面向NVMeoF存储网络的负载感知传输机制研究
2022-08-26齐勇军汤海林
齐勇军,汤海林
(广东白云学院大数据与计算机学院,510450,广州)
1 问题提出
NVMe(NVM Express)主机控制器接口协议专为SSD和PCIe物理接口而设计,大大提高了主机到SSD访问的并行性,突破了传统SCSI协议和SATA/SAS硬盘接口的性能瓶颈[1]。NVMeoF(NVMe over Fabrics)协议进一步将NVMe的优势扩展到了存储网络结构,如高并发、低延迟、低协议开销等。为了实现NVMe SSD通过以太网构建高性能存储网络,广泛应用于数据中心,Lightbits、Facebook、Intel、Cisco、Dell EMC、Micron[2-5]等公司联合开发了NVMe over TCP标准,被 NVM Express[6]组织批准为新的 NVMeoF 传输层标准。然而,基于TCP的NVMeoF存储网络的NVMe需要计算节点和存储节点在每次I/O请求完成时响应多个中断请求。在高并发I/O场景下,会向CPU发出海量的中断请求。并且随着超高速以太网在未来数据中心的部署和应用,NVMe over TCP存储网络的性能瓶颈逐渐转移到CPU对各类NVMeoF报文的处理效率上。
本文设计并实现了Load-Aware NVMeoF消息处理机制LANoT(Load-Aware NVMe over TCP)。 使用interupt合并技术缓解中断风暴问题,通过感知不同CPU核心和目标NVMe SSD的专用队列中的I/O负载,匹配相应的NVMeOF存储网络消息处理机制,实现不同特性应用的关键指标表现。
2 问题研究
2.1 中断风暴问题
与只有单个请求队列的传统 SCSI 存储设备不同,NVMe SSD 可以同时并发处理大量 I/O 请求。驱动完成NVMe请求的初始化后,立即通过Doorbell寄存器通知NVMe SSD开始处理NVMe指令。此外,通过单个磁头串行执行读写请求的磁盘相比,NVMe SSD具有通道间、芯片间、晶圆间和组间4个级别的并行性,可以并发执行同时多条数据读写指令,并在指令执行后并发向CPU发起中断请求。
数据密集型应用需要主机CPU和NVMe软件协议栈每秒处理数百万个数据中断请求,这会导致主机CPU计算能力被中断请求产生的上下文切换开销消耗。本文将大量CPU资源用于处理NVMe SSD中断请求而导致应用执行效率急剧下降的问题称为NVMe中断风暴。
2.2 多应用I/O干扰问题
随着人工智能技术、云计算、大数据和物联网技术的发展,以及多通道CPU服务器和多核CPU技术在数据中心的普及,数据中心的数据流量呈指数级增长。数据中心计算节点通常同时运行多个应用程序,每个应用程序具有不同的I/O特性和需求。CPU Core A上运行着数据密集型应用和延迟敏感型应用。对于这2种应用,服务质量保证对不同的性能指标敏感。
在计算节点和I/O节点的NVMeoF存储网络I/O关键路径中,如果只用一套机制来管理不同CPU核对应的NVeoF队列中指令的处理和发送,是无法针对性地在不同应用程序的 I/O 中实现。 I/O特性和需求准确实现应用负载感知指令处理和发送策略,更好地实现不同应用的服务质量保证。例如,针对数据密集型应用优化的NVeoF存储网络指令处理策略无法满足延迟敏感应用的I/O需求,甚至可能对延迟敏感应用的I/O造成延迟放大问题,导致计算结果错误。点应用之间的I/O干扰问题,针对延迟敏感应用的NVeoF存储网络指令处理策略,由于追求极低的延迟,也无法充分发挥网络性能及满足数据密集型应用的高吞吐要求。因此,如何为NVMe over TCP存储网络的主机和目标I/O关键路径中的每个CPU核设置专用的消息处理策略,并根据I/O负载动态调整,是有效避免多核CPU的关键。同时,正在运行的应用程序之间的I/O干扰问题,是为了充分发挥ULL-SSD高并发、低延迟所面临的关键问题。
3 系统设计
3.1 应用I/O特性分析
