基于词典模型融合的神经机器翻译*
2022-08-19季佰军段湘煜
王 煦,贾 浩,季佰军,段湘煜
(苏州大学自然语言处理实验室,江苏 苏州 215006)
1 引言
机器翻译[1 - 3]的主要研究目的是通过计算机实现将一种语言自动翻译成另一种语言。传统的统计机器翻译SMT(Statistic Machine Translation)[4]系统性能提升缓慢。但是近年来,随着神经机器翻译NMT(Neural Machine Translation)[5,6]的发展,机器翻译性能得到大幅度提升,机器翻译再次得到了广泛关注。2017年Vaswani等人[7]提出的基于自注意力的Transformer模型在翻译速度和质量上相比于SMT取得了较大的提升。有监督的神经机器翻译需要平行语料来指导训练,往往平行语料的数量决定着最终翻译模型的质量,但是平行语料的获取不仅需要耗费大量人工翻译时间,一些小语种的平行数据也很难获取,这在一定程度上阻碍了机器翻译的发展。由于单语语料通常很容易大量获取,近几年只使用单语语料的无监督神经机器翻译[8]渐渐进入人们视野。
多个训练无监督跨语言词嵌入训练方法[9,10]的提出,使得只使用单语语料训练无监督神经机器翻译模型成为了可能。而在结合使用降噪自编码器[11]和反向翻译[8]后,无监督神经机器翻译效果也得到了显著提升。BERT(Bidirectional Encoder Representation from Transformers)[12]模型利用Transformer模型构建框架,使用无监督方法在单语数据上进行预训练并生成语言表征模型,可以较好地挖掘出词之间的关系。随后XLM(Cross-lingual Language Model)[13]模型在此基础上进一步扩展训练生成跨语言的语言模型,让不同语言中意思相近的词在词嵌入中的位置相对一致,最终有效提高了无监督机器翻译模型的训练效果。
虽然可以利用大量的单语语料训练模型,无监督机器翻译模型仍与使用平行数据训练的有监督模型的效果有较大差距。反向翻译方法虽然可以建立伪平行语料来训练模型,但是因为其初始训练的语言模型是建立在单语数据上的,没有平行数据指导训练过程,并不能完全在2种语言中意思相近的词之间建立联系,往往会导致翻译的伪数据质量较差,在之后的训练中这些翻译错误会不断累积,导致实际学习到的模型逐渐偏离正确的目标模型。
针对以上问题,本文提出2个方法,以中-英方向模型的训练为例:(1)用一个中-英的双语词典对中文单语数据进行替换,利用中文词的对应英文翻译词在训练过程中建立2种语言间的联系;同时,在训练2个方向模型的过程中,利用英-中方向训练出来的模型,对中-英方向模型的词嵌入(Word Embedding)进行修正,缩小不同语言间的差异。(2)双编码器融合训练方法,利用英-中方向训练出来的模型指导中-英方向模型的训练,充分利用各个方向学到的语义信息。实验结果表明,本文方法的BLEU值在中-英等数据上相比基线无监督翻译系统的分别提高2.39和1.29,同时在英-俄和英-阿等单语数据上也取得了不错的效果。
2 相关工作
随着无监督神经机器翻译的不断探索,越来越多的人注意到虽然可以使用大量的单语数据训练模型,但是仍然不能很好地在不同语言之间建立联系。针对这个问题,Lample等人[14]使用联合BPE(Byte Pair Encoding)[15]的方法将不同语言数据合并进行BPE。当源语言和目标语言相关时,它们会天然地共享部分的BPE词语,从而拉近2种语言在词嵌入空间的分布。之后Lample等人[13]进一步扩展此方法,提出了XLM模型,将多种语言放在一起采用新的训练目标进行预训练,从而使模型能够掌握更多的跨语言信息。对于预训练后的后续任务(比如文本分类或者翻译等任务),训练语料较为稀少的语言可以利用在其他语料上学习到的信息协助当前语言的学习。随后Wu等人[16]针对反向翻译中存在的错误积累问题,提出使用提取-编辑方法代替原本的回译方法,取得了不错的效果。Ren等人[17]则通过生成的跨语言词嵌入在2种语言的单语数据中寻找相似句,并通过对其重写生成伪平行训练语料来训练翻译模型。
