多特征融合的煤矿网络加密恶意流量检测方法
2022-08-13霍跃华赵法起吴文昊
霍跃华, 赵法起, 吴文昊
(1. 中国矿业大学(北京) 机电与信息工程学院,北京 100083;2. 中国矿业大学(北京) 网络与信息中心,北京 100083)
0 引言
煤炭素有“工业粮食”之称,在我国的能源化工领域有着不可替代的作用。伴随着互联网和移动信息的发展,煤炭行业的矿井环境监测、安全巡查和远程控制等正积极向网络化、信息化和智能化转型。这些转型提高了煤矿生产效率,但也为煤矿网络的安全性带来了挑战。
网络是煤矿产业(煤炭产业或煤炭行业)智能化建设和数据传输链路的关键。当前我国煤矿网络存在如下问题[1-2]:网络结构不合理,分配虚拟网络时易产生漏洞;使用大量非标准的通信协议,危险性高;煤矿网络采用典型环形以太网结构,威胁易扩散;从业人员缺乏网络安全意识,预防和处理网络风险能力差。针对上述问题,煤矿网络采取了安全措施,但现有安全措施存在不同程度的问题:防火墙技术无法阻止内部攻击;虚拟专用网技术费用高且在特定情况下易被攻破;安全扫描技术存在滞后性且消耗资源多;基于区块链的访问控制安全性研究不足[3]。因此,研究我国煤矿网络的安全入侵检测具有重要的实际意义。
当前煤矿网络面临严重的恶意软件攻击,例如APP病毒攻击[2],它通过伪造网络地址来阻碍煤矿网络与外网的正常通信,进而影响生产安全。2020 年,在通过 Internet 与远程系统通信中,有23%的恶意软件使用安全传输层协议(Transport Layer Security,TLS)加密;到2021年,这一比例接近46%,这个趋势使得煤矿网络的智能化建设也面临严峻的威胁[4]。为了提高网络的安全性,各界学者对TLS加密恶意流量识别进行了研究,大致经历了3个阶段:第1阶段,采用解密技术破解TLS加密协议,但该方法计算开销大、成本高,且侵犯了用户的隐私。第2阶段,在非解密的前提下,观测网络出口的加密通信流量(443端口),利用已掌握的数据资源,对加密流量进行判别[5],但现在恶意软件会绕过443端口使用其他端口实现入侵,降低了该方法的有效性。第3阶段,非解密分析流量包,通过提取流量包中的数据元特征、TLS明文特征[5]、DNS(Domain Name System,域名系统)和HTTP(Hyper Text Transfer Protocol,超文本传输协议)上下文数据流等特征,利用机器学习和深度学习[6-10]的方法实现非解密的TLS加密恶意流量检测,其中,特征的选取和数据的质量对这一类方法检测结果具有决定性影响[11-12]。上述3个阶段的研究都存在加密流量误报率高的问题,此问题加大了从业人员的工作量。
