群队级兵棋实体智能行为决策方法研究
2022-08-17张宏军徐有为冯欣亮冯玉芳
刘 满, 张宏军, 徐有为, 冯欣亮, 冯玉芳
(1. 陆军工程大学指挥控制工程学院, 江苏 南京 210007; 2. 中国人民解放军73131部队, 福建 漳州 363000;3. 陆军步兵学院, 江西 南昌 330000; 4. 中国人民解放军71375部队, 黑龙江 哈尔滨 150000)
0 引 言
多智能体(agent)对抗系统的动作空间复杂度随智能体的个数呈指数增长,这导致了多智能体集中控制的学习异常困难。腾讯推出的“绝悟”支持王者荣耀1v1全部角色,需要使用1 064块NVIDIA GPU训练超过70 h。DeepMind推出的“AlphaStar”支持星际争霸Ⅱ整场游戏,使用了384块TPU训练超过44天。然而,对于普通研究机构,很难拥有这些超大规模的计算资源。计算机兵棋推演平台能够对敌对双方或多方的军事行动进行随机性模拟,为军事智能决策的研究提供贴近真实战争的决策背景和试验环境。兵棋推演是典型的多智能体决策环境,指挥员(兵棋玩家)控制多个同类型或者不同类型的作战实体(棋子),使之能够协同配合,达到整体的作战目标。在战术级兵棋对抗中,深度强化学习开始得到应用,因训练难度和计算资源的限制,目前只实现2个同类型棋子的控制,且决策场景单一,无法直接迁移。对于群队级兵棋对抗平台,单方约有50个左右的棋子需要控制(人类一般需由5个人组成小队联合控制),这种大量作战实体的联合行为决策给人工智能技术带来了极大的挑战。
传统的计算机生成兵力(computer generated forces, CGF)对仿真中的虚拟实体进行行为控制,它借鉴了很多人工智能(artificial intelligence, AI)领域中基于知识驱动的决策方法,如有限状态机(finite state machine, FSM)和行为树(behavior tree, BT)等。但是这种决策模型主要从定性分析的角度,以逻辑推理的方法得到行为输出,其模式比较固定,对态势变化的响应不灵敏,缺乏类人的灵活性。
兵棋推演的复盘数据蕴含了较多的态势信息和策略信息,可以为兵棋的定量决策提供信息支撑。但是,这种高维、数量巨大的数据并不能直接使用,必须要经过特征提取等方式,才能得到人们容易理解的信息。郑书奎等人提出了一种栈式稀疏降噪自编码深度学习网络模型,用于兵棋演习数据特征提取,取得较好的分类精度。张可等人设计了关键点推理遗传模糊系统框架,有效整合了兵棋专家知识的建模和兵棋复盘数据的学习,从而提高了关键点的推理质量。Pan等人提出基于信息素的兵棋敌方位置估计算法,分析地形、威胁等因素,建立8类信息素,最终通过合成信息素值,预测敌方棋子可能的位置,取得了top-3的预测准确率为70%。借助于这些量化信息或特征的提取方法,一些基于量化决策的兵棋AI智能框架被提了出来。田忠良等人设计了以多智能体协同进化为设计理念的群体智能优化算法,解决多智能体、多攻击目标的火力分配问题,从而辅助指挥员决策。刘满等人通过挖掘兵棋复盘数据,提取多个位置评价的指标用于棋子的位置选择,提出了完整的决策框架,设计的兵棋AI展现了较好的智能性。量化分析有效整合了复盘数据中的历史信息和当前的态势信息,具有较高的灵活性和鲁棒性,但是这种决策方法需要大量高质量的人工复盘数据,这一前提条件往往很难满足。
