基于Adaboost的肤色分割算法设计与实现
2022-08-15薛宾田
薛宾田
(河南牧业经济学院 信息工程学院,河南郑州,450053)
0 引言
在进行人脸检查时往往会有非常复杂的背景,这些背景会影响人脸检查的结果。如果能够在此前将复杂背景尽可能过滤掉,就可以减少复杂背景对人脸检测算法的影响。由于复杂背景的颜色和人的皮肤颜色具有很大的不同,所以在人脸检测前进行肤色分割预处理是可行的。
肤色分割算法一般分为两类,一种是阈值分割,另一种其他分割方法。有阈值的肤色分割一般使用基于直方图或者高斯模型的方法,但是分割结果的好坏和设置的阈值有关。也有自适应的阈值分割,如文献使用real Adaboost算法首先求出图像中每个像素点的肤色相似度,然后使用大律法确定分割阈值,但是该算法时间复杂度太高。Adaboost算法的时间复杂度比real Adaboost算法低,而且Adaboost算法直接将肤色分为肤色和非肤色两类,而real Adaboost还要设置阈值,所以基于Adaboost肤色分割简洁高效,且更具有鲁棒性。
1 Adaboost算法原理
对于二分类问题,求出能够将一个训练样本准确分开的强分类器比较困难,即该分类器的错误率较低,而求出一个弱分类器比较容易,错误率高于50%的分类器为弱分类器。介于这一事实,如果能够使用弱分类和多个训练集合来构建一个强分类,那么二分类问题便得到解决,而Adaboost算法便是这样一种算法[1~2]。通过在同一个样本集,不同分布概率的训练数据集上运行Adaboost算法得到一系列的弱分类器并计算该分类器的错误率,然后通过线性组合将这些弱分类器和该分类器权重构成一个分类较精确的强分类器。弱分类的提取是在同一个样本上进行的,但是每次这些样本的分布是不同的,Adaboost算法针对不同的训练数据分布通过学习算法学习一系列弱分类器。
对于Adaboost算法来说,有两个问题需要解决:一是在每轮训练过程中如何改变训练样本的权值或者概率分布;二是通过何种方法将这些得到的弱分类器组成一个具有较低错误率的强分类器。在Adaboost算法计算过程中,算法会有针对的调整一些样本的权值,例如上次被错误分类的本次会重点关注,也就是加大权值,而上次被正确分类的那么说明其容易区分,本次分类就会减少其权值[3]。在这一轮训练过程中那些更加难以区分的样本权重得到提升,而特征比较明显的样本即较容易区分样本权重不再受重视。当我们得到许多弱分类器后便可以将他们组合起来形成一个非常有用的分类器,虽然每个弱分类器作用不大,但是当把他们集合起来并可以做出正确的分类,根据每个弱分类器错误率的大小来确定每个分类器的权值,如果弱分类器错误率高那么权值小,反之权值大,即弱分类器的权值和错误率成反比。Adaboost算法示意图如图 1 所示。
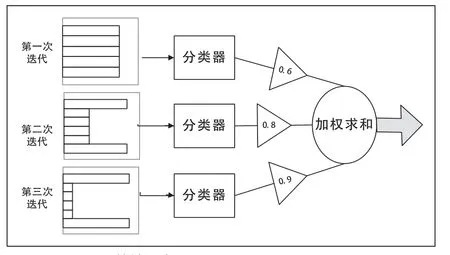
图1 Adaboost算法示意图
在Adaboost算法示意图中,左边的柱状图是数据集,其中直方图中每个条状的不同长度表示不同的权重。在经过一次迭代后求出一个分类并计算出该分类器的错误率,该分类器的权重通过其分类错误率可以得到,且权重与分类错误率成反比。每个三角形中的值为该分类器的权重,最后通过线性求和得到最后强分类器表达式。
2 改进的肤色分类算法
2.1 肤色分类器颜色空间选取
