多路系统Cache一致性验证中的错误追踪定位技术*
2022-08-11巨鹏锦计永兴
李 辉,巨鹏锦,计永兴
(上海高性能集成电路设计中心,上海 201204)
1 引言
在信息化革命早已席卷全球的今天,人们比以往任何时候都更依赖计算机,而在计算机的各种存在形态中,服务器拥有无可替代的重要地位,担负着对信息的存储、筛选、分析和加工等诸多任务。近年来,随着国家信息安全战略的稳步推进,国产服务器作为“十三五”期间国家信息安全链上的重要一环,已成为重点发展的对象。面对大数据、云计算对服务器处理器在运算能力、主存容量和网络服务能力等方面的需求,国产高性能服务器处理器的研制也从多核发展阶段进入到多路系统阶段。处理器设计的复杂度和规模成倍增长,而硬件设计能力与验证能力的差距在不断增大[1],验证周期不断增长,甚至贯穿整个芯片开发周期[2]。面对高性能处理器设计复杂度和规模不断增大的挑战,业界采用了模拟验证[1 - 4]、硬件仿真加速验证[5,6]、FPGA原型验证[7]和形式验证[6,8]等方法开展验证工作,其中模拟验证仍然是处理器验证的主要手段。
支持多路直连的服务器处理器可通过高速直连接口构建主存全共享的SMP(Symmetric MultiProcessor)系统,这使得处理器的验证复杂度从单处理器规模上升到了多处理器系统级规模,Cache一致性的验证也从单路多核处理器规模上升到了多路多核处理器规模,不但规模更大,而且Cache一致性协议实现更复杂。多路系统的验证不仅验证充分性更加难以保证,而且在模拟验证中追踪定位错误的难度越来越大,甚至严重影响了验证效率。
对处理器模拟验证结果检查的方式一般采用基于参考模型的验证方法[2,5,8,10],检查的是处理器设计在指令完成时的结果。对运算类指令而言,由于其执行周期固定,因而错误定位精度可以达到时钟周期级;但对于访存指令而言,本身指令执行的周期就不固定,而且在多路系统中,从错误发生的第一现场至反映到指令执行结果与参考模型结果比对不相等,这个时间跨度可能有几千个时钟周期甚至上万个时钟周期,而且错误数据传播的路径可能会非常长,而处理器的设计非常复杂,每个设计人员通常只了解跟自己相关的功能实现,因此这样一个错误的查错经常需要在多个设计人员和验证人员之间来回交互,查错工作需要几乎所有相关人员参与,如果错误比较复杂,有时查错时间甚至可以达到1~2天。在这种情况下,原有基于参考模型的验证方法只是解决了正确性比较的问题,而追踪定位第一出错点基本上都是靠人工完成,导致查错效率极低,亟待探索新的方法。
本文以某国产多路系统的验证为例,基于事务级验证TBV(Transaction Based Verification)技术[11],提出并实现了一种可以应用于模拟验证的自动错误追踪定位方法,实现了多路系统模拟验证环境中错误的自动追踪定位,显著缩短了错误定位时间,提升了多路系统模拟验证的查错效率。
2 验证需求分析
2.1 待测处理器介绍
本文以某款国产多路系统的Cache一致性验证为例进行需求分析。该国产处理器有32个核心,每个核心内包含了一个32 KB的一级指令Cache和一个32 KB的数据Cache,以及一个256 KB的二级Cache。处理器片内采用基于目录的Cache一致性协议实现,所有核心共享一个64 MB的三级Cache。处理器间可通过直连接口构建2路或4路系统,多路系统中处理器之间使用广播监听协议保证处理器之间的Cache一致性。
