基于IF-EMD-LSTM的数据中心CPU负载预测
2022-08-22李国,陈茜
李 国,陈 茜
(中国民航大学计算机科学与技术学院,天津 300300)
1 引言
2016年12月,英国国家航空服务公司(NATS)由于两条系统航班服务器通道均发生故障,导致数百架航班无法起飞,此次故障共造成120架航班被取消,500架航班被延误超45分钟,共影响约10000万名旅客[1]。
2016年8月8日凌晨2点,达美航空公司在亚特兰大的主数据中心发生故障,导致全球电脑和运营系统停顿。超过650各航班被取消,数千旅客滞留全球各机场,航班延误严重,损失数百万美金[2]。
一个典型的数据中心服务器可以运行成百上千资源不断变化的作业,然而现有系统并不能适应日益增长的调度复杂性。主要原因是管理系统将工作任务低效地分配给服务器,不能在安排工作任务之前充分考虑服务器状态。因此,高效管理数据中心资源,提高服务器负载预测精度,优化服务器资源调度至关重要。
国内外许多学者对提高资源负载预测精度问题进行了大量研究,并取得了一些研究结果。常见方法有三类,一、传统预测方法,如 Holter-Winter,差分整合移动平均自回归模型(ARIMA)和Prophet算法[3,5],结合历史数据进行趋势预测。二、人工智能方法,文献[6]重点研究谷歌数据中心服务器CPU负载预测,使用长短期记忆网络(LSTM)并与应用广泛的ARIMA预测结果进行对比。结果表明,LSTM模型预测结果准确率更高,学习非线性数据的能力比ARIMA模型表现更优异。文献[7]指出组合模型通过将两个或多个单一模型结合起来,综合单一模型的优点,克服了单一模型的缺点,提高了混合模型的整体预测精度。文献[8]研究发现农业时间序列既包含线性部分又包含非线性部分,线性部分使用ARIMA建模,非线性部分使用LSTM建模。最后,得到两种模型的混合预测结果。文献[9]提出了EMD/EEMD-ARIMA的混合预测模型。经验模态分解(EMD)和综合经验模式用于将黄河上游长期径流预测的水文时间序列分解为不同频率的IMF组件进行预测。
关于服务器CPU负载预测方法,相关研究主要使用传统时间序列预测方法或单一人工智能方法。传统时间序列预测方法虽然可变参数较少,但是对于非线性,非平稳,信噪比高的数据预测结果准确率不高,很难适应多变的时间序列预测。人工智能方法容易陷入局部最优、易发生过拟合,且模型参数不易精确获得,导致预测精度不高。结合上述问题,本文提取某航空公司数据中心CPU负载数据,首次采用基于IF-EMD-LSTM的服务器CPU负载组合预测方法,首先对原始数据进行预处理,IF能够去除数据中的异常点并提高原始数据信噪比;其次,LSTM的结构设计比传统预测模型ARIMA更适合该时间序列预测,并使用BA算法优化LSTM模型,减小LSTM参数人为主观选择对网络性能造成的影响。并与单一ARIMA,LSTM模型进行对比实验。根据预测结果可知,组合模型具有更高的预测精度,对于保证系统运行不中断,提前进行资源调度具有重要的指导意义。
2 预测模型构建
2.1 特征提取
本文采用某航空公司服务器集群数据集,该数据集详细记录了300+服务器从2018年11月1日至2018年11月15日,总计15天资源使用的详细情况。然而手动为300+服务器建立资源负载预测模型不合理。因此,只为其中一台服务器(机器ID:193)建立时间序列分析,建模和预测方法。其余服务器也是同样的建立方法。之所以选择数据集最活跃的机器进行研究,是因为该机器空缺值最少。以下ID为193的服务器被称为机器A。为了提取服务器每个时间窗的工作CPU负载,考虑到某些任务只部分运行5分钟时间窗这一事实。因此,将每相隔5分钟时间窗任务的所有CPU读数相加。并且观察到一些机器不活动时期CPU读数为0。使用线性插值方法来填充空缺值,使用空缺值的相邻值进行填充,保持序列的连续性[10]。共计4120条数据,选取前70%的数据作为训练集,20%的数据作为单步测试集,10%剩余数据用于验证模型的泛化能力。提取机器A CPU负载时间序列数据”CPU_load_data.csv”文件,数据格式为{time,CPU load data},其中time代表时间,CPU load data代表CPU负载数据,具体负载数据如图1所示。

