LaneAr:基于编解码实例分割的车道线检测方法
2022-08-19高尚兵汪长春胡序洋李少凡
李 杰,刘 奕,高尚兵,3,汪长春,胡序洋,李少凡
(1.淮阴工学院 计算机与软件工程学院,江苏 淮安 223001;2.江苏科技大学 冶金与材料工程学院,江苏 张家港 215600;3.江苏省互联网移动互联网技术工程实验室,江苏 淮安 223001)
随着深度学习技术的发展,人工智能在安全驾驶、道路区域分割和辅助驾驶方面的应用越来越广泛。车道线检测作为辅助驾驶的重要环节,伴随自动驾驶研究的不断深入,在道路场景的车道线检测方法也各有侧重。根据道路场景和采集到的路面信息的不同,大致可以分为传统的道路图像处理方法和基于深度学习的车道线检测方法。
传统方式进行车道线检测利用Hough变换能够检测直线的特性,将其运用到对图像中的车道线检测,姜立标[1]在对道路静态图像去除天空、建筑等一系列干扰区域后进行灰度化处理,再考虑到路面和车道线的灰度值的差异确定车道线的大致位置,利用改进的Hough变换对每条车道线的极角进行大小和方向约束,得到边缘像素点最多的两个方向,最后用双点去除R-最小二乘法对车道线的离散像素点进行拟合。付利军[2]利用sobel算子进行边缘像素提取,利用边缘检测的梯度方向得到自适应的感兴趣区域(RoI),在确定RoI分割线进行搜索区域定位时,需要对该区域的每一行进行边缘像素的数目进行逐一对比,在面对道路车辆较多时,很难准确地确定RoI的边界。
为了应对传统的车道线检测方法在不同的道路环境中检测效果不佳的情况,国内外的研究者着手将深度学习的方式运用到车道线检测中,建立能够适应多种场景下的车道线检测模型。李梅梅[3]提出的MultiRes+UNet网络针对多次下采样会丢失图像的特征信息引入空洞卷积提取不同尺度的特征,但在污损道路车道线检测效果就会大打折扣。邓天民[4]通过将原有的SegNet网络改进成为非对称的结构,将提取到的特征与二值图像的像素点进行归类从而达到车道线拟合的效果,对于道路上有车辆干扰和道路路面有磨损的情况监测效果不佳。陈立潮[5]针对光照变化、物体遮挡等多种复杂车道环境提出在模型的编码之后添加车道线预测分支、引入辅助损失函数训练分支和语义分割分支,利用双线插值法将前两个分支得到的特征图进行融合,语义分割分支判断融合后的特征图上是否有相应的车道线像素点,然后进行拟合出车道线,在9种不同环境下的车道图像中进行测试能够保证检测的准确性。蒋紫韵[6]预先对道路图像进行处理得到较多的细节信息,在获取到降噪后的二值图像后利用K-means聚类算法定位到图像的感兴趣区域,最后用训练好的全卷积的神经网络模型对聚类后的图像进行车道线检测,利用K-means聚类算法能够避免二值图像中存在的路面阴影和车道线被遮挡情况对后序的车道线检测的影响。