随着计算能力的不断提升和存储技术的进步,大型数据中心可以支持应用程序进行更复杂地分析和处理更大的数据集。例如,数据密集型分析应用需要读入大量原始数据才能获得深入分析结果,而超大规模模拟应用每次保存一个检查点都会持续写入TB级数据。数据密集型应用程序需要大量 I/O 带宽来访问呈指数增长的数据。由于数据中心计算节点通常同时运行多个应用程序,并且它们可能具有不同的I/O特性,因此不可能使用固定的机制来管理所有CPU核对应的NVeoF队列。因此,需要应用程序 I/O。I/O需要分析确定如何为每个CPU以及 NVMe over TCP 存储网络的主机侧和目标侧之间设置专用的消息处理策略。根据对美国橡树岭国家实验室管理的2个大型存储集群的运行记录的研究,small I/O已成为存储系统必须处理的重要I/O模式,其中60% Spider 2 集群上的写入请求为4 kB 或更少。根据应用程序的 I/O 特性,大致可以分为数据密集型应用和时间敏感型应用。

如果按照这个值设置聚合度,会导致聚合过大,在正常的定时器限制内无法达到聚合度,对于PDU大小较大的情况,聚合度会导致发送到网卡的数据包需要再次拆分,给网卡带来额外的工作量。
NVMe over TCP存储网络的Target端向Host端发送C2HData PDU和Resp PDU(消息结构)。其中,Resp PDU的典型大小为24 B,C2HData PDU根据携带的数据部分的大小而变化。根据聚合度的计算公式,合适的聚合度与CapsuleCmd PDU有较大差异。
1)对于写入密集型应用程序。NVMe over TCP存储网络的Host端向Target端密集发送CapsuleCmd PDU和H2CData PDU。此时的情况对应于读取密集型应用程序。Host发送高频大包,Target端发送高频小包。
2)对于时间敏感的应用程序。时间敏感的应用程序通常没有很高的吞吐率,消息大小也低于KB级别,例如实时控制流信息。虽然这种类型的应用程序不需要高带宽,但它需要足够低的延迟来确保应用程序的正常运行和良好的用户体验。对于这类应用,如果聚合度和定时器超时时间设置过高,则应用的消息延迟会过高,影响用户体验,甚至影响应用的正常运行。因此,应该采用低聚合、低定时器超时的策略,并牺牲一定的带宽/吞吐量和CPU使用率,以换取时间敏感的应用消息的低延迟。
3.2 基于聚合PDU的中断合并
LANoT有效地聚合了Host端的每个队列中PDU,以减少Target端的中断请求数量。LANoT引入了PG(PDU Group)数据结构来记录需要发送的多个PDU的内存起始地址和长度。在PG聚合度达到阈值或等待时间结束后,通过调用kernel_sendmsg()接口一次将包含多个PDU的PG发送给Target。这样,存储节点网卡收到PG后,只需要向CPU发起中断请求,CPU就可以在中断处理的下半部分连续解析处理多个PDU,从而避免CPU响应到多个中断请求和上下文切换开销。基于CPU核的负载检测。
在基于聚合PDU的中断合并策略中,如果要保证消息传输的延迟,必须设置一个较低的计时器超时时间,以确保在时限内及时发送消息。但是,减少定时器时间后,等待时间会发生变化。总之,相应的PG聚合度更难达到阈值,相当于降低PG聚合度。为了保证消息传输的高吞吐量,必须尽量提高PG的聚合度。PG的聚合度越大,中断合并的效率就越高,同时也会获得计算节点和存储节点的有效CPU算力,保护得更好。但是,随着PG聚合度的增加,如果想要PG聚合度达到阈值,就需要为定时器设置更长的超时时间,防止定时器超时超时。
这2个指标所需的消息发送机制似乎相互矛盾,需要进行一定的权衡。然而,根据华中科技大学杨颖等人的研究,通过观察大量以往的实验结果,多个应用的并发运行时负载呈现出规律的分布。在一定时间内,单个CPU核的负载特性表现出一定的一致性。虽然不可能同时达到2个最高的目标NVMe over TCP存储网络中的吞吐率和最低延迟,可以为CPU内核设置专用的消息处理队列,并根据实时I/O负载状态动态调整消息处理策略。最大程度满足应用对高吞吐量、低延迟的性能要求。