针对煤矿网络面临由恶意软件所产生的TLS加密恶意流量威胁和检测过程加密流量误报率高的问题,提出了一种基于多特征融合的煤矿网络加密恶意流量检测方法。首先提取流的连接特征、元数据和TLS握手特征,构建特征集。其次,利用特征工程方法进行规约处理。最后,构建投票模型训练样本集,实现高效的TLS加密恶意流量检测。
1 TLS加密协议
TLS加密协议位于开放式系统互联(Open System Interconnection,OSI)7层参考模型中的第3层和第4层之间,为网络中的任意2个通信应用程序提供加密服务。该协议由TLS记录协议和TLS握手协议构成。TLS记录协议主要用来识别TLS中的消息类型,并对每条消息的完整性进行保护和验证。TLS握手协议负责在客户端与服务器在交换数据之前,协商建立加密信道,通信双方建立连接的过程采用明文传输,该协议也是本文重点研究的协议。
TLS握手过程是由客户端发起,服务端响应,在通信双方进行一系列信息交换和身份验证后完成,如图1所示。一个完整的TLS握手过程包括Client Hello,Server Hello,Certificate&Key&Cipher,ChangeCipherSpec 4个部分[13],通信双方在建立连接过程中协商选择TLS协议版本号、加密算法等信息来确定加密方式。进一步通过证书校验、密钥交换等操作来进行身份验证,验证通过后,构建加密信道进行数据传输。
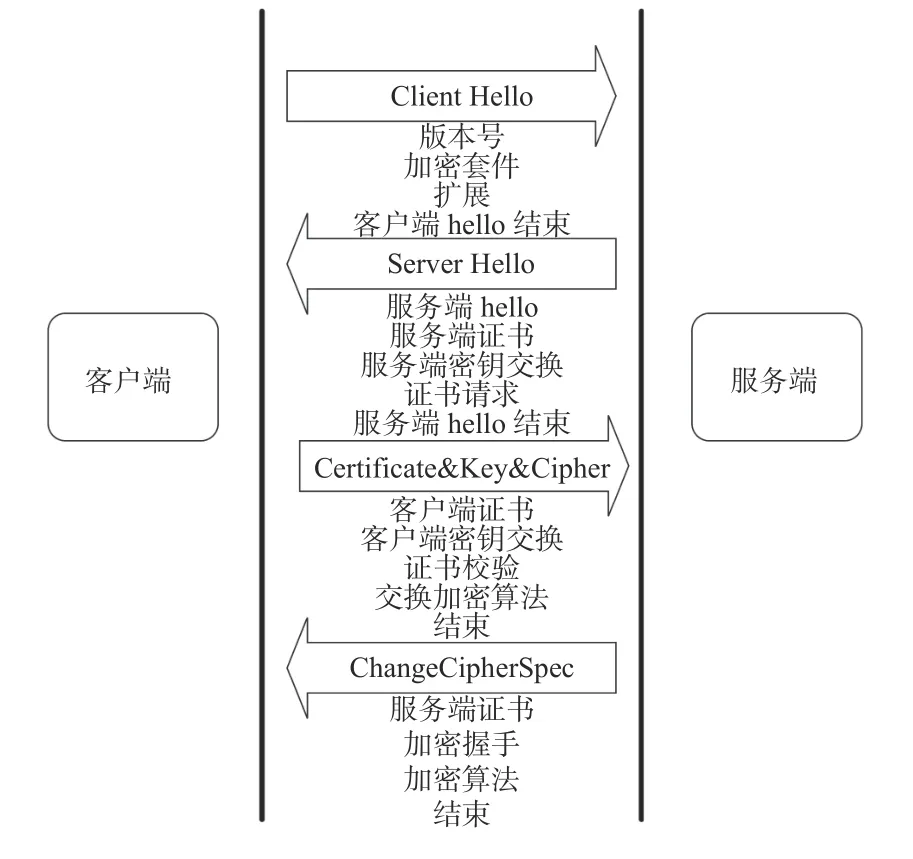
图1 TLS握手过程Fig. 1 TLS handshake process
2 基于多特征融合的TLS加密恶意流量检测方法
为了高效检测TLS加密恶意流量,提出了基于多特征融合的TLS加密恶意流量检测方法,如图2所示。该方法包含特征选择、特征子集的构建与标准化、特征子集降维及模型训练与评估4个模块,采用有监督的机器学习算法建立检测模型,利用特征工程将数据集转换后导入检测模型进行训练和预测,通过预测结果对模型进行评估。
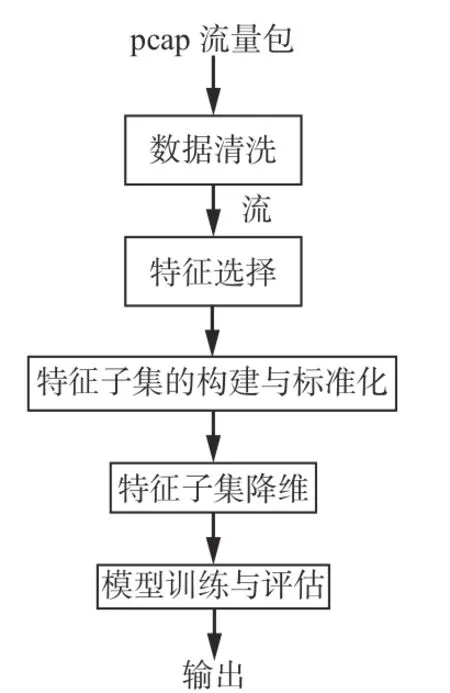
图2 基于多特征融合的TLS加密恶意流量检测方法流程Fig. 2 Flow of TLS encrypted malicious traffic detected method based on multi-feature fusion
2.1 特征选择
