基于优化变分模态分解和核极限学习机的集装箱吞吐量预测
2022-08-24张丰婷杨菊花任金荟金坤
张丰婷,杨菊花*,任金荟,金坤
(1.兰州交通大学交通运输学院,兰州 730070;2.中国铁路兰州局集团有限公司兰州货运中心安全生产部,兰州 730030)
0 引言
在全球经济一体化的背景下,港口在国际贸易活动中的作用日益显著[1],特别在21 世纪,集装箱航运业务的迅速增长引发了一系列问题,如港口日常运营管理、基础设施建设和升级改造等,所以港口吞吐量预测尤为重要[2]。准确的港口吞吐量预测不仅可以避免重复建设,而且可以提高港口资源利用效率[3]。如果吞吐量预测的准确性较差,就会发生政策偏差,导致重大的财务损失。因此,准确预测港口集装箱吞吐量很有必要。本研究采用深圳港集装箱吞吐量月度数据集,建立混合模型进行短期预测。
集装箱吞吐量预测是一个热门的研究内容,目前采用的集装箱吞吐量预测模型可以粗略地分为三类:传统的计量经济模型、人工智能模型和混合集成模型[4]。传统的计量经济模型是一类发展比较成熟的建模技术,常用模型主要包括:指数平滑(Exponential Smoothing,ES)、整合移动平均自回归(AutoRegressive Integrated Moving Average,ARIMA)等基础模型,以及它们的扩展模型,如季节自回归移动平均(Seasonal ARIMA,SARIMA)[5]等。计量经济模型通过捕捉集装箱吞吐量变量及其影响因素之间的因果关系来预测集装箱吞吐量。如Zhang 等[6]利用因果分析模型预测港口短期货物吞吐量;杜柏松等[7]利用马尔可夫理论对优化后的GM(1,1)预测残差值进行修正,得出上海港集装箱吞吐量的预测值。实验结果表明,计量经济模型能够成功地将观测数据与理论相结合,修正后的回归模型提高了预测精度;但是,具有强大理论支撑的计量经济模型需要完整的输入信息和准确的因果关系[8],而样本数据通常被施加较为严格的假设,如平稳性、自变量不相关性等,这些假设往往与现实情况相悖。
随着研究的不断深入,鉴于集装箱吞吐量的非平稳性、非线性和复杂性[9],神经网络模型通过在线调整权值和阈值等方法可以将任意非线性函数逼近到预期的精度,并捕捉数据中固有的复杂、动态和非线性特征,实验结果表明,基于神经网络的人工智能模型通常比计量经济模型具有更高的预测精度。神经网络算法中最著名的是反向传播(Back Propagation,BP)神经网络[10],其衍生的算法有:广义回归神经网络(Generalized Regression Neural Network,GRNN)、径向基函数(Radial Basis Function,RBF)[11]和支持向量机(Support Vector Machine,SVM)[12]等。人工智能模型利用历史数据模式中的相关空间和时间特征,通过模拟人类智力或自然现象设计输入与输出变量的规则关系[13]。由于这些人工智能技术可以在不知道问题解决方案的前提下近似任何复杂水平,因此它们被广泛应用于港口吞吐量预测[14],如Xie 等[15]基于最小二乘支持向量回归(Least Squares Support Vector Regression,LSSVR)模型对集装箱吞吐量进行预测;Geng 等[16]利用鲁棒支持向量回归(Robust Support Vector Regression,RSVR)预测港口吞吐量。但人工智能模型并不是十全十美的,人工智能模型参数的训练需要足够的样本量[17];另外,参数敏感性较高,容易在学习的过程中陷入局部最优和存在过拟合现象。
