基于多尺度优化感知网络的口罩检测方法*
2022-08-20赵绪言
苟 淞,赵绪言,侯 松,李 威
(西南交通大学计算机与人工智能学院,四川 成都 611756)
1 引言
新冠肺炎(COVID-19)疫情给全世界人民的生活造成了严重的危害,在各国政府和医疗系统的共同努力下,新冠肺炎疫情正逐步得到控制。根据中华人民共和国国家卫生健康委员会疾病预防控制局发布的信息可知,口罩是预防呼吸道传染病的重要防线,可以降低新型冠状病毒感染风险。口罩不仅可以防止病人喷射飞沫,降低飞沫量和喷射速度,还可以阻挡含病毒的飞沫核,防止佩戴者吸入[1]。科学佩戴口罩,对于新冠肺炎、流感等呼吸道传染病具有预防作用,既保护自己,又有益于公众健康[2]。
因此,智能口罩检测成为了一项重要的任务,可以督促人们在公共社交场合佩戴口罩,对于维护公众健康有着重要的意义。然而,基于深度学习的口罩检测是一项全新的任务,其核心主要是2个方面:一是获取人脸目标在图像中的位置信息;二是判断该人脸是否佩戴口罩。目前口罩检测的相关研究和方法十分有限。该任务面临着以下巨大的挑战:
(1)如图1a所示,在口罩检测的应用场景中,首先需要对人脸进行检测,而人脸具有尺度多变、数量冗大、表情多样、视角差异、局部遮挡和化妆伪装等特征,这些特征通常会对检测方法带来较大的影响,导致误检或漏检。
(2)如图1b所示,口罩的外观具有多样性,如款式多样、颜色各异、带有花纹图案,且侧脸戴口罩特征不明显等,给口罩检测算法的设计带来了困难。并且,当人戴上口罩后,部分面部被遮盖,也会增加人脸检测的难度。
(3)如图1c所示,未正确佩戴口罩(口罩没有遮住口鼻或置于其他位置等)和面部局部被遮挡,会对口罩检测造成干扰,容易在戴口罩与未戴口罩两类间造成混淆。
按照现有的通用深度学习目标检测方法,口罩检测任务可以由单阶段目标检测模型或两阶段目标检测模型来完成。当前通用单阶段目标检测模型有CenterNet[3]、FCOS[4]和YOLOv1[5]等Anchor-Free检测模型,也有基于Anchor 机制的SSD(Single Shot multibox Detector)[6]、YOLOv2[7]和YOLOv3[8]等检测模型。通用2阶段目标检测模型中,R-CNN[9]系列模型的检测效果较为出色,该类模型的推理过程分为2个阶段,第1阶段通过滑动窗口推测出目标可能的位置坐标,第2阶段对预测框进行分类和评估。之后的Faster R-CNN[10]抛弃了传统的滑动窗口和Selective Search生成检测框的方法,直接使用RPN(Region Proposal Network)生成检测框,提升了检测框的生成速度。然而,上述通用深度学习目标检测模型都缺乏针对口罩检测特性的独有设计,在多尺度感知方面仍有不足,造成检测效果不够理想。