该处理器的待测DUT(Design Under Test)逻辑结构如图1所示,Core表示核心;LCPM为三级Cache控制部件和片内Cache一致性协议处理部件;GCPM为全局Cache一致性协议处理部件,主要处理多路系统间的Cache一致性;MC为DDR4存储控制器,负责DDR4内存的读写访问控制。
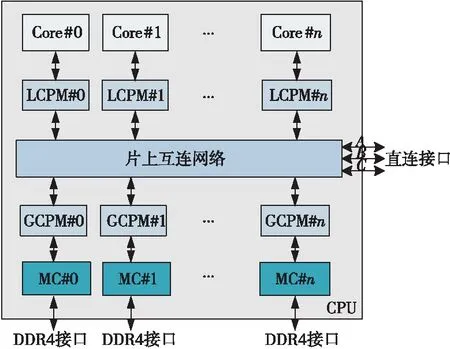
Figure 1 Logic structure of DUT processor图1 处理器的待测逻辑结构
多路系统通过处理器提供的A、B、C共3个直连接口互连,多路系统结构如图2所示。
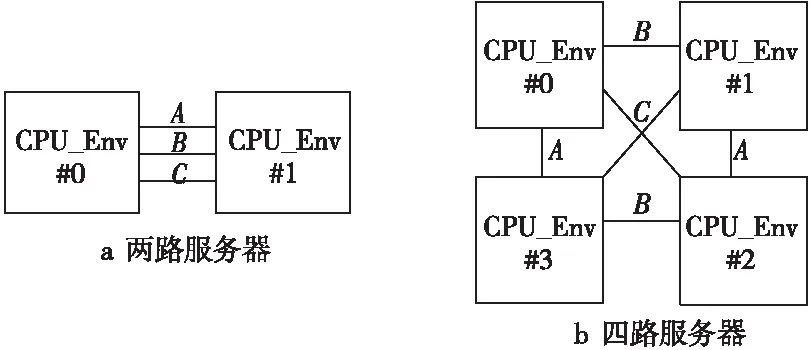
Figure 2 Multi-processor system architecture图2 多路系统结构
2.2 难点与需求分析
由于采用了目录和广播监听两级Cache一致性协议,且四路系统的核心数量最多可达128核,因此该处理器Cache一致性验证不但环境规模大、功能复杂,而且错误的追踪定位也成为了一个难点。
首先,Cache一致性协议非常复杂,一个典型的处理流程就包含了Local-CPU(请求源CPU)、Home-CPU(请求目标CPU)和多个Peer-CPU(对等CPU),还涉及片内一致性处理流程和片间一致性处理流程,如图3所示。从图3中可以看出,该处理器Cache一致性处理过程的特点是涉及的设计部件数量多、处理流程步骤多和飞行中的各类消息类型种类多。据统计该协议中包含的消息类型共计9个大类,87个子类,为理解协议和查错带来了很大困难。

Figure 3 Example of multi-processor system cache coherence 图3 多路系统典型Cache一致性处理示例
其次,该验证环境中查错遇到的困难还包括:
(1)由于接口协议十分复杂,解析错误波形的信号总线非常繁琐。
(2)由于设计实现要考虑硬件开销,不同部件之间传递的信息都是必要最小集,因此查错需要的信息在某一时刻的特定接口上通常是不完整的;另外,还有些消息包的控制信息和数据信息会通过不同的物理通道分开传递,造成时间上的不同步,需要根据ID号或其他信息向前回溯,同时结合多个部件接口分析才能得到,这一过程费时费力、难度大、易出错。
(3)查错时通常要在波形上搜索和筛选关键信息,缩小关注范围,由于设计和环境复杂,各个部件接口的信息量很大,且错误第一现场距离出错点的时间范围有可能跨度很大,这些都增加了搜索和筛选信息的难度。
(4)由于处理器的设计非常复杂,每个设计人员通常只了解跟自己相关的功能实现,因此一个错误的查错经常需要在多个设计人员和验证人员之间来回交互,增加了人力和时间开销。
(5)同样由于设计和环境规模很大,记录信号级波形不但严重影响模拟运行速度,而且空间占用也很大,给查错工作增加了很大代价。
通过上述分析可以看出,研究探索一种自动高效的错误追踪定位技术,对于解决多路系统Cache一致性验证中遇到的错误定位困难是非常必要的,上述关键难题的解决对提高验证效率非常有帮助。
3 错误追踪定位技术研究
3.1 基于参考模型的验证方法
处理器的模拟验证主要还是基于参考模型的正确性检查方法,典型的环境结构如图4所示。处理器的参考模型通常都采用指令集模拟器ISP(Instruction Set Processor),实时比较的内容通常是每个设计核执行完指令后的目标寄存器结果与参考模型结果做比较。
