目标语义与位置融合的方面意见词抽取
2022-08-29刘德喜万常选刘喜平廖国琼
廖 黾,刘德喜,万常选,刘喜平,廖国琼
(江西财经大学 信息管理学院,南昌 330013)
(江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013)
E-mail:dexi.liu@163.com
1 引 言
文本情感分析旨在利用计算机自动地从非结构化的评论文本中抽取有用的观点信息,挖掘出的信息可以运用于电商平台、网络舆情、企业制造、公共服务中,帮助企业、机构、政府了解大众的看法,完善产品、系统和服务,同时也为大众提供参考.
不同于文档/句子级情感分析,细粒度情感分析(Fine grained Sentiment Analysis)可以分析评论文本中商品/服务的具体对象(target)或方面(aspect)、具体意见词以及具体的情感[1],因此细粒度情感分析也被称为方面情感分析(Aspect-Based Sentiment Analysis,ABSA),它可以细分为多个子任务,包括方面类别检测、方面目标抽取(或目标抽取)、方面意见词抽取(或意见词抽取)、方面级别情感分类等.方面目标抽取和方面意见词抽取是两个基本子任务,其中,方面目标是句子中用户态度或情感所针对的对象,意见词是用户态度或情感的具体表达.
典型的ABSA能够帮助分析评论文本中某个方面的情感极性(正面、负面、中性),而无法提供针对该方面的具体意见词,但这些意见词却可以很好地展示用户对该方面的具体情感表达甚至情感产生的原因.因此Fan等人[2]为ABSA提出了一个新的子任务,称为面向方面目标的意见词抽取(Target-oriented Opinion Words Extraction,TOWE).
给定评论文本和评论的目标,TOWE任务是从评论中抽取描述或评估方面目标的相应意见词.在同一句子中,对于不同的目标,模型需要输出不同的抽取结果.因此TOWE可以给出针对每个方面的具体的观点信息,从而帮助我们理解用户情感及其的来源,细化情感分析任务的粒度.
针对TOWE任务的相关研究成果较少.Fan等人[2]提出了融合方面目标信息的神经序列化标注模型(Target-oriented Opinion Words Extraction with Target-fused Neural Sequence Labeling,IOG),Wu等人[3]提出了潜在观点迁移网络模型(Latent Opinion Transfer Network,LOTN),通过迁移评论情感分类数据中的潜在观点来提升TOWE任务的性能.
本文基于IOG模型进行改进,其中IOG模型遵循编码器—解码器体系结构.在编码器中,模型设计了3个LSTM,分别为向内LSTM(Inward-LSTM)、向外(Outward-LSTM)以及全局LSTM(Global-LSTM).Inward-LSTM使用两个方向(句子的起始至方面目标和句子的结尾至方面目标)的LSTM分别建模,把方面目标词作为LSTM的最后一个输入单元,能够更好的利用方面目标的语义信息.Outward-LSTM确保针对不同的方面目标,句子中每个单词的方面目标融合表示形式有所不同,以方面目标为原点运行两个LSTM,并朝句子的两端延伸,最后生成融合了方面目标的上下文语义特征.由于Inward-LSTM和Outward-LSTM中的上文和下文是分开编码的,但在检测上下文中的意见词时,理解整个句子的全局含义很重要,因此Global-LSTM使用Bi-LSTM建模整个句子以获取完整的句子表示.在解码器中,采用贪婪解码对每个位置进行3类分类,即标注B、I、O3种标签.
IOG模型使用Inward、Outward、以及Global-LSTM模型融合方面目标信息,但存在以下不足:1)Inward-LSTM和Outward-LSTM向量通过相加的方式得到融合方面目标的上下文信息,无法充分地、独立地利用上下文传递给方面目标的语义信息以及方面目标传递给上下文的语义信息;2)在Global-LSTM中忽略了局部信息.使用Bi-LSTM进行完整的语义编码,却无法关注到整体句子中更重要的信息;3)忽略了方面意见词与方面目标之间的位置信息.意见词一般在离方面目标比较近的位置,相对位置较近的候选意见词更有可能成为该方面目标对应的意见词.
