基于射线驱动的Siddon正投影算法并行计算研究
2022-08-22陈云斌刘清华李寿涛
陈云斌,刘清华,李寿涛,王 远
(1.中国工程物理研究院 应用电子学研究所,绵阳621900;2.国家X射线数字化成像仪器中心,绵阳 621000)
0 引言
计算机断层扫描成像(Computed Tomography,CT)的实际执行过程分为正投影和反投影两大步骤。正投影指计算给定函数沿指定射线方向的线积分过程。反投影指由投影数据进行图像重建,获取切片体数据。
迭代重建算法是CT重建算法的重要分支,多用于有限角、稀疏投影重建,包括SART[1](Simultaneous Algebraic Reconstruction Techniques)、EM[2](Expectation Maximization)和TV[3](Total Variation)等算法。迭代重建算法重复了CT成像的两大步骤,即正投影和反投影。与实际物理成像的区别在于,迭代重建算法的正投影步骤是在数字图像域,沿指定路径对图像矩阵的像素灰度值进行线积分。
计算机模拟仿真是CT成像研究的重要技术手段,广泛用于重建算法验证、扫描成像参数验证和物理现象的跟踪分析等领域。计算机模拟仿真方法大致分为两类:统计仿真方法和解析仿真方法。统计仿真方法的典型例子就是蒙特卡罗方法。解析仿真方法借助生成的数字模体,通过解析公式计算相关参量,其中典型的例子就是给定数字模体的图像矩阵,通过正投影算法模拟生成投影数据。
综上所述,正投影算法和计算策略是迭代重建算法和计算机模拟仿真的关键技术手段,在CT成像研究领域具有重要作用。
1 正投影算法概述
常见的正投影算法大体包括如下几类,即Siddon算法[4]、Joseph算法[5]和等距采样法[6],下面逐一进行简要介绍。
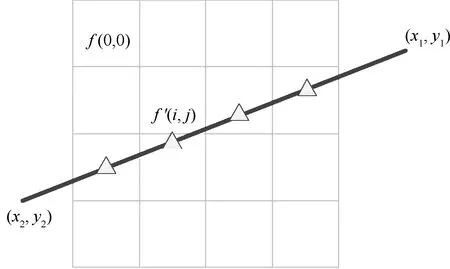
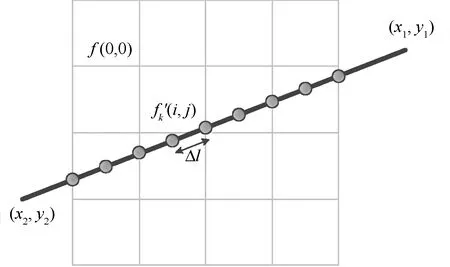
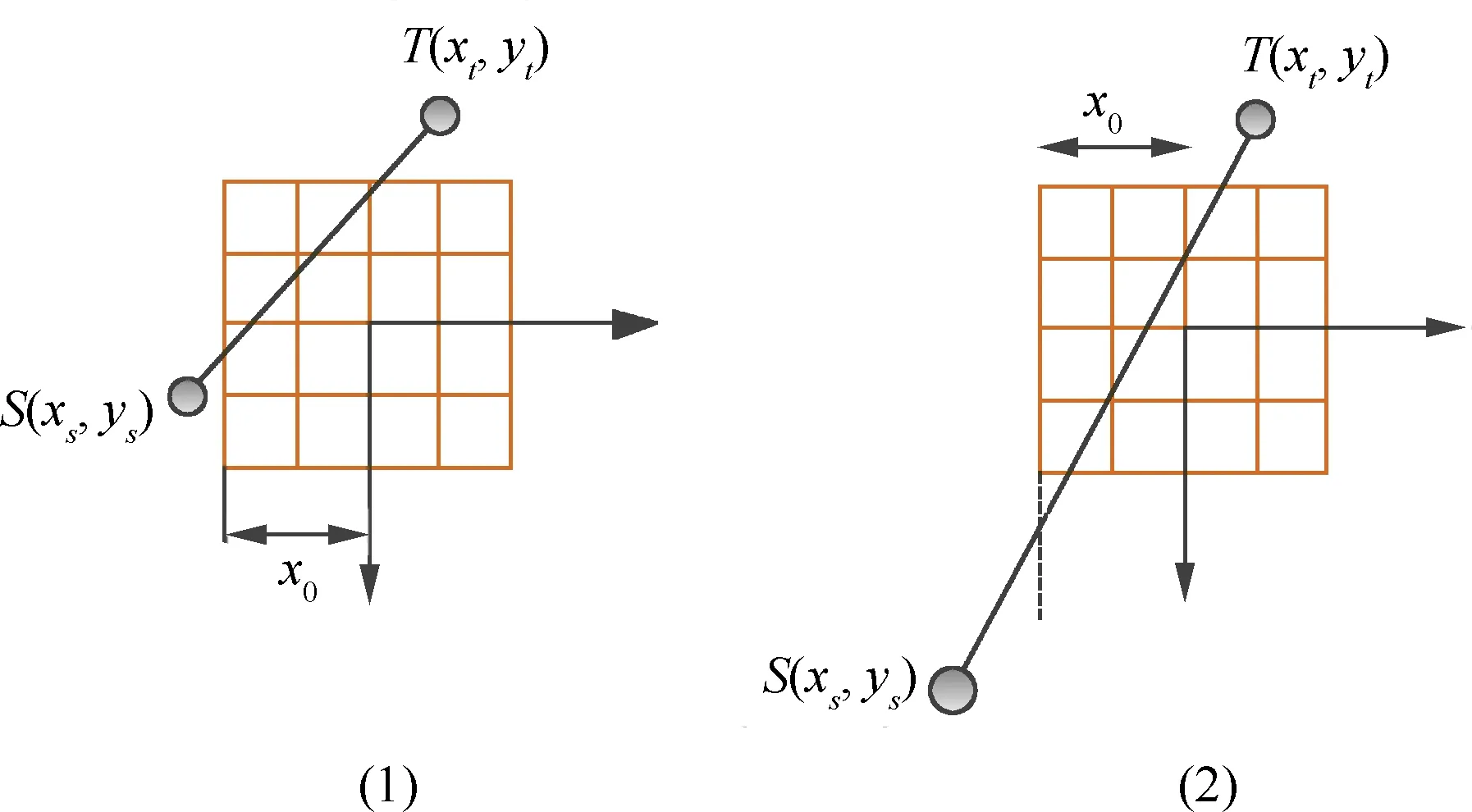