本文提出了知识与数据互补的行为决策方法,有效利用人类专家先验知识和基于兵棋数据的量化数据进行综合决策。特别是对于群队级这种大规模作战实体联合决策的情况,进行了针对性改进,提出了按实体类型分组决策、作战目标指引、位置评价指标并行计算等方法。最终,设计了适用于营级规模作战实体的行为决策框架,并实现了一个群队级兵棋AI,实验结果表明,此AI具有较强的灵活性和迁移能力。
1 兵棋行为决策算法
1.1 群队级兵棋推演及其行为决策
兵棋是运用规则、数据和阶段描述实际或假定的态势,对敌对双方或多方的军事行动进行模拟的统称,是分析战争的重要手段。陆军战术级兵棋是指单方兵力规模在营及以下的兵棋系统,一般可以分为分队级和群队级。分队级的兵力一般由连级规模的多种作战力量组成,包括10个以下棋子(1个棋子代表1个班组或1个排)。群队级的兵力一般为营级规模的多种作战力量组成,包括多个分队级兵力和配属力量(炮兵、空中力量),棋子个数一般在50个左右。因为需要控制的棋子数量较大,且没有大量的人类复盘数据供监督学习,群队级兵棋智能体决策是人机博弈领域有待攻克的挑战。
因地形遮挡和观察距离的限制,棋子很多时候不能被对方观察到,因此不完全态势是战术级兵棋的典型特点。战术级兵棋智能决策的主要内容是根据盘面上的不完全态势,判断决策出作战实体的行动。该实体行动具有4个明显的特点:规则性、目的性、位置主导和高度协同。规则性是指实体行动必须遵循兵棋系统所有的规则;目的性是指实体行动必须以作战目标(如夺控某个位置)为导向;位置主导是指实体必须依靠合适的地形、地物才能保护自己并发挥武器效能;高度协同是指各作战实体间必须相互配合协同作战。因此,战术级兵棋智能决策是“多实体在兵棋规则的限制下,高度协同配合,在合适的时间,棋子能够移动到具有战术优势的地点,对敌人实施打击,最终完成作战目的”。
按问题的量化程度,决策可以分为定性决策和定量决策。定性决策是指决策问题的诸因素不能用确切的数据表示,只能进行定性分析的决策。定量决策是指决策问题能量化成数学模型并可进行定量分析的决策。战术级兵棋的具体原子动作可以表示为动作名称和动作参数的联合,根据有无动作参数和动作参数的复杂程度,可以将棋子的动作分为宏观动作和微观动作,宏观动作是指动作的组合、参数未知的虚动作或简单参数的动作,微观动作是指具有复杂参数的动作。一般来说,宏观动作不需要求解复杂的动作参数,可以从定性决策的角度,以态势信息为判断条件,利用专家知识和兵棋规则进行推理得出;而微观动作需要求解复杂的动作参数,如机动终点、机动路线、射击目标等,可以从定量决策的角度,对兵棋数据进行数学计算,利用量化评估的方式选出离散的动作参数。可见,宏观动作和微观动作并没有明显的区分界限,二者关注动作的方式不一样,宏观动作关注的是动作名称,即要不要执行某个动作,而微观动作关注的是动作的复杂参数,即动作的具体内容。
1.2 基于知识驱动的决策算法
兵棋行为决策中的知识是指人类在长时间的兵棋推演中认识和总结的行为规律和制胜方法,它能以战法、策略等形式用文字概略描述出来。编程人员可以和兵棋专家合作,将这些战法和策略进行梳理、分解,形成领域知识库,并以逻辑推理的形式模仿专家的推理进行决策。