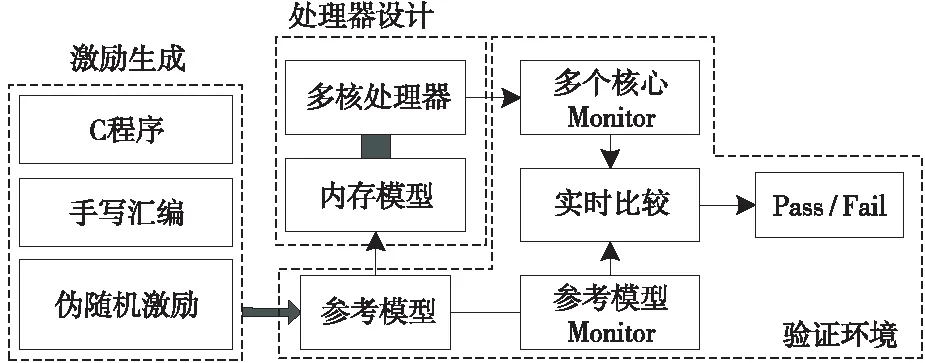
Figure 4 Verification environment based on reference model图4 基于参考模型的验证环境结构
为了保证参考模型的功能正确性,指令集模拟器基本上只实现软件可见的处理器结构,如寄存器和页表快表TLB(Translation Look-aside Buffer)等。而与处理器流水线站台密切相关的结构,比如Cache,因其行为与很多微结构紧密相关,难以与实际设计进行比对,因而对于访存指令而言,尤其是写指令结果,难以通过检查Cache状态和内容做判断,而写一旦出错,往往需要等到相关地址的读指令结果与参考模型结果比较不相等后才能发现,因此从错误发生的第一现场至反映到指令执行结果与参考模型结果比对不相等,这个时间跨度可能会非常长。
传统的基于监测模块Monitor的模拟验证环境中,Monitor会在日志文件中记录状态检查和调试查错时需要的各种信息,查错时利用这些信息进行分析和追踪。在多路系统中,不仅每个核心都会有一个Monitor,有些部件也有自己的Monitor,如果采用这种基于日志的记录方式,整个验证环境中会生成上百个日志文件,信息量非常大,而且难以有效关联搜索,从而导致查错效率不高。
因此,探索一种有效的错误追踪定位技术,既要能够与基于参考模型的处理器验证环境相结合,还要解决环境中调试信息的采集、记录和搜索筛选问题。
3.2 事务级建模和错误追踪技术
基于事务的验证TBV技术是一种成熟验证技术,在系统级验证的建模中事务级建模TLM(Transaction-Level Modeling)被广泛采用,也常用于RTL级的模拟验证[12,13]。多数HDL(Hardware Description Language)模拟器都支持通过特定的库接口将事务级的数据写入生成的波形数据库,从而帮助设计和验证人员在事务级对设计和环境的行为进行分析。通常EDA工具提供的事务级波形查看工具可以支持搜索和筛选功能。
以Cadence公司IES(Incisive Enterprise Simulator)模拟器为例,该工具支持通过C++接口定义的SDI2(Simulation Database Interface version 2)库,在模拟环境中实现事务级信息的采集,并且记录到生成的波形数据库中。图5是SDI2库的结构和事务定义方法[13]。
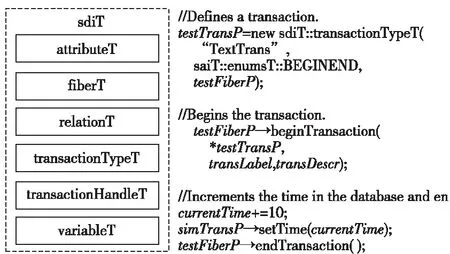
Figure 5 Structure of SDI2 library and TBV definition图5 SDI2库的结构和事务定义方法
将Monitor的日志记录方式改为事务记录方式后,能够实现事务信息与波形数据库的紧密结合,通过工具支持还可以实现快捷的信息搜索和筛选。另外,事务级波形所占空间远小于信号级波形,而且对模拟速度的影响更小。
TBV技术为解决多路系统Cache一致性验证提供了技术支撑,利用TBV技术对Cache一致性验证环境建模,如何实现错误的快速追踪定位,还需要考虑以下方面的问题:
(1)事务级建模的原则。
如何确定建模要覆盖的设计部件和层次?如上所述,该多路系统的Cache一致性处理流程复杂,涉及的设计部件众多,是否所有的部件都需要进行事务级建模?是否需要在部件级以下进行模块级建模?
