基于节点-属性二部图的网络表示学习模型
2022-08-24周乐代婷婷李淳谢军楚博策李峰张君毅刘峤
周乐,代婷婷,李淳,谢军,楚博策,李峰,张君毅,刘峤*
(1.电子科技大学信息与软件工程学院,成都 610054;2.河北省电磁频谱认知与管控重点实验室,石家庄 050081;3.中国电子科技集团公司航天信息应用技术重点实验室,石家庄 050081)
0 引言
表示学习是指采用机器学习算法,将图结构数据中的实体节点表示为低维实值向量,可用于与图相关的推理计算任务,如链路预测[1]或节点分类[2]等。在应用层面,可根据社交网络中用户间的拓扑结构与用户描述等上下文信息预测用户的交友兴趣,或根据论文引用网络中的拓扑结构和关键词信息推断文章的研究主题等。
根据研究对象的不同,表示学习模型可分为两类:1)关系类型单一的网络表示学习模型,如DeepWalk[2]、node2vec[3]等,该类研究大多基于随机游走方法进行网络节点序列采样,然后采用Skip-gram[2-3]、循环神经网络(Recurrent Neural Network,RNN)[4]等序列学习模型得到节点的向量表达;2)关系类型多样的知识图谱表示学习模型,如TransE[5]、图卷积神经网络模型(Graph Convolutional Network,GCN)[6]等,该类研究大多基于节点-关系语义映射思路[7],采用深度学习模型学习节点和关系的向量表达。本文主要关注属性网络表示学习建模问题。
基于随机游走的采样模型在大规模稀疏的网络表示学习任务中因性能良好而被广泛采用[1-3,8]。但近期研究表明,如果仅根据网络的拓扑结构进行随机采样,即限定随机游走仅发生在直接相邻的节点之间,容易导致采样结果中,度较高的中心节点出现频率较高[8-9],这样不仅会削弱采样结果的多样性,而且难以有效利用网络中的节点属性等上下文信息[10-11]。为解决上述问题,Huang 等[4]提出了一种基于节点-属性二部图的随机游走(Attributed random Walk,AttriWalk)方法,如果图中的节点具有相同的属性(虚拟节点),则可以通过该属性节点对不相邻的节点采样,从而利用节点的属性等上下文信息,该方法在提高采样结果多样性的同时有效地缓解了采样偏向中心节点的问题。
然而,AttriWalk 也存在明显局限性。AttriWalk 将网络视为节点-属性二部图,分别采样得到节点-节点、节点-属性-节点两种形式的序列。在“节点-属性”采样过程中,每个节点有多种属性,不同属性有不一样的取值,AttriWalk 直接对属性值归一化,以此作为从多个属性中选择下一跳目标的迁移概率计算依据,这种概率计算方式易导致采样过程偏向属性值较高的属性,而忽略了属性值低、但在有边相连的节点对之间频繁出现的属性。