针对IOG模型的不足,本文以Global-LSTM中的位置和注意力信息作为切入点,将上下文信息、相对位置信息以及注意力机制结合,提出了IOG的改进模型AP-IOG——目标语义与位置融合的IOG模型(Target-oriented Opinion Word Extraction Based on the Fusion of Aspect Target Semantics and Position model).本文主要贡献在于:
1)提出目标语义与位置融合的方面意见词抽取模型AP-IOG.AP-IOG模型使用3个LSTM融合方面目标及其上下文和位置信息,首先使用向内LSTM和向外LSTM信息拼接,而后使用一个位置注意力增强的全局LSTM.这样,通过3个LSTM很好地融合了方面目标、上下文以及位置信息.
2)采用位置注意力增强机制.AP-IOG建模方面目标与意见词的位置关系,以更多地关注方面目标附近的候选意见词,提升模型识别方面意见词的能力.
3)充分独立地利用上下文信息和方面目标信息.AP-IOG对向内LSTM和向外LSTM输出的向量进行拼接,可以将上下文信息和方面目标信息充分独立地传入解码器.
4)对AP-IOG模型进行了全面的评测,得到较好的评测结果.在4个英文开源的数据集上,AP-IOG模型获得的F1值分别为82.25%、73.45%、76.00%以及85.24%,平均高出基准模型IOG 2.9%.
本文的结构安排如下:引言部分,首先介绍TOWE任务的意义及目前方法存在的问题;第2节总结ABAS和TOWE任务的研究现状.第3节介绍目标语义与位置融合的方面意见词抽取模型AP-IOG,以及各层的搭建与作用;第4节详细说明了本文的实验设定,并介绍了实验结果;最后,对全文进行总结并提出下一步的工作.
2 相关工作
TOWE是方面级情感分析的基础,研究成果主要体现在两个方面:方面意见词抽取、方面目标与方面意见词的联合抽取.
2.1 方面意见词抽取
早期抽取方面意见词的方法主要依赖于特征工程,或者是直接使用意见词词典进行抽取.为了弥补常用情感词典的词条较为通用,缺乏领域性的缺点,Yu等人[4]自行构建了电商领域情感词典抽取方面意见词.然而,构建领域词典需要专家知识和较多的人力物力.
基于规则的方法通过一些词性规则与句法规则来实现对方面意见词的抽取.例如,Liu[5]使用两组不同的句法规则(一组高精确率、一组高召回率)分别对语料进行处理,而后通过双向传播算法进行方面意见词的抽取.Janna[6]将需要标注的方面意见词采用外部词典的方式输入至句法分析器当中,通过词性标注的方式对方面意见词进行标注.
基于深度学习的方面意见分析工作比较丰富,经典方法是采用长短期记忆网络(Long Short-Term Memory,LSTM)[7]和注意力机制相结合.针对预训练过程中无法调整输入的词向量,Zhang等人[8]提出了一种有序神经元长短时记忆和自注意力机制模型(ON-LSTM-SA),使用ELMo对语料进行了预训练.为了充分利用方面目标信息,Xing等人[9]提出了方面感知LSTM(AA-LSTM),在使用注意力机制之前的上下文建模阶段将方面信息合并到LSTM单元中,以获取更有效的上下文表示.考虑到方面目标和其他词对于方面意见词的重要性不同,Qi等人[10]提出了基于权重增强的图卷积神经网络模型(AW-IGCN),通过权重增强的句法依存树来获取更完整的句法结构.
Fan等人[2]提出TOWE任务,目的在于根据给定方面目标(target)抽取其对应的意见词(opinion words),同时提出IOG模型,可以有效地将方面目标信息分别编码到候选意见词的左上下文和右上下文中.然后,结合方面目标的左右上下文和全局上下文,以在解码器中抽取相应的意见词.Wu等人[3]针对TOWE任务,提出LOTN模型,通过迁移学习的知识,把预训练的情感分类中得到的意见词传递给TOWE模型,增强了模型的性能,同时降低了复杂度.