就本文来说,事务级建模的原则应该从建模的目的出发,建模是为了方便进行Cache一致性错误追踪和定位,因此建模的原则可以归纳为:
①建模应该至少覆盖Cache一致性消息传输的关键通路,例如各层级缓存控制器(Cache Controller)接口、主存控制器(Memory Controller)接口和片上互连网络NoC(Network on Chip)接口等。
②处理器核心的访存流水线建模通常包含LQ/SQ(Load/Store Queue)、MAB Tag(Missed Address Buffer Tag)和WCSB(Write Combining Store Buffers)等。如果核心相对比较成熟,也可只对核心对外的接口建模,这样性价比更高。
③推荐在部件级层次建模。一方面,部件级通常有专职的设计人员负责,当错误定位到部件级后就不再需要在多名设计人员和验证人员间反复交互了;另一方面,部件级功能相对完整,事务级建模更加简洁清晰,如果在模块级建模,因接口协议更加琐碎会导致建模的难度加大,事务级验证的性价比降低。
(2)事务的属性和功能定义。
确定了事务级建模的部件和层次后,就需要从设计的功能实现和验证需求方面考虑事务级建模需要实现的功能。本文着重从Cache一致性验证错误追踪定位的需求出发确定事务属性和功能,主要包括:

Figure 6 Implementation of automatic error trace environment 图6 自动错误追踪环境的实现原理
①要能够对每个访存请求进行唯一标识,以实现对其全流程的精确追踪。由于设计中可能并不存在这样的一个唯一标识,因此实现时需要结合信息的源和ID,甚至需要增加时间戳等信息来实现。
②同一个请求引起的所有事务均携带相同的事务唯一标识号,以方便建立这些消息之间的联系。
③每个事务都必须定义消息类型属性,且类型要覆盖所有消息。
④访存地址要精确到Cache块地址(Cache Block Address),且应该携带所有中间过程的请求或响应。
⑤不同的事务属性通常在不同的运行阶段才能得到,因此实现时要确定登记内容的时机。由于设计中的信息在时间和空间上都是分布形成和传播的,因此事务建模时需要构造一张或者多张表来集中记录这些信息,以此为基础来定义和实现事务模型。
(3)基于事务模型的错误自动追踪和定位。
事务级建模完成后就可以在模拟时生成事务级波形了,通过EDA工具提供的用户界面可以对事务信息进行搜索和查错[14]。虽然相比信号级波形查错效率得到了提高,但是仍然需要很多人工操作,且很多情况下都是重复性工作,因此需要探索错误的自动追踪和定位技术,以进一步提高查错效率。
EDA工具提供了一种TxE(Transaction Explorer)[14]脚本语言。该语言主要由TCL(Tool Command Language)构成,结合工具提供的接口命令,可以实现比较复杂的搜索算法。以此为基础并结合Cache一致性的功能流程可以实现自动的错误追踪定位功能。实现时需要考虑的问题主要包括:
①定义错误类型,例如响应超时、数据比较不等和故障报错等。错误类型不同,其查错方法也不同。
②基于事务级的错误追踪要与基于参考模型的实时比较报错信息相结合。基于参考模型的实时比较报错信息包含查错的指令信息,如PC、出错时刻、错误结果和期望数据等,访存指令信息还包含访存虚地址和物理地址信息。基于这些信息可以编写程序实现在事务级波形中的信息检索。