肤色分割主要是用肤色分类器实现。人脸肤色分类器的选取主要包括颜色空间的选取和弱分类器的构造两个步骤。首先是颜色空间的选取,如RGB色彩空间、HSV色彩空间和YCbCr色彩空间等[4~5],合适的颜色空间将使肤色具有较强的聚类性,这对肤色分割具有决定性的作用。其次是分类器的选择,合适的分类器将可以直接将肤色与环境区分开。
人对色彩的感知主要通过色彩的色度、亮度和饱和度来区分。其中色度和光波的长度有关,它代表颜色的基本信息,能够用来区分不同的色彩;亮度表示人眼感觉到的相对明亮程度,它是颜色光谱的功率;饱和度是指各种色彩在光线中所在的比重,颜色种类越多饱和度越底。在计算机中色彩信息使用颜色空间来表示,不同的颜色空间侧重点不同。
(1)RGB颜色空间
RGB颜色空间是由红色、绿色和蓝色三种基色来表示,通过改变三基色所占的比例可以得到不同的颜色。RGB颜色空间可以认为是三维空间坐标系中一个边长为255的立方体,三维空间中三个坐标轴上的值表示红、绿、蓝三基色在RGB空间的值,立方体内没一点代表RGB空间中的一种颜色。
RGB颜色空间的设计主要是为了适应计算机图像系统方便各种颜色的表示。由于RGB颜色空间中红、绿、蓝三基色间的联系太过于紧密,这使得一些图像处理算法难以设计和执行,许多技术比如颜色直方图,只能用在色彩变化比较剧烈的图像上才起作用。
(2)HSV颜色空间
HSV(Hue, Saturation, Value)是根据颜色的直观性为特点提出的一种颜色空间。HSV色彩空间构建原理和人眼对现实中的色彩感知过程类似,人眼通过感受像素的亮度、色调和饱和度来判断像素颜色。在HSV色彩空间中H、S、V分别指色调、饱和度和亮度三个分量,三个分量互不相关。其中色调分量是指颜色信息的外观,是人的视觉系统对颜色种类的感觉,色调用角度来度量,取值范围为0~360 。饱和度分量是指各种颜色分量所占的百分比即颜色的纯度,取值范围为0.1~1.0,值越大颜色越饱和,饱和度在人的视觉系统中表现为颜色的浓或淡。亮度分量指颜色在人眼观测时的相对明暗程度,亮度的取值范围为255(白色)~0(黑色)。
HSV分量值的计算,首先需要对RGB色彩空间进行归一化处理,亮度V等于R,G,B归一化后的最大值,而色度H和饱和度S则要经过复杂的计算得到。由于从RGB空间转换到HSV色彩空间的计算需要对归一化后的三个分量大小进行判断来确定亮度分量,所以转换复杂计算量大,而且当图像饱和度低时转换得到的色调并不稳定,所以HSV颜色空间一般不能应用到要求精确高和计算速度快的系统。
(3)YCbCr/YUV颜色空间
YCbCr颜色空间主要应用在消费类视频产品中。YCbCr中Y是指亮度分量即光的浓度,Cb(Blue-Y)指蓝色色度分量即蓝色的浓度偏移量,而Cr(Red-Y)指红色色度分量即红色的浓度偏移量。在YCbCr色彩空间中根据三个分量在采样是所占的比例不同形成了不同的存储格式常用的YCbCr比例格式有4:2:0,4:2:2,4:4:4。这些采样的依据主要是根据人眼对Y分量更加敏感,对于色度分量的减少并不影响人的视觉效果,而且可以减少图像存储使用的空间。从RGB色彩空间转换到YCbCr色彩空间线性转换关系为:
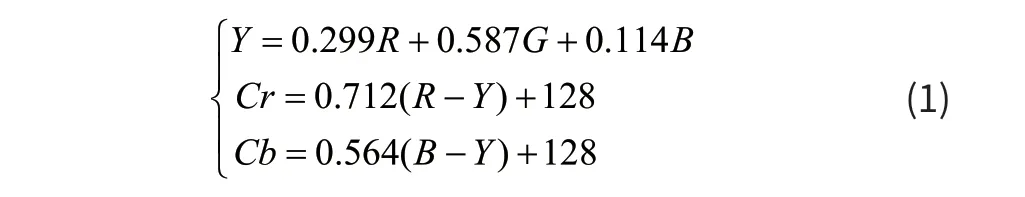
(4)色彩空间的选取
