基于SGC-LDA模型的财经文本主题研究
2022-08-09覃桂双
傅 魁,鲁 冬,覃桂双
武汉理工大学 经济学院,武汉 430070
财经数据挖掘被广泛应用于各种经济领域,如股票价格预测[1]、经济不确定性度量[2]以及经济周期预测[3]等。当前财经领域模型研究主要是定量的模型,针对结构化数据进行研究[4],而对于非结构化的财经文本类数据关注较少。同时,当今互联网上的财经文本数据呈现出信息量庞大、增长速度迅猛、非结构性、主题模糊、高度动态性、覆盖范围广等特征,造成了“信息丰富而知识匮乏”等问题,而传统数据挖掘技术难以应用其中,导致无法从财经文本中高效而准确地获取有价值的财经信息。因此如何实现对财经文本中隐含的主题进行准确的建模,成为一个亟待解决的问题。
当前,主题建模技术被广泛应用于股票趋势分析[5]、财经政策主题提取[6]、行业分类[7]、短视频的喜好率预测[8]、投资者情绪识别[9]等领域。准确进行财经主题建模,并保证模型的时效性,是对财经统计数据的一种有效补充,对于促进经济领域中的评估经济状况、预测市场波动和趋势、抑制通货膨胀、为投资者和决策者提供有价值的参考、改善投资策略等都至关重要同时大有裨益。
LDA模型是应用最常见的主题模型,诸多学者由基本LDA模型出发,致力于构建可以满足不同应用场景需求的LDA扩展模型。其中,Blei等人[10]提出CTM(correlated topic model)模型,该模型将分布替换为逻辑正态分布,通过计算协方差矩阵来度量不同主题之间的关联度。Rosen-Zvi等人[11]提出并构建作者-主题模型(author-topic model,ATM),通过引入作者要素,研究文本主题与文本作者以及不同文本主题之间的关系。Li等人[12]引入有向无环图以全面表征所有主题之间的关联性,建立PAM(pachinko allocation model)模型。王振飞等人[13]提出MTLDA(microblog topic latent dirichlet allocation)方法,通过时间片划分完成了微博话题的生成,证实话题演化结果与实际情况吻合。Wang等人[14]通过对文本主题的演化进行建模,有效识别了动态主题,其方法称为TM-LDA模型。
虽然传统的LDA模型在主题发现方面优势明显,但其难以有效解决建模文本的稀疏性和噪声性的问题,并且采用滑动时间窗口技术对主题进行动态性建模容易造成主题间断。因此本文考虑引入一种通用财经主题以过滤文本噪声,采用滑动时间窗口技术,同时加入遗传因子保持不同主题间的连续性,提出并构建SGCLDA模型的财经文本主题模型。本文提出的方法有以下几点优势:
(1)基于滑动窗口技术,引入财经主题遗传因子和通用财经主题,提出改进的SGC-LDA财经文本主题模型,弥补了传统主题模型在研究财经主题领域的不足,提升对于财经文本主题研究的精度。
(2)基于通用财经主题的文本噪声过滤建模,有效降低了财经文本数据中噪声数据带来的负面影响。
(3)引入财经主题遗传因子以解决采用滑动时间窗口技术对主题进行动态性建模容易造成主题间断的问题。
(4)运用财经文本对于本文所提出的SGC-LDA模型进行实证分析,验证了模型在财经文本挖掘领域的优越性。
1 LDA主题模型