③针对不同的错误类型,要根据设计处理流程实现不同的追踪算法,可以根据错误出现的频繁度优先实现常见错误的自动追踪功能。
事务级建模和参考模型相结合的自动错误追踪环境的实现原理如图6所示。事务级模型开发的主要工作是结合设计的功能,定义一系列关键信息的数据结构,并基于此对DUT内的关键模块进行事务建模,将各种功能流程中的数据流和控制流定义为一系列的有向图模型,以便追踪出错模块。传统正确性检查的手段还包括断言检查ABV(Assertion Based Verification)和参考模型比较,这些手段可以实时监测错误并终止模拟运行,同时将出错信息写入日志。出错后,验证环境会解析出错日志,对错误自动分类并标记,错误追踪定位工具结合模拟出错日志和错误类型,通过TxE接口访问事务波形,根据定义的规则库(追踪算法)找到出错的模块和错误时刻,验证和设计人员可以据此信息通过信号波形完成对错误的最终定位。
4 错误追踪定位环境的实现
通过上述分析,本文在某款国产多路系统的Cache一致性验证环境中实现了事务级建模和参考模型相结合的自动错误追踪环境,如图7所示。
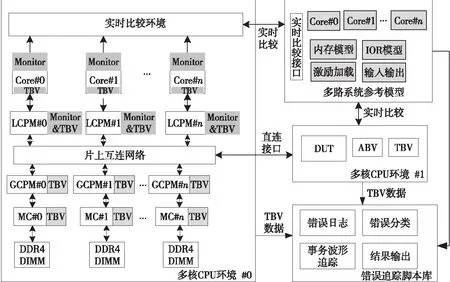
Figure 7 Multi-processor system cache coherence verification environment图7 多路系统Cache一致性验证环境
从图7可以看到,该环境由2个相同的多核CPU环境、多路系统参考模型和错误追踪脚本库组成。每个多核CPU环境都包含了设计DUT、断言检查ABV、事务级建模TBV、监测模块Monitor、实时比较和DDR4 DIMM模型等验证组件。图中TBV的设计部件包括核心的核外接口、LCPM部件、GCPM部件和存控MC部件。验证环境支持2个或4个多核CPU互连或者虚拟多核CPU(VCPU)通过直连接口互连;支持基于多路系统参考模型的核心级实时比较;支持错误追踪脚本库收集实时比较环境的错误日志,分析错误类型,访问TBV波形数据并追踪错误等。
在本案例实现中,事务级建模的层次和位置在选择时统筹考虑了错误定位精度、建模位置和编程工作量。建模位置决定了错误定位的精度,为了迅速定位错误,可以考虑在顶层各个部件之间进行建模。部件之间连线比较规整,并且传输包的关键信息一般接口可见,建模后可从事务级波形上直观查看各类包的传输,给验证人员提供了极大便利。
事务包格式的确定跟待测芯片行为紧密相关。事务包格式主要指包的关键信息,本文验证对象的主要行为是多路系统以及处理器外设的访存一致性设计。因此,包格式需包括访存地址、数据、请求响应类型和请求响应ID等。如果存在控制包和数据包在2个物理通道传输或数据包分多个子包传输情况,在编程时需要将控制和整个数据封装在一个包内。特殊情况下,仅使用接口信号无法完整表达协议包之间的关系,可能需要结合部分模块设计代码来编写TBV代码,完成TBV包的创建。下面以GCPM模部件为例说明建立请求事务包的方法,首先定义MONITOR_GCPM模块,声明输入信号,然后根据接口协议把接口信号转化成事务包:
moduleMONITOR_GCPM
(
inputClk;
input [2:0]i_LocalNld;
inputB2G_HomVld;
input [63:0]B2G_HomInf;
)
HOM_TYPEM_B2G_Hom,c_InvHom;
integerHomFiber,DatFiber;