2.2 方面目标与方面意见词联合抽取
针对方面目标和方面意见词联合抽取任务,在以往的研究[11]中,根据现有的词典抽取出方面目标和方面意见词,并设置滑动窗口找出方面目标和方面意见词对,但是在实验过程中发现现有的词典规模小,并且受限于特定的领域,因此难以推广.
部分研究者尝试根据主题构建词典,或尝试其他机器学习方法来实现对方面目标和方面意见词的联合抽取.由于词典在不同领域的学习效果不一,并且网络上总有一些源源不断地新词冒出,导致词典无法识别的,因此Wei等人[12]首先构建出一个初始的词典,而后根据电商数据设计了联合抽取的规则,利用己抽取的方面目标和方面意见词,实现基础词典库的自动扩充.但是,这种方法在很大程度上取决于外部资源,例如解析器或词典,以及解析结果的质量.
随着深度学习在自然语言处理领域中的广泛应用,深度学习技术被应用于方面目标与方面意见词的联合抽取.例如,Shen等人[13]首次将LSTM运用于方面目标与方面意见词的联合抽取任务中.在此基础上,Peng等人[14]使用图卷积神经网络(Graph Convolutional Network)和Bi-LSTM完成该序列标注任务.为了获取更深层次的语义信息,Chen等人[15]使用CNN和BiGRU模型抽取方面目标与方面意见词.在最近的研究中,Chen等人[16]提出同步多通道循环网络模型(Synchronous Double-channel Recurrent Network for Aspect-Opinion Pair Extraction),首先分别抽取方面目标与方面意见词,而后判断两个词是否具有对应关系.
为了更好的捕捉方面目标和方面意见词之间的关系,Yu等人[17]首次将多任务学习框架运用于方面目标与方面意见词的联合抽取任务中.在此基础上,Zhao等人[18]提出了一个基于跨度的多任务学习框架(A Span-based Multi-Task Learning Framework for Pair-wise Aspect and Opinion Terms Extraction),通过充分利用跨度级别信息,抽取方面目标、方面意见词以及其搭配关系.
3 目标语义与位置融合模型AP-IOG
本文将TOWE任务定义为序列标注任务,即:给定一个表达评论的句子,其中包含方面目标Target以及对应的方面意见词Opinion,标注出句子中各个词是否是给定方面目标的意见词,如表1中的示例.

表1 数据标注示例Table1 Annotation examples
本文使用BIO标注方案,对于句子中的每个单词,标记其是否为方面意见词的开始(B)、中间或结尾(I),或者不是方面意见词(O).为了简化问题,要求每个样本中,仅存在一个方面目标.如果某句子中有多个方面目标,则重复构建多个样本,使得每个样本仅针对一个方面目标抽取方面意见词,如表1中的示例2和示例3.
目标语义与位置融合的方面意见词抽取模型AP-IOG如图1所示,使用编码器-解码器体系结构.
3.1 方面目标融合编码器
AP-IOG模型使用方面目标融合编码器将方面目标信息合并到上下文中并学习融合方面目标的上下文表示,然后将它们传递给解码器进行序列标注.它主要由5个部分组成.首先使用增加头尾标识符的文本作为输入层,而后使用3个LSTM,分别为Inward-LSTM、Outward-LSTM以及位置注意力增强的Global-LSTM,生成融合方面目标信息的上下文信息,最后在融合层融合.
3.1.1 输入层
在观察数据集时发现,部分句子的方面目标或方面意见词处于句子初始位置或者结束位置,在模型训练过程中方面目标或候选方面意见词缺失左侧信息或右侧信息,导致上下文语义信息不完整,降低模型准确率.因此,AP-IOG模型在句子的开头和结尾分别补上头标识符[SEP]和尾标识符[CLS],如表1所示.
使用嵌入查找表L∈Rd×|V|生成每个单词的输入向量,其中d是嵌入向量的维度,|V|是{w1,w2,…,wn}词汇量.嵌入查找表将{w1,w2,…,wn}映射到向量序列s={x1,x2,…,xn},其中xi∈Rd.
