侧扫声纳检测沉船目标的轻量化DETR-YOLO法
2022-08-17汤寓麟李厚朴张卫东边少锋翟国君张晓平
汤寓麟, 李厚朴,*, 张卫东, 边少锋, 翟国君, 刘 敏, 张晓平
(1. 海军工程大学电气工程学院, 湖北 武汉 430033; 2. 军委联合参谋部战场环境体系论证中心,北京 100088; 3. 海军海洋测绘研究所, 天津 300061; 4. 中国人民解放军91001部队, 北京 100841;5. 中国地质大学(北京)信息网络中心, 北京 100083)
0 引 言
随着侧扫声纳探测技术的不断进步,使用侧扫声纳搜索失事沉船成为海道测量障碍物核查和海上搜救的重要内容。目前,随着计算机视觉技术的不断发展与叠代,基于深度学习的侧扫声纳影像自动识别和目标自动检测是海道测量领域发展的前沿方向,国内外学者开展了广泛的研究。文献[17]在与经典机器学习SVM算法对比后提出以改进的VGG-16为框架的卷积神经网络迁移学习识别方法,完成了侧扫声纳海底沉船的影像自动识别并取得明显优于传统方式的精度和效率。目标检测是在图像识别的基础上实现目标的定位,文献[18]使用Faster R-CNN模型实现了侧扫声纳海底沉船目标的自动检测,但是针对该模型存在结构复杂、训练和检测效率低等问题。文献[19]提出了基于迁移学习的改进YOLOv3模型的侧扫声纳沉船目标检测方法,虽然在一定程度上提高了训练和检测效率,但是仍存在小目标漏警率高,检测速度无法满足实时性要求等问题。文献[20]针对YOLOv3存在的问题以及面向工程应用的现实需求,通过对比8种不同深度和宽度的结构后,提出了改进的YOLOv5a模型,该模型虽然在小尺度目标的检测精度和整体检测效率上取得了很大的提升,但是在重叠目标以及复杂海况下的检测性能有待进一步加强。
近年来,随着Transformer在机器翻译、NLP(natural language processing)领域取得令人瞩目的成绩,越来越多的研究者开展Transformer相关研究。Transformer是一种主要基于自注意机制的深度神经网络,最初应用于自然语言处理领域,之后逐渐被应用到更多的计算机视觉领域。文献[27-28]提出了基于Transformer的像素自回归预测模型,并在图像分类任务上取得不错的成绩。文献[29]提出基于ViT的Transformer模型,利用纯Transformer进行图像块序列预测,并在多个图像识别基准数据集上获得SOTA性能。在目标检测领域,Facebook AI于2020年利用Transformer中能够有效建模图像中的长程关系的attention机制,简化目标检测的pipeline,构建端到端的目标检测器DETR(Detection Transformer),并取得了优异的检测性能,该模型虽然拥有高效的检测效率,但是需要大量的数据作为样本支撑才能达到满意的检测精度。