肤色分割对图像的色彩空间有两个要求。首先在该色彩空间中亮度分量和色调分量能够分离且相互独立,这样可以减少光照变化对肤色色调的影响,保证对肤色分割的稳定性。其次,肤色颜色的色调分量在该色彩空间中具有聚类特征,通过某种分类方法能够比较准确的将肤色与非肤色分类。如果色彩空间满足以上两个条件,肤色分割算法在该颜色空间就可以得到较好肤色分割效果。
在RGB色彩空间中,三基色都包含有亮度信息,当光照变化时三基色颜色都会有变化,肤色分割容易受光照变化影响。当对RGB颜色分量进行归一化后虽然减少了亮度分量,但是仍然会受到光照影响,因此RGB色彩空间和归一化后的RGB都不适合作为肤色分割色彩空间。
HSV 和 YCbCr 两个色彩空间亮度分量和色度分量是相互独立的,但是HSV色彩空间的三个分量是由R,G,B分量经过非线性计算得到的,需要多次比较R,G,B分量大小,计算效率低,而且HSV中存在部分点对RGB色彩空间微小的变化会有剧烈的反应,使HSV颜色空间表现的很不稳定。而YCbCr空间的三个分量是由R,G,B三个分量经过线性变换得到的,计算效率高。
经过对三种色彩空间的分析总结出YCbCr颜色空间具有以下优势:
(1)YCbCr色彩空间中亮度分量与色度分量相互独立的。
(2)从RGB色彩空间转换为YCbCr色彩空间是线性变换,相比于HSV的非线性转换更据有优势。
(3)YCbCr色彩空间的构成和人类视觉的色彩的认知过程具有相似性。
(4)人脸肤色在YCbCr空间具有很好的一致性和聚类性。如图 2 所示。使用肤色和非肤色数据来自SFA(A Human Skin Image Database based on FERET and AR Facial Image)人脸肤色数据库。图 2(a) 表示肤色在YCbCr空间分布,图 2(b)表示非肤色分布,对比两幅图像可以发现肤色像素和非肤色像素在YCbCr色彩空间中的Cb和Cr分量分别在不同的区域具有聚类的特点。在YCbCr色彩空间通过分类算法可以将肤色和非肤色进行分类。
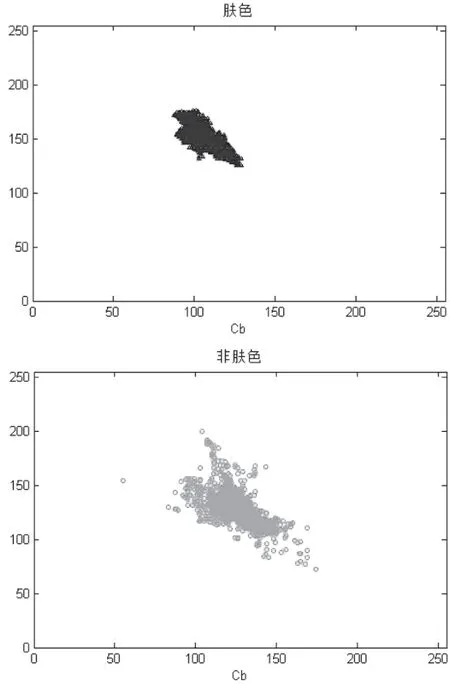
图2 YCbCr色彩空间肤色与非肤色分布图
2.2 肤色弱分类器的构建
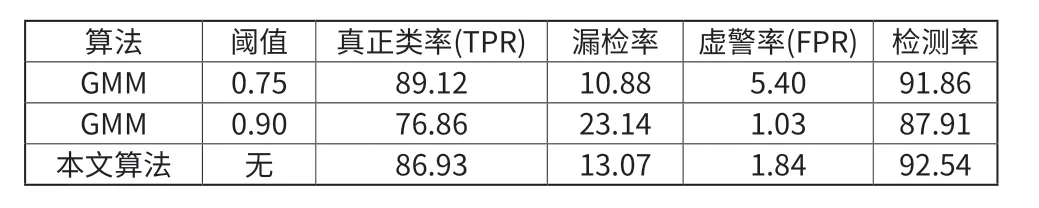
本文训练肤色分类器采用的数据来自SFA(A Human Skin Image Database based on FERET and AR Facial Image)人脸肤色数据库,该人脸肤色数据库包含人脸侧面和正面在不同光照条件下的人脸图像,其中有白色人种、黄色人种和黑色人种,共有1118个人脸图像,从这些图像中采样得到8944个大小为35×35的样本,其中3354个肤色样本,5590个非肤色样本。这些数据中,肤色像素点共计4108650个,非肤色像素点共计6847750个,对肤色样本的Cb,Cr分量统计可以得到Cb和Cr色度分量的分布范围:126 统计结果显示所有的肤色点都分布在左上角定点为(85,175),右下角顶点为(129,126)一个矩形内,但肤色像素坐标的分布范围不能使用多个分段线性方程来表示,多个分段线性函数组成的一个密闭凸多边形区间表示多维线性分类器。圆形分类器可以解决这种非凸多边形范围描述问题,所以本文选用圆形作为肤色弱分类器。 在矩形区域内,以每个像素点为圆心,以r为半径,作为一个圆形弱分类器,r的取值范围为,小于肤色矩形的一半,大于肤色区域的十分之一,即5 < r < 25。