大多数的集装箱吞吐量预测模型都有各自的优点和缺点,没有一种预测模型总能得到预期的预测结果。综上,传统计量经济模型与人工智能模型都存在各自的数据针对性与优劣势,而分解集成模型可以通过提取不同个体模型的优点来提高预测精度。目前,基于“分而治之”思想提出的分解集成模型取得了巨大的进步,由于它精确的预测结果,分解集成模型被广泛应用于许多领域的预测问题,如风速预测[18]、空气污染预测[19]和货运量预测[20]等。
在预测之前,许多研究者一直利用不同的数据预处理技术处理数据序列中存在的波动性和噪声。比较常见的分解技术有:经验模态分解(Empirical Mode Decomposition,EMD)、集成经验模态分解(Ensemble EMD,EEMD)、互补集成经验模态分解(Complementary EEMD,CEEMD)、经验小波变换(Empirical Wavelet Transform,EWT)等。近年,Dragomiretskiy 等[21]提出了一个创新的分解方法变分模态分解(Variational Mode Decomposition,VMD),与其他分解技术相比,VMD 不仅可以分离出相似频率的特征,而且具有优越的去噪性能。然而,预设的超参数比如分解模态个数K,在没有先验知识的情况下较难确定,。本文利用循环法寻找最优K值,提出一种更加具有实际应用价值的分解技术优化的VMD。
在预测的方法中,基于一类前馈神经网络的机器学习算法极限学习机(Extreme Learning Machine,ELM),Huang 等[22]提出了核极限学习机(Kernel ELM,KELM)算法,KELM 将核函数引入了ELM 中代替隐含层映射,提高了ELM 的泛化能力。使用KELM 算法的研究不多,在集装箱吞吐量预测中的应用也很少。
目前已有研究将分解集成模型应用到集装箱吞吐量预测领域。如:文献[23]建立了VMD-SVR(Variational Mode Decomposition-Support Vector Regression)分解集成模型,文献[24]建立了VMD-ELM(Variational Mode Decomposition-Extreme Learning Machine)分解集成模型,文献[25]提出了CEEMD-ELM(Complementary Empirical Mode Decomposition Ensemble-Extreme Learning Machine)的分解集成预测模型。由于各个模型之间有效的组合还需大量研究验证,所以进一步提高混合预测模型的性能不可或缺。
本文借助分解集成思想提出一种创新的集装箱吞吐量混合短期预测方法,主要包括四步:
1)分解。用汉佩尔辨识法(Hampel Identifier,HI)方法对数据进行预处理,剔除异常数据后用分解效率较高的优化变分模态分解(Optimal VMD,OVMD)技术将集装箱吞吐量信号分解成一系列相对平稳的分量。
2)分类。计算出各个分量的样本熵(Sample Entropy,SE)值,根据样本熵的大小将各分量分为高频低幅、中频中幅和低频高幅信号。
3)建模预测。用相空间重构方法优化模态分量,计算出预测维数,并根据不同种类模态分量的特点单独建立核极限学习机预测模型,即选用不同的核函数进行预测。
4)集成。累加所有模型的预测值,完成对集装箱吞吐量时间序列的预测。
最后将本文模型分别与传统模型和采用其他模态分解方法的模型对比,并结合预测误差进行分析,检验本文模型的准确性。
1 理论基础
1.1 离群点处理
离群点是指数据中远离数值一般水平的极大值和或极小值,也称之为奇异值或野值,不论是何种原因引起的离群点对之后的时间序列分析都会造成一定的影响[26]。