integerHomHandle,DatHandle;
initial
begin
c_InvHom=GenInvHom();
HomFiber=$sdi_create_fiber("sdi+B2G_Hom","TVM");
end
always@(negedgeClk)
begin
if(B2G_HomVld) task_b2g_hom;
end
taskautomatic task_b2g_hom;
begin
M_B2G_Hom=c_InvHom;
M_B2G_Hom.Type=HOM_CODE′(B2G_HomInf[4:0]);
M_B2G_Hom.Offset=B2G_HomInf[7:6];//Addr[6:5]
M_B2G_Hom.Addr=B2G_HomInf[43:8];//Addr[42:7]
……
HomHandle=$sdi_transaction("BeginEnd",HomFiber,"CAB2GCPM_HOM");
$sdi_set_attribute(HomHandle,M_B2G_Hom.Type);
$sdi_set_attribute(HomHandle,M_B2G_Hom.Addr);
……
@(posedgeClk);
M_B2G_Hom=c_InvHom;
$sdi_end_transaction(HomHandle);
end
endtask
endmodule
错误追踪搜索结合TxE脚本和Python脚本实现,TxE脚本实现部分代码如下所示:
txe_search_create search TB{
source{
}
init{
seterr_addr0x80161d//错误访存地址
}
#capture all the transactions with a child in the database apply{
fiber*{
trans_type*{
setaddr{attribute"Addr"}
if{$addr==$err_addr}{
setlast_time[tformat12.2ns [end_time]]
set_attributelasttime$last_time
accept
}
}
}
}
settext_file[open "err_info.log""w"]
puts $text_file"Some Utilization Stastics for a bus modele"
puts $text_file""
foreachs[txe_search_get_list]{
#Execute the search.
txe_search_execute$s//执行搜索算法
#Write the results table
puts $text_file"[txe_search_get_path $s]"
puts $text_file"-----Error Transaction Flow-----"
txe_table_write$text_filetext$s
puts $text_file"------------"
}
下面以一个响应超时的错误为例展示错误追踪过程:
CG0 mpe7 ROB Timeout!!!
"The ROB Addr is 0x400000088
Calling Stop_run() from at line 60 in @ds_bfm_quit.