最近Duan等人[18]提出了DIV(Dictionary-based Independent View)方法,用词典对单语数据进行替换,来进行无监督机器翻译模型的训练。首先使用Muse词典[9]对源端单语数据进行替换,用替换过的源端单语数据与未替换的目标端单语数据训练源端到目标端的无监督机器翻译模型。先在预训练步骤中使用替换数据进行训练,让模型学习不同语言的信息,之后再使用单向训练与双向训练建立无监督机器翻译模型,最终取得了很好的效果。
本文方法与DIV[18]的步骤类似,但是本文方法将源端与目标端的数据都进行了替换,并且将替换的数据与原数据合并,使用合并的数据训练各个方向的模型。同时本文还提出了2个方法:(1)对使用替换数据训练得到的预训练模型的词嵌入进行替换,利用一个方向训练出来的模型,对另一个方向模型的词嵌入进行修正,充分利用2个方向的训练结果。(2)在训练阶段,本文在传统的编码器-解码器[7]结构基础上,提出双编码器融合训练方法,在训练过程中同时使用2个方向的模型进行训练,通过一个权重调整各个方向模型的重要性,充分利用它们在之前训练中学习到的知识。
3 模型融合训练方法
3.1 无监督机器翻译
无监督机器翻译通常遵循3个步骤:初始化、建立语言模型和反向翻译。
(1)初始化:针对机器翻译任务,希望利用模型预训练初始化建立2种不同语言间最初的联系,以方便之后的训练。通过将2种语言训练数据合并后进行联合BPE,使得它们共用同一个词表,之后使用单语数据训练编码器,建立潜在的联系。

(1)
其中,D为单语数据集,C(x)表示对样本x进行加噪的过程。通过训练,模型可以掌握各个语言句子的基本构建信息。
(3)反向翻译:通过前2个步骤,不断拉近2种语言间语义空间的距离,这时利用反向翻译进行训练,将目标端句子通过模型映射为源端句子,建立伪平行语料,之后按照有监督机器翻译的方法进行训练。如式(2)所示:
Lback=Ex~D,y~M(x)[-logP(x|y)]
(2)
其中,D为单语数据集,M(x)表示对目标端样本x进行翻译的过程,y为翻译出来的伪源端语句。将(y,x)作为伪平行语料进行有监督训练。
DIV方法在预训练初始化的过程中使用词典对源端训练数据进行替换,之后使用替换的源端数据和目标端数据进行预训练,利用替换词在2种语言间建立联系,拉近2种语言语义空间的距离。而在本文方法中,源端使用的是词典替换后的语料加上原始语料,而目标端只有未替换的原始语料,因此在训练过程中可以进一步拉近替换词和原词之间的距离,让2种语言的语义空间距离更近。
DIV方法中训练翻译模型又分为单向训练和双向训练。在单向训练中使用降噪自编码器建立语言模型并且通过反向翻译优化模型,同样在训练时也会用词典先对源端训练数据进行替换,之后使用替换的源端数据和目标端数据进行训练。本文方法除了和之前预训练中一样将替换数据加上原数据进行单向训练以外,还提出了词嵌入融合初始化和双编码器融合训练2种方法,充分利用各个方向在预训练中学到的知识,可以更好地利用词典替换数据,缩小不同语言间的距离。
DIV[18]方法的双向训练步骤则是利用单向训练中训练的目标端到源端的翻译模型,将目标端单语数据翻译为源端数据,之后将翻译的伪源端数据与目标端数据作为伪平行语料,训练源端到目标端的翻译模型。而本文提出的词嵌入融合初始化和双编码器融合训练2种方法可以更好地抽取语言间的关系,实验表明,本文方法可以取得更好的效果。
3.2 词嵌入融合初始化
