch Normolization,BN)和Mish激活函数组成;CBL由卷积层(Conv)、批处理归一化层和Leaky Re LU激活函数[20]组成;Headn通过一个CBL后再经卷积可实现特征提取;SPP为空间金字塔池化,即采用1×1、5×5、9×9、13×13的最大池化的方式,进行多尺度融合。改进后的YOLOv4-Dense网络沿用了YOLOv4网络的特征融合层Neck及预测层Head,通过修改残差网络为密集连接网络,加强了网络的特征复用,提高了数据集训练的效率及模型的检测精度。

图8 YOLOv4-Dense模型的网络结构图Fig.8 The network structure diagram of YOLOv4-Dense model
1.3 芽叶采摘点定位方法
模型识别检测出图像中的茶树芽叶区域后,需要将目标芽叶区域单独分割出来,用于进一步的处理,图9(a)为检测出的茶树芽叶图像,检测框上的值为置信度。为准确获取采摘点位置,还需要将茶树芽叶的轮廓提取出来。图9(b)和图9(c)分别为RGB色彩通道和HSV色彩通道下的茶树芽叶区域图片,由于外界光照和拍摄角度变换不定,因此在RGB通道下会产生芽在明处,茎在暗处的样本图,目标部分的阈值范围难以确定,但在HSV色彩通道下,目标芽叶区域不会受到该因素的影响,阈值信息有很大的确定性。图9(d)、(e)、(f)分别为R、G、B色彩通道下的茶树芽叶区域图片,图9(g)、(h)、(i)分别为H、S、V色彩通道下的茶树芽叶区域图片,通过对比分析这些图片可以得到,在H色彩通道和S色彩通道下茶树芽叶和老叶背景部分颜色过渡明显,因此选择在H色彩和S色彩通道下提取芽叶的轮廓。

图9 不同色彩通道下的茶树芽叶图像Fig.9 Images of tea buds and leaves under different color channels
轮廓提取常用的方法是阈值分割,根据颜色特征把目标与背景分离。在HSV色彩通道下,H色彩通道和S色彩通道的值决定了该像素点的色相与饱和度,V色彩通道的值决定了像素点对应颜色特征下的亮度。由于亮度信息无法区分出芽叶与背景,因此从含有茶树芽叶的100张HSV图像中,按照芽叶的三个特定部位随机选取若干点确定阈值分割中的H和S的取值范围,部分数据如表1(见第 466页)所示。

表1 部分茶树嫩芽像素点信息Tab.1 Pixel information of some tea buds
计算出以上3个特定区域H和S的平均值,比较分析后可以得到整体茶树芽叶区域H和S的取值范围,相关公式如下:

式中:i为随机选取的像素点;j=1、2、3分别代表茶树芽叶的3个特定区域,由式(6)和式(7)可得到嫩芽不同部分的像素点H和S的均值信息,代入式(8)和式(9)可得

对二值图像进行中值滤波,去除阈值分割过程中产生的椒盐噪声,得到的效果如图10(a)所示,白色部分为茶树芽叶的基本轮廓。然后对图像进行腐蚀操作,使芽叶与芽茎分离,出现叶茎熔断行。由于腐蚀操作会使目标芽叶区域零散分布,所以形态学操作后还需找到其最大连通区域,得到如图10(b)所示的部分嫩芽轮廓图,虚线为熔断行所在位置。熔断行以上的部分为需要采摘的目标茶树芽叶,熔断行以下部分为其他不相关区域,进行全部滤除。此时,熔断行与目标采摘区域的交点即为理想采摘点,并将该位置的像素点拓展为长40个像素,宽10个像素的矩形条,将其定义为采摘点横向路径。如图11(a)所示,红色区域为采摘点横向路径,将其还原到原图中即可得到采摘点的二维像素坐标,最终效果如图11(b)所示。

