基于边界点检测的变密度聚类算法
2022-08-24陈延伟赵兴旺
陈延伟,赵兴旺*
(1.山西大学计算机与信息技术学院,太原 030006;2.计算智能与中文信息处理教育部重点实验室(山西大学),太原 030006)
0 引言
聚类分析依据一定的准则将数据对象划分为不同的类,使同一类别中的对象具有较高的相似度,而不同类中的对象之间相似度较低。作为一种重要的数据挖掘技术,聚类分析已经在社交网络分析、模式识别、生物信息学等诸多领域得到了广泛应用[1-3]。
经过数十年的发展,研究者针对不同的领域提出了大量聚类分析算法,主要分为以下几类:基于划分的聚类算法、基于层次的聚类算法、基于密度的聚类算法以及基于图的聚类算法等[4]。其中,密度聚类算法由于具有对噪声鲁棒、善于处理结构复杂数据且事先不需要指定类个数等优势,近年来得到研究者的大量关注[5]。1996 年Ester 等[6]提出基于密度的噪声应用空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法,通过将高密度区域划分为类,能够在含“噪声”的空间数据库中发现任意形状的类。1999 年Ankerst 等[7]提出通过点排序识别聚类结构(Ordering Points To Identify the Clustering Structure,OPTICS)算法,得到一个有序的对象列表用于提取聚类信息,但不显式地生成数据聚类结果。2014 年Rodriguez 等[8]提出一种新型的基于密度峰值的聚类算法(Density Peaks Clustering Algorithm,DPCA),该算法基于类中心的密度大于周围邻居点的密度和类中心与更高密度点之间的距离相对较大的假设,用于寻找被低密度点隔离的高密度区域以达到对数据聚类的目的。尽管经典的密度聚类算法在处理形状复杂、包含噪声的数据方面具有一定优势,但是,该类算法面临着由于数据集中不同类的密度分布不均,且类与类之间边界难以区分等导致聚类效果较差的问题。
针对以上问题,本文提出了一种基于边界点检测的变密度聚类算法(Varied Density Clustering algorithm based on Border point Detection,VDCBD)。算法主要包括以下步骤:1)基于给出的相对密度度量方法识别变密度类之间的边界点,以此增强相邻类的可分性;2)对非边界区域的点进行聚类以找到数据集的核心类结构;3)依据高密度近邻分配原则将检测到的边界点分配到核心类结构中;4)基于类结构信息识别数据集中的噪声点。在人造数据集和UCI 数据集上与已有的经典聚类算法进行了比较分析。实验结果表明,本文算法可以有效解决类分布密度不均、边界难以区分的问题,并在4 个评价指标上优于已有算法。
1 相关工作
本章主要对已有的变密度聚类算法进行介绍。
2014 年在Science上发表了快速搜索和发现密度峰值聚类算法(DPCA)[8]。该算法结合了划分聚类算法和密度聚类算法的优点,通过寻找合适的聚类中心点以得到理想的聚类结果,但不能保证每个类中有且仅有一个密度峰,因此DPCA 对变密度数据的聚类效果有限。为了解决变密度聚类问题,一些学者从不同角度对DPCA 进行了改进[9-10]。