在道路车道图像分割方面,罗嗣卿[7]针对Seg-Net[8]对称编解码模型的编码器部分存在多个不同尺度的卷积层,对它们捕获的不同的感受野进行自底向上通路与跳层进行连接,将每一个卷积获得特征图传递给对应的单尺度特征解码器中,充分利用每个解码器层都能获得多尺度的语义信息。后续相关论文为了使得这类对称型的编解码网络[9]在语义分割的效果和性能上有较大提升,本文提出一种编解码通道注意力机制的网络用于车道线检测的方法,改进的方向主要有两点:
(1)优化编码部分。在语义分割网络中,特征提取的任务主要集中在编码部分,在特征提取网络中加入Ar-Block残差模块和空洞卷积模块,通过优化主干网络的编码能够得到较多语义特征信息。
(2)设计残差网络中通道注意力机制。编码器的残差网络提取到车道线的相关语义特征,通道注意力机制更加注意提取到的车道线语义信息,通过对应通道的元素进行分别加权矩阵相乘得到全新的特征。
1 车道线检测
1.1 总体结构
近年来,通过图像分割方法对道路图像进行处理,将车道线的线性检测问题转化为对图像像素的二分类问题,能够细化图像中车道线的特征信息,以此,本文提出一种改进的非对称的编解码的图像分割车道线检测算法,图像分割主要是对图像中的每一个像素点进行准确的分类预测。总体车道线识别流程如图1所示,LaneAr网络模型总体呈现编解码结构,包括残差模块、空洞卷积和通道注意力机制,将道路图像与车道线的标签文件经过归一化处理后通过本套算法进行训练得到能够识别车道线的模型,在同等的道路环境下,本文训练出来的模型在进行车道线检测有较高的准确率,同时对于车道线被车辆遮挡、天桥光线较暗路面情况也有较好鲁棒性。
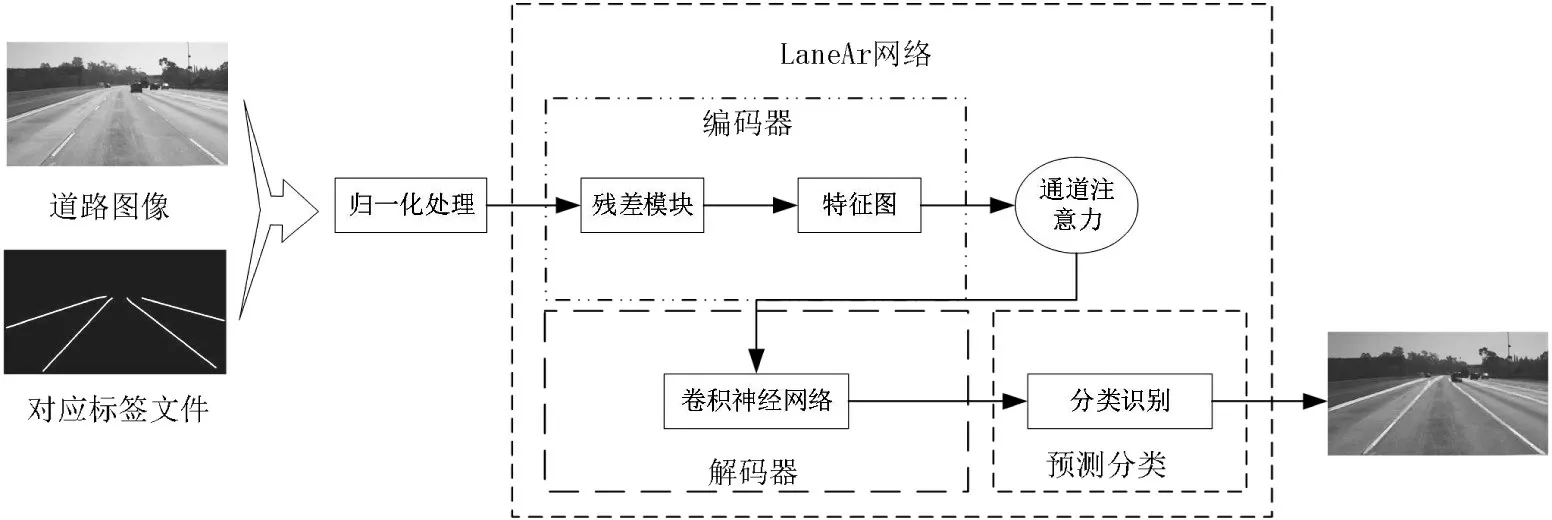
图1 车道线检测流程图
1.2 特征提取
现阶段将图像分割运用到道路场景进行车道线检测的情况很多,在特征提取方面构建Ar-Block残差结构[10]结合卷积核实现下采样操作,在残差结构提取后的卷积使用多种扩张率的空洞卷积(dilated convolution)[11],收集到更多车道线的语义特征。
残差模块中结合BN(Batch Normalization)层[12]进行语义特征提取,提出残差模块对道路图像的车道线进行语义信息提取,如图2所示。残差模块在采用卷积层和BN层结合的思想,将每层卷积层提取到的特征数据重新回归,将其数据值固定在一个分布区间中。在该模块中将输入分为两个阶段,通过左边的多个卷积操作叠加得到的参数量会增加,在右侧进行平均池化和短路连接进行融合,从而减少卷积操作的计算量,得到更多的语义信息。
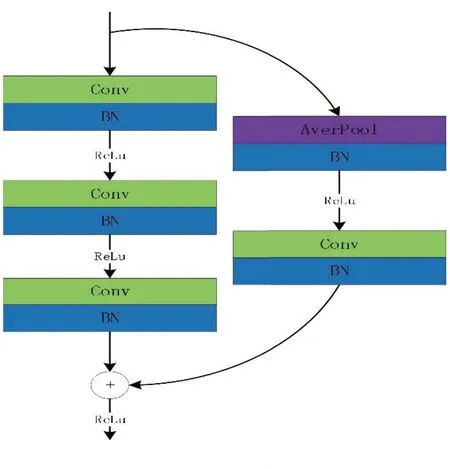
图2 Ar-Block残差模块
在进行图像分割的经典网络中,采用空洞卷积替换传统的卷积网络,在进行图像处理的时候能够在保证原有的图像尺寸的同时增加感受野。卷积通过串联操作,在进行卷积计算时在部分的卷积核中采用不同扩张率的空洞卷积,扩展率是2的倍数,在进行卷积操作的计算量不会因为卷积层的扩展率的增加而增加。