图10 茶树嫩芽采摘点定位过程Fig.10 The process of locating the picking point of tea buds

图11 茶树嫩芽采摘点位置Fig.11 Location of tea plant buds picking point
2 实验与讨论
2.1 运行条件及训练过程
本研究使用YOLOv4-Dense模型。实验在Ubuntu 18.04操作系统上运行,处理器为Intel Xeon E5,主频2.3 GHz,运行内存32 GB,训练使用的GPU为RTX 2080Ti。程序运行在Anaconda搭建的虚拟Python环境下,其中Pytorch版本为1.7.0。
使用Adam优化器对模型进行优化,模型训练分为两个阶段,分别是冻结阶段和解冻阶段。冻结阶段设置起始世代数Init_Epoch为0,冻结训练的世代数Freeze_Epoch为50,冻结训练世代批样本数为8,网络参数学习率为0.001。解冻阶段设置总训练世代Un Freeze_Epoch为100,解冻训练世代数批样本数为4,网络参数学习率为0.000 1。
训练集和测试集的loss曲线如图12所示,其中训练集损失值、测试集损失值、平滑后的训练集损失值、平滑后的测试集损失值呈现下降的趋势,可以看到最终训练集与测试集的loss收敛到了0.7左右,检测模型已经收敛。

图12 训练集和测试集的loss曲线Fig.12 Loss curve of training set and verification set
2.2 检测结果及对比分析
图13为使用训练好的检测模型对自然条件下茶树芽叶进行识别检测的结果,可以看出,本研究采用的方法对大部分芽叶具有良好的检测效果,能够以较高置信度检测出目标对象。

图13 茶树芽叶检测结果图Fig.13 Tea bud leaves detection result view
为了进一步研究YOLOv4-Dense检测模型在茶树芽叶检测方面的有效性,将其与YOLOv4,YOLOv3[21]进行了对比。模型的对比实验均在同一数据集上进行训练和测试。图14为自然条件下3种方法的检测结果对比,可以看到,针对同一张茶树数据集,YOLOv4-Dense模型检测出了11个芽叶区域,YOLOv4模型检测出了7个芽叶区域,YOLOv3模型检测出了5个芽叶区域。针对图片中叶片遮挡的芽叶部分,YOLOv4-Dense表现出了更好的性能。

图14 检测结果对比图Fig.14 Comparison among detection results view
检测模型常用的评价指标有m AP和FPS,前者代表平均准确度,后者代表推演速度。m AP值由预测模型的精确率(Precision)和召回率(Recall)计算得到,本研究针对单一目标检测,平均精度可用AP(Average Precision)值表示,AP值为Precision-Recall曲线所围成的面积,并使用F1score代表精度与召回率的调和均值。Precision、Recall、F1score的计算公式如式(13)、(14)和(15)所示。

令待检测的目标为正类,其他为负类,则:TP为正类预测为正类;FN为正类预测为负类;FP为负类预测为正类;TN为负类预测为负类。
3种检测模型的PR曲线如图15所示,由此图可以发现,YOLOv4-Dense曲线的封闭面积大于改进前的面积,即AP值更高,实现了更高的平均精度,卷积神经网络的检测效果更好。
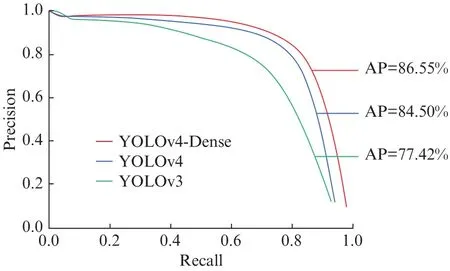
图15 3种检测模型在数据集上的PR曲线Fig.15 PR curves of 3 kinds detection models on the data set
不同模型的精确率(Precision)、召回率(Recall)、平均准确度(AP)、F1分数(F1score)、每秒可以处理的图片数量(Frames Per Second,FPS)如表2所示。