2016 年Du 等[11]介绍了一种基于k近邻和主成分分析的密度峰值(Density Peak Clustering based onk-Nearest Neighbors,DPC-kNN)算法,该算法引入k最近邻重新定义局部密度以考虑数据集的局部分布情况,减少了截断距离对聚类结果的影响,并引入了主成分分析(Principal Component Analysis,PCA)以处理高维数据集;2016 年,Xie 等[12]提出了一种模糊加权k近邻的密度峰值聚类(Fuzzy weightedk-Nearest Neighbors Density Peak Clustering,FkNN-DPC)算法,该算法通过引入k最近邻给出了一种新颖的局部密度度量方法,并使用两种新的点分配策略将剩余点分配到最可能的类以消除DPCA 点的分配策略导致的“多米诺效应”[13];2018 年Liu等[14]提出了一种基于共享邻居的密度峰值聚类(Shared Nearest Neighbor based Density Peaks Clustering,SNN-DPC)算法,该算法基于共享邻居重新定义数据对象的局部密度和相对距离,并引入两种基于共享邻居信息的分配策略提高非中心点分配的准确性;2020 年Flores 等[15]提出了一种基于中心点自动检测的密度峰值(Density Peak Clustering with Gap-Based automatic center detection,GBDPC)算法,通过对一维决策图中数据点连续对之间的距离处理以自动确定聚类中心点个数,以解决多密度峰值的问题;2020 年Wang 等[16]提出了一种多中心密度峰值聚类(Multi-center Density Peak Clustering,McDPC)算法,该算法通过对决策图进行再规划,将样本划分为不同的密度层用来识别低密度区域的类,并对参数δ(与更高密度点的最近距离)进行类似的划分以识别包含多个密度峰值的类。
另一部分学者提出新的聚类算法用于处理变密度数据。2016 年Chen 等[17]提出了一种有效识别密度主干的聚类(CLUstering based on Backbone,CLUB)算法,该算法通过将DPCA 中寻找聚类中心的策略转换为寻找密度主干,并利用k近邻生成初始类以此定义基本密度骨架,然后根据高密度近邻原则分配其余点并识别噪声点以获得最终的聚类结果;2016 年,Zhu 等[18]提出了基于密度比的聚类算法解决变密度问题,该算法通过使用密度估计器计算密度比和对现有数据进行自适应的缩放两种方法用于对变密度数据的处理;2017年Louhichi 等[19]提出了一种基于样条的无监督变密度聚类(Multi Density ClUsTering,MDCUT)算法,该算法利用k最近邻距离的指数样条寻找合理的密度层次,并利用这些密度层次作为局部密度阈值获取不同密度的类;2020 年Averbuch-Elor 等[20]提出一种边界剥离聚类(Border Peeling clustering,BP)算法,通过迭代剥离边界点并建立边界点与其相邻非边界点的联系,之后利用核心点间的可达性进行核心点的聚类并通过建立的联系分配剥离的边界点。现有算法在不同程度上可以识别变密度数据集的类结构,但是仍然面临着相邻类之间的边界难以区分等导致聚类效果较差的问题。
2 基于边界点检测的变密度聚类算法
假设D={x1,x2,…,xn}表示由n个数据对象组成的数据集,其中xi表示数据集中第i个对象。
定义1k最近邻:对于D中的每个数据对象xi,在欧氏距离下与xi最相似的k个数据对象称为xi的k最近邻,表示为KNk(xi),其中KNk(xi) ⊂D。
定义2逆k最近邻:对于D中的数据对象xi,如果其余任一对象xj的k最近邻中包含xi,则xj为xi的逆k最近邻,形式化描述如下:

