面向Flink的负载均衡任务调度算法的研究与实现*
2022-08-11李文佳季航旭罗意彭
李文佳,史 岚,季航旭,罗意彭
(1.东北大学计算机科学与工程学院,辽宁 沈阳 110169;2.辽宁工业大学软件学院,辽宁 锦州 121000)
1 引言
近年来,随着数据经济在全球的加速推进,以及5G、人工智能、物联网等相关技术的快速发展,全球数据量迎来巨大规模的爆发,越来越多的政府机构和研究人员开始重视这种大量数据的收集、使用与处理。伴随着数据的爆炸式增长与多种多样需求的出现,一些传统的大数据模型和分布式计算引擎已经很难满足当前业务的需求,因此,许多新的分布式计算框架应运而生。大数据计算引擎的发展历程主要分为4个阶段。第一代大数据计算引擎是谷歌于2004年提出的基于MapReduce[1]的Hadoop[2]计算引擎。Hadoop主要依靠把任务拆分成map和reduce 2个阶段去处理,这种模式由于难以支持迭代计算,因此产生了第二代基于有向无环图DAG(Directed Acyclic Graph)[3]的以Tez[4]和Oozie为代表的计算引擎。虽然第二代计算引擎解决了MapReduce中不支持迭代计算的问题,但是由于这种计算引擎只能处理离线任务,在线任务处理需求增加的驱动下,产生了第三代基于弹性分布式数据集RDD(Resilient Distributed Dataset)[5]的Spark[6]计算引擎。Spark既可以处理离线计算也可以处理实时计算,它是在Tez的基础上对Job作了更细粒度的拆分,但是其延迟较大,难以处理实时需求更高的连续流数据请求。因此,产生了现在主流的可以处理高实时性任务的第四代大数据计算引擎Flink[7]。Flink对事件时间的支持、精确一次(Exactly-Once)的状态一致性以及内部检查点机制等特性,决定了其在大数据计算引擎上占据主流地位。现如今越来越多的公司采用基于Flink的大数据计算引擎去实现多种场景,比如阿里巴巴双十一实时大屏的投放、腾讯实时平台的搭建以及美团、饿了么、爱奇艺等公司的数据处理流程都是基于Flink构建的。
在大数据计算引擎Flink中,大量的计算任务需要被调度到资源节点上,如何使整体任务用最少的完成时间,在很大程度上由它的调度算法决定,因此良好的任务调度算法是分布式计算的重要组成部分。有效的任务调度是分布式计算的一个关键问题,其目标是在满足任务依赖关系的前提下,调整任务的执行顺序,将任务分配给对应的资源,使整个系统的任务能在最短的时间内执行完成。
由于集群的异构性以及不同算子复杂度不同,大数据计算系统中不可避免地会出现负载不均的情况,本文提出了基于资源反馈的负载均衡任务调度算法RFTS(load balancing Task Scheduling algorithm based on Resource Feedback)。与传统的负载均衡算法不同的是,RFTS算法综合考虑了集群计算资源的实时负载情况以及处理任务的优先级和顺序,更高效地完成任务与计算资源之间的分配,通过实时资源监控、区域划分和基于人工萤火虫优化GSO(Glowworm Swarm Optimization)的任务调度算法3个模块,把负载过重的机器中处于等待队列中的任务分配给负载较轻的机器,提高系统处理任务的执行效率和集群利用率。
本文的主要贡献包括以下3个方面:
(1) 设计了一个Flink系统的实时监控系统Monitor,实时监控每个从节点(Slave)的CPU核数、CPU利用率、内存利用率和总内存大小等性能指标,从而获取每个资源节点的负载大小。
(2) 提出基于资源反馈的负载均衡任务调度算法。该算法在集群出现负载不均时,重新分配每个资源节点的任务,以提高系统执行效率和整体资源利用率。该算法通过实现的实时监控系统Monitor来监控资源节点的负载情况,并根据区域划分算法把集群划分为过负载、轻负载、近饱和和差饱和4个区域,由于过负载区域的机器负载过重会影响整个集群的执行效率,因此用基于人工萤火虫优化算法的调度策略,把过负载区域中资源节点位于等待队列的任务调度给差饱和区域的资源节点。
(3) 通过编写源码,在大数据计算系统Flink中,实现了RFTS算法。
最后在TPC-C和TPC-H[8]数据集上对基于资源反馈的负载均衡任务调度算法进行了实验,实验结果表明,该算法在执行时间和吞吐量方面均有明显的提升效果.