1.3 通道注意力机制
在编解码网络中,由于LaneAr网络编码器部分提取到的感受野区域较为局限,可以通过引导的方式使得提取到的区域包含更多的特征信息,通道注意力机制(channel attention module)[13]将剩余的可用资源合理化的集中向信息量最集中的区域,从而提高网络的表达能力,将解码器提取到的13×13的特征图通过通道注意力机制合理分配资源信息,实现降低特征图中提取到的噪声信息,从而使得网络能够得到更好的语义分割效果。
图3为通道注意力机制的模型,首先将编码器获得原始的特征X作为输入,其大小为H×W的c个特征映射,将原始的特征通过全局平均池化处理后进行卷积操作,再采用ReLU激活函数进行处理使得原始的特征数据更加便于处理,同时,将全局平均池化后的原始特征进行输出,每个通道注意力机制的通道都能得到对应的通道数,通过通道矩阵的Sigmoid函数得到的标量数据在固定的区间,同时数值为C,将标量与原先的通道进行矩阵的加权相乘得到新的通道注意力特征。将两者进行矩阵相乘和Sigmoid激活函数确保通道注意力的权重在0~1之间,最终生成融合通道注意力权重的H×W×C的特征图。

图3 通道注意力机制结构
1.4 损失函数
在图像分割方面,衡量深度学习训练出来的模型好坏的其中一个标准就是损失函数值的大小。龚晓庆[14]在进行医学CT图像分割时提出在语义分割特征图上结合交叉熵损失函数和自适应的预训练权重来帮助网络进行训练,在训练过程中通过调整训练参数和学习率能够降低损失函数的值,从而得到泛化效果更佳的模型。鉴于此,本文提出的LaneAr网络是利用图像分割的方法将道路图像中的车道线像素与非车道线像素分割出来,为了得到最佳的分割效果,LaneAr网络在进行模型训练时采用常用的交叉熵损失函数进行类别分类。式中,x为车道线像素分类的置信度,c为车道线类别和非车道线类别的索引值,分别为0和1,j为通道注意力获取到局部特征图的个数。通过上述的交叉熵损失函数的计算得到的损失函数的值越小,说明车道线的真实值和预测值保持一致。

1.5 总体网络模型
总体的车道线检测模型包括特征提取、像素还原和车道线预测分类三个阶段,特征提取阶段由编码器组成,利用残差模块实现下采样操作,像素还原阶段利用反卷积进行上采样,在语义特征不丢失的情况下得到能够匹配图像编码之前的像素。整体的网络模型如图4所示。利用残差模块作为第一层的特征提取层,在后续每个残差模块后都串联一个卷积层,卷积层中采用维度与残差结构提取维度相同的1×1、3×3的卷积模块,在部分层中运用不同扩张率的空洞卷积扩大感受野,便于后续的解码中进行上采样处理的能够有更多语义进行还原。随着残差结构将图像的像素不断压缩,卷积层采用的卷积核的通道数也在逐渐增加,以此获取到13×13的特征图,将获取到的特征图输入到通道注意力机制剔除特征图通道中的噪声信息后进行第三阶段的像素还原,此时特征图中含有的较多的车道线语义信息,利用多通道的3×3卷积对其进行还原能够尽可能的保留其语义信息。