本文算法主要包括边界点检测、非边界点聚类、边界点分配以及噪声点识别4 个步骤。
2.1 边界点检测
边界点位于每个类的边缘位置,当两个类相距较近时,两者之间的边界很难识别,受INFLO(INFLuenced Outlierness)算法[21]思想的启发,提出了一种基于相对密度的边界检测方法,用于识别不同变密度类难以区分的边界点,增强数据类结构的可分性。为了提高的运行效率,检测边界点过程中仅考虑所有数据点密度排序后一半低密度的数据点。
定义3数据点密度:一个数据集中每个数据点的密集程度可以表示为该点到与它最近的k个邻居间的距离之和。通常来说,距离和越大,该点与它的邻居间的距离越远,因此,这个点的密度也就越小。考虑到两个类中数据密度为变密度时,该方法不能有效体现两个类中密度的关系,因此,通过增加一个权重提升稀疏类中相对密集点的密度大小。给定一个数据点x与它的k最近邻间的距离集合为{d1,d2,…,dk},数据点x的密度形式化描述如下:

其中:den(x)代表点x的密度;k代表最近邻的个数;di表示数据点x与第i个最近邻点的距离;count(RKN(x))表示数据点x的逆k最近邻个数。
定义4相对密度:将该点的密度与其周围点的密度的均值作比较。比值越小,该点的相对密度越小,即该点成为边界点的可能性越大,数据点x的相对密度形式化描述如下:

其中:RDx表示数据点x的相对密度;RKKN(x)表示数据点x的k最近邻和逆k最近邻的并集。
定义5边界点:将该点的相对密度与其k最近邻点的相对密度作比较,如果该点的相对密度小于其k最近邻的均值,则该点为边界点。形式化描述如下:

为了更直观地体现每个步骤的效果,下面分别以在Flame 和Jain 数据集上处理的结果为例进行介绍,其中Flame数据集由两个相距较近的类组成,Jain 数据集则由两个密度不同的类构成。图1 为Flame 和Jain 数据集上的边界检测结果,边界点使用蓝色空白点表示。由图1 可知,通过该步骤可以有效识别出类与类之间的边界点,进而增强类之间的可分性。

图1 Flame数据集和Jain数据集上的边界识别结果Fig.1 Border recognition results on Flame dataset and Jain dataset
2.2 非边界点的初始聚类
通过对原始数据进行边界点识别,相邻类之间的间距因排除边界点而增大,使类结构探测更为容易。该步骤主要通过对非边界点进行聚类进而找到数据集的核心类结构。首先,从非边界点找到密度最大点,将该点放入一个新的队列中;然后将该点的k最近邻点中尚未分配标签的点加入到该队列中,遍历队列中的下一个点,也将其尚未分配标签的k最近邻点加入队列中,依次遍历队列,直到没有尚未分配的非边界点与队列中数据点存在k最近邻关系;最后给队列中数据点分配新的类标签。以这种方式,访问剩余尚未分配的非边界点,直到所有非边界点类标签分配完毕。
图2 为该步骤对非边界点进行聚类的结果,可以看出通过第一步的边界区域识别后,可以对非边界点进行有效的聚类(空白点是边界点),得到数据集的核心类结构。

图2 Flame数据集和Jain数据集上的非边界点聚类Fig.2 Non-border point clustering on Flame dataset and Jain dataset
2.3 边界点分配
在该步骤中,对第一步中识别的边界点进行分配。分配时,将每个边界点分配到它的最近邻且密度比其大的数据点所在的类中。该方法通过先识别核心类结构再分配边界点的方法,有效地解决了DPCA 聚类中心点难以确定、因数据点的单步分配策略的容错性较差产生的“多米诺骨牌效应”等问题。图3 为经过边界点的分配后得到的最终类结构。
2.4 噪声点识别
经过边界点分配后的聚类结果中可能包含噪声点。例如,图3(a)为Flame 数据集的聚类结果,在左上方有两个明显远离大多数数据点的点,应为噪声点。该步骤通过对噪声点有效识别的过程进一步对聚类结果进行提升。根据数据异常校验中常用的拉依达准则(PauTa 准则),该步骤通过对各类中边界点的密度与所属类的密度信息比较判断是否为噪声点,噪声点的形式化描述如下:

图3 Flame数据集和Jain数据集上的边界点分配Fig.3 Border point allocation on Flame dataset and Jain dataset

其中:noise表示满足条件的噪声点集合;den(xi)表示数据点xi的密度;cl(xi)表示数据点xi所在类的标号;mean(cl(xi))表示数据点xi所在类cl中点的密度均值;std(cl(xi))表示数据点xi所在类cl中点的标准差。
如图4 所示,该步骤在有噪声的Flame 和无噪声的Jain数据集上进行了噪声识别结果。通过图4(a)中可以看出左上角的两个噪声点可以被成功识别出来,并得到最终的聚类结果。

图4 Flame数据集和Jain数据集上的噪声点识别Fig.4 Noise point recognition on Flame dataset and Jain dataset
因此,基于上述思想,本文提出一种基于边界点检测的变密度聚类算法,如算法1 所示。
算法1 基于边界点检测的变密度聚类算法(VDCBD)。
输入数据集D;最近邻数k。
输出聚类结果cluster。


