融合行为模式的Android 恶意代码检测方法
2022-08-16杨吉云范佳文高凌云
杨吉云,范佳文,周 洁,高凌云
1.重庆大学 计算机学院,重庆400044
2.中国石油集团测井有限公司西南分公司,重庆400030
近年来,随着移动智能终端技术的快速发展,移动智能设备已经与人们的生活密不可分。目前智能设备上的主流操作系统大致可以分为IOS 和Android两大类,而Android 系统由于其开源的优势,其市场份额逐年上升,目前已占据了移动操作系统85%以上的市场份额。但Android 系统却更易受到安全威胁,例如窃取用户的隐私信息、未经用户许可发送消息以及诱导用户访问恶意网站等,从而严重威胁到用户的财产信息安全,成为了恶意应用程序攻击的主要目标。近年来,如何有效且准确地检测Android恶意软件用于保护用户隐私信息已成为信息安全领域的热点之一。
基于机器学习方法构建Android恶意软件检测模型是目前主要的研究方向,请求权限、API(application programming interface)调用、组件、字节码以及API调用序列等特征在现有基于机器学习的检测模型中被广泛应用。Wang等人提取APK(Android application package)文件的请求权限、敏感API 调用、代码相关信息以及硬件信息等多种静态特征,结合集成学习方法实现模型的检测和训练。类似的文献[3]和文献[4]将清单文件中的多种字符串特征和API 调用划分为不同类型,再对其分别处理后作为特征。Badhani 等人将请求权限和API 的抽象包作为特征,首先通过K-Modes 聚类方法对数据集进行聚类,然后使用集成方法实现对恶意代码的检测。Wang 等人提出将权限进行风险排名的方法,方法中使用互信息、相关系数和T 检验对Android 单个权限进行风险排名,将排名靠前的单个权限以及风险权限子集作为分类特征。Scalas 等人将提取的API 调用进行分级处理,抽象得到包级、类级和方法级的API 信息,并使用随机森林算法对其训练检测。Fan 等人使用自然语言处理方法以及聚类算法对技术博客内容进行分析,构建敏感行为特征库,并对权限、意图以及API 调用作相同处理,根据敏感行为出现的频率构建特征向量。Xu 等人基于组件间通信机制提出一种新的检测方法ICCDetector,与基于恶意软件所需的资源(权限和敏感API 调用等)的方法相比,该方法可有效检测通过利用组件间通信来操作其他应用以执行恶意行为的恶意软件。陈铁明等人提出一种基于抽象Dalvik 指令的静态检测方法,使用N-gram 对抽象的指令序列进行编码,然后结合机器学习算法构造检测模型。基于语法特征的检测方法,如请求权限、API调用、组件、操作码等,缺乏应用程序的行为语义,可解释性不强,不能有效检测新出现的恶意软件。
应用程序的行为通过调用API 函数实现,因此API 函数调用序列可以表征应用程序的行为,在现有检测方法中被广泛使用。Lei 等人利用事件组来表示应用的行为,并将事件组用于神经网络的训练。该方法利用不同事件中的行为模式来反映应用程序可能的运行活动,不仅能有效检测恶意软件,还能适应恶意软件的演化。陈铁明等人动态提取API 调用序列,并结合主题模型检测应用程序的行为,但该方法需要运行程序来提取序列会消耗大量的时间和资源。MaMaDroid使用马尔科夫链对抽象API 调用序列建模,以此来提取特征进行恶意代码检测。Zhang 等人提出基于关联规则挖掘的检测方法。首先提取API 调用序列并对其抽象化,然后使用关联规则挖掘算法Aprior 来发现API 调用之间的关联规则,最后结合机器学习算法实现对Android 恶意代码的分类检测。但文献[13]和文献[14]都只考虑了两个API 调用之间的关系,其序列特征的行为语义偏弱,且提取的特征序列中包含一些与恶意行为无关的API调用,影响检测效率和分检测效果。Zhu 等人提出一种基于数据挖掘的Android 恶意家族分类方法。首先根据应用程序的API 控制流图提取API 序列,然后计算每个API 序列的支持度,根据最小支持度获得每个家族中频繁出现的API 序列,最后使用频繁序列训练分类模型。但该方法没有对API 函数进行筛选处理,以及没有考虑不同样本提取的API 调用序列数量不同,会对Android恶意代码检测产生影响。
为有效检测Android 恶意代码,本文提出一种融合行为模式的Android 恶意代码检测方法。首先,提取应用程序的API 调用序列,通过调用序列约简和调用序列合并,提取了最长敏感API 调用序列。然后,定义加权支持度,在此基础上提出了改进的序列模式挖掘算法,挖掘同类样本的平衡序列模式,并将不同类别样本集中挖掘到的频繁序列模式集合进行过滤,作为分类特征。最后,构建了机器学习算法的检测模型。
1 基于行为模式的检测方法
1.1 方法概述
本文提出了一种基于行为模式的检测方法,如图1 所示,主要由三部分组成:预处理、特征提取和模型训练。首先,对APK 文件进行预处理以提取敏感API 调用序列;然后,通过序列模式挖掘技术获取良性样本和恶意样本间不同的行为模式,筛选出具有高区分度的特征作为分类特征;最后,根据分类特征生成的特征向量训练和测试机器学习模型。