针对因海洋环境复杂,声纳影像存在大量的噪声而造成的目标信息混淆、特征细节模糊以及重叠目标漏警与虚警率高的问题,结合Transformer和YOLOv5模型在目标检测任务中的特点,本文尝试将Transformer与YOLOv5模型结合,拟构建基于DETR-YOLO的侧扫声纳沉船自动检测模型,通过加入多尺度特征复融合模块,减少特征信息的丢失,提高小目标检测能力。融入注意力机制SENet,强化模型对重要特征通道的敏感性,提取更强有力的特征。采用加权融合框(weighted boxes fusion, WBF)加权融合框,提升检测框的定位精度和置信度,降低检测的漏警率和虚警率,以期在获得复杂海况下优异检测性能的同时满足轻量化工程部署需求。
1 DETR-YOLO模型
DETR-YOLO模型结构由输入、Backbone、Neck和输出4部分组成,具体如图1所示。
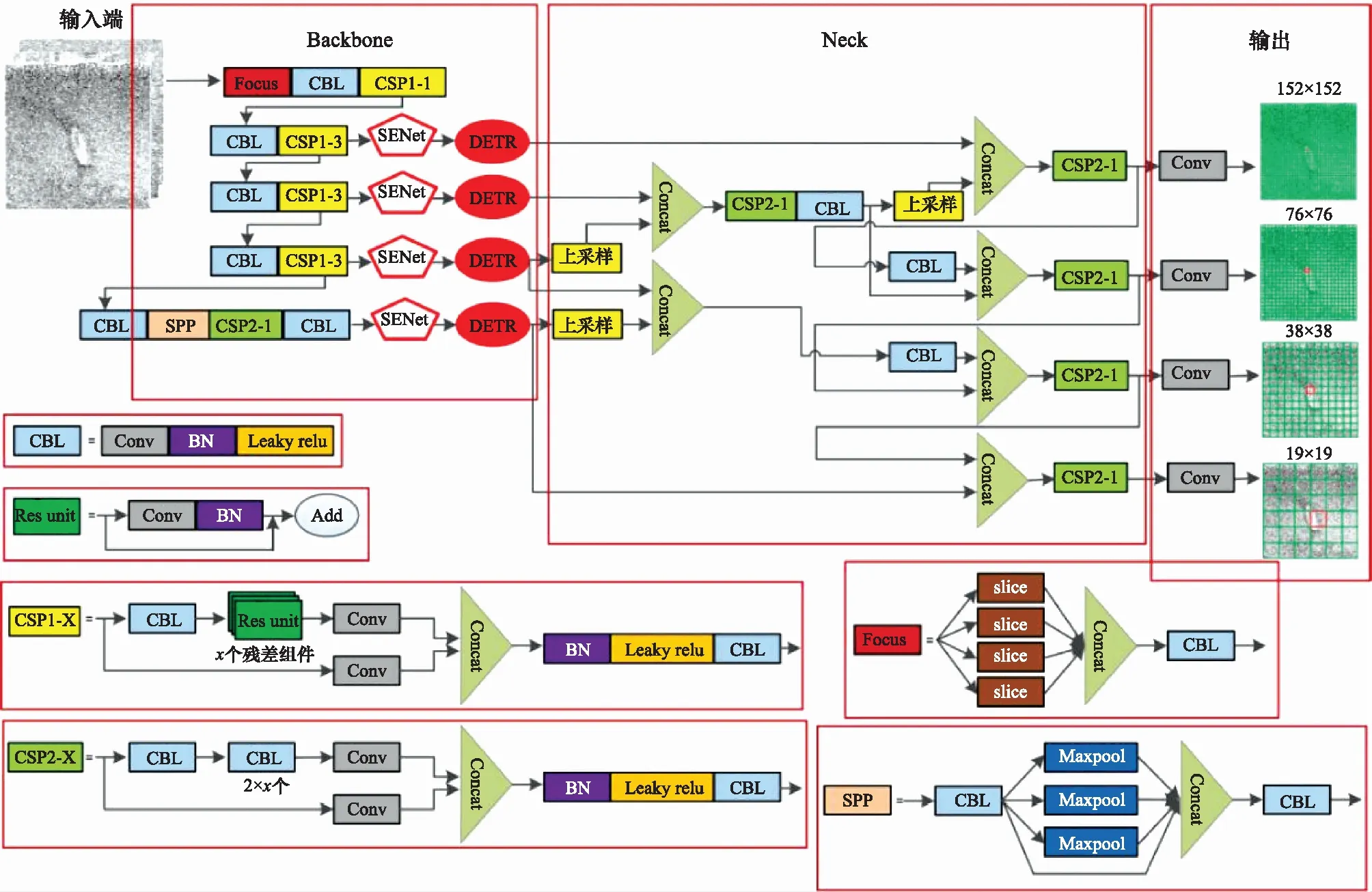
图1 DETR-YOLO模型结构Fig.1 DETR-YOLO model structure
1.1 DETR
为使模型达到更好的检测效果的同时实现模型的轻量化目标,本文创新融合了DETR结构。DETR结构由Encoder、Decoder和Prediction 3部分组成,具体如图2所示。在Backbone部分,使用常规的卷积神经网络(convolutional neural network, CNN)学习输入图像的特征并送入Encoder进行位置编码;在Encoder部分,首先将Backbone输出的特征图进行维度压缩,即通过1×1卷积核对××维的特征图进行卷积操作,将通道数压缩为得到××维特征图。其次,对特征图进行序列转换,即将空间维度×压缩到得到×的2维特征图,最后将2维特征图加上positional encoding进行位置编码。Encoder部分共包含6层,每层均包含8个自注意力模块和FFN(feed forward network);Decoder部分同样包含6层,每层包含8个自注意力模块、8个共同注意力模块和FFN。Decoder对Encoder输出的特征图进行特征提取,Decoder将少量固定数量的位置嵌入Object Queries,作为输入并参与输出。最后将Decoder的输出传递给FFN,进行网络检测类别(class)和位置(box)或无目标类。

图2 DETR结构Fig.2 DETR structure
DETR注意力模块的引入使模型有选择的聚焦输入有效部分,提升模型目标特征学习的针对性,同时与传统Transformer不同的是,DETR在特征图处理的过程中一次性处理全部的Object Queries,即一次性输出所有的预测结果,而不是从左至右逐一的输出,大大的节省了模型训练的效率,利于模型的轻量化目标。
1.2 多尺度特征复融合