上述代码表示模拟环境报错,终止运行,错误信息含义为7号核心出现指令响应超时“ROB Time Out”,并且给出了错误的物理地址。
多路系统的访存通路非常长,事务级查错方法与常规方法一致,都是根据处理流程由正向或逆向逐级递推来查错。以下是针对此“ROB Time Out”错误的查错过程。
(1)根据出错地址查询GCPM接口的事务波形,得到的结果如图8所示。波形描述的是CPU0发起独占数据读请求“vcpu_RdDataM”,GCPM收到了CPU0的独占读请求和另外3个VCPU的无效监听回答“vcpu_RspI”,由GCPM向CPU0推送了独占数据及完成消息“vcpu_AckDataE_Cmpl”,因此数据响应是向上游推送了的,GCPM的功能正确。
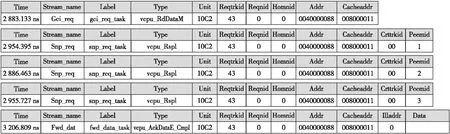
Figure 8 Step 1 for acknowledge timeout debug demo图8 响应超时查错演示步骤1

Figure 9 Step 2 for acknowledge timeout debug demo图9 响应超时查错演示步骤2
(2)继续查看CPU0的LCPM部件,用出错地址进行查询,如图9所示,发现LCPM发送了独占读请求“vcpu_RdDataM”和独占监听请求“vcpu_snpDataM”后,并未收到完成消息,说明是LCPM与GCPM之间的桥接模块出现了问题,可以定位错误在桥接模块。如此,一个在四路直连系统中出现的错误经过2次查询就可以锁定错误模块,大大缩减了错误定位时间。
本文使用Python和TxE脚本实现了多种常见错误的自动追踪定位,查错效率得到进一步提升,而且对查错人员的能力要求大大降低,从而使得整个验证团队工作效率都得到了提升。图10展示了对出错访存地址“0x00080161D”的自动追踪过程,问题发生在CAB0给了GCPM请求但GCPM没有将请求继续转发出去,因而最终定位出错模块为GCPM,出错时刻为第2 844.7 ns。

Figure 10 Example of automatic error trace by scripts图10 自动化脚本错误追踪示例
5 应用效果
5.1 事务级建模代价分析
表1统计了本文TBV建模部件的RTL代码行数和TBV代码行数,“TBV_Def”部分主要是事务级包的数据结构定义,不属于DUT。从统计数据来看,TBV建模代码行数与对应部件的RTL代码行数不存在正相关关系。TBV代码行数与RTL代码行数之比最大的模块是芯片顶层SOC_TOP,该TBV并不复杂,主要定义了TBV Monitor例化和TBV Monitor间的连线。其次比例较高的分别为RN和DLX,RN为DUT的片上网络,DLX为DUT的片间网络,因为接口众多,使得TBV代码量较大。从总体数据看,TBV建模的代码量是被测设计的3.2%,开发代价不大。
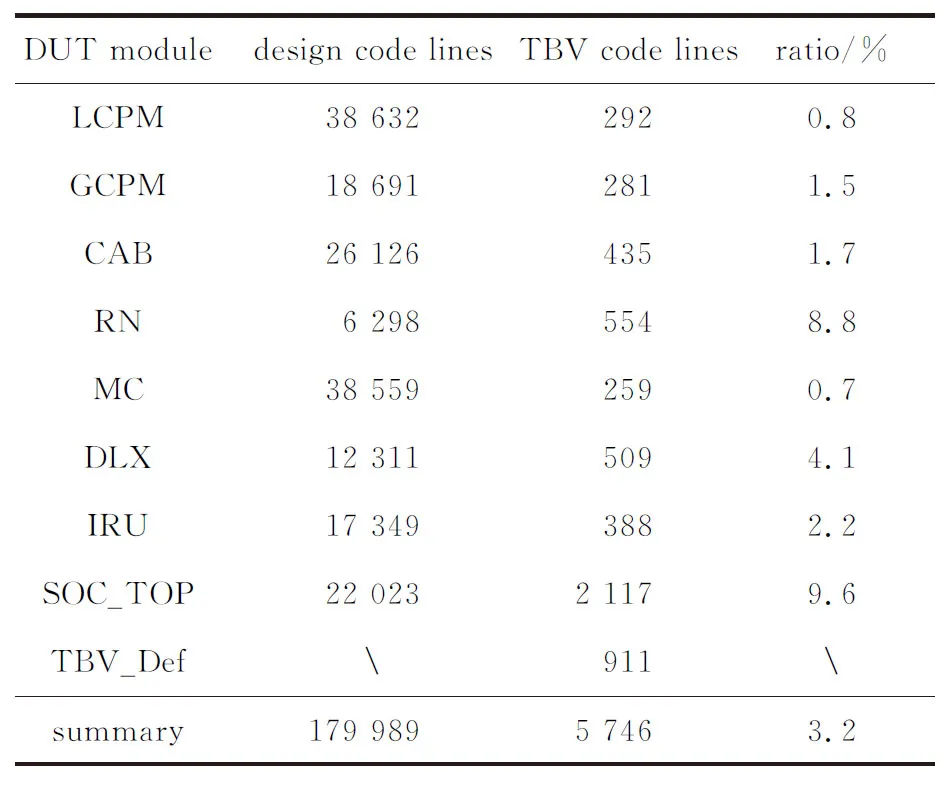
Table 1 Statistics of DUT and TBV code lines表1 被测设计和TBV代码行数统计
从与设计的耦合程度分析,TBV建模只关注事务包在DUT模块间的传递和处理结果,并不关注DUT模块内部的处理过程,因此只需要对DUT模块的接口进行TBV建模,表1的统计数据也印证了这一点。
5.2 事务级建模优点