2 相关工作
任务调度是指系统将用户提交的任务通过某种方式进行拆分、重组并分配到集群中对应的资源节点进行计算的过程。众所周知,任务调度问题是NP-hard[9]。大数据计算模型是一种新型的分布式计算模型,专门用于处理海量数据的存储、分析和计算,其优点在于能以使用较低的时间和空间成本来实现系统的高可扩性和可伸缩性。这些决定了大数据计算模型不仅可以应对数据日益增长的计算、存储和分析需求,也可以很好地满足并适应网络环境中复杂多变的特点,保障基本的网络性能请求。大数据计算中资源的服务质量好坏是衡量大数据计算效果的一个重要方面,但是大数据计算中云端存在诸多形态,且系统规模巨大,资源节点之间的结构差异性也较大,因此如何更好地实现任务调度就成为了大数据计算研究中的热点和难点问题。
调度算法的目的是将任务调度到资源节点的同时使得任务的执行时间和吞吐量尽可能好。任务执行所需要的资源、网络IO、耗费的时间和用户需求等都由任务调度策略决定。因此,在分布式计算中任务调度很大程度上决定了分布式计算系统的系统性能。
分布式计算中常用的调度算法有经典调度算法和启发式调度算法。经典调度算法主要有Max-Min算法[10]、Max-Max算法和Sufferage算法[11]、先到先服务、轮询调度算法[12]以及公平调度算法[13]等,这些算法由于参数少、操作简单、容易复现等优点被广泛使用。但是,这类算法也存在着面对复杂场景和数据频繁被调度的场景时任务分配效果较差、容易导致数据倾斜等缺点[14]。因此,研究人员提出了主要针对复杂场景的启发式调度算法。Holland于1975年通过观察生物界进化的规律,通过组合交叉、遗传和变异的方式提出了遗传算法[15];1991年意大利学者Dorigo通过模拟蚁群根据信息素的反馈信息不断改变寻找食物的速度和方向的行为提出了蚁群算法[16];1995年Eberhart和Kenny博士通过观察鸟群在迁移过程中根据其他鸟类的飞行轨迹来改变自身速度和位置的行为模式,提出了粒子群算法[17];还有现在被广泛使用的模拟退火算法[18]、差分演化算法[19]等。启发式调度算法虽然适合复杂场景并能够快速展开全局搜索,但也存在随机性过高、容易陷入局部最优解和参数难以控制等缺点。
Flink系统中默认的调度策略是轮询调度算法,这种算法不考虑每个资源节点的异构性,容易导致集群负载不均,使性能强的资源节点和性能差的资源节点面对同样多的任务,这时性能差的资源节点需要更多的时间,根据水桶效应,系统的执行效率是由性能最差的节点所决定的,因此集群负载不均会降低整个系统的执行效率。
基于上述分析可知,现有的调度算法不足以高效优化实时大数据计算系统Flink的执行速度,因此需要研究新的任务调度算法,使其在面对Flink系统复杂场景时能保证负载均衡且尽可能地提高系统执行效率。所以,本文提出了基于资源反馈的负载均衡任务调度算法RFTS。与传统的负载均衡调度算法相比,RFTS算法根据集群中每台机器当前的负载压力和任务优先级来快速而高效地分配任务,可以在不降低任务处理实时性的前提下,提高系统处理任务的总体执行效率。
3 基于资源反馈的负载均衡任务调度算法RFTS
由于集群的异构性以及不同算子复杂度不同,分布式计算系统中不可避免地会出现负载不均的情况。针对该问题,本文提出了基于资源反馈的负载均衡任务调度算法。
在本节中,首先介绍RFTS算法的基本思想;接着,借助实例分别介绍RFTS算法包含的3个主要模块。
3.1 定义与说明
首先对RFTS中用到的变量和公式进行定义与说明。令TM={TM1,TM2,…,TMm}为分布式系统中资源节点的集合,T={T1,T2,…,Tn}为需要执行的全部任务的集合。
定义1(任务整体完成时间) 任务整体完成时间是指从第一个任务执行开始到所有任务中最后一个任务完成所经历的时间,记为TotalTime。负载均衡的目标是使得TotalTime尽可能小。
定义2(资源节点性能指标) 资源节点的性能指标如式(1)所示:
Metricj=C1*Core_Numj*ω1j+
C2*(1-ω2j)*ω3j,j=1,2,…,m