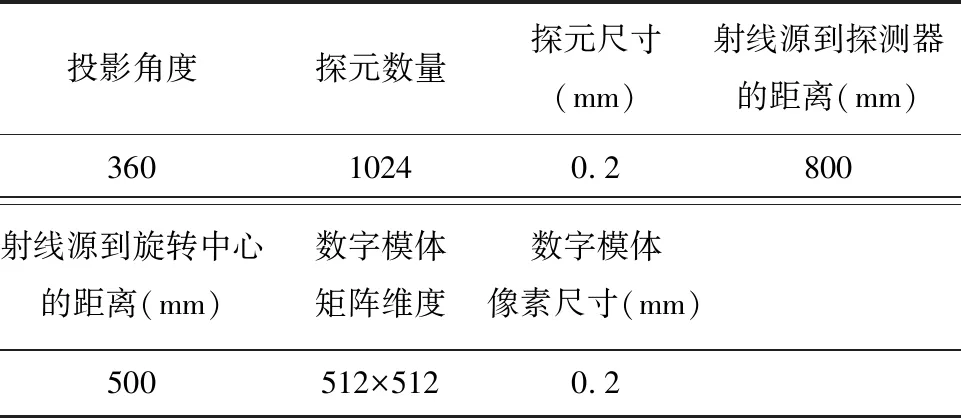
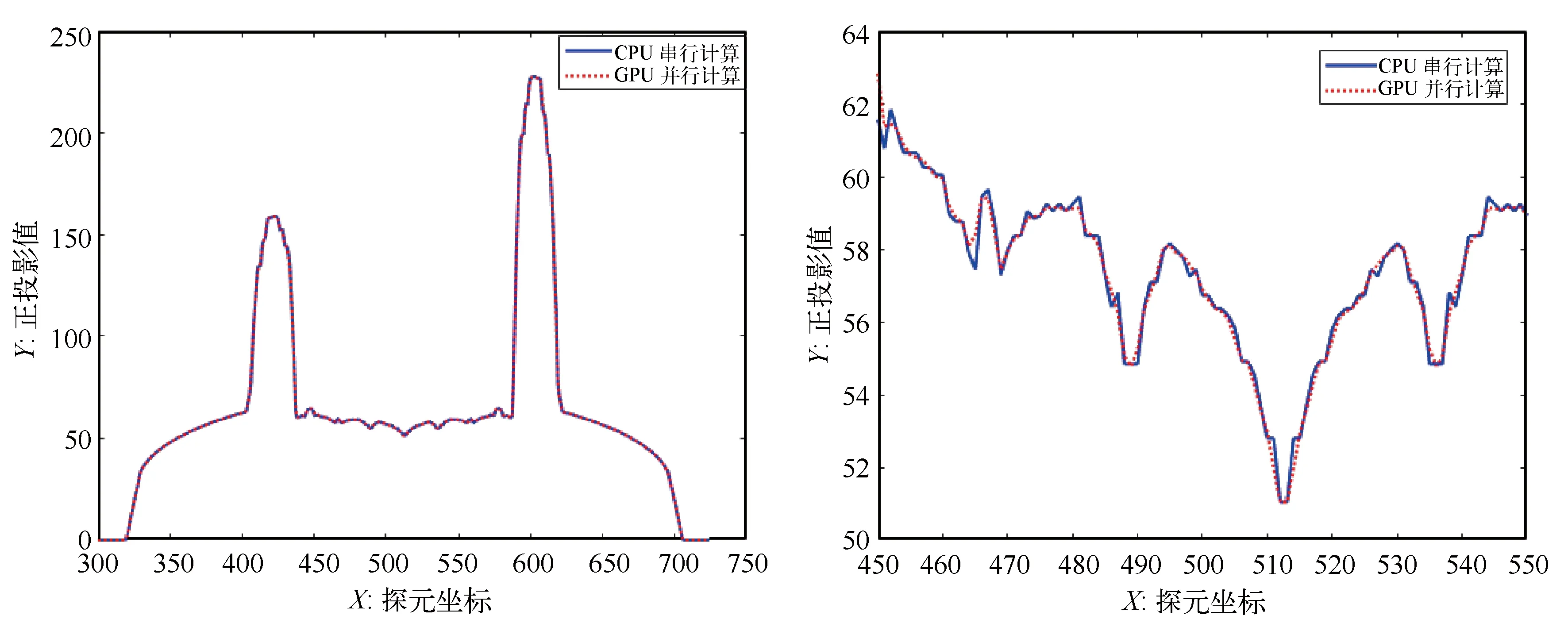
Siddon算法的核心思想是计算射线L与单位像素f(i,j),0≤i 图5-1 Siddon正投影算法示意图 (1) Joseph算法的核心思想是通过射线的端点坐标(x1,y1)、(x2,y2),并比较分量|x1-x2|、|y1-y2| 的大小确定该射线的主传播方向。比如,|x1-x2|>|y1-y2|,则X方向为射线的主传播方向。Joseph算法只需计算射线在主传播方向上的采样点,如图2所示。采用Joseph算法得到的正投影值为: 图2 Joseph正投影算法示意图 (2) 式中,f′(i,j)为采样点经过双线性插值得到的像素灰度值。Joseph算法计算量小,但计算精度有所损失。 等距采样法,顾名思义,沿着射线传播方向等间距采样,如图3所示。逐渐累加得到射线穿过整个图像矩阵的正投影值,如式(3)所示。 图3 等距采样法正投影算法示意图 (3) 式中,Δl为采样间距;f′k(i,j)为采样点经过双线性插值得到的像素灰度值。 综上所述,Joseph算法计算量小,但计算精度存在损失。等距采样法计算精度由采样间距决定,采样间距大,能够降低计算量,但计算精度也会下降。根据正投影算法的原理,Siddon算法是一种精确算法,计算量较大。实际应用中,等距采样法和Siddon算法应用广泛,是迭代重建领域主流的正投影技术手段。为了提高Siddon算法的计算效率,本文主要研究基于GPU(Graphics Processing Unit)的Siddon算法并行计算策略。 首先,对扫描物体进行离散化,形成n行n列的图像矩阵,像素灰度为f(i,j),0≤i 图4 Siddon算法原理 (4) 为了便于描述,对图像矩阵中各单位像素的坐标进行离散化,如下式所示: (5) 式中,xi+1-xi=1,yi+1-yi=1。 (6) (7) αstart=max(0,min(αx0,αxn),min(αy0,αyn)) (8) 出射点距射线起点S的距离占据射线总长|ST|的比例因子为αend,有: αend=min(1,max(αx0,αxn),max(αy0,αyn)) (9) (10) αstart≤αxj,αyi≤αend (11) 如图4所示,射线与像素f(0,0)相交的入射点为A,该点为射线与边界直线y=y0的交点,该点距射线起点S的距离占据射线总长|ST|的比例因子为αy0;出射点为B,该点为射线与边界直线x=x1的交点,比例因子为αx1。截距|AB|的实际长度为: |AB|=(αx1-αy0)|ST| (12) 射线经过像素f(0,0)的区间线积分为: pf(0,0)=f(0,0)·(αx1-αy0)·|ST| (13) Siddon算法的计算量较大。对于n×n的图像矩阵,每条射线的正投影值需要计算(n+1)×(n+1)个交点坐标,且需对交点距射线起点的距离占据射线总长的比例因子进行排序计算;如果探元数量为m,投影角度为v,则射线数量为v×m。合计需要计算v×m×(n+1)×(n+1)个交点坐标,进行v×m次排序计算。如果扩展到锥束扫描的情况,射线数量和交点数量还会急剧增加,串行计算策略难以满足实际工程需要。 根据Siddon算法原理,射线与射线之间的正投影计算独立进行,具备并行计算的前提条件。本文基于CUDA架构,将图像矩阵绑定至纹理存储器,每个线程负责一条射线的正投影计算,实现Siddon正投影算法的GPU并行加速运算。 原Siddon算法需要计算射线与各单位像素边界直线的交点,并存储交点距射线起点的距离占据射线总长的比例因子,然后进行排序计算。然而,上述计算策略存在两大缺点,不利于GPU并行计算,具体表现为: (1)由于每个线程对应一条射线的正投影计算,因此正投影计算所需的比例因子{αxj,αyi}作为私有变量需要由每个线程开辟存储空间进行独立维护。一般情况下,线程私有变量会被分配到延迟访问极低的寄存器中。但是,比例因子{αxj,αyi}数据量大,寄存器空间不足,最终会被分配到延迟访问较高的显存中。