基于YOLOv4改进算法的复杂行人检测模型研究*
2022-08-20李兰,刘杰,张洁
李 兰,刘 杰,张 洁
(青岛理工大学信息与控制工程学院,山东 青岛 266000)
1 引言
当今社会,监控遍布住宅小区、超市、工厂、广场、车站和机要室等众多场所,为维护社会治安发挥着重要作用。卷积神经网络的出现及应用为高速准确地在图像和视频序列中进行目标检测提供了可能。目前主流的目标检测算法有2种:两阶段检测算法和单阶段检测算法。两阶段检测算法首先在第一阶段通过选择性搜索算法提取出候选区域,生成提议对象;然后在第二阶段利用深度神经网络实现分类。该类检测算法主要包括R-CNN(Region-based Convolutional Neural Network)、SPPNet(Spatial Pyramid Pooling Network)、Fast R-CNN(Fast Region-based Convolutional Network)、Faster R-CNN(Faster Region-based Convolutional Neural Network)和R-FCN (Region-based Fully Convolutional Network)等,其特点是检测精度较高,但检测速度慢。单阶段检测算法跳过了提议对象的生成,直接预测目标边界框和分类。该类检测算法主要包括SSD(Single Shot multibox Detector)、YOLO(You Only Look Once)、YOLOv2、YOLOv3和YOLOv4等,其特点是检测精度略低,但检测速度明显优于两阶段检测算法[1-3]。
行人检测存在行人姿态和尺度多样及行人遮挡的问题,导致YOLOv4算法对部分行人检测不准确,存在误检和漏检的情况。本文提出一种在YOLOv4模型基础上的改进算法。改进算法使用k-means聚类算法对数据集中目标真实框尺寸进行聚类分析,根据分析结果选出适用于行人的先验框尺寸。在此基础上使用PANet(Path Aggregation Network)将浅层特征和高层特征进行融合,解决行人的多姿态多尺度问题。对于行人遮挡问题,使用斥力损失函数,利用预测框吸引指定目标,同时排斥周围其他行人目标,使预测框靠近正确目标的同时远离错误目标,提高行人检测效果。然后将非极大值抑制NMS(Non-Maximum Suppression)替换为soft-NMS(soft Non-Maximum Suppression)和DIoU-NMS(Distance-IoU Non- Maximum Suppression)[4,5],当其他先验框与得分最高的先验框重叠时,衰减其他先验框的分数,重叠越多受到的惩罚越大,衰减得也就越多,以此减少目标的丢失。实验结果表明,基于YOLOv4算法改进的行人检测模型能够很好地定位图像中多姿态多尺度的行人,并且对处于遮挡情况下的行人也能检测得很好。