(1)
其中,C1、C2为常数,Core_Numj表示资源节点TMj的CPU核数,ω1j表示资源节点TMj的CPU利用率,ω2j表示资源节点TMj的内存利用率,ω3j表示资源节点TMj的总内存大小。因此,资源节点性能指标Metricj由CPU核数、CPU利用率和空闲内存大小决定,最后作归一化处理。
定义3(资源节点负载值) 负载值代表该资源节点上任务负载量相对于该节点当前性能的承担能力。负载值越小,表示该节点承受负载的能力越好,即可以承受更多的任务;反之,负载值越大,该节点承受负载的能力越差,需要减少该节点执行的任务。负载值的定义如式(2)所示:
(2)
其中,TaskNumj表示资源节点TMj的任务队列中的任务数量;Metricj代表资源节点TMj的性能指标,Metricj越大,代表该资源节点性能越好,可以在单位时间内处理更多的任务;反之,则代表该资源节点的性能越差,在单位时间内能够处理的任务越少。
集群负载平均值的定义如式(3)所示:
(3)
定义4(集群负载值) 集群负载值表示整个集群的负载均衡程度,如式(4)所示。如果集群负载值C_Load小于阈值β,则说明集群整体负载处于均衡状态,算法结束;否则,集群负载值越大,说明集群负载不均的程度越高,此时需要将每个节点的负载值和集群负载值存入MongoDB数据库中,为下一阶段的区域划分和任务重新调度做准备。
(4)
3.2 主要思想
由于Flink系统中任务以随机顺序调度,本文提出了一种基于资源反馈的负载均衡任务调度算法,算法构建了一个优化器,通过集群资源实时监控、集群区域划分和任务重新分配去优化Flink系统中的调度策略,以避免负载不均的情况。
RFTS算法的总体框架如图1所示,其基本思想是先通过实时监控集群的性能情况,得到每个资源节点的负载值和整个集群的负载值,并把这些信息实时存储到MongoDB数据库中,集群的负载越小,则说明整个集群的负载越均衡。因此,当负载均衡值小于阈值时,说明集群处于均衡状态,算法结束;否则,利用区域划分算法划分整个集群,把集群分成过负载、轻负载、近饱和和差饱和4个区域,最后采用基于人工萤火虫优化的任务调度算法结合任务的优先级把过负载区域的任务迁移到差饱和区域中的资源节点上,以降低整个集群的负载值。

Figure 1 General framework of RFTS图1 RFTS算法总体框架
本节进一步优化基于Flink本身的调度算法,针对已经完成初步调度策略的集群进行实时性能监控,当负载不均时根据各节点任务队列中任务的数量和任务的优先级重新产生调度策略。
3.3 资源监控系统
资源监控系统为RFTS算法后期的区域划分和基于人工萤火虫优化的任务调度收集重要的系统实时信息。该系统每隔10 s对每个资源节点统计一次实时资源性能数据。在计算资源中最具代表性的资源性能数据包括CPU核数、 CPU 使用率、内存使用率和总内存大小,这4个指标反映了节点当前的负载能力。因此,本文用这4个指标构成的综合值来代表该资源节点的实时性能,并通过计算得到每个资源节点的负载值,进而得到整个集群的负载值。
资源监控系统的具体流程如算法1所示,当集群负载值大于或等于β时(第1行),对于集群中的每个资源节点TMj,根据监控和管理Java虚拟机(JVM)管理接口的ManagementFactory管理工厂类中的getOperatingSystemMXBean方法去获取资源节点底层的性能指标,计算节点TMj的CPU核数Core_Numj、CPU利用率ω1j和空闲内存量ω2j,根据式(1)和式(2)可以得出该资源节点TMj的性能指标Metricj和负载值Loadj(第2~5行);根据式(4)得出集群的负载值,并把每个节点的负载值和集群负载值放入数据库MongoDB中(第6、7行),直到集群负载值小于阈值β,即集群实现整体的负载均衡。
算法1资源监控系统实现算法
输入:资源节点集合TM、每个资源节点上的任务分配情况TaskNum。
输出:数据库MongoDB。
1.While集群负载值大于或等于阈值βdo