基于知识的推理是AI技术最早期的经典方法之一,它通过专家知识构建的规则库,用逻辑的方式实现决策,是符号主义的代表。FSM和BT的模型构建比较简单,易于维护,在CGF和游戏的行为控制中得到广泛应用。
FSM是具有基本内部记忆功能的抽象机器模型,表示有限离散状态以及这些状态之间转移的数学模型,其在任意时刻都处于有限状态集合中的某一个状态,当满足转移条件中的某一确定事件时,FSM会从当前状态转移到另一个状态。BT是适用于控制决策的分层节点树,可解决可伸缩性问题。行为树中有叶节点和组合节点,同时把行为划分成了很多层级,低层级的行为为叶结点,低层级的行为能够组合成较高层级的行为,以组合结点表示。行为树在执行的时候,会执行深度优先搜索,依次达到末端的叶节点,从而选择出叶结点(底层级行为)。BT是FSM的改进,它将状态高度模块化,减少了状态转移条件,使状态变成一个行为,从而使模型设计更加容易。但是当决策逻辑复杂时,行为树的组织结构会迅速扩张,这会造成行为树的可读性降低。
对于兵棋多agent行为决策,既要考虑集体行为,也要考虑个体行为,本文提出FSM与BT分层决策的方法。FSM建模兵棋多agent作战任务的转换,可以从整场比赛的角度优化决策模型;BT建模单个agent在给定任务条件下行为动作的输出,完成单个agent在特定任务条件下的局部优化。图1展示了FSM和BT分层的多agent行为决策框架,FSM根据整场比赛的情况进行任务转移,输出作战任务,单个agent根据作战任务,考虑局部态势情况,通过行为树决策输出动作。
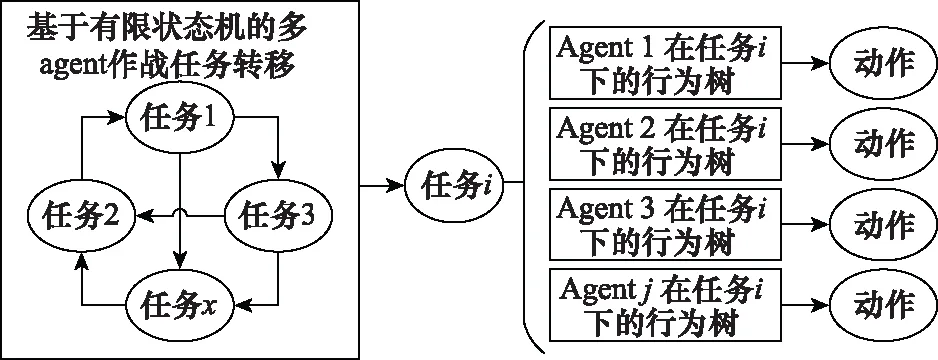
图1 FSM和BT分层的多agent行为决策框架Fig.1 Hierarchical multi-agent behavior decision-making framework based on FSM and BT
FSM、BT这种行为模型大量地依赖领域相关人员参与构建,能够较好地模拟人类顶层的推理思维,适宜兵棋智能对抗中宏观动作的决策。但是,包含复杂参数的微观动作,需要对态势数据、地图数据充分响应,基于知识的推理算法难以精细处理。常用的解决思路是基于方案设计,即领域专家提前预想多种情况,并充分分析地图,将复杂的参数(如机动终点)提前以脚本的形式固化下来,形成多套方案供决策模型选择。但是这种做法使模型输出的行为缺乏灵活性,同时决策模型也难以迁移到其他推演想定。
对于复杂动作参数的优化问题,一个可行的方法是使用定量决策的方法,充分利用兵棋数据进行评估优化。
1.3 基于数据驱动的软决策算法
兵棋数据按产生的方式可以分为想定数据、环境数据、规则数据、复盘数据和态势数据。想定数据是指一场兵棋推演对地图、实体、作战目标等规定的数据;环境数据是指兵棋系统对战场环境的量化表示而产生的数据,如地图数据等;规则数据是指兵棋系统对作战实体、作战规则等描述而产生的数据;复盘数据是指兵棋推演系统在推演整个过程中记录下来的过程数据。态势数据是指在兵棋推演中实时产生的描述战场动态情况的数据。这些兵棋数据蕴含了大量兵棋行为决策的知识,可以通过数据挖掘等方法将它们转化为支持决策的量化数据。
