差异性案件要素增强的案件舆情时间线生成方法
2022-08-29高盛祥余正涛黄于欣
高盛祥,赵 瑶,余正涛,黄于欣
(昆明理工大学 信息工程与自动化学院,昆明 650500)
(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
E-mail:huangyuxin2004@163.com
1 引 言
随着互联网的快速发展,案件发生后在短时间内会产生大量的微博文本,为了使用户充分了解案件的相关信息,掌握案件的发生发展脉络,通过时间顺序来总结案件舆情生成时间线具有重要的研究意义.
舆情时间线生成可以看做在时间维度上对文本进行内容归纳和概要生成的任务[1,2].早期的时间线生成任务主要关注于如何确定事件发展过程中重要的日期节点.例如,Kessler等人[3]提出一种根据日期下句子的数量判定日期的重要程度,根据搜索查询自动构建时间线.在此基础上,Yan等人[4]通过摘要的方法生成一种进化的跨时间摘要(ETTS)时间线,在不同的时间范围内生成局部和全局摘要,选择得分最高的摘要句生成时间线.但是上述研究仅基于统计的方法来确定重要的时间节点而没有考虑舆情新闻内容的关联性.Nguyen[5]等人提出一种集群间排名算法,该算法将来自多个集群的事件作为输入,并根据事件的内容相关性和显著性对句子进行排名,构成事件主题时间线.Steen等人[6]将描述同一事件的句子表征到高维空间然后进行聚类,生成摘要候选句,通过打分的方式选出最佳摘要句,最终生成事件时间线.
与传统的时间线生成任务不同,案件舆情通常围绕某一特定案件展开讨论,这些舆情新闻通常会关注该案件相关的案件要素,如涉案人员、案发地点等信息.如表1列举了杭州女子失踪案相关的舆情新闻,可以看到所有的舆情文本均关注到了杭州(案发地点)、女子和丈夫(涉案人员)等信息,这些相同的要素可能导致微博文本在高维的聚类空间中出现重叠.通过分析表1我们发现,虽然这些微博文本都是描述杭州女子失踪案的舆情新闻,但是微博文本(1)主要关注女子失踪的事实,而文本(2)则关注女子丈夫杀人分尸的过程,而文本(3)又关注了女儿的心理及抚养问题,每个微博文本虽然都有相同的要素(表1中的黑体字),但是也存在和当前话题相关的差异性要素(表1中的仿宋体字).我们认为可以通过从不同微博文本中抽取差异性的案件要素来增强微博文本的区分度.因此本文提出一种差异性案件要素增强的案件舆情时间线生成方法,在文本表征的过程中,将差异性案件要素和时间要素作为额外的增强信息来强调不同文本之间的差异性,最后基于K-Means聚类方法生成案件舆情时间线.

表1 “杭州女子失踪案”数据集(部分)Table 1 Dataset of “Hangzhou Woman Missing Case”
2 差异性案件要素增强的案件舆情时间线生成模型
基于上述思想,本文提出一种差异性案件要素增强的案件舆情时间线生成模型.该模型主要包括3个部分:1)抽取差异性要素和案件时间,并将它们与微博文本一起作为BERT(Bidirectional Encoder Representations from Transformers)[7]模型的输入,生成文本的高维向量表征;2)利用自编码器将高维向量表征经过线性变换为低维特征向量,通过BOW(Bag of word)重构文本提高上下文一致性;3)基于该低维特征向量和K-Means聚类的方法,并通过自编码过程中的重构损失和聚类损失不断微调聚类中心,生成最终舆情案件时间线.所描述的模型图结构如图1所示.
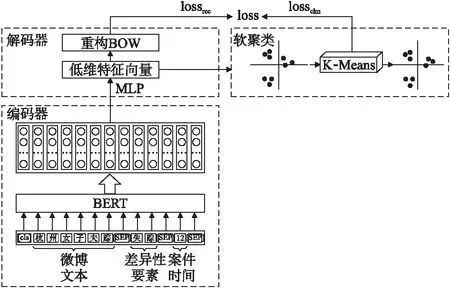
图1 差异性案件要素增强的案件舆情时间线生成模型图Fig.1 Timeline generation model diagram of case public opinion enhanced by different case elements
2.1 编码器
在编码阶段,本方法首先抽取差异性要素k和表示案件时间t,然后将差异性要素k、案件时间t和微博文本c作为BERT模型的输入,进行文本表征.