2.For集群中的每一个资源节点do
3. 计算资源节点TMj的CPU核数、CPU利用率和当前机器的空闲内存量;
4. 更新资源节点TMj的性能指标和负载值;
5.Endfor
6. 更新集群的整体负载值;
7. 把每个节点的负载值和集群负载值存入数据库MongoDB中;
8. 输出数据库MongoDB;
9.Endwhile
下面通过一个实例来描述资源监控系统的执行过程,如图2所示。对于整个集群而言,每隔10 s统计一次每个资源节点的CPU核数、CPU利用率、内存利用率和总内存大小,根据式(1)计算出每个节点的性能指标Metricj,根据每个节点上当前任务队列中的任务数量和实时性能指标计算每个节点的负载值Loadj和集群负载值C_Load,并把这些信息实时存入MongoDB数据库中,重复上述过程直到集群负载值C_Load小于β。
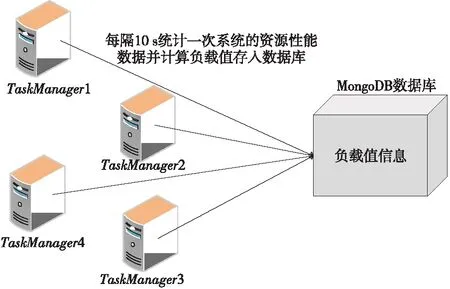
Figure 2 Execution of the resource monitoring system图2 资源监控系统执行过程

Figure 3 Execution of regional division图3 区域划分执行过程
3.4 区域划分算法
本文将整个集群划分为过负载、轻负载、近饱和和差饱和4个区域,依次记为UPGroup、LPGroup、NSGroup和DSGroup。
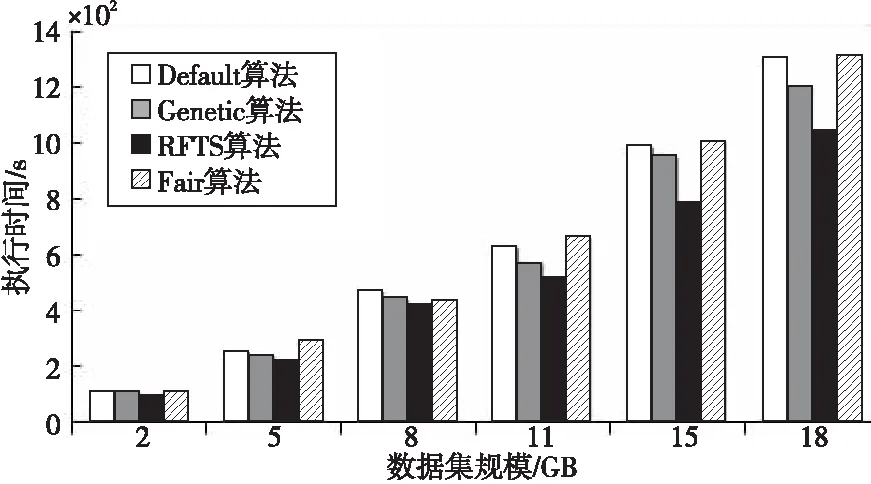
通过定义如式(5)所示的偏移量offset来划分集群区域。h_threshold为启发式集群高域值,且h_threshold≥0;l_threshold为低阈值,且l_threshold≤0。如果offsetj≥h_threshold,则节点TMj属于过负载区域UPGroup;如果0≤offsetj offsetj=δj-β,j=1,2,…,m (5) 其中资源节点TMj负载偏差值δj如式(6)所示: (6) 区域划分算法的伪代码如算法2所示。当满足过负载区域UPGroup不为空且差饱和区域DSGroup不为空,或者集群负载值C_Load<β这2个条件中的一条时(第1行)开始区域划分算法,每隔10 s从MongoDB数据库中提取当前资源中每个节点的负载值loadj,计算得出当前整个集群的平均负载,根据式(5)计算得到每个资源节点的当前偏移量offsetj(第3、4行),并结合启发式集群高低阈值h_threshold和l_threshold计算出该节点的负载承受能力,根据该节点负载承受能力的高低把该节点分配到对应所属区域(第5~16行)。如果区域划分算法结束时C_Load小于β,则算法结束,否则,进入到基于人工萤火虫优化的任务调度算法重新分配任务调度集合。 算法2区域划分算法 输入:数据库MongoDB。 输出:过负载区域UPGroup、轻负载区域LPGroup、近饱和区域NSGroup和差饱和区域DSGroup。 1.While(UPGroup≠∅∧DSGroup≠∅)∨(C_Load<β)do 2.ForMongoDB数据库中的每一个资源节点 3. 计算每个资源节点TMj的负载偏差值δj; 4. 计算每个资源节点TMj的偏移量offsetj; 5.Casewhenoffsetj≥h_thresholdthen 6. 把资源节点TMj放入过负载区域UPGroup; 7.When0≤offsetj 8. 把资源节点TMj放入轻负载区域LPGroup; 9.Whenoffsetj 10. 把资源节点TMj放入差饱和区域DSGroup; 11.Whenl_threshold≤offsetj<0then 12. 把资源节点TMj放入近饱和区域NSGroup; 13.EndWhile 14.输出划分好的过负载区域UPGroup、轻负载区域LPGroup、近饱和区域NSGroup和差饱和区域DSGroup. 下面通过一个实例来描述区域划分算法的具体执行过程,如图3所示。