对于战术级兵棋的棋子移动位置决策,文献[12]使用兵棋数据挖掘与融合的方法,提取了多个与棋子位置选择相关的指标,通过多指标综合评价优选算法,得出棋子的移动位置。
首先对多个标准化之后的指标进行综合,令
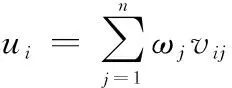
(1)
式中:为第个终点位置的加权综合评价值;为第个位置的第个标准化指标值;为第个属性值的加权系数。
将综合评价值转换为能够调控热度的概率值,并依据概率的大小来选择方案:
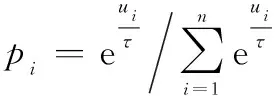
(2)
=random_choice()
(3)
式中:表示由评价值转换的概率值;>0,称为“温度因子”,具有调控概率的作用;为待评估位置的总数;为由组成的离散概率数组;random_choice()为依概率选择坐标函数;为最后优选出的棋子移动位置。
当→0时,趋向于最大评估值决策;当→+∞时,趋向于随机选择决策;当1≤≤e时,决策较好地兼顾质量与变化。
使用这种基于数据驱动的软决策方法充分利用了兵棋数据特别是态势数据中的信息,可以部分解决不完全态势的问题,优选出的棋子移动位置兼顾了质量与变化,配合规则推理,使兵棋AI的决策具有高度的灵活性。另外,这个算法依据数据计算,不依靠专家知识,有很好的可复用性。
但是,大量高质量的人工复盘数据集很难得到,这一前提条件限制了该算法的应用范围。
2 群队级兵棋AI关键技术和框架
2.1 知识与数据互补的行为决策算法
基于数据驱动的软决策算法具有灵活的优势,但是需要人工高质量的复盘数据;基于知识驱动的决策算法利用兵棋专家的领域知识进行决策,无需人工复盘数据,但是难以优化复杂的动作参数。本文将这两种算法结合起来,提出了知识与数据互补的行为决策算法。
图2展示了知识与数据互补的行为决策算法框架,在构建知识库时,专家将不再对地图具体点进行分析,而是根据战场进程,设定agent的任务区域和任务区域内选点的指标权重。利用基于知识驱动的决策算法对整场推演进行战术筹划,即使用FSM对多agent任务进行决策,使用BT对agent进行行为决策,输出动作名称、任务区域和指标权重。任务区域具有全局位置优化的能力。在任务区域和指标权重给定的条件下,利用基于数据驱动的软决策算法,就可以计算出棋子在任务区域内的移动终点。当然,我们也可以使用定量计算的方法得到其他动作参数,如机动路线、射击目标等。最后,综合动作函数和动作参数,就可以解析出原子动作命令。另外,基于数据驱动的软决策算法需要复盘数据作为支撑,本文使用随机数据让决策模型先运行起来,从而得到自我对战的复盘数据,进而通过迭代优化,提升复盘数据质量,进而优化整个决策模型的决策质量。

图2 知识与数据互补的行为决策算法框架Fig.2 Framework of behavior decision-making algorithm based on complementary knowledge and data
知识与数据互补的行为决策算法,将全局规划、行动推理交给基于知识驱动的决策算法处理,将动作参数的计算和优选交给基于数据驱动的软决策算法处理,分别发挥了两种算法的优势,实现了兵棋AI在无人类复盘数据指导下的灵活决策。