表2 模型性能指标评估对比Tab.2 Model performance index evaluation and comparison
由表2模型性能指标评估对比表明:YOLOv4-Dense模型的网络复杂度与网络密度都更高,使得检测精度要高于其它模型。YOLOv4-Dense模型的Precision值为91.83%,比YOLOv4模型高2.21%,比YOLOv3模型高5.66%。YOLOv4-Dense模型的Recall值为68.84%,比YOLOv4模型高2.00%,比YOLOv3模型高15.26%。YOLOv4-Dense模型的AP值为86.55%,比YOLOv4模型高2.05%,比YOLOv3模型高9.13%。YOLOv4-Dense模型的F1score为0.79,比YOLOv4模型高0.02,比YOLOv3模型高0.13。YOLOv4-Dense模型处理图片的速度稍慢于YOLOv4模型,但并不影响检测效果。可以得到,本研究使用的YOLOv4-Dense模型可以提高茶树芽叶检测的准确率并能达到实时性检测目的,是3个检测模型中最符合应用需求的。
将本文方法与其他茶树芽叶检测方法的识别精确率进行比较,结果见表3。

表3 比较YOLOv4-Dense和其他茶树芽叶识别方法Tab.3 Comparison of YOLOv4-Dense and other tea bud leaves recognition methods
表3中,张怡等[7]基于ResNet卷积神经网络搭建绿茶深度学习模型,识别精确率为90.99%。吕军等[22]基于Alex Net识别模型对不同开放形状的茶树芽叶进行训练学习,识别精确率为88%。周智等[23]基于高色差分离预处理的K-means方法对茶树芽叶进行分割,识别准确率在80%以上。陈钰婷等[9]使用Faster R-CNN模型识别茶树芽叶,识别准确率为79%。本文采用YOLOv4-Dense模型识别茶树芽叶,识别准确率为91.83%。
2.3 采摘点定位结果及对比分析
将茶树芽叶测试集传入采摘点定位模型中进行测试,结果如图16所示。其中,定位框上的P(w,h)为采摘点对应的像素坐标位置,以图片左上角顶点为原点,w为采摘点对应横坐标像素数,h为采摘点对应纵坐标像素数。

图16 自然条件下芽叶采摘点的定位结果图Fig.16 Location results view of picking points for tea buds
本研究针对提出的熔断行交点法获取其多项评估指标,其中:TP为正确定位到的采摘点数,FP为错误定位到的采摘点数,FN为没有定位到的采摘点数。并将熔断行交点法获取的评估值标与矩函数法、最小外接矩形中心点法、卷积网络训练法进行对比,结果见表4(第470页)。

表4 评估指标对比Tab.4 Comparison among evaluation indicators
由表4可以得到,熔断行交点法在定位茶树芽叶采摘点上实现了80.8%的精确率,83.2%的召回率;与矩函数法相比,精确率提升了3.5%,召回率提升了1.4%;与最小外接矩形中心点法相比,精确率提升了7.1%,召回率提升了6.1%;与卷积网络训练法相比,精确率提升了4.4%,召回率略显不足。此外,本研究方法平均定位到一个采摘点的时间为0.119 s,因此可以满足采摘点定位所需的精度与速度要求。
3 结 语
本研究提出了一种基于改进YOLOv4的茶树芽叶采摘点定位方法。一方面,我们在YOLOv4模型的主干网络基础上将Res Net单元替换为DenseNet单元,通过增强网络层间的密集度缓解了梯度消失的现象,加强了特征的传播与复用,提高了茶树芽叶的检测精度;另一方面,我们在有效目标区域内基于OpenCV图像处理方法定位采摘点的位置,实现了80.8%的精确率,83.2%的召回率,与其他定位方法相比,分别提升3.5%和1.4%。
实验结果表明,针对自然环境下的茶树芽叶,本研究方法在定位采摘点上能够取得良好的效果,为采茶机器人提供借鉴。为进一步提升模型的小目标检测能力,扩大其应用场景,在今后工作中我们将继续改进注意力机制。