2 相关工作
由文献[6]可知,R-CNN算法利用选择性搜索算法从输入的图像中提取出2 000个可能存在目标的候选区域;然后复制所有候选框所对应的原图区域并将其缩放为固定大小的图像,依次将其输入到卷积神经网络中进行特征提取,使用支持向量机进行分类;最后通过线性回归器得到每个类的精确位置信息。但是,R-CNN算法中的每个候选框都要单独进行特征提取和分类,非常耗时。蔡佳然[7]和罗鹏飞[8]在SPP(Spatial Pyramid Pooling)模型中引入了空间金字塔池化策略,使得检测模型可以接受任意大小的输入,提高了模型对于目标形变的鲁棒性。文献[9]中的Fast R-CNN检测算法使用卷积神经网络提取整幅输入图像的深度特征;接着用选择性搜索算法基于原图生成候选框;随后将候选框映射到特征图并使用ROI Pooling提取其对应的特征,将Softmax分类器添加在全连接层的后端以实现模型的分类,使模型特征提取和分类都基于神经网络实现;最后使用边界回归器调整位置坐标。但是,Fast R-CNN算法仍使用选择性搜索算法,耗时大以致无法实现真正的端到端检测。文献[10]也采用了Faster R-CNN检测算法,在使用卷积神经网络提取整幅输入图像的深度特征后,用RPN(Region Proposal Network)取代选择性搜索算法生成候选框并映射到所提取的特征图上;然后ROI Pooling将候选框所对应的特征转换为固定长度的输出数据;最后利用Softmax分类器分类并进一步调整物体的位置信息。文献[11]采用R-FCN算法,根据目标检测需要定位目标位置的特点将ResNet(Residual Network)网络改造成用一层位置敏感卷积层替换掉全连接层的全卷积网络,旨在解决目标检测过程中全连接层丢失目标精确位置信息的问题。
单阶段检测算法中整个检测过程只有一个网络,可以进行端到端的回归,在单个的神经网络中,直接从一次评估中得到目标的位置信息和类概率。由文献[12]可知,YOLO检测算法将原始输入图像分成S×S个网格单元,每个网格单元生成B个边界框和置信度,进行物体的框定和分类,最后利用NMS去除冗余的边界框,得到最终的位置信息和类概率。YOLO大大加快了检测速度,但1个网格单元只能预测2个边界框而且这2个边界框属于同一个类,导致靠得近的目标和尺度小的目标都很难被检测到。由文献[13]可知,YOLOv2对网络中每一层输入的数据进行批量归一化处理和预处理,大大提高了训练速度和效果;引入的先验框可以在一个网格单元中预测多个尺度的不同物体,增加了预测框的数量;通路层获取上一层特征图的细节信息,并将该特征图同最后输出的特征图相结合,提高了对小目标的检测能力。