2.1.1 差异性要素
首先在涉案舆情时间线数据集中,根据数据集的微博文本数目,通过词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)[8]算法抽取描述案件的10个案件要素,记作kdoc.然后在每条微博文本中,使用同样的方法选择词频最高的5个案件关键词,则第i条微博文本的案件关键词记作kconti.最后选取每条微博文本中非案件要素的案件关键词作为差异性要素ki,如公式(1)所示:
ki=kconti-kdoc
(1)
其中,i表示第i条微博文本的差异性要素,-表示案件关键词与案件要素做差值运算.
2.1.2 案件时间
在案件舆情时间线生成过程中,案件时间是一个很重要的因素,在本文的数据集中,案件时间是从微博文本的发文时间中获得的.从微博文本提取案件时间为YYYY-MM-DD,其中,YYYY表示年,MM表示月,DD表示日.然后,如文献[9,10]提出的方法,将案件时间按日期从小到大排序,取最小的案件时间表示为时间标签0,然后将其他的案件时间与该最小的案件时间做差值,差值结果作为其他案件时间对应的时间标签值t.
2.1.3 编码层
在编码层阶段,本文与传统的BERT模型不同,采用的BERT模型的输入如图1所示,BERT的输入部分是个线性序列,每一条输入文本si由差异性要素ki、时间标签ti和微博文本ci拼接得到,它们通过分隔符[SEP]分割,最前面和最后分别增加标志符号[CLS]和[SEP],如公式(2)所示:
si=ki⊕ci⊕ti
(2)
其中,i表示第i条输入文本,⊕表示拼接运算.
然后,经过BERT得到文本的高维表征vi,如公式(3)所示:
vi=BERT(si)
(3)
其中,BERT()表示BERT函数,i表示第i条高维向量.
2.2 解码器
经过BERT编码之后得到文本通用特征向量,为了更好的捕获文本间的关系,在解码过程中,只使用自编码器的解码部分,本文将经过解码器得到的高维特征向量通过线性变换构造低维特征向量,具体做法如下:
该高维表征vi经过自编码进行线性降维(MLP),得到文本的低维表征vdi,如公式(4)所示:
vdi=MLP(vi)
(4)
其中,MLP()表示自编码器中对高维表征vi进行线性降维.
本文引入用于从BERT语言模型进行预训练得到文本的向量表示,然后经过非线性变换重构此文本表示,在线性降维过程中,使用词袋模型(BOW)重构文本[11]提升聚类性能,在重构文本表示过程中的重构损失为Lossrec,如公式(5)所示:
(5)
其中,mi∈[1,2,…,|V|],θ是BERT中编码部分的参数,θ1是自编码器中重构之后的文本参数,V是词典的大小.
2.3 软聚类
经过线性降维之后得到压缩数据,本文选择k-means算法作为聚类算法,但由于在k-means算法中,不同的聚类中心会导致不同的聚类结果,从而得到局部最优,而得不到全局最优,为了解决这一问题,本文引入软聚类[12]算法,将文本以一定的概率分配到各个类别中.首先随机初始化聚类中心,然后重复以下2两个步骤.
步骤1.计算一个向量文本放入每个簇的概率;
步骤2.计算辅助的概率分布,作为编码网络的目标.网络权重和聚类中心会迭代更新,直到满足条件为止.
针对步骤1,向量zi放入uj簇的概率符合自由度为1的学生t-分布[13]Q,如公式(6)所示:
(6)
其中,qij表示使用学生t-分布作为函数衡量向量i的嵌入表示zi和类j的中心uj之间的相似性得分.
针对步骤2,本文使用一个辅助目标分布P,与相似性得分qij相比,该概率的目的是提高聚类纯度,定义如公式(7)所示,其定义依赖于qij的分布.
(7)
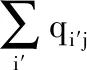
每次迭代需要更新的参数如公式(8)和公式(9)所示:
(8)
(9)
公式(8)是优化自编码中的编码端参数,公式(9)使优化软聚类中心.其中,α是学生t-分布的自由度,值为1.
聚类通过最小化软聚类标签分布Q和辅助目标分布P之间的KL散度来得到最优的聚类结果,如公式(10)所示:
(10)
该公式也是该软聚类过程中的损失函数,最小化目标函数Lossclu是自训练[14]的一种形式.
