多源异构数据特征的智能结构化方法仿真
2022-08-22吕仲琪董卓达刘晓丽芦惠娟
吕仲琪,董卓达,刘晓丽,芦惠娟
(深圳市华云中盛科技股份有限公司,广东 深圳518057)
1 引言
数据作为人工智能所应用的一个重要前提是数据具有结构化特征。目前关于法院法律文书的大数据分析报告中指出,在法律大数据上对裁判文书进行标注、挖掘、分析、建模等法律人工智能应用的研究。除了对外公布的法律裁判文书,其它关键部分的法律决策过程大多不具有结构化特征的数据。除此之外,司法决策运行的程序过程信息也不充分,如大量的程序过程如刑侦过程、起诉过程、庭审过程等文字记录具有散乱、无序和碎片化的特点[1]。
在语料稀缺的法律大数据领域,面对各种各样的多源异构数据[1],传统的命名实体识别(Named Entity Recognition,NER)的标注方法[14]并不能获得很好的效果。法律领域数据中命名实体识别任务更加复杂,其难点主要表现在:①领域命名实体识别局限性。②命名实体表述多样性和歧义性。③命名实体的复杂性和开放性。尽管法律裁判文书对法律的主体、案件事实、适用等要素做了明确规定,但细化到法律用语上,并未作出统一规定。以丧葬费为例,在起诉状中“丧葬”可能被称为“安葬”、“殡葬”,“停尸”的等价表达有“存尸”、“收尸”。这些非结构化的数据表述为机器的知识构建造成了很大的障碍。在法律这种非客观领域知识挖掘过程中,无监督学习效果不甚理想,必须通过其它途径对法律数据进行处理。
本文提出了一种多源异构数据融合的法律文书实体识别方法,结合领域知识,建立BERT-BiLSTM-CRF模型用于法律文书的命名实体识别,为命名实体关系抽取模型并挖掘结构化特征,实验结果表明,该方法比传统的样本融合方法的实体识别效果有显著优势,满足领域要求。
2 相关工作
人工智能对证据的审查、判断、采信的过程是法官模糊决策过程,类似的,人工智能量刑预测的过程可以抽象为不同源头数据融合的过程[1]。数据融合本质上是对来自不同时空,不同类型,不同速率的多源数据的协同处理的过程,达到完善协同信息的目的[10]。文献[2]研究了GIS中的多源异构数据的部署与管理,以及融合模型的构建;文献[5]研究了基于异构数据融合的数据管理和决策架构,提高了针对数据的融合决策的准确性和有效性;文献[3,4]研究了IOT环境下海量多源异构数据的融合策略,并有效用于目标追和路径过程推演应用;文献[6]利用神经网络方法研究了在实际生产应用过程中的多源异构数据融合技术,保证了基础信息平台的知识互补和安全高效。
在多源异构数据数据的融合过程中,命名识别(NER)任务越发重要,人们开始用深度神经网络来处理领域信息的NER过程,并取得了可观的效果。这种方法的优势在于,不需要对数据进行预处理,可由给定的神经网络模型自行训练并提取特征。在基于卷积的深度神经网络模型来解决序列标注的问题的基础上,Chiu和Nichols[14]提出了一种双向LSTM-CNNs架构,该架构可自动检测单词和字符级别的特征。Ma和Hovy[12]进一步将其扩展到BiLSTM-CNNs-CRF体系结构,其中添加了CRF模块以优化输出标签序列。Liu等[13]提出了一种称为LM-LSTM-CRF的任务感知型神经语言模型,将字符感知型神经语言模型合并到一个多任务框架下,以提取字符级向量化表示。随着问题的深入,也出现了许多半监督学习方法,例如基于预训练语言模型BERT等[15]的半监督方法。
3 多源异构序列标注数据融合模型
3.1 多源异构数据融合方法
数据融合从算法层次上分为数据(像素)级融合、特征级融合以及决策级融合。本文研究多数据源在命名实体识别、特征提取级等决策层面上的融合,其方法主要有加权平均法、Dempster-Sharer证据推理法(D-S 方法)和选举决策法等[8]。
1)加权平均法
设wi为数据源i的权重,tij为数据源i对决策j的支持度,即计算∑~witij值,根据支持度确定决策算法。该方法考虑了数据源的重要程度,但权重的确定具有随意性。
2)D-S 证据理论
将待识别个体所有可能性构成的集合定义为D,其子集记为2D,∀A⊆D,定义:m:2D→[0,1],其中:m(∅)=0,∑A⊆2Dm(∅)=1,∅为空集,则m为 2D上的基本概率分配函数(Basic Probability Assignment Function,BPAF),它实际上是根据证据对 D 的子集信任程度的分配。
实际中往往针对同一问题因证据不同而得到不同的mi,考虑所有证据后的m可通过下式得到
m(A)=K-1×∑∩A=Ai∏mi(Ai)(1≤i≤n)
其中:K=∑∩Ai≠∅∏mi(Ai)
3)选举决策法
将各个数据源抽象为投票者,通过对比各决策获得的票数确定优劣
Sup(ai)=F(Supj(ai))
其中:ai为第i个决策,Sup(ai)为其所得“票数”;Supj为数据源j对ai的支持度,若支持则取1,否则为0,函数F可定义为求和运算。
由于存在多源异构数据的 BPAF 难于确定,投票法不能区分票数相同的问题,本文采用OWA 方法[10]解决面临的挑战。
3.2 多源异构数据融合结构
受文献[7]的启发,针对法律领域的数据和知识归纳了如图1 所示的融合结构。