流[14]是指在一定时间内,具有相同源IP地址、源端口号、目的 IP 地址、目的端口号和协议的网络数据包所携带的数据特征总和[13]。使用Zeek工具对pcap流量包进行特征提取,并将得到的流特征分别存储在flowmeter.log,conn.log,ssl.log和X.509.log日志文件中。pcap流量包中每条流使用的IP地址和端口等信息均存储在日志文件中,每条流都对应一个唯一的流指纹uid,用于关联流在不同日志中的行为。pcap流量包处理流程如图3所示。先将恶意和良性pcap流量包进行预处理,利用Zeek工具解析pcap流量包中每条流,得到所有流的特征并存储在4个日志文件中,进而利用Zat工具将所提取的特征转换为恶意流量特征子集和良性流量特征子集。
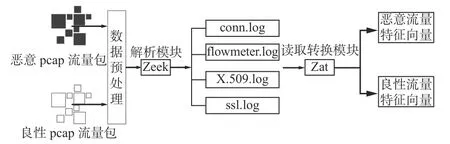
图3 pcap流量包处理流程Fig. 3 Flow of pcap traffic packages processing
(1) 流元特征。存储在flowmeter.log日志文件中的流元特征包括有效负载的数据包数量、大小、到达时间和有效负载字节数等,良性流量与恶意流量在这些特征上具有统计学意义的差异[15]。
(2) 连接特征。连接特征包括跟踪TCP/UDP建立连接的过程和TLS握手特征中的Client Hello,Server Hello,ServerHelloDone,分别存储于conn.log和ssl.log日志文件中。连接特征反映了网络中通信主体在何时持续多长时间及使用何种协议进行数据传输。
(3) X.509证书特征。X.509证书特征是TLS握手过程中证书校验部分,包括证书签发者、证书是否自签名、证书包含的域名数量等,存储于X.509.log日志文件中。
过多的特征会导致训练与检测的效果下降,所选特征过多会增加计算开销,占用过量的内存和存储空间,造成资源灾难。为了避免这个问题,在特征提取阶段避免选择重复或相似度较高的特征;采用特征工程对所提取的特征进行降维,删除冗余特征,将相似特征在特征空间进行合成,降低特征维度,保留有效信息。
2.2 特征子集的构建与标准化
提取的流元特征、连接特征通过流指纹uid构成流特征子集,共94维。将流子集进行标准化,使特征数据均值和方差服从N(0,1)分布。首先计算特征数据的最大值、最小值、均值和方差,进而对每个维度的特征进行标准化处理。

式中:x′为标准化后的特征值;x为特征子集中的特征值;μ为特征子集中某特征的平均值;σ2为特征子集中某特征的方差。
将所得到的标准流特征子集X1与对应的标签值构成一个训练集T1。
X.509证书特征包括issuer,subject和cipher 3个部分,作为证书特征子集。对证书特征子集进行onehot编码,得到2 874维稀疏证书特征子集X2。
2.3 特征子集降维