主题模型是一种文本内容的概率生成模型,能找到生成文本的最佳主题和词项,最大程度表示文本所蕴含的含义,有效解决文本、潜在主题和词项之间的语义关联问题[15],因此常被用于文本主题建模。主题模型包括如潜在语义分析(LSA)[16]、概率潜在语义分析(PLSA)[17]和潜在狄利克雷分布(LDA)[18]等,其中运用最为广泛的是LDA模型。
LDA模型是一个包含文本、主题和词语三个层次的贝叶斯模型,通过非监督学习的方式对大规模文本集中的潜在主题信息进行识别。其基本原理是模拟了一篇文本的生成过程,即根据一篇文章的主题循环抽取主题对应的词语从而生成一篇文本,基于LDA模型的文本具体生成过程如下所示:
(1)给定文本d,选择d的长度N即d包含的词项总数,N~Poisson(ξ)。
(2)选择θ,使θ~Dirichlet(α)。
(3)选择N个词项中的每个词项:
①选定主题Zn,使Z n~Mutinotional(θ)。
②根据p(w|Z n,β)的计算结果选择词项w n,其中,矩阵βKV中βij=p(W j=1|Z i=1)。
对应的图模型如图1所示。
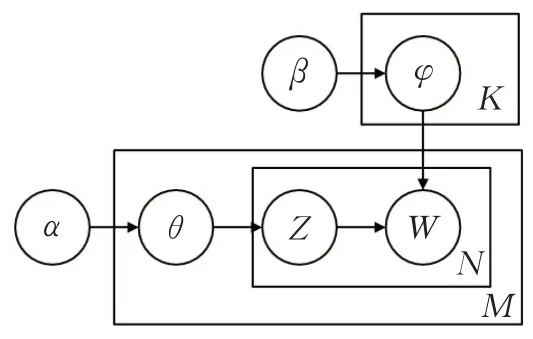
图1 LDA模型图Fig.1 LDA model diagram
2 财经主题建模
2.1 财经主题建模框架
为解决主题模型存在的问题,本文在LDA模型的基础上,考虑时间因素,基于滑动窗口技术(sliding-window technique),引入财经主题遗传因子(genetic factor of financial topic)和通用财经主题(common financial topic),提出一种SGC-LDA(sliding-window,genetic factor and common financial topic LDA)模型,从而解决传统LDA模型在财经文本建模中存在的噪声问题和主题间断问题,更好地反映财经文本的关键主题。
本文财经主题建模框架如图2所示,包括核心步骤文本噪声过滤、时间片划分、引入遗传因子和SGC-LDA财经主题建模四部分。具体来说:
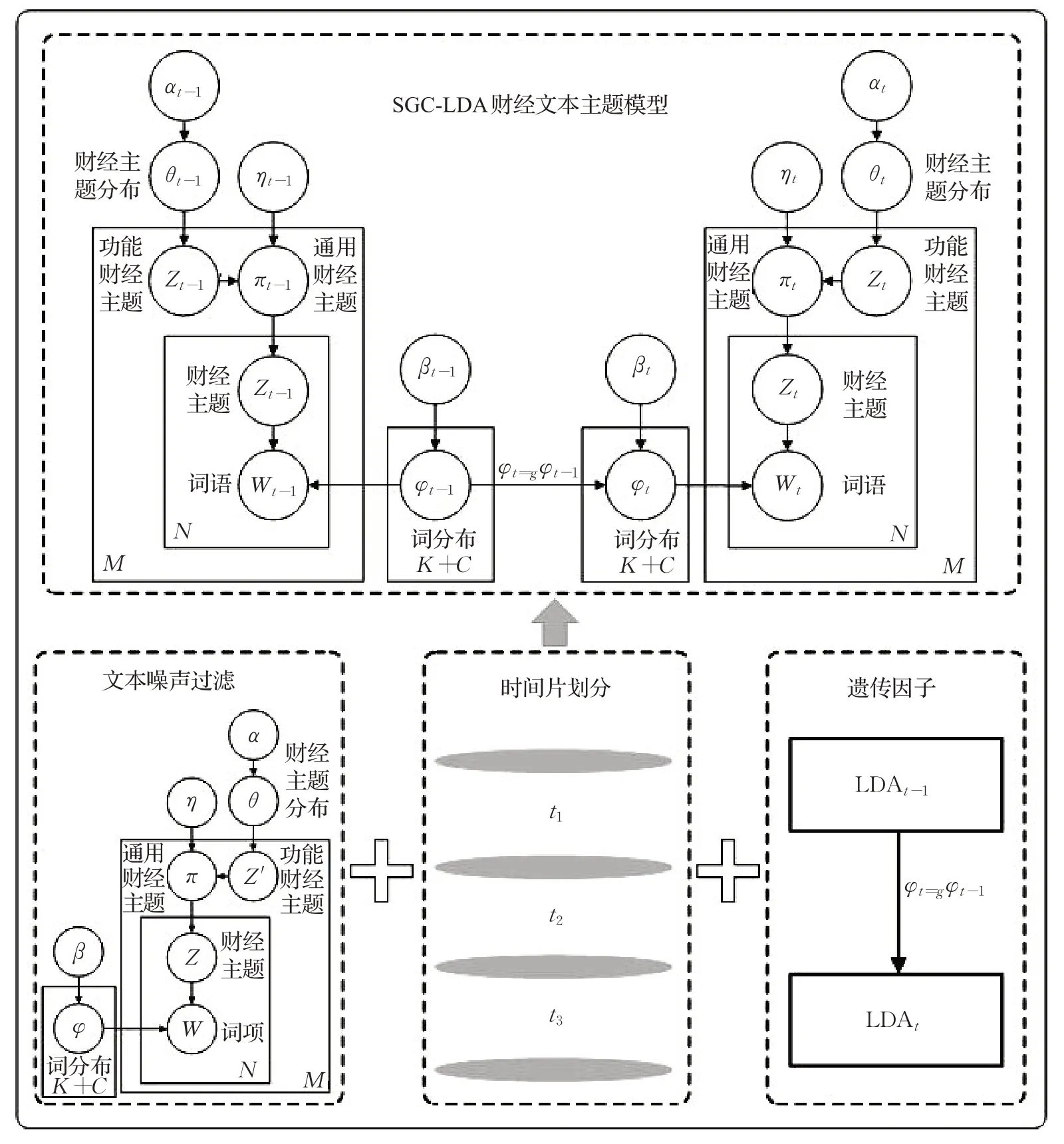
图2 基于SGC-LDA模型的财经文本主题建模框架Fig.2 Financial text topic modeling framework based on SGC-LDA model
(1)基于通用财经主题的文本噪声过滤。为减少噪声数据的影响,本文引入通用财经主题,以捕获通用语义和噪声干扰词,定义描述特定财经主题的常规主题为功能财经主题,假定每个财经文本都是功能财经主题和通用财经主题的混合,本文结合通用财经主题和功能财经主题实现文本噪声过滤。
(2)对财经文本进行时间片划分。为避免文本数量稀少时间片的跨度太大的问题,本文结合等时间切分和等文本数量划分两种方法,先对文本采用等时间片切分,当该切分的时间片下文本数量达不到既定的阈值时,自动合并下一个时间片的文本作为当前窗口的文本。
(3)引入财经主题遗传因子。本文通过引入财经主题遗传因子,将前一时间片此项分布后验概率乘以财经主题遗传因子作为后一时间片此项分布的先验概率,来保持财经主题的连贯性。
(4)SGC-LDA财经文本主题建模。结合上述三点,本文提出并构建SGC-LDA模型,并将其用于财经主题建模。