本文采用HI 对原始集装箱吞吐量序列训练集进行预处理。HI 被认为是最有效和鲁棒性较好的离群点校正方法之一,能识别与校正正常数据序列中的异常值,降低原始序列的复杂度,过滤数据系列的异常信息。HI 的具体过程可以描述如下:
设定集装箱吞吐量序列为X=X1,X2,…,XN;评估参数为默认值θ=0.674 5;根据3δ统计规律,本文的阈值TR设置为3。如果样本Xi(i=1,2,…,N)满足条件Z′ >TR,样本Xi被视为第i个异常值,用数mi代替。
在滑动窗口中,局部子序列的中值计算公式为:
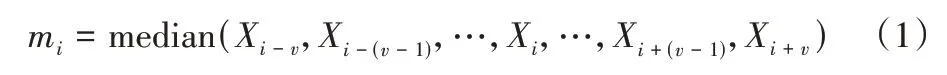
其中:Xi是输入数据的第i个样本;v是最优滑动窗口个数。滑动窗口内局部子序列的平均绝对偏差(Mean Absolute Deviation,MAD)定义为:
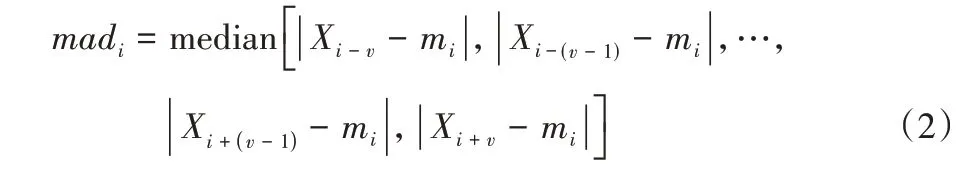
Z′的值可以定义为:
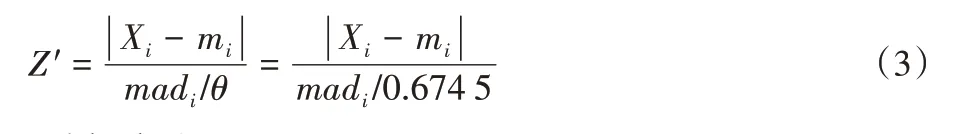
1.2 分解方法
1.2.1 变分模态分解
变分模态分解(VMD)是一种信号处理方法,它能自适应地确定信号的带宽和频率,同时估计相应的模态,适当地平衡模态之间的误差。VMD 主要解决变分问题,能有效地处理递归分解方法引起的包络估计误差。解决了EMD 模态混叠和端点效应问题后,可有效提取原始序列不同频率尺度分量的信息[27]。
1)变分问题构造。
VMD 通过分解原信号得到K个模态分量。变分问题的构造即求得所有本征模函数(Intrinsic Mode Function,IMF)rk(t),变分模态分解理论将IMF 定义如下:

其中:mk表示瞬时振幅,也叫包络线;ϕk(t)为递减函数的相位;k=1,2,…,K。根据式(4),rk(t)可以认为是mk和ϕk(t)的纯和谐波信号,振幅和频率的变化相对缓慢;t是时间。
为了计算各模态的带宽,利用希尔伯特变换得到各本征模态分量的解析信号,将得到的每个模态信号的频谱调谐到相应的“基带”,以式(5)来评估模态的带宽:

其中:δ(t)表示单位脉冲函数;j 表示虚数单位;*表示卷积算子;ωk表示第k个模态的中心频率是一个指数项,表示复杂面上的中心频率。
通过计算上述模态宽度的L2 范数,对于原始输入信号ψ,最终可以构造出有约束的变分问题,表示为:
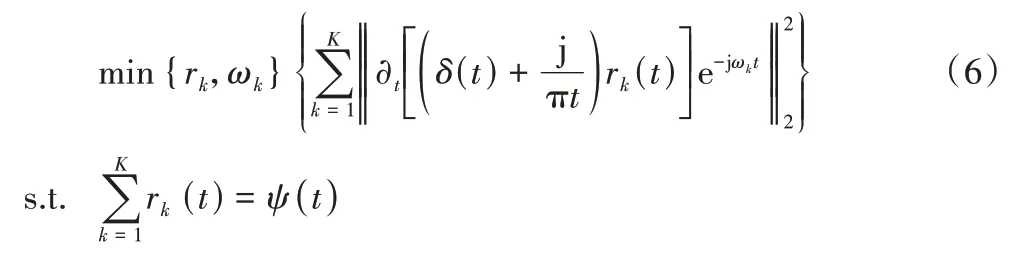
其中:rk表示第k种模态;∂(t)是函数的偏导数;δ(t)代表Dirac 分布。
2)变分模态求解。
①通过引入拉格朗日乘子λ(t)和惩罚参数α得到非约束问题,然后使用乘法算子交替算法来找到非约束问题的最优解。rk(t)和ωk的更新公式如下:
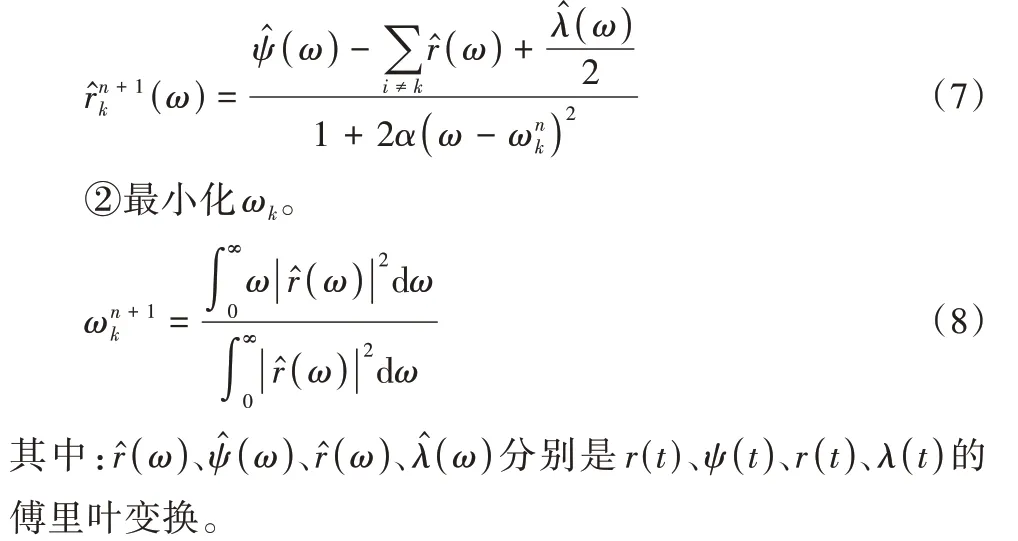
1.2.2 优化的变分模态分解
VMD 可有效抑制信号分解过程模态混叠的问题,能同时提取所有的模态,但VMD 进行信号处理时需自定义模态数K,限制了方法的适应性。如果模态数的预设有较大的偏差,就会导致模态的丢弃或混合。因此,本文主要针对参数K的确定优化研究,提出了优化的VMD 方法对原始集装箱时间序列分解。
图1 给出了获取模态数K的过程,即本文提出的OVMD算法。
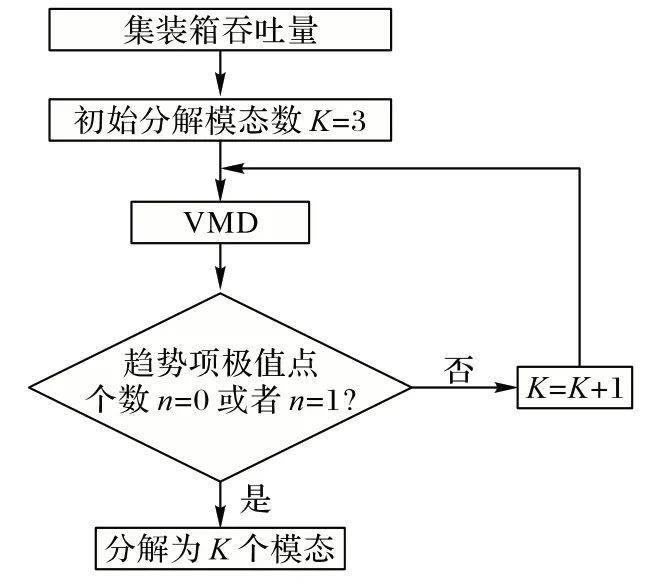
图1 OVMD流程Fig.1 Process of OVMD
详细过程描述如下:
步骤1 设置初始分解模态数K=3。
步骤2 判断第3 个分量是否满足停止标准:极值点的个数为0 或1;否则,模态数增加1。