由文献[14]可知,YOLOv3算法使用加入了残差模块的Darknet-53解决了深层网络的梯度问题,使用k-means聚类算法确定了先验框尺寸,改进了多尺度特征融合网络,小目标行人的检测效果得到进一步提升。Bochkovskiy等人[15]提出了YOLOv4检测算法,使用CSPDarknet53作为主干特征提取网络,SPP和PANet作为加强特征提取网络。SPP分别利用4个不同尺度的最大池化层进行处理,极大增加了感受野,分离出最显著的上下文特征;PANet在完成特征金字塔从上到下的特征提取后还需要实现从下到上的特征反复提取。此外,YOLOv4还有Mish激活函数、Mosaic数据增强、CIoU(Complete Intersection over Union)、学习率预先退货衰减等“堆料”应用,相较于其他算法检测精度更高,检测速度更快。YOLOv4是目标检测模型,行人与物体目标之间存在长宽比、形态、尺寸和遮挡等差异,如果直接将YOLOv4模型用于行人检测,会导致模型对小尺度、非站立姿态、被遮挡行人的检测效果并不是特别令人满意。
3 改进的YOLOv4算法
为了使YOLOv4算法更好地适用于行人检测,本文对YOLOv4进行以下改进:首先,使用k-means聚类算法对行人数据集真实框尺寸进行分析,根据聚类结果确定先验框尺寸;其次,利用改进的PANet特征金字塔进行多尺度特征融合,增加对多姿态、多尺度行人目标的敏感度,以提高检测效果;最后,针对行人遮挡问题,利用预测框吸引指定目标的同时排斥周围其他行人目标,提出使用斥力损失来优化损失函数,使得预测框靠近正确目标的同时远离错误目标。
3.1 目标框聚类分析
YOLOv4算法中,先验框(即初始边界框)是根据不同尺度的网络层来确定的。早期目标检测算法中先验框的尺寸是凭经验确定的,过于主观。YOLOv2之后的算法大多使用k-means聚类分析来确定先验框尺寸。
k-means聚类算法发现给定数据集的k个簇并用簇的中心点来描述,k-means聚类算法使用欧氏距离来度量样本间的相似度,若在真实框聚类过程中使用k均值欧氏距离,就会使较大的边界框产生较多误差。因此,本文提出如式(1)所示的先验框聚类的距离度量计算公式,使得样本间的距离与边界框的大小无关。
distance(box,cen)=1-CIoU(box,cen)
(1)
其中,box和cen分别是真实框和边界框簇中心点集合;CIoU是IoU(Intersection over Union)基础上的改进,对边界框的尺寸不再敏感,不仅考虑了真实框与边界框簇中心的交并集比值,还考虑了真实框与边界框之间的中心点距离、重叠率、长宽比和最小闭包区域对角线距离。CIoU计算如式(2)~式(4)所示:
(2)
(3)
(4)