2.2 基于SGC-LDA模型的财经文本主题建模
本文财经文本主题模型可以用时间片、财经主题、词项和概率四个元组表示为:

其中,Zi1={(w1,p(w1|z1)),(w2,p(w2|z2)),…,(w n,p(w n|z n))}(Zi2,Zi3,…,Z in表达式同理),z为财经主题模型隐含主题,w为特征词表中的词项,p为对应财经主题中相应词项的概率;T为每个时间窗口对应的时间片。
2.2.1 基于通用财经主题的文本噪声过滤
财经类文本主要由财经主题和非财经噪声数据构成,为了解决噪声问题,本文基于混合一元模型[19]思想,引入通用财经主题,以收集噪声词,通过将噪声词的生成过程添加到模型结构中来解决噪声问题。具体而言,定义通用财经主题,以捕获通用语义和噪声干扰词,而描述特定财经主题的常规主题称为功能财经主题,假定每个财经文本都是功能财经主题和通用财经主题的混合。
混合一元模型假设每个文本仅涉及一个主题,这种假设可以间接丰富文本级别的主题的词项标记样本,从而为稀疏的文本进行有效建模。基于混合一元模型思想,文本W具体的产生流程主要包括2个步骤:第一步,按照语料库级主题分布θ,选取主题Z w;第二步,基于第一步的条件,独立于主题-词项分布生成N d个词项标记,进一步生成文本W。假设有Z1,Z2,…,Z n,生成文本W的概率表示为式(2):
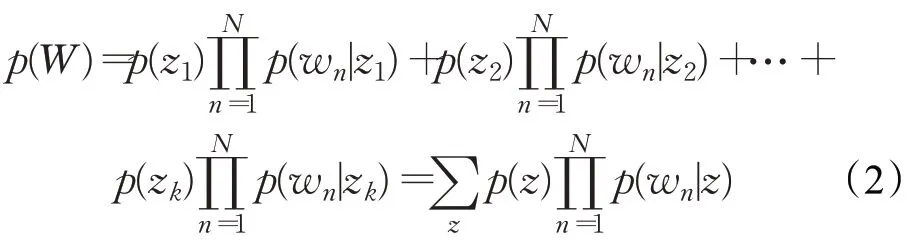
混合一元模型通过为所有词项分配相同的主题来对文本建模,本文基于混合一元模型的思想,提出并构建本文文本噪声过滤模型。首先,由Dirichlet先验α得到功能财经主题上的语料库级多项式分布θ。其次,从Dirichlet先验β得出所有主题的词项多项式分布φ。最后在单词生成过程中,对于每个文本d,从分布θ得出功能财经主题z t,进一步根据Dirichlet先验η在所选功能财经主题和所有通用财经主题上生成多项式分布πd。对N d个标记词项重复以下过程N d次:从分布πd采样主题z dn,然后从分布φz d采样标记词项w dn。图3为本文提出的文本噪声过滤建模图模型,参数说明如表1。
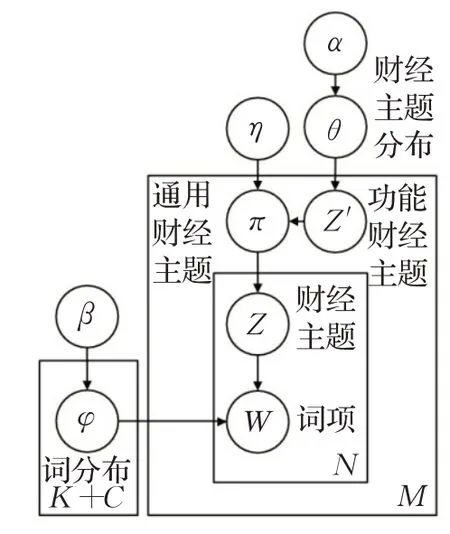
图3 基于通用财经主题的文本噪声过滤建模图模型Fig.3 Text noise filtering modeling graph model based on general financial theme
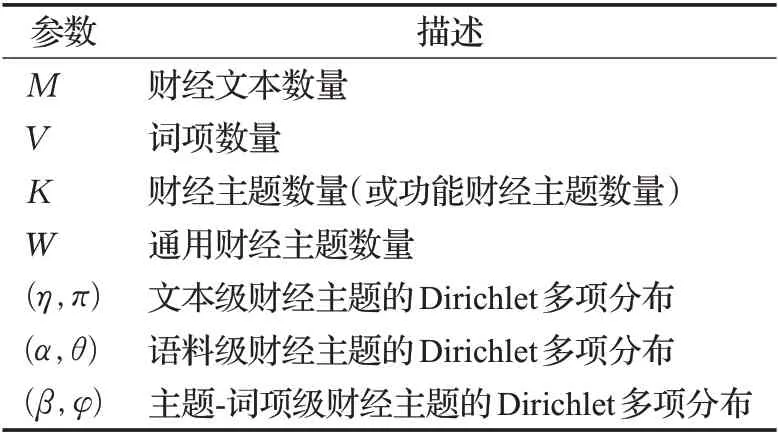
表1 参数说明Table 1 Parameter description
由于共轭Dirichlet多项式的设计可以有效地边缘化多项式分布φ、θ和π。因此,只需要采样两个主题分布z′和z。其中功能财经主题z′t和z t在给定所有其他变量的情况下交替采样,直到收敛。
与混合一元模型及LDA模型的推导过程类似,K个功能财经主题上z′的条件后验概率如式(3)所示:
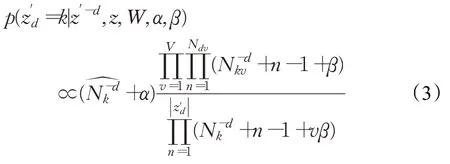
其中,表示分配给功能财经主题k的文本数量;N v和N kv分别表示词项类型v的数量和分配给财经主题k的单词总数;N dv表示财经文本d中出现的单词类型v的数量;是在财经文本d中分配给所选功能财经主题的标记词项的数量;上标“-d”表示除去文本d后的财经文本数量。