YOLOv5模型包含8×8,16×16,32×32大小感受野的目标检测,但是针对更小尺度目标存在特征学习不充分进而导致最终漏检的情况,本文首先增加检测层,通过3×3卷积核经步长为2的降采样得到152×152大小的特征图,以获得4×4的特征感受野,从而更好的对小尺度目标进行检测。检测层的增加虽然提升了小尺度目标特征提取和特征融合的能力,但是一定程度上导致模型的复杂程度加深,因此带来的计算量的增加和冗余计算不利于模型的轻量化。为此,在原有模型的基础上采用CSP(cross stage paritial)模型结构,如图1所示,通过残差结构的堆叠和卷积的同步操作完成跨阶段结构下结果的合并,实现梯度变化在特征图上的集成,在增强模型学习能力的基础上降低计算瓶颈和内存成本,解决网络优化中梯度重复的问题,更好的达到模型轻量化的目的。
随着降采样的不断加深,模型不断的从浅层特征学习到深层的语义特征学习。针对深层的语义特征学习虽然拥有更大的感受野,但是较大的降采样因子会带来位置信息的损失,同时深层的语义特征与浅层特征之间相对独立,因缺少信息的融合造成特征信息的利用率不高,不利于模型训练的问题,本文采用了多尺度特征复融合结构,具体如图3所示。首先,通过上采样将强语义特征向上传递,与浅层特征进行融合,增加多尺度的语义表达。随后,通过下采样将强定位特征与深层的语义特征融合,增强多尺度的定位能力,从而全面提升模型的特征学习能力。另外,本文将多尺度的特征进行交叉复融合,加强融合特征之间的再融合,从而实现多层的参数聚合,进一步提升抽象特征和位置信息的学习。
图3 多尺度特征复融合示意图Fig.3 Schematic diagram of multi-scale feature fusion
1.3 SENet模块
针对传统的卷积操作是在局部感受野上将空间信息和特征维度信息进行聚合以获取全局信息,往往忽略了特征通道之间的相互关系,遗失细节特征,并且没有针对性的进行有效特征学习的问题,本文采用了SENet注意力机制结构进行优化,让模型以全局信息为基础,通过学习的方式自动获取每个特征通道的重要程度并赋予相应的权重,在增强有益特征学习的同时抑制冗余特征的学习,以加强特征学习的针对性,提高模型的检测性能。具体结构如图4所示。
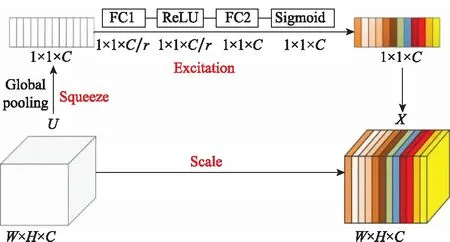
图4 SENet结构图Fig.4 SENet structure
SENet分为Squeeze和Excitation两部分,其中Squeeze部分通过全局平均池化(Global pooling)对相应的特征图进行一维压缩,即将××的特征图压缩成1×1×:

(1)
式中:×表示特征图的宽高;为通道数;(,)表示第个通道位置为(,)的元素,∈。
在Squeeze操作获得全局特征后通过Excitation操作提取各通道之间的关系:
Ex=((,))=((,))
(2)