3 实验与结果分析
为验证VDCBD 的有效性,与多个聚类算法在人造数据集和真实数据集上进行了比较。比较算法包括经典的K-means 算法[2]、DBSCAN 算法[6],以及三个新算法DPCA[8]、CLUB 算法[17]和BP 算法[20]。其中,DPCA 和CLUB 算法可以处理具有任意密度的复杂数据集。对于每个算法,通过大量的迭代实验调整其相应的输入参数确定最优的聚类结果。其中只有BP 算法基于Python3.8 运行,本文所提VDCBD 和其余对比算法都是基于Matlab 2019b 上运行的结果。实验环境为Windows10 操作系统,Intel Core i7-4790 CPU @3.60 GHz。
3.1 人造数据集的聚类结果
VDCBD 和5 个比较算法在8 个人造数据集上进行了聚类结果的可视化展示并通过几种评价指标对其聚类结果进行了评价。8 个数据集的样本数、特征数、真实类个数和来源如表1 所示,其中6 个都标明了来源,S1 和S2 是自制的变密度数据集,数据集T4、T8、S1 和S2 没有真实类别信息。

表1 人造数据集描述Tab.1 Description of artificial datasets
8 个数据集的真实分布如图5 所示,不同颜色和形状代表不同的类别,其中黑色空白点表示数据集中的噪声点。

图5 8个数据集的真实分布Fig.5 Real distribution of 8 datasets
本文采用4 种不同的指标对算法性能进行了度量,包括准确度(Accuracy,ACC)[23]、F 度量(F-Measure,FM)[24]、标准化互信息(Normalized Mutual Information,NMI)[25]和调整兰德指数(Adjusted Rand Index,ARI)[26]。其中只有ARI取值范围为[-1,1],其余三个评价指标取值范围为[0,1],其值越大,表明算法聚类结果与真实标签越吻合,聚类结果越好。
图6~13 分别为6 种算法在8 个人造数据集上的聚类结果。每个算法都有自己的参数设置,其中K-means 算法中参数K表示数据集类的个数;DBSCAN 算法中参数epsion表示数据集中每个对象的邻域半径阈值,参数MinPts表示对象的邻域半径中对象个数的阈值;DPCA 中参数percent表示求截断距离时的百分比大小;CLUB 算法和本文VDCBD 的参数k表示k最近邻的个数。每个算法名称后括号中的数字表示该最优结果对应的参数值。

图6 6种算法在Flame数据集上的结果Fig.6 Results of 6 algorithms on Flame dataset
图6 为6 种算法对Flame 数据集的聚类结果。从图6(a)可以看出,K-means 算法因只能处理球形数据集无法对该数据集进行有效聚类。从图6(b)~(c)可以看出,DBSCAN 算法和DPCA 虽然能准确识别出数据的基本框架,但未能准确识别其中的噪声点,对后续的数据分析工作造成一定的影响。CLUB 算法、BP 算法和VDCBD 可以得到正确的聚类结果。
图7 为6 种算法在Jain 数据集上的聚类结果,Jain 数据集是一个典型的变密度数据集。从图7 可以看出:K-means 算法和DPCA 将下方数据集的一部分错误地分配给了上方的类,而DBSCAN 算法则将数据集的一部分错分成为一个新的类,CLUB 算法则将其上方类错误地分成三个小类并将一部分点识别为噪声点,BP 算法则将其错误地分成多个类并产生了大量的噪声点,只有VDCBD 对Jain 数据集的聚类效果最好。

图7 6种算法在Jain数据集上的结果Fig.7 Results of 6 algorithms on Jain dataset
图8 所示的6 种算法在Aggregation 数据集上的聚类结果表明:大多数算法可以对Aggregation 数据集进行有效聚类,只有K-means 算法无法对该数据集进行有效聚类,DBSCAN算法和CLUB 算法则将少量的数据点识别为噪声点。图9 为6 种算法在具有典型球形结构的D31 数据集上的聚类结果。从图9(b)可以看出DBSCAN 算法未能将相邻的两个类分开,且将大量的数据点识别为噪声点,CLUB 算法和BP 算法将部分的数据点识别为噪声点,其余算法对D31 数据集的聚类结果都较好。