此外,z在所选功能财经主题z′和通用财经主题C上的条件后验概率如式(4)所示:
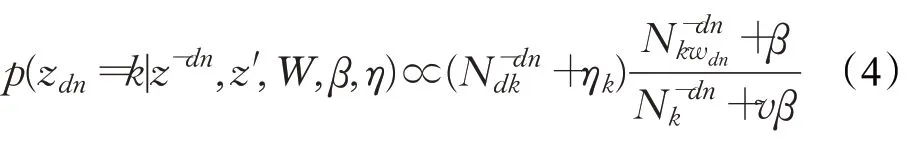
其中,N dk表示在文本d中分配给财经主题k的标记词项的数量;上标“-dn”表示从位置(d,n)除去zdn后的财经文本数量。本文提出的文本噪声过滤模型的Gibbs采样推断算法。
2.2.2 财经主题遗传因子
由于当前时间片内的语料信息中携带了历史信息,即相邻时间片的语料间存在继承关系,本文将这种关系定义为“财经主题遗传”。本文在传统的时间窗口法的基础上,根据“财经主题遗传”的思想,在财经主题建模过程中基于以下方法来维持财经主题的遗传性:将时间片t-1的词项分布后验概率乘以财经主题遗传因子g的结果作为时间片t的词项分布先验概率。
由于时间片t内的语料信息中包含有时间片t至时间片t-1的信息,因此计算时间片t+1的主题分布时仅考虑时间片t的计算结果即可。一般而言,g不同取值会对实验结果产生不同的影响,过小的g值将导致前后财经文本的主题无法对齐,过大的g值则容易造成非相关财经主题因为共词的出现被强制对齐的问题。为了便于模型的高效实现,本文根据简化遗传度处理方式,财经主题遗传因子g的计算如式(5)所示:

其中,Token t-1表示t-1时间片内的词项数目,λ为自定义参数。结合权重λ值及相邻时间片的词项数目进行变换,类似于对文本语料进行平滑处理,有助于解决对文本语料进行切分导致财经主题连续性被破坏的问题。
2.2.3 SGC-LDA财经文本主题建模
基于SGC-LDA模型的财经文本主题建模具体做法是,首先采用等时间片对财经文本进行切分,当该切分的时间片下文本数量达不到既定的阈值时,自动合并下一个时间片的文本作为当前窗口的文本;然后,将前一时间片t-1输出的财经主题-词项分布的后验概率φt-1乘以遗传因子g得到的φt=gφt-1,其结果作为当前时间片t内财经主题-词项分布的先验概率;同时,定义通用财经主题πt,通过在每个时间片中将噪声词的生成过程添加到模型结构中来解决噪声问题;最后构建财经主题模型,SGC-LDA财经文本主题具体建模过程如下所示:
首先将财经文本按照设定好的时间段划分为t个时间片文本集,每一个时间片文本集内对应一个φt和θt。
(1)抽取时间段t。
(2)如果是第一个时间片t=1,则θt=Dirichlet(αt)。
(3)否则,计算计算φt=gφt-1。
(4)对于给定文本d,采样一个功能财经主题分布θt=Dirichlet(αt),抽取财经主题概率分布θt:p(θt|αt)。
①对于文本d中的每个词项,选择一个财经主题z t:p(z t|θt),生成每一个词项w t:p(w t|z t,βt)。
②对于文本d:
采样一个功能财经主题z′t~Multinimial(φtn)。
采样一个z′t及所有通用财经主题的混合分布πt~Dirichlet(ηt)。
对于Nt个词中的每个词Wtn,采样一个财经主题Ztn~Multinimial(πt),采样一个词项Wtn~Multinimial(φtn)。
对应的图模型如图4所示。
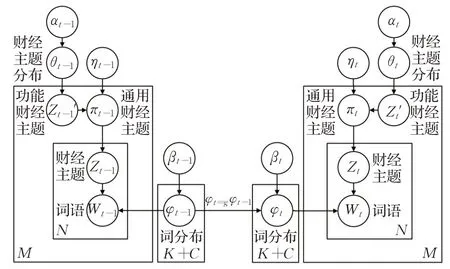