步骤3 利用OVMD 得到K+1 个本征模函数。
步骤4 判断第K+1 个分量是否满足停止标准;否则,模态数增加1。
步骤5 重复步骤2~4,直到满足停止标准。
停止准则保证第K+1 个模态数的极值点个数仅为1 或第K+1 个分量为单调信号,在OVMD 中,第K+1 个分量表示历史集装箱吞吐量时间序列的趋势。
1.3 样本熵
利用Richman 等[28]提出的样本熵(SE)评价数据序列的复杂性。SE 的优点包括两个方面:一方面,它的计算结果并不依赖于原始数据的长度;另一方面,原始数据的丢失对SE的计算影响不大,即使丢失了原有数据的1/3,也不会对计算产生很大影响。SE 值计算过程涉及三个基本参数:1)相似容限r,选择原始数据标准差的10%~25%,本文设为0.2STD,其中STD为序列的标准差;2)嵌入维数m,一般选择1 或者2,实际使用中学者都优先选择m=2;3)时间序列的大小N。
实现SE 值的具体步骤如下所示:

序列的非平稳度取决于它们的SE 值:SE 值越大,序列的复杂度越高;反之SE 值越小,序列的复杂度越低。
1.4 相空间重构
采用相空间重构(Phase Space Reconstruction,PSR)法优化模态分量序列后再输入模型进行预测,能促进预测模型对原始数据的充分学习,改善预测效果[29]。
对于给定时间序列X=X1,X2,…,XN,定义嵌入维数m以及延迟时间τ,将时间序列拓展成m维的相空间:


图2 相点与元素的映射关系Fig.2 Mapping relation between phase points and elements
关于嵌入维数m及延迟时间τ用网格搜索法确定。网格搜索法是指定参数值的一种穷举搜索方法,即手动给模型中的这两个参数赋值后由程序自动使用穷举法都运行一遍,通过交叉验证的方法选择最优的一组m和τ。
1.5 KELM算法
极限学习机(ELM)是一种有效的单隐含层前馈神经网络(Single-hidden Layer Feedforward Neural Network,SLFNN)。该算法一次更新权值和偏差,取代了传统算法中的权值和偏差,因此在学习速度上有很大的优势,被广泛应用于许多领域。ELM 的拓扑结构如图3 所示。
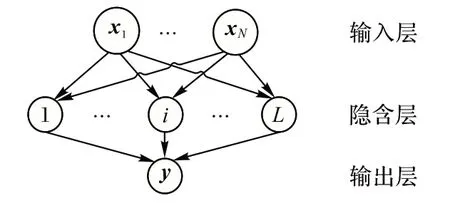
图3 ELM的拓扑结构Fig.3 Topological structure of ELM
ELM 的基本原理是隐含层节点的参数可以随机分配,输出层的权值用隐含层输出矩阵的一个简单的广义逆运算表示。对于训练集(xi,yi),xi,yi∈Ri{i=1,2,…,N},ELM 表示如下:

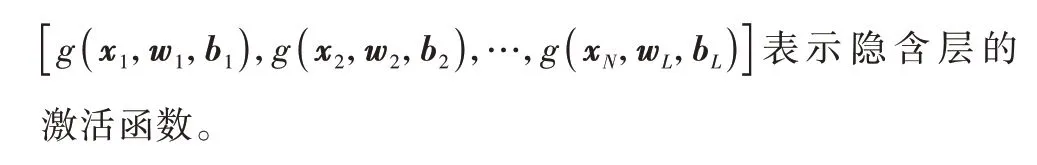
当ELM 的输出结果能够以零误差逼近观测数据时,利用矩阵表达可以写成式(17)的形式:

其中:Η为隐含层输出矩阵。
为了增强模型的稳定性,和提高其泛化能力,在对β的求解中,引入一个正数C,并以最小训练误差ei和最小输出权值的范数为求解目标,优化模型可以写成:
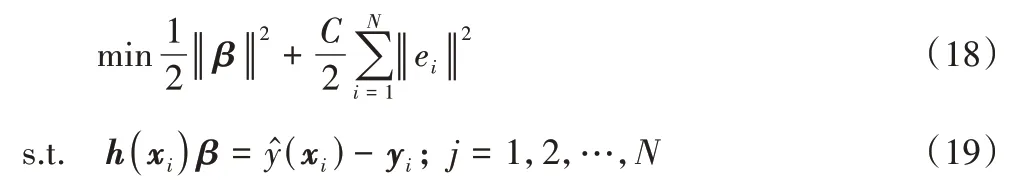
其中:C为正则化系数;h(xi)为隐含层特征映射函数。
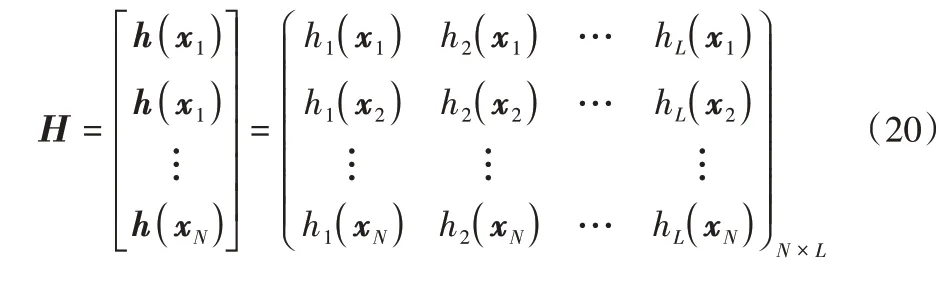
对于训练样本较大的情况,例如N≫L,可以得到:

极限学习机的输出函数为:
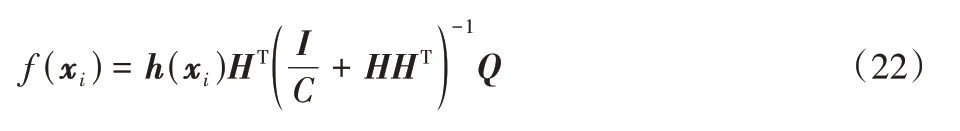