神经语言模型通过学习词嵌入来捕获词中隐含的语言和概念信息[19],在预训练中由于使用了词典替换的数据,在相应方向替换词的词嵌入训练程度较高,因为词同时在2种语言的句子中出现,可以同时学到2种语言的语义信息。但是,在另一个方向的训练过程中,因为这个词被词典替换成了这个方向目标端语言的对应词,所以这个词在该方向的训练过程中并没有被训练到,无法学习相关的语义信息。针对这个问题,本文提出了词嵌入融合初始化方法,对预训练后的模型进行初始化。以中-英模型训练为例,使用英-中方向中利用英-中词典替换训练的中文替换词初始化中-英方向中的该中文单词,让2个方向互相学习对方在训练中获得的信息。
如图1所示,图中Emb表示训练模型中的词嵌入向量,因为预训练时的模型使用中英数据联合BPE建立词表,所以词嵌入中包含中文与英文词。但是,在中-英方向的预训练过程中,用词典将训练数据中的中文zh1替换为英文en2,因为源端是词典替换后的语料加上原始语料,而目标端只使用了未替换的原始语料。所以,源端数据中包含zh1和其对应的en2,en2可以直接学习到与zh1相关的中文信息,而zh1只能通过en2间接学习到与其相关的英文信息,最终zh1的词嵌入并没有得到足够训练,而英-中模型的zh1的词嵌入学习到了完全的英文和中文的信息。因此,本文将中-英模型中的zh1的词嵌入用英-中模型的zh1的词嵌入进行初始化。同样,在英-中方向的预训练过程中,en2的词嵌入并没有得到足够训练,本文将英-中模型中的en2的词嵌入用中-英模型中的en2的词嵌入进行初始化。

Figure 1 Word embedding initialization图1 词嵌入融合初始化
最后将每个方向的源端词典替换数据与其原数据合并,进行各个方向的单向训练,这样训练的单语数据中的源端同时包含了词典替换数据和原数据。比如中文数据中同时包含“华为 phone”和“华为 手机”,可以通过“华为”作为媒介拉近“phone”与“手机”之间的距离,为了保证目标端为真数据,故而目标端都是使用原数据。实验表明,此方法可以明显提高翻译效果。

Figure 2 Dual-encoder fusion training图2 双编码器融合训练
3.3 双编码器融合训练
词嵌入融合初始化方法虽然可以利用另一个方向预训练模型中替换词的训练结果来促进这个方向的训练,但仍会损失一些替换词与其他词训练中学习到的信息。为了更好地利用2个方向的训练模型的训练结果,本文提出了一个双编码器融合训练方法,如图2所示。以中英训练为例,经过预训练后,在训练中-英方向的模型时,同时加载预训练中获得的中-英方向的编码器模型和英-中方向的编码器模型,将训练数据同时输入2个编码器中分别训练,对其输出结果用式(3)进行处理:
encout=encout-src2tgt+λ*encout-src2src
(3)
其中,encout-src2tgt是源端到目标端编码器的输出,encout-tgt2src是目标端到源端编码器的输出,使用λ来控制输出所占比重,之后将最终的结果encout输入目标端到源端的解码器模型中进行训练。
通过这种方法,在中-英的训练过程中可以同时利用中-英和英-中的预训练编码器模型进行训练,编码器可以输出2种不同视角的编码结果,对其按照一定比重进行处理,可以利用英-中编码器视角对中-英编码器视角中一些被忽略的地方进行修正,取得更好的效果。由于训练数据的源端也是词典替换数据与其原数据合并后进行各个方向的单向训练,在训练中2个编码器可以相互辅助,可利用对方在预训练中学习到的知识。比如“华为 phone”和“华为 手机”中“手机”在中-英方向的预训练中没有得到足够训练,而在英-中方向的预训练中训练充足,同样“phone”在英-中方向的预训练中没有得到足够训练,而在中-英方向的预训练中训练充足,在训练中这2个模型就可以互相利用对方已经学习过的“手机”与“phone”的知识,来调整相关词与其他词的关系,缩短“华为”与“手机”“phone”的距离,从而提高翻译质量。
4 实验设置与结果
4.1 数据集