Figure 1 Examples of difficulties in face mask detection图1 口罩检测困难示例
人脸检测是口罩检测的重要组成部分。张修宝等[11]提出的口罩检测方法具有重要的意义,该方法先进行人脸检测,再对检测结果进行戴与未戴口罩分类。近年来,研究人员提出了一批专用的人脸检测网络,例如用于人脸检测与对齐的三级联CNN(Convolutional Neural Network)[12]网络MTCNN(Multi-Task Convolutional Neural Network)[13]、单阶段人脸检测器PyramidBox[14]和RetinaFace[15]等。其中PyramidBox基于FPN(Feature Pyramid Network)[16]进行了优化,提出低层级特征金字塔网络,充分结合高层级环境语义特征和低层级面部特征,能够单步预测所有尺度的人脸。目前,能够将高层级特征和低层级特征进行结合,在多尺度上进行感知,并作为专用口罩检测的方法还非常少。
本文提出了一种多尺度优化感知的口罩检测方法——PyramidMask。本方法采用ResNet50作为骨干网络,保证深层的戴口罩人脸的特征能够被有效地提取;在 FPN思想的基础上,结合骨干网络的特性,设计尺度感知网络和高密度先验框,增强检测模型的多尺度感知能力,保证口罩检测模型在处理不同尺度人脸、口罩时的性能;设计图像拼接的数据增强方法,增强训练集中目标的多尺度特征,同时在数量上扩充数据集。上述3个优化点的结合,能够有效解决口罩检测所面临的3个挑战。本文方法在公开的口罩检测数据集[17]上进行了测试,相较于基准方法,在未戴口罩和戴口罩的检测召回率上分别有12.5%和5.4%的提升,在未戴口罩和戴口罩的检测精确率上分别有4.1%和6.0%的提升;在多尺度检测实验中,本文方法的检测精度也领先于主流的单阶段检测模型YOLOv3和CenterNet,以及两阶段检测模型Faster R-CNN R50 FPN;然后,通过对原训练数据进行图像拼接增强,使得本文方法的检测精度又有进一步的提升。
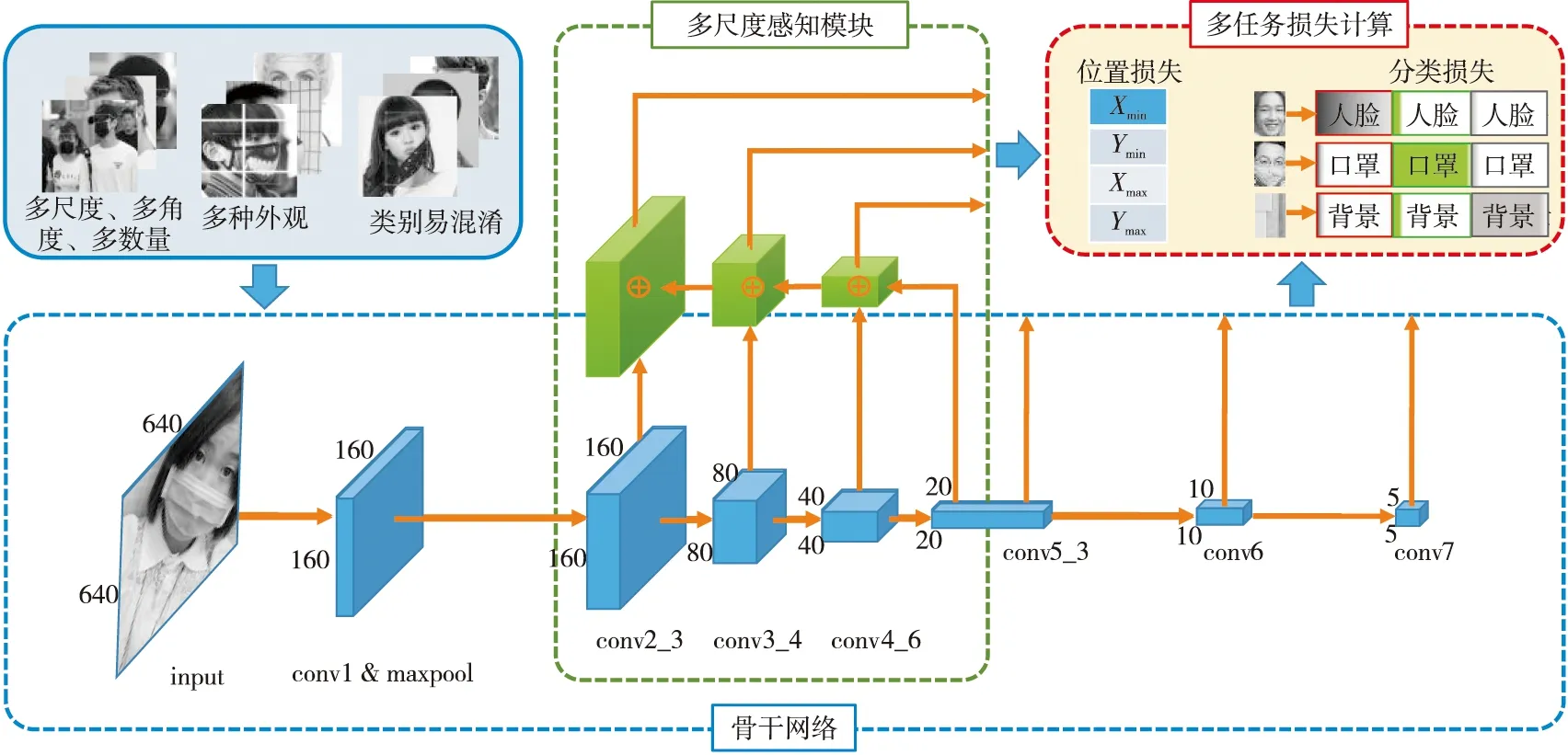