图8 6种算法在Aggregation数据集上的结果Fig.8 Results of 6 algorithms on Aggregation dataset

图9 6种算法在D31数据集上的结果Fig.9 Results of 6 algorithms on D31 dataset
图10~11 展示了6 种算法在两个数据规模达到8 000 的数据集上的聚类结果,T4 和T8 均是具有复杂结构和噪声点的数据集,且T8 数据集中包含不同密度的类为典型的变密度数据集。从图10 中可以看出,算法在对复杂数据集T4 聚类时,K-means 算法、BP 算法和DPCA 未能识别真实类结构,DBSCAN 算法虽能识别出数据的真实类,但却有多个小类被错误识别,只有VDCBD 和CLUB 算法可以对数据进行有效地聚类且能识别出噪声点。从图11 中可以看出,只有VDCBD 能够准确识别T8 数据集的类结构,并能识别其中的噪声点,其余算法都不能识别真实的类结构。

图10 6种算法在T4数据集上的结果Fig.10 Results of 6 algorithms on T4 dataset

图11 6种算法在T8数据集上的结果Fig.11 Results of 6 algorithms on T8 dataset
图12~13 所用数据集为本文提供的两个变密度数据集。从图12 所示的6 种算法在S1 数据集的聚类结果可以看出:只有VDCBD 可以得到较好的聚类结果,DBSCAN 算法错误地将上方类分为几个新类且将大量的点识别为噪声点。CLUB 算法可以识别出三个真实类,但将上方类中的部分数据点错误划分为其他类或噪声点,其余算法均未能识别真实的类结构。图13 的S2 数据集相较于S1 相邻的类之间的密度差更大,从(d)可以看出对S1 数据集有较好聚类效果的CLUB 算法也未能将两个密度相差较大的类进行准确地聚类,DPCA 和CLUB 算法无法识别出上方半环型的类。只有VDCBD 准确地识别了数据集的类结构,仅将少量的点识别为噪声点。

图12 6种算法在S1数据集上的结果Fig.12 Results of 6 algorithms on S1 dataset

图13 6种算法在S2数据集上的结果Fig.13 Results of 6 algorithms on S2 dataset
从8 个人造数据集的可视化结果中可以发现,本文VDCBD 相较于其他算法在处理具有复杂结构且密度不均的数据集时更加有效。表2 为VDCBD 与对比算法在4 个人造数据集上通过四种评价指标进行质量评价的结果,其中T4、T8、S1 和S2 数据集由于没有真实标签,因此这四个数据集没有出现在表2 中。
从表2 中可以看出,在具有复杂结构的Flame 数据集和Aggregation 数据集中,除了K-means 算法外,其余算法均获得了较好的聚类结果,VDCBD 达到了最高的聚类结果,且参数k的取值在一定程度上有着不错的鲁棒性。在对变密度数据集Jain 的聚类中,VDCBD 可以对该数据集准确聚类,在四个评价指标上均达到了最高值1,说明了本文算法在处理变密度数据集时的有效性。在典型的球形数据集D31 结果中可以看出,VDCBD 和K-means 算法的聚类结果相差无几,仅在ARI 和NMI 评价指标上略低于K-means 算法,但VDCBD 在四种评价指标上均高于其余4 种密度聚类算法。综上所述,本文提出的VDCBD 在处理复杂结构的人工数据集,尤其是在变密度数据集时与其他算法相比可以获得更优的聚类结果。

表2 6种算法在4个人造数据集上的聚类结果Tab.2 Clustering results of 6 algorithms on 4 artificial datasets
3.2 真实数据集的聚类结果
为了验证算法在真实环境下的有效性,用6 种聚类算法对真实数据集进行聚类来验证算法的有效性。其中,真实数据集来源于UCI 机器学习数据库[27],其详细信息可见表3。