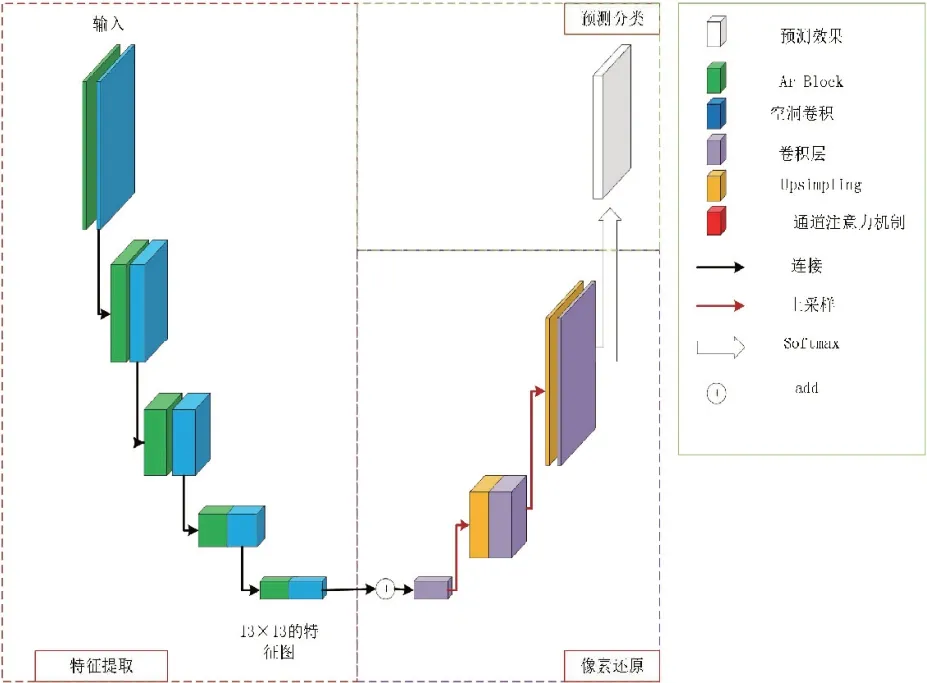
图4 网络结构图
解码器部分主要作用是将提取到的特征图进行像素还原和对特征图进行车道线特征再提取,采用二维的上采样Upsampling模块,为了避免编码器处理后的特征图的参数过多,导致训练时出现过拟合的现象,在解码器部分引入dropout模块同时减少卷积核的通道数,将最后一层的卷积核的维度设置为2并输入到softmax层进行车道线预测分类。
2. 实验结果分析
2.1 实验环境及数据集
算法使用python作为开发语言,利用python中的图像处理的opencv库和神经网络相关的tensorflow框架搭建网络模型。在window10系统上进行训练和测试,硬件环境为i5-6300HQ CPU@2.30GHz、NVIDIA GeForce GTX 950M,显卡的共享内存为6G,能够满足深度学习的最低要求。
实验采用公共数据集tusimple,其中包含3626张原始的道路图像以及对应的车道线标记图像可以用于进行模型训练,2728张图片作为测试图像。图像分辨率为1280×720像素,图像多以白天良好天气为主,其中也存在部分的道路场景车辆拥挤、车道线被天桥阴影遮挡等情况,这些场景可能会影响到本次模型提取车道线的语义特征。在做实验前,对图像做必要的处理,先将标签图像的通道数由8位的单通道转换为24位的RGB三通道,其次为了方便后期的归一化处理,将所有的原始图像的像素固定在412×412像素。
2.2 算法评价标准
针对实验在道路场景实验的训练和检测效果,本文引用准确率(Acc)作为评价指标,使用该模型在tusimple数据集中进行验证,其准确率的计算公式如下:

式中,设定模型检测出来的线段与标准在图像中的线的交并比IoU为0.50,TP(true positives)和TN(true negatives)分别代表大于等于IoU阈值被标注为车道线、图像中没有标记同时模型检测为非车道线的像素,total是指总的像素点的个数。
其次,在对图像进行分割时用F-score进行逐像素级的分类评价:

其中Precision为精准度、Recall为召回率表示方式如下:

式中,FP(False Positive)表示被正确标记为车道线像素但IoU小于阈值的样例,FN(False Negative)表示图像中被标记但模型中没有被检测到的样例。本次实验设置的β值为1,则化简公式为

2.3 训练过程