Figure 2 Network structure of PyramidMask 图2 PyramidMask口罩检测方法网络结构
2 PyramidMask口罩检测方法
如图2所示,本文提出的PyramidMask口罩检测方法为一个端到端的单阶段检测模型,由骨干网络、多级尺度感知模块和多任务损失计算3个部分组成。使用ResNet50作为骨干网络,负责特征提取,生成特征图,提高模型对未戴口罩人脸和戴口罩人脸特征的提取性能;设计多尺度感知优化的尺度感知网络,提取足够的浅层图像信息和深层语义信息,减少特征未对准和细节丢失的影响;损失计算是多任务的,分为位置损失和分类损失2个部分,对尺度感知网络的每一层输出计算损失,计算L1范数得到位置损失,计算softmax和交叉熵得到分类损失。PyramidMask每进行一次推理,会输出2部分信息:一是预测的目标框位置,二是对应目标框的分类置信度。
2.1 骨干网络
卷积神经网络CNN利用卷积核与原始图像或特征映射进行卷积,提取更高层级的特征。但是,研究人员发现,当卷积神经网络的深度超过19层时,随着卷积层深度的继续增加,网络在训练集和测试集上的性能却降低了,这是因为较浅层和较深层的网络在训练时的优化难度不一样,且难度的增长并不是线性的,越深的网络越难以优化。
ResNet[18]通过引入如图3所示的残差块(Bottleneck Design)在输入和输出之间建立了一条直接的关联通道,从而使得强大的有参层能集中精力学习输入和输出之间的残差。检测、分割和识别等领域的很多方法都是在ResNet的基础上完成的。
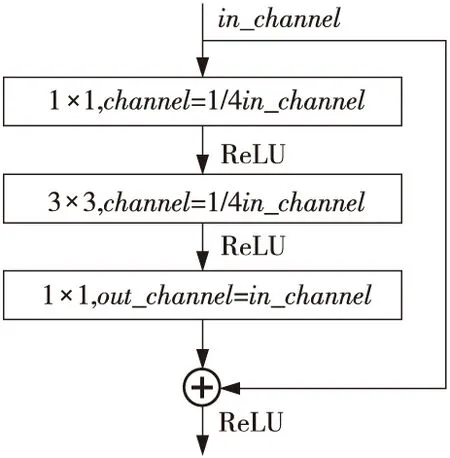
Figure 3 Bottleneck design for ResNet(50/101/152)图3 ResNet(50/101/152)的残差块
本文所提出的口罩检测方法PyramidMask,使用ResNet50作为骨干网络,在面对外观多样、角度各异的口罩以及人脸时,相较于VGG(Visual Geometry Group)[19]网络,有着更佳的深层特征提取性能[20],能为后续的尺度感知网络提供更有效的、自上而下的和最初始的多尺度的语义信息和特征图。
2.2 尺度感知网络的设计
人脸、口罩这类尺度多变的目标,对检测模型的多尺度检测性能有很高的要求。尤其是针对图像中像素较少的小尺度目标,在经过逐层卷积操作和下采样后,在网络末端,这些小尺度目标的特征会变得更小且更不明显。骨干网络对图像中物体特征进行提取时,浅层网络分辨率高,提取到的是目标的细节特征,深层网络分辨率低,提取到的更多是目标的语义特征。例如,SSD、YOLO等模型在增加网络深度的同时,却没有充分利用浅层特征,造成模型对口罩、人脸这类多尺度目标的检测效果不理想。