如前所述,TOWE的核心挑战是学习方面目标融合的上下文表示.显然,不同的方面目标在句子中的位置不同,语境也不同.因此,我们首先将句子分为3个部分:上文{w1,w2,…,wl},方面目标词{wl+1,…,wr-1}和下文{wr,…,wn}.
3.1.2 向内LSTM(Inward-LSTM)


图1 目标语义与位置融合的方面意见词抽取模型网络框架Fig.1 Target-oriented opinion word extraction based on the fusion of aspect target semantics and position
(1)
(2)
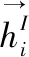
显而易见,方面目标词{wl+1,…,wr-1}的编码在前向LSTM和后向LSTM中分别计算了两次.因此本文对方面目标单词的两个表示形式求平均得到方面目标单词的最终表示形式hI,方面目标隐藏状态平均算法如图2和公式(3)所示:

图2 方面目标隐藏状态平均算法图Fig.2 Average algorithm diagram
(3)
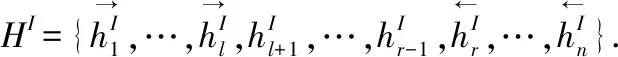
3.1.3 向外LSTM(Outward-LSTM)
Inward-LSTM将包含候选意见词的上下文信息传递给方面目标,但方面目标信息不会传递到上下文中.例如,在"The decoration is festive and beautiful."这句话中,方面目标是"decoration",Inward-LSTM从句子的首尾单词"The"和"beautiful"向方面目标"decoration"进行建模.但"The"和"beautiful"的编码却没有依赖"decoration"的信息.为了解决这个问题,使用向外LSTM(Outward-LSTM).Outward-LSTM的想法是将方面目标传递给上下文,如图1所示.Outward-LSTM以方面目标词{wl+1,…,wr-1}为原点运行两个LSTM,并朝句子的两端延伸,分别为前向LSTM和后向LSTM.

(4)
(5)
(6)

此外,Outward-LSTM确保针对不同的目标,每个单词具有不同的表示形式.例如"The atmosphere is aspiring,and the decoration is festive ",对于方面目标"atmosphere"或"decoration","festive"的方面目标融合表示形式有所不同,生成方面目标融合的上下文.
3.1.4 位置注意力增强的全局LSTM(AP Global-LSTM)
1)Global-LSTM
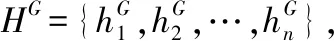
(7)
(8)
(9)

2)Self-Attention
在Global-LSTM建模过程中,为了更好地注意到整体句子中更重要的局部信息,本文使用Self-Attention机制[20].
Self-Attention是输入句子Source内部元素之间的Attention机制,Query(Q)、Key(K)、Value(V)是由全局上下文表示HG经过不同的线性变换得到.通过Self-Attention得到权重求和的表示HAG,如公式(10)所示:
(10)
3)位置注意力增强机制
使用Self-Attention可以获得整个句子的局部信息,在TOWE任务中,上下文中的单词和方面目标词之间的相对位置包含着很重要的特征信息,方面目标附近的词更有可能表达对方面目标的情感,即为方面意见词,并且随着相对距离的增大影响越小.因此本文设计了一个位置注意力增强机制,不仅仅能够注意到整个句子的局部信息,同时更多的关注方面目标词周围的词,使其具有更多的信息传入到方面目标词中.
如图3所示,对于该上下文中涉及的第1个方面目标"atmosphere"的情感由相对位置2的"aspiring"表达,而不是相对位置8的"festive"表达,因此"atmosphere"方面目标相对应的方面意见词为"aspiring".第2个方面目标"decoration"对应的方面意见词为相对位置2的"festive".