在实验过程中需要下载相关的tusimple数据集的预训练的权重做迁移训练,由于训练集数据量为3000张图片,采用的batch_size为4,使得模型的收敛速度减慢,初始的学习率为10×e-3,在训练过程中利用Adam自适应的优化器调整学习率来降低损失值,随着迭代次数的增加,学习率在不断的减小的同时会在10×e-4时趋于收敛,在学习率不断减小的过程中,模型在训练到50次迭代时会趋于平缓,在进行模型训练和车道线检测时的损失值会迅速地收敛,训练时采用early stopping函数当损失值一直趋于一个值并不出现减小的迹象时停止训练,降低过拟合的出现的几率。
2.4 实验结果
为了验证该算法模型在车道线检测方面的鲁棒性,选取了几种经典的语义分割网络在相应的数据集上进行实验,分别对实验的准确度(Acc)和相同IoU为0.4的阈值下F-socre的表1列出实验对比结果。
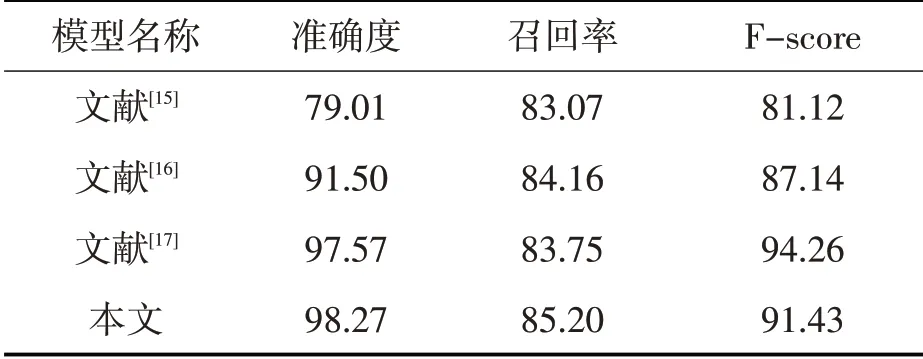
表1 不同车道线检测模型实验对比 %
Lu[15]运用U-net网络在高分辨率的无人机影像数据集中进行遥感车道线检测,通过深度学习与图像视觉特征相结合的方法对车道线记性检测和拟合,在准确度上有待提升,仅为79.01%。Zeng[16]将深度卷积神经网络和聚类方法应用到火车轨道上进行实验,由于国内外对轨道线的研究相对较少,手工收集铁路图像数据并通过专业的车道线图像数据集标注软件labelme进行标注,进行训练的数据图像在1020张左右,训练后得到的模型对轨道车道线测试准确度达到91.52%。Long[17]利用特征金字塔池化模块将提取到的特征图像分化为四种不同尺寸的池化特征,最后将这些特征图层一起输入到FCN层得到预测效果,该网络在图像的语义分割效果较好,其IoU(交并比)能够达到77.3%。
基于Lane-Ar的车道线检测算法利用残差结构提取更多的语义特征,在车道线被遮蔽的环境下也有较好的检测效果,如图5所示,能够很好地适应真实驾驶环境的道路车道线场景,模型在车道线检测的准确率能够达到98.72%,F-socre能够到达93.43%,均优于上述提到的几种车道线的检测算法。

图5 车道线检测原图和效果图
为了进一步地验证本文方法复杂场景中的车道线检测效果,使用了包括白天、夜晚、城市道路、车辆遮挡、隧道等道路场景图像进行训练和测试,从表2可以看出不同道路场景会很大影响车道线检测的效果,方法能够适应隧道光线较暗和车辆遮蔽场景使用要求。

表2 不同道路场景下的准确率
3 总结
通过研究现阶段的车道线检测的方法和编解码模式的网络,提出了一种利用残差网络作为编码器的编码解码网络Lane-Ar用于车道线检测,在残差结构中结合BN层使得提取到的特征数据的分布区间相对固定,配合着串联卷积层中的不同扩张率的空洞卷积扩大感受野;同时利用通道注意力机制增强特征提取效果,在解码器部分通过二维的上采样层和减小相关卷积核的通道数的方式减少参数量,达到精确检测车道线的效果。下一步工作主要是在保证复杂环境中精准检测到道路图像中的车道线,同时提高车道线检测模型处理单张图像的速度。