图1 CPU负载数据
2.2 孤立森林算法
孤立森林是基于集合的快速异常线性时间复杂度高的检测方法。这是一种异常检测算法满足大数据处理的要求。孤立森林适合用于连续数据的异常检测,并且异常被定义为“孤立的容易隔离的点,可以理解作为一个稀疏分布且远离的点密集的人群[11]。偏远的森林需要使用集成方法得到一个收敛值(蒙特卡罗方法),也就是说,从头开始反复切割,然后平均每次切割的结果。孤立的森林需要使用整体方法为了得到一个收敛值(蒙特卡罗方法),也就是说,从一开始就反复地剪平均每一次切割的结果。孤立森林组成的 每一棵树结构实现方式如下:
1)随机选择一个属性A。
2)随机选择此属性值的值。
3)根据A对每条记录进行分类; 将小于A的记录放在左边的子树上,并将大于或等于value的记录放在右边的子树上。
4)构造左,右子树使用递归方式,直到满足以下条件:①传入数据集仅具有一个或多个相同记录,并且②树的高度达到高度阈值。
对于有 4 个样本的测试数据 1、23、29、100 遍历一棵孤立树,如图2所示。从图2中看出,样本 100 最先被孤立出来,所以最有可能是异常数据。

图2 测试样本孤立树
2.3 经验模态分解
EMD分解可以将非平稳信号自适应地分解为一系列IMF信号和残差。IMF满足两点:第一,极端点的数目和零交叉点的数目必须相等或相差不超过一。其次,在任何一点上,包络都是由局部最大值和局部极小值点形成的。极小值点形成的包络的平均值为零。对于给定信号,执行EMD分解的步骤如下[12]:
1)求出x(t)的上极点和下极点; 使用插值方法形成上下包络并计算初始值m1;
2) 提取细节:
h1=x(t)-m1
(1)
3)确定h1是否满足IMF条件。 如果满足,则h1是x(t)的第一个成分,记录为c1=h1,并终止分解。 如果不满意,请对k重复以上步骤k次以获得
h1k=h1(k-1)-m1k
(2)
其中h1k是IMF,则c1k=h1k是第一个IMF信号x(t)的分量;
1)在上述迭代满足术语标准标准偏差(SD)之前,标准偏差通常为(0.2-0.3);
2)将c1与x(t)合并得到:
r1=x(t)-c1
(3)
3)分解c1,c2,…,cn并重复进行:组件包含不同的分量频率段从高到低。 总而言之,原始信号的分解是

(4)
2.4 蝙蝠优化算法
蝙蝠算法是Xin-Sbe Yang 等在2010 年研发的高效生物启发式的算法[13]。蝙蝠的回声定位的行为可以通过与待优化的目标函数相关联的方式进行表达,即将蝙蝠寻找最优位置的过程替换为寻找目标函数fitness和目标变量x=(x1,x2,x3,…,xd)T的最优值问题。蝙蝠算法的具体运行过程如下:
步骤一:设置蝙蝠的个数N,维度d,迭代次数r,脉冲响度A,脉冲频率r,脉冲频率范围[Qmin,Qmax],位置范围[xmin,xmax]以及适应度函数fitness。

Qi=Qmin+(Qmax-Qmin)*γ
(5)

(6)

(7)
随机产生一个数rand,比较rand与脉冲频率r的大小关系,如果rand大于r,则通过式(16)对当前最优解xbest进行随机干扰。如果rand比r小则直接利用式(17)引进行越界处理,具体公式如下所示

(8)

(9)
式(16)中,ρ∈[-1,1]的随机值,AVt是t时刻蝙蝠群体脉冲n向度的平均值。
步骤四:对新位置xt;求适应度函数值fnew。 生产随机数rand,若rand小于脉冲响度A并且fnew小于目前位置适应度函数值fitness,则把fnew赋值给fitness。

(10)


(11)

(12)

步骤六:重复步骤二至步骤五,直至达到最大法代次数或者最优适应度函数值小于设定值。
2.5 长短时记忆网络
在阈值神经网络中,LSTM网络最为著名。存储器是用来判断的信息是否有用。与传统时间序列预测模型相比,LSTM模型解决长期依赖问题并充分考虑时间序列数据的特点。图2显示了LSTM模型原理图。
LSTM包含四个非常关键的元素输入门,输出门,遗忘门,和内存单元。下面对LSTM中各部分进行描述:
1) 输入门
it=δ(Wi·[ht-1,xt]+bi)
(13)
式中,wt表示输入门的权重矩阵,bt为偏置,δ为 sigmoid函数
(14)
2)输出门
ot=δ(Wo·[ht-1,xt]+bo)
(15)
式中,W0表示输出门的权重矩阵,b0为偏置。
3)遗忘门
ft=δ(Wf·[ht-1,,xt]+bf)
(16)
式中,Wf是遗忘门的权重矩阵,bf为偏置,δ为 sigmoid。
4)内存单元
ct=tanh(Wc·[ht-1,xt]+bc)
(17)