假定当前集群由6个TaskManager组成,根据3.3节提出的资源监控系统,每个TaskManager的实时负载值都存储在MongoDB数据库中,每隔10 s从该数据库中重新提取当前资源中每个节点的负载值Loadj和集群的负载值C_Load,并计算得到每个节点相对于集群负载平均值的偏移量。该实例中,TaskManager1~TaskManager6的偏移量分别是0.91,-0.09,-0.12,-0.58,-0.31和0.87,集群的高阈值为0.83,低阈值为-0.27,根据区域划分算法,分配结果如图3的右图所示,TaskManager1和TaskManager6被分配到UPGroup,TaskManager2和TaskManager3被分配到NSGroup,TaskManager4和TaskManager5被分配到DSGroup。 人工萤火虫优化GSO算法是2005年由印度学者Krishnanand和Ghose提出的一种新型的全局智能优化算法。该算法定义了萤火虫的解空间,每个萤火虫都有决策域,即自己的视线范围。每只萤火虫的亮度与其所在位置的目标函数值有关,萤火虫位置的目标函数值越高,其亮度越大;相反,则亮度越小。根据萤火虫的自然生活规律,它将在决策域中找到下一次运动方向。在决策域中,区域越亮,对萤火虫的吸引力越强。萤火虫的飞行方向会根据邻域改变。另外,决策域的大小受邻域中个体数目的影响,当邻域密度减小时,萤火虫决策域半径增大,为了发现更多的邻居,邻域密度越大,其决策域半径越小。最终,大部分萤火虫会在一个区域内凝结,即达到极值点。 本节提出的基于人工萤火虫优化的任务调度算法的原理是,基于3.4节的区域划分算法把过负载区域UPGroup中的节点TMj上的任务Ti按照基于人工萤火虫优化的任务调度策略调度到差饱和区域DSGroup中的节点TMp上,UPGroup中的节点按照负载值的大小降序排序,依次调度到DSGroup中,直到集群负载值C_Load小于阈值β。在该算法中任务Ti被定义为萤火虫,DSGroup区域中的节点TMp被定义为萤火虫的目标区域,任务的目标函数由UPGroup中节点TMj的任务数量、节点TMj中的任务Ti的优先级、目标节点TMp的负载值和目标节点TMp上高优先级任务的数量共同决定。下面先对本文提出的基于人工萤火虫优化的任务调度算法进行基本定义与概念说明: 令N={n1,n2,…,nn}为萤火虫集合,初始化每个萤火虫的荧光素为l0,决策域为r0。萤火虫ni在时刻t的荧光素值如式(7)所示: li(t)=(1-ρ)li(t-1)+γf(xi(t)), i=1,2,…,n (7) 其中,ρ代表萤火虫中荧光素的消失率,γ代表荧光素的更新率,f(xi(t))表示萤火虫ni在时刻t时位置xi(t)的目标函数值。 萤火虫ni在t时刻的邻居集合Gi(t)如式(8)所示: li(t) (8) 萤火虫ni的速度方向v的定义如式(9)所示。 v=max(pi),pi={pi1,pi2,…,piGi(t)} (9) 其中, (10) 为萤火虫ni向萤火虫nj方向的转移概率。 萤火虫ni在时刻t时的位置定义如式(11)所示: (11) 其中,s为萤火虫的步长。 φ(gt-1-|Gi(t-1)|)}} (12) 其中,rs表示萤火虫的感知域范围,φ表示决策域的更新率,gt-1表示萤火虫在t-1时刻的邻域阈值,Gi(t-1)表示萤火虫ni在t-1时刻的邻域。 基于人工萤火虫算法的任务调度算法的流程如算法3所示,首先把UPGroup中的任务按照负载值高低进行排序,把UPGroup中的任务设定为萤火虫,DSGroup区域设定为发光区域,在发光区域中寻找最优解并把任务调度到最优的资源节点上。 算法3基于人工萤火虫优化的任务调度算法 输入:萤火虫集合N={n1,n2,…,nn}、迭代次数M、过负载区域UPGroup、轻负载区域LPGroup、近饱和区域NSGroup、差饱和区域DSGroup。 输出:把UPGroup区域的任务调度给DSGroup中的节点DataNode。 1. 初始化算法中需要用到的参数; 2.ForniinN 3. 