核函数具有很强的非线性映射能力,线性不可分问题通过核函数映射到高维空间,从而使它们线性可分。参考核函数的内积理论,直接采用核函数代替ELM 隐含层节点的映射。
本文提出了一种基于核函数的极限学习机-核极限学习机(KELM),如果功能映射函数h(xi)隐含层的神经元是未知的,内核矩阵可以被定义为:
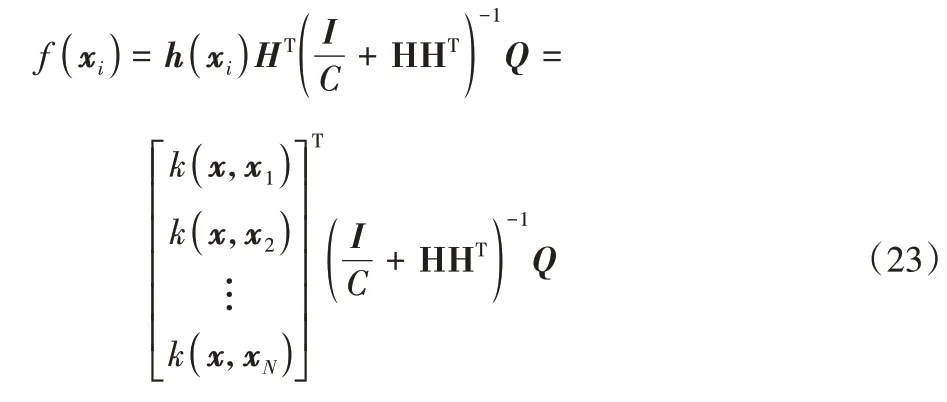
在通过核函数实现ELM 的过程中:HHT为核矩阵;k(xi,xj)为相应的内核函数;I表示单位矩阵;Q表示期望输出。上述情况表明,核函数可以代替ELM 的随机映射,使输出权值比以前更加稳定。根据核函数的学习能力和时间序列的特点选择相应的核函数,KELM 算法中常用的核函数有以下几种。
1)线性核函数:

2)高斯核函数:
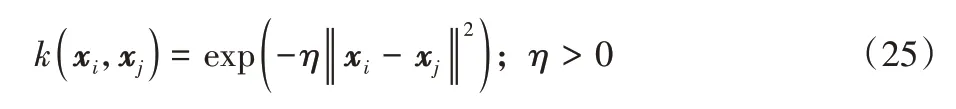
3)小波核函数:

2 集装箱吞吐量预测模型
集装箱吞吐量时间序列是非线性、非平稳信号,对集装箱吞吐量时序的本质进行处理是预测的关键。设计基于分解-分类-重构思想的集装箱吞吐量预测框架,如图4 所示。
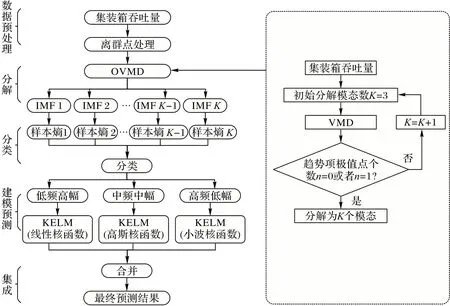
图4 本文集装箱吞吐量预测模型的框架Fig.4 Framework of the proposed container throughput prediction model
首先采用优化的变分模态分解(OVMD)对原始负荷序列进行分解。将分解得到的各固有模态函数(Intrinsic Mode Function,IMF)经样本熵(SE)计算后,将各个分量进行分类,根据分量特点设计多组核函数不同的KELM 预测模型,最后叠加各IMF 的预测结果,得到最终预测结果。
集装箱吞吐量预测步骤如下:
步骤1 数据准备。将集装箱吞吐量数据集分为训练集和测试集,利用训练数据建立预测方法,并利用测试集的数据对所建立的方法进行评估。
步骤2 采用HI 异常值检测与校正方法对训练集的异常值进行校正,校正后的训练集和测试集作为以下步骤的输入序列。
步骤3 OVMD。将VMD 应用到数据预处理过程中,模式的数量会显著影响预测结果:一方面,极有可能只有太少的模式不能充分提取出隐藏在原始序列中的特征信息;另一方面,由于误差累积的影响,过多的分量可能会产生较差的预测结果,即每个模型的预测误差会在最后的集成步骤中累积。本文用OVMD 对模态数进行循环寻优处理,设置初始模态数,依次增加模态数,直到满足趋势项极值点个数为0 或1时,跳出循环,结束操作。
步骤4 采用SE 方法对分解结果进行测试,SE 值越大,表明信号的复杂度越高;相反地,较低的SE 值说明了信号的复杂度越低。以SE 值的大小将时间序列分为3 种:高频低幅、中频中幅和低频高幅。
步骤5 用相空间重构法计算出预测模型的预测步长。
步骤6 基于多核学习思想,KELM 结合ELM 和SVM 的优点,并引入了核函数,因此核函数类型及核函数参数的选择也影响KELM 的性能。KELM 一般采用线性核函数、高斯核函数以及小波核函数,根据不同的序列特点选择不同的核函数建立多组KELM 预测模型。
步骤7 将所有分量预测结果叠加得到最终的集装箱吞吐量预测值。
选择KELM 算法作为数据预测模型的原因是:
1)KELM 算法会随机生成输入层和隐含层之间的连接权值,以及隐含层神经元的阈值,在训练过程中不需要调整;
2)通过设置隐含层神经元数量,得到唯一最优解;
3)KELM 算法具有运算速度快、泛化能力强、克服过拟合困难等优点。
3 实例分析
以深圳港的集装箱吞吐量历史数据作为实证研究对象建立集装箱吞吐量短期预测模型。
3.1 数据来源与分析