这样弱分类器总数为45000个,其数学描述为: 式(2)中 X代表待分类像素,Cb和Cr代表矩形区域内每个点Cb,Cr分量值,r为圆形弱分类器半径。对分类器的几何意义为,如果当前像素点在该弱分类器内部则判断为肤色即 h 等于1,否则h 等于0。 通过分析Adaboost算法流程和各种色彩空间的特点,本文选择使用YCbCr颜色空间描述肤色像素值,并选择圆形图像作为弱分类器来判断像素点的类别。经过Adaboost算法学习得到强肤色分类器 ()Gx,将待分类像素值作为强分类器的输入参数,经过分类器判断得到分类结果。强分类器结果由每个弱分类器权重和投票来决定,如果概率和大于0判断为肤色,即 ()1Gx= ,反之为非肤色。 肤色分割算法实现的总过程可以分为几个步骤如图 3 所示。 图3 肤色分割算法实现流程 针对一副人脸图像,我们进行了肤色分割实验。为了对比,我们也进行了基于混合高斯模型的实验,并设置了不同的阈值进行对比。 实验结果如图4和5所示。 图4 GMM肤色模型分割结果 图4是基于混合高斯模型的肤色分割实验结果。图4 (a)为阈值取0.75的分割结果(假设概率密度大于0.75的像素点为肤色),图4(b)为阈值取0.9的分割结果;从结果可以看出,阈值对肤色分割结果有很大的影响。 图5是本文肤色分割算法,可以看出,本文算法结果要优于高斯混合模型的结果。 图5 本文算法肤色分割结果 从表1可以看出,本文肤色分类算法获得的正确率是92.54%,虚警率是1.84%。虽然本文算法的真正类率和基于高斯混合模型的肤色分割算法的阈值取0.75时相比,稍微低一点,但是本文算法对于不同的图像都具有较高的检测率同时虚警率较低。 表1 肤色分割错误率 % 从图4和表1可以看出,使用高斯混合模型时,若阈值较小时基本全部肤色被正确分类,但是一些类似于肤色的像素点也被错误分类为肤色,虚警率增加;当阈值较大时,漏检率增加。因此肤色分割结果好坏取决于阈值的设置,而一旦阈值固定,则要么虚警率高,要么漏检率高。但是目前并没有很好地算法可以算出合适的阈值使用于所有情况。。 从图5和表1可以看出,由于本文的肤色分类器是从肤色数据库中学习得到,因此不需设阈值便可以实现肤色分割;其检测率与混合高斯模型相近,但虚警率和漏检率都有下降。 以上分析表明,与混合高斯模型相比,本文算法不需要设置阈值且具有较好的分割效果。 针对肤色分割问题,首先分析了传统基于概率的肤色分割的缺点,然后提出了基于Adaboost算法的肤色分割,并对各种色彩空间进行分析和对比,对肤色在YCbCr色彩空间的分布规律进行了分析,最后确定选择YCBCr色彩空间并使用圆形作为肤色弱分类器。通过Adaboost算法,在大量肤色和非肤色的样本中进行学习,得到了肤色的强分类器。最后本文通过实验把本文算法和其他算法进行对比论证,实验结果充分证明了本文算法的有效性和鲁棒性。虽然这对大部分情况本文的肤色分割算法表现良好,但是当人脸受到光照变化影响时会有一些部位判断错误,所以后续如何消除光照变化的影响是本文改进部分。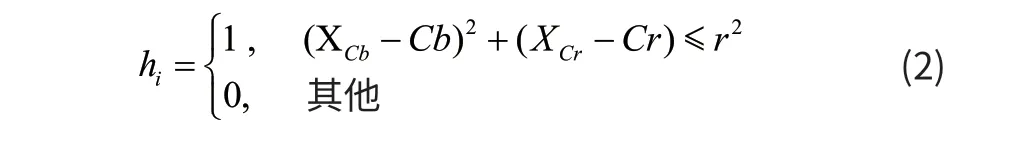
2.3 改进肤色分割算法实现
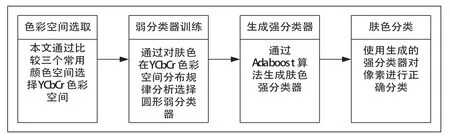
3 实验及结果分析
3.1 实验结果


3.2 实验分析
4 总结