在实际网络中,在不考虑属性值影响的情况下,当部分属性在有邻接关系的节点对间出现次数越多,则非邻接节点间含有这类共有属性的数量越多,产生关联的可能性越大。例如,在以关键词为属性、关键词在论文中出现的次数为属性值的论文引用网络中,两篇论文是否相关与其属性值大小无关,主要取决于它们是否同时包含多种在其他主题相似的论文中频繁出现的共有关键词,当这类关键词种数越多,主题相似性越大。
针对上述问题,本文通过分析属性对节点关系的影响,提出了一种基于节点邻接关系与属性关联关系的随机游走方法,根据网络中相邻节点间共有属性分布情况调整属性的权重,从而使得对节点间语义关联真正有贡献的属性获得采样优势,并以此为媒介增加网络中非邻接节点间的关联。在此基础上,构建了一个基于节点-属性二部图的网络表示学习模型,学习获得网络中的节点向量表达。
本文主要工作如下:
1)提出了一种基于节点邻接关系与属性关联关系的随机游走方法。与已有工作不同的是,该方法通过邻接节点的共有属性分布获取不同属性对节点关联的重要性,进而得到节点到每种属性的采样概率,又称基于属性权重的随机游走(Weighted attribute based random Walk,WarWalk)方法。
2)构建了一种基于节点-属性二部图的网络表示学习模型(Network Embedding model based on Node Attribute Bipartite braph,NE-NAB)。NE-NAB 以WarWalk 的采样结果为输入,通过基于自注意力机制的序列学习模块得到网络节点的向量表达。在3 个公开数据集上的实验结果表明,NE-NAB 的性能表现均优于相关工作,且WarWalk 可以通过“节点-属性-节点”类型的采样序列提取非邻接节点间的隐含信息,使采样以较大概率发生在网络中的同类节点间,从而增加序列中所包含的信息量。
1 相关工作
现有表示学习模型根据研究对象的不同,可划分为关系类型多样的知识图谱表示学习模型和关系类型单一的网络表示学习模型。
知识图谱表示学习模型重点关注多关系数据中节点-关系的映射,并采用深度学习模型获得映射规律与节点关系的向量表达。如TransE[5]、TransH[12]、TransAH[13]以缩小知识图谱三元组〈节点,关系,节点〉中任意两个元素加和后与第三个元素的距离为节点-关系的映射方式,从而得到节点与关系的向量表达。DistMult[14]认为节点与节点之间的关系为线性映射;ComplEx[15]针对DistMult[14]线性映射中有向边引发的语义不对称性问题,将表示学习的向量空间推广到复数空间;ConvE[16]、HolE(Holographic Embeddings)[17]分别通过二维卷积、循环卷积的方式学习节点-关系映射模式。上述模型通过知识图谱三元组学习节点-关系的映射模式,忽略了多关系数据中节点的多跳关联,对此,Yun 等[18]提出基于元路径的GTN(Graph Transformer Network)模型,将异构图转换为由元路径定义的同构图。Kipf 等[6]引入分层传播规则对图中节点的多跳邻居进行信息聚合。