2.2 群队级兵棋实体行为决策面临的困难和解决思路
群队级兵棋的作战力量一般由多个分队,以及附属的多个空中力量和炮兵力量组成,单方控制的棋子数量约50个左右,夺控点约5~10个。使用知识与数据互补的行为决策算法时,这种大量作战实体的控制将面临以下几个困难:
(1) 作战力量包括多个分队和配属的空中力量、炮兵力量,如果以分队为单位设计有限状态机和行为树,专家的工作量将大大增加;
(2) 夺控点数量增加,且数量不固定,如何为大规模的作战实体分配合适的夺控点作为作战目标;
(3) 位置评价指标的总时间与棋子个数的关系为()。群队级棋子指标的计算时间严重拖延了决策速度。
为了解决以上问题,我们提出了以下方法:
(1) 按棋子类型分组
群队包含多个分队,分队包括多个不同类型的棋子,如果按照正常的人类指挥控制方式,为每个分队确定作战任务,分队内棋子根据任务确定行为树,这样分解将大大增加专家的工作量,且设计出的决策模型迁移能力较差。本文采用按棋子类型分组的方式,每个类型分组内包含同类型的多个棋子,这些棋子可以共用一个行为树。类型组的作战任务将着眼于整个战场,而不需要考虑不同类型组的作战地域划分,作战任务按照作战进程进行划分。类型相同的棋子在作战任务条件下复用同一个行为树。为了使同类型棋子的行为输出多样化,以作战目标(夺控点)来确定作战区域,这样同类型的不同棋子的作战区域将会不同。
(2) 类型组内作战目标(夺控点)自动分配
群队级兵棋推演一般会设置多个夺控点作为作战目标,敌对双方围绕这些夺控点展开争夺战。对于多个夺控点,综合考虑距离和均匀分配,为类型组内的每个棋子分配一个夺控点作为作战目标。这样该棋子行为树中任务区域的计算将以该夺控点和当前位置为定位点,以扇形、圆形、环形区域及这些区域的集合运算确定任务区域。
(3) 评价指标并行计算
使用多指标综合评价软优选算法,一般是已知待选作战区域后,才调用指标计算函数计算这个区域的多个评价指标。当棋子数量急剧增加后,这种按需计算的方式,严重降低了决策环的速度。为此,提出了双进程指标并行计算的方法。如图3所示,单进程指标按需计算是指当优选算法需要指标数值时,调用函数计算指标值,其计算可以分为3步。双进程指标并行计算是指主进程控制决策流程,另外开辟一个子进程,循环计算我方每个棋子周边区域六角格的指标值供主进程算法调用,其计算分为2步。主进程使用位置评价指标时,可以直接调用子进程计算好的数值,这样就大大缩短了决策环的时间。
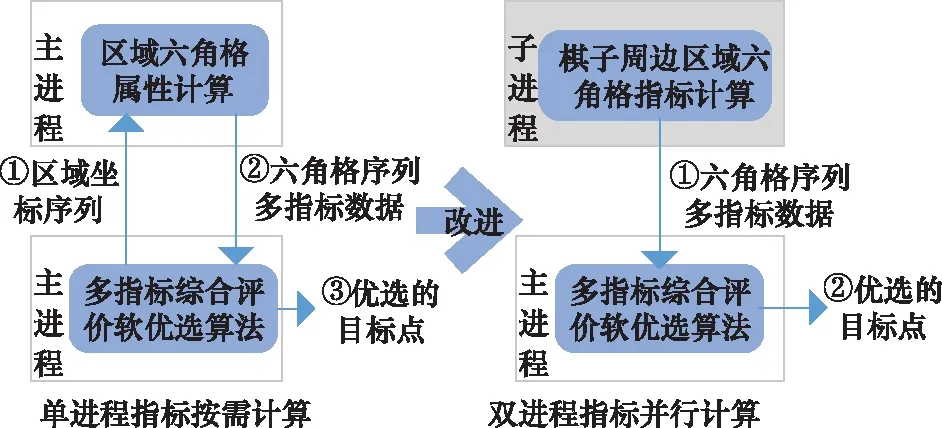
图3 单进程指标按需计算和双进程指标并行计算过程对比Fig.3 Comparison of single process attribute on demand computing and dual process attribute on parallel computing
以上3点改进,使知识与数据互补的行为决策算法在群队级兵棋推演中能够使用,简化了专家的工作量,提升了计算效率,也使模型的泛化性大大提升。
2.3 群队级兵棋AI技术框架
OODA(Observe,Orient,Decide,Act)环理论提供了一种以观察、判断、决策、行动循环来描述对抗的方法,被广泛应用于军事决策过程模型的研究。反映到决策行为模型中,观察和行动是与外界环境交互的过程,分别完成了模型的输入(战场态势)和输出(作战行动)。态势判断和行动决策运行于模型的内部,完成决策的生成。