针对这一问题,在 FPN思想的基础上,本文设计尺度感知网络的核心思路是:
(1)将骨干网络的浅层细节信息和深层语义信息充分融合,避免细节丢失;
(2)通过高密集的先验框(Anchor)采样,保证小尺度的人脸、口罩目标也有高召回率。
设计的尺度感知网络结构如图4所示,左边的网络自底向上是骨干网络ResNet50的正向传播过程,特征图经过卷积核计算,尺度会越来越小;右边的网络自上而下,对更抽象、语义更强的深层特征图进行上采样。在参考了FPN设计思想的基础上,本文选择ResNet50中4个残差块各自的最后一层作为特征图提取层,即conv2_3、conv3_4、conv4_6和conv5_3,再将提取的特征图与右边的上采样网络横向连接叠加(横向连接的2层特征的空间尺寸相同),组成完整的尺度感知网络,并在每层进行独立预测。设计高密度先验框,在网络6个从上至下的特征层中分别设计了25 600,6 400,1 600,400,100和25,总计34 125个先验框,相较于SSD的8 732个先验框,在数量上有较多的增加,从而保证了对不同尺度目标检测的高召回率。
至此,浅层特征得到了语义信息的增强,每一层预测所用的特征图都融合了不同分辨率、不同强度的特征,配合高密度先验框,可以增强对多尺度目标,尤其是小尺度目标的检测性能。

Figure 4 Structure of multi-scale awareness network图4 尺度感知网络结构
2.3 多任务损失函数的设计
多任务损失函数由2部分组成:一个是位置损失Lloc,另一个是分类损失Lconf。在训练过程中,口罩检测模型预测包括3类矩阵:先验框坐标矩阵Ppro(Ppro∈Rm×4)、分类置信度矩阵Pconf(Pconf∈Rm×c)和预测框坐标矩阵Ploc(Ploc∈Rt×4,t∈[0,m])。训练数据中标注的内容包括2类矩阵:目标真实框坐标矩阵Tloc(Tloc∈Rn×4)和目标真实框类别矩阵Tconf(Tconf∈Rn×1),表示目标真实框坐标集合和目标真实框类别集合。其中,m为先验框个数,n为正样本个数,t为预测框个数,c为目标类别个数,Rm×4为一个m行4列的矩阵。
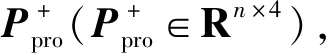