图1 检测系统架构Fig.1 Architecture of detection system
1.2 预处理
函数调用图是一种基于树的结构,可以表示应用程序中API 的调用关系,反映程序的执行流程。本文选择通过对应用程序的函数调用图进行分析,获取API调用序列。
通常,恶意软件的敏感行为是通过调用特定的API 实现的。这种特定的API 会受应用程序的访问权限控制来访问敏感信息(如,用户电话号码、位置信息)或执行敏感任务(如,改变手机的WIFI状态、发送短信),此类API 被称为敏感API,本文根据文献[16]的方法构建敏感API集合。
为了获得API 调用序列,本文使用静态分析工具FlowDroid来分析Android 应用程序的数据流,以提取应用程序的函数调用图(function call graph,FCG)。FCG 可以用一个有向图表示,=(,),其中,={v|1 <<}表示应用函数调用的全部顶点集,v是函数。⊆×是有向边集,边e=(v,v)表示函数v对函数v进行调用。图2 是一个简化的函数调用图,其中节点、、、、、、是抽象的函数。
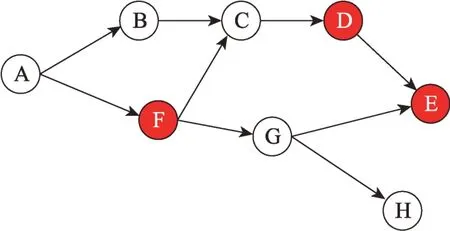
图2 函数调用图Fig.2 Function call graph
应用程序的FCG 拥有成千上万个节点和边,若对整个函数调用图进行分析会大大增加时间消耗,并且其余的无关信息可能会降低模型检测精度。通过对Android 应用程序进行分析后发现,程序的敏感行为通常与敏感函数节点有关,而敏感函数节点仅占整个FCG 的一小部分。又由于从函数调用图中提取的API 调用序列存在信息冗余,即某一个API 调用序列存在于另一个调用序列中。为了减少冗余信息,降低序列挖掘过程中的复杂度,本文提出了最长有效敏感API调用序列提取方法。
在对序列提取方法进行详细描述之前,对相关概念进行定义。
(调用序列)序列是不同函数项的有序排列,序列记为<…v>,其中每个v代表一个API 函数。序列包含的元素个数称为序列的长度,长度为的序列记为-序列。
(子序列)序列中多个连续的项组成的序列称为该序列的子序列。若存在序列=<>包含在序列=<…a>中,即⊆,则序列是序列的子序列。
最长有效敏感API调用序列提取方法具体如下:
(1)调用序列约简
删除API 调用序列中非敏感API 节点,并保留原敏感API 节点的调用顺序。在函数调用图=(,)中,图中所有API 调用序列组成集合,={,,…,s},若序列∈,=<…v>,其中,,是敏感API,序列中其他节点是非敏感API,则删除序列中的非敏感API 并保留敏感API 以及调用顺序,得到序列′=<>。通过调用序列约简,删除序列集中所有调用序列的非敏感节点,得到该文件只含有敏感API的调用序列。
(2)调用序列合并
调用序列约简后得到APK 文件的所有敏感API调用序列组成的集合,={,,…,s}。存在序列s,s∈,若s⊆s,即调用序列s是调用序列s的子序列,则从集合中删除序列s。通过调用序列合并,得到该文件所有的最长有效敏感API 调用序列集合′。
对图2 所示的函数调用图提取最长有效敏感API调用序列过程如图3 所示,其中、、为敏感API,通过调用序列约简和调用序列合并,得到了(,,)和(,)两个序列。