图4 SGC-LDA财经文本主题建模图模型Fig.4 SGC-LDA financial text topic modeling graph model
为了更好地描述财经文本的主题,本文基于文本对于财经主题的贡献度选出代表性文本,对于指定财经主题内容的覆盖度即贡献度较高的文本将被选为该财经主题的主题文本,从而对不同财经主题进行扩充。主题文本的选择按照文本中包含指定财经主题的关键字比例来进行,计算方法如式(6)所示:
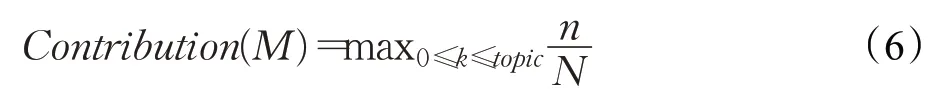
其中,topic是财经主题总数,n代表文本M的中包含主题t k的关键词个数,N代表文本M的词项总数量,如果文本中N>5,则该文本为候选主题文本。按照内容覆盖度对计算结果进行排序,为所有的财经主题选择主题文本。
3 实验及结果分析
综合Alexa排名[20]、百度权重、PageRank值(PR值)[21]等评估标准,本文选取新浪财经、凤凰财经和中国经济网这三个财经新闻网站平台,为本文实验提供财经文本数据。本文通过网络爬虫技术,从上述平台的财经新闻模块爬取了自2019年1月1日至2019年12月31日共一年的财经文本,总计10 950篇。
3.1 对比基准模型及模型评价指标
(1)对比基准模型
为了验证本文提出的SGC-LDA模型的泛化能力、模型在保持财经主题的连续性等方面的优势,本文选取传统LDA模型作为本文的对照模型。
(2)模型评价指标
衡量模型的困惑度(Perplexity)是当前用于衡量主题模型泛化能力的常用方法,通过对比新模型与基准(Baseline)模型的困惑度,验证新模型对于未观测数据具备更好预测能力。困惑度的计算表示为式(7):
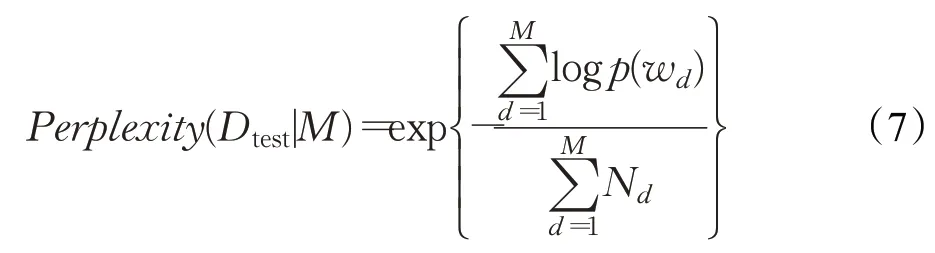
其中,M代表测试文本集中文本的数量,N d代表文本d中词语的数量,w d代表文本d中的词语,p(w d)代表文本中词语w d出现的概率。
3.2 财经文本主题建模过程与结果分析
3.2.1 模型参数设定
(1)根据经验的参数取值
(2)文本语料的时间段划分方法
为了研究不同的时间段划分方法对模型性能产生的影响,本文分别选取了以2个月、3个月、4个月为一个时间片的不同划分方法,然后均取第一个时间片,对比不同主题数取值下的模型困惑度值结果。从图5可知,三种方式下的困惑度均随着主题个数的增加而降低,其中按照2个月为一个时间片的划分方式进行建模,其困惑度始终低于其他两种,说明在该划分方式下本文模型性能最优。所以本文将实验的财经文本以每2个月划分为一个时间片的方式进行财经主题建模。

图5 不同时间段划分方式下的模型困惑度对比Fig.5 Comparison of model confusion degree under different time period division methods
(3)SGC-LDA模型在不同时间片内的最佳主题数量
对于同一主题模型,主题数量K的不同取值会对建模效果产生不同的影响。为了获得最佳建模效果,一般通过计算主题模型的困惑度来确定K的取值,主题模型对新样本的分类效果和泛化能力同困惑度大小成负相关关系。当预测数据的不确定程度较高时,困惑度折线图中曲线的拐点处对应最优主题数取值点。实验过程中选取不同的K值,观察本文模型(时间片均为2个月)与传统LDA模型的困惑度变化情况,结果如图6所示。