其中,b和bgt分别表示边界框和真实框的中心点,d表示2个中心点的欧氏距离,c表示最小闭包区域的对角线长度,α是权重参数,v表示长宽比的相似性,w和wgt分别表示边界框和真实框的宽,h和hgt分别表示边界框和真实框的高。图1中左上角为真实框,右下角为边界框,外边框为两者的最小闭包区域。
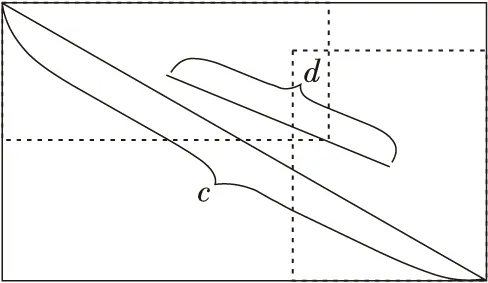
Figure 1 Relation of ground truth,boundary box and minimum closure area 图1 真实框、边界框与最小闭包区域关系
本文利用k-means聚类算法将行人数据集分成k个簇,经过一系列迭代运算使得簇内边界框的距离尽可能小,簇间边界框的距离尽可能大,再通过目标函数确定先验框的尺寸。通过对行人数据集中真实框的尺寸进行聚类分析,选出适合行人目标的先验框尺寸,取代YOLOv4算法中原来的先验框尺寸,以达到提高检测效果的目的。
3.2 改进的多尺度特征融合
浅层网络包含更多的行人定位信息,深层网络包含更多的行人语义信息,网络经过一系列的下采样操作后,小尺度行人的定位信息就会丢失[3]。本节的目的是通过多尺度特征融合,使浅层小目标行人的定位信息更多地传递到深层网络中,以提高YOLOv4检测模型对小尺度行人的检测精确度。
YOLOv4算法中SPP模块[16]设计在CSPDarknet53最后一个特征层的卷积里,分别利用4个不同尺度的池化核(分别为13×13,9×9,5×5和1×1)进行最大池化处理,将不同尺度的特征转换为长度固定的输出,以极大地增加感受野,分离出最显著的上下文特征[7]。SPP加强特征网络结构如图2所示。
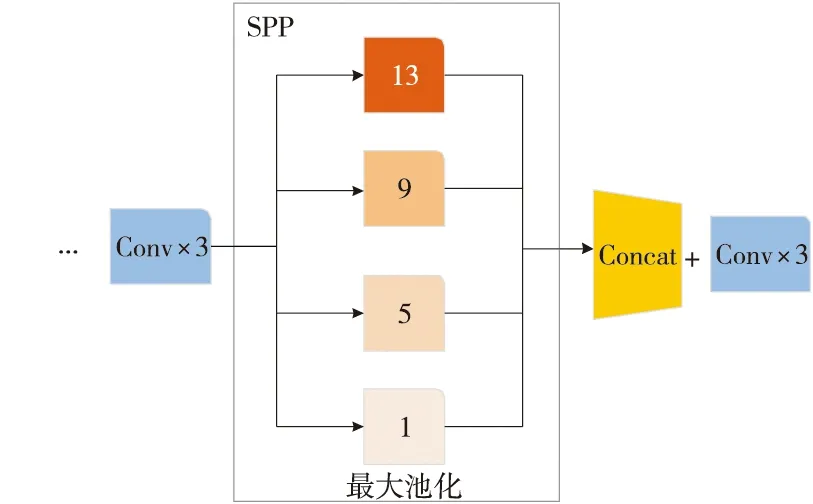
Figure 2 Structure of SPP enhanced feature network 图2 SPP加强特征网络结构
PANet结构[17]首先在传统特征金字塔结构FPN(Feature Pyramid Network)中完成从上到下的特征提取,这一步中只增强了语义信息,没有传递定位信息;然后在下一个特征金字塔中完成从下到上的路径增强特征提取,将浅层的强定位信息传递上去;接下来自适应特征池化层利用金字塔所有层的特征使得后期的分类和定位更加准确;最后是全连接层融合。其网络结构如图3所示,从左到右a为FPN特征金字塔,b为从下到上路径增强,c为自适应特征池化,d为分类定位,e为全连接融合。
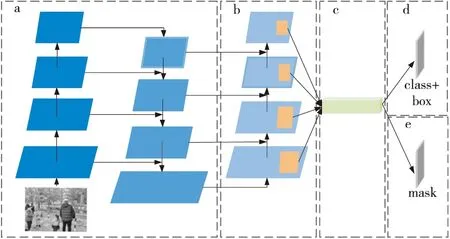
Figure 3 Structure of PANet 图3 PANet结构
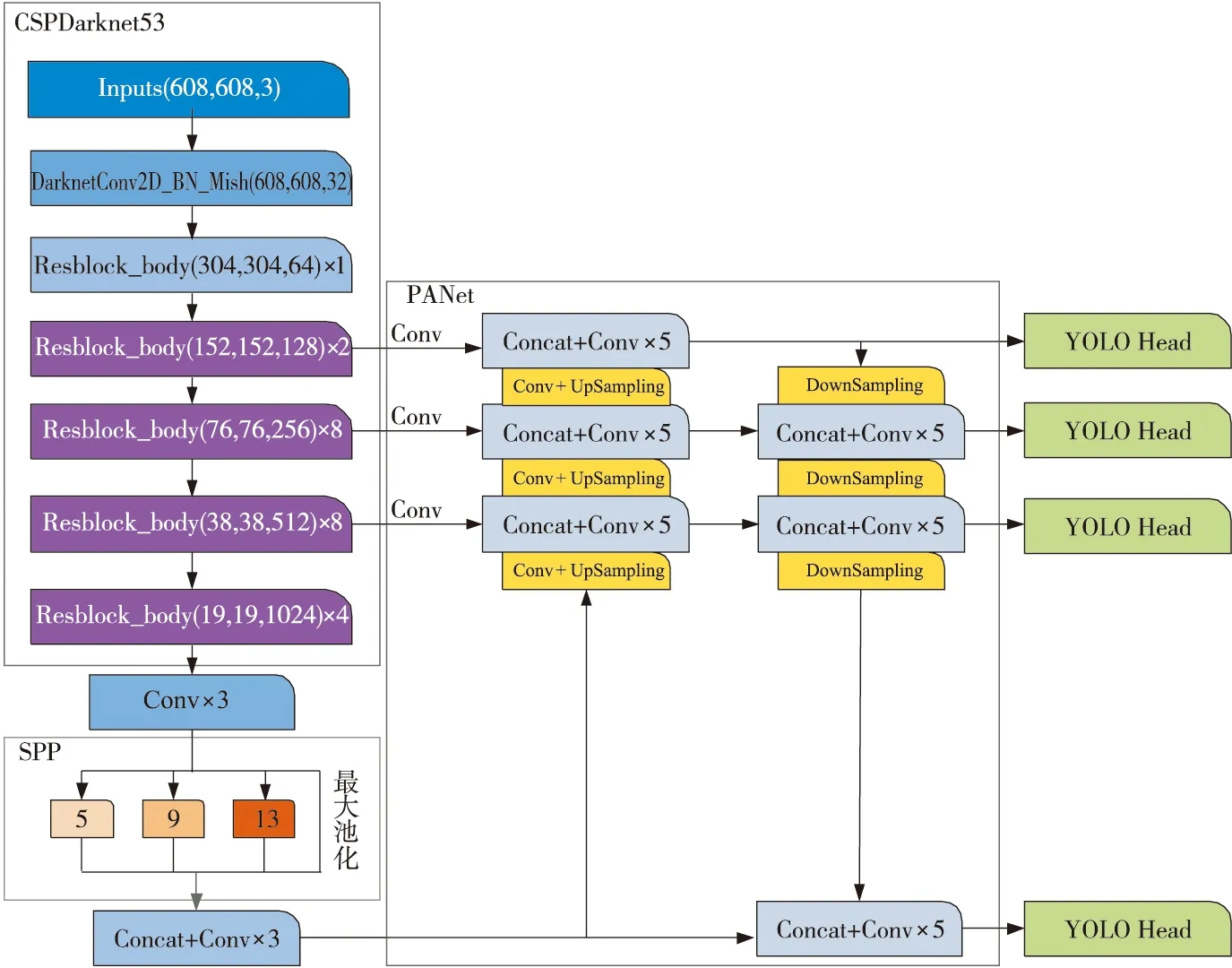