网络表示学习模型(如DeepWalk[2]),通过随机游走从网络中采样得到节点序列,然后用Skip-gram 算法进行序列学习,得到图中节点的向量表达。DeepWalk 通过均匀随机分布的方式选取随机游走序列中下一个节点,采样过程中会对中心节点重复采样,Grover 等[3]定义目标节点到邻居节点的不同转移概率,将广度优先搜索和深度优先搜索引入随机游走中,使得采样序列从不同角度捕获网络特征,从而提高网络表示学习的效果。不同于DeepWalk 与node2vec 的近邻相似假设,Ribeiro 等[19]认为除共同邻居外,空间结构相似的节点也拥有很高的相似性,如星型结构的中心节点、社区结构之间的桥接节点等,并提出基于分层带权图的struc2vec模型。
上述网络表示学习模型从不同角度提取节点信息,在链路预测[1]、节点分类[2]等任务中各具优势,但由于采样过程主要关注网络结构信息,即仅根据网络结构进行随机游走,忽略了节点的上下文描述信息[10-11],导致采样向度中心性较高的节点偏移[8-9],即越靠近网络中心的节点采样序列越相似。同时,对于分布不均衡的网络,常存在簇内连接紧密、簇间关联稀疏的簇结构,上述采样方法可能陷入簇内,很难全面访问节点。
对于上述问题,部分研究者提出了通过构建节点邻居集[20]、节点角色抽象图[21]或节点-属性二部图[4]的方式,获取除节点关系以外的节点属性、角色等描述信息。如Hou 等[20]提出通过属性相似度进行节点聚类,用有偏采样方法区分属性相似和近邻相似对目标节点的影响。Ahmed 等[21]通过聚类方法定义网络中的节点角色,并根据节点类型、标签、属性值等提出基于节点角色的随机采样方法。Huang 等[4]提出了一种基于节点-属性二部图的属性随机游走模型,不仅可以将节点的直接邻居作为采样目标,还可以将节点的属性作为采样目标。该方法将属性抽象成“节点”进行随机游走,缓解了采样向高中心性节点偏移的问题,但缺乏对属性采样概率的考虑,即以不同属性为桥梁增加网络中的节点交互时,不同属性对节点关联的重要性各异。
2 网络表示学习算法
2.1 符号系统
令G={V,E,FT}表示带属性的无向网络,其中:V={v1,v2,…,vn}表示图中的节点集合;E={e1,e2,…,em}表示图中的边集合;FT={ft1,ft2,…,ftk}表示图中节点的属性类型集合。令A∈Rn×n表示网络邻接矩阵,F∈Rn×k表示节点的属性值矩阵,其中:n、m、k分别表示图中节点、边、属性的数量。