表3 真实数据集描述Tab.3 Description of real datasets
在UCI 数据集上的聚类结果仍然采用ARI、NMI、FM 和ACC 四个评价指标进行质量评价,并给出了聚类结果对应的参数。6 种算法在真实数据集的聚类结果如表4 所示。
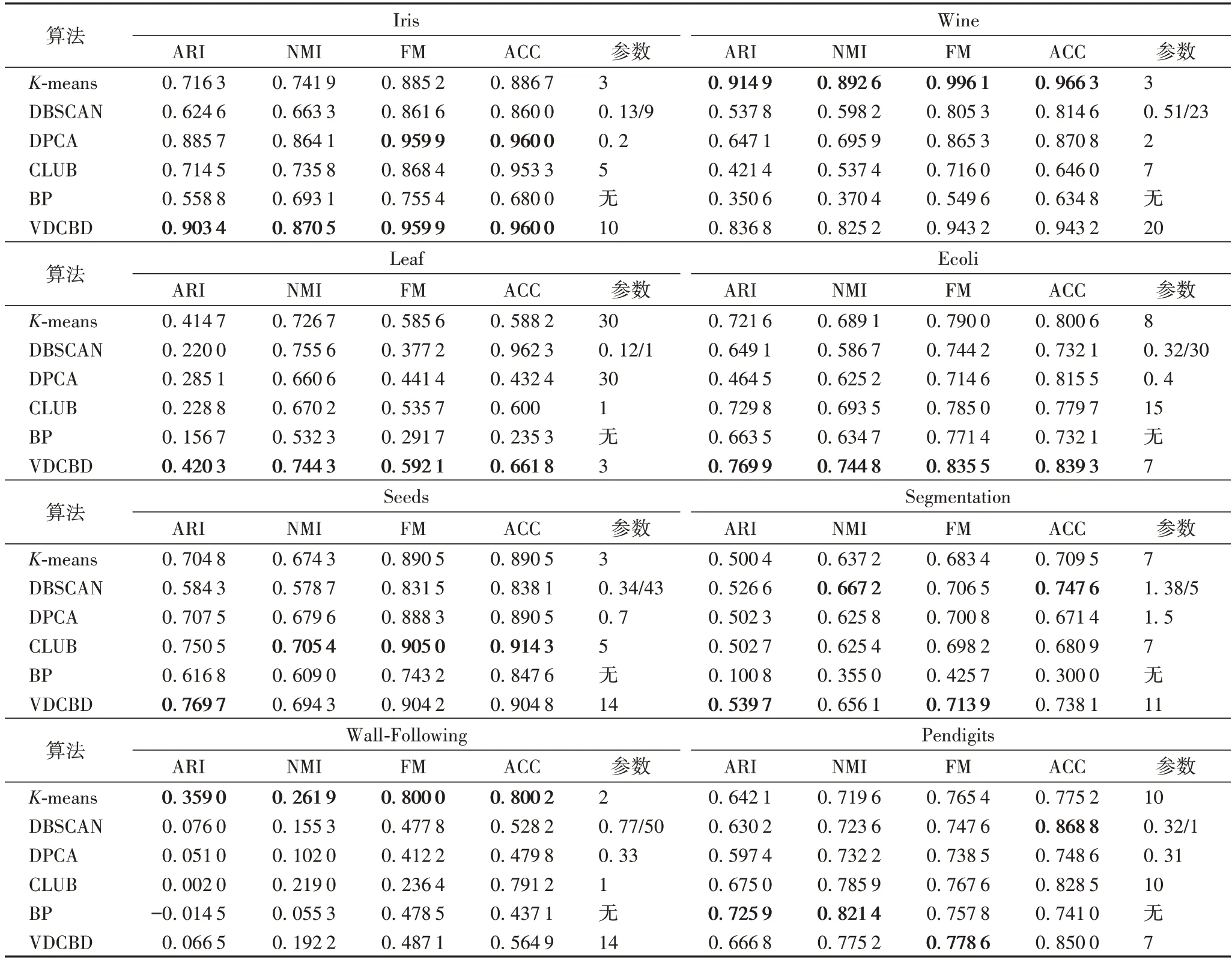
表4 6种算法在8个真实数据集上的聚类结果Tab.4 Clustering results of 6 algorithms on 8 real datasets
从6 种算法在真实数据集上的聚类评价结果可以看出,VDCBD 相较于对比算法在Iris、Leaf 和Ecoli 三个数据集上聚类效果最好;在Wine 数据集上虽未达到最好的聚类结果,但相较于其余4 种密度聚类算法有不小的提升。在Seeds 数据集中,VDCBD 在ARI 评价指标上达到了最好结果,并且在四种评价指标上均高于K-means、DBSCAN、DPCA 与BP 算法。在Segmentation 数据集中,VDCBD 和DBSCAN 算法在该数据集的聚类结果相差无几,在ARI 和FM 两个指标上相比DBSCAN 算法略有提升。当数据规模达到5 000 以上时,VDCBD 与对比的密度聚类算法相比仍具有一定的竞争力。综上所知,VDCBD 在处理真实数据集上的聚类结果相较于对比算法有一定的提升。
3.3 时间复杂度及运行效率分析
本文VDCBD 在计算数据点的密度时,时间复杂度为O(n2),其中n为数据集大小;在第一步边界点的检测过程中,时间代价至多为O(k×n)+O(r×n),其中k为最近邻个数(k≪n),r为数据点最大的RKKN 的个数;在第二步对非边界点的识别过程中,其时间代价最大为O(k×m2),其中m为非边界点的个数;第三步对边界点的分配过程中,时间代价为O(n×(n-m))+O(n);最后对各类中噪声点的识别过程中,时间代价为O(c_count×g)+O(m),其中c_count为类别数,g为类中的最大数据个数。综合以上分析,本文算法的总时间复杂度为O(n2)。