初始化荧光素、初始位置和初始决策域; 4.While当UPGroup区域和DSGroup区域都不空时,才有任务可以调度的空间do Figure 4 Execution process of task scheduling algorithm based on GSO algorithm图4 基于人工萤火虫算法的任务调度算法执行过程 5.ForniinN 7.For邻域集合中的萤火虫nj 8. 根据式(10)更新萤火虫ni向萤火虫nj方向的转移概率; 9.If萤火虫ni向萤火虫nj方向的转移概率大于此时最大值maxthen 10. 更新最大值为此时的转移概率; 11.Endif 12.Endfor 13. 选出最大值作为萤火虫ni的移动速度方向v; 14. 使萤火虫ni向下一次迭代速度方向v移动并更新萤火虫移动后的位置点; 15.Endfor 16. 更新萤火虫在t+1时刻的决策域范围并求出全局最优点pbest; 17.For过负载区域UPGroup中的任务Tj 18. 把任务Tj调度到差饱和区域DSGroup中选出的最优节点pbest; 19.Endfor 20.Endwhile 21.Endfor 22. 输出更新过后的过负载区域UPGroup、轻负载区域LPGroup、近饱和区域NSGroup和差饱和区域DSGroup集合. 下面通过一个实例来描述基于人工萤火虫优化的任务调度算法的具体执行过程,如图4所示。 图4a为原本的区域分配情况以及任务和资源节点的对应调度情况,当UPGroup和DSGroup都不为空时,把过负载区域UPGroup中的资源节点根据负载值由高到低进行排序,并把该资源节点中的任务按照优先级由高到低进行排序,对于UPGroup中的节点对应的分配任务模拟为萤火虫,DSGroup定义为萤火虫的区域移动范围。 在本次实例中UPGroup中资源节点为TaskManager1和TaskManager6,它们的偏移量分别是0.91和0.87,TaskManager1中的任务Task1、Task2、Task3的优先级分别是低、低和高,TaskManager1中的任务Task3的优先级分高;对于DSGroup中的TaskManager4和TaskManager5的偏移量分别是-0.58和-0.31;NSGroup中资源节点为TaskManager2和TaskManager3,LPGroup区域为空。因为UPGroup中任务重新调度的顺序为先按照资源节点中偏移量由高到低排序,对于同一资源节点中的任务再按照任务的优先级由高到低排序,因此UPGroup中第一个被调度的任务为TaskManager1中的Task3,由于DSGroup中TaskManager4的偏移量低于TaskManager5的偏移量,因此TaskManager1中的Task3任务被调度到TaskManager4中。 此时系统实时性能发生改变,从MongoDB数据库中获取实时的资源节点负载值信息,并根据节点当前的任务队列数量进行重新分区。此时集群任务分配情况如图4b所示,TaskManager1偏移量更新为0.64,处于LPGroup区域,下一个被调度的任务为UPGroup中的TaskManager6的Task10,此时DSGroup中的TaskManager4和TaskManager5的偏移量分别是-0.37和-0.28,因此Task10被调度到TaskManager4中,并且资源节点的性能发生变化;此时集群重新划分后如图4c所示,TaskManager4被划分到LPGroup,TaskManager6被划分到DSGroup区域,此时UPGroup为空,即最终的任务调度分配方案。 本文通过修改Flink 1.8.0的源码,实现了基于资源反馈的负载均衡任务调度算法RFTS。本节设计并实施了一系列实验,基于TPC-C和TPC-H数据集,从执行时间和吞吐量2个方面对Flink默认的调度算法、公平调度算法、遗传算法和本文提出的RFTS算法进行对比实验,测试了本文提出的面向Flink系统的任务调度优化算法的实用性。 