群组决策主观评分型竞赛名次的优化模型
2022-08-18郭东威丁根宏
郭东威, 丁根宏
(1. 周口师范学院数学与统计学院,周口 466000; 2. 河海大学理学院,南京 211100)
0 引言
所谓群组决策是指多个决策者就同一问题共同做出决策,其理论研究和应用研究已成为当前管理学、数学、经济学、社会学和政治学等学科决策研究者共同关心的热点话题和前沿领域[1–2]。为确保决策的科学性、民主性,人类的决策问题越来越依赖于群组,尤其是对于具有不确定性或依赖主观评价的问题。群组决策的具体实施如下:
设有S1,S2,···,Sm共m个决策者,他们构成决策群组G。被评估的对象(或称目标、指标)为B1,B2,···,Bn共n个。xij ∈[I,J]是第i个专家对第j个被评对象的评分值。xij越大,表示Si认为目标Bj越好。向量xi= (xi1,xi2,···,xin)T和矩阵x=(xij)m×n分别代表专家个体Si和群组G在一次决策行为中所作的结论。
本文以全国大学生数学建模竞赛为例来研究主观评分型竞赛公平阅卷及排名问题。阅卷的理想情况是每位评委能公平公正地评阅每份论文,但是由于工作量、时间等原因的限制,这种理想的阅卷方案很难实施。目前对此类大型竞赛的评阅方式通常为:按照一定的规则每份论文仅由随机指定的几个评委逐一评阅。群组决策在一定程度上减小了单个评委误判或感情分带来的不公平现象,然而也产生了新的不公平现象,即由评委打分尺度不同引起的系统误差会给最终的排名带来较大误差。
以A= (aij)表示评分矩阵,aij表示第i号评委对第j篇论文的评分,如果第i号评委没有对第j篇论文评阅,那么元素aij空着不填(不参与计算),于是评分矩阵A=(aij)是残缺不全的,但一般情况下每篇论文都有相同的缺失率,并且缺失数据是随机分布的。因此,传统的排名方法,即直接取均分排名误差较大。例如有A、B 两篇论文,客观上A 论文比B 论文质量好,但由于随机分配,A 论文分配给了三个打分普遍偏低的评委,B 论文分配给了三个打分普遍偏高的评委,结果可能导致A 论文的平均得分低于B 论文的平均得分。为了减小此类误差,目前常用的方法是T 分数法[3]。虽然T 分数法可以通过调整原始评分,将评委的打分尺度统一,但是它局限于同一样本之间的横向比较,对于残缺评分情况依然存在较大误差。我国学者史晓峰建立了公平评卷的多目标优化模型,提高了论文排名的准确性[4];鄢丽建立了在一定的置信概率下逐轮淘汰的评判方法,使得排名的公平性在一定的置信概率下得到保证[5];易昆南等提出了对缺损评分矩阵进行填补的方法[6–7],但是填补缺失数据的办法仅对缺失率很小的情况有效,对于缺失率较大的情况反而很可能增大排名的误差。文献[8—9]为了减小了系统误差,根据理想点法及误差平方和最小模型求得了评委的权重,对T 分数加权平均,提高了排名的科学性。文献[10—11]分别利用成对比较矩阵及数量积法确定了评委的权重,对T 分数加权平均,减小了论文的争议度及评委评分的误差度,从而提高了排名的准确性。为了提高评委打分的可信度,近年来兴起了网上阅卷方式,该方式可以实时监控评委打分的情况,比如均分、方差及分布等。网评模式在一定程度上控制了评委打分的系统误差,提高了打分的一致性,但是也导致了评委打分保守的负面效应[12]。本文首先给出论文均匀分配的数学模型,其次将原始评分转化为T 分数,应用极差平方和最小法求得各评委权重,最后对T 分数求加权平均进行排名。通过200 次模拟实验比较,证明本文方法比传统方法及T 分数法更科学公正。
1 论文分配的数学模型