在软聚类过程中,仅仅使用聚类损失会使嵌入特征空间被篡改[15],因此自编码器的重构损失也被加入到损失函数中,与聚类损失同时被优化,最终得到的文本损失为Loss,如公式(11)所示,通过最终损失不断微调BERT,优化整个聚类过程:
Loss=Lossrec+Lossclu
(11)
其中,Lossrec为重构损失,Lossclu为聚类损失.
3 实 验
3.1 数据集
本文从新浪微博中构建两种不同讨论热度的涉案舆情时间线数据集.涉案舆情时间线数据集的统计信息如表2所示,案件时间跨度描述的是微博文本中所包含的不同案件时间,它决定了聚类中心的数目.“杭州女子失踪案”构建的是从2020年7月18日~2020年7月27日共7420条数据,其中,案件时间跨度是11天;“女子不堪家暴跳楼案”构建的是2020年7月22日~2020年7月27日共2719条数据,其中,案件时间跨度是6天.

表2 涉案舆情时间线数据集的统计信息Table 2 Statistical information of the public opinion timeline data set involved in the case
训练集与测试集的相关信息如表3所示,涉案舆情时间线数据集的训练集和测试集的比例划分为9∶1.其中,“杭州女子失踪案”的训练集是6677条,测试集是743条;“女子不堪家暴跳楼案”的训练集是2447条,测试集是272条.

表3 训练集与测试集的相关信息Table 3 Information about the training set and test set
在两种不同的涉案舆情时间线数据集中的差异性要素的分布情况如图2所示,其横轴表示微博文本中的差异性要素的个数,其纵轴表示微博文本中的差异性要素的个数在涉案舆情时间线数据集中的占比,当差异性要素为0时,本文在拼接文本时将不进行拼接操作,此时BERT编码器的输入为微博文本和案件时间.
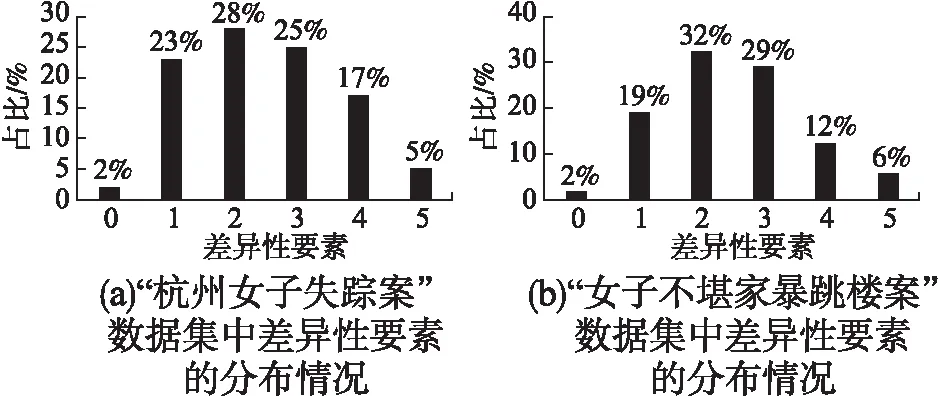
图2 涉案舆情时间线数据集的差异性要素的分布情况Fig.2 Distribution of the different elements of the public opinion timeline data set involved in the case
3.2 实验参数设置
本文使用的是Google提供中文训练的BERT模型,将模型BERT的CLS位置的输出向量句子的向量表示,词典为BERT中文预训练模型chinese_L-12_H-768_A-12中的vocab.txt文件.在实验过程中,批次大小设置为256,学习率为1e-4.在自编码过程中,批次大小设置为64,以0.01的学习率和0.9的动量值初始化随机梯度下降(SGD).在重构过程中,V的大小与BERT词典大小一致为30000条.在聚类过程中,为了减小初始中心对K-Means聚类性能的影响,本文重复100次随机初始化聚类中心[16],并选择最佳中心点,最佳中心点到聚类中心的平方距离最小,实验结果取5次实验的平均值.
3.3 评价指标
本文使用无监督聚类的正确率(Accuracy,ACC)和标准化互信息(Normalized Mutual Information,NMI)[17]两个常用的评价指标.
无监督聚类的正确率定义如公式(12)所示:
(12)
其中,N表示文本总数,yi代表指标函数,yi是xi真实的类标签,ci是算法预测xi的标签,map()表示预测类标签和真实类标签之间进行所有可能的一对一映射.正确率度量会对所有预测标签在真实标签中找到一个最佳匹配[18].