Figure 4 Structure of improved feature extraction network 图4 改进后的特征提取网络结构
YOLOv4算法在3个有效特征层上使用了PANet结构,但对于小目标行人和多姿态行人的识别效果还是不佳。因此,本文对YOLOv4进行如图4所示的改进,使其在4个有效层上进行多尺度特征融合。
3.3 斥力损失函数
遮挡分为类间遮挡和类内遮挡,前者是对象被其他类别的对象遮挡,后者是对象被同一类别的对象遮挡。进行行人检测时,类内遮挡所占比例更大[18]。本文针对类内遮挡提出使用斥力损失函数来优化YOLOv4原有损失函数,利用预测框吸引指定目标的同时排斥周围其他行人目标框,增大预测框与周围其他行人目标框的距离,使得预测框靠近正确目标的同时远离错误目标。计算公式如式(5)所示:
L=LYOLOv4+γ·LRepGT+β·LRepBox
(5)
其中,LYOLOv4表示预测框与其指定目标的损失计算值,本文继续沿用YOLOv4中的损失计算方式;LRepGT表示预测框与周围其他目标真实框的损失计算值;LRepBox表示预测框与周围其他目标预测框的损失计算值;γ和β分别表示2种损失的权重。
当预测框与其他目标真实框靠得太近时,会出现检测不准确的情况。本文通过使用LRepGT减小其他目标真实框对预测框的影响,其计算公式如式(6)~式(11)所示:
(6)
(7)
(8)
(9)
(10)
(11)
其中,P=(lp,tp,wp,hp)和G=(lg,tg,wg,hg)为预测框和真实框,分别由它们的左顶点坐标及其宽度和高度表示;ρ+={P}是所有预测框的集合;ζ={G}是一幅图像中所有真实框的集合;ρ+中的预测框P经过回归计算得到BP;光滑函数Smoothln(x)在(0,1)中连续可微;σ∈[0,1)是调整斥力损失函数对异常值敏感的光滑参数。
当预测框与其他目标预测框靠得太近时,在进行soft-NMS、DIoU-NMS计算过程中容易筛选掉IoU大于阈值的预测框,出现漏检的情况。本文使用LRepBox将不同目标的预测框分开,可以有效缓解这种情况,其计算如式(12)所示:
(12)
其中,BPi和BPj分别表示P中第i个和j个预测框;当预测框之间的交并比大于0时使用I(·)函数进行计算;ε为很小的常数。
4 实验与结果分析
4.1 实验环境
本文在Windows系统下使用keras搭建基于YOLOv4改进的目标检测框架作为实验运行环境。硬件条件为CPU:Intel(R)Core i7-8750H 2.2 GHz,最高睿频4.1 GHz;GPU:NVIDIA GeForce GTX1060Ti。
4.2 实验数据集