令O∈Rk×k表示由属性独热(one-hot)向量组成的特征矩阵,如式(1)所示:

令序列集合Seq={Q1,Q2,…,Qn}表示采样结果,其中Qi表示以节点i为起点得到的采样序列,有:

2.2 基于属性权重的随机游走方法
节点间的差异体现在节点本身所包含的属性信息以及节点在网络中的拓扑结构。文献[22-24]中的研究表明,节点的拓扑结构与节点所包含的属性信息存在显著关系。现有工作[5]虽然通过引入属性增加了节点交互的多样性,但忽略了不同属性对节点关联的作用程度不同。对此,本文提出基于属性权重的随机游走方法,其核心在于分析相邻节点的共同属性分布,根据属性对节点语义关联的影响,提高对节点语义关联真正有贡献的属性采样概率。WarWalk 示意图如图1 所示。
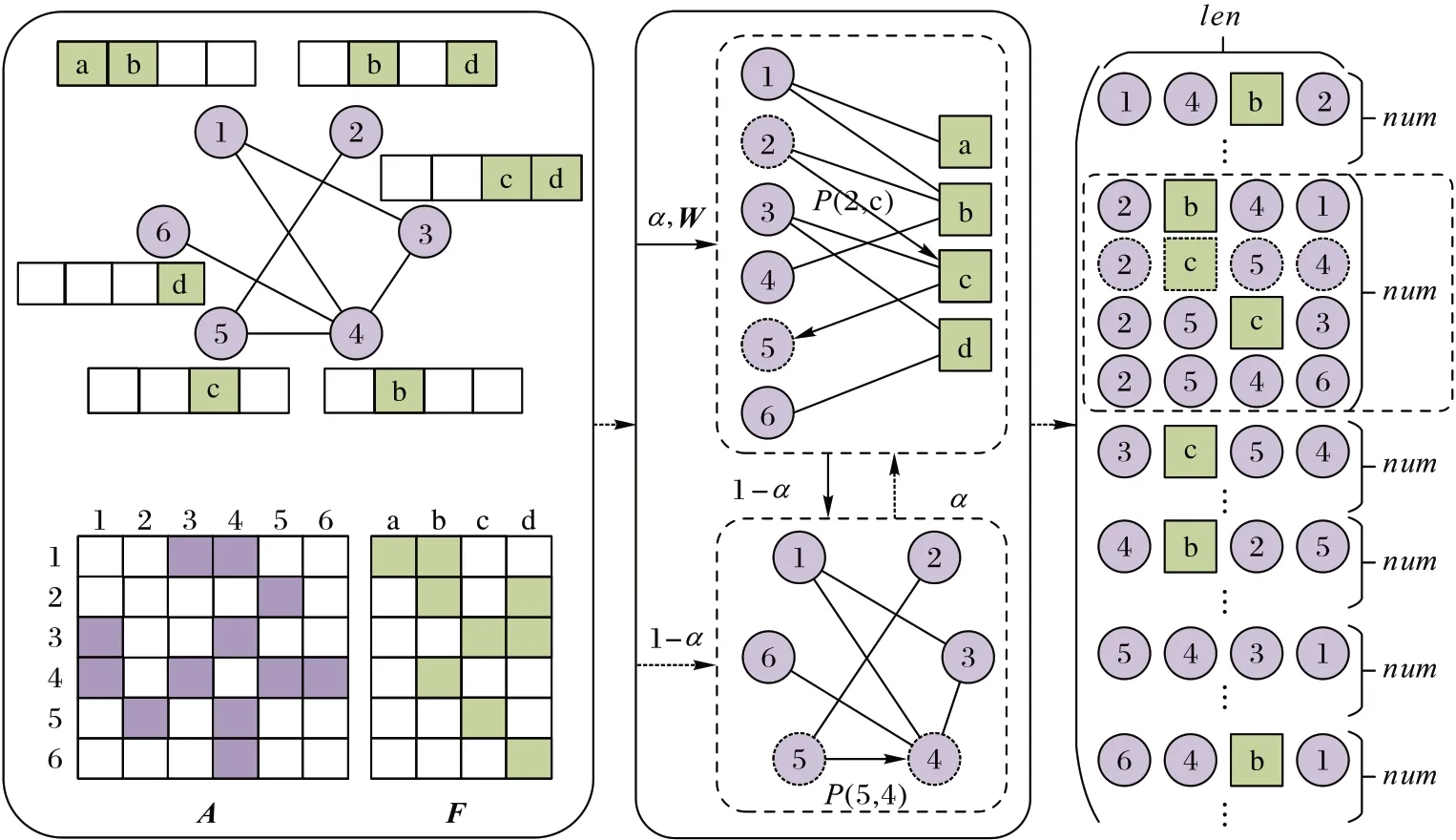
图1 WarWalk示意图Fig.1 Schematic diagram of WarWalk
首先,根据网络拓扑结构获取邻接矩阵中有直接交互(即有边)的节点,然后从属性矩阵中抽取两个节点对应的属性向量,通过属性向量相乘判断两个节点之间的共有属性,进而获得不同属性权重W∈Rn×k,如式(4)所示:
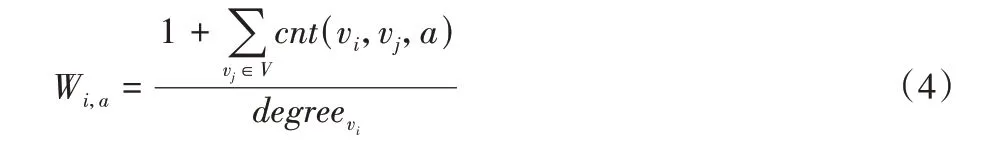
其中:Wi,a表示节点i与周围节点产生语义关联时,属性a的重要程度;degreevi表示节点i的度;函数cnt(vi,vj,a)用于统计有边关联的节点i与节点j是否含有共同属性a。cnt(vi,vj,a)的计算公式如式(5)所示:

根据上述采样概率矩阵可以计算得到采样序列Qi中,从元素到元素采样的概率如式(8)所示:
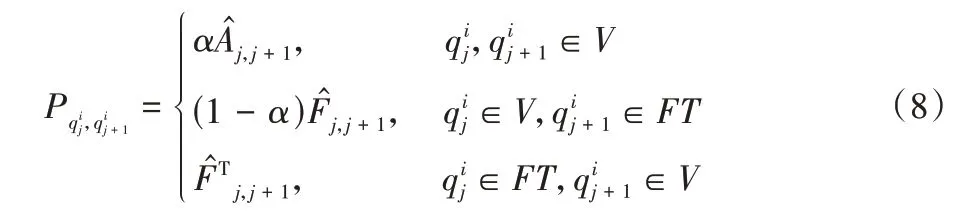
根据上文描述的基于节点邻接关系与属性关联关系的混合游走方法,具体实现过程如算法1 所示。
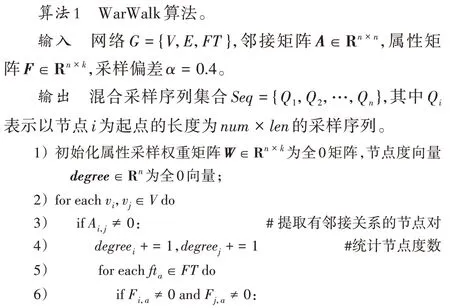

2.3 网络表示学习模型
网络采样过程决定模型输入包含何种网络信息,序列特征学习则决定了模型可以从输入中学习何种特征形成节点向量表达。本文以WarWalk 中的采样序列为输入,通过自注意力机制提取序列特征获得节点向量表达,如图2 所示。
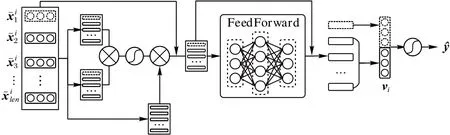
图2 NE-NAB示意图Fig.2 Schematic diagram of NE-NAB
首先,通过属性矩阵F与属性独热矩阵O初始化序列Qi中对应元素的向量表达,并将其映射到低维向量中展开计算,如式(9)所示:

在上述序列向量矩阵中,表示从节点i出发,第一次采样经过j-1 跳可以到达的元素,表示从节点i出发,第二次采样经过j-1 跳可以到达的元素,对此,通过平均池化的方式,将每次采样得到的信息按照跳数进行整合,如式(10)~(11)所示:

接着,通过基于自注意力机制堆叠前馈神经网络的序列学习模块提取不同跳数上的元素特征,如式(12)~(13)所示:

根据上述模块得到采样序列中每个元素的向量表达。由于每个采样序列是由一个目标节点出发得到,因此所得表达不仅包含目标节点自身的语义特征表达,还包含其不同跳邻居的语义特征表达。类比GCN 中的信息聚合方式[6],此处通过平均池化与向量拼接⊕得到节点i的向量表达vi∈Rd,d表示向量维度,如式(14)所示:
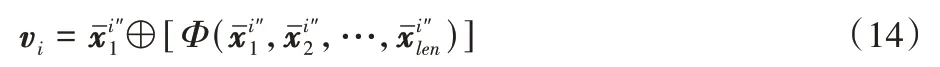
根据所得节点向量表达,使用Softmax()函数为每个节点计算每个类别对应的概率,并使用交叉熵计算模型的损失,如式(15)~(16)所示:
PDCA循环贯穿整个项目施工过程,从最初的立项、结构图纸设计、现场的施工进度管理、质量控制措施,安全管理等。随着现代管理水平和施工技术水平的迅猛发展,在土木工程施工的过程中PDCA循环的应用越来越普遍,所起的作用也越来越显著。

3 实验与结果分析
3.1 数据集与预处理
本文实验数据情况如表1 所示。其中:n、m分别表示网络中的节点、边数量;k、l表示网络属性种类、节点标签数量;Edge Density 与Attributed Density 分别表示边与属性的分布密度。
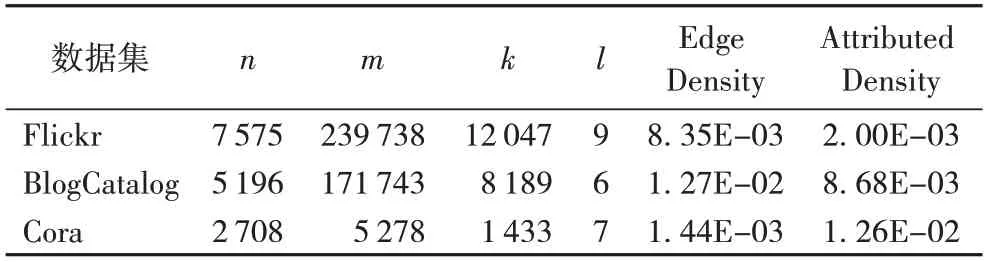
表1 实验数据信息统计Tab.1 Statistics of experimental datasets
三个数据集分别如下:
1)Flickr 由图片分享网站中的7 575 个用户、12 047 种用户描述信息与239 738 条好友关系组成,根据用户喜欢的图片类型,可将其划分为9 种不同的兴趣组;
2)BlogCatalog 是由博客社区中的5 196 个博主、171 743条关系组成,博主属性由8 189 个博客关键字描述构成,可将其划分为6 种不同的类别;
3)Cora 数据集由2 708 篇论文、5 278 条引用关系组成,论文节点的属性由1 433 个摘要关键词组成,可划分为7 种不同主题。
由于数据集来自不同领域,网络稀疏性与属性分布情况各不相同,所得实验结果能够较好地反映出本文所提表示学习算法模型的鲁棒性和泛化性。
3.2 实验设置
在模型训练过程中,设置属性采样概率α=0.4,学习率为0.000 1,隐藏层神经单元数为200,dropout设置为0.2,算法迭代次数为100。