本文在中-英、英-俄和英-阿数据上进行了实验。对于跨语言预训练阶段,本文从维基百科数据中分别抽取了8 000万条英文、1 300万条俄文和550万条中文的单语训练数据来进行训练。在单向训练和双向训练阶段中,对于中-英方向的训练,从语言数据联盟LDC(Linguistic Data Consortium)提供的440万条平行数据中抽取其中220万条作为中文单语训练数据,另外220万条作为英文训练数据。同时,使用NIST2006和NIST2002分别作为中-英训练的验证集和测试集。对于英-俄方向的训练,使用WMT(Workshop on Machine Translation)2007~2017年的单语新闻数据进行训练,同时使用WMT newstest-2015和newstest-2016作为验证集和测试集;而对于英-阿方向的训练,本文在Eisele等人[20]发布的英语和阿拉伯语平行数据中随机各抽取975万条,作为单语数据训练模型,同时使用他们发布的验证集和测试集作为英-阿训练的验证集和测试集。
本文使用MUSE双语词典对数据进行替换,对于MUSE词典中一个源端词有多个目标端翻译的情况,选取目标端在单语训练数据中出现最多的那个词作为目标端最终的替换词,表1展示了词典中词对数目与其在训练数据中所占比例。

Table 1 Word number and coverage of dictionary表1 字典词对数与覆盖率
4.2 实验设置
在预训练过程中,本文使用了XLM模型中的掩码语言模型MLM(Masked Language Model)进行训练,其与BERT类似,在训练时随机掩盖句子中15%的词语,同样在这些词中选择80%用[MASK]标志掩盖,10%用字典中随机词替换,另外10%保持不变。
本文使用XLM模型进行无监督机器翻译的训练,它是从BERT模型的基础上发展而来的,使用了Transformer[7]作为训练的主要框架,能更彻底地捕捉语句中的双向关系。Transformer模型由编码器与解码器组成,而编码器与解码器又由多个编码器层与解码器层堆叠而成。在实验中编码器和解码器层数都设置为6,每个注意力层含有8个头,词嵌入维度为1 024。本文对训练数据用联合BPE进行处理,中英数据共享约4万条词汇,英俄数据共享约6万条词汇,其余低频词用〈UNK〉替换。
训练时,随机失活率(Dropout)设置为0.1,使用Adam优化器[21],初始学习率设为0.000 1。解码时,使用长度惩罚为1.0的贪婪生成方法,双编码器融合训练方法中λ取值为0.8。
4.3 基准系统
本文使用以下模型作为实验的基准系统[14]:
(1)UNMT(Unsupervised Neural Machine Translation):为Lample等人[14]所用方法,没有使用预训练模型,只使用单语训练数据直接训练的无监督机器翻译模型。
(2)XLM+UNMT:为Lample等人[13]所用方法,在使用XLM模型训练的跨语言预训练模型基础上训练的无监督机器翻译模型。
(3)ACP(Anchored Cross-lingual Pretraining)+AT(Anchored Training):为Duan等人[18]在跨语言预训练模型基础上,对训练数据使用词典替换后,在XLM模型上使用单向训练方法训练的无监督机器翻译模型。
(4)ACP+Bi-view AT:为Duan等人[18]在跨语言预训练模型基础上,对训练数据使用词典替换后,在XLM模型上使用双向训练方法训练的无监督机器翻译模型。
4.4 实验结果
实验结果如表2所示,本文使用BLEU(BiLingual Evaluation Understudy)[22]分数作为最后的评价指标。
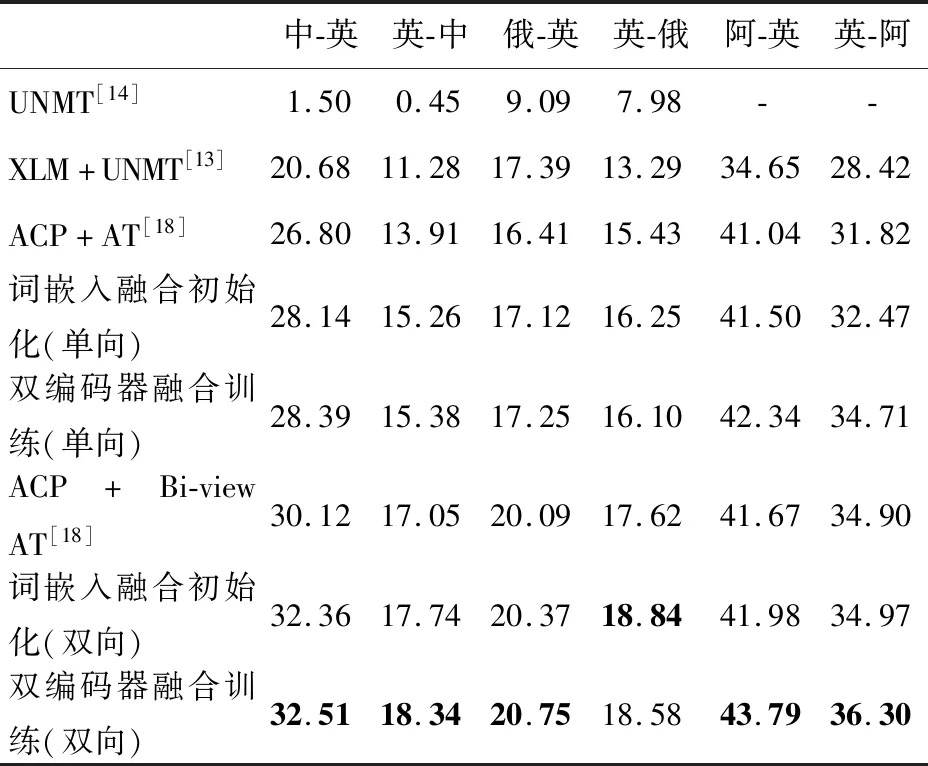
Table 2 Experiment results evaluated by BLEU表2 实验的BLEU评估结果