实验所用环境为4个节点组成的分布式集群,包括1个主节点(Master)和3个从节点(Slave),每台服务器的配置信息如表1所示。 Table 1 Hardware configuration表1 硬件配置 搭建成由4台服务器组成的Flink集群,其中的1台Master为Flink集群中的JobManager节点,3台Slave节点为Flink中的TaskManager节点,节点间通过千兆以太网连接,节点间的运行方式为Standalone模式。Flink集群的软件及其版本如表2所示。 Table 2 Software configuration表2 软件配置 本文实验使用TPC-C和TPC-H数据集分别生成6个不同大小的数据集,测试程序将在这12个数据集上进行测试。数据集的来源和规模如表3所示。 Table 3 Dataset size表3 数据集规模 下面分别介绍这2个数据集的数据特征: TPC-C是联机交易处理系统OLTP(On-Line Transaction Processing)的规范,TPC-C测试中使用的模型是一家大型商品批发销售公司,在不同地区中设有多个仓库,随着业务的增长,公司需要添加新的仓库,每个仓库有10个销售点,每个销售点为3 000个客户提供服务,每个销售订单对应10种产品,大约有1%的产品显示缺货时,需要从其他区域的仓库中调运。整个TPC-C数据集由9张表组成,包括客户表、区域、订单表等等,产生的交易事务主要有5种,分别是新订单、支付操作、发货、订单状态查询和库存状态查询,该数据集可以通过命令指定生成数据集的大小。 TPC-H是商品零售业决策支持系统的测试基准,测试系统中复杂查询的执行时间。它包含8个基本表,数据量可以设置为1 GB~3 TB不等,其基准测试包含22个查询,查询语句严格遵守SQL-92语法,并且不允许修改,主要指标为每个请求的响应时间,即提交任务后返回结果所花费的总时间。TPC-H中数据量的大小对查询速度的影响很大,使用SF描述数据量,1SF对应1 GB单位,并且人工设定的数据量只是8个表中的总数据量并不包含索引和临时表等空间占用情况,因此设定数据时需要预留更多的空间。对于同样规模大小的数据集,TPC-H产生的数据类型比TPC-C产生的数据类型更多样,关系更复杂。 本文分别在TPC-C和TPC-H不同规模的数据集上测试RFTS算法的处理时间,结果如表4所示,TPC-C代表简单场景下的测试,TPC-H代表复杂场景下的测试。随着数据集规模的增大,算法处理时间占任务整体执行时间的比例也增大了,这是因为处理任务的数据规模越大,出现负载不均的情况越多,需要迁移的任务急剧增多,因此调度算法所占整体执行时间的本身的比例也就越大。从表4可以看出,无论对于简单数据还是复杂数据而言,调度算法所占整体执行时间的比例都小于1%。 其中,Dataset7~Dataset12对应的数据是基于TPC-H数据集的测试结果,Dataset1~Dataset6对应的数据是基于TPC-C数据集的测试结果。通过对比Dataset1&Dataset7,Dataset2&Dataset8,Dataset3&Dataset9,Dataset4&Dataset10,Dataset5&Dataset11,Dataset6&Dataset12,可以发现基于TPC-H数据集的实验中任务整体执行时间和调度算法本身占用的时间都比基于TPC-C的要大,但是算法处理时间占任务整体执行时间的比例反而更小了。这是因为对于复杂数据场景,负载不均的情况更常见,RFTS算法的调度算法本身增加的时间对于优化的系统执行效率来说影响更小,即优化的效果更好。实验结果表明,无论是TPC-C对应的简单环境还是TPC-H对应的复杂场景,算法本身处理时间占任务整体执行时间的比例都很小。 Table 4 Proportion of processing time of the RFTS algorithm表4 RFTS算法的处理时间占比 执行时间是指从任务提交到完成所需要的总时间。执行时间越少,代表系统处理任务的计算能力越强。