为解决应用之间的I/O干扰问题,根据不同应用的I/O特性,通过动态机制调整,首先要通过获取相关维度的I/O传输特性数据来确定当前的负载特性。在NVMeoF消息处理方法中,以每个CPU核的特殊消息处理队列为粒度进行I/O传输特征数据感知。对应中断合并机制中聚合、数据长度、等待时间3个维度的特点,考察每个聚合PG在CPU核心专用队列中的聚合度、聚合数据的长度、是否定时器超时,获取的数据感知当前运行的应用I/O负载特性,对每个CPU使用Qos算法内核的专用消息处理队列匹配当前I/O负载特性对应的专用消息处理策略正在运行的应用程序。
3.3 Load-aware动态NVMeoF消息处理机制
针对NVMe SSD在多核CPU中多个并发运行应用之间I/O干扰情况下面临的高并发、低延迟特性的关键问题,本文采用机制与策略分离。设计思路是针对数据中心的多核CPU负载多样性问题,在NVMe over TCP存储网络中设计Load-aware NVMe over TCP动态消息处理机制LANoT(Load Aware NVMe over TCP),并设置专门的消息处理机制针对每个CPU核根据I/O负载动态调整策略,有效避免了多核CPU中多个并发运行的应用程序之间的I/O干扰问题,充分发挥了CPU的高并发、低延迟特性NVMe固态硬盘。
如图1所示,对应聚合度、数据长度和等待时间3个维度,可实现对应用负载情况的感知,主动调整响应策略。例如,当一个PDU Group对应一个NVMeoF队列时,如果因为数据长度达到阈值而连续N次触发PDU Group的发送,则预测在NVMeoF队列中要发送的NVMe指令主要来自来密集的I/O请求。CPU中运行的程序归类为高吞吐量应用程序,针对CPU利用率进行了优化,提高了PDU Group的数据长度阈值,减少了中断次数。如果因为等待时间达到阈值,连续N次触发PDU Group的发送,预测NVMeoF队列中要发送的NVMe指令主要来自非密集I/O请求,并且这些请求对应的PDU在PDU Group中较长。时间等待会导致I/O延迟显著增加。因此,对CPU中运行的程序进行了延时优化,降低了PDU Group的数据长度阈值,适当减少了等待时间。具体的策略调度由Qos算法控制。
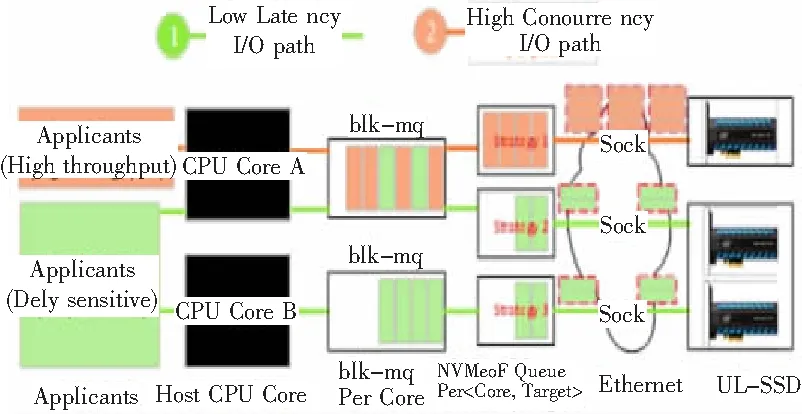
图1 Load-aware动态NVMeoF消息处理机制
不同I/O特性的应用程序具有不同的性能目标。对于数据密集型应用,其追求的性能指标是吞吐率,对延迟时间指标要求不高。为了实现更高的吞吐量,NVMeoF存储网络应在通信网络允许的情况下,采用尽可能增加PDU聚合度的策略,以减少中断次数,提高CPU和数据的处理效率。对于延迟敏感的应用,它追求的性能指标是延迟时间,对吞吐量的要求相对较低。为了实现更低的时延,NVMeoF存储网络应该在不浪费CPU算力的情况下,尽量减少PDU传输等待时间,从而减少网络开销以外的不必要的延迟,提高NVeoF存储网络的延迟性能。
感知具有不同I/O特性的应用程序。当应用为数据密集型应用时,特点是频繁发送PG,定时器基本不超时。为了实现针对数据密集型应用优化的性能目标,此时的策略应该是:逐渐增加聚合度,达到合适的值。当应用对时间敏感且数据不密集时,其特点是频繁的定时器超时和NVeoF网络中发送的PG的低聚合。为了达到针对数据密集型应用优化的性能目标,此时的策略应该是:逐渐降低聚合度到合适的值。为了实现对不同应用程序使用不同的策略,首先要解决如何确定的问题。LANoT为每个CPU核和目标存储节点设计了专用的处理队列,设置了SmallPG-send、PG-send和doorbell-ring 3个统计每个队列中的变量来收集每个队列的工作状态,并实时传递给Qos算法,以达到根据不同的非通过工作状态实时调整NVMeoF存储网络消息处理策略的设计目标。队列充分适应不同特性应用的性能需求。其中small PG-sned统计队列发送的聚合度低的PG个数,PG-send统计队列发送的正常PG个数,doorbell-ring统计定时器超时的次数,当一个变量到达a setthreshold 时,调整聚合度,重置2个变量的值。如果2个变量相差很小,说明当前队列应用特征不明显,直接重置2个变量,不调整策略。
4 系统评估
4.1 系统环境测试