3.1.1 数据来源
本文使用的数据来自Wind 数据库(http://www.wind.com.cn),数据集时间范围为2001 年1 月至2019 年12 月。将数据分为两个集合:训练集数据和测试集数据。训练集数据用于确定神经网络的权值和阈值,训练集数据涵盖的时间段为2001 年1 月至2016 年2 月;测试集数据用于判断所建立模型的性能,数据时间段为2016 年3 月至2019 年12 月。
3.1.2 数据分析
1)集装箱吞吐量的非线性。
如图5 所示,深圳港的月度集装箱吞吐量整体呈现曲折上升趋势。在所选区间内,每年2 月港口集装箱吞吐量明显下降,是由于处于北半球的深圳港2 月仍在冬季,有海面结冰等不利海运的情况发生;且该时段常为我国农历新年,进出口贸易量受节假日影响较大,呈现非线性的特点。
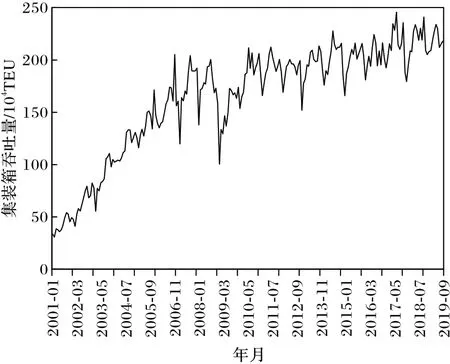
图5 深圳港月度集装箱吞吐量Fig.5 Monthly container throughput at Shenzhen Port
2)集装箱吞吐量的非平稳性。
时间序列的平稳性指其统计变量在一定时期内保持稳定,不受时间变化的影响。本文通过计算时间序列的自相关系数(AutoCorrelation Function,ACF)值对吞吐量时间序列进行非平稳性验证。
如图6 所示,深圳港集装箱吞吐量的ACF 分析显示,原始月度时间序列的ACF 数值具有拖尾性,在第76 个数据时才趋于零,说明了样本数据是非平稳时间序列。
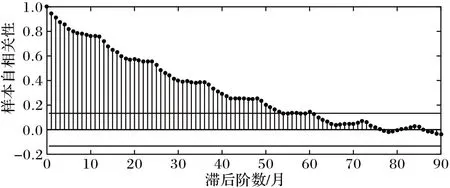
图6 集装箱吞吐量月度时间序列的ACF分析Fig.6 ACF analysis of monthly time series of container throughput
3)集装箱吞吐量的复杂性。
通过本文1.3 节介绍的样本熵(SE)方法评价数据序列的复杂性。根据SE 方法求得本文原始时间序列的样本熵值为0.774 5,说明样本数据是复杂时间序列。
综合来说,港口集装箱吞吐量变化复杂,影响因素多,呈现非线性、非平稳性和复杂性的特点,难以直接分析预测。
3.2 性能评价指标
对预测性能的评价有多种误差测量标准。然而,相关研究表明,并没有一个通用的标准公式来评价预测模型的有效性。因此,采用以下4 个常用指标从不同的角度评估效用,平均绝对误差(Mean Absolute Error,MAE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Square Error,RMSE)和决定系数(R2)检验。
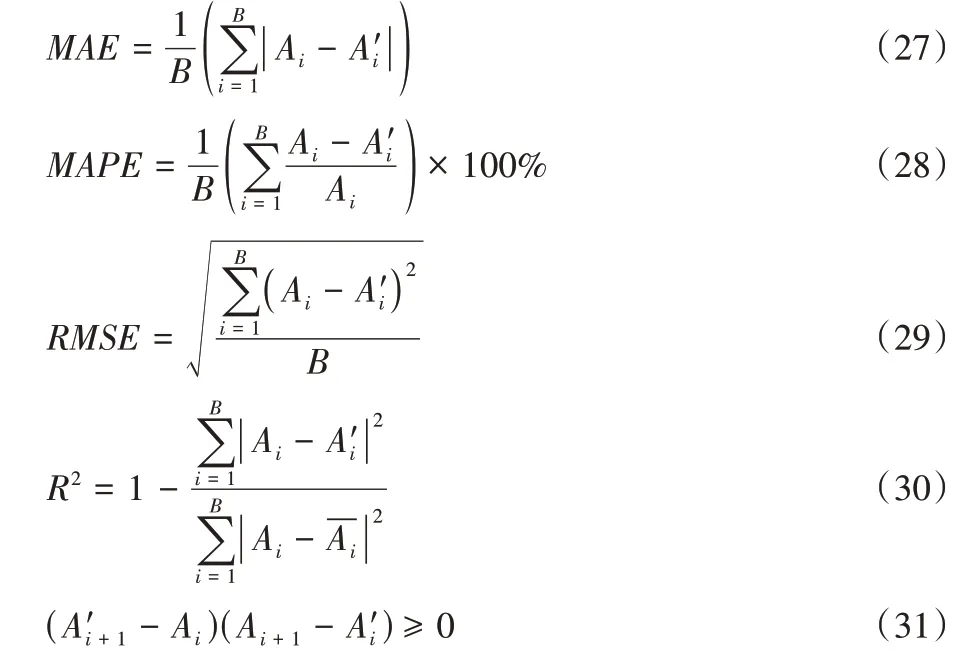
其中:Ai和分别为第i(i=1,2,…,B)周期时间序列的实际值和预测值;为实际的平均值;B为测试样本集个数。
MAPE、MAE 和RMSE 是用来衡量预测值与实际值之间的偏差的,它们的值越小,预测效果越好;R2的值越接近1,预测值和真实值的相似度越高。
3.3 分解-分类-集成-预测过程
3.3.1 基于OVMD的集装箱吞吐量分解
1)离群点处理。
首先本文采用HI 数据处理方法对原始月度集装箱吞吐量时间序列进行预处理的目的是通过去除离群值降低原始序列的复杂度,以提高序列的鲁棒性和稳定性。数据选用深圳港2001 年1 月至2019 年12 月的月度港口集装箱吞吐量,预处理结果如图7 所示。
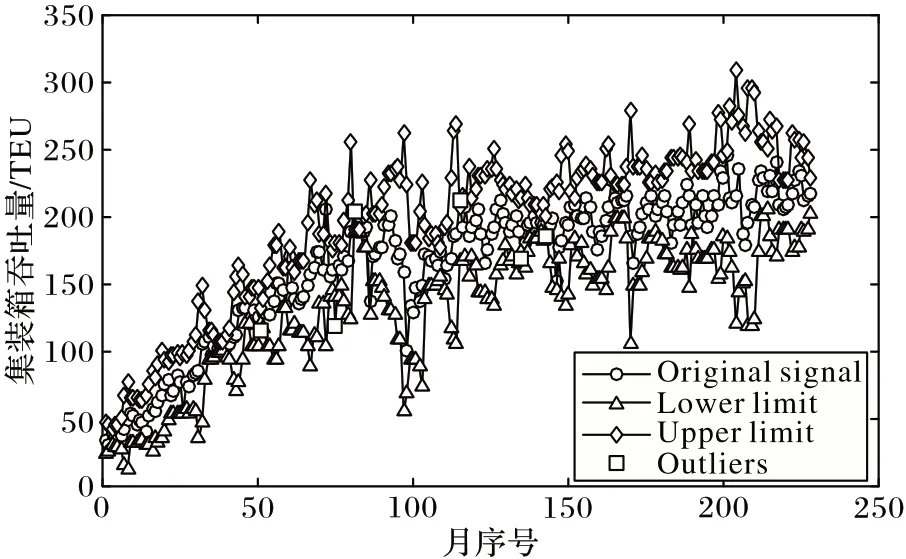
图7 HI离群点处理结果Fig.7 HI outlier processing results