步骤1 输入评委、论文相关参数;
步骤2 选取未分配的论文p;
步骤3 对论文p分配给评委i进行检测:
1) 论文p是否已经分配给了评委i;
2) 评委i是否与论文p来自同一所学校;
3) 论文p的分配是否超过了评委i能评阅量的上限;
4) 论文p的分配是否超过了评委i能评阅此学校论文的上限;
如果论文p分配给评委i是可行的,计算此分配引起的目标函数值的增量;
步骤4 经过对论文p分配给所有评委进行检测,如果论文p可以分配给多个评委,则比较这些可行分配方案使目标函数值的增量,随机选取使目标函数值增量最小的分配方案作为论文p的最终分配;
步骤5 重复步骤3 和步骤4,直到论文成功分配给3 个评委;
步骤6 重复步骤2 至步骤5,直到所有论文分配成功。
该论文分配模型保证了每个评委评阅的论文数量尽可能接近,避免了评阅数量不均的现象,从而在下节确定评委权重的模型中,保证了每个评委可用的数据量尽可能接近,减小了因数据量差异较大引起的误差。
2 论文排名的极差平方和最小法
模型假设:
1) 每篇论文分配给3 个评委独立评阅,所有评委都有较高的评阅水平,即他对一组论文进行排名应和该组论文的真实排名不会出现严重不合,误判情况除外;
2) 每个评委都是公正的,即如果他认为论文A 优于论文B,则该评委给A 的评分高于给B 的评分。
基于以上假设,那么一篇论文的三个得分越靠近(方差越小)越能体现该论文的真实水平,但是由于评委打分尺度不同,往往三个得分差异较大,而且每篇论文的评委都不尽相同,导致传统方法及T 分数法的排名结果都有较大误差。为了使每篇论文的三个得分尽可能接近,首先将原始评分转化成T 分数,然后对T 分数乘以评委权重进一步调整。确定评委权重的具体方法如下。

合理性分析:对于同一篇论文,其客观水平是确定的。因此,如果各个评委的评分标准一致(即不考虑系统误差)且客观公正,那么每个评委对该篇论文的评分应该相差不大。但实际情况是各评委之间往往存在较大系统误差,导致对同一篇论文的评分存在较大差异。模型确定的评委权重,可以使每一篇论文的各个得分加权后尽可能接近。因此,评委权重的确定方法是合理的。

3 仿真实验及对比分析
3.1 成绩的生成
研究表明[13-15],在考生众多的大型竞赛或考试中,考生总体成绩及评委打分合理有效的分布应该呈对称正态分布或偏态分布。因此,本文所做的100 次仿真实验,论文的客观成绩及各评委所打的分数均服从正态分布,其中客观成绩可以视为无数评委打分的均值,具体操作如下。

3.2 检验排名结果优劣的指标
常用排名方法有传统方法和T 分数法。传统方法是指按原始得分的均值进行排名的方法;T 分数法是指依据T 分数均值进行排名的方法。
为了检验排名结果的优劣,定义以下概念[16]。

Di的值越小,说明i号评委的评分越接近论文的最终得分,即他的评分误差度就越小;反之误差度就越大。Hj的值越小,说明评委们对j号论文的评价越一致。根据经验,一般争议大的论文可能有两种情况,一是评委误判,二是该论文创新性强,所用方法还未被充分认可。因此,造成评委不能够达成统一的认识。所以在赛制允许的情况下应该对争议大的论文重新讨论并进行分数修正。
3.3 具体实验及结果分析
为了检验本文方法的有效性,分两组做模拟实验,每组实验模拟100 次。第一组实验论文数量n= 40,评委数m= 5,并将结果与传统法及T 分数法的结果进行比较,具体结果见表1。第二组实验论文数量n= 100,评委数m= 20,并将结果与传统法、T 分数法、文献[9]中的加权T 分数法、文献[16]中的梅西法作比较,具体结果见表2。
从表1 中数据可以看出,对小规模竞赛,本文方法的排名结果无论是平均重合度还是平均乱序度都远优于传统法和T 分数法。由表2 知,对评分缺失率较大的大规模竞赛,本文方法的排名结果远优于传统法、T 分数法及文献[9]中的加权T 分数法,与文献[16]中的梅西法结果相近,平均重合度比梅西法多0.07,平均乱序度比梅西法多1.62。两组实验结果表明本文方法可有效降低系统误差带来的排名偏差,使排名结果更客观准确。