图3 LSTM原理图
ct=ft·ct-1+it·ct
(18)
式中,Wc为存储单元的权重矩阵,bc为记忆单元的偏差项,tanh 函数表达式为:
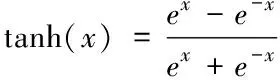
(19)
LSTM的最终输出由输出门和单元状态决定
ht=ottanh(ct)
(20)
其中初始化时,c0=0,h0=0,LSTM的输入单元为x(t),输出单元代表h(t)。
首先本文设置LSTM除初始值和阈值之外的数,通过构造每层256个神经元的两层LSTM,可以更改历史序列长度,batch_size和训练回合,以找到最适合该参数的值。 平均绝对误差用作模型的评估指标:
将训练回合编号设置为50; batch_size为20; 历史序列长度为5、10、15、20、25。预测结果如表1所示。其中,当历史序列长度为20时MAPE最小。

表1 不同历史序列下的预测结果
将历史记录序列的长度设置为10;训练数回合为50;表2中显示了预测结果。batch_size为52时,误差最小。

表2 不同batch_size下的预测结果
将历史记录序列的长度设置为10;batch_size为20时;训练回合的数量分别为30、50、80、100,300和1000。预测结果如表3所示。其中,当训练轮回合为80时,误差最小。

表3 不同训练回合下的预测结果
LSTM除初始权值和阈值外最优参数设置,如表4所示。

表4 LSTM参数设置
3 BA-LSTM模型构建流程
步骤一:首先根据本文第三部分静态确定LSTM参数,除初始权值和其阈值;
步骤二:准备数据:利用IF进行数据预处理,EMD进行数据分解;
步骤三:BA参数初设和训练:首先根据式(21)求出BA算法的维度,其中,j,k,l表示LSTM中输入层,隐含层和输出层的个数;
d=4*j*k+4*k+j*k*l
(21)
BA与LSTM目标函数相同:

(22)
其中:o是指蝙蝠中的第o个;p是指第p条数据;oip和Tip是第o只蝙蝠确定模型LSTM样本数据p下的输出值和真实值;m是指样本总数。
步骤四:将步骤三得到的最优值等于LSTM的初始权值和阈值,训练BA-LSTM模型。
4 混合算法总体流程
基于IF-EMD-LSTM的CPU负载趋势预测方法总体流程如图4所示。

图4 基于IF-EMD-LSTM的CPU负载预测方法流程图
1) 数据预处理:采用孤立森林算法对数据中的高异常点进行剔除并提高信噪比。
2) 数据分解:为了进一步提高预测精度,采用EMD算法将输入数据分解为不同频率的IMF组件和残差。
3) 优化神经网络:利用BA算法优化LSTM初始权值和阈值,利用优化的值构造BA-LSTM模型,减少人为主观选择参数对网络性能的影响。
4) 神经网络训练:对每组IMF组件执行优化后的LSTM网络训练,并通过单独的优化后的LSTM神经网络预测每个IMF和残差,并从每个预测值中重建预测值。
5 实验评价指标
评价指数
模型预测量化指标使用平均相对误差(MAPE)以及均方根误差(RMSE)评估算法性能:

(23)

(24)
其中m是序列长度,Xj是数据的真实值,j是数据的预测值。
6 实验结果与分析
实验需要Keras深度学习框架下的LSTM库,Sklearn机器学习库,Pandas,Numpy,Matplotlib科学计算库和绘图库。分别使用ARIMA,LSTM和IF-EMD-LSTM混合模型进行预测。图5显示了孤立森林对异常点去除情况的展示。从图中可以看出,一些高爆炸异常数据已被消除。图6显示了使用EMD算法对数据进行分解的结果,将数据分解为不同频率的IMF组件和残差。图7显示了使用ARIMA模型预测,图8显示了使用LSTM预测模型的曲线预测结果。图9显示了使用IF-EMD-LSTM混合算法总体预测结果。

图5 孤立森林原始数据异常点去除

图6 EMD分解后数据曲线

图7 ARIMA模型预测结果

图8 LSTM模型预测结果

图9 IF-EMD-LSTM模型预测结果
三个预测算法使用MAPE和RMSE做为评价标准,预测结果对比如表5所示。从表中可以看出MAPE和RMSE优于ARIMA和LSTM预测模型。

表5 三种预测算法评价指标的比较
7 结语
1)根据从某航空公司服务器资源负载数据提取出的CPU负载时间序列数据特点,利用IF和EMD算法对原始数据进行预处理,解决原始数据非平稳,非线性,信噪比高对预测模型性能影响较大的问题。
2)引入蝙蝠算法(BA)优化LSTM,避免了单一理论方法的局限性,组合预测模型与单一ARIMA和LSTM模型预测相比平均相对误差(MAPE)分别提高了18.72%和8.71%,预测效果更佳。使用组合预测模型进行服务器CPU负载预测相比单一模型有了显著改进。
3)本文着重于研究服务器负载资源中CPU资源使用情况,未考虑其它因素,如内存,磁盘,网络等。
接下来的研究,将结合CPU资源与其它因素对服务器负载情况进行预测。