2)OVMD。
时间序列预测依赖于时间序列的平稳性,需要对集装箱吞吐量时间序列进行适当的分解,以获得平稳的时间序列分量。利用OVMD 对深圳港2001 年1 月至2019 年12 月的原始月度集装箱吞吐量时间序列进行分解,结果如图8 所示。
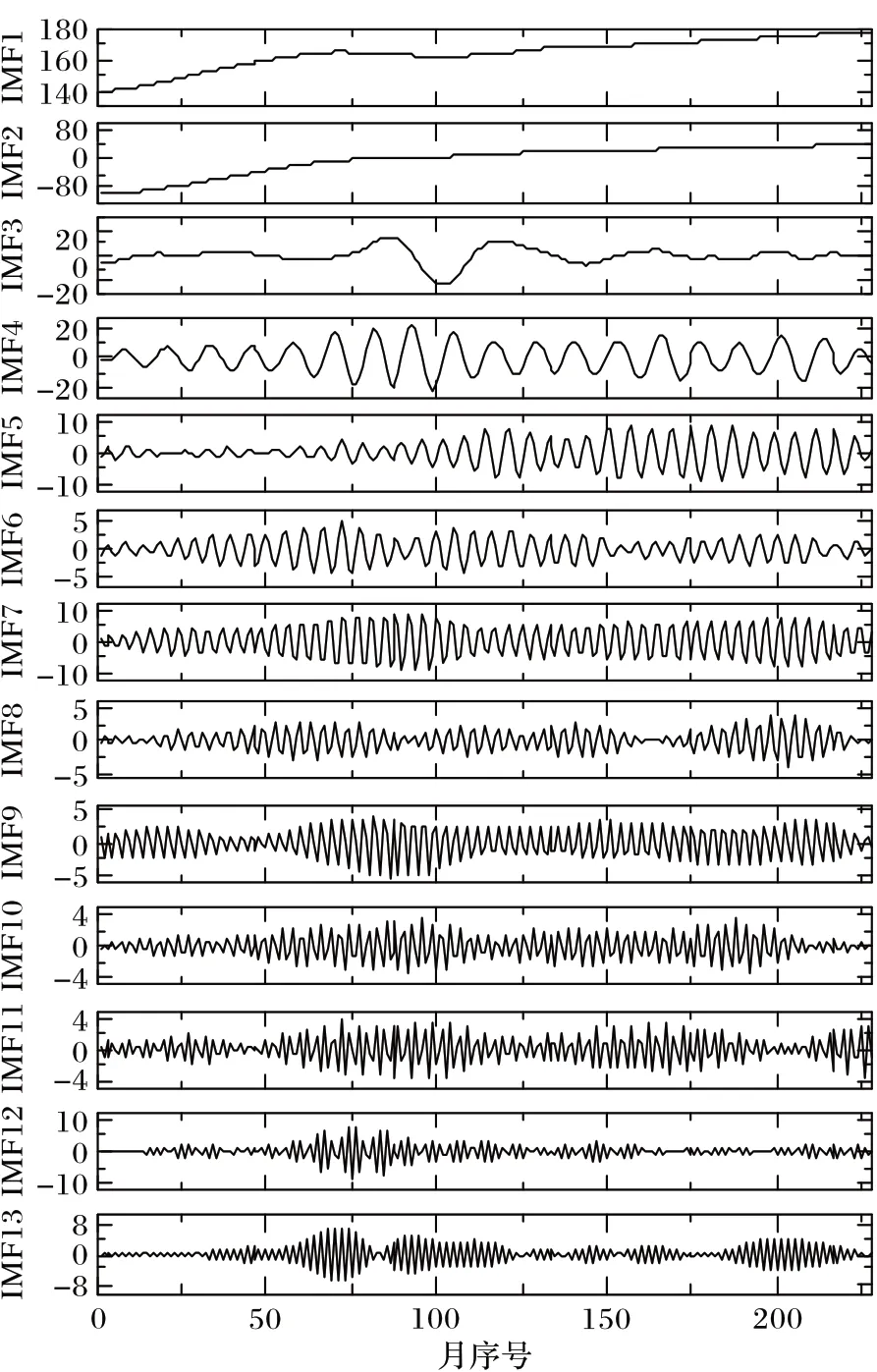
图8 OVMD结果Fig.8 OVMD results
用OVMD 优化模态函数个数K以充分提取原始序列的特征,子序列中心频率相近时判定为过分解,得到K=13 时分解效果最好。其余参数设置为初始参数,带宽σ、中心频率ω和带宽约束强度τ的初始参数分别为2 000、0 和0。
3.3.2 基于幅频特性的本征模函数的分类
振幅和频率是时间序列的基本参数。分解的高频和低频分量分别包含噪声项和趋势项。高振幅的低频分量代表了这些分量的趋势,而低振幅的高频分量表示包含噪声的细节。因此,这些模态函数分为3 类。
1)使用SE 方法对OVMD 得到的每个IMF 序列进行熵值计算,结果如表1 所示。
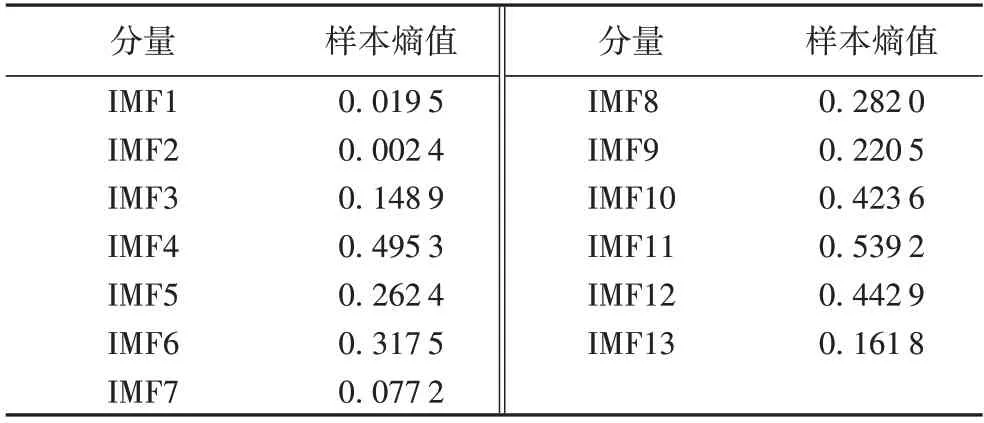
表1 各IMF的样本熵值Tab.1 Sample entropy values of IMFs
2)根据SE 值的大小将IMF 序列分为三类:第一类包含低频的高振幅分量IMF1、IMF2、IMF7;第二类由中频的中振幅分量IMF3、IMF5、IMF8、IMF9、IMF13 组成;第三类包括高频低振幅分量IMF4、IMF6、IMF10、IMF11、IMF12。
3.3.3 不同类别的时间序列预测模型
本节为不同分量建立不同的时间序列预测模型。
1)为提出的模型选择最优的输入步长,即确定p值大小。
本文对整个时间序列通过相空间重构法计算出的最佳输入步长为2,预测时对每个分量单独进行预测,所有分量的预测步长均为2。用前两个月的数据作为输入预测第三个月的集装箱吞吐量,序列预测函数关系如式(32)所示:
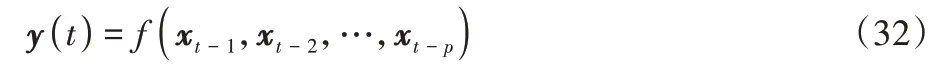
其中:xt表示历史集装箱吞吐量;p是最佳输入个数;f(x)由KELM 算法构建函数关系;y(t)为t时刻预测值。
2)选择不同核函数。
大量的核函数被应用于KELM 算法。这些具有不同性质的核函数被分为全局核和局部核。高频时间序列要求具有良好局部学习能力的局部核函数;相反地,低频时间序列需要具有良好全局学习能力的全局核函数。由于不同类型的模态函数具有不同的数据特征,根据时间序列的特征选择相应的核函数,可以提高模型的预测能力。KELM 算法主要有以下3 种核函数:线性核、高斯核和小波核函数。这3 种核函数具有不同的学习能力。
本文将13 个IMF 分量分别用KELM 算法的3 种核函数同时做3 组不同的预测,然后在3 组实验结果中选择预测误差最小的核函数作为该IMF 相应的匹配核函数。为了直观地看出不同核函数对测试集不同IMF 的预测效果,本文仅取训练集的后46 个样本(2012 年3 月至2015 年12 月的月度集装箱吞吐量真实值)和测试集的前46 个样本(2016 年1 月至2019 年10 月的月度集装箱吞吐量预测值)进行绘图,如图9所示。
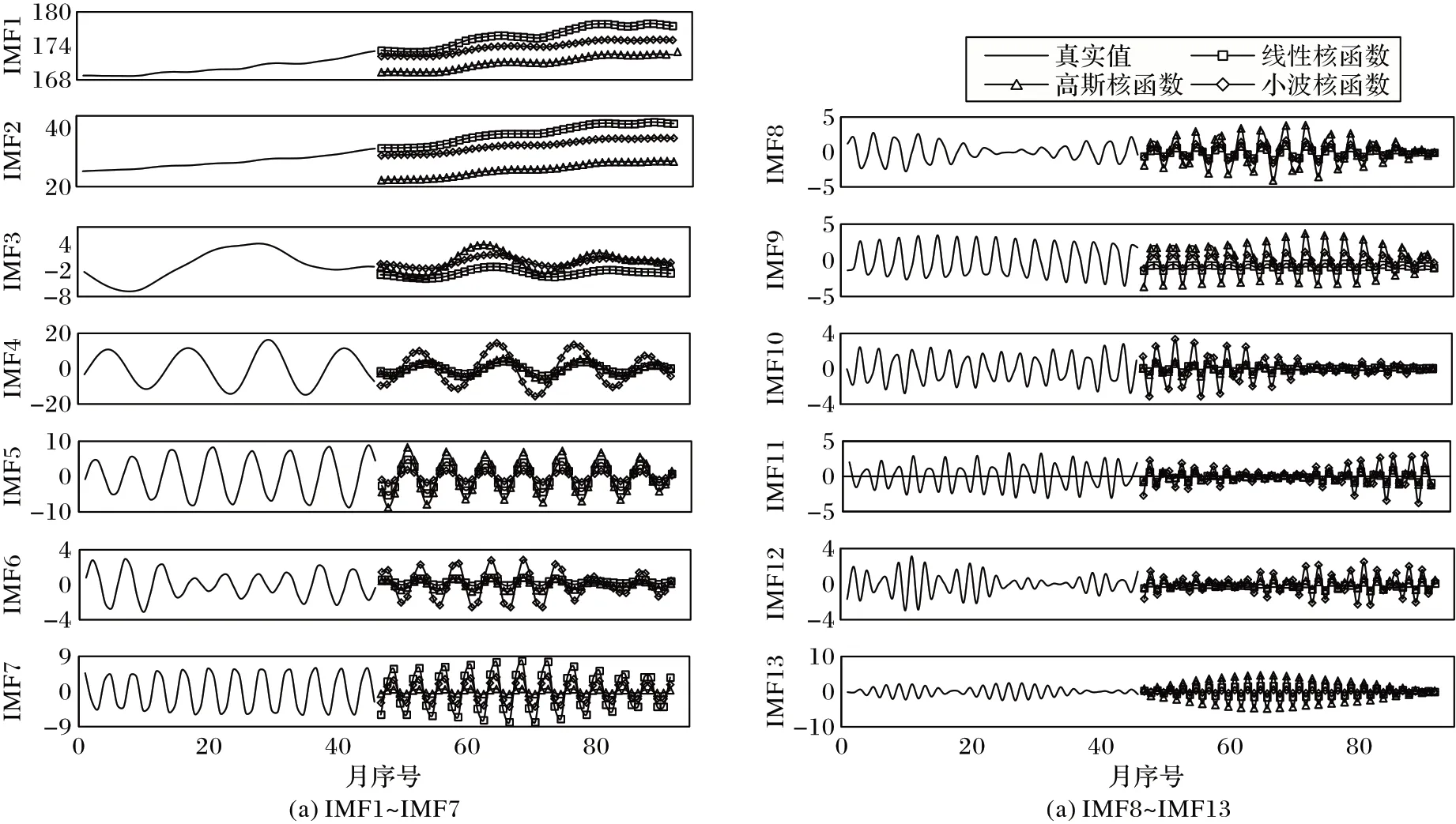
图9 不同核函数预测对比Fig.9 Prediction comparison of different kernel functions