图6 LDA与SGC-LDA模型的困惑度对比Fig.6 Comparison of confusion degree between LDA and SGC-LDA models
从图6中可以看出每个时间片中的主题模型以及传统LDA模型下的困惑度指标虽然都随着主题数的增加而降低,但是具体取值有所区别,其中以传统LDA模型的困惑度最高,说明LDA模型性能表现最差。另外,各个模型的最佳主题取值也有所区别,分析得出,t1~t6时间片内的财经主题模型、LDA模型分别取6、6、6、5、5、6、6的时候,模型的性能相对较好,主题抽取结果较为理想。
3.2.2 财经文本主题分析
针对所有实验语料进行建模,得到财经主题的词语分布情况。对不同时间片内的语料利用SGC-LDA模型、对所有语料利用LDA模型分别进行财经主题建模,部分建模结果对比如表2所示。
为了更直观地表示财经主题模型的标签和权重,本研究采用词项概率分布进一步生成财经主题模型的词云图,可视化SGC-LDA模型建模结果生成的词云图如图7所示。

图7 SGC-LDA财经主题模型的词云图表示Fig 7 Word cloud diagram representation of SGC-LDA financial topic model
从表2可以看出传统LDA模型输出结果存在较多的噪声数据,而本文提出的SGC-LDA模型在输出结果主题词几乎不含噪声词,且从表2中t2到t3时间片和图7中t1到t6时间段所展示的主题词的变化,能够反映出的财经主题的连贯性十分明显,体现出财经主题的遗传特性,综上可以分析得出以下结论:
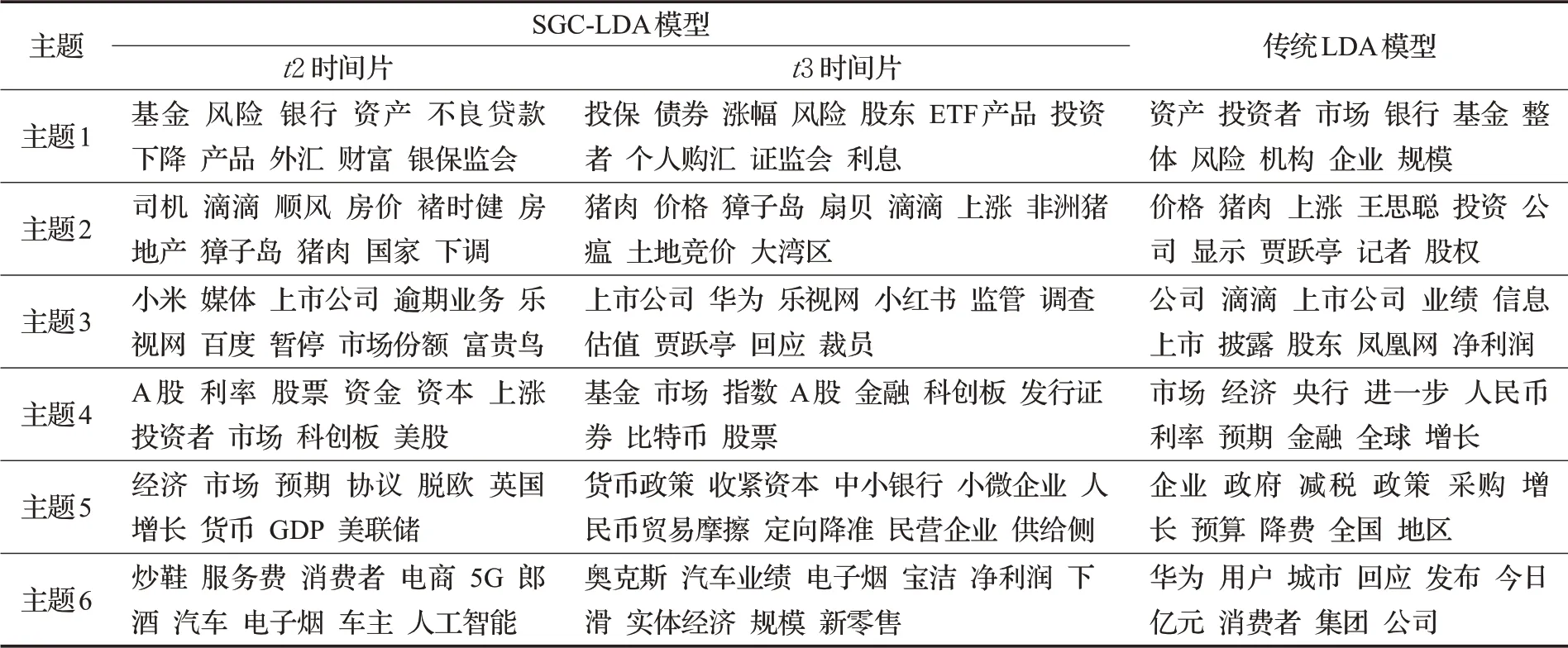
表2 SGC-LDA模型与传统LDA模型的财经主题词项对比(示例)Table 2 Comparison of financial subject terms between SGC-LDA model and traditional LDA model(example)
(1)通用财经主题在财经主题建模去噪能力方面表现出一定的有效性。
财经文本中经常出现“本报讯”“责任编辑”和“本报记者”等词项,通用财经主题能够有效过滤这些背景噪声词。因此,通用财经主题在某种程度上成功地收集了干扰词,有助于SGC-LDA模型发现更多一致的功能财经主题。
(2)SGC-LDA模型在财经文本主题建模方面表现出优越的分类性能和主题连续性。
对表3进行分析发现,t2、t3时间片财经主题模型下,主题1~6分别与投资理财、民生时事、商业动态、金融市场、宏观经济、产业经济有关。由此可见基于SGCLDA模型对财经文本进行主题建模,财经主题分布的输出结果中主题间重叠度低,指定财经主题下的词项能够清晰准确描述该主题,且相邻时间片之间的主题也具有较强的关联性。而传统LDA模型由于建模时间跨度大,包含语料信息过多,因此输出的财经主题包括一些背景噪音词,如“亿元”“记者”和“凤凰网”等,模型分类效果较差。所以,相较于传统LDA模型,本文提出的SGC-LDA模型具备优越的分类性能和主题连续性。
(3)财经文本主题主要由投资理财、民生时事、商业动态、金融市场、宏观经济、产业经济六个主要部分组成。