图1 多源数据源融合结构
针对上述融合过程,本文提出了多源异构数据融合自动特征结构化模型,如图2 所示。模型包括数据仓库、支持度管理、OWA算子权重计算和数据处理4 个模块,具体描述如下。
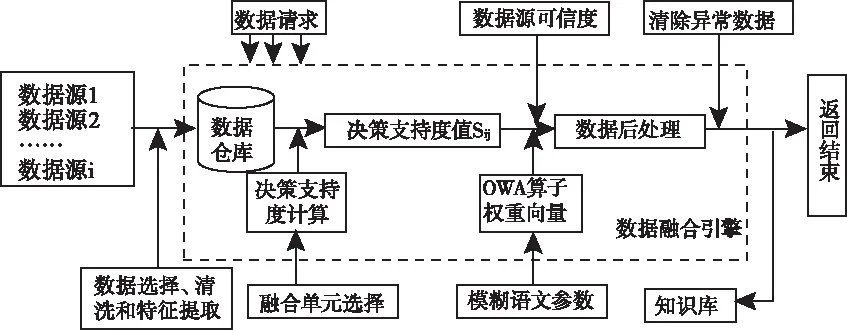
图2 多源异构数据融合模型
1) 数据仓库作为前后衔接模块,为后续的业务提供数据源,前端处理整合数据消除异构性,统计并特征提取等功能。
2) 决策支持度计算模块从数据仓库获取数据,并计算相应的支持度值sij;
3) OWA 算子计算模块根据决策者提供的模糊语义原则来量化对数据源的偏好,计算出 OWA 权重向量wi;
4) 数据转换与排序根据可信度值,结合 OWA 权重向量wi对sij进行转换,并将转换后的结果排序,最后通过求和计算出决策值(结果返回)。
3.3 多源异构序列标注模型框架
本文主要研究基于深度学习模型的多源异构数据特征融合的方法,结合语言模型的的框架其融合思路如图3 所示。
语言模型被普遍应用于自然语言处理的各个环节中。目前,神经语言模型(Neural Language Model)得到了广泛的研究,Devlin等[15]将其应用到神经机器翻译系统,缓解了手工设计退避(back-off)规则的需要,且支持不同上下文的泛化性能。将深度神经网络语言模型与信息融合模型结合[8]产生的互补信息进行推理,构建一个逐层深度学习模型框架,用于多源异构数据训练学习,以提取融合多源数据特征的目标信息。从运行结果上看,模型方法具有较好的通用泛化能力。
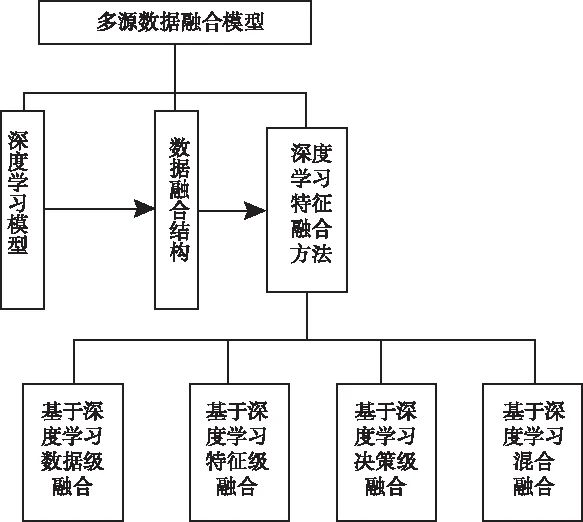
图3 基于深度学习的融合思路结构框图
4 多源异构数据融合算法
4.1 数据类型及其特点
根据数据类型的不同,重点研究随机类型、二值类型、程度类型和词汇术语类型4类描述,如表1所示。