本文多路系统的Cache一致性验证采用事务级环境和自动错误追踪技术后,相比原有验证技术在功能、性能和效率等多个方面都得到了提升,主要表现在以下几点:
(1)事务级波形可读性更强,错误追踪方便。如图11所示,上部分为信号级波形,接口信号分别为64位和288位,分析波形时必须对照接口协议按位解析;下部分为事务级波形,能直观地看到事务级协议内容。

Figure 11 Signal level waveform and TBV waveform 图11 信号级波形与事务级波形
(2)从波形占用空间大小和对模拟速度的影响方面来说,事务级验证更具优势。如图12所示,模拟环境为1个真CPU(32核)+3个VCPU构成的四路系统,运行时间为21万个时钟周期。

Figure 12 Comparison of TBV waveform and signal level waveform图12 事务级波形与信号级波形对比
(3)错误追踪速度和定位精度大幅提升。从图12可以看出,当设计规模比较大时,全部跟踪波形不但文件很大,而且速度很慢。常规查错方法是根据出错时间点仿真前后一段时间内的波形进行错误跟踪,但如果跟踪的波形没有包含第一现场,则需要将波形跟踪点前移并重新运行,如此反复直至找到错误原因。事务级方法的优势在于,当设计规模比较大时,在不明显影响运行速度的情况下,仍然能够记录全部事务级波形,完整便捷的信息检索可以精确、快速定位第一现场,解决了常规方法反复迭代的问题。
(4)新增的事务级覆盖率分析使得覆盖率量化分析更加全面。
覆盖率驱动的验证方法CDV(Coverage Driven Verification)是当今主流的验证方法,覆盖率作为一种定量度量手段对判断验证充分性、指导激励生成有重要作用。通常将覆盖率分为2大类:代码覆盖率和功能覆盖率。代码覆盖率包含行覆盖、分支覆盖、状态机覆盖、表达式覆盖和翻转覆盖等多种类型,由EDA工具自动生成。功能覆盖率由设计者或验证者使用SV(System Verilog)或PSL(Property Specification Language)语言定义,主要是依据设计的功能描述定义功能验证点,实际实施过程中一般由设计者在模块级或者部件级定义,相对代码覆盖率而言,功能覆盖率偏主观。
事务级验证不仅大大提高了查错效率,还带来了一个额外的好处,那就是验证者可以基于事务级环境描述和分析功能覆盖点,包括芯片级、系统级和协议级的功能覆盖分析。其分析方法与使用SV或PSL描述功能点的方法不同,事务级覆盖分析主要是基于事务级波形,通过编写事务级覆盖率查询程序,生成事务级覆盖率报告,例如模块在一定时间范围接收和发送的特定类型包数量、Cache一致性处理流程的各种情况统计等。
引入事务级覆盖分析后,使得覆盖率分析可以从3个维度进行度量,如表2所示,分别是工具自动分析生成的代码覆盖率、设计者角度定义的功能覆盖率和验证者角度定义的事务覆盖率。

Table 2 Characters of the coverages表2 各类覆盖率分析的特点
6 结束语
本文介绍了一种将事务级验证技术应用于多路系统验证的方法,实现了在事务级环境下对多路系统Cache一致性验证的错误自动追踪定位。该方法不仅提升了复杂多路系统的验证效率,而且新增的事务级覆盖率分析使得覆盖率量化分析更加全面。该方法也可推广于其他SoC芯片的验证中,具备一定的应用价值。后续研究如何将该方法普适化形成一个框架,以适应更广泛的设计类型和更多样的设计变化。