本文基于知识与数据互补的决策算法,并对群队级具有大量作战实体的情况进行针对性改进,依照OODA环的流程,设计了群队级兵棋AI技术框架。分为5个模块:离线学习模块、感知模块、判断模块、决策模块和行动模块,如图4所示。离线学习模块是对自对抗复盘数据集或其他复盘数据集进行数据挖掘,增量更新知识数据。其他部分对应于OODA环的4个部分。
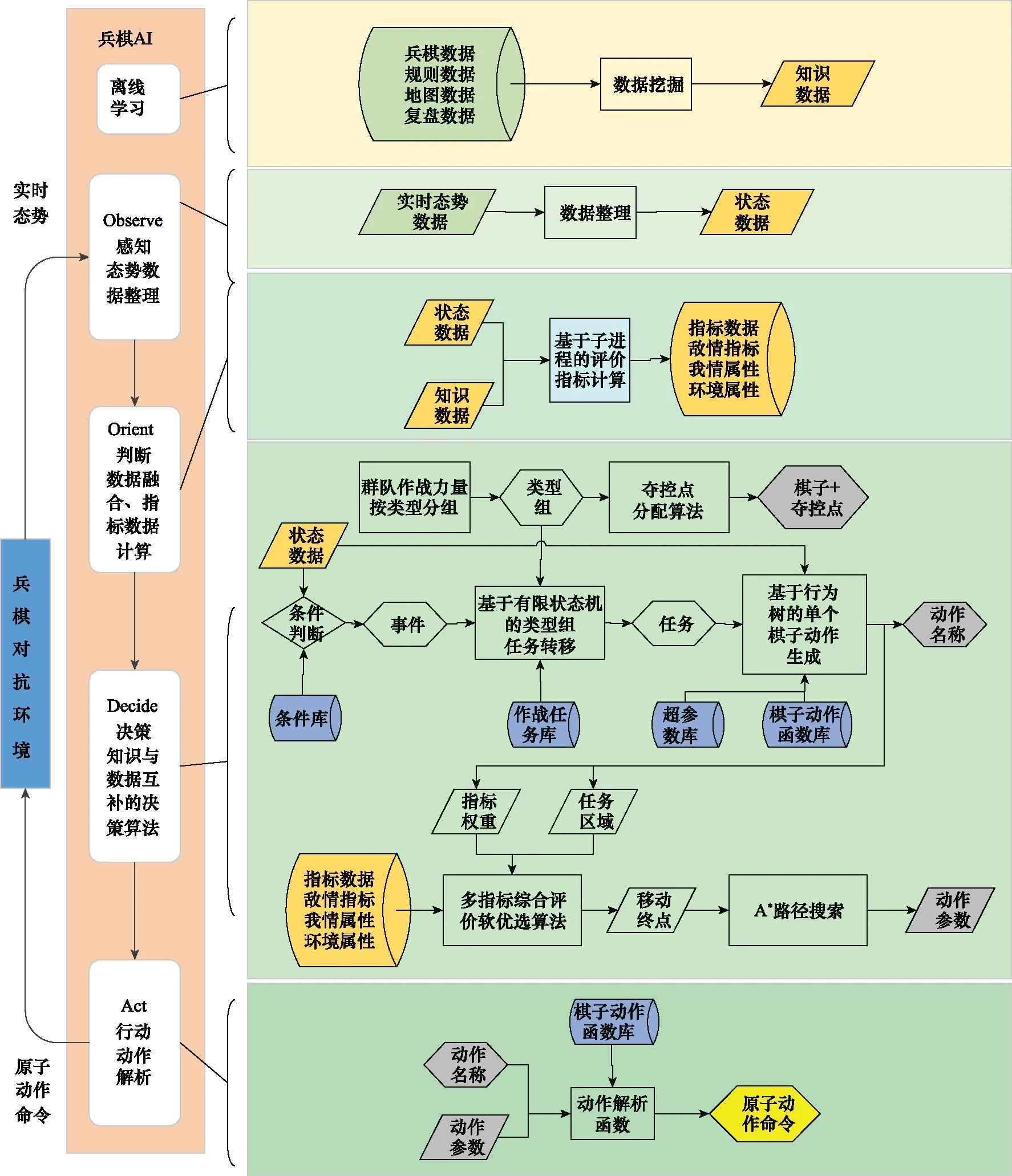
图4 群队级兵棋AI技术框架Fig.4 Group-level wargame AI technology framework
离线学习模块设计按照文献[12]中数据挖掘部分的框架和流程进行设计,提取兵棋数据中一些支持决策的知识数据(棋子历史位置概率表、夺控热度表、观察表等)。
感知模块对兵棋推演平台推送的态势数据进行格式整理和分类存放,形成状态数据(全局状态、我方棋子状态、敌方可见棋子状态、夺控点状态等),便于后续模块使用。
判断模块设计参考文献[12]中数据融合的方法,但是在计算方式上采取子进程并行计算,即状态数据不断循环更新,指标数据也不断循环计算更新。得到的多个指标传输到主进程中存储,供多指标综合评价软优选算法查询调用。
决策模块是兵棋智能决策引擎的核心部件,它主要由3部分组成:一是专家知识库,二是基于知识驱动的决策算法,三是基于数据驱动的决策算法。专家知识库和基于知识驱动的决策算法联合设计,可以复用的部件放入专家知识库中,形成作战任务库、条件库、超参数库和动作函数库。基于知识的决策算法主要负责行为的推理决策,以FSM、BT的形式编程。群队级所有作战力量按照类型进行分组,而后为每个类型组设计有限状态机,为了简单起见,本文为所有类型组设计了通用有限状态机。另外,我们需要为类型组内的每个棋子分配合适的夺控点作为作战目标。基于知识的决策算法完成多agent的动作名称输出,即FSM生成类型组当前的作战任务,BT生成当前作战任务下单个agent的动作名称、任务区域和指标权重。基于数据驱动的决策算法以任务区域和指标权重为参数,调用任务区域对应的多个评价指标,根据软概率优选和路径算法,最后生成棋子移动路径作为动作参数。
行动模块为每一个棋子生成原子动作命令。原子动作命令是兵棋对抗环境能够识别的棋子动作。专家建模了动作函数库,动作函数以动作名称和动作参数为输入,经过基于兵棋规则的合法性筛查后,输出多agent原子动作序列。需要特别指出的是,动作参数并不是都需要计算,如状态转换、上车、下车、夺控等只需要实体对象作为参数,通过简单的逻辑判断就可以得出。但是机动路线、行军路线、射击目标选择等都是需要计算评估后才能得到合适的动作参数。
3 群队级兵棋AI主要模块设计
3.1 作战目标点分配和通用有限状态机设计
群队级兵棋AI的棋子按照类型进行分组,小组内每个棋子可以复用相同的行为树进行决策,但是为了避免小组内棋子行为趋于一致,需要为小组内每个棋子指定不同夺控点为作战目标。我们以距离为匹配标准,均匀分配夺控点给同类型的棋子。以士兵为例,分配算法如下。