Excitation操作采用Sigmoid中的gating机制,通过引入全连接层FC,以参数将通道降低为原来的1,经ReLU函数()激活后通过全连接层FC,以参数将通道恢复原来通道数,最后经Sigmoid函数()生成各通道权重。本文采用的降维比例为=16。
最后,将生成的权重值经过Scale操作加权到对应的特征通道中,得到最终的输出:
=()=·
(3)
SENet以轻量级的结构在增加少量计算量的同时提升模型对通道特征的敏感性,带来模型性能的提升。
1.4 WBF
常规的目标检测任务在筛选预测框时采用非极大值抑制(non-maximum suppression, NMS),NMS虽然可以有效去除单一目标的冗余预测框,但是针对重叠目标,NMS由于仅从交并比(intersection over union, IoU)单一角度考虑,所以存在漏检的问题。因此,本文采用WBF,具体如图5所示。
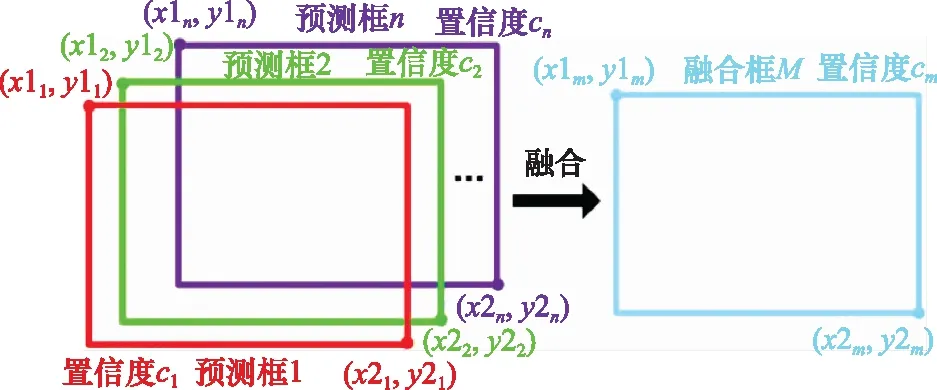
图5 WBF示意图Fig.5 WBF schematic
WBF考虑了每个预测框在检测框生成中的作用,即根据置信度分数赋予每个预测框权重,并生成加权融合框的坐标,融合框的置信度由所有预测框的平均置信度,具体如下:

(4)
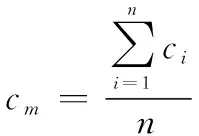
(5)
式中:(1,1),(2,2)为生成融合框的左上角和右下角坐标;(1,1),(2,2)为第个预测框的左上角和右下角坐标;和分别为生成融合框和每个预测框的置信度分数。
NMS和WBF生成的最终检测框如图6所示,相较于NMS策略生成的检测框将两个相近重叠目标误检成单一目标,WBF策略生成的检测框正确地检测出两个目标,在一定程度上有效的降低了相近目标漏警的概率,同时拥有更高的定位精度和置信度,证明WBF策略在本数据集中的有效性。

图6 检测框对比图Fig.6 Anchor frame comparison chart
2 实验与分析
2.1 数据集与预处理
本文的实验数据延用文献[20],主要由国内外各涉海部门以及国内生产厂家提供,使用包括Klein3000、EdgeTech4200、Yellowfin和海卓系列等主流侧扫声纳设备在我国东海、南海、黄渤海以及内陆湖泊实测得到,同时使用爬虫程序在网络上进行数据的搜集,共1 200张。
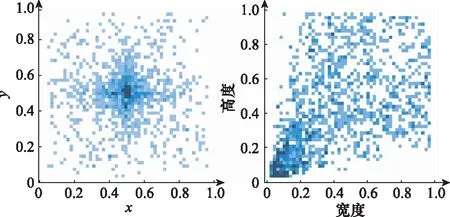
图7 沉船目标分布和尺寸情况Fig.7 Distribution and size of shipwreck targets
从图7中可以看出,沉船目标主要集中在图片的中央位置,且大多为小尺寸的目标。为了进一步丰富样本数据,同时弥补沉船目标的尺寸和分布局限性,让模型获得更好的训练效果,本文首先对数据集进行归一化处理,并采用Moscia、图像旋转、多尺度剪裁放大、图像平移、图像镜像、图像加噪等数据增强操作。Mosaic数据增强方法丰富了目标的位置分布情况且在一定程度上放大了小尺寸目标,从而在提高模型训练效率的同时提高模型的泛化能力。