从图9 可获得以下结论:对于IMF1、IMF2 和IMF7,KELM 的线性核函数的预测结果相较于高斯和小波核函数的预测结果更加接近验证集;对于IMF3、IMF5、IMF8、IMF9和IMF13,KELM 的高斯核函数的预测结果更加接近验证集;对于IMF4、IMF6、IMF10、IMF11 和IMF12 选择小波核函数构建预测模型效果更佳。本文根据核函数的学习能力和时间序列的特点,确定低频高幅、中频中幅和高频低幅分别采用线性核、高斯核和小波核函数预测。
3.3.4 集成
最后,对预测模型的输出进行集成。将每个IMF 通过KELM 预测算法得到的各个分量预测值线性相加,得出最终的模型预测结果,如图10 所示。将本文提出的模型和其他对比模型的预测结果与深圳港的实际历史月度集装箱吞吐量数据进行对比,判断本文模型是否能够很好拟合深圳港集装箱吞吐量走势。
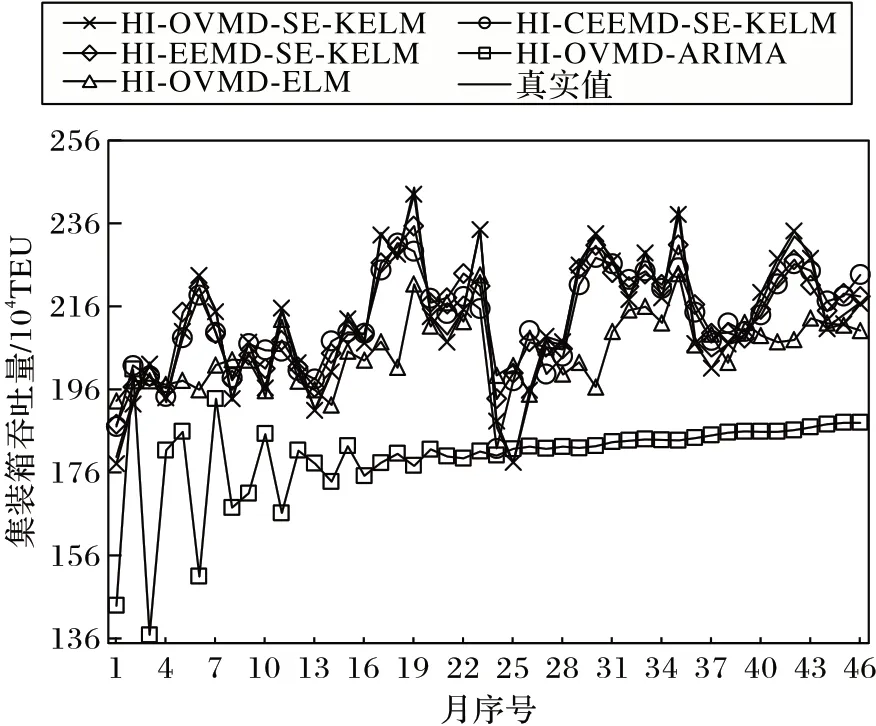
图10 本文模型和其他模型的预测曲线对比Fig.10 Prediction curves comparison of the proposed model and other models
4 结果分析
将本文模型HI-OVMD-SE-KELM 与4 种对比模型HICEEMD-SE-KELM、HI-EEMD-SE-KELM、HI-OVMD-ARIMA、HI-OVMD-ELM 模型作对比实验,结果如表2 和图11 所示。

表2 不同模型的性能评价指标Tab.2 Performance evaluation indicators of different models
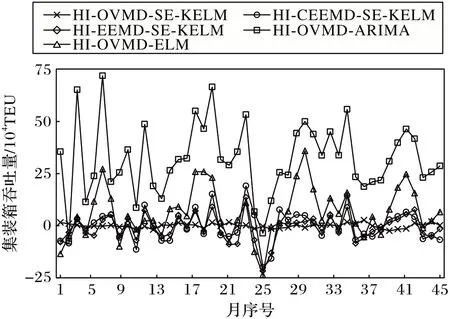
图11 不同模型的预测误差曲线Fig.11 Prediction error curves of different models
由表2 和图10~11 可以得出以下结论:
1)通过图10 可以看出,本文提出的HI-OVMD-SE-KELM模型相较于对比模型更接近实际数据,整体预测曲线的拟合程度优于其他4 种模型,说明本文模型具有更高的拟合精度;
2)与EEMD 和CEEMD 方法相比,采用OVMD 作为数据预处理方法,可以有效提取出隐藏在原始集装箱吞吐量序列中的不同波动特征,预测精度有明显的提高;
3)相较于ARIMA 预测算法,KELM 算法具有学习速度快、泛化能力强等优点,有利于非线性序列的预测;
4)通过KELM 和ELM 的比较可以清楚地看到,所开发的方法比基于ELM 的方法获得了更高的精度,说明不同核函数的加入也降低了KELM 组合预测中产生的误差,核函数在生成最优KELM 中起着重要作用。
5 结语
针对集装箱吞吐量复杂性、非线性和非平稳性的特点,本文提出一种基于HI-OVMD-SE-KELM 的混合预测模型。采用HI 预处理数据后,选择OVMD 方法将时间序列分解后用KELM 预测方法进行评估。在结果分析部分,对每个模型的预测结果用常见的测量评估标准进行了测验。结果表明OVMD 模型在一定程度上优于传统的CEEMD 模型和EEMD模型,VMD 模型能显著降低原始序列的复杂性,充分提取集装箱吞吐量数据中的特征信息,适用于复杂性、非线性和非平稳时间序列。对OVMD 结果分类后选择不同核函数的KELM 方法预测和单一预测模型相比更能预测所有的分解组件。通过4 种对比模型和本文模型在MAE、MAPE、R2和RMSE 4 种指标下的对比,证明了本文模型具有更好的预测性能。
当前各类预测研究中,有诸多优秀的算法和模型,本文选择的仅仅是其中一种组合模型,仍可通过选取和建立更合适的混合预测模型提高预测的准确性,因此,构建更优的混合模型也是未来的研究方向之一。