本节对RFTS算法、公平调度算法(Fair)、遗传算法(Genetic)和Flink默认的轮询调度算法(Default)在任务整体执行时间上进行对比实验,分别基于TPC-C和TPC-H的6个数据集进行测试,作业并行度都设置为12,测试用例为WordCount。图5和图6分别为基于TPC-C和TPC-H数据集的执行时间对比图。 Figure 5 Comparison of execution time based on TPC-C dataset图5 基于TPC-C数据集的执行时间对比 Figure 6 Comparison of execution time based on TPC-H dataset图6 基于TPC-H数据集的执行时间对比 从图5和图6可以看出,采用Fair调度算法与默认的轮询调度算法的执行效率相差不大;采用遗传算法Genetic的执行效率要优于采用Fair调度和默认的轮询调度算法的,优化效果约为3.1%,在数据集为11 GB时优化效果最好;而采用本文提出的RFTS算法比采用Flink默认的轮询调度算法、Fair调度算法和Genetic算法的执行时间都要短,且随着数据集规模的增大,执行时间的优化效果越好,且在数据集规模大小相同的情况下,图6对应的基于TPC-H数据集的执行时间优化效果优于图5对应的基于TPC-C数据集的执行时间优化效果。原因同上,这说明RFTS算法对于复杂的、大规模场景执行时间优化效果更好。但是,无论是在TPC-C对应的简单场景还是在TPC-H对应的复杂场景下,采用RFTS算法后的整体任务执行时间都要少于采用Flink默认的轮询任务调度算法的。在多种数据集的测试下最终求出采用RFTS算法时整体任务执行时间的平均优化效率为6.3%。 吞吐量(throughput)是指系统单位时间内能够处理的数据量大小,代表了系统的负载能力。图7为RFTS算法、公平调度算法(Fair)、遗传算法(Genetic)和 Flink默认的调度算法(Default)在不同并行度下的吞吐量对比分析图。分析图7可知,采用Fair算法时的吞吐量比采用Flink默认的轮询算法的低;采用Genetic算法时的吞吐量优于采用Flink默认的轮询算法和Fair算法的,在多种数据集测试下最终求出的采用Genetic算法的吞吐量平均优化效率为3.9%;而采用RFTS算法相比采用Flink默认的轮询算法、Fair算法和Genetic算法的吞吐量更大,并且随着并行度的增大,增加了同一时间内处理任务的机器数量,系统承受负载的能力增大,即系统单位时间内可以处理更多的数据。相比而言,使用RFTS算法吞吐量优化效果更好,这是因为使用RFTS算法会实时监控系统性能,并根据每个资源节点的负载承受能力,去调整任务队列中的任务数量,时刻保证集群负载均衡,大大提升了资源利用率以及单位时间内可以处理的数据量。在多种数据集测试下最终求出的采用RFTS算法的吞吐量平均优化效率为11.7%。 Figure 7 Comparison of throughput at different degrees of parallelism图7 不同并行度下吞吐量对比 Flink作为现在主流的大数据计算引擎,在实时数据处理和离线数据处理上都表现出了良好的效果,然而Flink计算引擎中的任务调度还有许多待优化的空间,因此本文提出了基于资源反馈的负载均衡任务调度算法RFTS。实验结果表明,本文提出的RFTS算法能够有效减少Flink计算引擎中任务的整体执行时间,增加吞吐量。 未来希望本文提出的RFTS算法可以应用于其它的大数据计算引擎中,并取得性能提升。3.5 基于人工萤火虫优化的任务调度算法

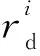

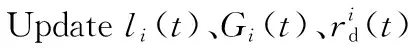

4 实验与分析
4.1 实验环境配置


4.2 数据集

4.3 算法本身处理时间

4.4 执行时间对比分析

4.5 吞吐量对比分析

5 结束语