图3 提取最长有效敏感API调用序列过程示例Fig.3 Example of extracting the longest valid sensitive API call sequences
1.3 特征提取
经过调用序列约简和调用序列合并,生成了最长有效敏感API 调用序列集合。AprioriAll算法具有很好的序列模式挖掘性能,可以从最长有效敏感API 调用序列集合中挖掘出区分度高的调用序列,该算法的本质是通过计算序列的支持度来筛选频繁序列模式,支持度定义如下:
(支持度(s))序列s的支持度是该序列集中包含序列s的序列个数占序列集中总序列数的比例,即该序列的频率。
该算法要求样本的序列数量分布均匀,否则会产生虚假序列模式,进而降低检测模型的准确率。假设一共有100 个同类APK 文件,每个APK 文件的敏感API 调用数量均不相同,其中某个APK 文件(A)提取了100 条敏感API 调用序列,其余99 个APK 文件只提取了一条敏感API调用序列。现A 文件的100条敏感API 调用序列中均包含子序列,而其余99个APK 序列文件中不包含该序列。A 文件中只有一条敏感API 调用序列包含子序列,其余的99 个APK 序列文件都包含该序列。根据支持度定义,计算和的支持度都为0.503。
示例中所有APK 文件都包含序列,而只有一个APK 文件包含序列,由此可知,序列更能代表该类样本的一种行为,序列比更具样本代表性。然而通过计算发现子序列和的支持度相同,即序列和具有相同的代表性,但两个序列的支持度相同,就意味着根据支持度产生的序列模式与实际不符,导致最终挖掘到的频繁序列模式不完全具有数据集中样本行为模式的代表性,从而影响分类模型的检测准确度。
为此,在实验样本中随机选取了3 300 个APK 文件的API 调用序列,对其分析后发现在这些APK 文件的API 序列中,敏感API 调用序列数量在1~10 范围内的样本约占APK 样本总数的34%,10~20 范围内的样本比例约为28%,20~50 范围内的样本比例约为25%,50~100 范围内的样本比例约为5%,大于100 的样本比例约为2%。分析结果表明Android 应用的敏感API 调用序列数量分布不均匀,因此不能直接应用AprioriAll算法进行序列模式挖掘。
为了解决该问题,本文提出了加权支持度,并改进了AprioriAll算法。
(加权支持度ws(s))序列s的加权支持度是s在类样本中出现加权频率,其计算方法如式(1)所示:

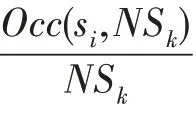
(频繁序列模式)给定数值为最小支持度阈值,对于子序列,如果该序列在数据集中的支持度大于或等于阈值,即(s)≥,则称序列s为数据集中的一个频繁序列模式。
改进后算法的主要过程为:首先根据数据集获取其中的候选1-项集,删除支持度小于设定的阈值的1-项集得到频繁1-序列;再由连接剪枝产生候选2-项集,扫描数据库,删除小于的序列得到频繁2-序列;最后递归扫描直到候选项集为空时停止扫描。改进算法的伪代码如算法1 所示。
改进算法的时间复杂度与原算法相同,均为(),但该算法针对API 调用序列数量不平衡导致大量无用序列存在和代表性序列丢失的问题,对候选序列的支持度计算进行了优化,提高了挖掘的序列特征的有效性。
改进的序列挖掘算法