为了减少计算开销,提高检测的准确性,对特征子集X1和X2进行降维。采用随机森林特征重要性评估器对标准流特征子集X1进行降维,先将训练集T1输入随机森林分类器进行训练,训练完成后从随机森林特征重要性评估器中得到每维特征的重要性权 重 εi(i=1,2,···,94,i为特征维数)1,选取εi≥0.01的28维特征作为降维后的标准流特征子集,标准流特征子集对流特征子集的贡献率为0.715 8。前28个特征和特征重要性权重见表1。

表1 εi≥0.01的前28个特征和特征重要性权重Table 1 Top 28 features with εi≥0.01 and feature importance weights
编码后的证书特征子集升维会造成维度灾难,随机森林特征重要性评估器的方法不再适用。为此,采用主成分分析法(Principal Component Analysis,PCA)去除数据中的噪声且缓解维度灾难,对稀疏证书特征子集X2进行降维。首先从X2中获得协方差矩阵,根据协方差矩阵得到X2的特征值和特征向量,进而得到每个特征向量对训练集的贡献率,降维后的特征维度由前j个主成分的特征贡献率θk(k=1,2,···,j)决定,则累计特征贡献率(前j个主成分贡献率的总和)为
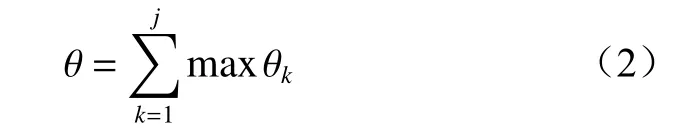
为了避免过拟合,在降维过程中丢弃冗余的信息,经过大量实验验证可得,当 θ∈[0.9,0.95] 时,机器学习训练效果最好,本文以计算量最小原则,取θ=0.9的阈值进行PCA 降维,进而确定降维后的稀疏证书特征子集X2共有106维,对证书特征子集的贡献率为0.900 1。
将TLS握手过程中所提取的TLS版本号特征作为每条TLS加密流的标志。其中,本文所使用数据集中含SSL3.0/ TLS1.0/ TLS1.1/ TLS1.2[16]4个TLS版本,对TLS版本号特征进行独热编码后得到4个维度的数值特征。将TLS版本号特征与处理后的流特征子集和稀疏特征子集通过流指纹拼接,得到138维特征集X,X与其标签Y构成样本集T,将样本集T按照7:3的比例划分为训练集和测试集,其中训练集与测试集中恶意流量和良性流量的比例与样本集T保持一致,均为2:1。
2.4 机器学习模型
使 用 决 策 树(Decision Tree, DT)分 类 器[17-18]、K近邻(K-Nearest Neighbor, KNN)分类器、高斯朴素贝叶斯(Gaussian Naive Bayes, GNB)分类器、L2逻辑回归(Logistic Regression, LR)分类器和随机梯度下降(Stochastic Gradient Descent , SGD)分类器5个子模型对所提出特征集进行检验。