例如,图像矩阵为1024×1024,单条射线维护的交点数量为1025×1025,需要的存储空间为1 M。若同时计算的射线数量为1024,则需要的存储空间为1 G。因此,原Siddon算法在进行并行计算时需耗费大量的存储空间。 (2)每个线程需要对比例因子{αxj,αyi}进行排序计算,增加额外的计算量。 基于上述原因,本文对Siddon算法进行计算策略优化,使其利于GPU并行计算,提高算法执行效率。 ①考查边界直线x=x0,该边界线与射线的交点坐标为: (14) 如果x0≤x≤xn且y0≤y≤yn,则该交点作为射线穿过图像矩阵的入射点,如图5(1)。否则,继续寻找入射点,如图5(2)。 图5 确定射线穿过图像矩阵的入射点 ②考查边界直线x=xn,该边界线与射线的交点坐标为: (15) 如果x0≤x≤xn且y0≤y≤yn,若入射点已存在,则该交点作为射线穿过图像矩阵的出射点;如果x0≤x≤xn且y0≤y≤yn,若入射点不存在,则该交点作为射线穿过图像矩阵的入射点。如果x ③同理,分别考查边界直线y=y0、y=yn与射线的交点,确定入射点或出射点。 如果始终无法确定入射点,说明该射线与图像矩阵不相交,沿该射线的正投影值为p=0。 如前文所述,Siddon算法的串行计算策略需要进行排序计算,导致每条射线对应的线程需要维护大量的私有变量,造成存储资源的消耗和计算量的增加。为了克服上述缺点,首先,确定射线穿过某单位像素的起点后,应直接定位后继点,完成起点至后继点区间内的线积分运算。然后,更新起点坐标,重新定位后继点,直到后继点为射线穿过图像矩阵的出射点。其中第一个起点为射线穿过图像矩阵的入射点。 假设射线穿过某单位像素的起点坐标为(xpre,ypre),后继点坐标为射线穿过该单位像素的出射点(xnext,ynext)。根据Siddon算法原理,后继点一定是射线与单位像素某边界直线的交点。这里分别沿着射线方向的x分量和y分量搜索单位像素的边界直线,确定后继点。