图3 上下文中单词和方面目标之间的位置关系Fig.3 Positional relationship between opinion and targets
本文对位置信息的处理方法为:
①给定一个句子s={w1,w2,…,wn},其中包含方面目标词{wl+1,…,wr-1}.检索到方面目标所在的位置[l+1,r-1],设置该方面目标的相对位置li为0,如公式(11)所示:
(11)
②以方面目标为中心,在方面目标的两侧设置两个工作指针,分别依次计算方面目标左侧单词和方面目标左侧wl+1之间的相对位置,右侧单词和方面目标右侧wr-1之间的相对位置的值,记相对位置为li,其计算公式如公式(12)所示:
(12)
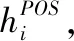
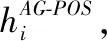
(13)
在位置注意力增强全局LSTM中,为了更好地注意到句子中的方面目标信息以及附近候选意见词的信息,从而完善句子的语义信息,本文通过将位置注意力增强的句子表示和全局LSTM的句子表示相加,获得位置注意力增强的全局上下文表示形式HAPG,如公式(14)所示:
(14)
3.1.5 融合层:AP-IOG
本文将Inward-LSTM、Outward-LSTM和AP Global-LSTM上下文拼接起来,向量拼接可以使各个不同类型的特征向量充分发挥其作用,使得输入层具有更丰富的信息,如图1所示.每个单词的最终目标语义与位置融合的上下文表示r如公式(15)所示,其中⊕为拼接操作:
(15)
最终表示r是方面目标信息和位置注意力增强机制的全局上下文信息的融合,随后传递给解码器进行序列标注.
3.2 解码器和训练
本文使用贪婪解码作为解码器,贪婪解码被独立地描述为每个位置的3类分类问题.本文使用softmax来计算概率,计算公式如公式(16)所示:
p(yi|ri)=softmax(Wsri+bs),1≤i≤n
(16)
贪婪解码只是简单地选择具有最高逐点概率的标签.它不考虑标签之间的依赖关系,但运行速度更快.使用负对数似然(L(S))作为损失函数,计算如公式(17)所示:
(17)
与已有的面向方面目标的方面意见词抽取模型相比较,本文提出的目标语义与位置融合模型AP-IOG具有以下特点:
1)强化方面目标信息在TOWE任务中的作用.不同于普通的序列化标注任务,TOWE的难点在于对同一个句子,如果输入的方面目标不同,那么对应标注的意见词也应该不同.因此AP-IOG使用3个LSTM充分使用方面目标信息以识别方面意见词,其中Inward-LSTM可以很好地利用方面目标的语义信息,Outward-LSTM将方面目标信息传递至上下文,以生成方面目标融合的上下文,同时位置注意力增强的AP Global-LSTM,可以利用方面目标和方面意见词的位置信息,以获取更有效的上下文表示.通过这3个LSTM向量拼接,从而充分融合方面目标及其上下文信息.
2)充分地、独立地利用方面目标语义与上下文信息.将Inward-LSTM、Outward-LSTM的结果进行拼接.AP-IOG将内外LSTM输出的信息向量进行拼接,使得解码器可以关注到融合方面目标信息的上下文表示中的更多信息.
3)具有更强的可解释性.在Global-LSTM中,AP-IOG使用位置注意力增强机制,融合方面目标语义信息、上下文语义以及位置信息,不仅能够在内外LSTM层有效利用方面目标信息,还可以在全局LSTM层有效利用局部信息.同时,在文本长度较长时,可以更多地关注方面目标附近的候选意见词,从而达到更好的效果.
4 实验与结果分析
4.1 数据描述与评测指标
本文使用SemEval 2014任务4、SemEval 2015任务12和SemEval 2016任务5(Pontiki等人[21-23])构建的数据集.这些数据集是许多ABSA子任务的基准,包括方面目标抽取、方面意见词抽取、方面意见词和方面目标相关情感分析.SemEval任务提供了餐厅和电脑领域的多个数据集.在SemEval任务的原始数据集中,标注了方面目标(方面),但未提供方面意见词和与方面目标的对应关系.因此,Fan等人[2]为方面目标标注了相应的方面意见词,并且仅保留包含方面目标词和方面意见词对的句子.