采用控制变量法得到DT分类器子模型的最大深度为 20,并使用信息熵作为特征划分依据;建立 KNN分类器子模型,采用网格搜索法确定K值为5;建立GNB分类器子模型,利用极大似然法计算先验概率;建立LR分类器子模型,设置正则化参数L2;建立SGD分类器子模型,设置正则化参数L2,损失函数为“hinge”。将训练集分别输入5个子模型进行训练,用测试集对5个子模型进行检验,使5个子模型达到最优效果。
2.5 构建多模型投票检测模型
为了提高检测模型的鲁棒性,本文结合投票法原理将5个子模型结合,构建了多模型投票(Mutimodel Voting Classifier,MVC)检测模型。MVC检测模型将5个分类器子模型作为投票器,每个分类器子模型单独训练样本集,输出每个样本为良性/恶意流量的预测值,按照少数服从多数原则进行投票,进而得到每个样本的最终预测值。
3 实验验证
为验证本文方法的有效性,对MVC检测模型进行了实验。实验环境为Python 3.7,通过调用scikitlearn[19]库来构建机器学习模型。
3.1 数据集
本文使用的是开源CTU-13[20]数据集,该数据集是在特定场景中分别执行13个恶意家族软件并收集恶意软件感染过程所产生的流量,包括良性流量子集和13个恶意家族流量子集。由于恶意家族的软件在真实的网络环境中所产生的攻击行为具有同源性,对于某一个家族来说,其在攻击任何网络主体时,所产生的流量行为具有高度的相似性。基于恶意家族的特性,CTU-13数据集的采集环境可以很好地代表煤矿网络面临的攻击环境。
本文在CTU-13数据集中挑选了7个恶意pcap流量包和1个良性pcap流量包,对MVC检测模型进行验证,其中,每个恶意pcap流量包中只包含一种恶意软件产生的TLS加密恶意流量。利用Wireshark工具将所获取的pcap流量包按时间序列进行合并,得到1个恶意流量包和1个良性流量包。将流量包进行数据清洗,删除冗余、无效的信息,忽略TCP(Transmission Control Protocol,传输控制协议)校验和无效的流量。实验所用流量数据集(表2)共有314 733条良性流量(含51 373条TLS加密流量)和657 198条恶意流量(含35 383条TLS加密流量)。
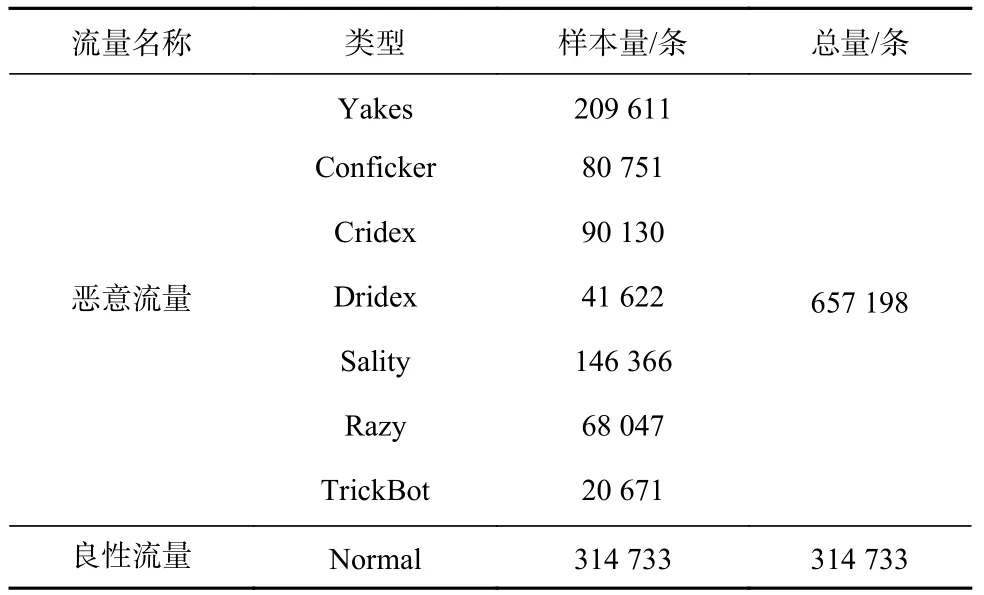
表2 流量数据集Table 2 Traffic dataset
3.2 性能指标
为更加客观地评价MVC检测模型的有效性,本文从2个方面对模型进行评估:① 使用准确率A、召回率R、F1分数(精确率和召回率的调和平均数,即认为精确率和召回率同等重要,权重都为1)和误报率W(正样本被预测为负样本的概率)检验模型分类效果。② 从检测模型错误分类的TLS加密流量样本量来进行评估。