(1)
其中,i为正样本中的先验框序号,j为预测框的序号。
(2)
其中,c为目标类别个数,本文中c=3,表示存在戴口罩类、未戴口罩类和背景类3个类别。
(3)
最后,总的损失函数如式(4)所示:
L=Lloc+Lconf
(4)
3 实验及结果分析
3.1 数据集
本文实验使用公开口罩检测数据集[17],共计7 959幅RGB图像(训练集6 120幅,测试集1 839幅),标注框分为戴口罩和未戴口罩2个类别,其中戴口罩标注有3 970个,未戴口罩标注有9 586个。该数据集由WIDER FACE[21]人脸数据集和MAFA[22]人脸遮挡数据集中部分数据组成。WIDER FACE人脸数据集共计32 203幅RGB图像(含已标注的训练集12 880幅,验证集3 226幅),训练集中标注内容只包含159 420个人脸类(作为未戴口罩类)。MAFA人脸遮挡数据集共计30 811幅RGB图像(训练集25 876幅,验证集4 938幅),其训练集中只标注出了29 430个遮挡的人脸类(筛选出部分作戴口罩类)。
口罩检测数据集中人脸和口罩的尺度多样,角度丰富,口罩样式较多,且包含有手部和其他非口罩物品对面部的遮盖等,数据集示例如图5所示。

Figure 5 Examples of public face mask detection dataset图5 公开口罩检测数据集示例
3.2 评估标准
参照公开口罩检测数据集[16]的评估标准,本文采用精确率precision和召回率recall作为本文实验的评估标准。评价方法的混淆矩阵如表1。

Table 1 Confusion matrix for evaluating method表1 评价方法的混淆矩阵
精确率precision和召回率recall的计算分别如式(5)和式(6)所示:
(5)
(6)
3.3 对照实验
模型的训练、推理均在Ubuntu16.04系统上完成,代码使用PyTorch深度学习框架开发。硬件平台为4块NVIDIA GeForce GTX TITAN xp。输入图像尺寸大小为640×640,batchsize设置为16,训练采用动态学习率,初始值为0.000 1,前8 400批次的训练,每400个批次将学习率提升0.5倍,从第13 000批次的训练开始,每6 000个批次将学习率降低一半。使用SGD(Stochastic Gradient Descent)优化器进行反向传播和更新。