为验证模型性能,根据近期相关工作选取DeepWalk[2]、node2vec[3]以及GraphRNA(Graph Recurrent Networks with Attributed random walks)[4]为基准,并构建了基于NE-NAB 的两种对比模型,具体如下:
1)DeepWalk。只从节点关系采样,然后采用Skip-gram学习网络节点的向量表达。
2)node2vec。在DeepWalk 的基础上引入超参数p、q控制节点的深度优先采样和广度优先采样趋势,随机游走仍然只考虑节点关联关系。
3)GraphRNA。通过节点-属性二部图采样获得既包含节点关系又包含节点属性描述信息的序列,然后通过循环神经网络提取节点信息,获得节点向量表达。但是,在属性采样时,未考虑属性对节点间关系的影响。
4)NE-NAB_NW。与NE-NAB 相比,在属性采样时,使用不加权重的属性矩阵为采样依据,即使用GraphRNA 中的AttriWalk 采样方式,然后通过基于自注意力机制堆叠前馈神经网络的方式学习采样序列中的特征。
5)NE-NAB_NA。如图3 所示,与NE-NAB 相比,在得到不同跳的聚合信息后,直接聚合节点i的多跳邻居信息。通过对比NE-NAB_NA 与NE-NAB,可验证所提自注意力机制堆叠前馈神经网络在序列特征提取中的性能。
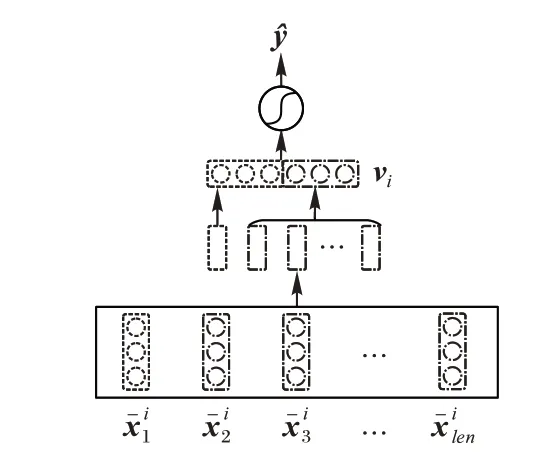
图3 NE-NAB_NA示意图Fig.3 Schematic diagram of NE-NAB_NA
3.3 节点分类任务
网络节点分类指通过节点与其他节点的关联关系等网络结构信息、节点的属性描述等上下文信息对节点进行分类。通过节点分类,可以有效区分不同类别的实体,从而根据实体类别进行信息管理和推荐。NE-NAB 与对比模型在3个数据集中的节点分类实验结果如表2 所示,为与相关工作保持一致,将数据集划分为训练集、测试集和验证集,其中训练集的比例(Training Rate,TR)根据50%、70%、90%依次递增。由于,采样过程具有随机性,所以相同比例训练集的实验将重复进行10 次,实验结果取平均值,以Micro-F1、Macro-F1 为评判标准。
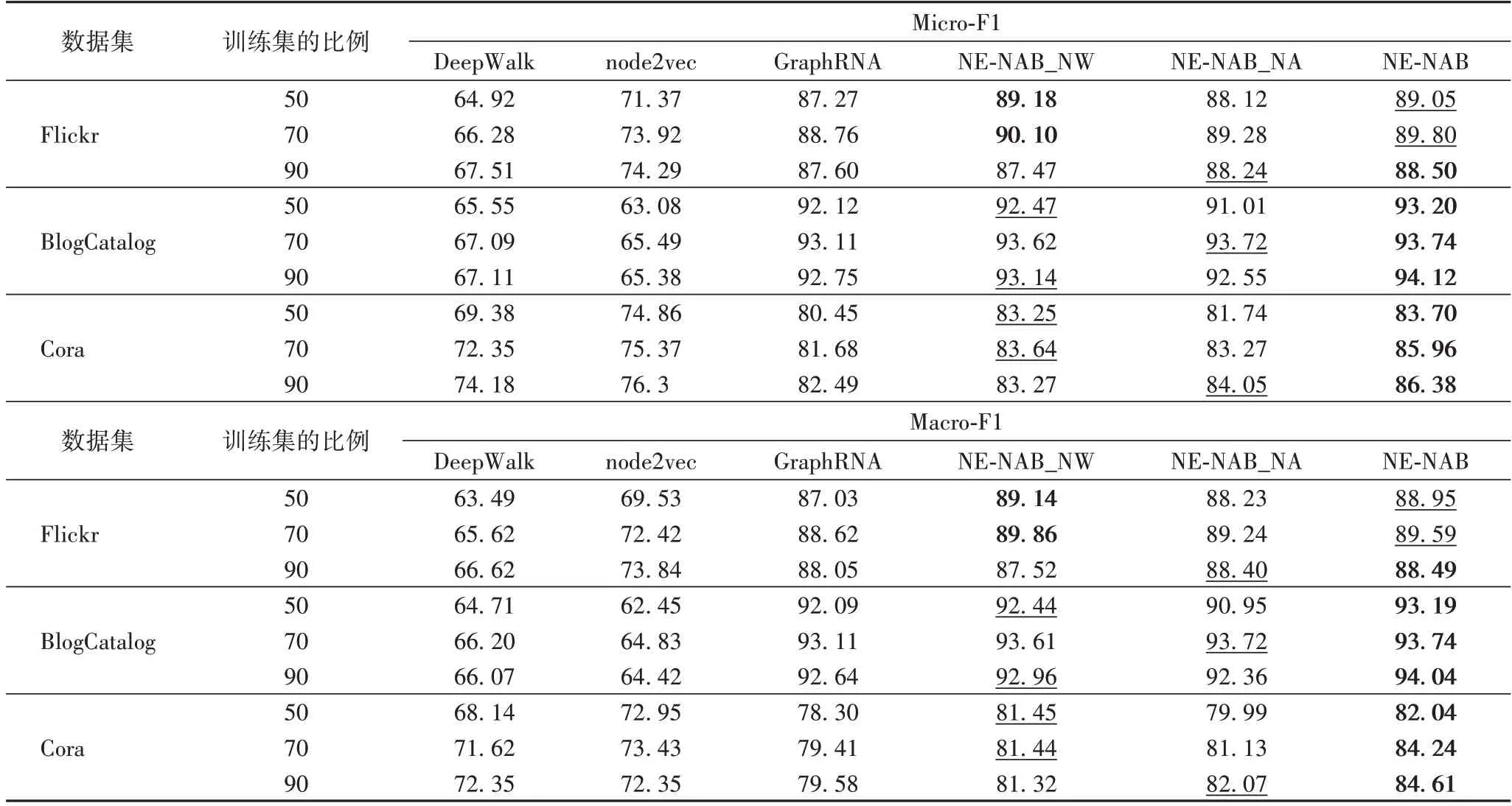
表2 Flickr、BlogCatalog和Cora数据集上的节点分类结果 单位:%Tab.2 Node classification results on Flickr,BlogCatalog and Cora datasets unit:%