相比于DIV方法,词嵌入融合初始化方法在中-英与英-中的单向训练中,BLEU分数分别有1.34和1.35的提升,在双向训练中,BLEU分数分别有2.24和0.69的提升。改进后的双编码器融合训练方法在中-英与英-中的单向训练中,BLEU分数分别有1.59和1.47的提升,在双向训练中,BLEU分数分别有2.39和1.29的提升。而2种模型融合方法在英-俄与英-阿实验中的结果也有明显提升。
5 实验分析
5.1 结果分析
由表2可知,本文的词嵌入融合初始化方法和双编码器融合训练方法相比于之前的无监督训练方法的BLEU都有了明显的提升,除了词嵌入融合初始化方法在英-俄的2个方向训练中优于双编码器融合训练外,在其他情况下双编码器融合训练方法训练效果都要好于词嵌入融合初始化方法。这可能是因为英-俄的训练数据使用字典替换时替换率过高,达到88.77%,使得训练数据中2个方向中大部分都是俄语数据,因此在双编码器融合训练方法中辅助训练的俄-英模型学到的英语与英语间的联系对英-俄方向的训练影响不大,甚至在一定程度上反而阻碍了英-俄模型的学习。而词嵌入融合初始化方法中只是用俄-英模型初始化了英-俄模型,获得了之前训练中词典替换词的知识,在之后的训练中并不会持续影响训练过程,所以最后词嵌入融合初始化方法训练效果较好。
5.2 不同λ取值结果
为了得到最佳的实验结果,本文测试了双编码器融合训练方法在不同λ取值下中-英模型训练的最终效果,如表3所示。

Table 3 BLEU values of dual-encoder fusiontraining model with different λ表3 不同λ取值下双编码器融合训练模型BLEU分数
可以发现,双编码器融合训练方法的分数只在英-中方向λ=1时比DIV[18]方法的低,其他情况下都有所提高。λ取值从0.2提升到0.8的过程中,翻译分数都不断提高,并且在λ取值为0.8时达到最高,但是当λ设置为1.0时分数迅速下降,说明当权重设置过高后另一个方向的模型对该方向的训练影响过大,反而会阻碍模型的学习。
5.3 不同句长的结果
同时本文测试了不同句子长度下中-英方向上使用2种模型融合方法训练得到的模型的翻译效果。如图3所示,在单向训练过程中,除了双编码器融合训练方法在句子中包含词的个数在低于10个的情况下BLEU略低于DIV方法外,其他情况中本文的2种方法都优于DIV方法,并且在处理包含10~50个词的中长句子时本文方法的翻译质量要明显超过DIV方法的。
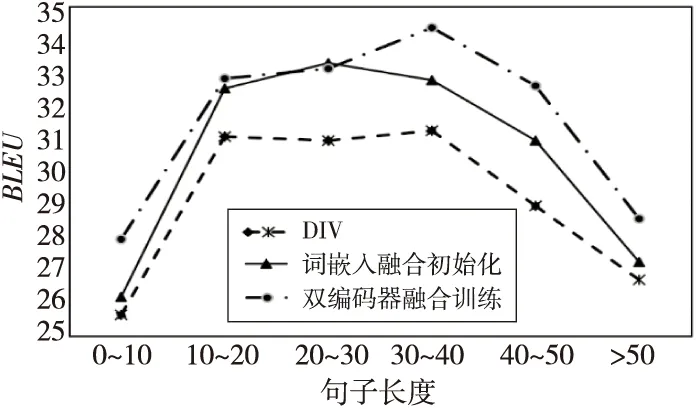
Figure 3 Single-directional training scores with different lengths图3 不同句长下单向训练分数
由图4可知,在双向训练过程中,本文的2种方法在处理所有长度的句子时都要优于DIV方法,同样在处理包含10~50个词的中长句子时也有明显的进步。同时可以发现双编码器融合训练方法对包含30个以上词的句子的翻译效果的提升更加明显,说明在2个不同方向模型的相互辅助训练后,不同方向的模型可以从不同视角分析句子,可以更好地捕捉词在中长句子中的语义信息,有效提高了句子的翻译效果。

Figure 4 Bi-directional training scores under different lengths图4 不同句长下双向训练分数
6 结束语
在无监督机器翻译模型的训练过程中,虽然有大量单语数据,但仍很难在2种语言间建立联系,针对这个问题,本文提出了采用词典替换数据,并且使用词嵌入融合初始化和双编码器融合训练来加强不同语言词之间的联系的方法。实验结果表明,相比于其它无监督基准翻译模型,本文方法在中-英、英-俄和英-阿无监督机器翻译中翻译效果都有了明显的提升。未来我们将探索其在更多语言上的效果,同时测试该方法在有监督机器翻译领域是否也会有一定的效果。