* 设定未被选择夺控点集合open,包括所有夺控点,集合close为空集* 对每个步兵棋子i进行循环:* 从open集合中找到与i机动时间最小的夺控点j,将j分配给棋子i,open集中去除j,close集中增加j* 当open集合为空时,初始化open和close集合
为了减小设计工作量,给全部作战力量按照棋子类型进行分组后,我们仅设计一个通用有限状态机供红蓝双方所有类型组使用,如图5所示,作战分为3个阶段:机动渗透阶段、中远攻击阶段和夺控阶段,并且设计了转移条件。这些状态和转移条件组成作战任务库和条件库。
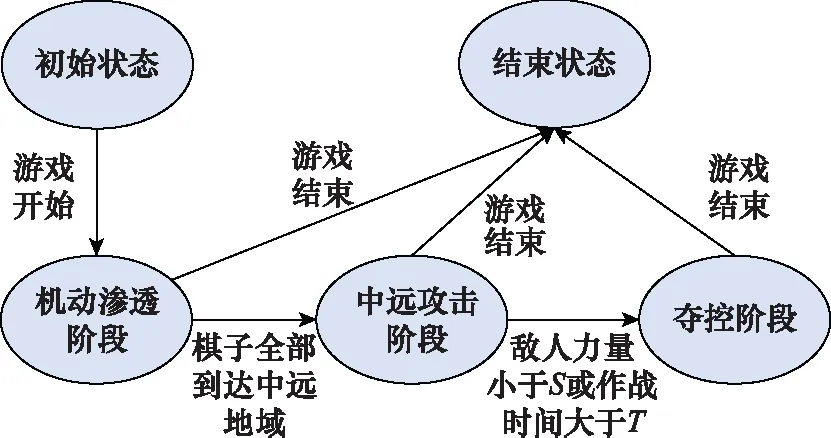
图5 通用FSM状态转移图Fig.5 General state transition diagram of FSM
3.2 基于棋子类型的行为树设计
通用FSM设计好之后,需要按照3个作战阶段为每个类型的棋子设定行为树,这里以红方步兵、装甲车为例,描述这些类型棋子的作战内容,如表1所列。最后根据作战内容,为每类棋子设计行为树。
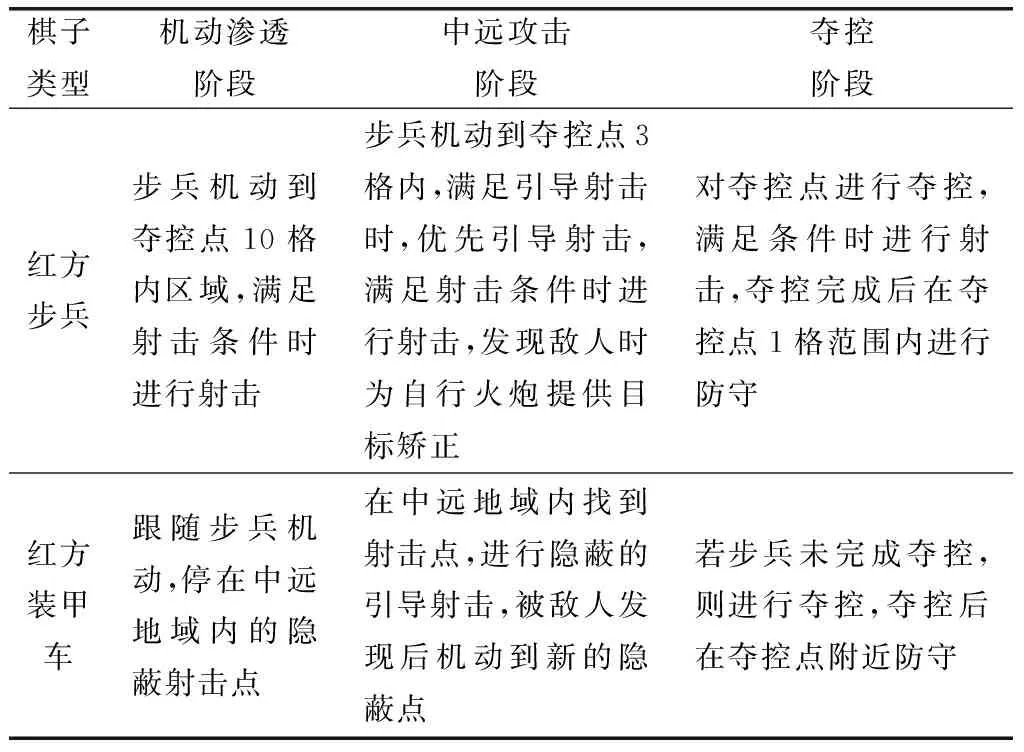
表1 红方步兵和装甲车各作战阶段的作战内容
3.3 基于共享内存的多进程机制
Python语言环境有两种方式支持并行计算:多线程(调用threading模块)和多进程(调用multiprocessing模块)。但是Python多线程受全局解释器锁(global interpreter lock, GIL)限制,不能实现真正意义上的并行计算。本文使用多进程实现多指标并行计算。共享内存是最快的IPC(inter-process communication)方式,它是针对其他进程间通信方式运行效率低而专门设计的,本文采用这种方式进行IPC。共享内存的方法就是在主进程中建立共享内存对象,它包括3个方法:初始共享内存建立、数据存储和数据读取。这个共享内存对象可以被不同进程调用,并传递数据。本文以多进程和共享内存通信实现文献[12]介绍的位置评价指标的并行计算。
4 兵棋AI实现和对抗性能
4.1 兵棋AI编程实现
本文基于战术级兵棋即时策略推演平台“庙算·智胜”开发实现了一个群队级兵棋AI。该群队级兵棋AI使用python语言,采用结构化、对象化的思想进行编程。兵棋AI能够运行之后,还需要对决策模块进行优化:
(1) 优化知识数据。开启自对战模式,收集复盘数据并离线增量更新知识数据。如果有其他复盘数据集,也可以基于这个复盘数据集更新知识数据。
(2) 优化超参数。专家根据机机对抗的复盘回放,观察兵棋AI的动作执行效果。针对AI决策效果弱的地方,调整超参数库中的任务区域和指标权重,使兵棋AI在移动位置选择上策略更优。
我们实现的群队级兵棋AI支持2张地图共3个想定,命名为“道·思-group”。
4.2 对抗性能分析
“道·思-group”参加了全国“先知·兵圣-2019”战术级人机对抗挑战赛,取得前8名。因为比赛使用的是预设想定,其他队伍可以按照专家制定的作战方案指导棋子的行为决策。相比较而言,我们的兵棋AI在作战效果上并不特别突出。
随后,“道·思-group”参与了“庙算·智胜”人机对抗平台组织的AI综合能力测评。测评对象为国内主要的5个兵棋AI团队开发的群队级兵棋AI。