x分量方向的搜索起点为x=xj,其中xj满足下述条件: (16) y分量方向的搜索起点为y=yi,其中yi满足下述条件: (17) 后继点有两种可能:①射线与单位像素边界直线xnext=xj+sgn(xt-xs)·1的交点,其中sgn(·)为符号函数,该点距射线起点S的距离占据射线总长|ST|的比例因子αnext,其表达式为: (18) (19) 图6 确定后继点坐标 从起点(xpre,ypre)到后继点(xnext,ynext),射线在该区间内的线积分为: f(xj,yi)·(αnext-αpre)·|ST| (20) 更新起点坐标,将当前后继点作为新的起点,继续搜索下一个后继点,直到搜索至射线穿过整个图像矩阵的出射点,完成整个区间内的线积分,得到该射线穿过图像矩阵的正投影值。 Siddon算法的计算策略经过改进后,可以发现,每条射线不再维护庞大的私有变量数组,且算法迭代搜索后继点,并完成局部区间内的线积分计算,无需排序,便于采用GPU并行计算措施,提高算法执行效率。 为了验证Siddon算法GPU并行计算结果的有效性和准确性,本文设计人体颌部数字模体作为测试对象,模体尺寸512×512,如图7所示。 图7 人体颌部数字模体 设计正投影扫描参数,如表1所示。 表1 扫描参数 采用前文提出的GPU并行计算策略,对颌部模体进行正投影模拟计算,并得到圆周扫描范围内的扇束投影正弦图,如图8左图。为了验证正投影模拟计算结果的有效性,采用标准扇束FBP重建算法,重建矩阵依然设计为512×512,重建体素尺寸为0.2 mm,得到模拟投影对应的重建图像,如图8右图。可以发现,由模拟投影能够重建得到正确的断层图像,说明本文提出的GPU并行计算策略具备有效性。 图8 颌部模体的扇束扫描正弦图和重建图像 为了验证GPU并行计算结果的准确性,这里按照Siddon算法的串行计算策略采用CPU主机端进行计算,按表1所示的扫描条件重新获得颌部模体的扇束投影正弦图。分别取同一投影角度下CPU串行计算结果和GPU并行计算结果的投影数据进行比较,如图9所示。 图9 CPU串行计算结果和GPU并行计算结果比较 为了定量表征GPU并行计算结果的准确性,以CPU串行计算结果为参考标准,引用归一化平均绝对距离判据r对GPU并行计算结果进行综合评价。