2.2 实验配置与网络训练
实验均基于Pytorch框架用Python语言实现,实验环境:Windows10操作系统;CPU为Intel(R) Core(TM) i9-10900X@3.70 GHz; GPU为2块NVIDIA GeForce RTX 3090,并行内存48GB。
为在保证模型训练效果的同时提升训练效率,将数据集设定为8∶2,其中训练集的5%设定为验证集,并采用五折交叉运算策略进行模型训练;训练的初始学习率设置为0.000 1,并在开始训练前进行步长为5的warm-up训练,同时采用一维线性插值调整学习率,并在训练过程中采用余弦退火算法实现学习率的实时调整;训练步数设置为1 200步,并根据计算机配置设置batch size为32。
基于以上数据集和实验配置,本实验对比了YOLOv5a、Transformer和本文提出的DETR-YOLO3种模型。图8为3种模型的训练情况。
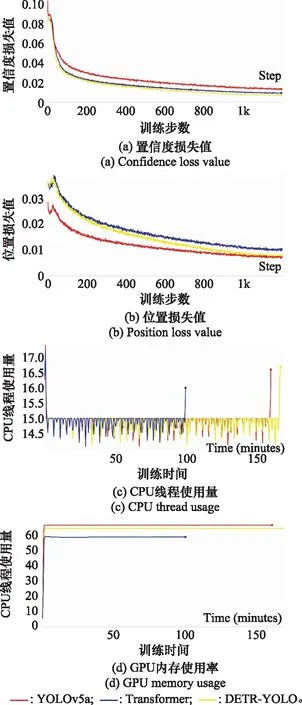
图8 3种模型训练过程对比Fig.8 Comparison of training process of three models
从图8(a)和图8(b)可以看出,3种模型的位置和置信度损失值均随着训练步数的增加而不断减小并最终趋于稳定,达到拟合状态。其中,本文模型由于使用了多尺度特征复融合策略以及SENet注意力机制,所以能够获得更加全面、细节的特征,因此置信度损失值最低。在位置损失值上,本文模型由于融合了DETR模块,所以在初始阶段需要进行位置信息编码,造成初始损失值较高,但是随着训练步数的不断增加,DETR全局感知和并行信息处理的优势逐渐发挥。同时,WBF策略充分考虑各个预测框的权重比例,避免有效预测框的信息丢失,使位置损失值迅速下降并趋于收敛,并在1 200步时和YOLOv5a几乎一样。
从图8(c)和图8(d)可以看出,本文模型虽然融合了DETR,在结构明显复杂于YOLOv5a模型的情况下训练时间仅延长了10 min,并且无论是在CPU线程使用数量还是GPU内存使用上均低于YOLOv5a。
3种模型在验证集上的平均精度AP值如图9所示。从图9(a)可以看出在IoU设置为0.5时,3种模型均在训练600步后AP值达到1。为更好的对训练模型性能进行比较,本实验比较了IoU阈值为0.5至0.95,步长为0.05情况下3种模型的AP值,具体如图9(b)所示。由图9可知,本实验模型AP值最终达到0.691,在训练过程中整体高于YOLOv5a和Transformer模型,并在训练700步后模型趋于稳定,在训练速度和效率上同样优于其他两个模型。
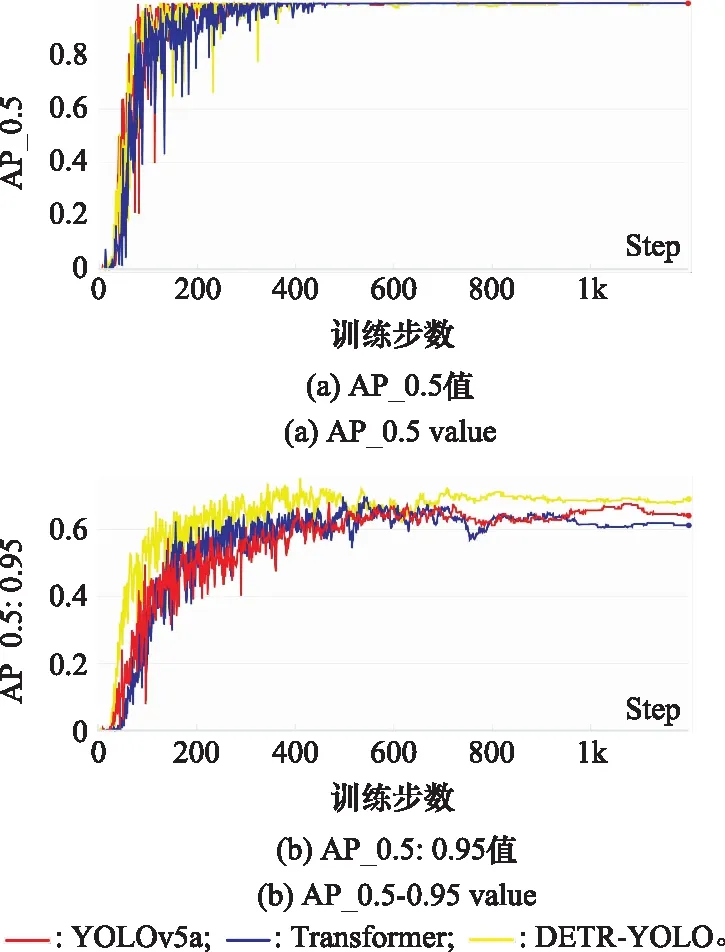
图9 3种模型AP值对比Fig.9 Comparison of AP values of three models