标准化互信息定义如公式(13)所示:
(13)
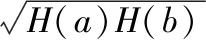
3.4 基线模型
本文的对比实验包括常用的无监督文本聚类方法K-Means和深度聚类算法,详细信息如下:
K-Means:一种基于聚类的无监督机器学习算法,以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.
K-Means(Doc):由gensim工具包提供Doc2vec[19]算法,创建一个文档的向量化表示,然后从自动编码器和句子嵌入两者中学习文本特征,然后使用k-Means聚类算法的分配作为监督来更新编码器网络的权重.
SIF-Train:由Hadifar等人[20]提出,通过线性变换得到低维表征解决短文本稀疏向量的问题,然后使用K-Means算法实现短文本聚类.
K-Means(BERT):使用BERT语言模型进行文本编码,通过微调之后获得句子级别的嵌入,然后从自动编码器和句子嵌入两者中学习文本特征,然后使用k-Means聚类算法的分配作为监督来更新编码器网络的权重.
3.5 实验结果与分析
3.5.1 本文模型和基准模型对比实验
为了验证本方法的有效性,表4列举本文模型和3种基准模型在涉案舆情时间线数据集上的ACC和NMI值.

表4 本文模型和基准模型的对比实验结果Table 4 Comparison of experimental results between this model and the benchmark model
可以看出,1)K-Means、K-Means(Doc)和SIF-Train的实验效果不佳.因为对于K-Means、K-Means(Doc)和SIF-Train方法,对涉案舆情时间线数据集使用的是离散稀疏的句向量表示方法,无法很好的捕捉句子的语义特征,造成实验效果不佳;2)K-Means(BERT)在基准模型上具有相对比较大的提升.因为使用BERT对涉案舆情时间线数据集进行表征时,可以有效的捕捉文本的上下文信息,提升了模型的性能;3)实验结果验证了本文模型的优越性.在本文模型中,加入了差异性要素和时间文本后,通过加大案件关键词权重的方式,从而提升了聚类的性能.
3.5.2 验证差异性要素和案件时间的有效性实验
为了验证模型提出的差异性要素(k)和案件时间(t)的有效性,本文分别在基准模型上做了进一步实验,分别使用K-Means(k,t):在K-Means算法的基础上融入差异性要素(k)和案件时间(t)、K-Means(Doc;k,t):在K-Means(Doc)算法的基础上融入差异性要素(k)和案件时间(t)、SIF-Train(k,t):在SIF-Train的基础上融入差异性要素(k)和案件时间(t)和本文模型进行比较,实验结果如表5所示.
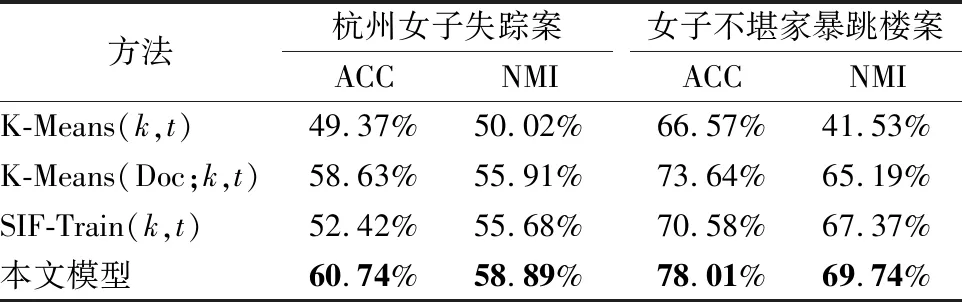
表5 验证差异性要素和案件时间的有效性的实验结果Table 5 Experimental results to verify the validity of the different elements and the time of the case
从实验结果可以看出:1)在编码器部分融合差异性要素(k)和案件时间(t)之后,模型的性能都有一定的提升,因为在融入特征之后,增强了文本表征能力;2)在模型K-Means(k,t)上实验性能的提升较为明显,说明本文模型中提出的增强文本表征的方法在传统的聚类方法中同样适用;3)验证了本文提出的差异性要素(k)和时间文本(t)在聚类性能提升上的有效性.
3.5.3 低维特征向量
图3分别验证不同涉案舆情时间线数据集中低维表征vdi的特征向量d的大小,在本文模型上对实验结果的影响.在实验过程中,选取d=10,20,50,100,200,保持其他参数不变,其中,横轴表示低维特征向量d的大小,纵轴表示在不同低维特征向量下在本文模型中得到的ACC和NMI值的大小,实验结果如图3所示.