为了评估LANoT的实际性能,在Linux内核中实现了基于NVMe的TCP设计的LANoT原型系统,在每个队列中引入struct kvec类型的数组PDU组,记录聚合PDU的内存开始地址和数据长度,并为PG维护PG聚合度和PG定时器。每次发送PG时,更新SmallPG-send、PG-send和门铃这3个统计变量的值,达到设定的阈值后调用Qos算法进行判断处理。
通过在真实系统上安装并部署了LANoT,并测试了其性能。LANoT测试的硬件平台包括2台宝德(PowerLeader)PR2124G双向服务器,CPU型号为Intel Xeon E5-2660 v3,主频2.60 GHz,内存256 GB。每台服务器包含1块迈络思网卡(Mellanox CX555A),2块服务器网卡的链路类型设置为以太网模式,通过EDR光纤直接连接。另外,在Target服务器上安装了一块2TB 的U.2规格DERA NVMe SSD,并通过PCIx8 NVMe扩展卡连接CPU,保证了NVMe SSD的链路带宽。LANoT软件测试环境是基于CentOS 7.7.1908 (Core)操作系统,内核版本为Linux 4.20.0-rc3,网卡驱动版本为ofd -5.0-2.1.8。用于与NVMe内核驱动交互的NVMe -cli软件版本为1.8.1,用于测试存储设备性能的FIO版本为FIO -3.7。
4.2 系统性能评估
为了综合评价LANoT的性能优势,引入了NVMe-Local、NVMe-TCP和PGIC(基于PG的中断合并)3个比较对象。其中,NVMe-Local用于测试相同负载下Target端NVMe SSD的本地读写。NVMe-TCP用于测试Linux内核中原生NVMe over TCP存储网络的性能,PGIC用于测试LANoT仅采用基于固定聚合PDU的中断合并策略时的性能。此外,还对通过NVMe-TCP、PGIC和LANoT远程访问的RAMDisk和NVMe SSD的性能进行了测试对比,避免了NVMe SSD性能瓶颈对存储网络远程访问性能的限制。在PGIC固定参数设置方面,根据实验数据兼顾延迟和性能的平衡,将PG定时长度设置为50 μs,PG聚合度阈值设置为16。
图2(a)和图2(b)分别是4 K随机写入和4 K随机读取的IOPS性能测试结果。对比本地NVMe SSD的4 K读写IOPS,3个线程发出请求时可以达到最高性能。

图2 基于SSD的读写IOPS对比
与本地NVMe SSD的性能不同,NVMe-TCP,PGIC和LANoT 3个NVMe通过TCP存储网络实现方法需要更多的CPU内核参与到NVMe SSD的IOPS完全传递到计算节点的应用程序。对于NVMe-TCP在Linux内核中,10个CPU内核都需要充分利用NVMe SSD的4 K下的随机写入负载的性能,而在4 K随机读取负载,20threads仍不能充分利用NVMe SSD的最高性能。这也间接验证了 NVMe over TCP 存储网络比本地 NVMe SSD 消耗更多的 CPU 资源。在相同的I/O负载下,使用基于聚合PDU的中断合并的PGIC和LANoT,可以通过5线程的存储网络充分发挥NVMe SSD的4K写入性能。8个线程,充分发挥4K读取性能,CPU资源消耗降低50%以上。
在NVMe over TCP存储网络中,4 K随机写入请求采用In-Capsule数据传输方式,写入NVMe SSD的数据与CapsuleCmd PDU一起从Host发送到Target。4 K读写IOPS测试因为每个PDU比较小,在饱和测试的情况下CPU占用率较高。它是模拟数据密集型应用程序的典型测试。
在基于NVMe SSD的性能评测中,LANoT在4 K随机写入负载下可比PGIC提升约25.30%的IOPS,在4 K随机读取负载下可比PGIC提升约36.06%的IOPS。但是由于PGIC和LANoT的性能在2个线程中接近NVMe SSD的最高性能,为了避免NVMe SSD的性能瓶颈掩盖了LANoT的性能优势,进行了性能评测。下图3为计算节点通过NVMeTCP、PGIC和 LANoT远程访问存储节点中的RAMDisk时的性能评估结果。 RAMDisk的读写性能比NVMe SSD更高,可以更好地评估存储网络的边界性能。如下图3(a)和(b)所示,在4 K随机读写负载下,当存储网络性能不受NVMe SSD最大性能限制时,PGIC和LANoT基于聚合PDU中断合并的优势大大提升。随着fiothread数量的增加,PGIC和LANoT逐渐达到了网卡的极致性能,而NVMe-TCP由于海量PDU收发操作引入的中断风暴,严重限制了存储网络性能,无法与NVMe SSD相比,更高性能的ULLSSD的性能优势被传递到计算节点应用程序。