综上,本文模型以少量训练时间增加为代价取得最低的训练损失值以得到检测性能最佳的模型,同时以更低的硬件要求满足工程化部署需求。
2.3 检测效果与性能评估
为评估训练完成后模型的检测性能,将YOLOv5a、Transformer和本文模型在测试集上进行检测,并以AP值和每秒检测帧数(frames per second, FPS)作为量化指标,评估模型检测精度和效率;以生成模型的权重大小作为轻量化以及工程化的评估依据,3种模型具体的检测量化结果如表1所示。
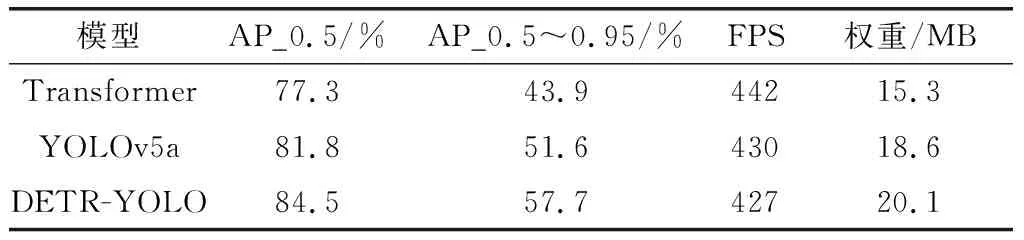
表1 3种模型在测试集检测结果对比
从表1可知,本文模型在AP值上明显高于其他两个模型,AP_0.5达到84.5%,较其他两个模型分别提高了2.7%和7.2%,AP_0.5~0.95达到57.7%,较其他两个模型分别提高了6.1%和13.8%,说明本文提出的模型具有最佳的检测精度;模型结构的复杂势必会带来检测速度的降低和权重的增加。因此,虽然在FPS和权重上DETR-YOLO模型较其他两个模型略有逊色,但是减少的少量FPS和增加的少量权重对模型轻量化和工程部署不会带来实质性影响。同时,以少量的检测速度和模型权重增加为代价换来的检测精度的大幅度提高是极具性价比的。
为验证多尺度特征复融合和SENet等策略的有效性,同样以AP值和FPS为评估指标,采用控制变量法对比分析各个策略对模型检测性能的影响,实验结果如表2所示。
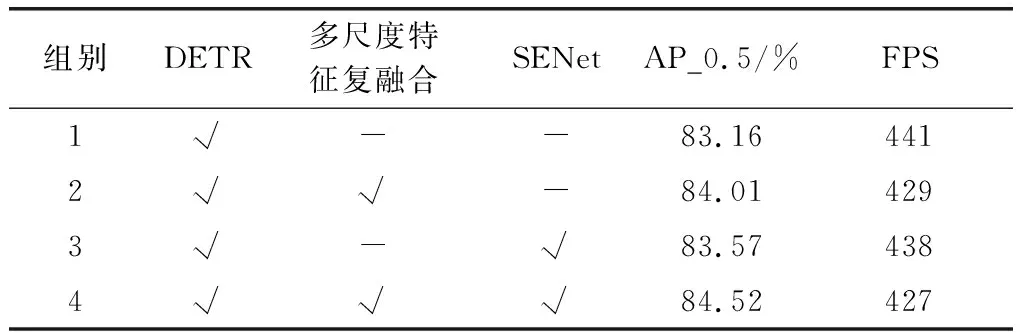
表2 不同策略的检测效果对比
对比组别1与YOLOv5模型可知,DETR模块的融入使AP_0.5提升了1.36%,并且FPS提升了11帧,证明DETR模块无论是在检测精度还是检测效率上都有显著的提升。对比组别1和组别2可知,多尺度特征复融合的融入使AP_0.5提升了0.85%,代表了检测精度的提高,证明了该策略可有效的实现特征参数的聚合,强化语义特征和定位特征的学习,降低信息损失带来的影响。但FPS下降了12帧,代表了新增的结构和参数带来了计算量的增加,一定程度上降低了检测的效率。对比组别1和组别3可知,SENet模块的融合使AP_0.5提升了0.41%,证明注意力机制的引入在增强有益特征学习的同时抑制了冗余特征的学习,加强了特征学习的针对性。在结合多尺度特征复融合和SENet策略后,通过对比组别1和组别4可知,两种策略的结合使AP_0.5提升了1.36%,同时也带来了FPS上14帧的损失。对比组别4和组别2,3可知,两种策略的结合要优于单一策略的使用。综上,模型模块的增加势必会带来结构的复杂和计算量的增加并导致检测效率的降低。但是,本文模型在如何以尽可能少的效率损失换来检测精度的大幅提升上取得了较好的成绩。