式中:NTP为被正确识别为正样本的正样本;NTN为被正确识别为负样本的负样本;NFP为被错误识别为负样本的正样本;NFN为被错误识别为正样本的负样本;P为精确率。
3.3 模型检测结果
将训练集输入5个分类器子模型和MVC检测模型进行训练,用测试集检验模型性能,测试集样本总量为307 179条,其中恶意样本量为198 944条,TLS加密良性样本量为10 476条,TLS加密恶意样本量为15 372条,模型性能对比见表3。
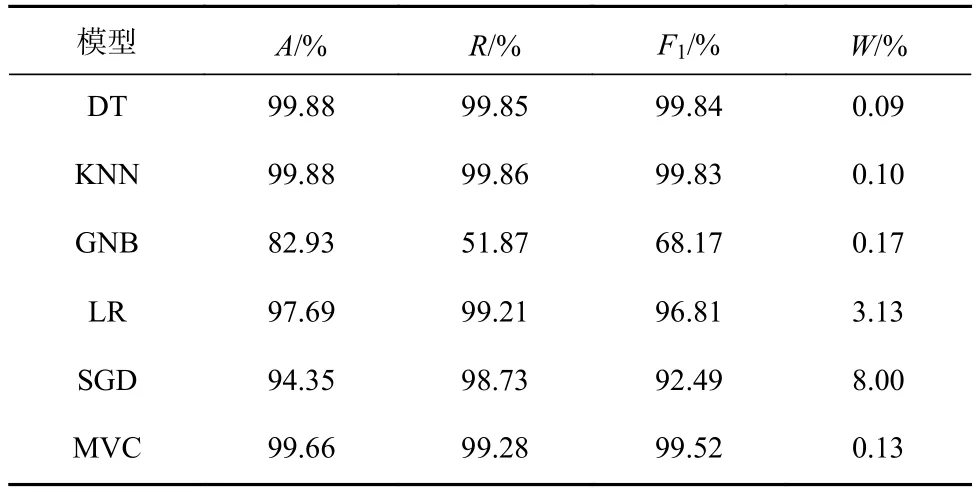
表3 模型性能对比Table 3 Comparison of the performance of models
由表3可看出,本文所提出的多特征融合特征集在DT分类器、KNN分类器和LR分类器子模型上有良好的表现,其中DT分类器和KNN分类器子模型表现较好,准确率和召回率达99%以上,误报率均在0.10%以下。而GNB分类器和SGD分类器子模型的检测结果相对较差,主要是因为GNB分类器子模型对数据表达形式比较敏感,经过特征工程处理的特征集将文本类特征转换为数值类特征,使得该分类器的表现有所下降,但其能够有效降低误报率,使得其在投票过程中依旧能够发挥优势。SGD分类器子模型对数据缩放和特征降维比较敏感,对于恶意流量检测检测效果较好,但其误报率较高。MVC检测模型准确率为99.66%,召回率达99.28%,F1分数为99.52,误报率为0.13%,提高了加密恶意流量的检出率。
模型错误分类TLS加密样本数量如图4所示。可看出MVC检测模型在数据集上实现了对TLS加密恶意流量的“零误报率”。
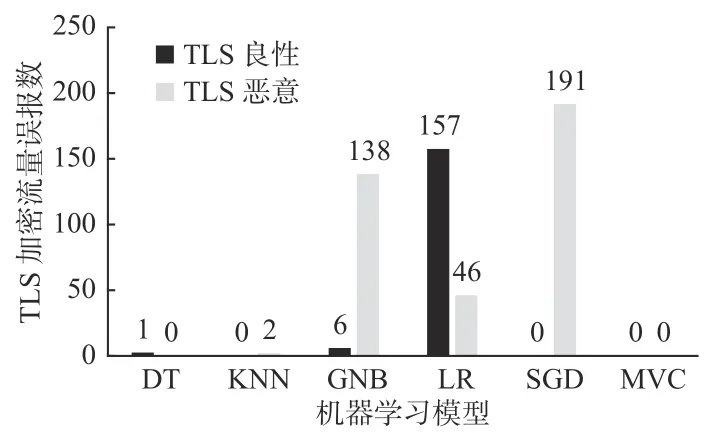
图4 模型错误分类TLS加密样本数量Fig. 4 Number of TLS encrypted samples misclassified by models
4 结论
(1) 所构建的特征集降低了样本集维度,提高了TLS加密流量检测效率。
(2) DT分类器和KNN分类器子模型在特征集上有良好的表现,其中准确率和召回率均在99%以上,误报率均在0.10%以下;GNB分类器子模型表现最差,召回率仅达51.87%;SGD分类器和LR分类器子模型具有相似的表现,其误报率都很高。
(3) MVC检测模型的准确率达99%以上,误报率为0.13%,提高了加密恶意流量的检出率。
(4) MVC检测模型在数据集上实现了对TLS加密恶意流量的“零误报率”。