表1 小规模竞赛的100 次试验结果
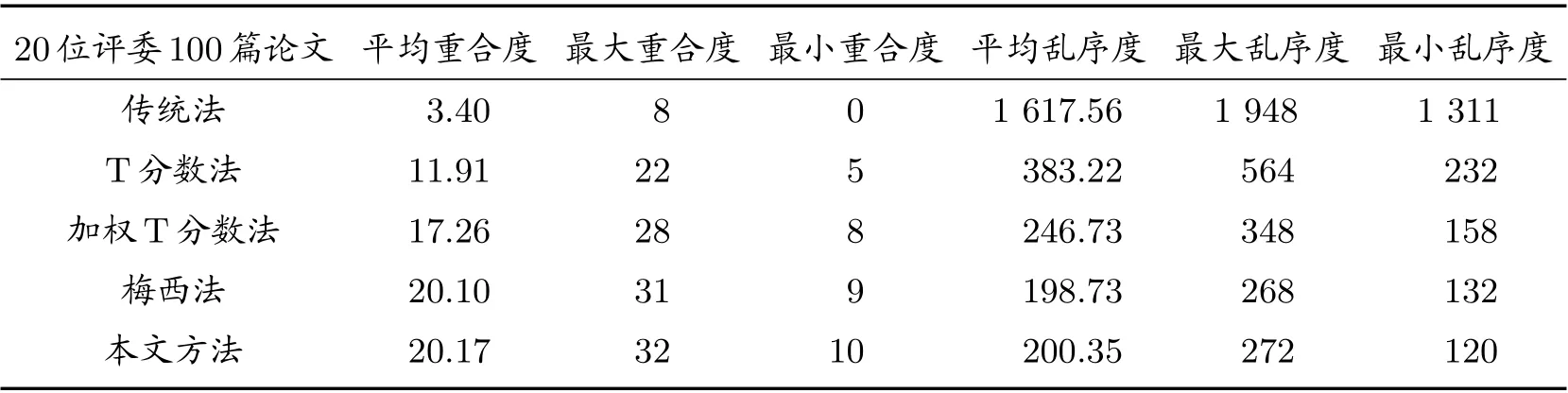
表2 大规模竞赛的100 次试验结果
表3 展示了第一组实验的其中一次具体数据及结果。表中sm:s为成绩,m为对应方法下的名次;x(n):x为原始评分,n为对应的评委编号。由表3 可知,每位评委评阅论文24 份,说明了本文给出的论文分配模型的可行性;比较三种排名方法,不难看出传统法的排名效果最差,而且容易出现得分相同的现象;T 分数法和本文方法在最终的得分上有1 分左右的差异,这是由于不同评委所评阅论文的整体水平的差异引起的,T 分数法局限于同一样本的横向比较,所以T 分数法对残缺原始残缺评分进行调整后依然存在较大误差;本文方法通过加权对T 分数法的这种局限性给予了修正,使得排名结果比T 分数法更科学准确。

表3 成绩及名次

续表
为了更直观地比较三种方法的优劣,下面给出评委评分误差度、论文争议度的直方图,如图1 和图2 所示。图中方法1、方法2 及方法3 分别代表传统方法、T 分数法及本文所提出的方法。

图1 评委评分误差度比较

图2 论文争议度比较
由图1 和图2 可以看出,本文方法较传统方法及T 分数法明显降低了评委评分的误差度及论文争议度,即本文方法通过对T 分数加权有效减小了评委打分的系统误差。计算三种方法下论文得分的方差分别为:传统方法80.62,T 分数法93.33,本文方法98.28。显然,本文方法增大了论文最终得分的方差,使论文水平的区分度更加明显,更便于选出优秀参赛者。
4 结语
大规模主观评分型竞赛的阅卷排名是复杂的系统工程,为了公平公正给予评价需要较多专家进行评审,但是由于时间的限制,很难做到每份试卷由每个专家逐一评审,往往只能每份试卷由随机分配的几个评委进行评阅。对这种残缺型评分,专家打分的系统误差往往给排名带来较大误差。为降低排名误差,本文根据得分极差平方和最小法确定了评委的权重,对T 分数加权平均排名,极大地提高主观名次与客观名次的重合度,降低了乱序度,减小了评委评分的误差度及论文的争议度,从而提高了排名的科学性及准确性。