图10为3种模型的部分沉船目标检测效果对比图,从左至右分别为原图、标注图、Transformer、YOLOv5a以及DETR-YOLO模型检测效果图。

图10 3种模型检测结果对比图Fig.10 Comparison of detection results of three models
由图10可知,Transformer模型仅能满足检测出沉船目标的要求,但是在定位精度和置信度上都没有出色的检测表现;YOLOv5a模型较Transformer模型在检测性能上有较大的提升,但是在重叠目标上存在漏警的问题;而本文提出的DETR-YOLO模型无论是在定位精度、置信度还是重叠目标的检测上都有显著的性能提升,尤其是第一组的重叠沉船目标检测上,在对细节准确区分的同时依旧保持较高的定位精度和置信度。
由于水声信号具有时变性和空变形,海水中存在各种环境噪声影响,且不同的海况以及海洋环境会对声纳影像造成不同程度的干扰,其中斑点噪声是影响侧扫声纳影像质量的主要因素。因此,为了更好的模拟不同海洋环境下的实际情况,从上至下分别对影像添加期望为0,标准差为20、60、100的瑞利噪声。3种模型的检测效果对比图如图11所示,从左至右分别为Transformer、YOLOv5a和DETR-YOLO。从图11(a)看出,对于添加了标准差为20、60和80的瑞利噪声后的影像,Transformer模型能够识别出右下角的大尺度目标,但是置信度和定位精度都大幅度下降,而对于左上角的目标全部漏检。从图11(b)看出,YOLOv5a对于添加标准差为20的瑞利噪声后的影像能够检测出所有沉船目标,但是却虚警了中间和左下角的非沉船目标。从图11(c)看出,DETR-YOLO模型对于添加标准差20、60和100瑞利噪声的影像均检测出所有目标,且无论是在检测的置信度还是定位精度上,都明显优于其他两个模型。虽然在标准差为60和100的瑞利噪声影响下分别虚警了右上角和左下角的目标,但是在真实的实际搜救任务中,虚警的价值要远远高于漏警的价值,这在一定程度上反应了本文提出的DETR-YOLO模型能够更好适应海洋的复杂环境,具有更优异的检测性能和泛化能力,鲁棒性强,具有更强的实用性与指导意义。

3 结束语
针对如何在复杂海洋噪声背景下进一步提高小尺度海底沉船目标检测的准确性、降低重叠目标的漏警率和虚警率的同时实现模型轻量化的现实需求,提出了基于DETR-YOLO模型的侧扫声纳沉船目标检测模型,通过融合DETR与YOLOv5结构,加入多尺度特征复融合模块,融入注意力机制SENet,采用WBF加权融合框策略,提升模型的整体检测性能。实验结果表明,DETR-YOLO模型在测试集中AP_0.5和AP_0.5∶0.95值分别达到84.5%和57.7%,较Transfermer和YOLOv5a模型大幅度提高;DETR-YOLO模型在检测精度和检测效率以及模型权重和模型结构上取得了较好的平衡,满足工程部署对模型轻量化的要求,对复杂海况下沉船搜救具有重要现实价值。