①财经主题普遍具有明显的投资理财专业领域知识主题特征。财经主题1中包含大量关于“基金”“风险”和“财富”等与投资理财领域知识相关的词项。通过人工观察相对应的新闻文本,发现该类新闻主要来自于平台上的理财模块,该板块文章主要是针对投资理财的专业方法论、理财传奇故事和理财产品等。
②财经主题普遍具有社会热点话题(包括民生时事、商业动态和金融市场)特征。如从时间维度上看,t1~t4时间片(2019年1月—2019年8月)财经主题出现的“猪肉”“非洲猪瘟”“价格上涨”等词项与“2019年非洲猪瘟疫情”相关。
③财经主题普遍具有明显的反映宏观经济政策和产业经济状况能力的特征。如t1时间片的“降息”、t2时间片的“降准”、t3时间片的“定向降准”、t4时间片的“稳中有降”等,有效地反映了我国2019年央行定向降准降息,降低企业融资成本,提高市场流动性,从而促进相关企业和产业发展的举措。
(4)结合财经主题特征词和财经文本对财经主题的扩充,能够更完整准确地描述其财经主题。
为了提高建模结果的可读性,通过本文模型得到财经文本的不同主题的主题词,根据前文进一步选择具有代表性的财经文本对每一主题进行扩充,利用主题词和主题新闻完成所有语料的财经主题描述。以表1中t3时间片财经主题5为例,按照式(9)选出该主题对应的财经文本,综合分析新闻文本的语义内容和选定的财经主题特征词,对其进行描述,结果为“央行定向下调中小银行人民币存款准备金率,旨在降低小微企业和民营企业的融资成本,深化金融供给侧结构性改革,但此次降准不能被视为央行货币政策转向宽松的信号,因为实际上市场感受到的是中性偏紧缩的货币政策”。结果证明,对财经主题进行主题扩充和描述有效提高了建模结果的可理解性。
3.2.3 财经主题动态性分析
根据“财经主题遗传”的思想,同一财经主题往往出现在连续的时间片中,且主体强度上下波动,具有动态性的特征,因此对于财经主题动态性的研究同样具有重要意义。为了描述和分析财经主题的动态性,本研究绘制了重要主题的主体强度及所有用户的主题强度变化率图,如图8、图9和图10所示。
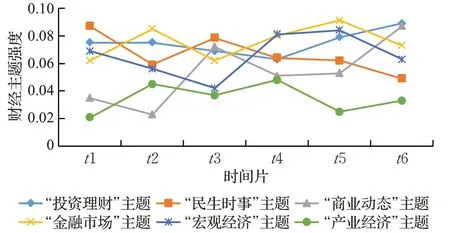
图8 时间窗口内财经主题模型部分主题的演化趋势Fig.8 Evolution trend of some themes of financialtheme model within time window
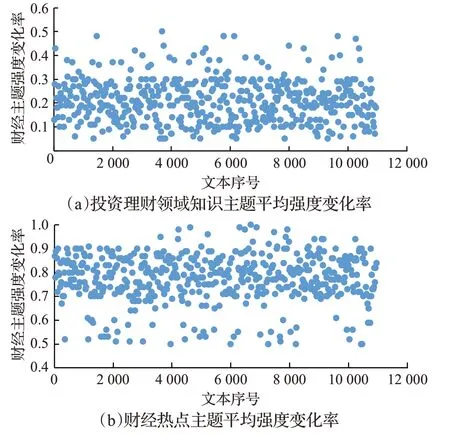
图9 财经主题的平均主题强度变化率分布Fig.9 Distribution of average topic intensity change rate of financial topics

图10 财经平均主题强度变化率分布Fig.10 Distribution of average topic intensity change rate in finance
通过综合分析可以发现以下演化规律:
(1)财经主题的主题内容和强度均在事件序列上随着财经热点话题的变化发生明显变动。结合图8,由于t1时间片中,发生了非洲猪瘟蔓延以及乐清女孩乘滴滴遇害案开庭等事件,“民生时事”主题的主题强度在t1时间片中达到峰值;随着财经领域新旧事件的迭代更新,t2时间片中“民生时事”主题的主题强度出现很大幅度的下降,投资理财方面的主题强度持续保持稳定状态,而金融市场的主题强度由于科创板的试点的逐步推行开始上升且保持在较高的概率;t3中,由于商业动态频繁,如乐视网原董事长贾跃亭卸任、富贵鸟陷入债务危机等事件,商业动态主题中出现了相应的词项,且主题强度持续升高,随着热度下降,其主题强度在后续时间片中开始逐渐下降,直到t6时间片中由于大众对于双十一、双十二活动的关注,以及王思聪所投资的熊猫直播破产等事件,商业动态主题的主题强度达到峰值。
结合图9财经主题中财经热点主题的强度变化率发现,其主题强度的变化率平均保持在80%的水平,这说明财经热点主题普遍具有明显的动态变化性。
(2)投资理财领域知识主题为财经主题的重要组成部分,且主题内容和强度均存在一定稳定性。观察图7财经主题的词云图可以发现,整个时间窗口中,关于“基金”“外汇”和“股票”等投资理财领域的词项一直是财经主题模型的核心特征,稳定不变。结合图8,“投资理财”主题在整个时间窗口中一直保持在较高的概率,波动幅度较小。结合图9投资理财领域知识主题的强度变化率可知,财经主题模型中投资理财领域知识主题强度的变化率相较于财经热点主题较小,维持在20%左右,进一步说明该类型主题变化具有一定的稳定性。
(3)整体财经主题呈现较为明显的动态性。观察图10可知,在整个时间窗口中,绝大部分财经文本的平均主题强度变化率维持在50%到80%之间,其中有9 373篇文本的财经主题其平均主题强度变化率超过50%,占比达85.6%,这说明财经主题整体上随时间推移都呈现出较为明显的波动。由于财经主题与当前的经济政策、市场环境、社会时事、产业发展等的变化都有关系,尤其是经济政策的发布、推行与对财经主题模型的主题强度变化率的影响最为突出,因此呈现出较为明显的波动性。
4 结语
传统财经领域研究通常关注结构化数据,较少关注非结构化的财经类文本数据,并且财经文本数据蕴含的信息量巨大。因此对于财经文本的分析,具有重要的意义。为了解决传统方法存在的噪声干扰、主题间断等问题,并系统化研究财经主题,本文在LDA模型的基础上,提出一种SGC-LDA财经主题模型,对财经统计数据的相关研究提供有效补充。通过对真实财经文本数据的实证分析,得到以下4点结论:(1)通用财经主题在财经主题建模去噪能力方面表现出一定的有效性;(2)SGC-LDA模型在财经主题建模方面表现出优越的分类性能和主题连续性;(3)财经文本主题主要由投资理财、民生时事、商业动态、金融市场、宏观经济、产业经济六个主要部分组成;(4)结合财经主题特征词和财经文本对财经主题的扩充,能够更完整准确地描述其财经主题。同时对于模型动态性进行分析,得出以下3点结论:(1)财经主题的主题内容和强度均在事件序列上随着财经热点话题的变化发生明显变动;(2)投资理财领域知识主题为财经主题的重要组成部分,且主题内容和强度均存在一定稳定性;(3)整体财经主题呈现较为明显的动态性。
本文提出并构建了用于财经主题建模的SGC-LDA模型,实证表明,该模型对财经文本的主题识别、连续性以及噪声过滤等方面表现出一定的有效性。本研究的不足之处有:(1)财经文本的数据来源需要进一步丰富和拓展以及所构建的模型应进行经济领域应用方面的合理探索;(2)仅对财经主题的识别方法和模型进行了研究和实证分析。