本文比较分析了CityPersons[19]、CoCo和CrowdHuman 3个行人数据集的特点。如表1所示,CityPersons中平均每幅图像有7个行人而且行人被遮挡的情况更多,行人多样性和被遮挡情况更符合本文研究内容。CityPersons行人数据集是在CityScapes数据集的基础上建立的,5 000个精细标注的图像中包含35 000个行人,划分为2 975个训练图像、500个验证图像和1 525个测试图像。行人主要分为4种:(1)步行的人,包括跑步、走路和站立姿势的行人;(2)骑行的人,包括骑自行车和摩托车的行人;(3)坐着的行人;(4)非正常姿势的人,包括弯腰、深蹲等姿势的行人。非密集图像上的实验是为了验证本文所提方法是否对孤立对象检测有影响。

Table 1 Pedestrian density in different datasets表1 不同数据集行人密度
4.3 实验参数
本文使用0.000 1的权重衰减和0.9的动量,模型分别以0.000 05,0.000 5和0.005的学习率进行4×103,8×103和30×103次迭代训练,训练批量为10,输入图像大小为608×608像素。
4.4 实验结果
训练集中的真实框经过k-means聚类后得到的12个先验框尺寸,如表2所示,将得到的先验框尺寸分别应用于网络不同尺度的检测层中。

Table 2 Anchorbox sizes after cluster analysis表2 聚类分析后先验框尺寸
本文改进模型在CityPersons数据集上的检测结果如图5所示。
从图5可以看出,不同形态尺度的行人和被遮挡的行人都可以被检测到,且准确率较高,在非密集型图像上也表现出了较好的检测效果,因此,在YOLOv4算法基础上进行改进的行人检测模型具有较好的检测效果。

Figure 5 Detection results of the improved YOLOv4 图5 本文改进的YOLOv4检测结果
为进一步证明改进模型的性能,将处理好的数据集分别在Faster R-CNN、YOLOv3、YOLOv4和改进的YOLOv4 4种模型上进行实验,检测结果对比如图6所示。

Figure 6 Comparison of detection results图6 检测结果对比图
从图6可以看出,相比于其他3种模型,改进的YOLOv4行人检模型架在小尺度、多姿态和被遮挡行人方面检测精度都更高。本文使用平均检测时间Avgtime、准确率Precision、召回率Recall和平均检测精度AP作为检测模型的评价标准。k-YOLOv4表示只对原YOLOv4模型进行k-means改进,P-YOLOv4表示只对原YOLOv4模型进行多尺度融合改进,检测结果对比如表3所示,6种检测模型的P-R值变化如图7所示。
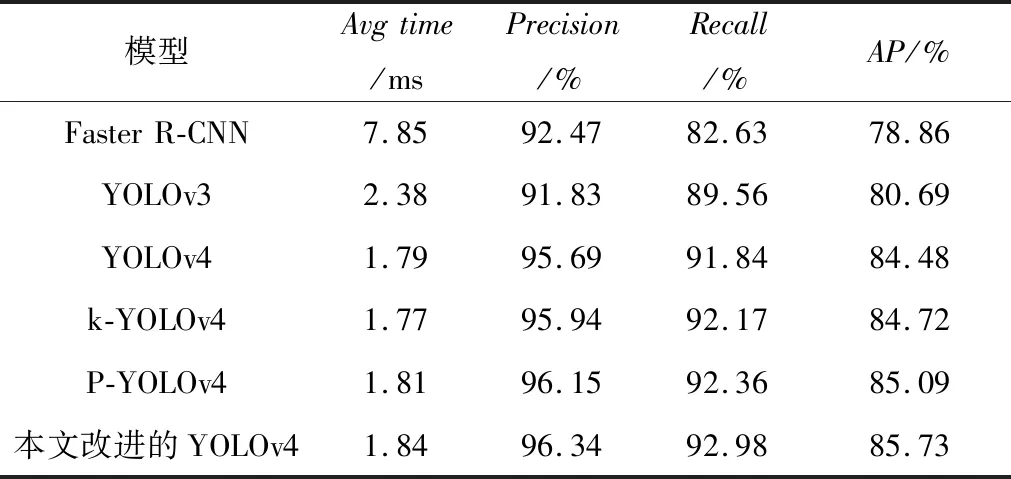