归一化平均绝对距离判据r的表达式为: (21) 经计算,GPU并行计算结果r=0.31%。 综上所述,CPU串行计算结果和GPU并行计算结果基本上保持一致,说明本文提出的GPU并行计算策略其计算结果具有准确性。 CPU串行计算和GPU并行计算的计算效率如下: 计算机CPU型号为Intel i5-6300HQ,主频2.3 GHz,内存4 G,Windows 7 64位操作系统。GPU型号为NVIDIA GeForce GTX 950 M,独立显存2 G。采用CPU串行计算耗时230 s,GPU并行计算完成同样的计算量耗时仅需9 s,运算速度提高25倍,运算效率得到大幅度提升。 Siddon正投影算法原串行计算策略存在两大缺点:①每条射线的正投影计算都需要维护庞大的私有变量数组,消耗存储资源;②每条射线的正投影计算都需要进行排序计算,增加额外的计算量。上述串行计算策略不利于基于多线程同步的并行计算。针对这种情况,本文提出Siddon正投影算法的并行计算策略。沿着射线方向顺序搜索、更新射线穿过单位像素的起点和后继点,逐渐累加射线穿过单位像素的线积分值,得到指定射线穿过图像矩阵的正投影值。 Siddon算法经过计算优化后,采用GPU实现扇束CT投影的多线程并行计算。实验结果表明,Siddon算法的并行计算结果在保证计算准确度的同时,获得20倍以上的计算效率提升,显著提升Siddon算法的工程实用价值。扩展到三维锥束扫描及重建的情况,Siddon算法的GPU并行计算将显得尤为必要。
2 Siddon算法的串行计算策略

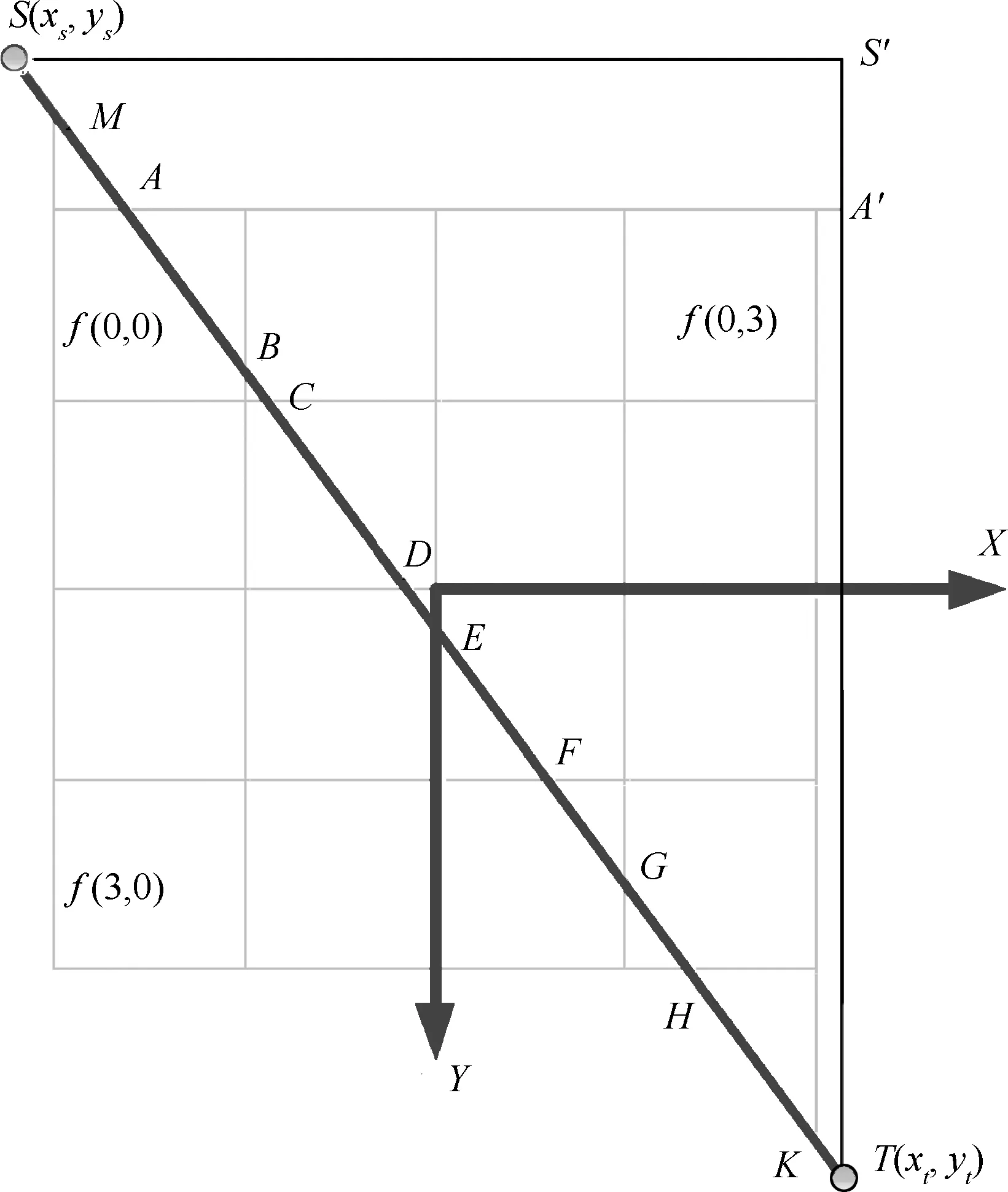
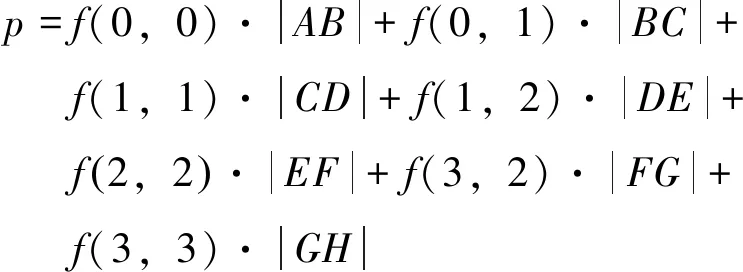
2.1 确定射线穿过图像矩阵的入射点和出射点
2.2 确定射线穿过单位像素的入射点和出射点
3 Siddon算法的并行计算策略
3.1 确定射线穿过图像矩阵的入射点和出射点
3.2 确定射线穿过图像矩阵的后继点


4 实验


5 结论