每个句子都由两个人标注,并且检查冲突.数据集的每个实例由一个句子序号、一个句子、方面目标的位置和相应方面意见词的位置组成.文本使用4个数据集:2014年SemEval的14res和14lap,2015年SemEval的15res和2016 SemEval的16res.14res,15res和16res包含来自餐厅领域的评论.14lap中的句子来自电脑领域.表2中显示了这4个数据集的统计信息.

表2 数据统计Table 2 Statistics of the dataset
本文使用精确率P、召回率R和F1值用作衡量模型性能的指标.
4.2 实验环境与超参数设置
本文所提出的模型采用Windows上的PyTorch进行搭建,实验采用的环境如表3所示.

表3 实验配置Table 3 Experimental environment
实验中,使用300维GloVe向量作为初始化单词嵌入向量,该向量在未标记的8400亿个词上进行了预训练.单词嵌入在训练阶段是固定的,不进行微调.在所有LSTM单元中,隐藏状态的维数均设置为300.选择Adam[24]作为优化方法,并使用原始论文中的默认设置.在训练集中随机分配20%的数据作为验证集,以调整超参数.模型超参数设置如表4所示.

表4 模型超参数设置Table 4 Hyperparameters
4.3 对比模型
1)Distance-rule:Hu和Liu[12]使用距离和位置(POS)标签来确定方面意见词.首先使用nltk工具箱对每个词进行词性标注,并选择距离方面目标词最近的形容词作为相应的方面意见词.
2)Dependecy-rule:采用Zhuang等人[25]提出的策略,使用基于依赖树的模板来识别意见对.在训练集中记录方面目标和方面意见词的词性标记以及它们之间的依赖路径作为规则模板.使用高频规则模板检测测试集中的方面意见词.
3)LSTM/Bi-LSTM:该方法是基于Liu等人[7]提出的单词嵌入的LSTM/Bi-LSTM网络.将整个句子传递到LSTM/Bi-LSTM中,随后每个隐藏状态都被输入softmax层进行3类分类,完成方面意见词的抽取.
4)Pipeline:该方法将Bi-LSTM方法和距离规则方法相结合.首先利用Bi-LSTM训练句子级方面意见词抽取模型,抽取出测试句子中的方面意见词,然后选择最接近方面目标的方面意见词作为结果.
5)方面目标嵌入Bi-LSTM(TCBi-LSTM):该方法将方面目标信息合并到句子中.通过方面目标嵌入的平均池化得到方面目标向量,单词在每个位置的表示为词向量和方面目标向量的相加,然后将其送入一个Bi-LSTM进行序列标注任务.
6)融合方面目标信息的神经序列化标注模型IOG[2]:该方法使用方面目标融合序列标注神经网络模型来执行此任务.方面目标信息被由内向外的LSTM很好地编码到上下文中.然后,将方面目标的上、下文与全局上下文进行组合,以找到方面目标对应的方面意见词.
4.4 实验结果分析
各模型在测试集上的实验结果如表5所示.
由表5可以看出,总体上本文提出的AP-IOG模型在各个评测指标上都显著优于其它模型,F1值在4个数据集上比IOG模型分别高出了2.23%、2.10%、2.75%以及3.55%.具体地:

表5 各模型实验结果对比Table 5 Experimental results
1)Distance-rule的性能不理想,是所有方法中性能最差的,尤其是召回率很低.说明仅选择距离方面目标词最近的形容词作为方面意见词并不能取得好的效果.
2)Dependecy-rule比Distance-rule得到了更好的效果,但仍低于基于序列标注的方法.依存句法规则的错误传播可能是导致模型性能差的一个原因.
3)Pipeline模型的性能显著优于Dependecy-rule,特别是在精度上,这说明机器学习方法可以更好地进行方面意见词抽取.然而,Pipeline模型仍然太不理想,F1值比AP-IOG模型大约低10个百分点.这说明仅仅使用距离信息,对于检测面向方面目标的方面意见词是不够的,而AP-IOG可以更好地处理长距离依赖问题.此外,Pipeline策略不能解决一个方面目标对应多个方面意见词的情况,它还容易受到错误传播的影响.