实验在原始的公开口罩数据集上训练本文的PyramidMask模型(单阶段)、CenterNet模型(单阶段)、YOLOv3模型(单阶段)、Faster R-CNN R-50-FPN(两阶段)模型和基准方法的SSD模型(单阶段),实验结果如表2和表3所示。
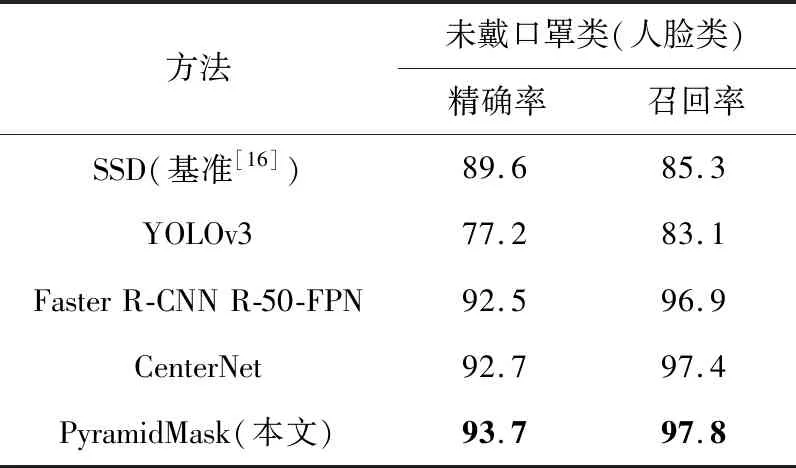
Table 2 Results of controlled experiment without masks表2 未戴口罩类对照实验结果 %
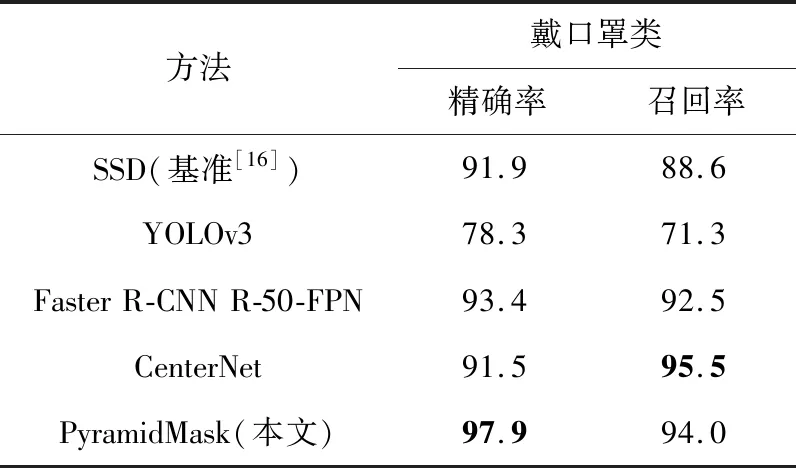
Table 3 Results of controlled experiment with masks表3 戴口罩类对照实验结果 %
相较于基准方法[17],本文提出的PyramidMask在未戴口罩和戴口罩的召回率上分别有12.5%和5.4%的提升,在未戴口罩和戴口罩的检测精确率上分别有4.1%和6.0%的提升。YOLOv3轻量的模型结构对小目标特征的提取能力不足。CenterNet和Faster R-CNN在经过下采样后,因为CenterNet网络底层特征图分辨率比Faster R-CNN的更高,保持了更多的细节特征,所以对于本文实验的小尺度数据,CenterNet召回率更高,为网络后续的热力点估计奠定了良好的基础,进而有着更高的精确率。
3.4 多尺度检测实验
如图6a所示,从左至右,将公开口罩检测数据集[16]的测试集中的图像调整为原始图像、相较于原始图像边长的75%,50%和25%,生成多尺度的测试集,并使用3.3节中完成训练的模型在不同尺度的图像上进行测试,以获取Faster R-CNN R-50-FPN、YOLOv3、CenterNet和PyramidMask模型在不同尺度目标上的检测性能。
图像在输入到检测模型时,模型会对图像进行分辨率调整,这会造成上述多尺度图像输入到模型时并没有严格按照所设计的尺度。针对这一问题,本文对输入图像进行填充处理,如图6b所示,使调整尺度后的图像在分辨率上与原始图像一致,从而确保多尺度检测实验的严谨性。
实验结果如表4和表5所示,PyramidMask模型在4个检测尺度上都有较高的精确率和召回率。
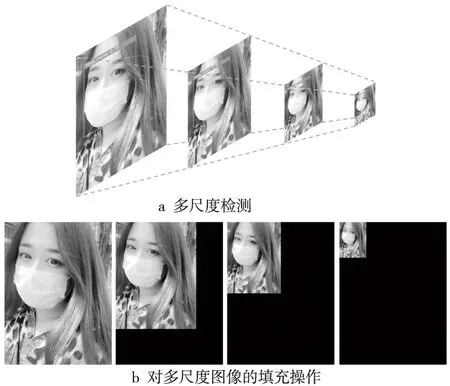
Figure 6 Multi-scale detection and padding operation on images图6 多尺度检测和图像的填充操作
3.5 数据增强的方法