K-means 算法的时间复杂度为O(t×n×K×ml),为线性时间复杂度,其中:t为迭代次数,K为类的数目,n为数据集总个数,ml为数据点维度;DPCA 和DBSCAN 算法的时间复杂度为O(n2);BP 算法的时间复杂度为O(t×(k×n+fknn)),其中:fknn是k最近邻的渐进时间复杂度。CLUB 算法的时间复杂度为O(nlogn)。
由于6 种算法在小规模数据集上的运行时间均较小,因此文中只比较了在数据规模达到5 000 以上的数据集的实际运行耗时。图14 展示了6 种聚类算法在较大规模数据集上的运行时间比较。为了保证数据的稳定性,每种算法均独立运行50 次,取平均值作为算法在该数据集上的运行时间。
通过图14 可以看出,当数据规模较大时,VDCBD 的运行效率高于DPCA、CLUB 算法和BP 算法。

图14 6种算法的运行时间比较Fig.14 Comparison of running time of 6 algorithms
4 结语
本文提出了一种基于边界点检测的变密度聚类算法VDCBD,用于更加有效地处理具有复杂结构、任意密度的数据集。不同于以往通过寻找聚类中心点聚类的方法,算法首先识别各类边界区域,扩大各类间的距离;第二步,通过对非边界区域的点进行聚类获得数据集的核心类结构,之后根据高密度近邻分配原则将检测到的边界点分配到核心类结构中;最后基于类结构信息识别数据集中的噪声点,得到最终的聚类结果。实验结果表明,本文所提VDCBD 在人造数据集和真实数据集上具有一定的优势,相较于对比算法更加准确有效,尤其在变密度数据集上聚类效果更加明显。
在未来的工作中,考虑将分而治之的思想融入到提出的密度聚类算法中,进而使其能够高效地处理大规模数据。另外,现有数据可能存在特征值缺失的情况,给密度聚类算法来了新的挑战,这也是下一步工作的研究重点。