4)LSTM和Bi-LSTM都是目标无关的,精度较低,性能甚至不如Pipeline方法.AP-IOG的表现平均比Bi-LSTM高出15个百分点左右,说明方面目标信息融合可以提升模型的效果.
5)TCBi-LSTM通过向量相加的方式包含方面目标信息,总体性能优于LSTM和Bi-LSTM.但TCBi-LSTM仍比AP-IOG低10个百分点以上,略低于Pipeline.
6)IOG使用内外LSTM模型向量相加的方式包含方面目标信息,而后使用全局LSTM了解句子的全局含义,显著改善了针对方面目标的方面意见词抽取性能,但IOG仍比AP-IOG低3个百分点左右.这说明,拼接向量可以充分利用上下文传递给方面目标的信息以及方面目标传递给上下文的信息,训练效果更佳;位置注意力增强机制可以在全局层帮助模型更好地注意到局部信息,也使得较长数据可以更加关注到方面目标词周边的词;增加头尾标识符的处理可以使得方面目标信息的上下文不会存在无特征向量的状况,从而得到更好的模型效果.
与基于规则的方法和其他的神经网络模型相比,AP-IOG在不同领域的数据集上都取得了最好的性能.可以看出,AP-IOG能够更有效地学习针对方面目标的特征,能够更好地捕捉方面目标与方面意见词之间的对应关系.
4.5 案例分析
为了证明AP-IOG模型的有效性,本文在测试数据集中选择一些示例,然后显示不同模型的抽取结果,如表6所示,其中“×”表示模型抽取错误,“√”表示模型抽取正确.

表6 抽取结果的示例Table 6 Case study
示例4中,由于Distance-rule无法抽取短语,因此模型抽取结果不正确.此外,使用Distance-rule方法时,仅选择最近的形容词作为方面意见词并非在所有情况下都能取得好的效果,如示例5和示例6("excellent"和"authentic","fresh").
在某些情况下,Dependecy-rule没有匹配的模板,因此无法抽取任何单词,如示例5.
Pipeline方法具有无法处理一对多的问题,一个方面目标对应多个方面意见词的情况(如示例6,只识别出"authentic"而未识别"fresh").示例7中,IOG受到整体长度以及其他词信息的影响,导致抽取到和方面目标信息距离较长的无关信息.AP-IOG模型使用位置注意力增强的方法,更多关注于方面目标附近的词,从而正确抽取方面目标"Chelsea"对应的方面意见词"impressive"、"creative".示例5中,由于Bi-LSTM不包含目标信息,尽管它抽取了"slow"和 "busy",但只有"slow"是对应"Service"的方面意见词.虽然TCBi-LSTM是融合了方面目标信息的模型,但它因为级联产生的干扰,所以经常会抽取无关的方面意见词.
当方面目标在句子的开头时,IOG在方面目标的左侧没有信息输入,如示例8,影响了模型的性能.AP-IOG模型在数据输入层增加了头尾标识符,使得方面目标的两侧都有有效信息,成功识别"Service"的方面意见词"slow".
当句子中的方面意见词较复杂且具有否定词时,如示例9,包括AP-IOG的所有模型都没能完全准确地识别出意见词.主要原因在于,获取句子的语义信息时,无法获取一些复杂的语法信息(Not…but…),因此只能识别出"biggest"和"adequate",而识别不出否定词(Not)是属于方面意见词还是无关信息.另外,训练数据集中类似的样本较少,也是模型分析不够准确的原因之一.
4.6 消融实验
为了分析本文提出的AP-IOG模型相对于IOG的在多个方面的改进效果,本文还在表7中展示了AP-IOG模型中各个模块的有效性.

表7 消融实验结果Table 7 Ablation experiments results
1)IOG[2]:该模型使用方面目标融合序列标注神经网络模型来执行此任务,其中包括3个LSTM,分别为Inward-LSTM、Outward-LSTM以及Global-LSTM,其中HIO=HI+HO;由Inward-LSTM、Outward-LSTM获得方面目标信息融合的上下文信息.然后,将方面目标的上、下文与全局上下文进行拼接,以找到相应的方面意见词.