为了获取更多尺度的目标数据,需要增加数据量。本文采用的方法为:对公开口罩检测数据集中的图像进行水平翻转,再进行四合一图像拼接处理,其对应的标注信息同时进行翻转和拼接。进行图像拼接处理具有以下优点:
(1)将4幅图像尺度缩小后拼接,不仅获得了多尺度的目标,也增加了单幅图像中目标的数量。可以模拟人脸尺度多变、数量冗大的特征。
(2)增加了单幅图像背景的复杂度。
(3)变相增加了训练时的批处理数据量[23]。
数据增强后,训练集扩充到了15 300幅图像,四合一图像拼接的数据示例如图7所示,图7a为原始图像,图7b为拼接后的图像。
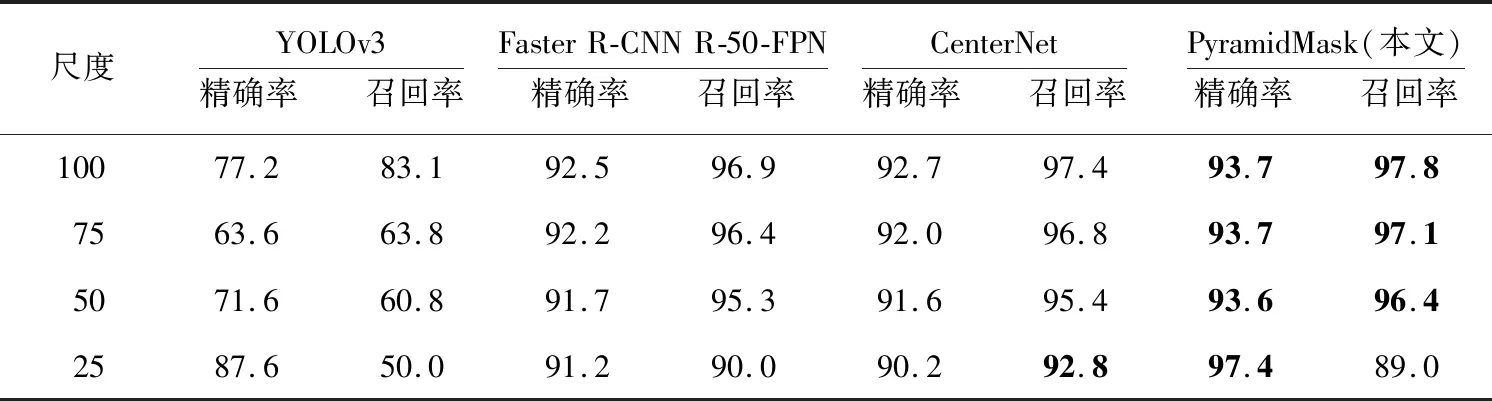
Table 4 Results of multi-scale detection experiment without masks表4 未戴口罩类多尺度检测实验结果 %
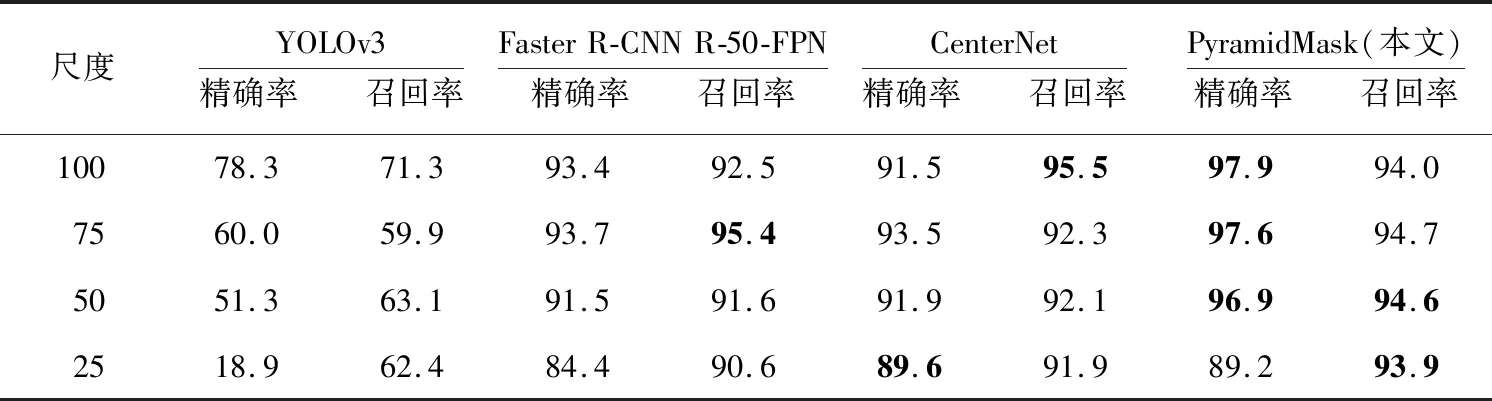
Table 5 Results of multi-scale detection experiment with masks表5 戴口罩类多尺度检测实验结果 %

Figure 7 Example of image mosaic expansion of mask detection dataset图7 口罩检测数据图像拼接扩充示例

Figure 8 Example of experiment on correct wearing of mask图8 口罩正确性佩戴检测实验结果示例
3.6 数据增强实验
3.5节提出了四合一图像拼接的数据增强方法后,本节实验使用的训练数据为:数据增强后的口罩检测数据再加上未增强的口罩检测数据集,共计15 300幅图像。其他实验条件(包括测试集)与3.3节中的相同。实验结果如表6和表7所示。

Table 6 Results of data expansion experiment without masks表6 未戴口罩类数据增强实验结果
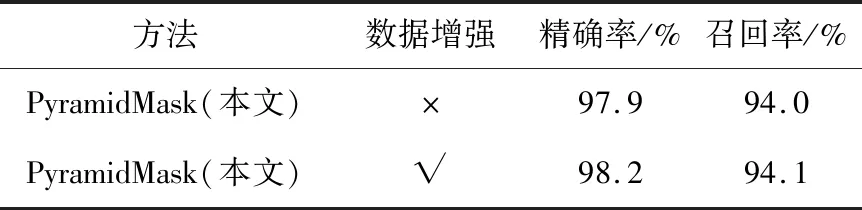
Table 7 Results of data expansion experiment with masks表7 戴口罩类数据增强实验结果
数据增强后,PyramidMask方法的精确率和召回率均有一定的提升。未戴口罩类中,在保持精确率的情况下,召回率提升了0.2%;在戴口罩类中,在召回率提升0.1%的情况下,精确率提升了0.3%,表明使用拼接数据增强方法后的数据训练模型,对提高检测性能有一定的帮助。