图3 特征向量 d 在不同数据集上的实验结果Fig.3 Experimental results of feature vector d on different data sets
由图3的实验结果可知:1)随之特征向量维度d的增加,本文模型在涉案舆情时间线数据集上的ACC值和NMI值总体呈现逐渐下降的趋势,说明随着特征向量d的维度的增加会降低本文模型的实验效果;2)在“杭州女子失踪案”中,ACC值和NMI值在低维特征向量d=20时出现一个最低值,因为特征向量的维度越高,张量的样本空间越大,聚类过程中难以捕获每一类样本的特征表示,容易导致欠拟合.基于以上实验,为了得到最佳实验结果,本文模型中选取的低维特征向量d的大小为10.
3.5.4 消融实验
在表6中,进行本文的消融实验,分别使用K-Means(BERT)模型,融合案件时间(t)的K-Means(BERT;t)模型,融合差异性要素(k)的K-Means(BERT;k)模型与本文模型进行比较,实验结果如表6所示.
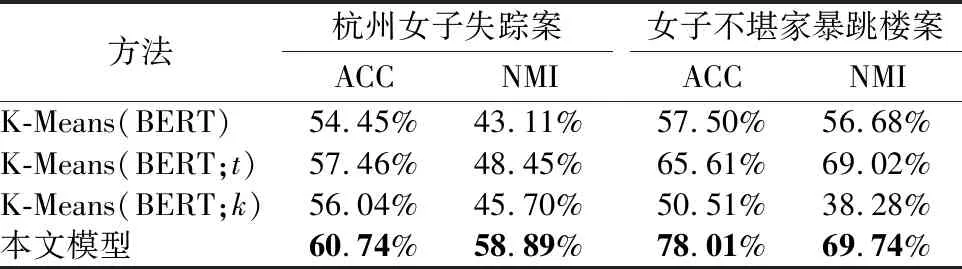
表6 消融实验Table 6 Ablation experiment
根据表6的实验结果可知:1)在两个不同的数据集中,模型K-Means(BERT;t)在ACC和NMI上的实验结果的提升均高于模型K-Means(BERT;k),因为案件时间转化为时间标签后,对文本聚类提供了确定的聚类类别信息,可以看出融合案件时间(t)的有效性;2)“女子不堪家暴跳楼案”中,模型K-Means(BERT;k)在ACC和NMI上的实验结果低于模型K-Means(BERT),因为该数据集规模过小,每条微博文本抽取的差异性要素无法清楚的描述文本信息.而随着数据规模的提升,如在“杭州女子失踪案”中,差异性要素对文本的分类能力逐渐加强.基于以上分析,可以看出融合差异性要素(k)的有效性;3)本文模型融合差异性要素和案件时间,在编码器部分强化文本表征,在ACC上均有超过5%以上的提升,在NMI上均有10%的提升.
4 实例分析
以舆情案件“杭州女子失踪案”为例,选取2020年7月18日~2020年7月27日的数据,部分结果如表7所示,可以看出,在2020年7月18日,差异性要素是“睡觉”、“离开”、“线索”,描述的是女子失踪事实;在2020年7月20日,微博文本(1)、(2)的差异性要素是“遇害”、“专案组”、“调查”,描述的是专案组介入失踪调查;在2020年7月25日,微博文本(1)、(2)的差异性要素是“水落石出”、“离奇”,描述的是案件水落石出事实,通过差异性要素和案件时间,可以将语义相似、案件时间一致的文本聚集为一类文本,如在2020年7月25日,仅包含于案件水落石出事实相关的微博文本,而丢弃无关的微博文本.通过将差异性要素和案件时间融入文本表征中,提升案件文本聚类的性能.

表7 “杭州女子失踪案”数据集的聚类结果(部分)Table 7 Clustering results of “ hangzhou woman missing case ”(partial)
5 结 论
针对案件舆情时间线聚类,本文提出一种差异性案件要素增强的案件舆情时间线生成方法,该方法通过提取差异性要素和案件时间增强文本表征能力,并将自编码过程中得到的低维特征向量作为软聚类过程中的初始聚类中心,通过文本损失不断优化聚类目标.在下一步研究中,我们将进一步研究在相同的时间下,不同语义的微博文本生成时间线的问题.