2)IOG+HT(增加头标识符Head和尾标识符Tail):在IOG的基础上,在句子的头部和尾部增加了一个头尾标识符号,以保证方面目标处于文本的初始或者结尾位置时,左右两边也都具有有效信息.
3)IOG*+HT:在IOG+HT中,改变HI和HO的组合方式,使其进行向量拼接,充分独立地利用上下文传递给方面目标的信息以及方面目标传递给上下文的信息,从而获得更多的信息.
4)IOG*+HT+AT:在IOG*+HT的基础上,Global层LSTM编码HG增加了Self-Attention机制,使得在Global-LSTM层也可以注意到更多的局部信息;
5)AP-IOG:在IOG*+HT+AT的基础上,使用了位置注意力增强机制,不仅仅能够注意到整个句子的局部信息,同时也更好的注意到方面目标词附近的词,使其具有更多的信息传入到方面目标词中.
表7显示,增加头尾标识符的处理,可以提升模型的效果,相比于IOG模型,IOG+HT模型的F1值在4个数据集上平均提升了0.8%;Inward-LSTM和Outward-LSTM拼接可以更好的利用方面目标信息,相比于IOG+HT模型,IOG*+HT模型F1值4个数据集上平均提升了0.6%;在模型中加入Self-Attention机制可以在Global层注意到句子中更重要的部分,相比于IOG*+HT模型,IOG*+HT+AT模型F1值在4个数据集上平均提升了0.9%;在Attention机制的基础上,增加方面意见词和方面目标相对位置,更好地注意到方面目标词附近的词,相比于IOG*+HT+AT模型,AP-IOG模型F1在4个数据集上平均提升了0.6%.
4.7 可视化
为了验证本文提出的AP-IOG模型中目标语义与位置融合机制能够有效提取方面目标对应的方面意见词信息,本文针对几个数据文本,从词的角度进行了可视化,如图4所示.

图4 AP-IOG在句子上的热力图示例Fig.4 Thermal diagrams of AP-IOG on sentence level
其中,阴影部分表示句子中单词的权重,颜色越深表示AP-IOG中相应注意力的权重越大.AP-IOG模型通过目标语义与位置融合机制注意到方面目标及其对应的方面意见词,例如图4(a)中方面目标"spot"对应的方面意见词"great".图4(b)和图4(c)中的例子比较有趣,两个方面目标和方面意见词均来自同一个句子,从注意力权重大小来看,在识别图4(b)中"atmosphere"对应的方面意见词"aspiring"时,不仅给方面目标"atmosphere"较大的权重,模型同时也注意到了句子中还存在的另外一对方面目标和意见词,只是权重相对较小.这是容易理解的,同时对模型也是有利的.
5 总结展望
本文在现有TOWE方法的基础上提出了一个新的位置注意力增强的方面意见词抽取模型AP-IOG.为了建模方面目标和对应上下文之间的语义关系,使用3个LSTM融合方面目标及其上下文和位置信息,其中Inward-LSTM、Outward-LSTM充分地、独立地利用上下文信息和方面目标信息,而位置注意力增强的Global-LSTM可以获取上下文单词与方面目标的位置信息.而后将3个LSTM输出进行拼接,以更好地识别面向方面目标的方面意见词.实验结果表明,该方法已达到最佳性能.
在研究过程中发现,TOWE任务的标注数据集比较匮乏,在数据标注过程中耗费了太多人力和时间.通过错样本的分析,发现模型在获取句子的语义信息时,无法获取一些复杂的语法信息.在以后的工作中,可以从以下几个方面对模型进行改进:1)考虑将TOWE任务运用到不同领域和语种的数据集中;2)考虑引入语法特征,语法结构包含词与词之间的依赖关系,也是TOWE任务的重要线索.此外,使用端到端的神经序列标注方法联合抽取方面目标和意见词,不用给定方面目标,以扩大TOWE的应用场景,也是今后的研究内容之一.