由实验结果可知,在Flickr、BlogCatalog、Cora 公开数据集上,用NE-NAB、GraphRNA、DeepWalk 得到的节点向量表达进行节点分类,Micro-F1 平均准确率分别为89.38%、87.36%、68.26%,NE-NAB 比GraphRNA 高出了2.02 个百分点,比经典工作DeepWalk 高出了21.12 个百分点。此外,与DeepWalk、node2vec、GraphRNA 等模型相比,NE-NAB 在节点分类任务中呈现出较好的稳定性与鲁棒性,当Cora 数据集中的训练集比例为70%时,NE-NAB 与GraphRNA 相比性能提高5.24%。
在使用WarWalk 方法进行随机游走后,NE-NAB_NA 通过简单映射模型可以获得与GraphRNA 相当的性能,说明本文所提WarWalk 方法可以通过提高部分属性的采样概率,有效增加网络中的节点关联,使采样序列包含更多网络信息,提高了表示学习模型输入数据的信息质量。该结论可通过对比NE-NAB 与NE-NAB_NW 的性能验证。当Cora 数据集中训练集比例为90%时,使用WarWalk 方法的NE-NAB 与不使用的该采样方法的NE-NAB_NW 模型性能差异最大,其中MicroF1 增加了3.73%,MacroF1 增加了4.05%。
此外,在不使用WarWalk 方法进行随机游走时,NENAB_NW 的性能在BlogCatalog、Cora 数据上的效果均优于DeepWalk、node2vec、GraphRNA 等模型,在Flickr 上的效果与GraphRNA 相当,由此可以说明:相较于GraphRNA 中的循环神经网络,本文提出通过基于自注意力机制堆叠前馈神经网络的序列特征学习方法可更好地学习节点序列的属性与结构信息。当NE-NAB 与NE-NAB_NA 都采用基于属性权重的随机游走方法时,该结论同样成立。NE-NAB 的性能优于NE-NAB_NA 模型,说明基于自注意力机制堆叠前馈神经网络的方法可以有效提取序列特征并将节点的上下文信息融入节点向量表达中。
在Flickr 与BlogCatalog 数据集上,随着训练数据从70%增加到90%,GraphRNA 与NE-NAB、NE-NAB_NA、NENAB_NW 等模型的节点分类实验结果不增反降,这一下降趋势在NE-NAB_NW 中较明显,当Flickr 数据集中的训练集比例为90%,Micro-F1 降低了2.92%。主要原因可能是随着训练集的增加,训练数据中节点关系带来的主要结构信息增加,通过共有属性引入的信息易对主要信息造成影响,从而导致性能下降。
3.4 案例分析
为验证属性权重对采样过程中提取网络信息的贡献,本文选取了三种方法进行了对比实验:
1)RandomWalk[2-3]。只根据节点关系进行随机游走。