改进后的算法应用加权支持度,解决本文提取的API 调用序列数量不平衡导致大量无用序列存在和代表性序列丢失的问题;同时保留了挖掘得到的所有长度的频繁序列模式,保证了序列信息的多元性。相比其他特征形式(单个敏感API 和G-gram 模式等),该算法挖掘到的序列模式更能有效地表示应用程序的行为语义。
根据最小支持度分别挖掘恶意样本集和良性样本集的频繁序列模式集合和。提取出来的频繁序列模式集合分别是每个类型样本集中应用程序常使用的API 调用序列。为了区分良性和恶意样本,而不仅仅是检测恶意代码,对和进行过滤,筛选分类特征。过滤规则如下:删除同时出现在两个集合中的序列模式,即分类特征如式(2)所示:

1.4 模型训练和检测
本文使用过滤后的敏感API 调用序列模式作为分类特征,根据该特征为每个样本构建特征向量,若该API 调用序列模式特征在样本中出现,对应的特征值为“1”,否则为“0”。本文使用了三种不同的分类算法来建立不同的分类模型,包括K 最近邻(Knearest neighbors,KNN)、随机森林(random forest,RF)以及多层感知机(multilayer perceptron,MLP)。
2 实验评估
本章将通过实验来评估本系统检测恶意软件的有效性,包括实验所用的数据集和评估指标,基于选取的数据集对系统的检测性能进行评估,以及与已有的检测方法进行比较。实验环境:IntelCorei5-8400 CPU@2.80 GHz 2.81 GHz 处理器,8 GB 内存的Windows 10 专业版操作系统。
2.1 实验数据集和评估指标
为了评估提出方法的有效性,本文收集了近1 万个实验样本,其中包含5 000 个恶意样本和5 000 个良性样本。实验数据中的恶意软件从VirusShare(https://virusshare.com/torrents)数据集中收集获得,良性样本从Google Play Store(http://play.google.com/store)获得。为了保证实验中所用样本都是纯净的,在实验之前使用VirusTotal(https://www.virustotal.com)对样本进行检测,剔除恶意数据集中检测为良性的样本和良性数据集中检测为恶意的样本。此外,由于本文方法的分类特征基于FCG,无法提取那些反分析应用程序的FCG。最终用于实验的样本一共有8 838 个(其中4 722 个恶意软件和4 116 个良性应用程序)。实验中,80%的样本用于训练模型,20%的样本用于测试模型。
本文通过准确率、精度、F 度量等指标来评估实验结果。这些评价指标都是基于混淆矩阵计算得到的。混淆矩阵如表1 所示,其中和分别是被模型预测为与原标签相同的样本数量,而和分别是被模型预测为与原标签相反的样本数量。真正例率()是被识别为恶意的样本占实际恶意样本数的比例,=/(+)。误报率()是预测为恶意的良性样本占良性样本总数的比例,=/(+)。

表1 混淆矩阵Table 1 Confusion matrix
根据混淆矩阵可以计算分类模型的评估参数,其中准确率、精度、F 度量的计算由式(3)~(6)确定:

2.2 性能分析
为了证明提出方法的有效性,本文进行了多组实验,包括采用不同的分类器进行实验的对比、序列模式和敏感API 的实验对比以及本文方法和其他检测方法的实验对比。
本文采用三种不同的分类算法来训练分类器,即K 最近邻(KNN)、随机森林(RF)和多层感知机(MLP),在加权支持度阈值为0.01 的条件下,三种分类算法的检测结果如表2 所示。从表2 中可以看出,在KNN 分类算法中,当值为3 时,模型精度在三种分类算法中表现最好,达到98.55%,而在随机森林分类算法中,同样是精度表现较好,达到96.20%,但综合考虑准确率、精度、F 度量三个评价标准,当使用MLP 训练模型时性能达到最佳,准确率为94.45%,精度为96.11%,F 度量为94.64%。
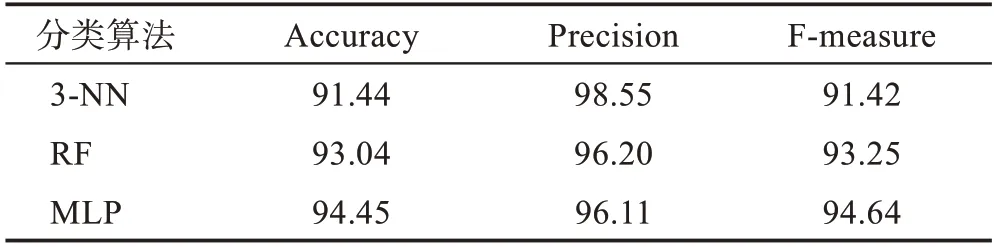
表2 不同分类算法检测结果Table 2 Detection results of different classification algorithms %
本文使用提取到的25 000 个敏感API 作为特征在同一数据集上进行实验对比,实验结果如表3 所示。实验结果表明,本文通过挖掘不同样本的行为模式的方法与只使用敏感API 作为特征的方法相比,检测率更高,并且F 度量达94.64%。

表3 敏感API与频繁序列模式的结果对比Table 3 Comparison of detection results of sensitive API and frequent sequence patterns
本文检测模型的整个时间开销分析如下:在提取应用程序的最长有效敏感API 调用序列过程中,平均分析每个样本需要8.72 s,其中,恶意样本平均需要4.47 s 完成提取,而良性样本完成分析需要约12.90 s。序列模式挖掘阶段产生比较大的时间开销,平均每个样本花费16.04 s。在最后的模型训练分类过程中,每个样本平均需要0.012 s。整个模型中序列模式挖掘这一过程花费更多的时间。另一方面,本文的特征提取方法大幅度减少了样本特征向量的维度,特征向量维度从25 000 缩小到912,减少了96%,模型训练的时间开销从0.290 s 降到0.012 s,时间开销减少95.9%,提高了模型训练的时间效率。
为了验证本文提出的检测方法的有效性,将本文方法与两种同类的Android 恶意代码检测方法进行了对比。其中陈铁明等人使用N-gram 对动态获取的API 调用序列进行特征提取,并引入主题模型对其进行建模。张家旺等人提出将权限和API 调用组合建立N-gram 特征序列。实验结果如表4 所示,与文献[12]的检测方法相比,检测精度高出了4.61个百分点,与文献[21]的方法相比,检测精度高出了2.11 个百分点。因此,本文提出的Android 恶意代码检测方法在检测效果上优于以上两种方法,能有效检测Android 恶意代码。

表4 本文方法与其他方法的结果对比Table 4 Comparison between proposed method and other methods %
3 结束语
本文提出了一种基于行为模式的Android 恶意代码检测方法,通过调用序列约简和调用序列合并,提取了最长敏感API 调用序列。定义了加权支持度,在此基础上提出了改进的序列模式挖掘算法。采用特征选择算法,构建了调用模式特征库,结合机器学习算法构建分类模型。实验结果表明提出的方法能够有效检测Android 恶意代码。与使用敏感API调用频率作为特征的检测系统相比,本文使用行为序列模式可以构建更高级的语义以发现应用程序潜在的行为模式。与使用所有敏感API 调用组合来生成对应的关联规则的方法相比,本文方法提取了更多的语义。同时,通过最长敏感API 调用序列提取方法减少了特征数量,消除了无关特征的干扰,提高了检测的效率和精度。
AprioriAll 算法在挖掘过程中产生大量的候选序列,且需要对序列数据库进行多次扫描,时间开销较大。在未来的工作中,将继续对算法进行优化,进一步提高时间效率。