3.7 口罩正确性佩戴检测实验
为检验本文模型对已戴口罩但佩戴不正确(没有覆盖到口鼻)现象的检测能力,自建和网络爬取了共计408幅未正确佩戴口罩类的图像,并使用3.3节中训练完成的各模型进行推理、对照验证。评判标准:若模型检测结果为未戴口罩类,则模型检测正确;若模型检测结果为戴口罩类,则模型检测错误。统计各模型检测正确的比例,比例越高,说明模型对未正确佩戴口罩检测的性能越好。实验结果如表8和图8所示。PyramidMask检测正确率高于其他3个对照组,有一定的正确佩戴口罩检测能力,表明其网络结构对数据特征有较优的提取和拟合能力。

Table 8 Results of experiment on correct wearing of mask 表8 口罩正确性佩戴检测实验结果
3.8 检测效果
本节在多尺度、多数量、多角度、多种外观口罩和未遮住口鼻等图像上,使用本文提出的PyramidMask口罩检测方法进行测试,以检验PyramidMask方法的鲁棒性。如图9所示,PyramidMask在不同类型的图像中,都能够检测出人脸和戴口罩的人脸,表现出了较好的检测效果。

Figure 9 Results of mask detection with PyramidMask图9 PyramidMask方法的口罩检测效果
4 结束语
本文针对当前专用口罩检测算法缺乏、通用目标检测模型在面对多尺度、多数量、多角度和多外观样式口罩以及人脸检测效果不佳的问题,提出了一种专用的、多尺度感知优化的、单阶段口罩检测方法——PyramidMask。通过设计结合ResNet骨干网络特性的尺度感知网络、高密度先验框、目标尺度特征增强和数量扩充的方法,在包含大量困难检测数据的公开口罩检测数据集上,获得了高于SSD基准、YOLOv3、Faster R-CNN和CenterNet检测模型的检测性能。在多尺度检测实验中,PyramidMask检测模型在多尺度目标的感知能力上也领先于单阶段检测模型YOLOv3、CenterNet和两阶段检测模型Faster R-CNN,表明了PyramidMask模型结构中尺度感知网络的有效性。并且,在公开口罩检测数据集的困难数据上,PyramidMask也表现出了较好的检测效果,体现了本文方法的鲁棒性。当前模型参数仍较为庞大,未来可以尝试在保证检测准确性的情况下,精简模型结构,以确保模型在现实场景中使用的便利性。