2)AttriWalk[4]。根据节点关系与不含权重的属性矩阵进行随机游走。
3)WarWalk。根据节点邻接关系和属性关联关系进行随机游走。
实验之前固定采样长度len=5,每个节点的采样次数为num=100,节点采样偏差α=0.4。
分别对三种随机游走方法所得序列中的节点类别进行统计,以节点i为例,在以节点i为起点的采样序列中,统计除采样起点外,与节点i含有相同类别的节点数量为ni,序列中除节点i之外的节点总数为sumi,节点i采样序列中含有相同标签节点所占比例Probi如式(17)所示:

用RW、AW、WW分别表示RandomWalk、AttriWalk、WarWalk。在三种采样中,所得采样序列中与目标节点含有相同标签的节点所占比例分别记为以RandomWalk 为例,具体计算方式如式(18)所示:

在Flickr 中的所有n=7 575 个节点中,与RandomWalk 方法相比,使用AttriWalk 与WarWalk 方法后,采样序列中与目标节点含有相同标签的节点所占比例分别增加了14.91%和15.05%,即增加属性对网络元素进行随机游走,尤其对共有属性分析计算权重,调整不同属性采样概率后,采样序列中与目标节点含相同标签的节点采样概率整体增加。为更好地验证上述结论,在Flickr 数据集中随机选取5 个节点,在相同采样设置、不同采样方法中,对每个节点采样得到的序列中与目标节点含有相同标签的节点占总采样序列总节点的比例分布如图4 所示。由图4 可知,在增加属性采样,并提高对节点关联有促进作用的属性采样概率后,能够在采样过程中更好地获得与目标节点标签相同的节点,增加采样序列所含信息。
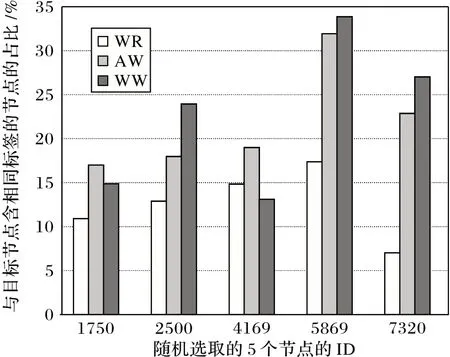
图4 Flickr数据集中与目标节点含相同标签的节点占比Fig.4 Proportion of nodes with common labels with target node in Flickr dataset
4 结语
本文通过分析属性对节点关系的影响程度,计算随机游走过程中的属性采样权重,充分挖掘网络潜在信息,并在有限采样次数中获取网络结构与节点属性信息,然后提出基于注意力机制堆叠前馈神经网络的模块提取序列中的节点特征,从而获得高质量的网络节点向量表达。本文模型与设计的实验主要面向带属性的同质网络,在未来的工作中,将针对如何提取异质网络属性信息展开研究。同质网络与异质网络的区别在于节点类型与关系类型的多样性。一般地,同种类型的节点才会有相似的属性,而不同类型的节点很难有相似的属性,所以基于属性的随机游走方式可以有效捕获同类节点间的特征,但在异质网络中将主要考虑如何将关系类型与关系属性合理纳入游走机制中。