Table 3 Comparison of results of different detection models表3 不同检测模型检测结果对比表

Figure 7 Comparison of P-R values of different detection models图7 不同检测模型P-R值变化对比图
从表3可以看出,在这6种检测模型中,YOLOv3的平均检测时间远远少于Faster R-CNN的,但准确率略低于Faster R-CNN的;Faster R-CNN的平均检测时间过长,达不到实时检测的目的;YOLOv4的平均检测时间较YOLOv3的少0.59 ms,平均检测精度提高了3.79%,且召回率也有所提升;k-YOLOv4和P-YOLOv4相比于YOLOv4检测效果均有所提高;改进的YOLOv4检测模型的平均检测时间略高于YOLOv4的,但召回率提高了1.14%,平均检测精度也提高了。从图7可以看出,改进的YOLOv4检测模型P-R值大于其余5种检测模型,一方面是因为聚类分析为先验框选择了合适的尺寸,使得目标定位更准确,多层的多尺度融合可以更好地检测小目标和多姿态的行人;另一方面是因为使用斥力损失函数提高了被遮挡行人的检测精度。总之,实验表明本文提出的YOLOv4改进模型具有更好的检测效果。
相同迭代次数下,截取的6种检测模型训练过程中的loss值变化情况如图8所示。
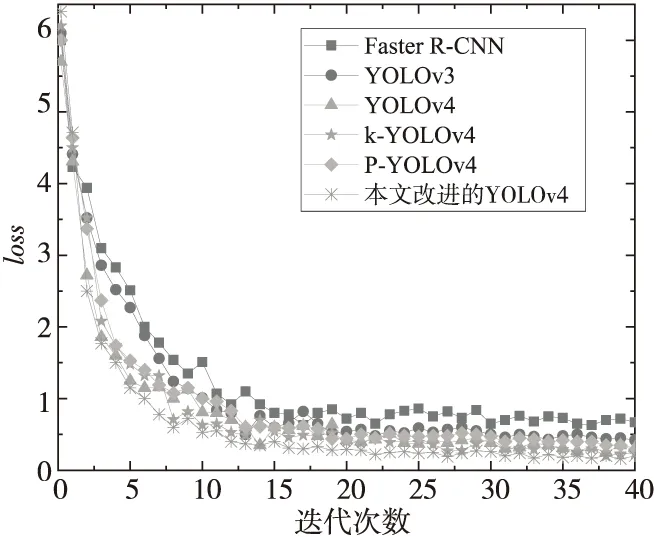
Figure 8 Change trend of loss values of different detection models图8 不同检测模型loss值变化对比图
从loss值变化对比图来看,本文改进的YOLOv4检测模型开始训练时loss值相比其他6种模型都大,经过训练后loss值开始下降并逐渐趋于平稳,收敛效果更好且收敛值更低。
本文还用自己采集的数据集进行了测试,检测结果如图9所示,说明进行多尺度特征融合对检测小目标、多姿态行人是有效的,斥力损失函数的使用也提高了被遮挡行人的检测精度。

Figure 9 Diagram of detection results图9 检测结果图
5 结束语
为了提高多尺度、多姿态行人的检测精度,本文对LOYOv4算法进行了以下改进:首先,使用k-means聚类算法对行人数据集的真实框尺寸进行分析,根据聚类结果确定先验框尺寸大小;其次,利用改进的PANet特征金字塔进行多尺度特征融合。针对行人遮挡问题,提出使用斥力损失来优化损失函数,利用预测框排斥周围其他行人目标,使预测框靠近正确目标的同时远离错误目标。实验结果表明,相比于YOLOv4和其他行人检测模型,本文提出的改进模型可以大幅度提高行人检测的准确率。