表2给出了5支AI队伍的机机对抗胜率。在既定想定的机机对抗中,“道·思-group”排名第4,展现了一定智能性。另外,测试组设置了临机想定。临机想定改变了作战力量的规模和夺控点的个数。在临机想定测评中,“道·思-group”的胜率由24%上升到46.5%,展现了基于通用FSM的设计,其可移植性较强的特点。
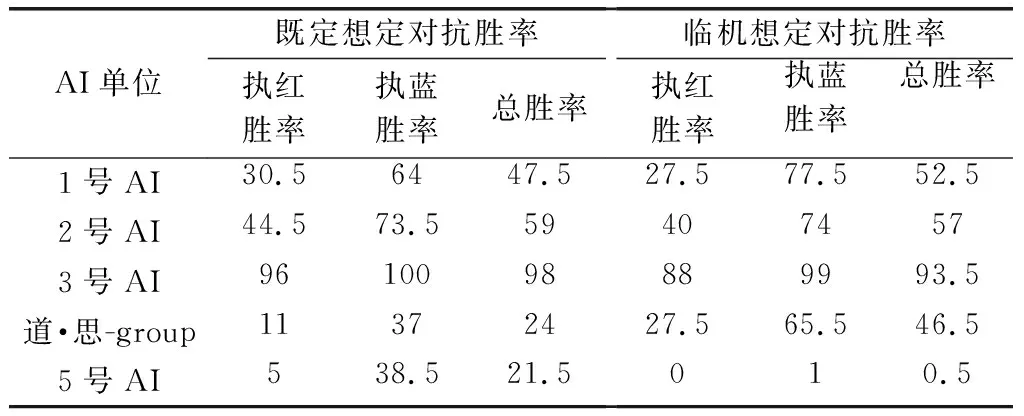
表2 群队级兵棋AI对抗胜率
但是总体对抗成绩不高,也反映了只使用通用FSM,使多agent作战任务的划分不够精细,棋子间的协同配合不够,整体作战策略优化不好。使用双进程指标并行计算方式,对计算资源的要求较大,指标计算子进程运算耗时长,计算出的指标与实时态势不匹配,从而影响了决策质量。
“庙算·智胜”测试组最后总结:测评的AI可以分为基于算法驱动和基于方案设计2类,基于算法驱动的智能体具有更好的地形分析计算和利用能力,火力使用更为敏捷和激进;基于方案设计的智能体则表现更为保守,射击频次和战果更少,但却通过更少的战损,以及较高的有效射击效率赢得对抗的胜利。临机想定中设置了与既定想定较大的差异,基于方案设计的团队多采用精细化方案设计,智能体模型更擅长打“有准备之仗”,但遇到新情况后,原方案可能会失效;基于算法驱动的团队多采用算法驱动的智能体模型,在战场态势发生突变时,具有更好的应变与稳定性。
得益于知识与数据互补的决策算法,我们的兵棋AI应属于算法驱动类型。有以下优点:
(1) 兵棋AI构建较为快速。FSM和BT分层决策的方法符合军事组织指挥的架构和任务分解模式,且免除了具体地图点的分析。基于数据驱动的决策方法无想定限制。基于可复用的领域知识库,只需要对FSM与BT进行简单的再设计,即可构建新的兵棋AI。
(2) 模型具有较高的灵活性和迁移性。每个兵棋想定中夺控点、起始点为已知点,以这两类点为定位点,设计相对位置的任务区域,并且增大任务区域范围,就可以提高决策模型的迁移性。另外,多指标综合评价软优选算法中探索因子增大后,决策模型的灵活性就会大大增加。
5 结 论
本文分析了群队级兵棋智能对抗中控制大量兵棋实体面临的困难,提出了知识与数据互补的决策算法,解决了无人类复盘数据情况下,实现棋子行为的灵活决策。我们提出了按棋子类型分类、分配夺控点为作战目标、位置评价指标并行计算等方法,解决了知识与数据互补的决策算法控制大量实体存在的困难,设计了群队级兵棋AI的技术框架。最后我们实现了群队级兵棋AI“道·思-group”,此AI在全国智能兵棋比赛和第三方测评中性能表现优异,显示出了设计简单、决策灵活和可迁移的特点。
但是使用通用有限状态机,虽然简化了设计难度,但是整体策略不够精细,导致高层策略并不是很优。另外,并行计算只是部分解决了计算时间问题,此兵棋AI依然存在计算量大、占用内存大的问题。下步将从3个方面做深入研究,一是设计更为通用的FSM和BT决策体系,并研究HTN等自动规划算法,使模型的可迁移能力更强,并可以自主规划作战任务;二是优化基于数据驱动的软决策体系,提升计算效率,同时利用深度神经网络的感知能力对评价指标进行计算;三是研究超参数的自动优化方法,减少专家工作量,同时提升模型决策能力。