表1 数据描述方式
随机变量服从正态分布,记为:X~(μ,σ2),μ为期望,σ为标准差。
二值类型数据用于描述命题的是或否,取值空间大多为{1,0}或{True,False}。
表示程度的数据采用汉语程度副词来描述,如较大、较多等,程度等级大多采用 7 或 9 个标准。
基于词汇术语的数据采用词汇表中规定的事物定性的描述,词汇个数视情况而定。
4.2 基于三角模糊数的支持度计算
多源数据具有模糊特征,可采用三角模糊数计算决策的支持度值[10]。
1)随机性数据的转换
设:x0=u-3σ
将区间[μ-3σ,μ+3σ]进行n等分,则随机数据的支持度定义为
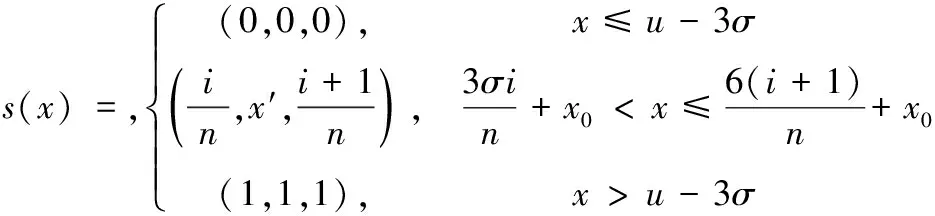
(1)
反之,则支持度定义为
s′(x)=(1,1,1)-s(x)
2) 二值型数据的转换
若二值型数据中取 1 和 0 的个数分别为n和m,则数据源对决策的支持度定义为
s(x)=(n/n+m,n/n+m,n/n+m)
(2)
3) 程度类数据的转换
本文采用 7 等级标准描述对象严重程度。比如在“盗窃金额”方面就可以细分为“数额较大”“数额巨大”“数额特别巨大”,并与具体金额挂钩。各等级对决策的支持度如表2 所示。

表2 程度类型数据的支持度
2) 词汇术语数据的转换
设词汇表w包含n个术语,按决策支持度从低到高排序:w={w0,w1,…,wn-1},则支持度表示为:
s(wi)=(i/(n-1),i/(n-1),i/(n-1))
(3)
4.3 权重向量计算
有序加权平均算子(OrderedWeighted Averaging,OWA)及其拓展的算子是一种决策信息融合工具,能够有效地处理模糊或者不确定决策信息。


(4)
其中:bi是ai中第i个最大的元素,则F称为n维OWA算子。
OWA权向量w=(w1,w2,…,wn)由下式确定
wi=f(i/n)-f((i-1)/n)
(5)
其中:i=1,2,…,n,f为模糊语义量化算子,定义为
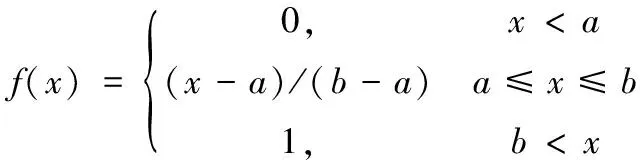
(6)
其中:x,a,b∈[0,1]。
此外,OWA算子定义的反映决策者乐观态度的度量算子

(7)
4.4 数据融合算法
设n个决策:A=(A1,A2,…,An),m个数据源:S=(S1,S2,…,Sm),各数据源的可信度为pi,数据融合算法描述如下:
第 1 步:计算数据源对决策的支持度。首先读取数据,根据4.2计算出对决策的支持度
Sij=(aij,bij,cij)
(8)
其中:Sij为数据源i对决策j的支持度,(aij,bij,cij)为支持度的三角模糊数表示,且:0≤aij≤bij≤cij≤1。
第 2 步:计算OWA算子权重向量。根据决策者的偏好,基于模糊语义原则确定式(6)中的参数和的值。根据参数可确定出模糊语义量化算子f(x)。
根据f(x),通过式(5)求得OWA权重向量w=(w1,w2,…,wn),n为数据源个数,并按式(7)求得c的值。
第 3 步:根据各数据源可信度pi和支持度值sij,对sij进行转换。设
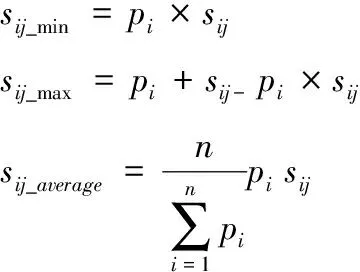
(9)
定义:当c≤0.5 时
h(c)=0,m(c)=2c,l(c)=1-2c
当c≥0.5 时
h(c)=2c-1,m(c)=2-2c,l(c)=0
则经过转换后的决策支持度值表示为
sij=h(c)sij_max+m(c)sij_average+l(c)sij_min
(10)
第4 步:依据前面步骤的结果对数据进行融合,并计算最终决策值;
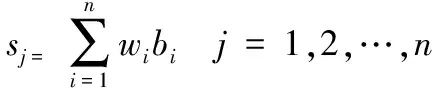
(11)
其中:bij为(s1j,s2j,…,snj)中第i个最大元素。
第 5 步:根据实际问题做出决策。
5 实验与结果分析
5.1 数据集
爬取裁判文书网等各行政机关网站公开的文书数据,从中挑取100万份标注好的数据作为本文使用的数据集。
该数据集标签共有1000多个,大致分为以下几大类:
1)文书信息类:如文书号、文书类型等;
2)相关人基本信息类:如姓名、性别、工作单位等;
3)案件事实类:如案发时间、案发地点等;
4)相关证据类:如证据类型等;
5)检察院审理及起诉情况类:如起诉时间、起诉罪名等;
6)法院判决情况类:如刑期、罚金等;
将数据集随机打乱顺序后,按照8:1:1的比例划分训练集、验证集和测试集。
5.2 实验设置
实验采用Tensorflow1.12.0深度学习框架,并使用NVIDIA TESLA T4显卡,优化器采用Adam自适应学习率梯度下降算法进行参数优化。本文使用Word2Vec的连续词袋模型(CBOW)算法在全量数据集上进行预训练,得到字向量的维数为512。BiLSTM的循环单元节点数为128,BERT里的多头注意力层数multi_head attention layer为6层,注意力头数为8,Adam学习率为1e-5,dropout为0.5。
本次使用精准率(Precision)、召回率(Recall)和F1值来评价模型的识别效果,其中F1值为精准率和召回率的调和均值,来综合评价模型的性能。
精准率计算方式如下:

召回率计算方式如下:

F1值的计算方式如下:
F1=(P+R)/(2*P*R)
5.3 实验结果与分析
5.3.1 与现有方法的对比
为验证本文模型的性能,将其和下列方法进行对比:
BiLSTM-CRF模型.该模型由Huang等提出并应用于序列标注任务[13]。将句子的词向量表示输入该模型对句子的标注序列进行预测。与Huang等不同,为了应对词语边界模糊的问题,本文以字为单位构建字向量。
BiLSTM-CNN-CRF模型.该模型是由卡耐基梅隆大学语言技术学院的Ma等人[12]提出的,首先使用CNN将一个词汇的字符级别信息编码到它的字符级别表示中去,然后将字符级别的表示和词汇级别的表示连接起来,将它们放到BLSTM中,对每个词汇的上下文信息建模。
Lattice-LSTM-CRF模型.该模型由新加坡科技设计大学的Zhang等提出[9],专门针对中文数据进行命名实体识别任务。该模型较基于字符的方法显性地利用词和词序信息;较基于词的方法不会出现分词错误。
Att-BiLSTM-CRF模型.该模型[16]在BiLSTM层和CRF层之间加入了注意力机制。
实验结果如表1所列。

表1 各种方法的实验结果(单位:%)
通过观察发现,BiLSTM-CNN-CRF和加注意力机制的Att-BiLSTM-CRF相比原始BiLSTM-CRF模型,识别率均有所提高。由此可见,通过给标注模型加入适当的外部知识或特征,有助于提升识别效果。本文提出的方法充分利用了未标注语料来训练语言模型,并由此得到语言模型特征;同时BERT中的多头注意力机制充分挖掘了文本本身的特征。因此,相比于其它方法,本文方法的F1值均有提高:相比于BiLSTM-CRF,提高了6.97%;相比于BiLSTM-CNN-CRF,提高了3.48%;相比于Lattice-LSTM-CRF,提高了3.37%;相比于Att-BiLSTM-CRF,提高了3.98%;
5.3.2 模型效率分析
在实际应用场景中,模型的运行效率也非常重要。为此,本文进行了效率对比实验。通过多次加载模型,对测试集进行预测,统计出模型的加载时间和推理时间,以加载时间的均值和推理时间的均值作为评价模型运行效率的指标。将本模型与BiLSTM-CRF等模型进行对比,结果如表2所列。

表2 不同模型的效率对比(单位:ms)
从表2中可以看出,模型加载时间没有明显的差别,而在测试时间中本文模型不占优势,这是因为本文模型在复杂度上高于另外4个模型。实验中,最快的模型(BiLSTM-CRF)处理每条数据的平均时间为312ms,本文模型为615ms。线上应用数据量一般较小,因此速度上差别不是很明显;而线下应用对时间的要求相对较低,且本文模型的F1值有较好的提升,所以该运行时间在可接受的范围内。
6 结论
本文在自动数据特征结构化的业务驱动下,提出了BERT-BiLSTM-CRF命名实体识别方法,并且成功在法律领域实现规模化应用。文中建立多源异构数据结构融合模型,研究了异构数据量化策略并改进了数据融合算法,结果证明融合方法是可行有效的。通过实验,表明结合融合算法的NER方法的模型结构和方法,对其它类似的数据处理和融合具有借鉴作用。