图3 基于RAMDisk的读写IOPS对比
比较2种基于中断合并的NVMeoF消息处理机制,因为在使用fio进行饱和测试的情况下,LANoT会根据负载逐步将NVMeoF存储网络的消息处理策略切换到对应的一种情况。数据密集型应用处理策略,增加PG定时器的超时时间,保证每次发送的PG有更高的聚合度,降低NVMeoF存储网络的计算开销。与PGIC相比,LANoT在基于RAMDisk的4 K随机写饱和测试中IOPS性能指标平均提升14.16%。当fio线程数为20时,最高增幅为 20.9%。在基于RAMDisk的4 K随机读饱和测试中,LANoT的IOPS性能指标平均可提升18.39%,最高提升28.24%。在基于RAMDisk的16 K随机写饱和测试中,LANoT将IOPS性能指标平均提升了14.3%,最高提升了37.14%。在基于RAMDisk的16 K随机读饱和测试中,LANoT平均提升了22.64%的IOPS性能指标,最高提升了29.24%。
但相应地,这是通过牺牲PDU延迟时间性能指标来实现的。如图4所示,在基于RAMDisk的4 K随机读写饱和测试中,与PGIC和NVMe-TCP不同的最低延迟基本维持在200 μs。下面,LANoT的最低延迟达到了300 μs的范围,而且由于LANoT采用动态NVeoF消息发送机制,其延迟稳定性更差。在16 K随机读写饱和测试中,LANoT的延迟不稳定性进一步加剧。但对于数据密集型应用来说,其更关注的性能指标是吞吐量,LANoT可以在满足数据密集型应用对延迟的性能需求的同时,大幅提升吞吐量。

图4 基于RAMDisk的最低读写延迟对比
为了测试CPU内核上运行时间敏感应用程序时LANoT的性能,使用fio在固定IOPS指标上进行了基于RAMDisk的4 K随机读写和16 K随机读写延迟测试,结果比较直观,介绍了之前饱和读写测试中延迟性能最好的NVMe-TCP机制进行对比。
如图5所示,在不手动修改任何参数的情况下,使用fio来测试当IOPS指标从50变为500时LANoT和NVMe-TCP的延迟。在基于RAMDisk的测试中,LANoT方法是最低的。延迟和平均延迟与NVMe-TCP方法基本相同。在基于SSD的测试中,LANoT的整体延迟性能略高于NVMe-TCP,但差距控制在100 μs以下。

图5 小数据随机读写延迟测试
5 结论
本文设计并实现了Load-aware NVMeoF消息处理机制LANoT[7-8]。首先,针对NVMe over TCP存储网络在高并发I/O环境下引入的中断风暴问题,在每个NVeoF队列中实现了一种基于聚合PDU的中断合并方法的设计与实现。引入PDU Group数据结构,高效聚合Host端的CapsuleCmd PDU和H2CData PDU,减少Target端的
CPU中断请求次数,高效聚合Target端的C2HData PDU和CapsuleResp PDU,减少CPU中断次数主机端的请求。其次,在PDU Group数据结构中引入并维护3个统计变量SmallPG-send、PG-send和doorbell-ring,表征不同CPU内核-目标内存专用队列的负载情况,进而感知各节点的运行状态。它们的应用和基于不同类型的负载情况匹配不同的NVMeoF存储网络消息处理机制,实现不同I/O特性的应用对应的关键性能指标的优化。解决了多应用I/O干扰问题,无法同时满足数据密集型应用和延迟敏感型应用的需求,所有团队采用单一机制。LANoT原型系统的性能测试结果表明:与标准Linux内核中的标准NVMe over TCP实现相比,LANoT 可以将数据密集型应用程序的 IOPS 指数提高约2倍,并且可以保证延迟敏感应用的延迟性能;与PGIC方法相比,LANoT可以将IOPS指标提升高达37.14%。
